はじめに
今回は、超ピンポイントな自分の疑問、「YOLOXのHEAD構造ってどうなっているの?」という疑問に答えていきたいと思います。
この記事を読んで欲しい人
- 物体検知モデルの構築に興味がある人
- YOLOXに興味がある人
YOLOXとは
YOLOXに関する詳しい説明は割愛しますが、「YOLOX: Exceeding YOLO Series in 2021」を読んでいただけたら概要がわかると思います。
論文には、以下のような図があります。
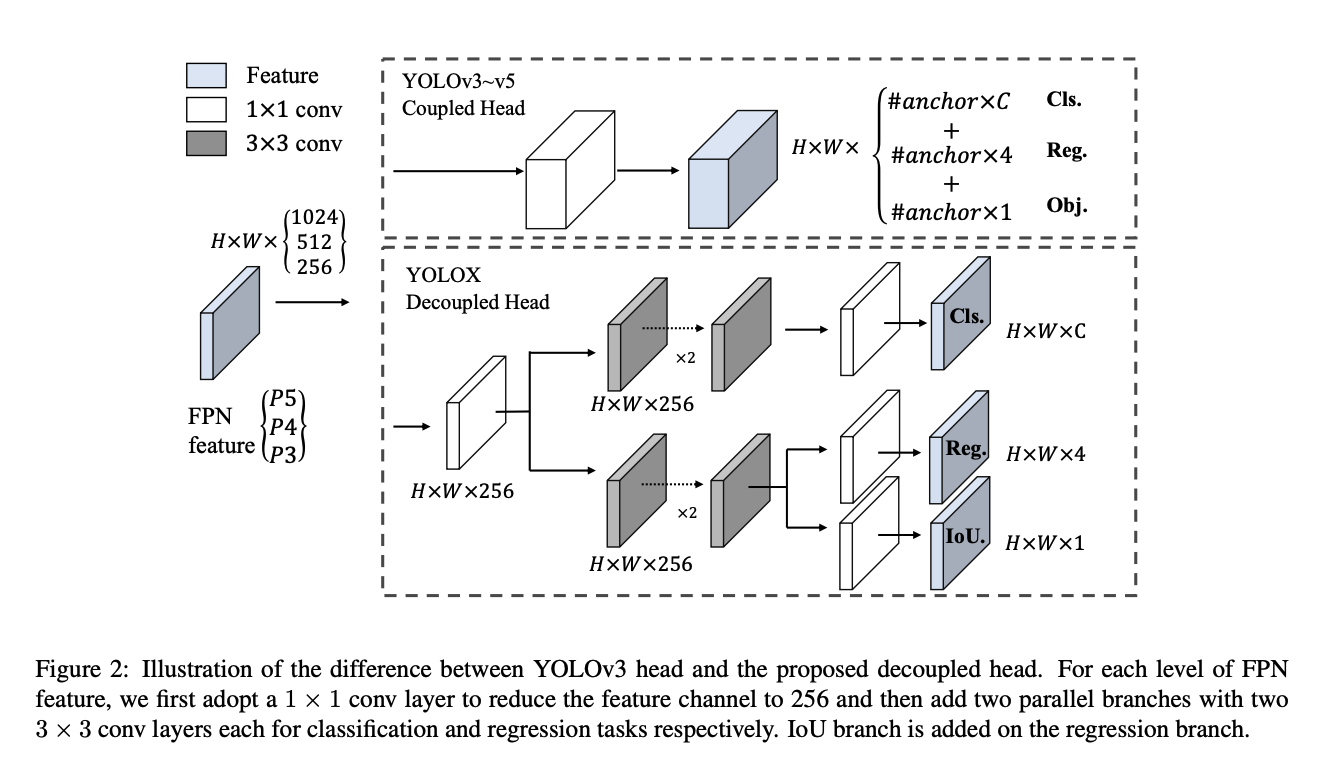
YOLOXの構造について分かったような分からないような気持ちになり、じゃあこんな感じでBBOXの情報となるにはどのような計算が必要かが知りたくなりました。

score閾値によるフィルタリングやNMSが必要となってくるのでしょうけども、それらは具体的にどのような計算によって実現されるのかを見ていきたいと思います。私の疑問は、「物体検知の後処理って何をやっているの?」という汎用的な疑問になります。
YOLOXのモデル構造
公式の実装を見ると、YOLOXにはYOLOPAFPNとYOLOXHead(80)の二つが用意されているのがわかります。backboneはDarknetが用いられておりますが、ここは深追いしないでおきます。
#!/usr/bin/env python
# -*- encoding: utf-8 -*-
# Copyright (c) Megvii Inc. All rights reserved.
import torch.nn as nn
from .yolo_head import YOLOXHead
from .yolo_pafpn import YOLOPAFPN
class YOLOX(nn.Module):
"""
YOLOX model module. The module list is defined by create_yolov3_modules function.
The network returns loss values from three YOLO layers during training
and detection results during test.
"""
def __init__(self, backbone=None, head=None):
super().__init__()
if backbone is None:
backbone = YOLOPAFPN()
if head is None:
head = YOLOXHead(80)
self.backbone = backbone
self.head = head
def forward(self, x, targets=None):
# fpn output content features of [dark3, dark4, dark5]
fpn_outs = self.backbone(x)
if self.training:
assert targets is not None
loss, iou_loss, conf_loss, cls_loss, l1_loss, num_fg = self.head(
fpn_outs, targets, x
)
outputs = {
"total_loss": loss,
"iou_loss": iou_loss,
"l1_loss": l1_loss,
"conf_loss": conf_loss,
"cls_loss": cls_loss,
"num_fg": num_fg,
}
else:
outputs = self.head(fpn_outs)
return outputs
def visualize(self, x, targets, save_prefix="assign_vis_"):
fpn_outs = self.backbone(x)
self.head.visualize_assign_result(fpn_outs, targets, x, save_prefix)
https://netron.app/で見てみたYOLOXのモデル構造

YOLOXのHeadはBackBone+Neck(CSPDarknet)からどんな情報を受け取るの?
1. backboneの処理
class YOLOXには以下の記述があります。
# fpn output content features of [dark3, dark4, dark5]
つまり、Darknetの3, 4, 5層目の出力をHeadは受け取っています。

| 層 | 出力次元 |
|---|---|
| stem | (batch_size, 64, H, W) |
| dark2 | (batch_size, 128, H/2, W/2) |
| ⭐dark3 | (batch_size, 256, H/4, W/4) |
| ⭐dark4 | (batch_size, 512, H/8, W/8) |
| ⭐dark5 | (batch_size, 1024, H/16, W/16) |
公式の実装を見ると、stemの段階ではstrideは1と読めるため空間解像度の縮尺はなさそうなのですが、以下の図ではstemの段階で空間解像度がH/2, W/2となっており、モデルのパラメータ設定が少し違う可能性あり
Darknetのそれぞれの層の出力次元を見ていくと、それぞれ空間解像度が1/2倍、チャンネル数が2倍になって進んでいくのが分かります。これらのうち、dark3±dark5までがYOLOXのHeadに入力されるようです。
2. YOLOPAFPNの処理
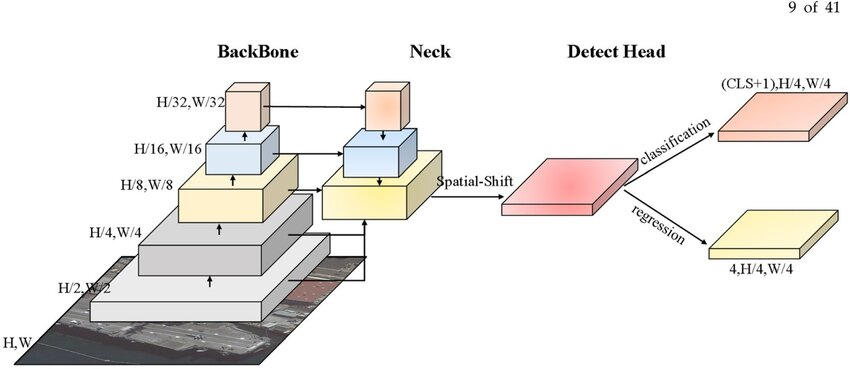
- PAN-FPN(Path Aggregation Network - Feature Pyramid Network) 構造とは、YOLOXのHeadに入力を渡すための特徴マップを生成します。一般的なNeckの役割を果たしています。
| 特徴マップ | 出力次元 | 特徴 |
|---|---|---|
pan_out2 |
(batch_size, 256, H/8, W/8) |
高解像度(小さい物体の検出に有効) |
pan_out1 |
(batch_size, 512, H/16, W/16) |
中間解像度(中程度の物体の検出に有効) |
pan_out0 |
(batch_size, 1024, H/32, W/32) |
低解像度(大きい物体の検出に有効) |
これらの特徴マップは、チャンネル数も空間解像度も違う状態ですが、そのままHeadに渡されるようです。
YOLOXのHeadではどんな処理が行われているの?
Headの役割は、物体検知タスクを行うことです。Backboneから受け取った特徴マップから「分類」「位置予測」タスクを行います。
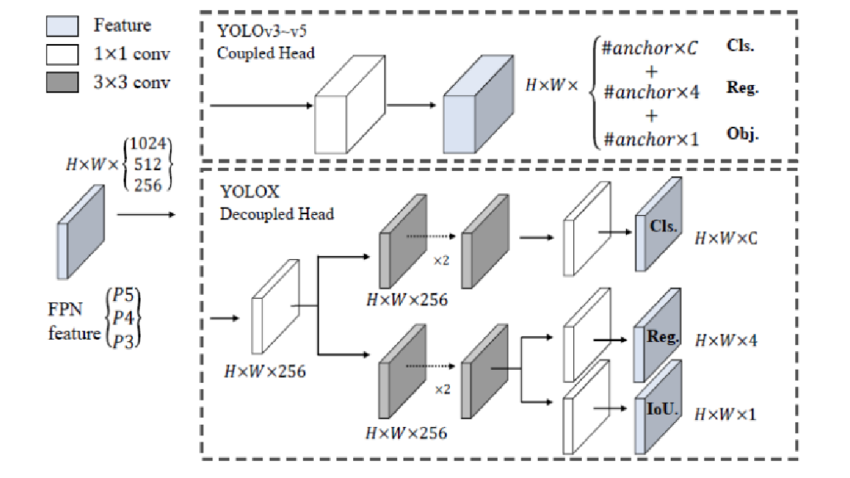
いよいよ論文掲載のこの図となりました。
実装や参考文献を読む限り、
- HeadのStemブロックで256chに統一している模様
- Cls BlockとReg/Objブロックに分離してそれぞれ畳み込み演算
for k, (cls_conv, reg_conv, stride_this_level, x) in enumerate(
zip(self.cls_convs, self.reg_convs, self.strides, xin)
):
x = self.stems[k](x)
cls_x = x
reg_x = x
もちろん他にもsimOTAなどポイントとなるアルゴリズムがありそうですが、一旦先に進めます。
YOLOXのHeadの出力は、入力画像が[512, 512]の場合にtorch.Size([1, 5376, 85])となっていました。
- 最後の85という数字は、coco2017のclass数の80 + bbox(4) + score(1)になっていると思われます。
- 5376という数字は、以下からきているようです。
高解像度(ストライド8): H/8 = 512/8 = 64
中間解像度(ストライド16): H/16 = 512/16 = 32
低解像度(ストライド32): H/32 = 512/32 = 16
-> それぞれWと乗算して加算すると、4096 + 1024 + 256 = 5376となります。
つまり、入力画像の解像度によって、最終的な出力数が二乗に比例して変わってくるようです。
YOLOXはanchorフリーとなっていますが、CSPDarknetから取ってくる層の位置から、「大きめの物体を検知するのが得意な層」〜「小さめの物体を検知するのが得意な層」があり、タスクの内容によって取得する層の位置を調整することで精度が上がる可能性を示唆しているように感じました。
おわりに
突然ですが一旦Headの構造を調査するのはここで終わりにします。NMSなどの実装はまた次回にします!