Confluent PlatformはApache Kafkaを使ったイベントストリーミングプラットフォームです。
自分なりにConfluent Platformを砕けた形で解説してみました。
できるだけ、初心者にわかりやすく書いているつもりですが、解りにくいところや内容が誤解されるようになっていたらご指摘していただけると嬉しいです。
Apache Kafkaとは
分散メッセージキュー(MQ)って良く言われています。と言ってもわかりにくいと思います。
まずメッセージとは、データの1レコードの事です。Excelとかで表にした場合、1行に各内容の事です。
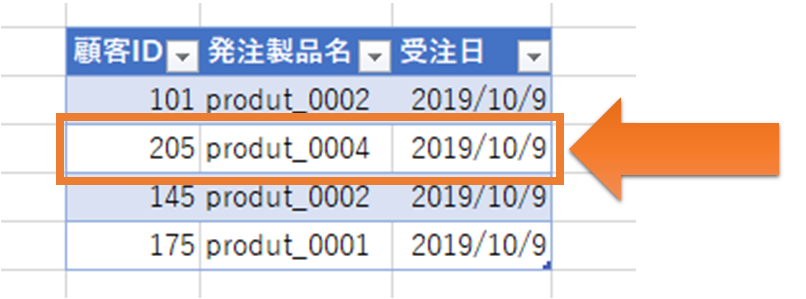
伝票1枚をイメージしてもらえばいいかと思います。
メッセージを一次的に蓄積する場所がキューです。伝票を一時保管するための伝票箱のイメージです。
現実世界でのイメージ
もう少し現実的な比喩として、メッセージ=伝票として受注から製造、発送するという簡単な製造業のプロセスに
置き換えて考えてみましょう。

キューの効果について
キューが存在しない例として受注が電話の場合、顧客が電話回線を通じて発注を行います。発注の内容が全て確認を行ってOKが出るまで
電話回線は使われたままになり、次の顧客は通話が終わるまで待たなければなりません。
そのため、無駄な待ち時間が発生してしまいます。
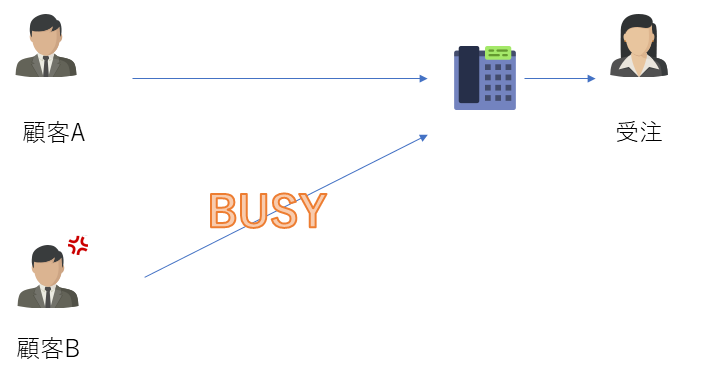
FAXというキューを使った場合、FAXで伝票(メッセージ)が送られ伝票箱(キュー)に一時的に保管されはしますが
顧客の待ち時間が激減して発注書を送ることができます。
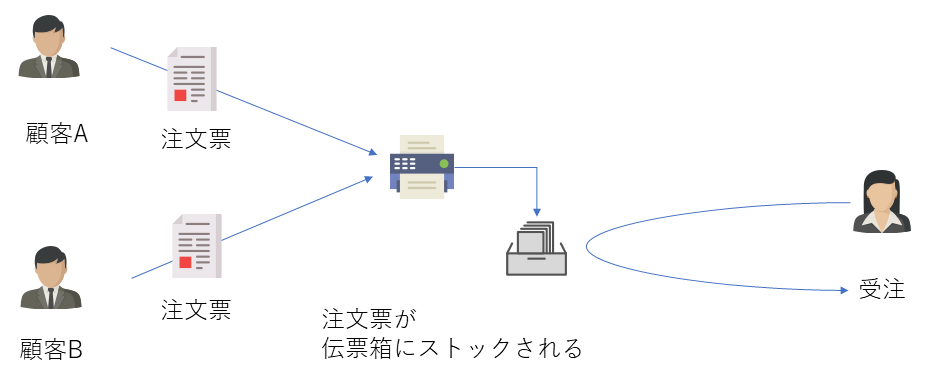
このように、伝票をいち早く受信して貯めてから処理をすることで、顧客の待ち時間を減らす伝票箱の役割がMQであり、
MQがある事により顧客側の待ち時間が改善されることで効率が非常に高くなることが分かります。
でも欠点もあります。例えば発注伝票に誤りがあった場合です。誤りがあった場合のチェックが後回しになったり顧客への確認するフローなど複雑化したりしますよね。エラーチェックは前段階でできるだけ行いエラーが無いメッセージをやり取りしをすることで効率を上げることが重要だったりします。
Apache Kafkaでは、メッセージの送り手を「プロデューサー」、メッセージを一次的に受け取り保管するキューを「ブローカ」、
保管されたメッセージの受け取り者を「コンシューマ」と呼びます。
キューの効果その2 受信側の状況に左右されない
受注の話の続きですが、FAXは24時間受信することができますよね。翌営業日の注文になるけれど伝票だけ送れるのって非常に便利ではないでしょうか?
このような効果もMQにはあります。コンシューマのプログラムが起動していない状態でも、プロデューサーはメッセージを送信してブローカーに保存することができます。
例えば、コンシューマのメンテナンスや計画停止などで止まっていてもメッセージを蓄積でき、コンシューマが起動すれば蓄積された
メッセージの続きから読み込むことができます。
コンシューマ側の都合によりプロデューサーを止める必要が無く処理を継続することができるので非常にメンテナンス性が高くなります。
もちろん、逆にプロデューサーだけ止めてもコンシューマに問題が起きることはありません。
業務フローの中で何度もキューイングすることで全体の効率アップへ
今までは、受注の場所の伝票だけの話をしましたが、受注の事務処理から製造現場への指示する場合も製造後の発送時も伝票は使いますよね。
そして、それぞれの間に伝票箱があって必要に応じて伝票を貯めて、それぞれのペースで作業をすることができ、次から次へと伝票が流れるように処理されていきます。1つのフローに対して何度もメッセージを蓄えては渡すことを繰り返して使われます。
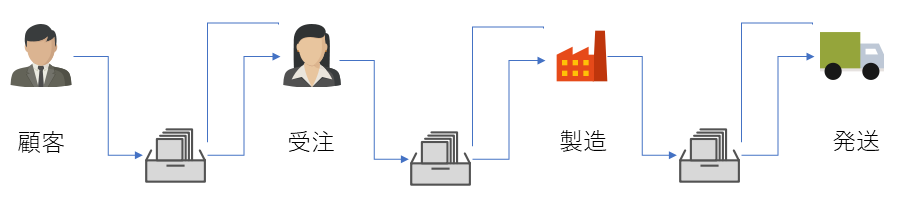
また、流れるようにメッセージを処理するのでストリーミングプラットフォームなんて呼び方もされています。
MQとKafkaの違い
ここまでは、一般的なMQのプロダクトと同じことです。Kafkaはこれに加えて、メッセージの長期保管と分散処理ができます。
キューの長期保管は、発送が終わった後の伝票を経理に渡して、経理が月締め日に一括処理を行い請求書を作成するように長い期間メッセージを確実に保管することができる機構をKafkaは標準で持っています。
※ kafkaではメッセージをストレージに保存するためブローカーの電源をOFFにしてもメッセージが消えることはありません。
Kafkaは複数台のブローカーを並列で動かすことができ、同じキューを複数に分散処理させることができます。
要するに伝票箱が複数あり伝票がロードバランスされ複数の受注者がそれぞれの伝票箱を並列で対応するイメージです。
Confluent Platformの特長
こんな素晴らしいApache Kafkaですが、実際にシステムを作ると結構大変な作業になります。
その大変な作業をを手助けしてくれる機能を備えたのがConfluent Platformです。
大きく分けて以下の3つの拡張を行ってくれます。
- 開発工数とデータアクセスの簡素化
- ストリーム処理の向上
- 運用管理性の向上
開発工数やデータアクセスの簡素化
以下のコンポーネントでアプリケーション開発を簡素化することができます。
- Kafkaコネクト
実際にスクラッチ開発を行う機会は数少なく、既存のデータを使って拡張することが多いです。既存のデータをApache Kafka ストリームへ変換するためにはプログラムを作成しなければなりません。ですが、Confluentは様々なデータを自由にKafka ストリームへ相互変換するKafkaコネクタを持っています。Kafkaコネクタは簡単な設定でデータ変換をしてくれるプログラムで、その種類は100を超えます。
例えば、SQLデータベースに保存されているレコードからストリームを作ったり、ストリームからSQLサーバへレコードを登録したり、ツイッターからツイート内容をストリーム化したり、シスログからストリームを作ったりすることができます。
- スキーマレジストリ
メッセージの内部形式を管理するための管理簿です。スキームごとにどのような内容が保存されているかを確認できるだけではなく、データの前方互換、後方互換を持つことができプロデューサとコンシューマ間のメッセージフォーマットのバージョンに合わせた形に変換してくれます。
これにより、双方のバージョンを同時にバージョンアップする必要がなくなり、デプロイするタイミングを柔軟に調整することができるようになります。
- kafkaクライアント
Apache Kafkaは標準では、Javaでしか使うことができません。そのため、プログラムに制約があります。Kafkaクライアントは、C/C++、Python,Go,Microsoft .NETがサポートされており、必要なプログラミングからKafkaを利用可能人します。オープンソースのクライアントは多数ありますがメンテナンスが行われているかをきちんと確認しなければ、思わぬ不具合は脆弱性に遭遇することがあります。Confluent社が保守をしているので安心して使うことができます。
- RESTプロキシ
REST-APIを使ってストリームへアクセスを行うためのインターフェースです。これにより、Kafkaクライアントに対応していないプログラムからもストリームへアクセスすることができるようになり実質プログラミング言語を選ばずKafkaストリーミングを利用することができるようになります。
- MQTTプロキシ
IoT機器で使われているMQTTデバイスから送られるデータをストリーム化することができます。MQTTブローカーを用意する必要が無いのが特徴です。
※ 詳細は割愛
ストリーム処理の向上
Kafkaで受信したメッセージを高速に一次加工してメッセージを渡すことで、後続のプログラムを簡素化し負荷を軽減するこために2つの方法を提供しています。
- KSQL
非常にパワフルなストリームエンジンであり、受信したメッセージを、簡単なルールに従って情報を付加したり、フィルタリングを行ったりすることができます。
主な利用用途は、
1. IDに従った情報(フィールド)の付加
2. ルールに従ったメッセージのフィルタリング
3. 不必要な情報の削除
※ SQLと付きますがデータベースの用に蓄積されたデータを検索する機能はありません。受信したメッセージ毎に処理され、Kafkaストリームで出力されます。
- Kafka Stream
受信したメッセージをJavaのカスタムプログラムを利用して加工して送信メッセージを送ることができます。KSQLに比べて複雑な処理を実装できますが、簡単なプログラムを作らないといけないのが短所です。
運用管理性の向上
- コントロールセンター
Confluent 全体を管理するためのGUIです。主にモニタリング目的としての利用を想定しているようで、ブローカーやトピック単位での細かな状態をわかりやすく表示しています。ただし、設定変更が可能なものはKSQLとKafkaコネクタのみのようでカスタマイズを行うような設定変更はできないので注意が必要です。
- レプリケーター
マルチデータセンター(マルチブローカー)環境にて、メッセージのレプリカを取得するための機能です。
※ 大規模向けなので初めから使うことはないので割愛します。
- オートデータバランサ
多数のブローカーでクラスタを組んでいる場合に、一部のメッセージが増えて偏った場合にメッセージをクラスタ内部で分散化して偏りをなくすための機能です。
※ 大規模向けなので初めから使うことはないので割愛します。
- セキュリティコントロール
AD/LDAP 連携を行い 参照権限が無いメッセージを送受信できないようにするセキュリティ機能です。
最後に
どうでしょう?Confluentに興味を持っていただけましたでしょうか?
今後技術的なことも書いていくのでよかったらまた読んでいいただけると幸いです。