この記事は全4本シリーズの2本目です。前回の記事をまだ読んでいない方は、ぜひ1本目からご覧ください。
0. 学習の前に
0-1. 全体のゴール
- BigQueryのオープンデータから、自分が欲しいデータを抽出する
- 抽出したデータを分析する
0-2. 技術
- BigQuery
- Colaboratory
- Google Cloud Platform
- Google Gemini
- Python3
- SQL
0-3. この記事で扱う範囲
● 1. データセットの選択
● 2. 集計データの内容
● 3. 結果の事前予想
● 4. データ抽出
* 4-1. アメリカで人気の名前年間トップ10(表)
* 4-2. アメリカで人気の名前年間トップ5の推移(折れ線グラフ)
・4-2-1. Googleアカウント認証
・4-2-2. SQLクエリ定義
・4-2-3. BigQueryからPandasへ読み込み
・4-2-4. データの集計と折れ線グラフ化
* 4-3. アメリカ年間出生者数に占めるトップ10の割合の推移(帯グラフ)
・4-3-1. データセットからデータ抽出
・4-3-2. SQLクエリ定義
・4-3-3. BigQueryからPandasへ読み込み
・4-3-4. データの集計と帯グラフ化
● 5. データ分析
* 5-1. 登録者数に占めるトップ10の割合の減少
・5-1-1. 女の子
・5-1-2. 男の子
* 5-2. ボーダーレスな名前の増加
* 5-3. ユニセックス・男女ペアの名前の増加
・5-3-1. ユニセックスな名前
・5-3-2. 男女ペアの名前
* 5-4. 1910年と2021年のトップ10比較
・5-4-1. 女の子
・5-4-2. 男の子
* 5-5. トップ5入りする名前の変遷
・5-5-1. 女の子
・5-5-2. 男の子
* 5-6. その他
・5-6-1. 2022年以降のデータ
4-2. アメリカで人気の名前年間トップ5の推移(折れ線グラフ)
ここからはGoogle Colabの出番です。Pythonを使い、4-1.でで取得したデータをベースに新たなSQLクエリを作り、アメリカで人気の名前年間トップ5の推移を折れ線グラフで可視化してみます。
出力する折れ線グラフのイメージです。ただし今回の分析対象は112年間分のデータなので、もっとカオスなグラフになるはず。
4-2-1. Googleアカウント認証
ColabでBigQueryにアクセスするには認証が必要なので、まずはGoogleアカウントで認証します。
# BigQueryクライアントライブラリをインポート
from google.cloud import bigquery
from google.colab import auth
# Googleアカウントで認証を行い、BigQueryへの接続を許可する
auth.authenticate_user()
print("Successfully authenticated!")
Googleアカウントの認証画面が表示され、一通り許可すると認証成功のメッセージが出力されます。print()は認証の成功を確認するためだけのコードなので、省略しても問題ありません。
Successfully authenticated!
4-2-2. SQLクエリ定義
続いては、Colabでも上記SQLクエリを定義します。4-2.では「男女別トップ5」のデータが必要ですが、4-3.(次回記事)では「男女別トップ10」のデータを使う予定です。そこで、性別と取得対象(トップn)を引数に指定できる関数「get_top_n_by_gender」を作成しました。
ちなみに末尾に★がある行は、4-1.のSQLクエリから変更・追加しています。
# アメリカの赤ちゃんの名前データの分析に必要なSQLクエリを定義
# BigQuery Studioで実行した、アメリカで人気の名前年間トップ5を抽出するクエリ
PJ_ID = 'GCPのプロジェクトID'
# gender_code:'F'または'M'
# top_n:取得対象(トップn)
def get_top_n_by_gender(gender_code, top_n):★
sql_query_top_n = f"""★
SELECT
name,
year,
gender,
sumNumber,
rank
FROM (
SELECT
name,
year,
gender,
SUM(number) AS sumNumber, -- 全米の登録者数
ROW_NUMBER() OVER(
PARTITION BY year, gender -- 各「年」と「性別」で順位をリセット
ORDER BY SUM(number) DESC
) AS rank
FROM
`bigquery-public-data.usa_names.usa_1910_current`
GROUP BY
name, year, gender
) AS RankedData
WHERE
rank <= {top_n}★
AND gender = '{gender_code}'★
ORDER BY
year DESC,
gender ASC,
rank ASC
"""
df_ranking = read_gbq(sql_query_top_n, project_id=PJ_ID)★
return df_ranking★
変更箇所の簡単な解説は以下の通り。
- def get_top_n_by_gender(gender_code, top_n)::関数定義
- sql_query_top_n = f""":
- 絞り込み対象の変更に合わせ、クエリ名を10→5に変更
- 引数を使用すべく、f文字列対応でf追加
- rank <= {top_n}:取得対象(トップn)指定に変更
- AND gender = '{gender_code}':性別指定を追加
- df_ranking = read_gbq(sql_query_top_n, project_id=PJ_ID):Pandasの機能でGCPプロジェクトのBigQueryからクエリ結果を直接読み込み、DataFrameとして扱う
- return df_ranking:アメリカで人気の名前年間トップ5の、指定した性別のデータを返す
4-2-3. BigQueryからPandasへ読み込み
続いて、上記で定義したSQLクエリ「sql_query_top10」を使ってBigQueryにアクセスします。その結果をPandasのデータフレームとしてColabに取り込みます。
import pandas as pd
from pandas_gbq import read_gbq
# BigQueryからデータを読み込む
df_usa_name_top5_female = get_top5_by_gender('F', 5)
df_usa_name_top5_male = get_top5_by_gender('M', 5)
print("Successfully inputted!")
print("USA Name Data Top5 (Girls)")
print(df_usa_name_top5_female.head())
print("USA Name Data Top5 (Boys)")
print(df_usa_name_top5_male.head())
4-2-1. 同様、print()は処理成功を確認するためだけのコードです。
Successfully inputted!
USA Name Data Top5 (Girls)
name year gender sumNumber rank
0 Olivia 2021 F 17728 1
1 Emma 2021 F 15433 2
2 Charlotte 2021 F 13285 3
3 Amelia 2021 F 12952 4
4 Ava 2021 F 12759 5
USA Name Data Top5 (Boys)
name year gender sumNumber rank
0 Liam 2021 M 20272 1
1 Noah 2021 M 18739 2
2 Oliver 2021 M 14616 3
3 Elijah 2021 M 12708 4
4 James 2021 M 12367 5
ちなみに急にBoysとGirlsを使ったのは、単純に「新生児ならMale・FemaleよりBoys・Girlsのほうがしっくりくる」と思っただけです。深い意味はありません。
4-2-4. データの集計と折れ線グラフ化
自分の備忘録を兼ねて、コメントは結構丁寧につけました。
import matplotlib.pyplot as plt
import numpy as np
# 年間の名前の順位推移をグラフ化し、凡例をグラフの下に配置する。
#df_ranking:4-2-2.で抽出したデータ、title:グラフのタイトル
def plotline_rank(df_ranking, title):
# 1. データフレームをピボット(ワイドフォーマットに変換)
df_pivot = df_ranking.pivot(
index='year', # 折れ線グラフの行見出し
columns='name', # 折れ線グラフの列見出し
values='rank' # 集計対象のデータ
).fillna(6) # トップ5圏外を6位として表示(NaNの補完)
plt.figure(figsize=(15, 8)) # グラフの大きさ(単位:インチ)
ax = plt.gca() # 現在のグラフの描画領域
# 2. 横軸の目盛を5年単位に設定
min_year = int(df_pivot.index.min()) # indexの最小値(1910)
max_year = int(df_pivot.index.max()) # indexの最大値(2021)
start_tick = (min_year // 5) * 5 # 横軸目盛の開始位置(1910)
year_ticks = np.arange(start_tick, max_year + 1, 5) # 5区切りの目盛配列を生成(目盛の最大値はmax_yearを超えない=2020)
ax.set_xticks(year_ticks) # 配列year_ticksの要素の位置に目盛を設定
ax.set_xticklabels(year_ticks) # 配列year_ticksの要素で目盛のラベルを設定
# 3. 折れ線グラフの描画
df_pivot.plot(
kind='line', # グラフの種類:折れ線グラフ
ax=ax, # 描画先のオブジェクト
title=title, # グラフのタイトル:title(引数)
xlabel='Year', # X軸のラベル
ylabel='Rank', # Y軸のラベル
legend=True, # 凡例を表示
)
# 4. Y軸を反転(1位を上、5位を下に表示)
ax.invert_yaxis() # Y軸を反転
ax.set_ylim(5.5, 0.5) # Y軸の表示範囲を0.5~5.5に設定
plt.grid(axis='y', linestyle='--') # Y軸に沿って破線のグリッド線を表示
# 5. 凡例の位置とレイアウトを調整 (グラフの下に横長に配置)
ax.legend(
loc='upper center', # 凡例ボックス内の要素の配置基準点を「中央上」に設定
bbox_to_anchor=(0.5, -0.15), # 凡例ボックス全体を配置する座標を指定(X軸の下)
fancybox=False, # 凡例ボックスの枠に装飾を施す
shadow=False, # 凡例の周囲に影をつける
ncol=8 # 凡例を横8列で並べる
)
# 6. X軸の表示範囲を調整
ax.set_xlim(min_year, max_year) # X軸の表示範囲を設定(1910~2021)
plt.tight_layout(rect=[0, 0.05, 1, 1]) # レイアウトの最終調整(描画領域の指定)
plt.show() # グラフを表示
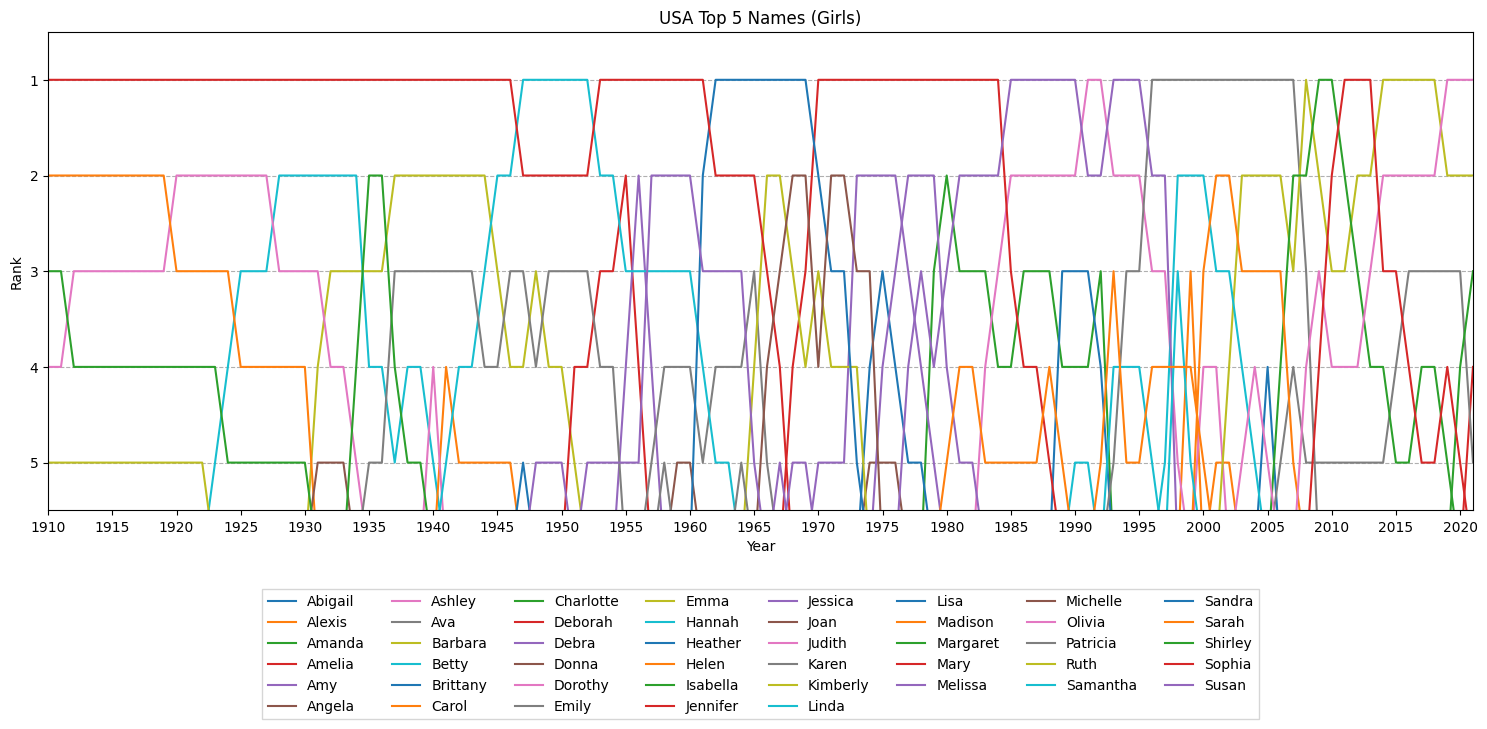
# アメリカで人気の名前年間トップ5の推移(女の子)の折れ線グラフを表示
plotline_rank(
df_usa_name_top5_female,
'USA Top 5 Names (Girls)'
)
# アメリカで人気の名前年間トップ5の推移(男の子)の折れ線グラフを表示
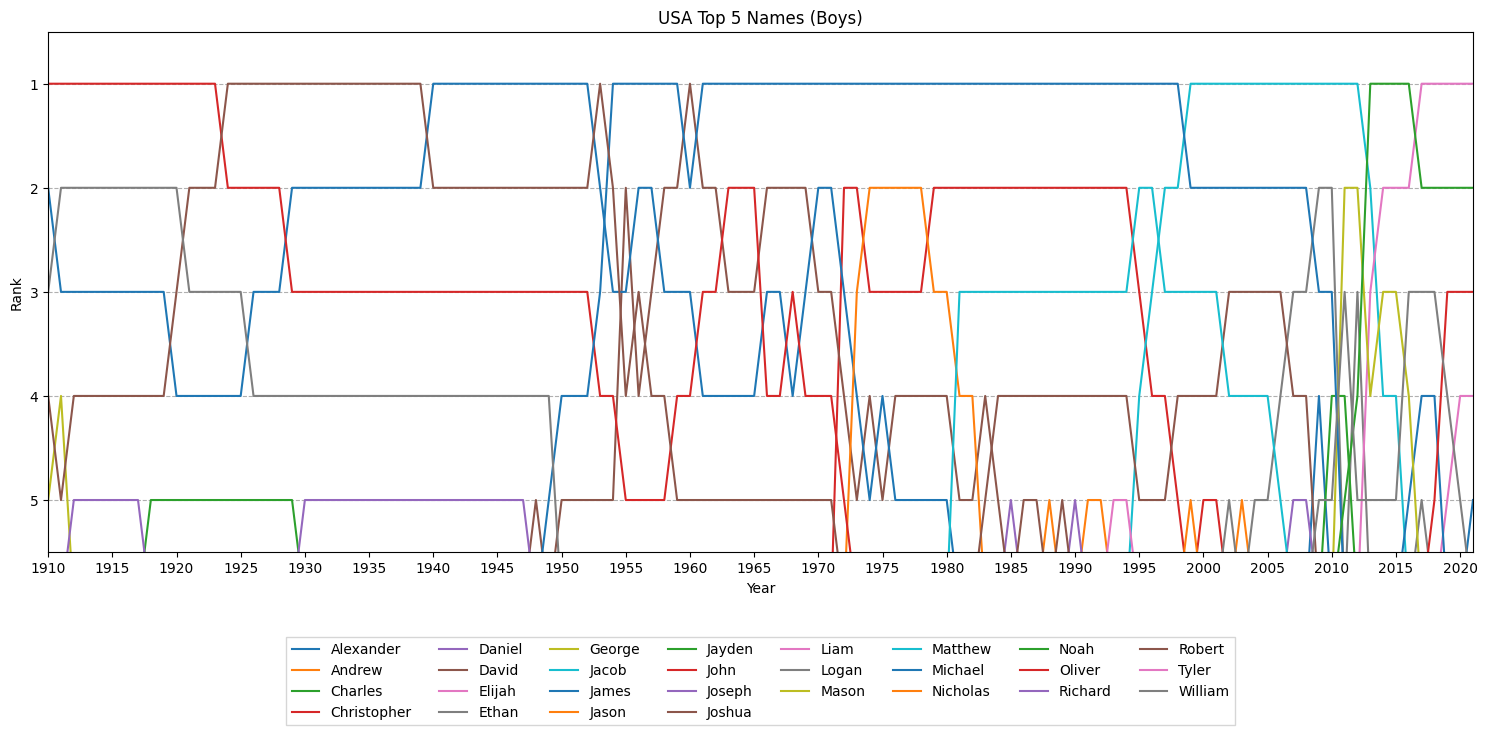
plotline_rank(
df_usa_name_top5_male,
'USA Top 5 Names (Boys)'
)
処理結果として表示された折れ線グラフが次の通りです。まずは女の子。
次に男の子。
次回は帯グラフの作成です
これらの結果についての考察は、最後の記事で行います。折れ線グラフの共有をもって、この記事を締めたいと思います。