はじめに
Kafkaは受信したメッセージを安全に保管し障害があったとしても安全にメッセージを保存するための機構を持ち合わせています。今回はこの安全に保存する方法を簡単に紹介します。
※ 実機での動作確認方法はほとんど記載していませんのでご了承ください
まれに、Kafkaは障害のタイミングによりデータロスが発生するというウェブ記事を見ますが、そんなことはなく正しい知識で実装すればデータロスは発生しないつくりをしています。細かい議論を今回するつもりはありませんが、Kafkaのバージョンが古い動作で考えたり検証している、机上計算に誤りがる、多重障害や不具合による複雑なケースを考えているからだと思います。
前提知識
本文章は、以下の関連記事を読んで理解していることを前提に記載しています。
Confluent Platfromの魅力について書いてみた
Apache Kafkaのメッセージ送受信について(REST-PROXY利用)
Kafkaを利用した分散処理について (パーティション機能の座学)
Kafkaクラスタでブローカーの冗長化
Kafkaブローカーは3台以上の物理サーバ上で内部に保存するデータをコピー(レプリカ)して冗長化を行います。
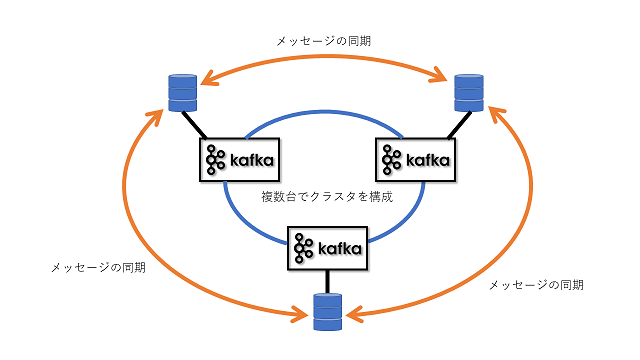
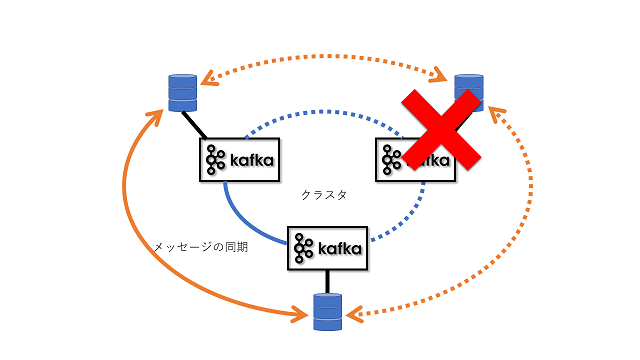
万が一障害が発生した場合でも、残りのサーバで縮退して動作を継続します。
冗長の制御は、パーティション単位で行います。同じトピックであってもパーティションが異なれば、保存されているサーバが異なる場合があり冗長性を高めているだけではなく負荷分散の役割も担っています。
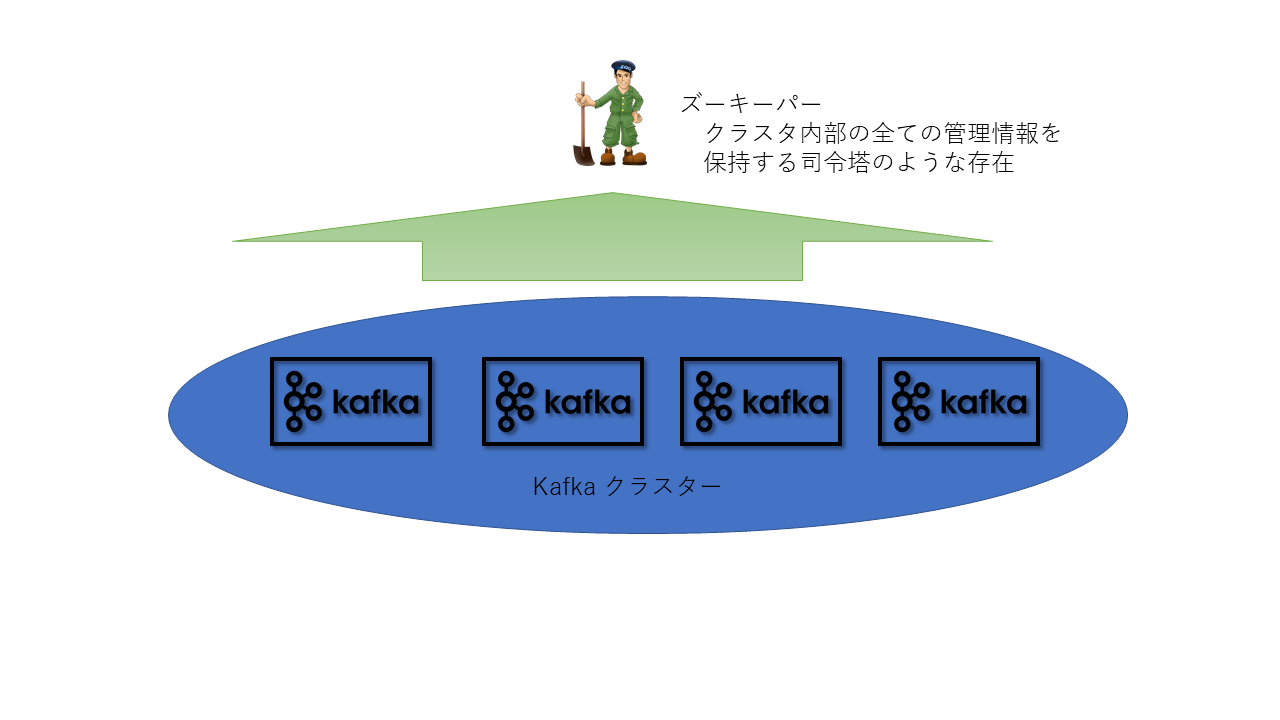
ブローカーの状態を管理するZookeeper
ブローカ間の制御はApache Zookeeper(ズーキーパー)と呼ばれるの状態を制御するソフトウェアを返して行われておりズーキーパーはクラスタ内部の全ての管理情報を保持しています。
Zookeeperは1台,3台,5台のいずれかしか構成が組めなくなっており通常は3台または5台で冗長化を行うのでKafkaのクラスタも3台冗長を利用されることが多いです。
※ 3台構成は2台冗長より可用性が低いので注意 詳しくはこちらで解説しています
※ zookeeper自体の動作などは本筋と少しずれるので解説は省かせていただきますが、小容量しかデータを保持できないが非常に可用性を高めた設定情報管理ソフトウェアでHadoopなどで使われています。
ブローカーの識別について
ブローカーの識別はブローカーIDによって決定されます。クラスタ内部のブローカーIDは重複が無いユニークな値にする必要があり、万が一の障害でサーバを交換した場合に保存されたメッセージを引き継ぐのであれば故障したサーバと同一のIDに設定することで引継ぎが行われます。1
冗長化はトピック毎に設定する
Kafkaの冗長化はトピックを作るときに冗長化のルールが決定します。主に以下の2つの値で動作が決まります。
- replication.factor (レプリカ数)
レプリカをとる個数を指定します。指定した数のブローカーへ同一のパーティションが作られます。
※ 未指定の場合は ブローカーのdefault.replication.factorの値が作成時に適用されます - min.insync.replicas (最小レプリカ数)
最低限同期できているレプリカの数を指定します。指定した数以上同期できていないパーティションに対しては新たなメッセージを送れなくなります。
※ 未指定の場合は ブローカーのmin.insync.replicas のカレントの値が適用されます
レプリカの数と最小レプリカ数の推奨値は?
用途によって使い分けることが重要です。
よく使われる4つを紹介します。
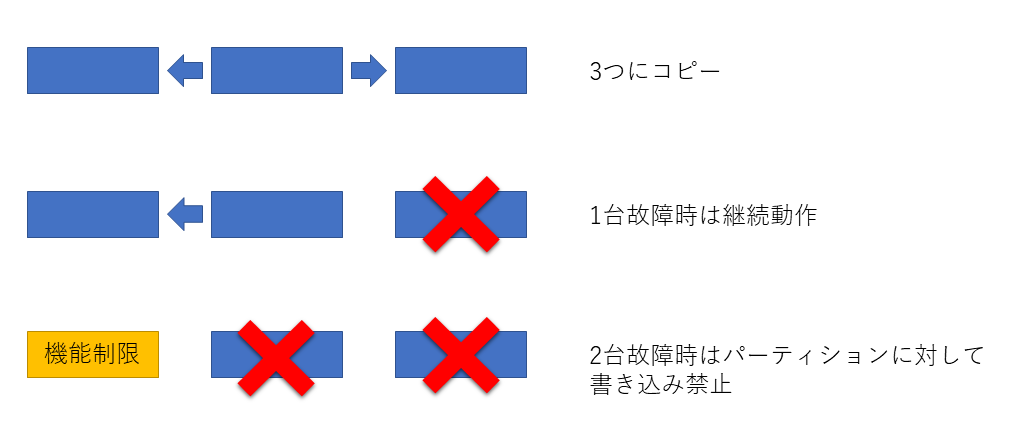
(1) 3冗長 1耐性
replication.factor = 3
min.insync.replicas = 2
パーテョションのログを3台に分散して保存します。1台の故障に対しては問題なく動作を続けますが2台故障した場合は動作を一部停止2してデータの保護を優先します。
非常に高いデータ保護ができるため、選択に迷ったらこれを使うのがいいでしょう
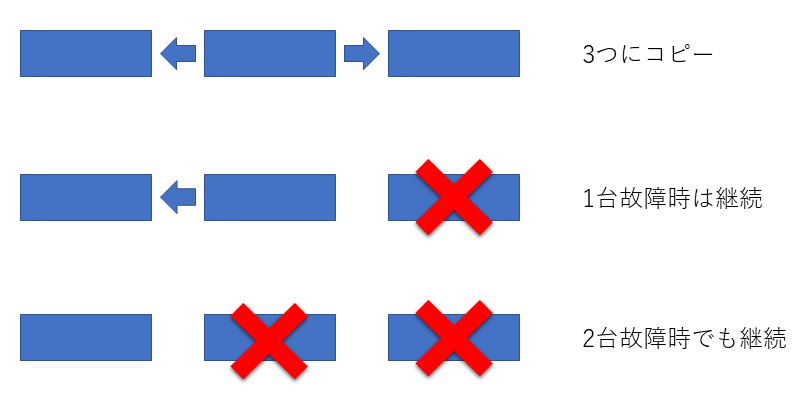
(2) 3冗長 2耐性
replication.factor = 3
min.insync.replicas = 1
パーテョションのログを3台に分散して保存します。2台の故障まで問題なく動作を続けます。当然3台目が故障するとデータは破損する可能性が高いです。
運用継続を優先する場合に利用します。1台故障しても2台で冗長化できるので常に冗長稼働させる場合に利用します。停止しないのでデータ保護の観点では脆弱になります。
※ 後述にある通り一部のメッセージが消失するケースがあるので注意してください。
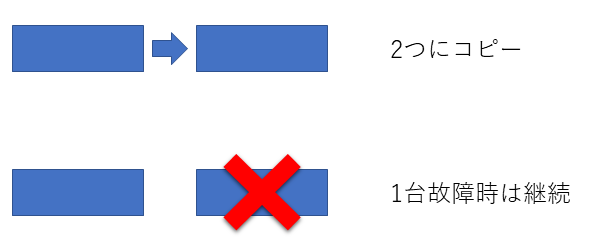
(3) 2冗長 1耐性
replication.factor = 2
min.insync.replicas = 1
一般的によく使われる2台冗長を行った構成です。1台が故障してももう一台で運用を継続できます。冗長はしたいがクラスタの台数を節約したいときの選択肢になります。
※ 後述にある通り一部のメッセージが消失するケースがあるので注意してください。
(4) 冗長無し
replication.factor = 1
min.insync.replicas = 1
冗長化しない場合です。主に開発環境での利用に適した方法です。(ステージングを除く)
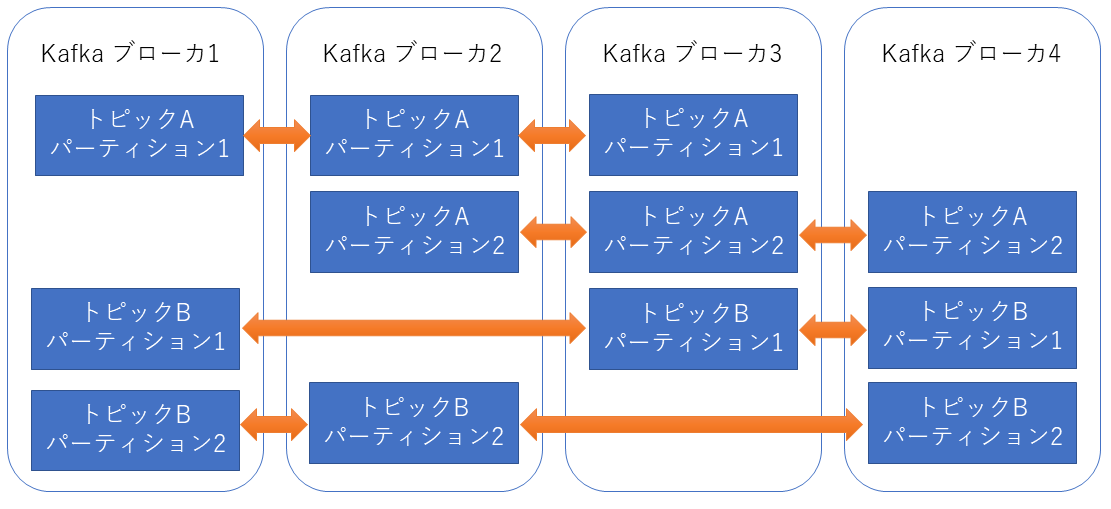
ログのレプリカはパーティション単位
ログは、パーティション毎にレプリカを取ります。
例えば、4台のブローカーに対してレプリケーション数を3にしてパーティションを2にした場合4台のブローカーに対してログを分散して格納します。
レプリカを制御する役割のリーダ
レプリカはパーティション毎に管理しておりZookeeperで情報を管理していると言いましたが、Zookeeper自体は管理情報を保存するだけにとどまっておりレプリケーション動作の制御は行いません。制御を行うのはリーダーと呼ばれるブローカーが行います。
リーダーはパーティション毎に決定しクラスタ内部のブローカーで分散するように決定します。3
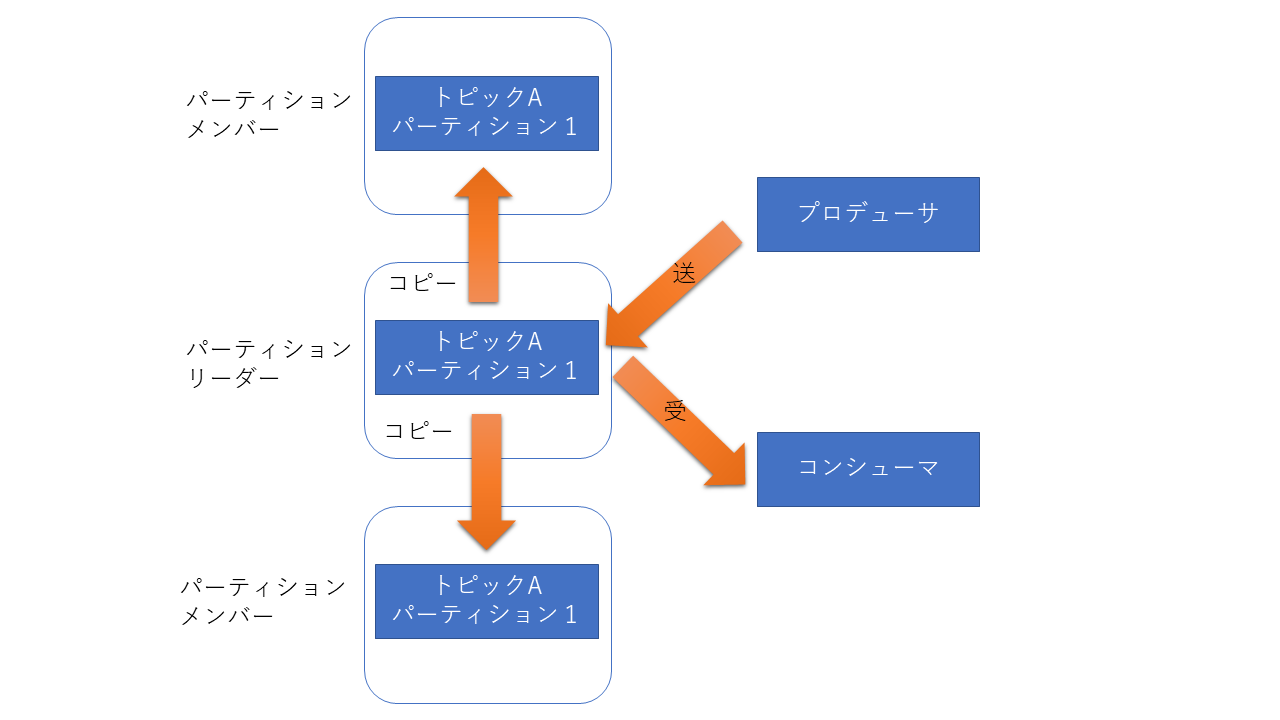
リーダは、プロデューサやコンシューマとのメッセージをやり取り担当し、パーティションのログ情報をメンバー(リーダー以外のブローカの事)に対してログの複製を行います。
万が一リーダが故障した場合はメンバーの中から新たにリーダが選ばれ処理を引き継ぎ処理を継続するようになっています。
メッセージ送信(プロデューサ)
メッセージをブローカーに渡す時にAPI内部でパーティションまで決定することは前に解説した通りです。
- パーティションが決定するとリーダーブローカーに対してメッセージを渡します。
- リーダブローカーはメッセージを渡した後にメンバーブローカーに対してレプリケーションを行います。
メッセージの保存確認
プロデューサからブローカーへメッセージを渡している時やブローカー間でレプリカを取得している時に障害が発生するとメッセージが消失することが考えられます。
Kafkaでは、プロデューサが送信したメッセージがきちんとレプリカされたことを確認することでメッセージを確実に届けることを担保しています。
担保するためには、プロデューサのacksプロパティをallにする必要があるので注意してください。
| acksの値 | 意味 | 説明 |
|---|---|---|
| 0 | メッセージの到達確認を行わない | ブローカへの通信が出来ないなどの明らかなエラー応答がない限り送信したメッセージをエラーになりません。エラー確認を行っていないので応答が早く負荷も小さいです。メッセージの到達性を保証する必要が無いときに利用します。 |
| 1 | リーダブローカーまでの到達性を確認 | リーダにメッセージを渡し終わった時点でリーダーがAckを返すことで到達性を確認します。ただしリーダーとメンバー間のレプリケーションの保証がされないのでメッセージ送信完了直後にリーダーで障害が発生するとメッセージが消失することがあります。多少のメッセージ損失を許す場合に利用します。 |
| all | レプリカが行われたことを確認 | min.insync.replicasの数のレプリカが終わった時点でackを返すことで到達性を確認します。注意しないといけないのは、min.insync.replicasが1だとacks=1とほぼ同じ動作になってしまいメッセージ損失が発生します |
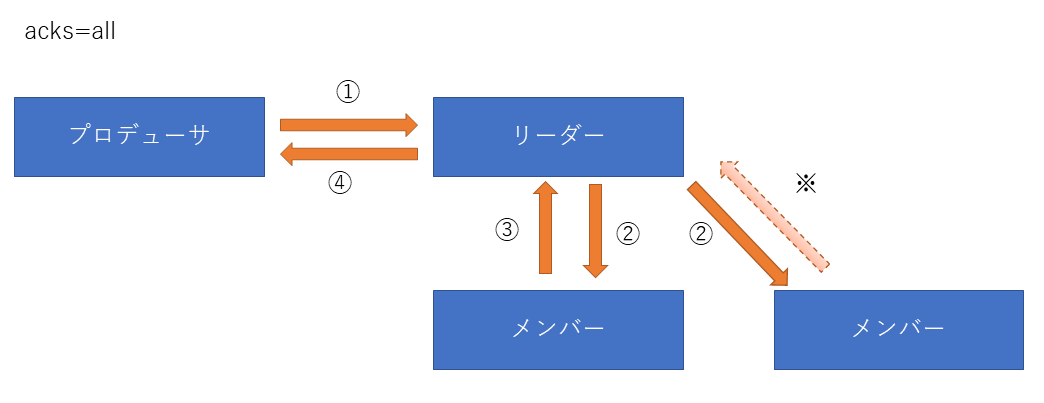
acks=allの動作
① プロデューサーからリーダーブローカーへメッセージを送信します。
② リーダーブローカーはメンバーへメッセージのレプリカを送ります。
③ メンバーがレプリカを受け取ったAckをリーダーへ返します。
④ リーダーは自分で保持しているメッセージを含めたmin.insync.replicasの数のレプリカがあることを確認したらプロデューサーへAcksを送ります。
※ min.insync.replicasの数を超えた場合でもメンバーからリーダへのAck動作は行われますが④のAckを送った後に受信する場合もあるのですべてのメンバーへのレプリカが成功したことは言い切れません。
万が一障害が発生した場合でもAck を受け取ったメッセージは保証されます。
Ack を受け取れていない場合は、保証されていないためリトライを行うかエラー処理を行う必要があります。
※ リーダーからAckが正しく戻らない場合にプロデューサの内部でリトライが行われますが、このリトライを信用せずにプログラム内部で書き込みが失敗した動作を作りこむことが必要になります。
※ Ackのみ消失した場合、プロデューサからリトライを行われメッセージ内部で自動的に管理されているシーケンス番号が同じためプロデューサから登録済みとメッセージを受け取ることで重複を防いでいます。
acks=1の動作
① プロデューサーからリーダーブローカーへメッセージを送信します。
② リーダーブローカーはプロデューサへAckを返します
③ リーダーブローカーはメンバーブローカーへレプリカを送ります
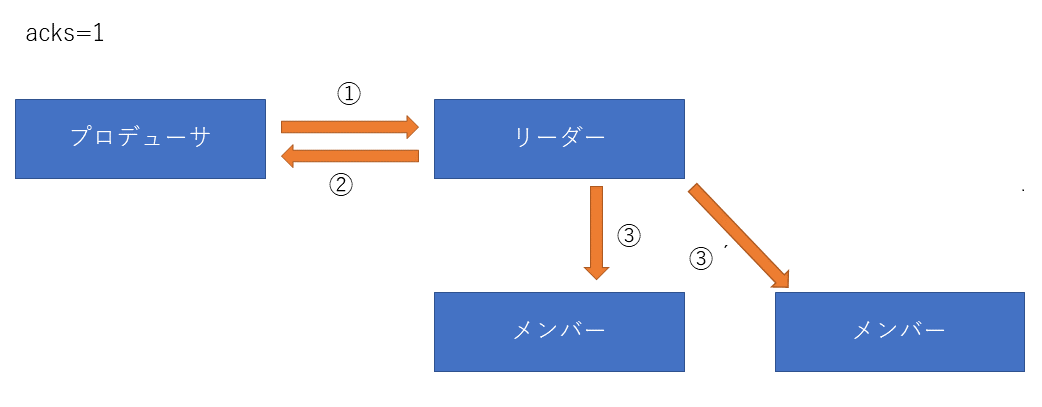
リーダーまでの到達性を保証しますが、②の後でリーダ障害が発生した場合当該のメッセージは消失してしまいます。
※ 正常時のみ到達性を保証する場合に利用します。Acks=allに比べてレスポンスが早いので高速性も必要な場合によく利用されますが障害対応する場合が少し複雑になる欠点があります。
acks=0の場合
① プロデューサーからリーダーブローカーへメッセージを送信します。
② リーダーブローカーはメンバーブローカーへレプリカを送ります
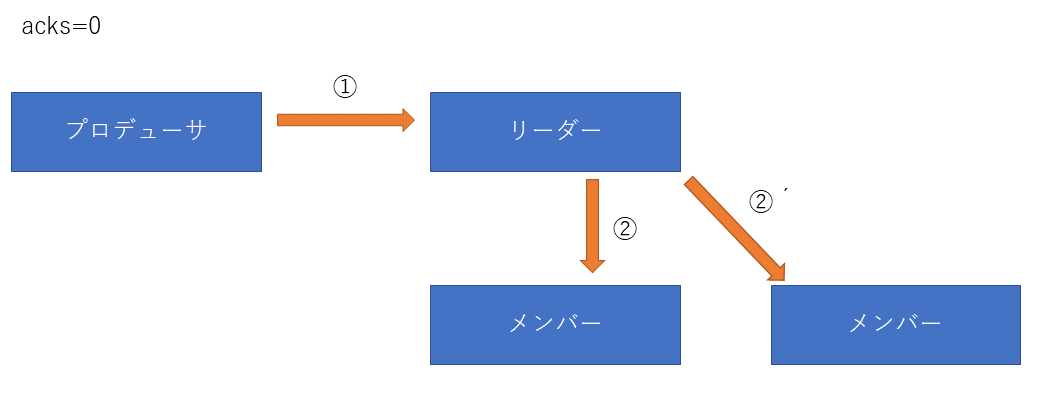
メッセージの到達確認を行わないためメッセージの欠落が発生する可能性が最も高い方法です。
ですが最も高速に大量なメッセージを受け取ることができます。
※ 例えばIoTの温度センサーを利用るう場合温度変化は頻繁には怒らず前後のメッセージでメッセージを補完できます。このように数メッセージの欠損があっても問題が発生しない場合に利用する方法です。
コンシューマ側の動作
コンシューマでパーティションに対してメッセージを取りに行く場合、ブローカーのリーダーへメッセージを取得します。
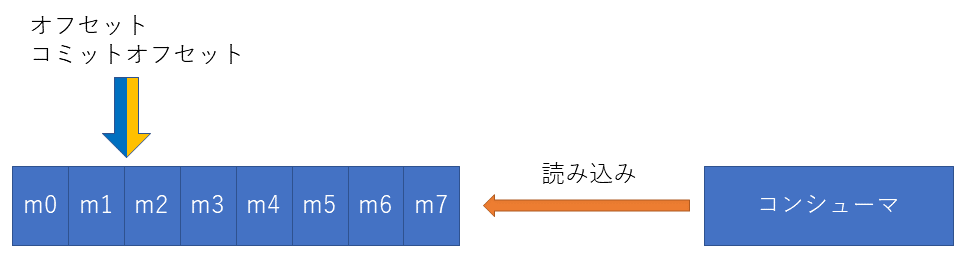
ブローカーのオフセットを送ったメッセージの個数分進めます4
万が一ブローカーが障害が発生した場合は、メンバーがリーダに昇格後メッセージを読み取ります。オフセットとコミットオフセット情報はズーキーパーが保持しているので影響を受けません。
コンシューマ側が障害となった場合は、コミットオフセットの次のメッセージから再度コンシューマへ送信を行い処理を継続します。
(補足)
コミットオフセットの更新は、poll命令などコンシューマーからKafkaに対して次の命令を出した時点で自動的に行われます(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIGがTrue時)。この方法だと複数のメッセージを同時に受信した場合にメッセージの途中で異常終了した場合に再度コミットオフセットまで戻って処理を行うので処理結果が重複する可能性があります。このような場合は処理レコードごとに手動(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIGがfalse時)にすることで1メッセージ処理するごとにコミットオフセットを1つづつ進めることもできます。
まとめ
Kafkaを使うと万が一の障害でもデータロスがなくメッセージ交換や処理の継続を行える機能が備わっていました。
ただし、事前設定が必要であり高可用性を目的とするのであれば以下の設定がお勧めです。も高可用性を行うとレイテンシが高くなるので、設定の1択ではなく扱うデータの内容や特性に合わせてトピック毎に設定を調整することも必要です。
高可用性のお勧め
高可用性求めるのであれば以下の設定をお勧めします
トピック
replication.factor = 3
min.insync.replicas = 2
プロデューサ
acks = all
retries >= 2
(補足1)コマンドでの確認方法
各トピックのパーティション数、レプリカ数、個別設定情報とパーティション毎のリーダブローカー、レプリカ対象のブローカー、レプリケーションの完了状況を表示するには、kafka-tppicsコマンドを利用します。
# docker-compose exec broker kafka-topics --bootstrap-server localhost:9092 --describe --topic test2
Topic:test2 PartitionCount:3 ReplicationFactor:3 Configs:min.insync.replicas=2
Topic: test2 Partition: 0 Leader: 2 Replicas: 2,4,1 Isr: 2,1
Topic: test2 Partition: 1 Leader: 3 Replicas: 3,1,2 Isr: 3,1,2
Topic: test2 Partition: 2 Leader: 1 Replicas: 1,2,3 Isr: 1,2,3
※ Docker-Composeを利用している場合のコマンド例です。
コマンドオプション
- --bootstrap-server <FQDN名>:<TCPポート番号>
ブローカーのFQDN及び接続ポート番号指定 (必須パラメータ) - --describe
トピックの詳細を表示するオプション - --topic <topic名>
トピック名を指定するオプション
結果
- Topic:
トピック名 - PartitionCount:
パーティションの数 - ReplicationFactor:
レプリカ数 - Configs
トピック固有設定情報 5
- Partition:
パーティションID - Leader:
リーダーとして稼働中のKafkaブローカーID - Replicas:
レプリカを取得する対象のKafkaブローカーのIDリスト - Isr:
in-sync replicaの略で、レプリケーションが完了してリーダと同じログを保持しているブローカIDリスト
(補足2) Linkedin では
よくLinked inでどのように使われているか気にしている人がいるので知っている限りの情報を書きます。
クラスターの数: 約100 クラスター
1クラスタ当たり(最大):60台のブローカー 50kトピック
ピーク時 秒間800kメッセージの受信 300MB (1メッセージ当たり300~400バイト程度) メッセージ送信1GB
replication.factor = 2 を標準としてKafka上でのメッセージロスは許容するアプリケーション設計
ハードウェア:Dual CPU(4コアのXeon)/24GBメモリ
Apache Kafkaから派生バージョンを利用
とのことです。規模感がすごいですねそれだけ多くのデータ分析を毎日繰り返していることがわかります。
個人的には規模感や使い方、アプリケーション設計が違いすぎるので参考にせず利用用途に合わせた選択するほうがいいと思いますので、大御所にとらわれずプロジェクトごとに考えて設計をお願いします。
-
ブローカーIDはコンフィグレーションで固定値に割り当てる方法と1001から順に自動で割り当てる2種類の設定があります。今回は細かくは解説しませんがブローカー障害時のリカバリー手順がことなるなど一長一短です。 ↩
-
メッセージの書き込みを抑止するため実質停止と同じです。 ↩
-
スタティックでパーティション毎にリーダーを決定することも可能 ↩
-
オフセット情報を保存しているのはズーキーパーです
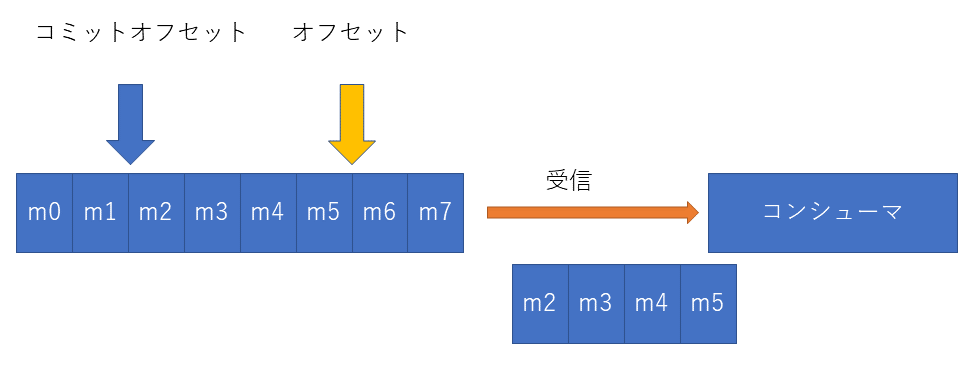
メッセージを処理を行った後にCommmitをブローカーに返すことでコミットオフセットを進めメッセージを処理済みに変更します。
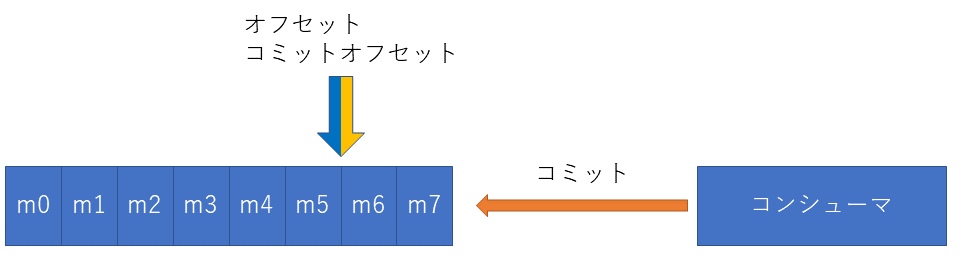 ↩
↩ -
例ではmin.insync.replicasと表示していますが、トピックに個別設定を行っていない場合は表示されません。 ↩