この記事は全4本シリーズの3本目です。過去の記事をまだ読んでいない方は、ぜひ1本目からご覧ください。
前回記事がこちらです。
0. 学習の前に
0-1. 全体のゴール
- BigQueryのオープンデータから、自分が欲しいデータを抽出する
- 抽出したデータを分析する
0-2. 技術
- BigQuery
- Colaboratory
- Google Cloud Platform
- Google Gemini
- Python3
- SQL
0-3. この記事で扱う範囲
● 1. データセットの選択
● 2. 集計データの内容
● 3. 結果の事前予想
● 4. データ抽出
* 4-1. アメリカで人気の名前年間トップ10(表)
* 4-2. アメリカで人気の名前年間トップ5の推移(折れ線グラフ)
・4-2-1. Googleアカウント認証
・4-2-2. SQLクエリ定義
・4-2-3. BigQueryからPandasへ読み込み
・4-2-4. データの集計と折れ線グラフ化
* 4-3. アメリカ年間出生者数に占めるトップ10の割合の推移(帯グラフ)
・4-3-1. データセットからデータ抽出
・4-3-2. SQLクエリ定義
・4-3-3. BigQueryからPandasへ読み込み
・4-3-4. データの集計と帯グラフ化
● 5. データ分析
* 5-1. 登録者数に占めるトップ10の割合の減少
・5-1-1. 女の子
・5-1-2. 男の子
* 5-2. ボーダーレスな名前の増加
* 5-3. ユニセックス・男女ペアの名前の増加
・5-3-1. ユニセックスな名前
・5-3-2. 男女ペアの名前
* 5-4. 1910年と2021年のトップ10比較
・5-4-1. 女の子
・5-4-2. 男の子
* 5-5. トップ5入りする名前の変遷
・5-5-1. 女の子
・5-5-2. 男の子
* 5-6. その他
・5-6-1. 2022年以降のデータ
4-3. アメリカ年間出生者数に占めるトップ10の割合の推移(帯グラフ)
今回はデータを帯グラフで可視化してみます。作業手順自体は前回記事(4-2.)とほぼ変わりません。クエリやPythonの記述が少し変わる程度です。
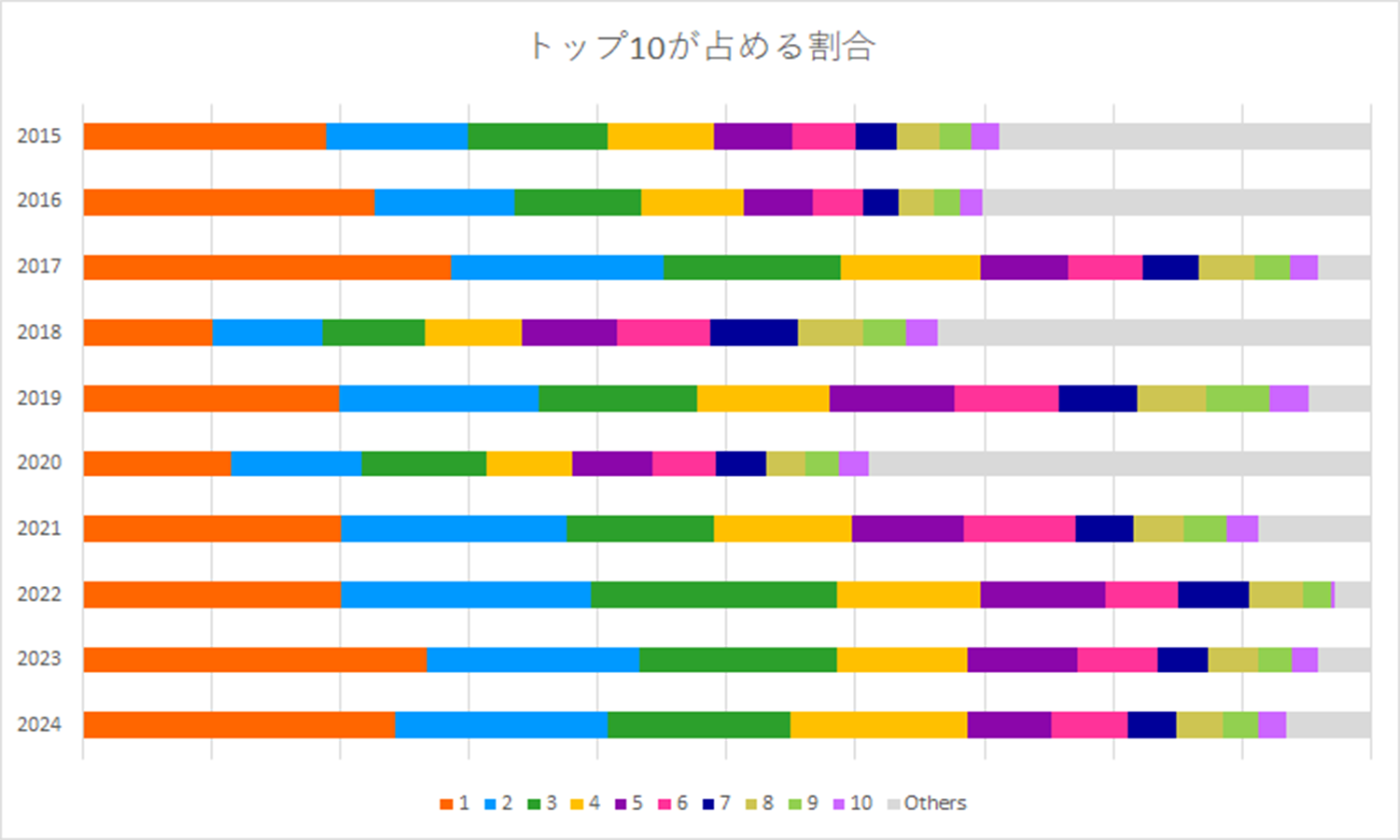
出力する帯グラフのイメージです。今回は112年分すべてのデータをグラフ化するため、全体的に縦長になるでしょう。当初は4-2.同様にトップ5のデータを出力予定でしたが、トップ10まで対象を拡大しました。トップ5で帯グラフを出力したところ、ほとんどのデータがトップ5圏外で、年代間の差分が小さかったからです。
4-3-1. データセットからデータ抽出
「全米の年間出生者数」を取得するため、4-1.のクエリではなく新たにクエリを作成します。登録条件が5≦numberに限定されているため、厳密には「総数」ではありませんが、それでも各年の男女ごとの総登録者数を取得できました。
SELECT
year,
gender,
annualNumber
FROM (
SELECT
year,
gender,
SUM(number) AS annualNumber -- 全米の登録者数
FROM
`bigquery-public-data.usa_names.usa_1910_current`
GROUP BY
year, gender
) AS AnnualData
ORDER BY
year DESC,
gender ASC;
抽出したデータをCSV出力したところ、以下のようなデータが取れました。抽出結果の量は「男女×1910~2021年(112年分)+ヘッダー=225行」です。
year,gender,sumNumber
2021,F,1320095
2021,M,1492780
2020,F,1303090
--- 中略 ---
1911,M,193441
1910,F,352089
1910,M,164223
4-3-2. SQLクエリ定義
ここは4-2-2.と同じ流れで、Colab上にSQLクエリを定義します。次のコードは4-2-2.直下に記載しており、コードセルの上部でPJ_IDを定義済みです。4-3-1.のSQLクエリから変更・追加がある行の末尾には★をつけました。
# BigQuery Studioで実行した、全米の年間出生者数を抽出するクエリ
# gender_code:'F'または'M'
def get_query_annual_by_gender(gender_code):★
sql_query_annual = f"""★
SELECT
year,
gender,
annualNumber
FROM (
SELECT
year,
gender,
SUM(number) AS annualNumber -- 全米の登録者数
FROM
`bigquery-public-data.usa_names.usa_1910_current`
GROUP BY
year, gender
) AS AnnualData
WHERE★
gender = '{gender_code}'★
ORDER BY
year DESC,
gender ASC
"""★
df_annual_sum = read_gbq(sql_query_annual, project_id=PJ_ID)★
return df_annual_sum★
変更箇所も4-2-2. とほぼ一緒ですが、変更内容を記載しておきます。
- def get_query_annual_by_gender(gender_code)::関数定義
- sql_query_annual = f""":引数を使用すべく、f文字列対応でf追加
- WHERE gender = '{gender_code}':性別指定をWHERE句で追加
- df_annual_sum = read_gbq(sql_query_annual, project_id=PJ_ID):Pandasの機能でGCPプロジェクトのBigQueryからクエリ結果を直接読み込み、DataFrameとして扱う
- return df_annual_sum:指定した性別の全米の年間出生者数のデータを返す
4-3-3. BigQueryからPandasへ読み込み
ここも4-2-3.と同じです。Colab上では4-2-3.直下に記載しているため、pandasやread_gbqは同一コードセルの上部でインポート済です。
# BigQueryからデータを読み込む
df_annual_sum_female = get_query_annual_by_gender('F')
df_annual_sum_male = get_query_annual_by_gender('M')
print("Successfully inputted!")
print("USA Name Data Annual Sum (Girls)")
print(df_annual_sum_female.head())
print("USA Name Data Annual Sum (Boys)")
print(df_annual_sum_male.head())
4-3-1. のCSVでは性別分けをしなかったため、「女男女男…」と交互に出力されていました。今回は引数で性別を指定したため、男女別に集計できています。
Successfully inputted!
USA Name Data Annual Sum (Girls)
year gender annualNumber
0 2021 F 1320095
1 2020 F 1303090
2 2019 F 1360299
3 2018 F 1382391
4 2017 F 1405262
USA Name Data Annual Sum (Boys)
year gender annualNumber
0 2021 M 1492780
1 2020 M 1478890
2 2019 M 1545678
3 2018 M 1570957
4 2017 M 1606186
4-3-4. データの集計と帯グラフ化
# df_top_n_data:get_top_n_by_genderで取得したデータフレーム
# df_annual_sum:全名前の年間合計データフレーム
# gender_code:性別
# title:帯グラフのタイトル
# top_n:取得対象(トップn)
def plotbarh_top_n_accurate(df_top_n_data, df_annual_sum, gender_code, title, top_n):
# 1. 年間合計(分母)の準備
df_denom = df_annual_sum[df_annual_sum['gender'] == gender_code][['year', 'annualSum']]
# df_annual_sum(全名前の年間合計データ)から、性別=gender_codeの行を抽出
# yearとannualSumのみを選択した分母のデータフレームdf_denomを作成
# 2. トップ10データと年間合計を結合
df_merged = pd.merge(df_top_n_data, df_denom, on='year', how='right')
# year列をキーに、トップ10のデータ (引数df_top_n_data) と分母データ (df_denom) を結合
# how='right':右外部結合
# 欠損値(NaN)を0埋め(対象:sumNumber、annualSum)
df_merged['sumNumber'] = df_merged['sumNumber'].fillna(0)
df_merged['annualSum'] = df_merged['annualSum'].fillna(0)
# 3. トップ10の名前の割合を正確に計算(Share列を作成)
df_merged['Share'] = np.where(
df_merged['annualSum'] > 0,
df_merged['sumNumber'] / df_merged['annualSum'],
0
) # 条件分岐に従い、df_mergedの新しい列'Share'に値を代
# 0<df_merged['annualSum']:sumNumber/annualSumを代入
# else:0を代入
# 4. グラフ描画のための整形
# ピボットテーブルを作成
df_plot_names = df_merged.pivot_table(
index='year', # 帯グラフの行見出し
columns='rank', # 帯グラフの列見出し
values='Share', # 集計対象のデータ
fill_value=0 # 該当年にデータがないランクは0埋め(NaNの補完)
)
# 列名を"Rank 1", "Rank 2"の形式に変換
df_plot_names.columns = [f'Rank {col}' for col in df_plot_names.columns]
# df_plot_namesの列名('rank'の値そのまま)を、f'Rank {col}'(例: 'Rank 1')に変換
# 5. Others割合の計算
df_plot_names['Top10_Share_Total'] = df_plot_names.sum(axis=1)
# df_plot_nameに格納されたトップ10の各名前の割合を合計し、結果をTop10_Share_Total列に代入
# axis=1:行ごとに計算(axis=0:列ごと)
# 全体(1)から Top10合計割合を引いて Others 割合を計算
df_plot_names['Others_Share'] = 1 - df_plot_names['Top10_Share_Total']
# Others_Share=1-Top10_Share_Total
# 計算誤差などで負の値になった場合は0に修正
df_plot_names['Others_Share'] = np.where(
df_plot_names['Others_Share'] < 0,
0,
df_plot_names['Others_Share']
) # 条件分岐に従い、df_plot_names'Others_Share'に値を代
# df_plot_names['Others_Share']<0:0を代入
# else:Others_Shareを代入
# 6. グラフ描画用データフレームの整形と列順序の調整
rank_labels = [f'Rank {i+1}' for i in range(top_n)]
# rank_labels = ['Rank 1', 'Rank 2'… 'Rank 10']を作成
plot_order = rank_labels + ['Others_Share']
# plot_order=順位ラベル['Rank 1', 'Rank 2'… 'Rank 10', Others]
# 定義した順序で列を抽出
df_final = df_plot_names[plot_order]
# df_plot_namesは列の順番がばらばらのため、plot_orderと同じ順番で出力するよう並び替え
# 7. グラフ描画処理
plt.figure(figsize=(12, len(df_final) * 0.25))
# figure関数で新しい図(グラフ全体)を作成
# 横幅:12、縦幅:データ行数(len(df_plot))×0.2(単位:インチ)
ax = plt.gca()
# 現在のグラフの描画領域
# 色の定義
base_colors = [
'#ff6600', '#0099ff', '#2ca02c', '#ffc000', '#8b06aa',
'#ff3399', '#000099', '#cec552', '#92d050', '#cc66ff'
] # グラフで使用する色のリストを定義
# 色をtop_nに基づいて固定
colors = base_colors + ['#d9d9d9'] # base_colors:トップ10の色、'#d9d9d9':Othersのグレー
# 横向き帯グラフの描画
df_final.plot(
kind='barh', # グラフの種類:帯グラフ
stacked=True, # 複数のデータ系列を積み重ね、積み上げ棒グラフとして描画
ax=ax, # 描画先のオブジェクト
title=title, # グラフのタイトル:title(引数)
color=colors, # グラフの色:リストcolors
legend=False # 凡例を非表示
)
# 8. 軸とレイアウトの調整
ax.set_xlim(0, 1.0) # X軸(占有率)の表示範囲:最小値0、最大値1.0に設定
ax.set_xlabel('Share (%)') # X軸のラベル:'Share (%)'
ax.set_ylabel('Year') # Y軸のラベル:'Year'
x_ticks_values = np.arange(0, 1.1, 0.1)
# X軸の目盛:最小値0、最大値1.1、0.1刻み
ax.set_xticks(x_ticks_values)
# x_ticks_valuesをX軸の目盛の位置に設定
ax.set_xticklabels([f'{int(x*100)}%' for x in x_ticks_values])
# X軸の目盛(0~1.1)×100で整数化し、%表示に変換してX軸の目盛ラベルに設定
ax.set_yticks(np.arange(len(df_final.index)))
# df_finalのインデックス(年)の位置に、Y軸の目盛を設定
ax.set_yticklabels(df_final.index)
# df_finalのインデックス(年)を、Y軸の目盛ラベルに設定
ax.set_title(title, y=1.01) # タイトル (引数title) をY座標1.01に配置
plt.tight_layout(rect=[0, 0.05, 1, 1]) # レイアウトの最終調整(描画領域の指定)
plt.show() # グラフを表示
# 9. トップ10のデータ取得とグラフ描画
N_10 = 10 # グラフで扱う順位の数(トップ10)
df_usa_name_top10_female = get_top_n_by_gender('F', N_10)
# 「性別='F'、順位数=N_10(10)」を引数に関数get_top_n_by_genderを呼び出す
# その結果(女子のトップ10データ)をdf_usa_name_top10_femaleに代入
df_annual_sum_female_renamed = df_annual_sum_female.rename(columns={'annualNumber': 'annualSum'})
# 女子の年間合計データ(df_annual_sum_female)の列名'annualNumber'を'annualSum'に変更
# その結果をdf_annual_sum_female_renamedに代入
df_usa_name_top10_male = get_top_n_by_gender('M', N_10)
# 「性別='M'、順位数=N_10(10)」を引数に関数get_top_n_by_genderを呼び出す
# その結果(男子のトップ10データ)をdf_usa_name_top10_maleに代入
df_annual_sum_male_renamed = df_annual_sum_male.rename(columns={'annualNumber': 'annualSum'})
# 男子の年間合計データ(df_annual_sum_male)の列名'annualNumber'を'annualSum'に変更
# その結果をdf_annual_sum_male_renamedに代入
# 年間トップ10が占める割合(女の子)の帯グラフを表示
plotbarh_top_n_accurate(
df_usa_name_top10_female,
df_annual_sum_female_renamed,
'F',
f'Share of the top {N_10} baby names in the USA (Girls)',
N_10
)
# 年間トップ10が占める割合(男の子)の帯グラフを表示
plotbarh_top_n_accurate(
df_usa_name_top10_male,
df_annual_sum_male_renamed,
'M',
f'Share of the top {N_10} baby names in the USA (Boys)',
N_10
)
処理結果として表示された折れ線グラフが次の通りです。まずは女の子。
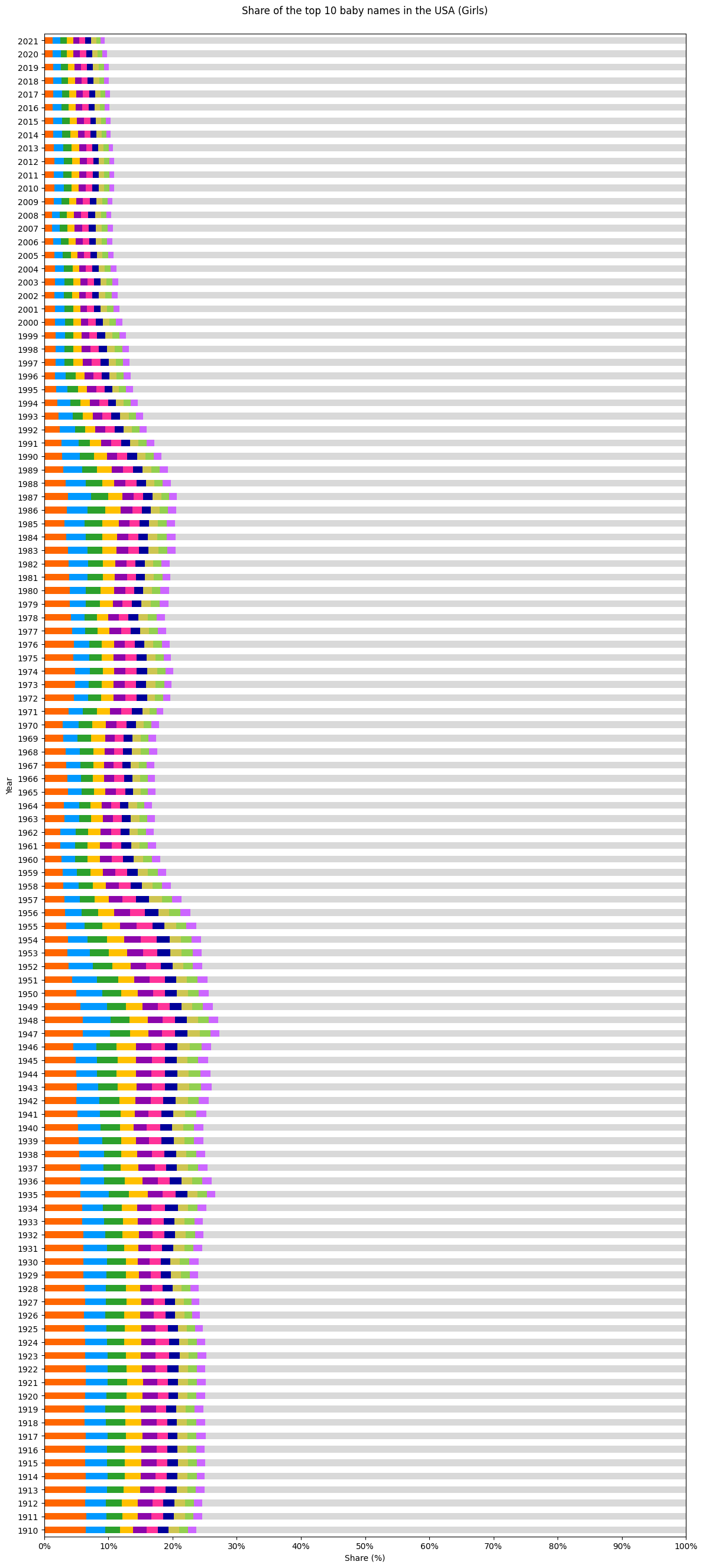
次に男の子。
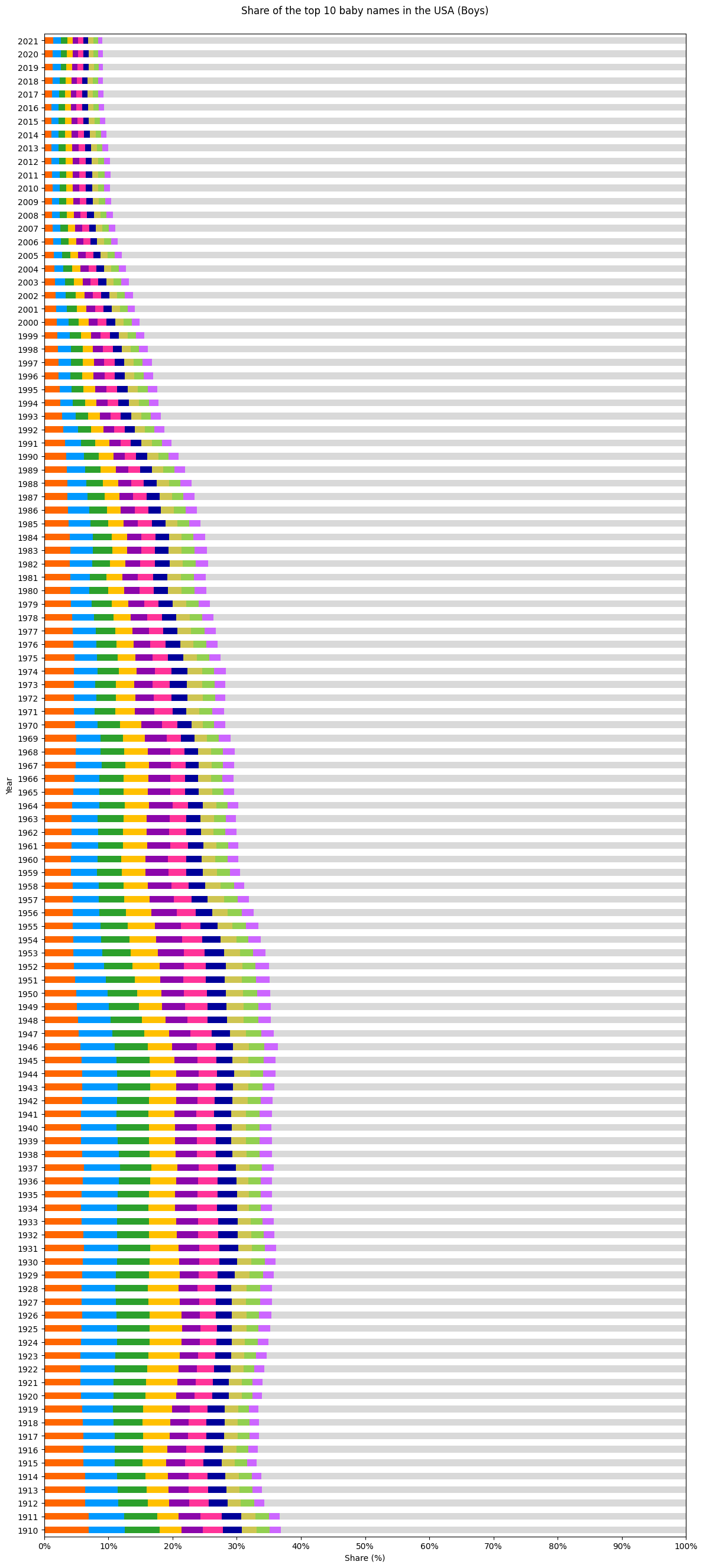
前回記事の折れ線グラフ同様、次回の記事でグラフを分析します。今回は結果の共有だけです。
いよいよ次回は分析!
先にお伝えしますが、分析記事にコードは登場しません。技術的な知見を求める方には物足りない内容かもしれません。分析にもお付き合いいただける方は、次回の記事をお楽しみに!