本コンテンツはConfluentの初心者向けに噛み砕いて記載しています。
また、以下のコンテンツの内容を理解していることを前提としてKafka用語を使って記載していますのでご了承ください。
Confluent Platfromの魅力について書いてみた
Apache Kafkaのメッセージ送受信について(REST-PROXY利用)
概要:Apache Kafkaの分散処理で利用するパーティション
非常に多いメッセージ(レコード)を1つプログラムだけで順次処理をするのでは処理しきれないことがあります。このような時に、メッセージを分散して同じプログラムをマルチプロセスや複数のサーバ上で分散処理させることで単位時間内に処理を終わらせるようにするパーティションと呼ばれる機能が標準で組み込まれています。今回はパーティションについて説明させていただきます。
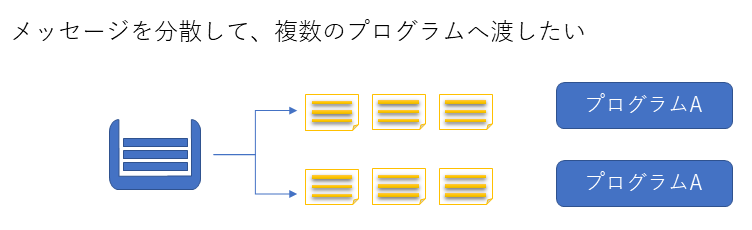
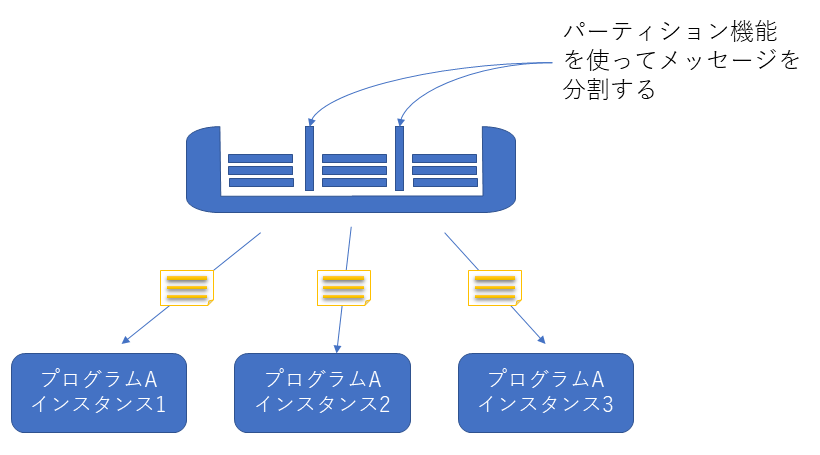
パーティション機能について
Kafkaでは、分散処理を行う場合トピックをパーティション機能を使ってトピック内のメッセージを分割します。文字の通りキューの中身をパーティション(区切り)を使って分割するイメージですが、パーティション数は区切りの数ではなく区切られた入れ物の数を指しますのでご注意ください。分割されたパーティション内部のメッセージ毎に分散起動プログラム(コンシューマ)に渡すことで分散処理を実現しています。
コンシューマを同じものか異なるものかを認識するために識別子としてインスタンス名(クライアントID)を利用します。パーティションを識別するには0から順番にナンバリングされたパーティション番号を利用します。1
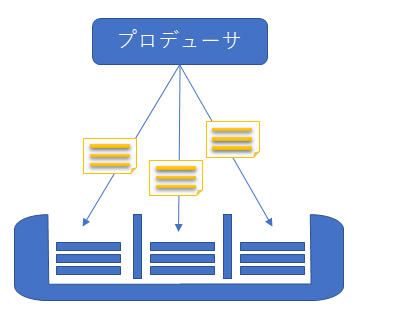
メッセージを分散して格納するのはプロデューサ
メッセージ分散はプロデューサが行いそれぞれのパーティションへメッセージを送ります。
パーティションにメッセージを入れるルールは次の1~3の3通りです(複数該当する場合は若番が優先されます)
- プログラム内でパーティション番号を明記
プロデューサーからメッセージを送信するときにパーティション番号を固定入力することで任意のパーティションへメッセージを登録します。2
- キーの値により自動分散(ハッシュ)
メッセージにはキーと値の2つのフィールドが用意されていて、其々自由にデータを入れることができるようになっています。キーに入っている値を元にハッシュ値を取りパーティション番号が決定されます。要するに、同じパーティションにメッセージを入れたい場合は同じキーを利用することで半分制御することができます。3 4 5
- ラウンドロビン
パーティション番号指定が無くキーも指定していない場合、全てのトピックに対して分散して均等にメッセージを送信します。6
コンシューマのパーティションの割り当て
前に「Apache Kafkaのメッセージ送受信について(REST-PROXY利用):コンシューマグループの役割(コンシューマーの再開)」にてコンシューマグループについて簡単に説明しましたが、このコンシューマグループ内部にインスタンスを作りインスタンスとパーティションを紐づけることにより分散処理を実現します。
紐づけの方法にはパーティションを自動選択するのオートと固定選択のスタティックの2種類があります。特別な理由が無い限り分散するプログラムがサーバ故障などで停止した場合でも残りのプログラムがメッセージを引き継げるオートを利用することを推奨します。
※ コンシューマグループ内部でオートとスタティックの併用はすることはできません。併用しようとした場合はsubscribeするときにエラーになります。
パーティションのスタティック割り当て
コンシューマグループを指定した後に、メッセージを取り出すパーティション番号も指定することでパーティションを紐づけます。固定で割り当てがわかりやすい分、きちんと管理を行わないとパーティションを割り当て忘れがないようにコントロールしたり、コンシューマが動作しなくなった場合の他のプログラムが引き継ぐロジックなどをコンシューマ側のプログラムに作りこむ必要があります。
パーティションのオート割り当て
コンシューマグループ内部のインスタンス数に応じて均等になるようにパーティションを割り当てます。インスタンスの数が変わるたびに割り当てを動的に変更を行い常に分散する形をとります。
インスタンス数 == パーティション数の場合
インスタンス数とパーティションの数が同一の場合は、1対1対応して分散します。非常にわかりやすい分散方法だと言えます。
また、インスタンス数の整数倍のパーティションがある場合も均等に割り当てが分散するためわかりやすいです。
パーティション数 < インスタンス数の場合
インスタンス毎にパーティション数がおおよそ均等になるように分散されます。
均等にできないパーテョションの余りは、一部のインスタンスへ1つづつ割り当てられます。
<<動作概要>>
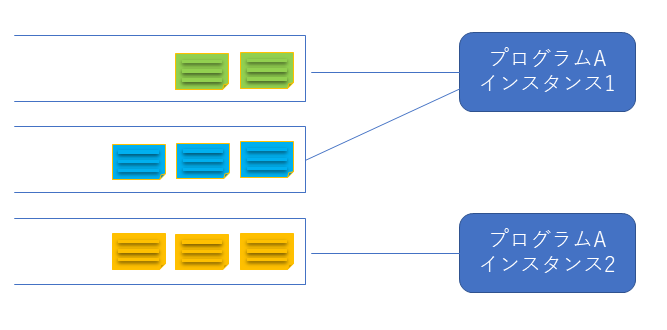
複数のパーティションを割り当てられたインスタンスは、1つ目のパーティションに残っているデータ順に読み込みます。
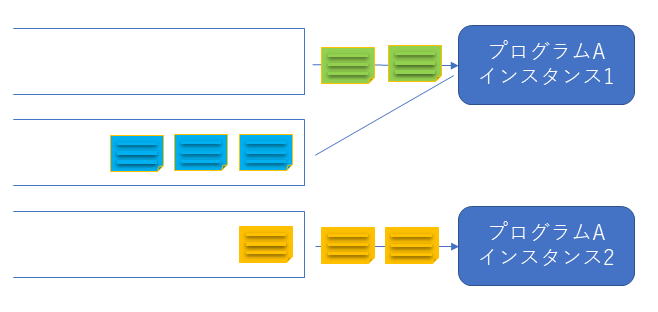
全てのメッセージを読み込みパーティションに残っているメッセージが0になると次のパーティションからメッセージを読み込みます。
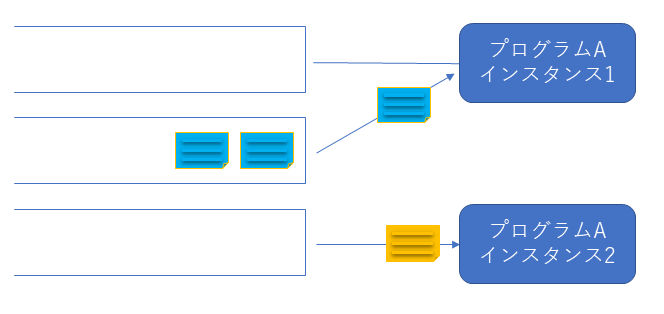
インスタンス数 > パーティションの場合
パーティションの数よりインスタンスの数が多い場合は、パーティションの数分のインスタンスに対して紐づけが行われます。
<<動作概要>>
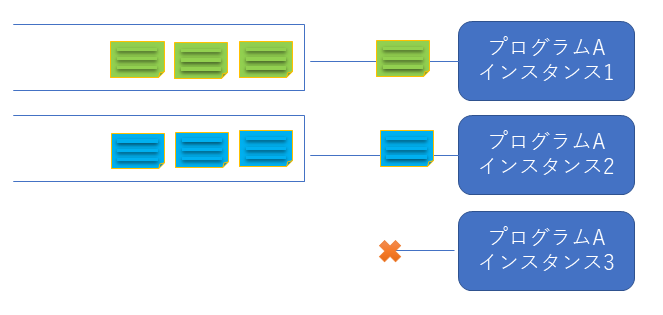
割り当て時に余ったインスタンスはパーティションが割り当てられずホットスタンバイになります。
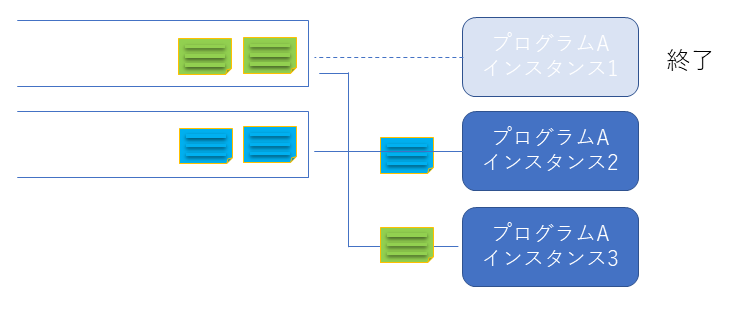
紐づけられたインスタンスが終了(異常終了を含む)すると終了したインスタンスのパーティションが新たなインスタンスに割り当てられ処理を継続します。
パーティションはいくつが望ましいか?
ここまで、パーティションの動作について解説しましたが、実際に利用する場合パーティション数はどのように設計すればいいかを解説します。
※ この考え方は部分的な評価のためすべてのパターンで適用できるわけではありません。基本的な指標としてとらえてください。
まずはインスタンスの障害時を考えましょう。サーバのハード障害、プログラムミスなどインスタンスが障害となり動作しなくなる場合があります。この時に、縮退しても均等分散を維持する場合、縮退して一部のインスタンスに引き継ぐ場合、ホットスタンバイにより引き継ぐ場合の3パターンが考えられます。
※ 通常時の基準が異なるだけで同様に将来拡張することを考慮して設計する方法もあります。
均等化を優先する場合
一番利用される分散方法です。通常時の数から縮退時の数までインスタンス数の最小公倍数を取る方法です。
-
5台のインスタンスがあり同時故障が1台の縮退時4台の場合
5,4の最小公倍数の20になります。
5台稼働中は、1インスタンス当たり4パーティション割り当てられます
4台に縮退した時は、1インスタンス当たり5パーティション割り当てられます。 -
5台のインスタンスがあり同時故障が2台の縮退時3台の場合
5,4,3の最小公倍数の60になります。
5台稼働中は、1インスタンス当たり12パーティション割り当てられます。
4台に縮退した時は、1インスタンス当たり15パーティション割り当てられます。
3台に縮小した時は、1インスタンス当たり20パーティション割り当てられます。
このように縮退時も常に均等に割り当てることができます。
縮退して一部のインタンスに引き継ぐ場合
インスタンス数とパーティション数を同数にする方法です。
障害はあまり起きないものと考え、インスタンスのリソースに十分な余裕がある場合に利用します。
・通常稼働中が5の場合
1台が故障で、残りの4台中1台が通常の2倍の処理を行い残りの3台が通常と同じ処理を行う
2台が故障で、残りの3台中2台が通常の2倍の処理を行い残りの1台が通常と同じ処理を行う
障害時は倍のリソースが必要になるので、障害時リソースに余裕があるサーバ上で動作させる必要があります。
運用上の理解が分かりやすく管理しやすいといった特徴があります。
ホットスタンバイにより引き継ぐ方法
最大障害想定台数分のインスタンスをパーテョションより多く稼働させるホットスタンバイ方式です。
障害発生時は、ホットスタンバイ上のインスタンスで引き継ぎます。
ホットスタンバイ機で動作させるためパフォーマンスが安定しますが、その分の空きリソースを確保しておく必要があります。
プログラムの要件により分散できない場合もある
プログラムによっては、メッセージの前後関係やすべての値の統計が必要になったりします。分散する関連するメッセージが異なるプロセスで読み込まれることがあるため分散が難しくなります。
各メッセージが(キー毎に)独立して処理できる場合にKafkaを利用した分散処理が一番効果を発揮します。
※ 分散の必要性などは設計時に決めることですのでここでは深く突っ込んで解説していません。要件に応じて利用する方法を検討するようにお願いします。
補足
プログラムの内容によっては分散処理が不可能であったり、不適切な場合があります。
全てのケースをカバーできるわけではなく、プログラム開発の設計時に分散可能性について判断していただくことが望ましいと考えます。
参考資料
どうしてもハッシュアルゴリズムを知りたい方のために
プロデューサのハッシュアルゴリズムを気にするような人は、パーティション番号を指定してご自身でコントロールすべきと考えます。
それでもハッシュアルゴリズムが気になるのであれば、ソースコードの該当部分のリンクを載せておきますのでご自身でソースコードを読んでください。return Utils.toPositive(Utils.murmur2(keyBytes)) % numPartitions;の部分が該当します。
https://github.com/apache/kafka/blob/trunk/clients/src/main/java/org/apache/kafka/clients/producer/internals/DefaultPartitioner.java
https://github.com/apache/kafka/blob/trunk/clients/src/main/java/org/apache/kafka/common/utils/Utils.java
プロデューサーの設定 ProducerConfig.PARTITIONER_CLASS_CONFIG で指定したデフォルトのアルゴリズム(DefaultPartitioner)です。
-
トピックを作るときにパーティション数を指定します。後から動的に変更することはできないのでご注意ください。 ↩
-
分散ルールを制御したい場合に利用します。(上級者向け) ↩
-
キーが異なっている場合、必ず異なるパーティションへメッセージが登録されるわけではなく同じパーティションになる場合もあります。 ↩
-
均等に分散するためには、キーの値種類が多くある必要があります。 ↩
-
ハッシュのアルゴリズムはカスタマイズ可能ですが、全てのプロデューサーに対して同じアルゴリズムにしないと正しく分散することはできませんのでご注意ください。 ↩
-
パーティション番号の順序はランダムに決定しますが各パーティションのメッセージの個数が均等化するようなアルゴリズムを採用しています。 ↩