はじめに
2023年5月にデータのインジェストからデータエンジニアリング、データサイエンス、可視化など、データにまつわるすべてが統合されているMicrosoft Fabricのパブリックプレビューが開始されました🙌
あらゆるデータソースと分析サービスを1つのプラットフォーム上に統合されています。誰でもデータとインサイトにアクセスし、管理できるサービスです。
製品の全体像、各機能について詳しくは、以下のブログやドキュメントがわかりやすいです。
Microsoft Fabricの全体像を眺めてみる
ドキュメントでも出てくるこの全体像の画像。ここで出てくる用語(技術)をふんわりとでも理解しないとMicrosoft Fabricを使い始めても最大限活用はできないと考えています。
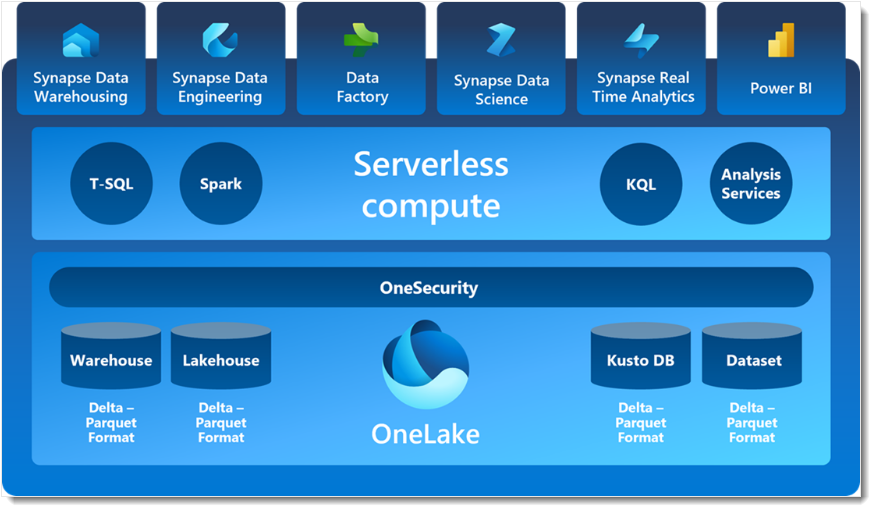
わからない用語(技術)をふんわり理解する
Data Warehouse
まずはData Warehouseです。
企業が持っている様々な情報(データ)をきちんと整理して保管しておく場所です。構造が決まっているデータが保管対象です。Data Warehouseはデータをきちんと整理した上で保管しているので、必要な情報をすぐに見つけることができます。
構造化データ
Data Warehouseを理解するにあたり、構造化データというワードも押さえておきます。
構造化データとは、予め定義されたモデル(つまり、特定の形式やスキーマ)に従って整理されたデータのことを指します。これは通常、行と列の形式で表現されるテーブルデータであり、リレーショナルデータベースで一般的に使用されます。
構造化データの主な特徴は以下の通りです。
-
予め定義されたスキーマ:構造化データは、データの形式、タイプ、関係を定義するスキーマに従います。例えば、顧客データベースでは、各顧客は名前、住所、電話番号などの特定の属性を持つことが期待されます。
-
クエリ可能:構造化データは、SQL(Structured Query Language)などのクエリ言語を使用して簡単に検索、抽出、操作することができます。これにより、特定の条件に一致するデータを迅速に見つけることができます。
-
効率的なストレージとアクセス:構造化データは、効率的なデータストレージと高速なデータアクセスを可能にするために、リレーショナルデータベース管理システム(RDBMS)に保存されます。
構造化データの例には、顧客リスト、製品インベントリ、財務レポートなどがあります。これらのデータはすべて、予め定義されたスキーマに従って整理され、特定の属性(例えば、顧客名、製品ID、財務期間など)を持っています。
構造化データのサンプル
構造化データは、通常、テーブル形式で表示され、各列には特定のデータタイプ(例えば、文字列、数値、日付など)が含まれます。以下に、顧客情報を保存するテーブルの例を示します。
| CustomerID | FirstName | LastName | Phone | |
|---|---|---|---|---|
| 1 | John | Doe | john.doe@example.com | 123-456-7890 |
| 2 | Jane | Smith | jane.smith@example.com | 098-765-4321 |
Data WarehouseをテーマにBing AIに画像を作成してもらう
なるほど🫣 きれいに整理されている感じがでていますね。

Data Lake
Lakehouseをふんわり理解する前に、Data Lakeもふんわり理解しましょう。
Data Lakeは、構造化データだけでなく、型や列名の定義もバラバラのデータや、画像も含む、大量の生データをそのままの形で保存するための大規模なストレージシステムです。Data Lakeは、データがその原始的な形式で保存されるため、データの種類や量に関わらず、すべてのデータを一元的に保存、管理することが目的となっています。
以下に、Data Lakeの主な特徴をいくつか挙げてみます:
データの多様性:Data Lakeは、構造化データ(例えば、データベースのテーブル)、半構造化データ(例えば、JSONやXMLファイル)、非構造化データ(例えば、画像やビデオ)など、あらゆる種類のデータを保存することができます。安価なストレージに大量にデータをためておくので、機械学習を利用するシナリオで活用されることが多いです。
スケーラビリティ:Data Lakeは、大量のデータを保存するために設計されており、データ量が増えるにつれてスケールアップすることができます。これにより、企業はデータの成長に合わせてストレージ容量を増やすことができます。
柔軟性:Data Lakeでは、データはその原始的な形式で保存されます。これにより、データを使用する前に必要な形式に変換することができます。これは、特定のビジネスニーズに対応するためにデータを自由に操作することを可能にします。
ビッグデータとの統合:Data Lakeはビッグデータツールと統合することができ、大量のデータを効率的に分析することが可能です。
半構造化データ
半構造化データとは、構造化データと非構造化データの中間に位置するデータの形式を指します。これは、一部の要素が構造化(つまり、特定の形式やモデルに従って整理)されているが、全体としては完全に構造化されていないデータを指します。
半構造化データの一般的な例には、以下のようなものがあります:
-
XML(eXtensible Markup Language):XMLは、データをタグでマークアップすることで構造を提供します。しかし、XMLデータは自由形式であり、任意の数の要素と属性を持つことができるため、完全に構造化されているわけではありません。
-
JSON(JavaScript Object Notation):JSONは、データをキーと値のペアで表現します。これにより、データに一定の構造が提供されますが、JSONオブジェクトは自由形式であり、任意の数のキーと値を持つことができます。
-
電子メール:電子メールは、送信者、受信者、日付、件名などの構造化フィールドを持つ一方で、メール本文は自由形式のテキストであり、非構造化です。
半構造化データの利点は、構造化データの柔軟性と非構造化データの詳細性を組み合わせることができる点にあります。これにより、半構造化データは、さまざまな形式のデータを一元的に処理し、分析するのに適しています。
半構造化データのサンプル
JSONファイルは半構造化データの一例です。
{
"customers": [
{
"CustomerID": 1,
"FirstName": "John",
"LastName": "Doe",
"Email": "john.doe@example.com",
"Phone": "123-456-7890"
},
{
"CustomerID": 2,
"FirstName": "Jane",
"LastName": "Smith",
"Email": "jane.smith@example.com",
"Phone": "098-765-4321"
}
]
}
非構造化データ
非構造化データとは、特定の形式やモデルに従わないデータのことを指します。これは、データが自由形式であり、予め定義されたスキーマやモデルに従って整理されていないことを意味します。
非構造化データの一般的な例には、以下のようなものがあります:
-
テキストファイル:これは、レポート、メモ、ブログ記事などのテキストドキュメントを含みます。これらのドキュメントは自由形式のテキストであり、特定の形式に従っていません。
-
画像とビデオ:これらは視覚的な情報を含むデータで、特定の形式に従っていません。画像とビデオは、色、形、動きなどの視覚的な要素を通じて情報を伝えます。
-
音声ファイル:これらは音声情報を含むデータで、特定の形式に従っていません。音声ファイルは、音の高さ、音量、音色などの音響的な要素を通じて情報を伝えます。
非構造化データの利点は、その詳細性と多様性にあります。非構造化データは、情報を最も詳細なレベルで捉えることができ、さまざまな形式のデータを一元的に処理することができます。しかし、非構造化データは、その自由形式の性質上、管理や分析が難しいという欠点もあります。そのため、非構造化データを効果的に使用するには、高度なデータ分析ツールやアルゴリズムが必要です。
非構造化データのサンプル
非構造化データは、特定の形式やモデルに従わないデータです。テキストファイルや画像、音声ファイルなどが該当します。以下に、非構造化データの一例として、テキストファイルの内容を示します。
John Doe is a customer who lives in New York. He can be reached at john.doe@example.com or 123-456-7890. Jane Smith is another customer who lives in California. Her contact details are jane.smith@example.com and 098-765-4321.
Data LakeをテーマにBing AIに画像を作成してもらう
Lake感が強いですね🫣

Data Warehouse VS Data Lake
では、組織として、DataはData Warehouseと Data Lakeのどちらの保管形態をとればいいのか。それぞれの形式にはメリットとデメリットが存在します。
一例をあげると、データの引き出し方にあります。
Data Warehouseでは、データは通常、リレーショナルデータベースに保存され、構造化クエリ言語(SQL)を使用して照会されます。データウェアハウスは、データが予め定義されたスキーマに従って整理されているため、特定の質問に対する答えを迅速に見つけることができます。
一方、Data Lakeでは、データはその原始形式で保存されます。これにより、データは非常に柔軟で、様々な形式のデータを保存することができますが、その反面、特定の情報を見つけるためのクエリを作成するのはより複雑になります。非構造化データや半構造化データをクエリするには、通常、特殊なツールやスキルが必要です。
データを保管する際に事前に定義が必要で面倒なData Warehouseですが、データを取り出す際は楽なんです。なんでもそのまま入っているData Lakeではそうもいかないわけです。
Lakehouse
そこで生まれたのがLakehouseという技術です。
Data Warehouse + Data Lake = Lakehouse
両方のいいとこどりをしようということですね。
Lakehouse(レイクハウス)は、データウェアハウス(Data Warehouse)とデータレイク(Data Lake)の機能を組み合わせた新しい種類のデータプラットフォームです。Lakehouse上でSQLライクなクエリを実行できるツール(例えば、Apache HiveやAmazon Athenaなど)が開発されており、Lakehouseからの情報抽出を容易にしています。Lakehouseは大量の生データをそのままの形で保存するデータレイクのスケーラビリティと、構造化データを効率的に分析するデータウェアハウスのパフォーマンスと管理機能を兼ね備えています。
以下に、Lakehouseの主な特徴をいくつか挙げてみます。
-
データの多様性:Lakehouseは、構造化データ、半構造化データ、非構造化データなど、あらゆる種類のデータを保存することができます。これにより、企業は一元的なデータプラットフォームでデータを管理することができます。
-
スケーラビリティ:Lakehouseは、大量のデータを保存するために設計されており、データ量が増えるにつれてスケールアップすることができます。これにより、企業はデータの成長に合わせてストレージ容量を増やすことができます。
-
高パフォーマンスの分析:Lakehouseは、Data Warehouseのように、構造化データを効率的に分析することができます。これにより、企業は大量のデータから迅速に洞察を得ることができます。
Lakehouseの利点は、データの多様性とスケーラビリティ、高パフォーマンスの分析、強力なデータガバナンスと管理機能を一つのプラットフォームで提供できる点にあります。これにより、企業はより広範なデータを効率的に管理し、分析することができます。
LakehouseをテーマにBing AIに画像を作成してもらう
もうデータ関係なくなってますね🫣

まとめ
まずは、
- Data Warehouse
- Data Lake
- Lakehouse
の3点をふんわり理解しました。
Microsoft Fabricは広い世界観のため、まだまだ続きます。
参考資料