Summary
- Notion APIラッパーの残り部分を実装し,動作確認
| crate | GitHub |
|---|---|
| rsrpp | rsrpp |
| rsrpp-cli | rsrpp |
| arxiv-tools | rs-arxiv-tools |
| ss-tools | rs-ss-tools |
| keyword-tools | keywords |
| openai-tools | rs-openai-tools |
| - | rs-notion-tools |
前回までのあらすじ
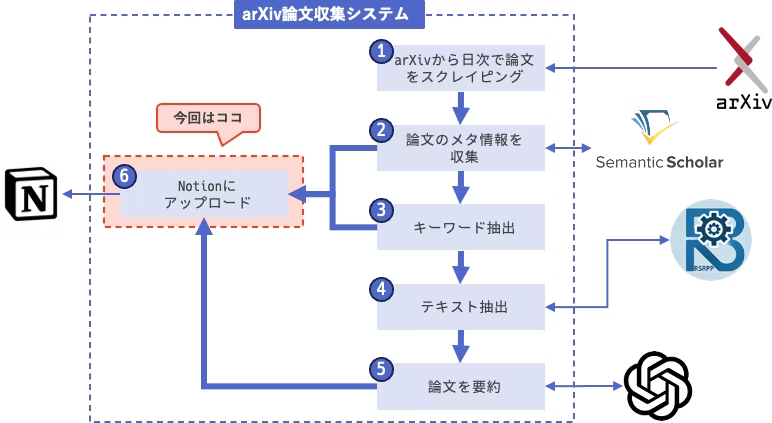
前回で,Notion APIラッパーの実装方針を定めました.
今回は,残りのAPIの実装&動作確認を行います.
APIの実装
今回の論文収集システムに必要なAPIをまとめて実装します.
と言っても,コード自体は前回掲載したものと大差ないので,詳しくはGitHub (rs-notion-tools) をご覧ください.
入口だけ簡単に説明しておくと,今回のNotion APIは基本的に以下のような形をしています.
前回設計した通り,Notion構造体にエンドポイントをまとめる形です.
impl Notion {
...
pub async fn create_a_page(&self, page: Page) -> Result<Page> {
let url = "https://api.notion.com/v1/pages";
let client = request::Client::new();
let data = serde_json::to_string(&page)?;
let content = client
.post(url)
.header("Content-Type", "application/json")
.header("Authorization", format!("Bearer {}", self.api_key))
.header("Notion-Version", "2022-06-28")
.body(data)
.send()
.await?
.text()
.await?;
let mut page = serde_json::from_str::<Page>(&content)?;
if page.status == 0 {
page.status = 200;
}
return Ok(page);
}
...
}
Notionを構成する主なオブジェクトは,Block及びPageですが,NotionのAPIではBlock/Pageの作成や更新のクエリパラメータと戻り値のJSONがだいたい対応しているので,両方とも同じ構造体でデータの受け渡しができるように実装しました.
Notion APIラッパーは構造体の数が多く,少々読みづらいコードになってしまっていますが,APIの入口を簡略化することで使う分にはできるだけ迷わずに使えるようにしたいです.
参考までに,Page構造体の定義は以下のような形.
Rustのserdeでは,シリアライズしたくないフィールドを除外したり,デシリアライズ時のデフォルト値を設定したりとかなり自由度が高いので,そのあたりに大分助けられています.
#[derive(Debug, Clone, Serialize, Deserialize)]
pub struct Page {
#[serde(default = "Parent::default")]
pub parent: Parent,
#[serde(default = "FxHashMap::default")]
pub properties: FxHashMap<String, DatabaseProperty>,
#[serde(default = "String::new", skip_serializing)]
pub object: String,
#[serde(default = "String::new", skip_serializing)]
pub id: String,
#[serde(default = "String::new", skip_serializing)]
pub created_time: String,
#[serde(default = "String::new", skip_serializing)]
pub last_edited_time: String,
#[serde(default = "User::default", skip_serializing)]
pub created_by: User,
#[serde(default = "User::default", skip_serializing)]
pub last_edited_by: User,
#[serde(default = "bool::default", skip_serializing_if = "std::ops::Not::not")]
pub archived: bool,
#[serde(default = "bool::default", skip_serializing)]
pub in_trash: bool,
#[serde(default = "Option::default", skip_serializing)]
pub next_cursor: Option<String>,
#[serde(default = "bool::default", skip_serializing)]
pub has_more: bool,
#[serde(rename = "type", default = "String::new", skip_serializing)]
pub type_name: String,
#[serde(default = "u32::default", skip_serializing)]
pub status: u32,
#[serde(default = "String::new", skip_serializing)]
pub code: String,
#[serde(default = "String::new", skip_serializing)]
pub message: String,
}
動作確認
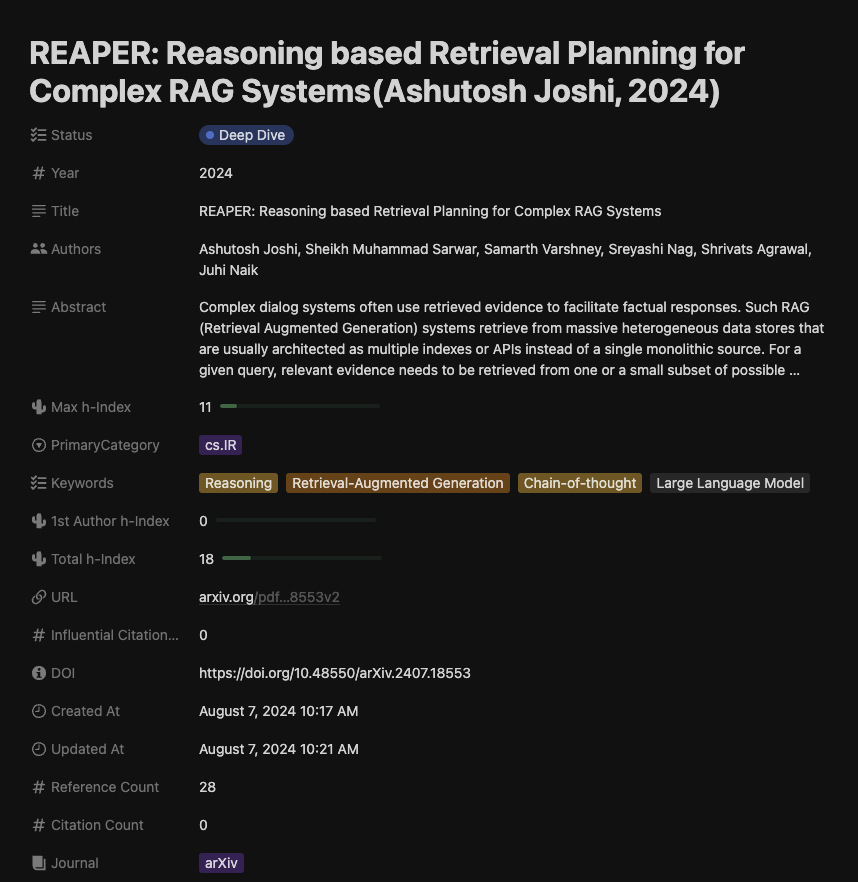
今回のarXiv論文システムでは,Notionにデータベースを作成して以下のフィールドを定義します.
| フィールド | 内容 |
|---|---|
| Status | 論文をチェック済みかどうか |
| Year | 発行年 |
| Title | 論文のタイトル |
| Authors | 著者のリスト |
| Abstract | 論文のアブストラクト |
| PrimaryCategory | arXivのPrimary Category |
| Keywords | 抽出したキーワード |
| URL | 論文のURL |
| Influential CitationCount | Semantic Scholarから取得した値 |
| DOI | 論文のDOI |
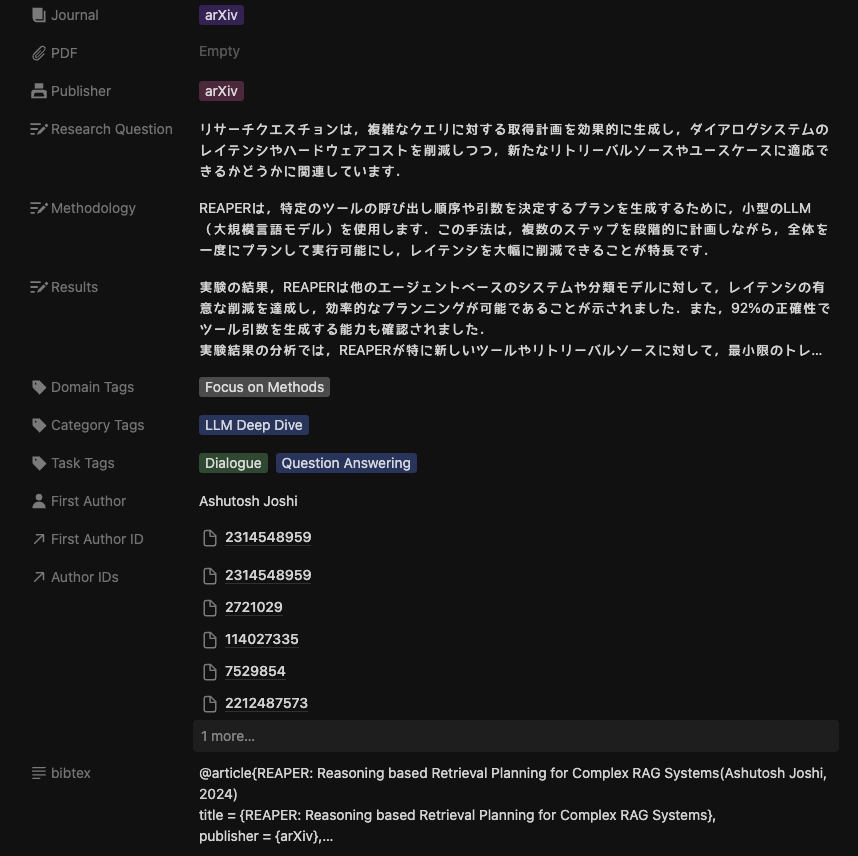
| Research Question | OpenAI APIで抽出したRQ |
| Methodology | OpenAI APIで抽出した分析手法の概要 |
| Results | OpenAI APIで抽出した実験結果の概要 |
rs-notion-toolsは汎用的なAPIラッパーなので,個別のデータベース設定に関する実装は載せていません.
手元でデータベースを更新してみた結果は以下のようなイメージになります.
これで,論文をチェックする際にはリサーチクエスチョンと提案手法あたりをざっと眺めれば,自分にとって必要な論文かどうかをかなり素早くチェックできるようになりました.
次回
次回は,arXiv論文収集システムのそれぞれのパーツを繋ぎ込んだ結果の完成系を紹介します.