本記事はこちらのブログを参考にしています。
翻訳にはアリババクラウドのModelStudio(Qwen)を使用しております。
PolarDBがTPC-Cベンチマークで世界記録を達成!技術の秘密に迫るシリーズ記事第2弾
最近、PolarDBは、以前の記録を2.5倍上回るパフォーマンスでTPC-Cベンチマークテストリストのトップに立ちました。1分あたり20億5,500万トランザクション(tpmC)というパフォーマンスと、単位コスト0.8元(価格/tpmC)で、性能とコストパフォーマンスの両面で新しいTPC-C世界記録を樹立しました。それぞれのシンプルに見える数字には、データベースの性能、コストパフォーマンス、安定性に対する無数の技術者の究極の追求が込められています。PolarDBの革新の歩みは止まることを知りません。「TPC-C首位獲得のためのPolarDB技術秘話」シリーズをここに公開し、「ダブル1位」の裏側にある物語をお伝えします。ぜひご期待ください!本稿はそのシリーズ第2弾「無限クラスタと分散スケーリング」です。
概要
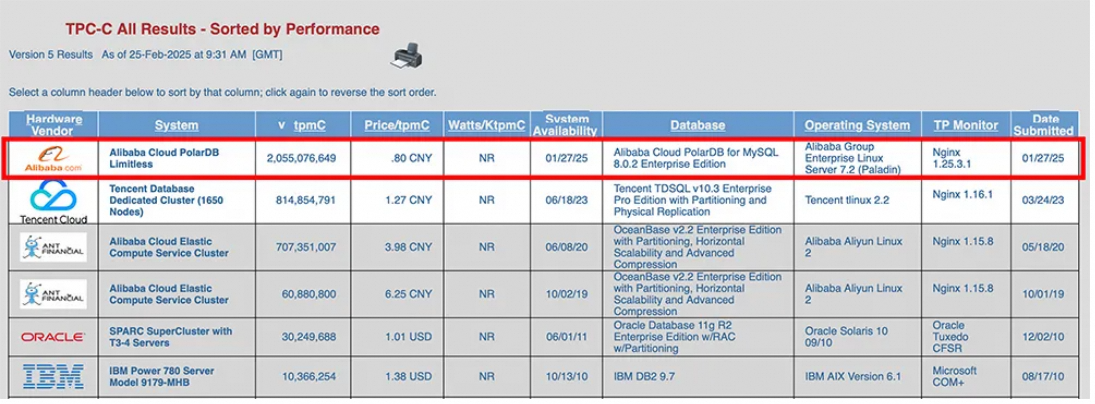
今回のTPC-Cベンチマークテストでは、PolarDB for MySQL 8.0.2を使用しました。PolarDB for MySQLは、Multi-master Cluster(Limitless)をサポートしています。読み取り専用ノードを追加することで、1つのプライマリノードと複数の読み取り専用ノードの構成をMulti-master Cluster(Limitless)に変更できます。PolarDB for MySQL Multi-master Cluster(Limitless)は、マルチマスターノード、メモリ統合、分散ストレージ、秒単位でのスケールアウトをサポートしています。また、シングルテーブルの読み書き操作を大量のノードにわたって透過的にスケールアウトすることも可能です。このTPC-Cベンチマークテストでは、PolarDBは2,340台の読み書きノード(仕様:48コア、512GB)で1分あたり20億5,500万トランザクション(tpmC)をサポートし、tmpCおよび価格/tpmCの両方でTPC-Cのパフォーマンスとコストパフォーマンスの世界記録を更新しました。
初期のクラウドネイティブなリレーショナルデータベースの主な形態は、コンピュートとストレージの分離に基づいた1つのプライマリノードと複数の読み取り専用ノードでした。これはネイティブまたは管理されたMySQL/PostgreSQLデータベースをうまく置き換えることができますが、単一書き込みアーキテクチャにより書き込み能力のスケーリングが制限されていました。クラウドネイティブなデータベース技術の進化に伴い、大規模展開と読み書きスケーリングをサポートするPolarDB for MySQL Multi-master Cluster (Limitless)が開発されました。そのコアの利点は、各ノードが読み書きリクエストを処理できるように計算ノードを柔軟にスケーリングできることです。さらに、複数のノードで同時に書き込みを行うことが可能で、単一サーバーの高性能と高弾力性を維持しながら、RDMA/CXLなどの技術を利用してノード間のトランザクションとデータを効率的に統合し、トランザクションの一貫性を保ちながら高速かつ透過的なクロスサーバーの読み書きスケールアウトを実現します。本稿では、PolarDB for MySQL Multi-master Cluster (Limitless)の全体的なアーキテクチャと、TPC-Cでの成功を支えたコア技術的革新について説明します。
1. PolarDB for MySQL Multi-master Cluster (Limitless)の全体アーキテクチャ
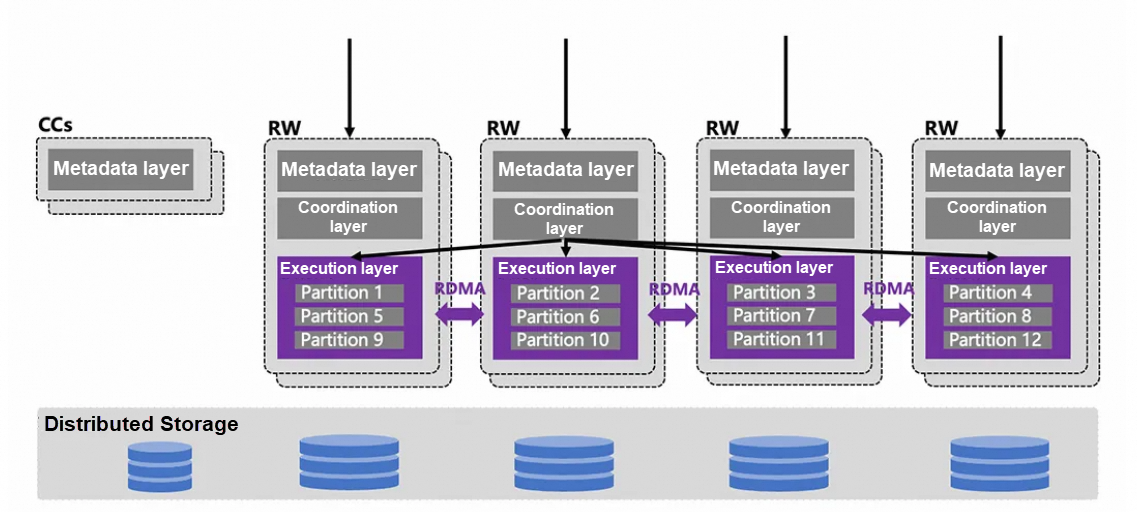
図1:PolarDB for MySQL Multi-master Cluster (Limitless)のアーキテクチャ
PolarDB for MySQLクラスタは、複数の読み書き可能なコンピュートノード、複数の読み取り専用コンピュートノード、およびオプションのCache Coordinatorノードで構成されています。その基盤層は、分散共有ストレージに基づいています。各読み書きノードは読み書き可能であり、RDMA/CXLの高速ネットワークを介してCache Coordinatorsと通信します。Cache Coordinatorsは、クラスタのメタデータ管理やトランザクション情報の調整を担当し、CDC機能をサポートし、統一されたグローバルbinlogを出力します。さらに、このアーキテクチャは、パーティション分割された単一テーブルの異なるパーティションを動的に異なる読み書きノードに分散します。パーティション刈り込みモジュールが、実行計画をどの読み書きノードにルーティングすべきかを決定します。これにより、異なるパーティションを各読み書きノードに同時に書き込むことができ、書き込み能力のスケールアウトを実現し、クラスタ全体の同時読み書き性能を大幅に向上させます。また、クラスタはクロスノードの分散クエリ、DML操作、DDL操作をサポートし、RDMAメモリ融合を通じてクロスノードトランザクションの一貫性と原子性を確保します。このアーキテクチャは、グローバルクエリ、複数テーブルの結合クエリ、列指向クエリの加速をサポートするグローバル読み取り専用ノードを設計しています。PolarDBクラスタでは、複数の読み書きコンピュートノードが対称的なアーキテクチャを使用しています。単一の読み書きノードは、従来の分散データベースのコーディネーターノード(CN)とデータノード(DN)と同じ機能を提供します。CNとDNの数を別々に設定する必要はありません。対称ノードには次のような大きな利点があります:
- 異なる負荷下で、1つのCN/DNが満杯で他のものがアイドル状態になる場合でも、リソース利用率を最大限に高め、リソースの無駄を防ぐことができます。
- CN/DNの分離による余分な通信コストを削減し、パフォーマンスを向上させることができます。
- 計算ノードはオリジナルのMySQL構文解析/オプティマイザ/エグゼキューターを使用して100%のMySQL互換性を提供します。
2. 高性能なクロスサーバーの読み書きスケールアウト
2.1 クラウドネイティブトランザクションシステム PolarTrans
ネイティブInnoDBトランザクションシステムはアクティブトランザクションリストに基づいて実装されていますが、リストの維持には大規模なグローバルロックが必要であり、それに伴うコストがかかり、高並列環境下でのシステム全体のパフォーマンスボトルネックになりやすいです。さらに、ほとんどの分散トランザクション一貫性ソリューションがコミットタイムスタンプスキーム(TSO、TrueTime、HLC)に基づいていることを考えると、PolarTransはCommit Timestamp Store (CTS)を使用してネイティブトランザクションシステムを最適化しています。コアとなるデータ構造はCTSログで、これはリングバッファのセグメントで構成されています。トランザクションID trx_idはモジュロ演算によって対応するスロットにマッピングされ、各スロットにはtrxポインタとcts値が格納されます。最適化の核心となるアイデアは、複雑なデータ構造の維持を取り除くことです。CTSログはトランザクションステータスの更新やトランザクション可視性といったトランザクションのコアデータを記録します。この操作は軽量です。さらに、PolarTransは大部分のロジックをロックなしで最適化しているため、混合読み書き
CNは、DNで実行されたDDL操作をすべてロールバックするための命令を各DNに送信し、これにより分散DDL操作の原子性を確保します。3. 高可用性メカニズム
高可用性を確保するために、従来のOLTPデータベースでは、各プライマリノードに対して1つまたは複数のスタンバイノードを維持しています。私たちは、ユーザーがコストを削減しつつシステムの高可用性を維持できるように、さまざまな高可用性ソリューションを提供しています。まず、プライベートリードオンリーノードに基づく高可用性ソリューションでは、ユーザーは各読み書きノードに対してプライベートリードオンリーノードを設定できます。このプライベートリードオンリーノードと読み書きノードは同じデータを共有しており、追加のデータストレージは必要ありません。読み書きノードが故障した場合、そのプライベートリードオンリーノードは数秒以内に読み書きノードに切り替わり、トラフィックリクエストを引き継ぐことができます。クラスタ全体のパフォーマンスには影響しません。一方、読み書きノードにプライベートリードオンリーノードを設定しない場合でも、読み書きノードが故障した際に別の読み書きノードが互いにスタンバイノードとして機能するメカニズムを提供して高可用性を確保します。読み書きノードが故障した際には、負荷の低い別の読み書きノードを選択し、障害ノード上のデータベースやテーブルをそのノードに再マッピングすることで、迅速にトラフィックを引き継ぐことが可能です。ただし、リソース制約により、高負荷下ではクラスター全体のパフォーマンスに影響が出る可能性があります。4. グローバルリードオンリーノード
複数のテーブル/データベースにまたがるグローバルクエリ/結合クエリをサポートするために、グローバルリードオンリーノード(RO)を設計しました。クラスタ内の各読み書きノードが共有ストレージ内の全データにアクセス可能であることを考慮し、グローバルリードオンリーノードは複数の読み書きノードを集約したデータベースとして設計されています。グローバルリードオンリーノードは、すべての読み書きノードによって書き込まれたデータを直接クエリできるため、複数の読み書きノードからデータを取得して集約する必要はありません。グローバルリードオンリーノードには追加のデータコピーを保存する必要がないため、集約データベースの追加ストレージオーバーヘッドを削減できます。複数の読み書きノードにまたがるグローバルクエリの場合、データベースクラスタは透過的なルーティングを提供し、PolarProxyを通じて自動的にグローバルクエリをグローバルリードオンリーノードにルーティングします。5. 極限のパフォーマンスと拡張性
PolarDB for MySQL リミットレス超大規模クラスタ(2,340台の読み書きノード、仕様は48コア、512GB)は、TPC-Cベンチマークプログラムを使用してパフォーマンステストを行っています。TPC-Cはデータベース分野における「オリンピック」とされており、OLTP(オンライントランザクション処理システム)データベースの性能試験において唯一の国際的に権威あるリストです。5.1 超大規模クラスタでの安定したパフォーマンス
 図3: PolarDB TPCCレポートからの抜粋
図3: PolarDB TPCCレポートからの抜粋
8時間連続のストレステスト中、クラスタ全体のtpmC変動率は0.16%以内(標準要件は2%以内)で推移し、8時間にわたって連続的かつ無誤差、かつ安定したストレステストを達成しました。クラスタ全体のtpmCは20億5500万に到達し、TPC-Cの新しい世界記録を樹立し、世界ランキング1位となりました。5.2 超大規模クラスタでの高可用性および災害復旧能力
 図4: PolarDB TPCC災害復旧シナリオでのパフォーマンスデータ
図4: PolarDB TPCC災害復旧シナリオでのパフォーマンスデータ
災害復旧シナリオテストでは、異なるコンポーネントに対する障害テストを行い、物理サーバーを実際に電源オフにして検証しました。クラスタは予期しない物理サーバーの故障が発生しても10秒以内にフェイルオーバーを完了し、2分以内に全体のパフォーマンスを回復できることを確認しました。災害復旧テスト中のクラスタ全体のパフォーマンスへの影響は2%以内に抑えられました(標準要件は10%以内)。データの整合性と分散トランザクションの一貫性も保証されています。5.3 秒単位でのスケールアウト能力
 図5: 秒単位でのスケールアウトテスト結果
図5: 秒単位でのスケールアウトテスト結果
スケールアウトテスト中、作成された4つのデータベースはすべて読み書きノード1上にありました。ストレステスト中に、読み書きノードの数を徐々に増やし、データベース2〜4を順次新しい読み書きノードにバインドしました。図はスケールアウトプロセス中のクラスタ全体のパフォーマンスの変化を示しており、クラスタが秒単位でスケールアウトできることを示しています。まとめ
PolarDB は、RDMAやCXLなどの新ハードウェアと深く統合された最初のクラウドネイティブリレーショナルデータベースです。PolarDBは大規模で高性能なクロスサーバーの読み書きスケールアウトをサポートし、数千のコンピューティングノードまでスケールアップできます。このアーキテクチャは、ノード間での高性能トランザクション一貫性、RDMA技術と深く統合されたクラウドネイティブトランザクションシステムPolarTrans、および弾力的な並列クエリ(ePQ)をサポートしています。その分散能力により、ほぼ線形のパフォーマンススケールアウトを実現します。さらに、インデックス構造やI/Oパスなど、90以上の最適化技術を通じて、クラスタ内の各ノードが究極のシングルサーバーパフォーマンスを達成しています。特に強調すべき点は、PolarDB for MySQL マルチマスタクラスタ(Limitless)がTPC-Cで新しい世界記録を達成したことです。これは、サーバー間での読み書きスケールアウトが可能なPolarDBの革新的なマルチマスタマルチライトクラウドネイティブアーキテクチャが、単一クラスタのスケーラビリティのボトルネックを打破しただけでなく、世界最大の同時トランザクションピークにも耐えうることを示しており、パフォーマンスやスケーラビリティ、その他の側面でグローバルリーダーであることを証明しています。