概要
機械学習用にコンテンツデータを集めないと行けなくて、毎回クローラー書くの面倒だったので、汎用的なクローラーを開発
構成
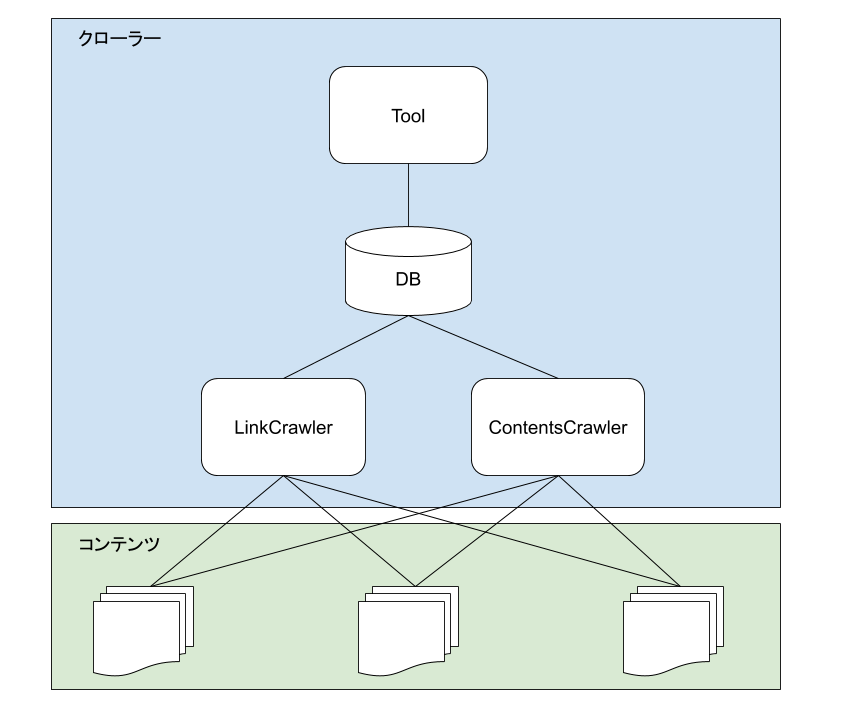
仕組み
LinkCrawlerで起点のURLからリンクを辿り対象のURL収集しDBに保存、
ContentsCrawlerで収集したURLを取得しコンテンツの取得を行ってDBに保存する
AWS
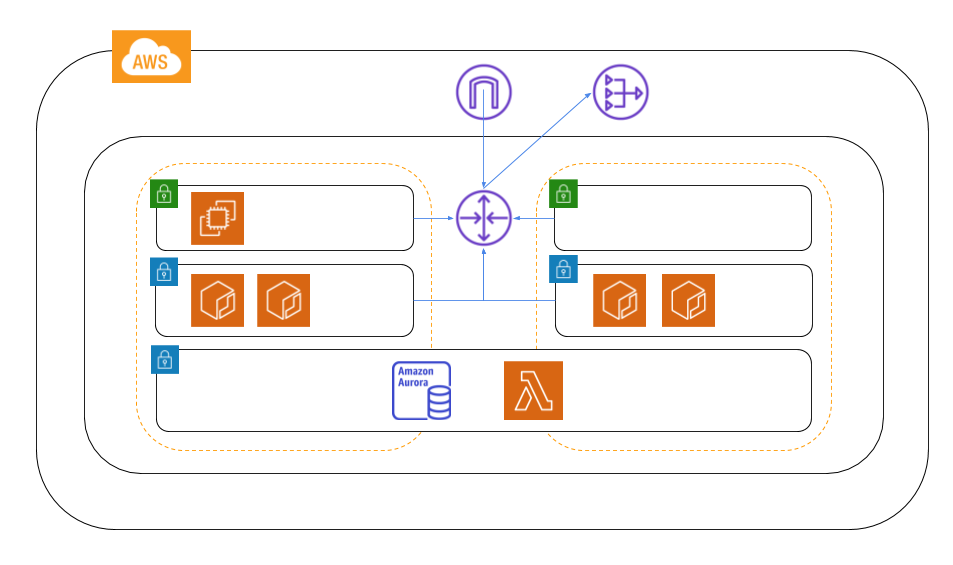
アプリケーション
・puppeteer
・node.js
DataBase
table
CREATE TABLE `site` (
`id` int(11) unsigned NOT NULL AUTO_INCREMENT,
`title` varchar(255) NOT NULL,
`url` varchar(300) NOT NULL,
`created_at` datetime NOT NULL,
`updated_at` datetime NOT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
CREATE TABLE `site_links` (
`id` int(11) unsigned NOT NULL AUTO_INCREMENT,
`site_worker_id` int(11) NOT NULL,
`url` varchar(300) NOT NULL,
`crawl_status` int(11) NOT NULL DEFAULT '0',
`crawl_date` datetime DEFAULT NULL,
`created_at` datetime NOT NULL,
`updated_at` datetime NOT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
CREATE TABLE `site_structure_data` (
`id` int(11) unsigned NOT NULL AUTO_INCREMENT,
`site_links_id` int(11) NOT NULL,
`structure_data` text NOT NULL,
`created_at` datetime NOT NULL,
`updated_at` datetime NOT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
CREATE TABLE `site_worker` (
`id` int(11) unsigned NOT NULL AUTO_INCREMENT,
`start_url` varchar(300) NOT NULL,
`allow_domains` varchar(300) NOT NULL,
`depth_limit` tinyint(4) NOT NULL DEFAULT '0',
`allow_url_regex` varchar(300) DEFAULT NULL,
`deny_url_regex` varchar(300) DEFAULT NULL,
`site_type` varchar(10) NOT NULL,
`json_column` varchar(10) DEFAULT NULL,
`is_deleted` tinyint(4) NOT NULL DEFAULT '0',
`created_at` datetime NOT NULL,
`updated_at` datetime NOT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
CREATE TABLE `site_worker_structure` (
`id` int(11) unsigned NOT NULL AUTO_INCREMENT,
`site_worker_id` int(11) NOT NULL,
`name` varchar(100) NOT NULL,
`is_deleted` tinyint(4) NOT NULL DEFAULT '0',
`created_at` datetime NOT NULL,
`updated_at` datetime NOT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
CREATE TABLE `site_worker_structure_selector` (
`id` int(11) unsigned NOT NULL AUTO_INCREMENT,
`site_worker_id` int(11) NOT NULL,
`site_worker_structure_id` int(11) NOT NULL,
`selector` varchar(1000) NOT NULL,
`attribute` varchar(100) DEFAULT NULL,
`created_at` datetime NOT NULL,
`updated_at` datetime NOT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
クローラー
link_crawler.js
require('dotenv').config();
const puppeteer = require('puppeteer');
const config = require('config');
const mysql = require('mysql2/promise');
const request = require('request-promise');
const { URL } = require('url');
const viewportWidth = 1024;
const viewportHeight = 600;
const userDataDir = `${config.root_path}/tmp/crawler`;
let connection;
const userAgent = 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_10_3) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/60.0.3112.101 Safari/537.36';
console.log('NODE_ENV=%s', process.env.NODE_ENV);
const in_array = (arr, str) => {
let ret = false;
for (const i in arr) {
if (arr[i].url === str) {
ret = true;
break;
}
}
return ret;
};
async function linkCrawler(browser, args) {
const links = [];
await getContents(browser, args, links);
for (const i in links) {
const data = [
links[i].site_worker_id,
links[i].url
];
const [rows, fields] = await connection.execute('SELECT id FROM site_links WHERE site_worker_id = ? AND url = ?', data);
if (rows.length > 0) {
continue;
}
await connection.execute('INSERT INTO site_links(site_worker_id, url, created_at, updated_at) VALUES(?, ?, now(), now())', data);
}
console.log(links);
}
async function getJson(args) {
const site_worker_id = args.id;
const start_url = args.start_url;
const allow_domains = args.allow_domains;
const json_column = args.json_column;
console.log('start_url', start_url);
const options = {
url: start_url,
json: true,
headers: {
'User-Agent': userAgent
}
};
const list = await request(options);
for (const i in list.list) {
const detail = list.list[i];
const data = [
site_worker_id,
`https://${allow_domains}${detail[json_column]}`
];
console.log(data);
const [rows, fields] = await connection.execute('SELECT id FROM site_links WHERE site_worker_id = ? AND url = ?', data);
if (rows.length > 0) {
continue;
}
await connection.execute('INSERT INTO site_links(site_worker_id, url, created_at, updated_at) VALUES(?, ?, now(), now())', data);
}
}
async function getContents(browser, args, links) {
const page = await newPage(browser);
const site_worker_id = args.id;
const start_url = args.start_url;
let depth = 1;
const allow_domains = args.allow_domains;
const allow_url_regex = args.allow_url_regex;
const deny_url_regex = args.deny_url_regex;
const depth_limit = args.depth_limit;
if (args.depth) {
depth = args.depth + 1;
}
console.log('start_url', start_url);
await page.goto(start_url);
await page.waitFor(1000);
const items = await page.$$('a');
for (let i = 0; i < items.length; i++) {
let pattern;
const str_href = await (await items[i].getProperty('href')).jsonValue();
if (str_href === '') {
continue;
}
const url = new URL(str_href);
// remove hash
url.hash = '';
const str_url = url.href;
if (in_array(links, str_url) === true) {
continue;
}
// domain
if (allow_domains !== undefined) {
pattern = new RegExp(`//${allow_domains.replace(',', '|//')}`);
if (str_url.match(pattern) === null) {
continue;
}
}
// url pattern
if (allow_url_regex !== null) {
pattern = new RegExp(allow_url_regex);
if (str_url.match(pattern) === null) {
continue;
}
}
if (deny_url_regex !== null) {
pattern = new RegExp(deny_url_regex);
if (str_url.match(pattern) !== null) {
continue;
}
}
console.log(depth, str_url);
links.push({url: str_url, depth: depth, site_worker_id: site_worker_id});
if (depth_limit > depth) {
const params = {};
Object.assign(params , args);
params.start_url = str_url;
params.depth = depth;
await getContents(browser, params, links);
}
}
await page.close();
}
async function newPage(browser) {
const page = await browser.newPage();
await page.setExtraHTTPHeaders({
'Accept-Language': 'ja,en-US;q=0.9,en;q=0.8'
});
const options = {
viewport: {
width: viewportWidth,
height: viewportHeight,
},
userAgent,
};
await page.emulate(options);
return page;
}
(async () => {
try {
connection = await mysql.createConnection({
host: 'localhost',
user: 'root',
password: '',
database: 'crawler'
});
const [rows, fields] = await connection.execute('SELECT * FROM site_worker WHERE is_deleted = 0');
if (rows === undefined || rows.length <= 0) {
console.log('no data');
connection.end();
return;
}
const params = rows[0];
if (params.site_type === 'contents') {
const browser = await puppeteer.launch({
headless: false,
devtools: false,
executablePath: config.chrome,
userDataDir: userDataDir,
args: ['--no-sandbox', '--disable-setuid-sandbox'],
});
await linkCrawler(browser, params);
browser.close();
}
if (params.site_type === 'json') {
await getJson(params);
}
connection.end();
} catch(e) {
console.error(e);
}
})();
contents_crawler.js
require('dotenv').config();
const puppeteer = require('puppeteer');
const moment = require('moment');
const config = require('config');
const mysql = require('mysql2/promise');
const { URL } = require('url');
const uuidv4 = require('uuid/v4');
const viewportWidth = 1024;
const viewportHeight = 600;
const userDataDir = `${config.root_path}/tmp/crawler`;
let connection;
console.log('NODE_ENV=%s', process.env.NODE_ENV);
async function contentsCrawler(browser, links, structure) {
for (const i in links) {
await getContents(browser, links[i], structure);
}
}
async function getContents(browser, args, structure) {
const page = await newPage(browser);
const id = args.id;
const site_worker_id = args.site_worker_id;
const url = args.url;
console.log('crawl_url', url);
const response = await page.goto(url);
await page.waitFor(10000);
const status = response.status();
const data = {};
for (const i in structure) {
const name = structure[i].name;
const selector_dic = structure[i].selector;
for (const j in selector_dic) {
const selector = selector_dic[j].selector;
const attribute = selector_dic[j].attribute;
const item = await page.$(selector);
if (item === null) {
data[name] = null;
continue;
}
if (attribute === null) {
data[name] = await (await item.getProperty('textContent')).jsonValue();
break;
}
if (attribute === 'src') {
const file_name = uuidv4();
const path = `tmp/images/${file_name}.jpg`;
const image = await page.$(selector);
await image.screenshot({
path: path,
omitBackground: true,
});
data[name] = path;
break;
}
data[name] = await (await item.getProperty(attribute)).jsonValue();
if (data[name]) {
break;
}
}
}
let params = [
JSON.stringify(data),
id
];
let sql = 'INSERT INTO site_structure_data(structure_data, site_links_id, created_at, updated_at) VALUES(?, ?, now(), now())';
const [rows, fields] = await connection.execute('SELECT id FROM site_structure_data WHERE site_links_id = ?', [id]);
if (rows.length > 0) {
sql = 'UPDATE site_structure_data set structure_data = ?, updated_at = now() WHERE site_links_id= ?';
}
await connection.execute(sql, params);
params = [
status,
id,
site_worker_id
];
await connection.execute('UPDATE site_links SET crawl_status = ?, crawl_date = now() WHERE id = ? AND site_worker_id = ?', params);
await page.close();
return data;
}
async function newPage(browser) {
const page = await browser.newPage();
await page.setExtraHTTPHeaders({
'Accept-Language': 'ja,en-US;q=0.9,en;q=0.8'
});
const options = {
viewport: {
width: viewportWidth,
height: viewportHeight,
},
userAgent: 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_10_3) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/60.0.3112.101 Safari/537.36',
};
await page.emulate(options);
return page;
}
(async () => {
try {
connection = await mysql.createConnection({
host: 'localhost',
user: 'root',
password: '',
database: 'crawler',
charset : 'utf8mb4'
});
const site_worker_id = 4;
const [structure] = await connection.execute('SELECT id, site_worker_id, name FROM site_worker_structure WHERE site_worker_id = ? order by id', [site_worker_id]);
if (structure === undefined || structure.length <= 0) {
console.log('no data');
connection.end();
return;
}
const [structure_selector] = await connection.execute('SELECT id, site_worker_id, site_worker_structure_id, selector, attribute FROM site_worker_structure_selector WHERE site_worker_id = ?', [site_worker_id]);
if (structure_selector === undefined || structure_selector.length <= 0) {
console.log('no data');
connection.end();
return;
}
for (const i in structure) {
for (const j in structure_selector) {
if (structure[i].id !== structure_selector[j].site_worker_structure_id) {
continue;
}
if (structure[i].selector === undefined) {
structure[i].selector = [];
}
const selector = {selector: structure_selector[j].selector, attribute: structure_selector[j].attribute};
structure[i].selector.push(selector);
}
}
const [links] = await connection.execute('SELECT id, site_worker_id, url FROM site_links WHERE site_worker_id = ? AND crawl_status = 0', [site_worker_id]);
if (links === undefined || links.length <= 0) {
console.log('no data');
connection.end();
return;
}
const browser = await puppeteer.launch({
headless: false,
devtools: false,
executablePath: config.chrome,
userDataDir: userDataDir,
args: ['--no-sandbox', '--disable-setuid-sandbox'],
});
await contentsCrawler(browser, links, structure);
browser.close();
connection.end();
} catch(e) {
console.error(e);
}
})();
最後に
うまく動かない場合はごめんなさい
ツールを作ってweb上から設定できるようにしていますが、長いので割愛