0. 目次
-
- はじめに
-
- 概要
-
- 詳細
- 3.1. MoviePyで動画ファイルを読み込んで映像と音声を分離
- 3.2. 短時間フーリエ変換で音声を分析する
- 3.3. 録音音声の最適なタイミングを探索する
- 3.4. 音声ファイルを更新して映像と結合する
-
- あとがき
1. はじめに
趣味でピアノの演奏動画をツイッターに投稿したりしているものです(Twitter)。電子ピアノで収録する場合、映像をiPhoneで撮影して、音声を電子ピアノの機能で録音してと別々に撮ります。後で動画編集ソフト(Aviutl)で編集していましたが、これがちょっと面倒くさい…。Pythonで動画いじれるかなと調べてみるとできるみたいなのでPythonを使って自動化してみました。
最初に言っておくと、合成には音声分析を用いていて画像認識は行っていません。
Githubに全コード載せときます。コードは基本的にコピペでその機能が動くように意識しました。ちゃんと動かしたい人はこちらをみてください。
https://github.com/amaguri0408/auto_merge_movie
2. 概要
やりたいこと:手元を撮影した動画ファイルと、別撮りの音声ファイルの結合(タイミングを同期)

今回使用するファイルはこちらです
動画ファイル
See the Pen xxEweGW by amaguri0408 (@amaguri0408) on CodePen.
音声ファイル
See the Pen gOwaygY by amaguri0408 (@amaguri0408) on CodePen.
完成したのがこの動画です
See the Pen eYdpogG by amaguri0408 (@amaguri0408) on CodePen.
大雑把な仕組み
動画ファイルには小さいですが鍵盤を叩く音が入っています。動画ファイルから音声を抽出し、分析を行います。同様に音声ファイルにも分析を行います。音が出始める(変化する)場所を両者で一致させ、動画と結合しました。

※上の図はaudacityで編集している様子ですが、音声の編集はこちらのソフトを使うととても簡単にできます。しかし、動画と音声の同期となればaudacityではできないです。動画編集ソフトではどうかというと、この操作がとても簡単にできるソフトもおそらくあります。しかし、私が普段使用しているフリーの動画編集ソフトのaviutlではこの操作はそんなに簡単ではありません。
3. 詳細
具体的なコードも含めての説明です。
3.1. MoviePyで動画ファイルを読み込んで映像と音声を分離
MoviePyを使って動画を編集します。MoviePyの使い方やトラブル対処は[1][2][3](リンクになってます)を参考にしました。まず、MoviePyをインストールします。
Anacondaを使っているのでcondaでインストールします。
conda install moviepy
Anacondaじゃない人はpipでインストールするとよいでしょう。
pip install moviepy
ファイルを読み込んで音声ファイルをそのままファイルに保存します。
import sys
import moviepy.editor as mp
##### 動画ファイル読み込み #####
video_file_name = sys.argv[1] # コマンドライン引数からファイル名を取得
video = mp.VideoFileClip(video_file_name)
video.audio.write_audiofile("movie_sound.wav")
video = mp.VideoFileClip(ファイル名)
でファイルを開く
video.audio.write_audiofile(ファイル名)
で音声を保存しています。
つまったところメモ
moviepyのトラブルに関しては[2][3]を参考にしました。
後の処理ですが、動画をエクスポートするときに映像に音が入らない、無音になってしまうというトラブルがあった。そこで[3]に記述があったように、moviepy/video/io/ffmpeg_writer.pyの87行目あたりの'-i', '-', '-an'の'-an'を消去したら正常に動きました。どうしてかはよくわかってないです。
3.2. 短時間フーリエ変換で音声を分析する
音声の分析に関しては[4]を参考にしました。
下準備としてファイルを読み込んで標準化してモノラルにします。
### ファイルを読み込んでx秒まででモノラルにする
rate, data = scipy.io.wavfile.read(file_name)
data = data / 2**15 # 標準化
data = data[:rate*12] # 12秒までのデータだけを切り抜き
data = (data[:, 0] + data[:, 1]) / 2 # モノラル化
スペクトログラムを表示する
短時間フーリエ変換を行ってそれをグラフ化したようなものをスペクトログラムといいます。それを表示します。詳しくは[4]を参照してください。
import librosa
import librosa.display
### 短時間フーリエ変換
# フレーム長
fft_size = 1024
# フレームシフト長
hop_length = int(fft_size / 4)
# 実行
amplitude = np.abs(librosa.core.stft(data, n_fft=fft_size, hop_length=hop_length))
# 振幅をデシベル単位に変換
log_power = librosa.core.amplitude_to_db(amplitude)
# グラフ
librosa.display.specshow(
log_power, sr=rate, hop_length=hop_length,
x_axis="time", y_axis="hz", cmap="magma")
plt.colorbar(format="%+2.0fdB")
plt.show()
電子ピアノで録音した音声ファイルについてこの処理を行った結果が次のようになりました。
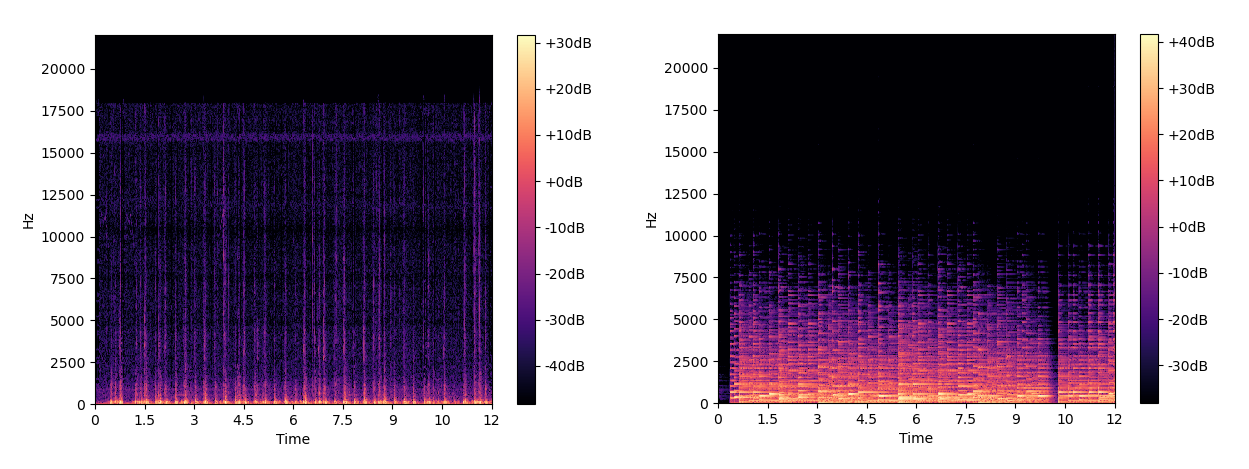
※左が動画の音声、右が電子ピアノの音声
このグラフは、横軸が時間で縦軸が周波数、色は右のバーが示すようにその時間その周波数でどれだけ鳴っているのかを表しています。このグラフを見ていると、周波数成分が切り替わるところがあるのが読み取れます。
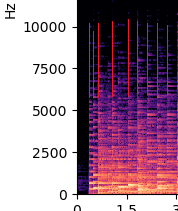
上記右図の一部拡大
この図で赤線の部分が周波数成分が切り替わるところです。線と線の間は同じような周波数が続いているので同じ音が続いていると考えられます。この周波数成分が切り替わるところがまさに音を鳴らし始めたところです。このタイミングを検知できれば動画の音声と同期できるようになります。周波数成分が切り替わるところをエッジと呼ぶことにします。
エッジを検出する
画像処理でエッジ検出というものがあります。簡単に言うと画像の輝度が大きく変化する場所を検出するというものです。エッジ検出についての詳しい説明はこちら等を見てください。この画像処理のエッジ検出のように周波数成分が大きく切り替わるところを検出したいと思います。
先程のグラフのデータであるlog_powerの中身は例えば次のようになっています。
[[ 23.19312914 23.19369638 23.19267702 ... 23.75021912 22.74694395 19.81192454]
[ 17.16754515 17.17831162 17.16774823 ... 21.15616827 16.8390254 13.65968477]
[-40.75176063 -41.94922622 -43.47059268 ... 17.2031842 11.25919247 6.81353332]
...
[-44.23359031 -44.23359031 -44.23359031 ... -44.23359031 -42.3577339 -34.60270017]
[-44.23359031 -44.23359031 -44.23359031 ... -44.23359031 -44.23359031 -34.37703212]
[-44.23359031 -44.23359031 -44.23359031 ... -44.23359031 -41.19783753 -34.03656409]]
横軸は時間成分、縦軸は周波数成分となっています。

上記の画像のように、隣り合っている成分各周波数成分の差の二乗を取り、すべて足しました。これをすべての時間について取ると以下のようなリストができます。
[ 2418.88217678 1549.30488421 1360.33843253 ... 5691.17180383 9063.47978256 31077.69730671]
これをグラフにすると以下のようになりました。
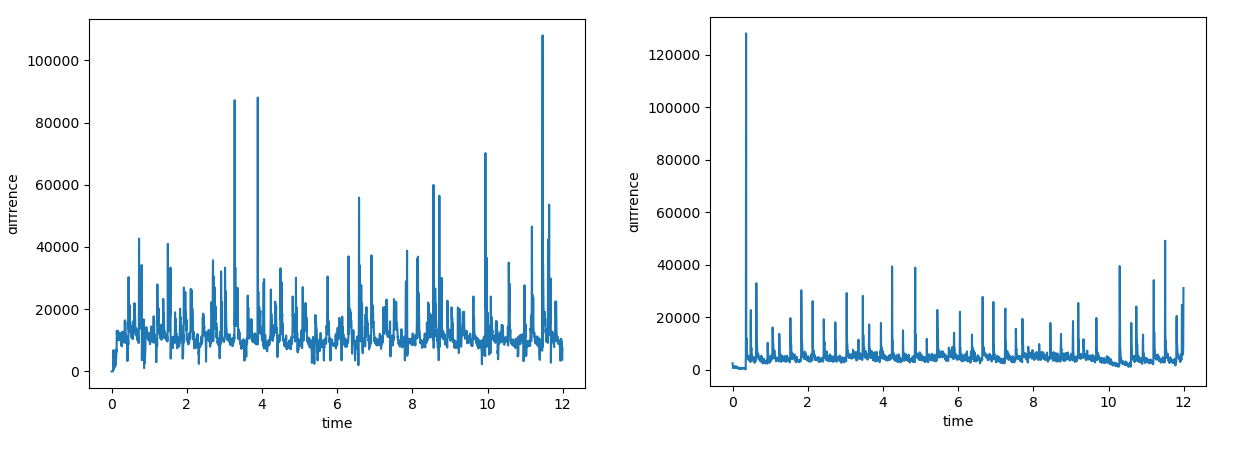
※左が動画の音声、右が電子ピアノの音声
上で示したリストの値が大きいタイミング、つまりグラフの縦軸の成分が大きくなっていてトゲになっているタイミングがエッジだと捉えることができる。
ここまでのコードを以下に示します。
### エッジのグラフ
# tとt-1のlog_powerを引いて2乗して足す
div_log_power = np.zeros(log_power.shape[1]-1)
for i in range(log_power.shape[1]-1):
div_log_power[i] = sum(abs(log_power[:, i+1] - log_power[:, i]) ** 2)
# plot
time = np.arange(0, div_log_power.shape[0]/(rate / hop_length), 1/(rate / hop_length))
plt.plot(time, div_log_power)
plt.xlabel("time")
plt.ylabel("diffrence")
plt.show()
上記のデータからエッジを検出する具体的な方法
エッジを割り出すためのグラフを出すことはできましたが、実際にどこをエッジとするかどう決めるか考えます。
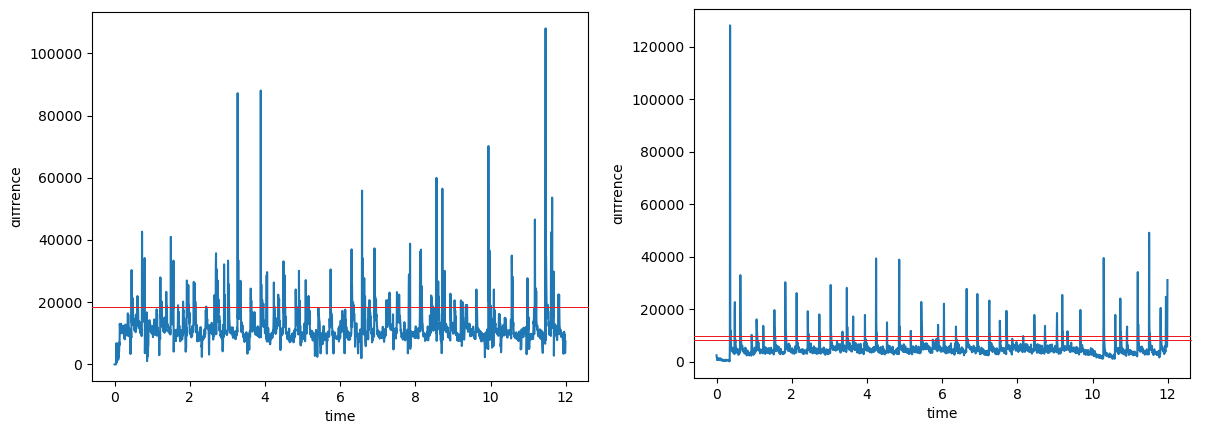
※左が動画の音声、右が電子ピアノの音声
上記のグラフのように適当なところで線を引いてみます。この線の決め方ですが、パーセンタイルを使います。パーセンタイルとは、四分位数の拡張版です。四分位数は簡単に言うとデータを小さい順に並べたときにデータの1/4, 1/2, 3/4の位置の値のことです。パーセンタイルはq/100の値を取ります。
上記左のグラフの線の値はパーセンタイルで90の値、右のグラフは95と50の値です。
上の線を越えてから下の線を下回るまでの値のうち最大値を取ったタイミングを記録しました。動画の音声の方は以後の処理もあって規準を低くしています。

参考図
こうして求めたエッジのタイミングをグラフにプロットします。
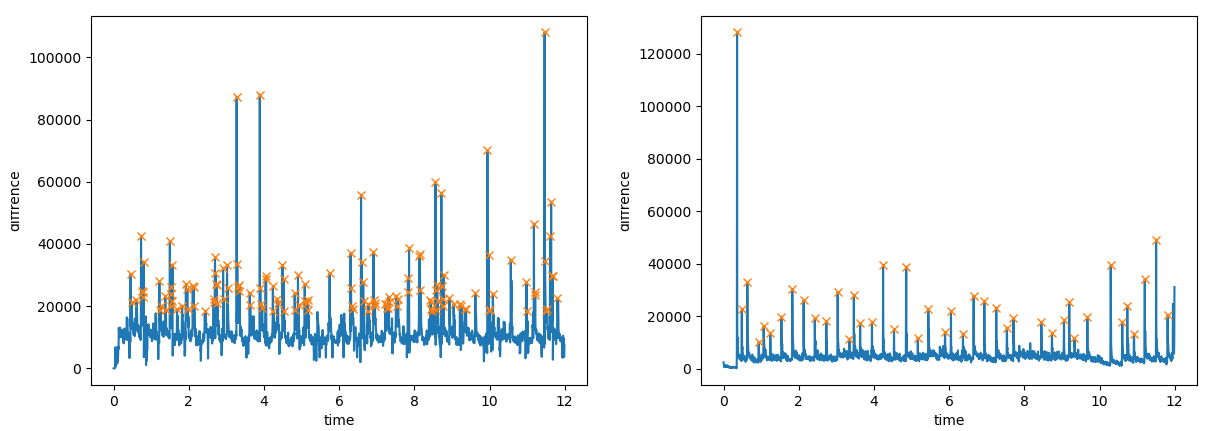
※左が動画の音声、右が電子ピアノの音声
この点のタイミングを記録します。以下は電子ピアノの音声についてのエッジのタイミングです。
[ 0.3599093 0.48761905 0.63274376 0.93460317 1.06811791 1.24226757
1.538322 1.82857143 2.13043084 2.42648526 2.73414966 3.03600907
3.34947846 3.46557823 3.6339229 3.94739229 4.24344671 4.53369615
4.85877551 5.16643991 5.44507937 5.89206349 6.04879819 6.36807256
6.65251701 6.93696145 7.25623583 7.53487528 7.70902494 8.45206349
8.73650794 9.05578231 9.19510204 9.33442177 9.6769161 10.29804989
10.60571429 10.73922902 10.91918367 11.20362812 11.50548753 11.81315193]
以下にコードを示します。
### 時間を割り出す
q = [50, 95] # 仮の値
tmp = np.percentile(div_log_power, q=q)
border1 = tmp[0]
border2 = tmp[1]
edge_array = np.array([])
edge_value_array = np.array([])
flag = False
max_value = 0
max_time = 0
for i, value in enumerate(div_log_power):
if value < border1:
if flag:
edge_array = np.append(edge_array, max_time / (rate / hop_length))
edge_value_array = np.append(edge_value_array, max_value)
max_value = 0
flag = False
elif value > border2:
flag = True
if flag:
if value > max_value:
max_value = value
max_time = i
### エッジのグラフとピークの点
# plot
plt.plot(time, div_log_power)
plt.plot(edge_array, edge_value_array, "x")
plt.xlabel("time")
plt.ylabel("diffrence")
plt.show()
3.3. 録音音声の最適なタイミングを探索する
さて、これで動画と録音の音声に対してのエッジの検出が終わったので、いよいよ録音音声をどのタイミングで開始するか調整する段階に来ました。まずタイミングが最適とはどういう状況下考えてみます。
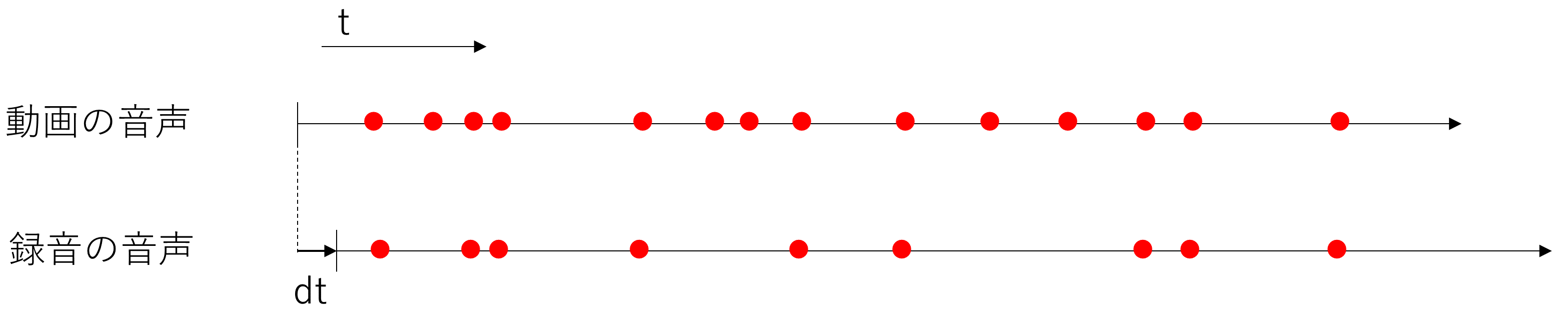
上の図のような状況を考えてみます。まず右方向が時間を表し、点の位置がエッジの位置を表します。上が動画の音声、下が録音の音声のエッジを表しています。録音の音声は動画の音声より開始時間がdtだけずれているという状況です。動画の音声には雑音も含まれているので録音の音声よりもエッジの数が多くなっています。
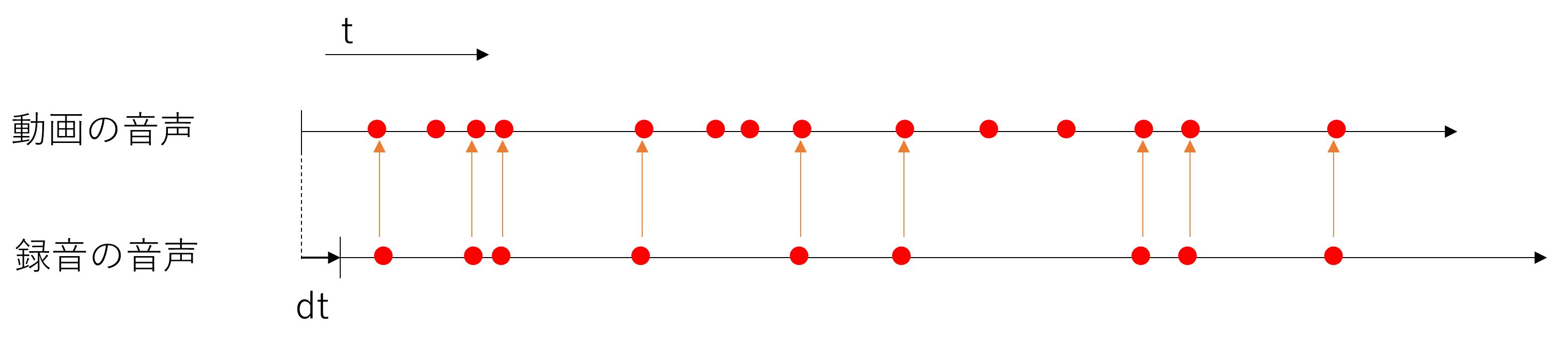
最適なタイミングであるとは、この図のように録音の音声のエッジが動画の音声にも存在していることです。そこで録音の音声のすべてのエッジに対して最も近い動画の音声のエッジの距離を考えます。

dtをさらに大きくするとエッジのタイミングがずれていきます。この図のように距離を取っていきこれの二乗の和を評価値とします。この評価値が一番小さいdtの値を求めたい値としました。
dtに対する評価値をグラフにしました。
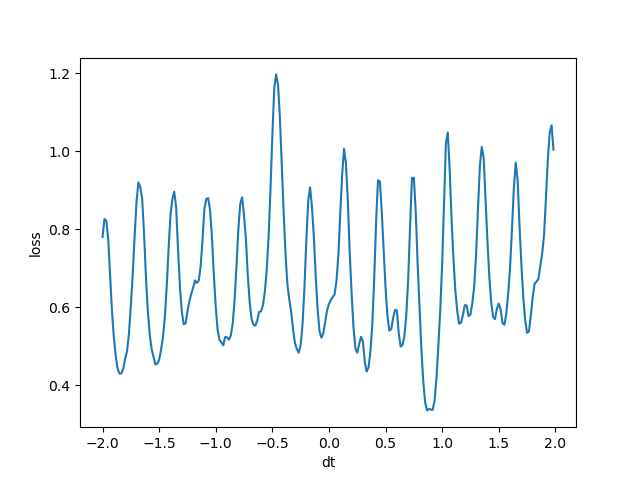
※サンプリングする秒数を増やしています。
このグラフから最適なdtの値は0.8秒あたりであることが分かりました!
(この方法では本当に正しいタイミングで評価値が良くなるとは限らないです。評価値が一番小さいタイミングの他に、2,3番目に小さいタイミングを候補にするともっと良いかなと思います。実装はしてないです)
具体的な求め方
dtに関しては最大値と最小値を決めて1/60秒くらいごとに遷移させます。動画の音声のエッジのリストの長さをN、録音の音声のエッジのリストの長さをMとします。その場合、愚直に求めると計算量はO(NM)となります。NでもN<10^4くらいだと思うので問題ない計算量ですが、一つ工夫してO(MlogN)まで計算量を落とします。
まず愚直に求めると、すべての録音の音声のエッジのタイミングについて、最も近い動画の音声のエッジを求めるので前半でO(M)、後半で**O(N)**かかり、**O(M*N)となります。ここで後半の最も近い動画の音声のエッジを求める工程を二分探索で行います。二分探索の計算量はO(logN)なので最終的な計算量はO(MlogN)**となりました。
二分探索についてはこちらの記事がめちゃくちゃわかりやすいです。ぜひ見てみてください。
コードは以下です
##### 定数の定義 #####
SAMPLE_RANGE = 12 # 開始から何秒をサンプリングするか
FPS = 60 # 一秒にFPS個の候補
MERGIN = 2 # 音声を±何秒までずらすのを候補とするか
'''
edge_movie_array : 動画の音声のエッジのリスト
edge_sound_array : 録音の音声のエッジのリスト
'''
##### 動画と音声の最適なタイミングを探す #####
# 二分探索のために値を追加
edge_movie_array = np.insert(edge_movie_array, 0, 0)
edge_movie_array = np.append(edge_movie_array, SAMPLE_RANGE)
ans_dt = 0
min_loss = float("inf")
dt_array = np.array([])
loss_array = np.array([])
for i in range(-FPS * MERGIN, FPS * MERGIN):
dt = i / FPS
dt_array = np.append(dt_array, dt)
loss = 0
for j in edge_sound_array:
if j < MERGIN or j > SAMPLE_RANGE - MERGIN: continue
key = j + dt
ng = 0
ok = edge_movie_array.shape[0] - 1
while abs(ok - ng) > 1:
mid = (ng + ok) // 2
if edge_movie_array[mid] > key: ok = mid
else: ng = mid
loss += min((edge_movie_array[ng] - key) ** 2, (edge_movie_array[ok] - key) ** 2)
loss_array = np.append(loss_array, loss)
if loss < min_loss:
min_loss = loss
ans_dt = dt
print(ans_dt, min_loss)
### 損失をグラフで表示
# plot
plt.plot(dt_array, loss_array)
plt.xlabel("dt")
plt.ylabel("loss")
plt.show()
3.4. 音声ファイルを更新して映像と結合する
音声をどれだけ動画に対してずらすか求まったのでそれをもとに、録音の音声ファイルを更新します。
'''
ans_dt : ずらす秒数
'''
##### 音声ファイルの開始位置を変更して保存 #####
wav_file = sys.argv[2]
rate, data = scipy.io.wavfile.read(wav_file)
if ans_dt >= 0:
data = np.insert(data, 0, np.zeros((int(rate * ans_dt), 2)), axis=0)
else:
data = data[abs(int(rate * ans_dt)):]
scipy.io.wavfile.write("out_sound.wav", rate, data)
その後、moviepyを使ってもとの動画ファイルと新しく作った音声ファイルを結合して出力します。
##### 映像と音声を結合して保存 #####
input_file = sys.argv[1]
video = mp.VideoFileClip(input_file)
video = video.set_audio(mp.AudioFileClip("out_sound.wav"))
video.write_videofile("main.mp4")
これで録音の音声とタイミングがピッタリ合った動画が出力できました!
4. あとがき
初めてQiitaの記事書いて大変でした。面白かった!とか、悩んでいたことが解決した!とか、そんなことできるんだやってみよう!とか一人でも多く感じてくれたら嬉しいです。
参考
[1] 動画からの音声抽出と動画への音声結合 - test.py, 2018/3/22, https://testpy.hatenablog.com/entry/2018/03/22/003000, 最終閲覧日:2020/11/29
[2] MoviePyを使ったらいろいろつまづいたのでメモ - Qiita, 2020/3/7, https://qiita.com/mynkit/items/74d496ce4703d92cece6, 最終閲覧日:2020/11/29
[3] CompositeVideoClip has no audio · Issue #876 · Zulko/moviepy, 2018/11/27, https://github.com/Zulko/moviepy/issues/876, 最終閲覧日:2020/11/29
[4] Pythonで音声解析 – 音声データの周波数特性を調べる方法, 2020/6/8, https://jorublog.site/python-voice-analysis/, 最終閲覧日:2020/11/29
[5] 【説明しよう】これがQiitaの投稿に動画(Youtube)を埋め込んで再生させる方法だ。 - Qiita, 2020/11/16, https://qiita.com/takada_impl/items/0287ddad3966a42903fb, 最終閲覧日:2020/11/29
[6] QiitaにCodePenを埋め込めない問題の対策 - Qiita, 2019/2/19, https://qiita.com/icchi_h/items/1e9447c27d6723872bf1, 最終閲覧日:2020/11/29