概要
Google AnalyticsのデータをS3に保存して、athenaに取り込んみQuickSightで可視化してみました
構成
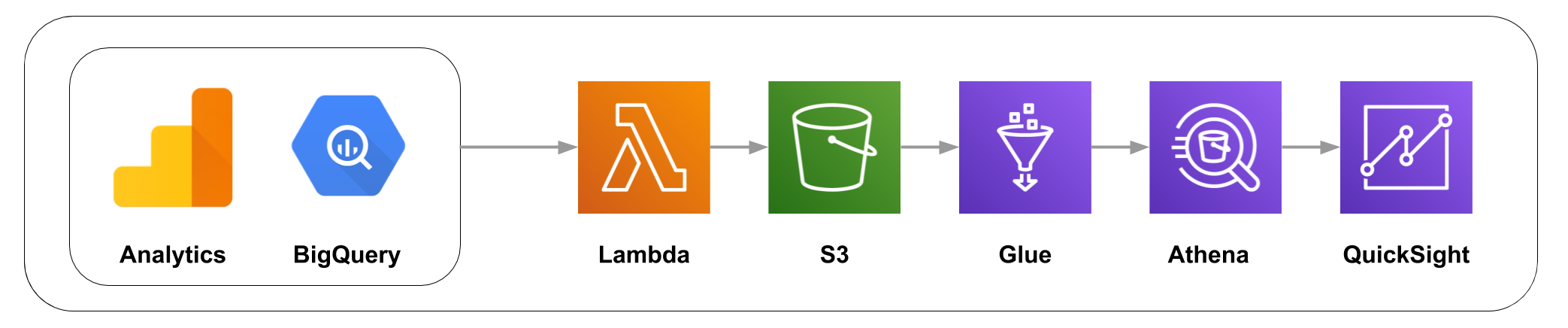
Lambda
LambdaでBigQueryからデータの取得しS3にアップロードする。
実際にはBigQueryから直接ダウンロードできないので、一旦Google StorageにBigQueryのダンプファイルを落とす感じになります
BigQueryのデータをダンプしてストレージ保存する
client = bigquery.Client(
credentials=credentials,
project=credentials.project_id,
)
project = credentials.project_id
dataset_ref = client.dataset(dataset_id, project=project)
table_ref = dataset_ref.table(table_id)
ext_job_config = bigquery.job.ExtractJobConfig()
ext_job_config.destination_format = bigquery.job.DestinationFormat.NEWLINE_DELIMITED_JSON
ext_job_config.compression = bigquery.Compression.GZIP
extract_job = client.extract_table(
table_ref,
destination_uri.format(gcp_bucket_name, target_day, file_name),
location='US',
job_config=ext_job_config
)
extract_job.result()
Glue
クローラーを設定する
設定内容はほぼデフォルトのですが「クローラの出力を設定する」の項目以下を設定
- 「設定オプション」で「新規列のみ追加します。」を選択
- 「全ての新規および既存のパーティション〜」にチェックをつける
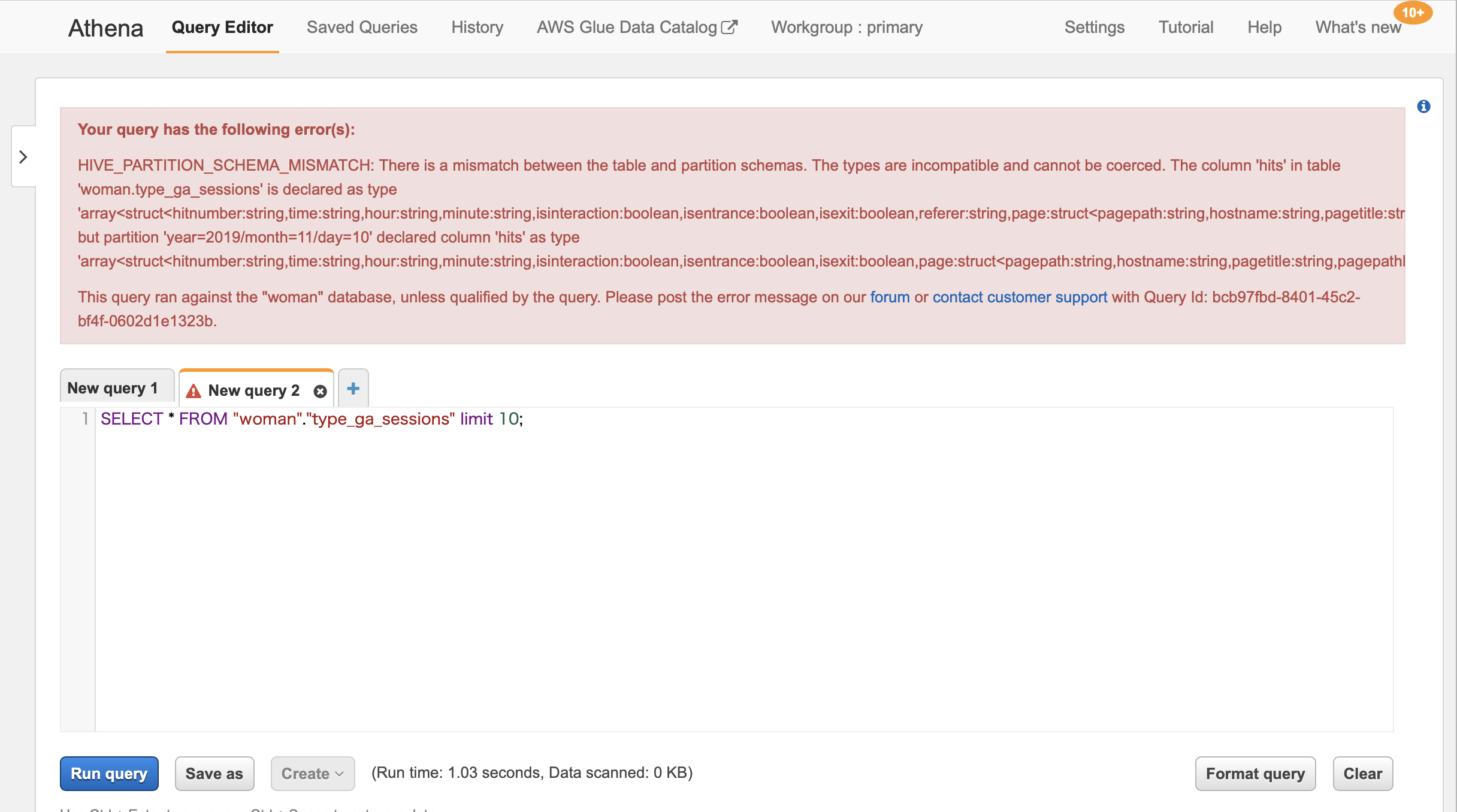
この設定をしないとAthenaでSQLを実行した際に下記の様なエラーメッセージができる
Your query has the following error(s):
HIVE_PARTITION_SCHEMA_MISMATCH: There is a mismatch between the table and partition schemas.
Athena
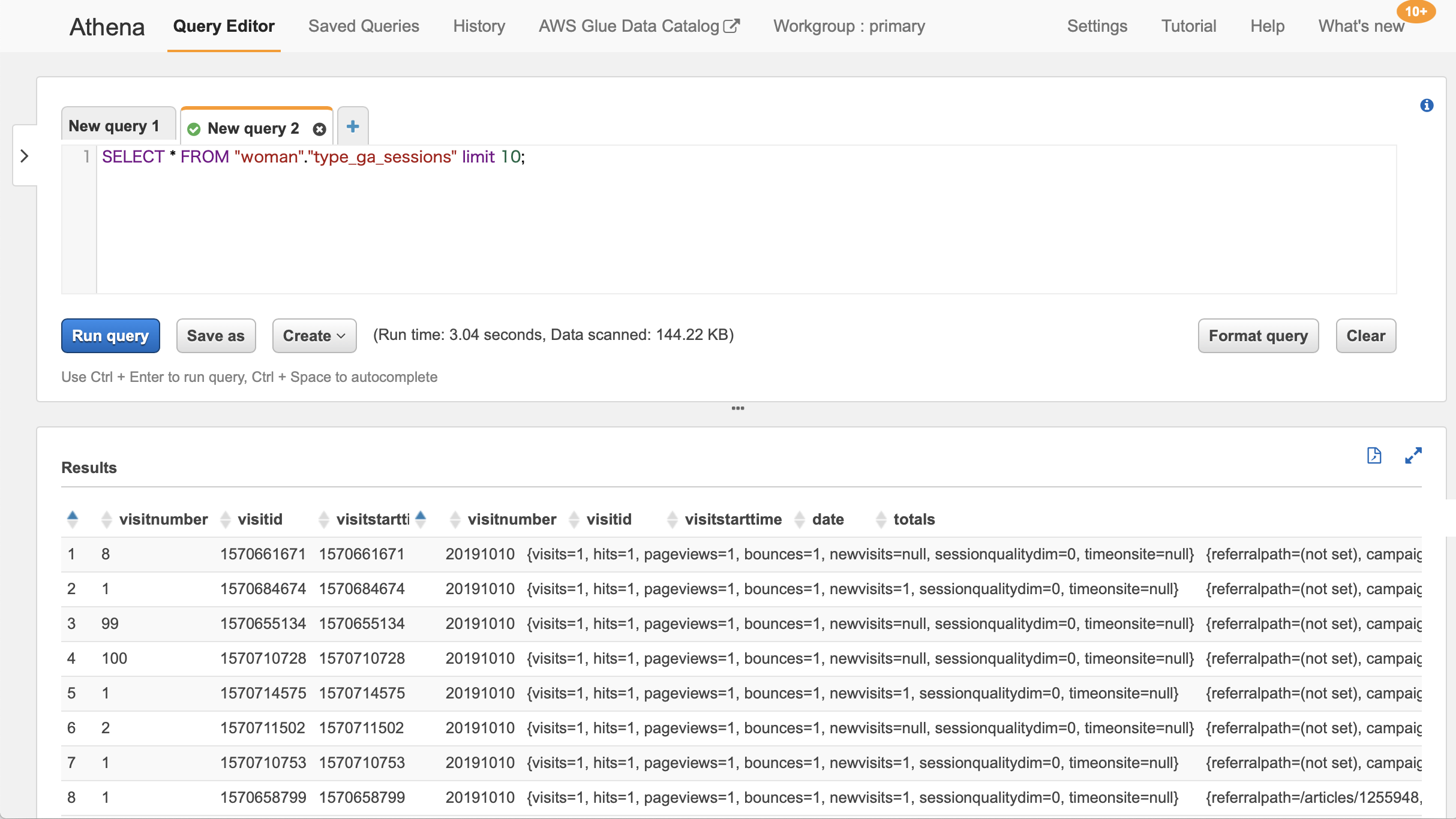
Glueでクロールが完了するとAthena側でSQLを実行してみる、以下の様に結果が表示されればOK
ちょっと一手間、Athenaに取り込んだデータのカラムが複合型なので、Viewを作りQuickSightで取り出しやすい形にしておきます
CREATE OR REPLACE VIEW ga_pageviews AS
SELECT
"date"
, "count"("totals"."pageviews") "pageviews"
FROM
woman.type_ga_sessions CROSS JOIN UNNEST("hits") t (hit)
WHERE ("hit"."type" = 'PAGE')
GROUP BY "date"
QuickSight
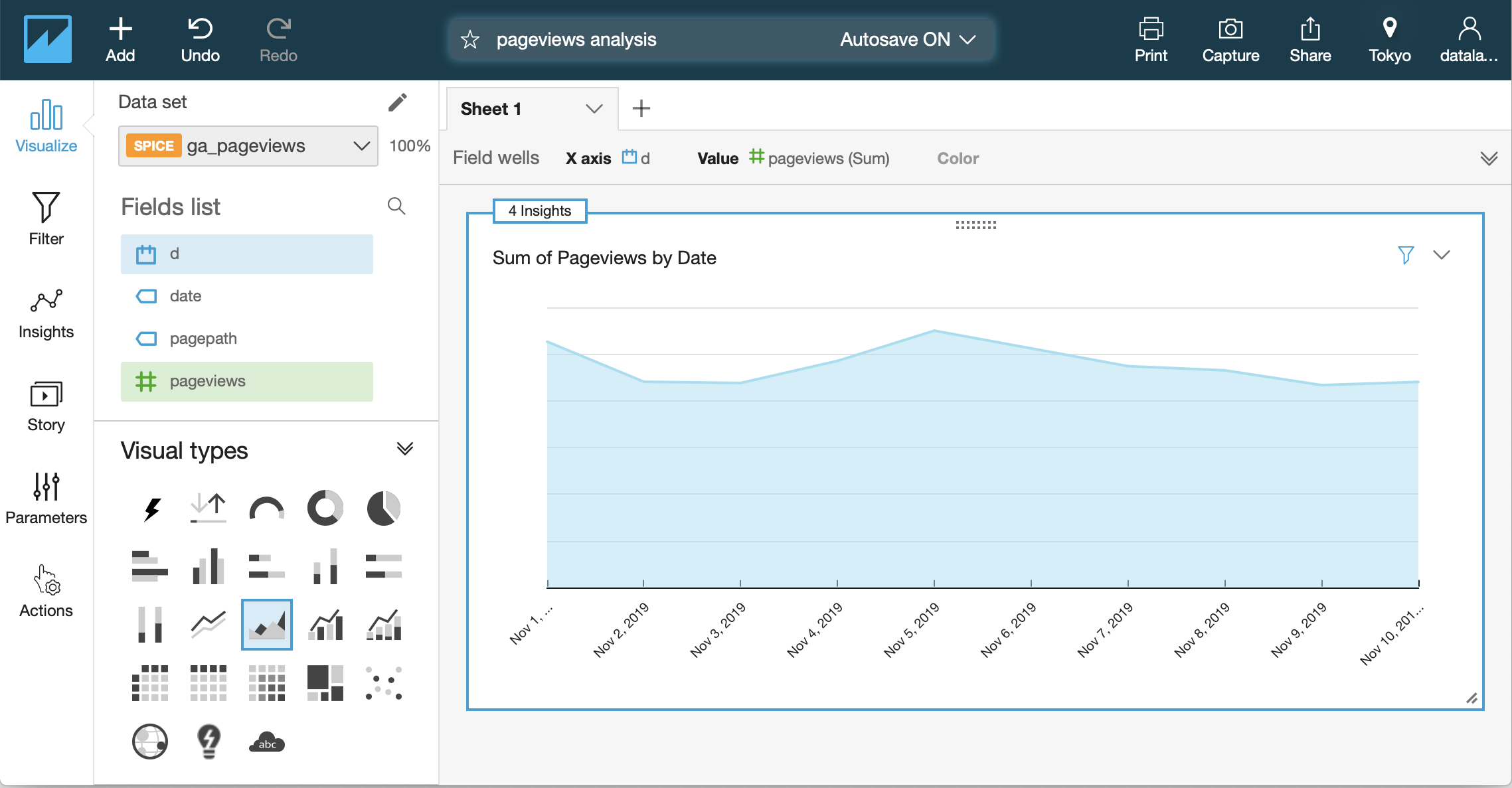
可視化のためQuickSightを使って可視化を行います
注意点
analyticsは360が対象です、360出ない場合はAPIで取得してS3にアップします(制限あり)
Athenaに取り込んだデータの型がstringなので、Glueのジョブで前処理をするか、QuickSigthの方でcastする必要があります
まとめ
開発工数は1〜2人日、すごく手軽にできます。
費用面もbigqueryよりathenaの方が安いように感じます
サービス内で持っているコンテンツの情報も取り込んで、analyticsの情報とかけ合わせると面白い分析が出来ると思いました。