Streamlitとは
StreamlitはPython向けのWebアプリケーションフレームワークです。
Streamlitを使うとフロントエンドの知識ゼロでもデータを可視化するためのWebアプリケーションを簡単に作れます。以下のような機能が特徴。
- 変数を地の文に書くだけで、GUIに出力される(マジックコマンド)
-
st.radioやst.text_inputのようなWidget APIを呼び出すだけで、GUIコンポーネントが生成される
30 Days of StreamlitはStreamlitのチュートリアルコンテンツ。SNSに進捗を共有しながらちょっとづつStreamlitを学習できます。
#30DaysOfStreamlitで検索すると先人たちのチャレンジの記録がたくさん!
やっていきましょう。
Day 20まで
Day 20までの日記はこちら。
Day 21
Day 21はプログレスバーを使ってみようという内容でした。
サンプルコードは以下のような感じ。
my_bar = st.progress(0)
for percent_complete in range(100):
time.sleep(0.05)
my_bar.progress(percent_complete + 1)
st.snow()
st.progressで初期化したインスタンスに対して0~100のint値を進捗率として指定すればそれに応じた表示になります。
ドキュメントによると0.0~1.0のfloat値でもいいそうです。
インスタンスから最後に設定した進捗率を取得する方法はなさそうなので、他の変数で管理する必要があるみたいですね。
Streamlitで時間のかかる処理や非同期処理のコールバック待ちするときの基本形も勉強したいなあ。
Day 22
Day 22は入力フォームを使ってみようという内容でした。

送信ボタン(form_submit_button)以外のボタンはフォーム内に置けないそうです。
これまでのチュートリアルでもセレクトボックスやスライダーなどのそれぞれの要素を操作した結果はプログラムで受け取れたのですが、この入力フォームが重要なのは、プログラムで受け取るタイミングが違うことですね。
入力フォームを使わないときは、要素を操作するとその結果の変数を即座にプログラムで受け取って(実はこのタイミングでプログラムが再実行されている!)、画面に反映していました。
入力フォームを使うことで、要素を操作しても送信ボタンを押すまでは結果の変数をプログラムに受け渡すのを待ってくれます。
内部的な挙動はStreamlitのドキュメントのAdvanced featuresが詳しかったです。
- The user changes a widget's value on the frontend.
- The widget's value in st.session_state and in the Python backend (server) is updated.
- The script rerun begins.
- If the widget has a callback, it is executed as a prefix to the page rerun.
- When the updated widget's function is executed during the rerun, it outputs the new value.
st.session_stateという特殊な変数を使うことで、要素を操作した結果をプログラムが再実行されたときに受け渡しているみたいですね。
昔ながらのHTMLの入力フォームだと送信ボタンを押したときの遷移先やアクションを設定することができましたが、それはst.form_submit_buttonの返り値がTrueになったときに何かやればよさそう。
このチュートリアルでは触れられていませんが、st.formsには送信ボタンを押したときにクリアされるオプションclear_on_submitがあったり、
st.form_submit_buttonにはプログラムを再実行したときに指定したコールバック関数を追加で実行してくれるオプションon_clickがあったりします。
参考:st.forms
参考:st.form_submit_button
Day 23
Day 23はst.experimental_get_query_paramsという関数を使ってみようという内容でした。
URLパラメータを取得できる関数です。
この関数、変わった名前ですが、Experimental feature(実験的機能)だそうです。
参考:st.experimental_get_query_params
This is an experimental feature. Experimental features and their APIs may change or be removed at any time.
翻訳すると以下のような感じでしょうか?
これは実験的機能です。実験的機能とそのAPIは、いつでも変更あるいは削除される可能性があります。
サンプルを見ても「ほらエラー出るでしょ?」という感じで挙動がよく分からないので、ちょっと書き換えて実行してみました。
import streamlit as st
# タイトルを表示
st.title('st.experimental_get_query_params')
# URLパラメータを取得して表示
params = st.experimental_get_query_params()
if params is None:
st.write('get_query_params(): None')
else:
st.write('get_query_params(): not None')
if isinstance(params, dict):
st.write('get_query_params(): dict')
l = len(params)
st.write('get_query_params(): len == {}'.format(l))
else:
st.write('get_query_params(): not dict')
st.write(params)
URLパラメータなしで実行した場合は以下のようになりました。
URLパラメータがない場合は空のdictを返してくれるようです。
get_query_params(): not None
get_query_params(): dict
get_query_params(): len == 0
{}
URLパラメータありで実行してみます。
自分はlocalhostで実行しているのでhttp://localhost:8501/?firstname=Hoge&lastname=Fugaみたいになります。
dictにURLパラメータが設定されています!
同じ変数名で複数の値を渡す場合があるので、値が配列になっています。
get_query_params(): not None
get_query_params(): dict
get_query_params(): len == 2
{
"firstname":[
0:"Hoge"
]
"lastname":[
0:"Fuga"
]
}
Day 24
Day 24はキャッシュ機能です。
とりあえずコピペで動かしてみる。
st.cache is deprecated. Please use one of Streamlit's new caching commands, st.cache_data or st.cache_resource.
More information in our docs.
30 Days of Streamlitの記載が古いようですね…ドキュメントを見ながら直してみましょう。
@st.cacheを@st.cache_dataに置き換えればおおむねOKなようです。
import streamlit as st
import numpy as np
import pandas as pd
from time import time
# タイトルを表示
st.title('st.cache')
# キャッシュを使用したデータ生成関数の試験
begin_time_with_cache = time()
st.subheader('Using st.cache')
# キャッシュを使用したデータ生成関数。有効時間を30秒に設定
@st.cache_data(ttl=30)
def load_data_a():
df = pd.DataFrame(
np.random.rand(2000000, 5),
columns=['a', 'b', 'c', 'd', 'e']
)
return df
st.write(load_data_a())
end_time_with_cache = time()
# キャッシュを使用した場合の処理時間を表示
st.info(end_time_with_cache - begin_time_with_cache)
# キャッシュを使用しないデータ生成関数の試験
begin_time_without_cache = time()
st.subheader('Not using st.cache')
# キャッシュを使用しないデータ生成関数
def load_data_b():
df = pd.DataFrame(
np.random.rand(2000000, 5),
columns=['a', 'b', 'c', 'd', 'e']
)
return df
st.write(load_data_b())
end_time_without_cache = time()
# キャッシュを使用しない場合の処理時間を表示
st.info(end_time_without_cache - begin_time_without_cache)
オプションを指定しないとキャッシュが効いているのかよく分からないので、有効時間を設定してみました。
実行時間を測定してみましょう。
| --- | 初回起動 | Rerun |
|---|---|---|
| キャッシュあり | 0.3062369823455811秒 | 0.17932486534118652秒 |
| キャッシュなし | 0.2697906494140625秒 | 0.24178194999694824秒 |
データ生成がキャッシュされた分だけちゃんと早くなってそうですね!
右上のハンバーガーメニューから手動でキャッシュクリアすることもできます。

引数の値が異なると違うものと判定されてキャッシュは使われません。
引数で挙動が変わる関数を作ってみましょう。
# 引数でシードを指定できるデータ生成関数
@st.cache_data(ttl=1000)
def load_data(seed):
np.random.seed(seed)
df = pd.DataFrame(
np.random.rand(5000000, 5),
columns=['a', 'b', 'c', 'd', 'e']
)
return df
ここに色んな引数を渡してみると、引数が同じときだけキャッシュが使われることが確認できます。

キャッシュにはいくつかオプションがありますが、基本的なものは以下になります。
- ttl:有効時間(TTL)
- max_entries:最大エントリ数。First-In-First-Outで制御される
- show_spinner:キャッシュされていない関数の実行中にスピナーを表示するかどうか
サンプルコードはランダムな数値が詰め込まれたデータフレームでしたが、MLモデルの読み込みなどで活用できそうですね。
Day 25
Day 25はst.session_stateです。
Streamlitは画面を操作するたび(例えばボタンを押したとき)にコードを上から実行し直しています。そのたびに変数がリセットされてしまいます。
それでは困るというときにこのst.sesssion_stateを使えばいいようです。
st.session_stateはdict型で変数を書き込み・読み出しできます。
読み出しの例はこんな感じ。
# session_stateに変数があるとき
if 'count' in st.session_state:
st.write('count:' + str(st.session_state['count']))
# session_stateに変数がないとき
else:
st.write('count: None')
書き込みの例はこんな感じ。変数があってもなくても変わらないですね。
# session_stateに変数があるとき
if 'count' in st.session_state:
st.session_state['count'] += 1
st.write('countをインクリメントしました')
# session_stateに変数がないとき
else:
st.session_state['count'] = 1
st.write('countを初期化しました')
dict型の違う記法を使うとこんな書き方もできます。
# .変数名 でsession_stateに変数を書き込み・読み出しする
# session_stateに変数があるとき
if 'time' in st.session_state:
# timeを5分進める
st.session_state.time += datetime.timedelta(minutes=5)
# session_stateに変数がないとき
else:
# timeを初期化する
st.session_state.time = datetime.datetime.now()
st.write('time:', st.session_state.time)
st.session_stateは画面を操作したときやRerunしたときはそのまま維持されます。
ただし、F5でリロードしたときは初期化されるようです。
ここまでだと簡単なんですが、こんな記事が先日投稿されていました。
このst.session_stateは非常に曲者だなと思いました。
useStateのように状態管理ができるようになる機能ですが、キーを持つsession_stateがインスタンス化された後はcallbackを使用しないと上書きできなかったり、色々ハマった部分でもあります。
どういうことかと言うと、以下のようにボタンやスライダーなどのウィジェットの動作に連動してst.session_stateを更新しようとして、以下のように書くとバグります。
# スライダーを使ってcountの値を表示・操作する
if 'count' not in st.session_state:
# 初期化する
st.session_state['count'] = 0
count = st.session_state['count']
new_count = st.slider(label='count', min_value=0, max_value=10, value=count)
st.session_state['count'] = new_count
# 値を読み直す
count = st.session_state['count']
st.write('count:', str(count))
具体的な対応方法はStreamlitのドキュメントのState managementの「Use Callbacks to update Session State」に記載されています。
ボタンやスライダーなどのウィジェットにはon_changeあるいはon_clickというコールバック関数を設定することができるので、そのコールバック関数の中でst.session_stateを更新すればいいようです。
具体的には以下のように書きます。
# ウィジェットを操作したときのコールバック関数
def on_change_count():
st.session_state.count = st.session_state.my_slider
# デバッグ表示。スライダーを操作してコードが再実行されたときに一番最初に実行される
st.write('count:', st.session_state.count)
# スライダーを使ってcountの値を表示・操作する
if 'count' not in st.session_state:
# 初期化する
st.session_state['count'] = 0
count = st.session_state['count']
new_count = st.slider(label='count', min_value=0, max_value=10, value=count, key='my_slider', on_change=on_change_count)
st.write('count:', str(new_count))
# 値を読み直しても問題ない
st.write('count:', str(st.session_state['count']))
ウィジェットにkeyを指定することで、st.session_stateにそのキーで値が格納されるようになるんですね。
今回は独自定義の変数を更新したかったので、コールバック関数の中でst.session_stateからst.session_stateに値をコピーしています。
Day 26
Day 26は外部のAPIを呼び出してみようという内容です。
サンプルコードで呼び出しているのはBored API…って何?
API仕様はこちら。
「退屈ならこういうアクティビティはどう?」という提案をしてくれるようですが、正直、実用性重視のAPIではなさそう。
「MEVN1 stackでAPIを実装してみたよ」「ついでに、いつでも自由に呼び出していいようにしておいたよ」みたいなノリでしょうか。
APIを呼び出す方法ですが、Streamlit独自のものではありません。requestsを使う一般的な方法ですね。
Streamlitらしいところはパラメータに代入する値としてユーザが要素を操作した結果を取得するところくらいでしょうか。
suggested_activity_url = f'http://www.boredapi.com/api/activity?type={selected_type}'
json_data = requests.get(suggested_activity_url)
suggested_activity = json_data.json()
st.metricというGUIコンポーネントがしれっと初登場しています。
すごくダッシュボード向きな見た目ですね。
st.metric(label='Number of Participants', value=suggested_activity['participants'], delta='')

APIが一般的な方法で呼び出せるということが分かったので、他のAPIで試してみてもよさそうです。例えばOpenAI APIを呼び出せばちょっとしたAIチャットを作れそう。
# チャット風のテキストボックスを表示して入力を取得
prompt = st.chat_input('OpenAIへの質問を入力してください')
if prompt:
# OpenAI APIを呼び出す
response = openai.ChatCompletion.create(
model='gpt-3.5-turbo',
messages=[
{'role': 'user', 'content': prompt},
],
)
# レスポンスからメッセージ本文を切り出す
message_content = response.choices[0]['message']['content'].strip()
# 画面に表示する
with st.chat_message(name="user", avatar="🐤"):
st.write(prompt)
with st.chat_message(name="openai", avatar="🤖"):
st.write(message_content)

Day 27
Day 27はStreamlit Elementsという3rd-Partyコンポーネントを使ってみようという内容です。
ほとんどStreamlit Elementsの説明ですね。
デモサイトはこちら。
Streamlit Elementsはかなり高機能なコンポーネントで、
- マテリアルUI
- ドラッグやサイズ変更できるダッシュボード
- Monaco Editor
- メディアプレイヤー
- Nivo:高機能なチャートライブラリ
- ホットキーやインターバルなどのイベントハンドリング
…などが使えるようです。
Streamlit単体だとUIコンポーネントのレイアウトは細かく調整できませんでしたが、グリッドレイアウトでいい感じにできるように。
# グリッドレイアウト。デフォルトでカラムが12分割される
layout = [
# "editor"はx=0/y=0から幅6/高さ3で置く
dashboard.Item("editor", 0, 0, 6, 3),
# "chart"はx=6/y=0から幅6/高さ3で置く
dashboard.Item("chart", 6, 0, 6, 3),
# "media"はx=0/y=3から幅6/高さ4で置く
dashboard.Item("media", 0, 2, 12, 4),
]
# このレイアウト設定をdashboard.Gridに指定する
# dashboard.Grid(layout, draggableHandle=".draggable")
Streamlit ElementsのサンプルコードはStreamlit標準に慣れていると独特に感じるのですが、次のような流れでUIコンポーネントを配置していくようです。
-
elementsを作成 -
dashboardを作成(or この階層にUIコンポーネントを配置) -
mui.Boxあるいはmui.Cardを複数作成 -
mui.Boxの下にはUIコンポーネントを配置 -
mui.Cardの下にはmui.CardContentを作成 -
mui.CardContentの下にはUIコンポーネントを配置
ただし、Streamlit標準のUIコンポーネントはグリッドレイアウトを無視してページの最上部から配置されてしまうようなので、Streamlit Elementsを活用したダッシュボードを作るときはStreamlit Elementsで準備されているUIコンポーネントだけで頑張る必要がありそうです。
色々なことができそうなんですが、ドキュメントやサンプルコードがまだ十分ではないので、ちょっとハードルが高いかなという印象でした。
Nivoについてもほとんど記載がないのですが、Reactのチャートライブラリだそうです。
サンプルコードで使われているもの以外のグラフを使うためには、まず、ソースコード(Nivo.tsx)で本家におけるコンポーネントとの対応関係を調べて、
次に本家のWebサイトでサンプルコードとサンプルデータを取得して、
それらを手動でPython向けに書き換える必要がありました。
そんなことあるのだろうか…何か自分が間違っているのでは…?という気持ちになりますが、他のやり方は見つけられませんでした。
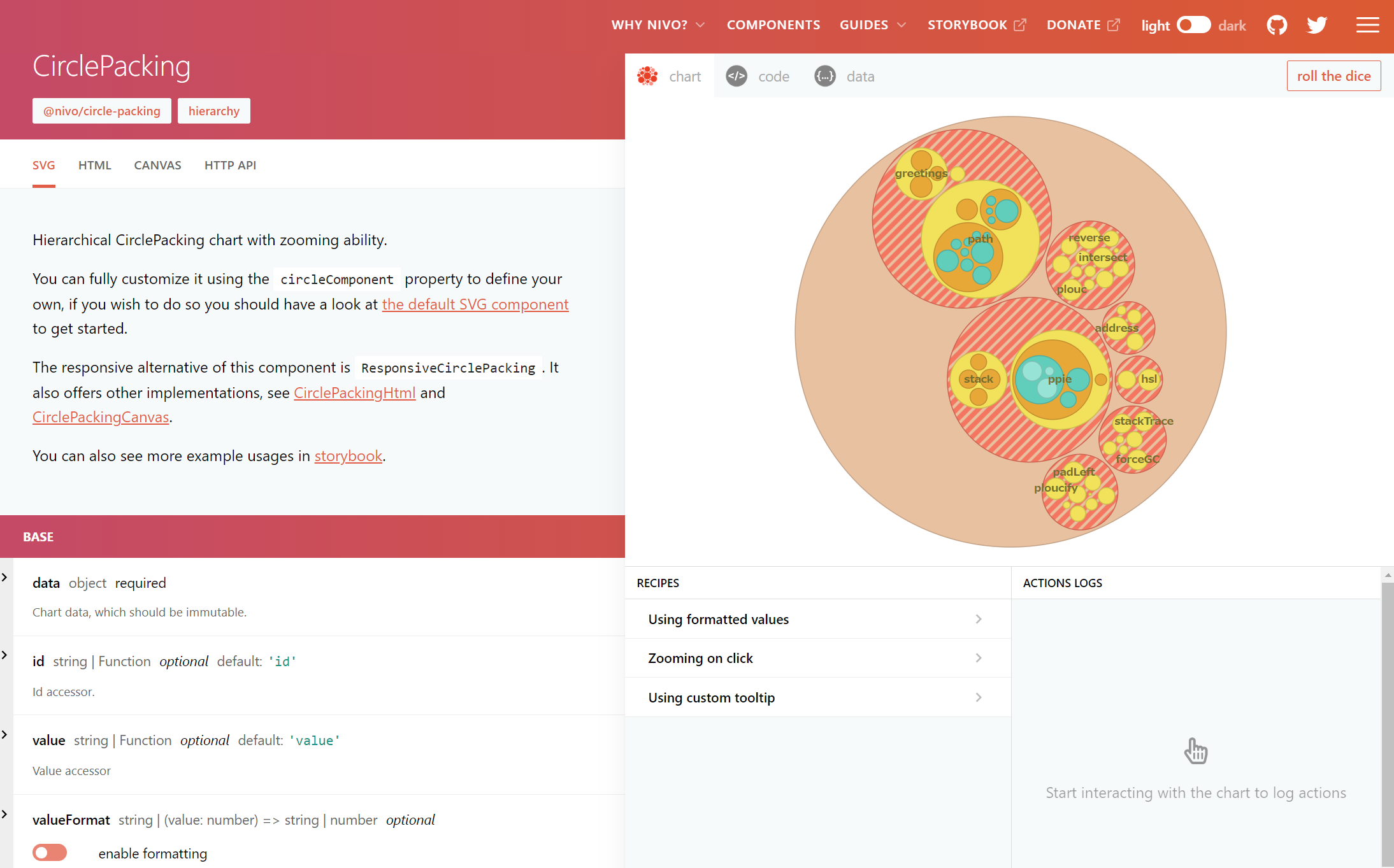
とはいえ、Nivoのグラフ、見た目は綺麗なので何かに使いたい。
追記:
Day 27のサンプルコードを動作させるには、コメントに書いてある通りデータdata.jsonを別途ダウンロードしてくる必要があります。
ダウンロードはNivoのバンプチャートのリファレンスページを開いて、
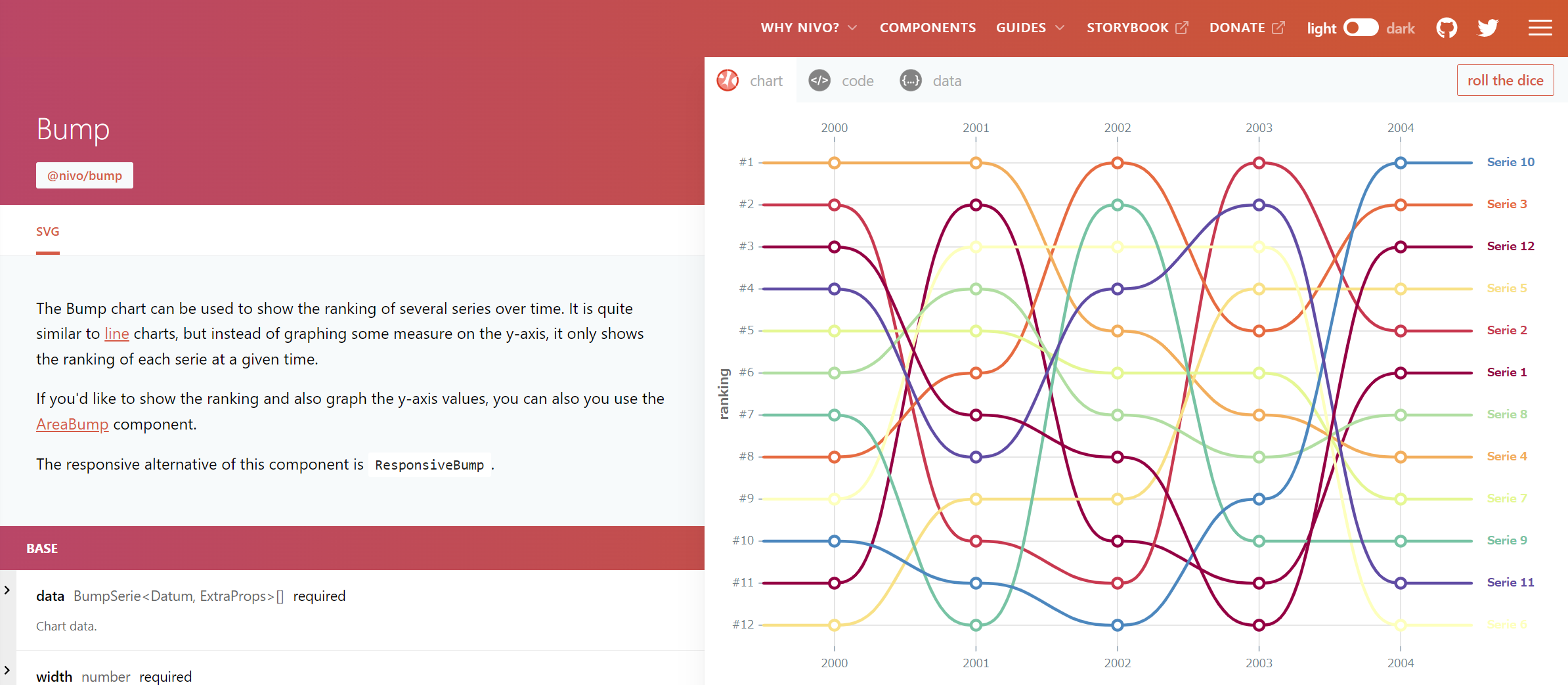
バンプチャート(グラフ)が表示されているところのタブをdataに切り替えると表示されるJSONを手動でコピペしてdata.jsonというファイル名で保存しましょう。

Day 28
Day 28は機械学習モデルのシャープレイ値(SHAP)を確認してみよう、という内容です。
突然難しくなるなあ!
シャープレイ値に関する一般的な解説は30 Days of Streamlitにはないので、以下を参照しました。
まず、開発環境で以下のパッケージを導入する必要があります。
# 機械学習(XGBoost)のパッケージ
pip install xgboost
# シャープレイ値(SHAP)を計算・可視化するパッケージ
pip install streamlit-shap
また、サンプルコードの一部が古い実装になっているため、実行するとワーニングが表示されます。
@st.experimental_memoを@st.cache_dataに修正すればいいようです。
サンプルコードでやっている機械学習はデータサイエンス界隈では一般的な演習課題で、Census Incomeという1996年のアメリカの国勢調査のデータセットを用いて、色々な個人情報から年収が5万ドルを超えるかどうかを予測する…というもののようです。
shap.datasets.adult()でデータセットを取得しています。
この関数の返り値が2つあって、それぞれ、
- x:個人情報
- y:xの各行に対する正解ラベル(5万ドルを超えたのであればTrue)
になっていました。
xの中身は以下のようなものになっています。
| カラム | どういう内容か |
|---|---|
| Age | 年齢 |
| Workclass | 職業・雇用形態。公務員、自営業、民間企業の社員など |
| Education-Num | 教育年数 |
| Marital Status | 婚姻状況。既婚、未婚、離婚など |
| Occupation | 事業領域。運送、漁業など |
| Relationship | 家庭内における位置付け。独身世帯、夫・妻である、子どもであるなど |
| Race | 人種または民族。白人、黒人、アジア系など |
| Sex | 性別。男女の二値になっているようです |
| Capital Gain | おそらく、資産の増加額 |
| Capital Loss | おそらく、資産の減少額 |
| Hours per week | 週の労働時間。1時間や99時間の行がそこそこあるので精度は怪しい |
| Country | 生まれた国または国籍。United-StatesやJapanなど |
なお、shap.datasets.adult()はデフォルトだと各値が機械学習用に数値化されていますが、display引数をTrueにすると各値が元々のラベル(Male、Femaleなど)のままになります。
このデータを用いて、XGBoostでモデルをトレーニングします。
細かいところはよく分からないですがXGBoostをシンプルに使っているだけみたいですね。
@st.cache_data
def load_model(x, y):
# データをトレーニング用とテスト用に分割する
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.2, random_state=7)
# データをXGBoost向けに型変換する
d_train = xgboost.DMatrix(x_train, label=y_train)
d_test = xgboost.DMatrix(x_test, label=y_test)
# XGBoostのパラメータを設定
params = {
"eta": 0.01,
"objective": "binary:logistic",
"subsample": 0.5,
"base_score": np.mean(y_train),
"eval_metric": "logloss",
"n_jobs": -1,
}
# XGBoostでモデルをトレーニングします
model = xgboost.train(params, d_train, 10, evals = [(d_test, "test")], verbose_eval=100, early_stopping_rounds=20)
# モデルを返す。このモデルを使うと予測(分類)ができる
return model
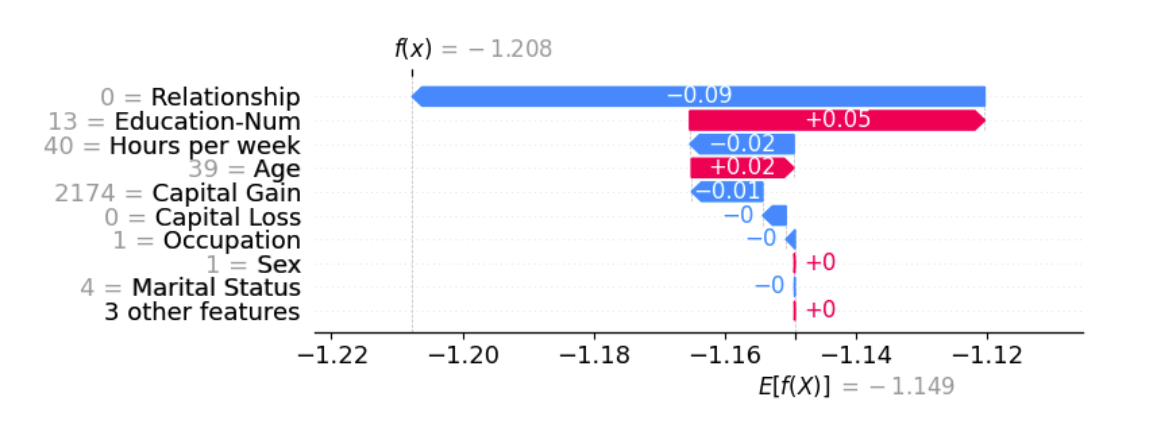
シャープレイ値の確認は以下の通り。
SHAPそのものは簡単に使えるけど、出力するグラフはちょっと複雑なので、Streamlitで表示しようとすると3rd-Partyコンポーネントが必要になる、ということですね。
# シャープレイ値を計算する
explainer = shap.Explainer(model, X)
shap_values = explainer(X)
# SHAPのAPIでプロットして、streamlit_shapで表示する
waterfall_plot = shap.plots.waterfall(shap_values[0])
streamlit_shap.st_shap(waterfall_plot, height=300)
無事に表示されました!
Day 27までの内容よりかなり実行時間を要するので(数十秒かかるかも)、使いどころを考える必要がありますね。
Day 29
Day 29はゼロショット学習を用いてテキストを分類するアプリです。
ゼロショット学習(Zero-shot learning)とは、AIが訓練中に見ていないものでも上手く分類や予測できるようにする機械学習のアプローチだそうです。
例えば猫や犬の画像をたくさん覚えさせたAIに馬の画像を分類させたときに、猫でも犬でもないと分類してくれるようなイメージだそうです。
Few-shot learningと呼ばれるものもあり、これはいくつかのサンプルをAIに見せてあげることで精度よく指示してあげることで提示することで高い精度で分類や予測できるようにする機械学習のアプローチだそうです。
技術的に同一なのかは分からないですが、プロンプトエンジニアリングでよくやる「例えばこういう風にしてください」という指示を出す方法とイメージが近いですね。
Day 29では機械学習そのものは自分で行わず、Hugging Faceで公開されているモデルをAPI経由で利用することでゼロショット学習をアプリに組み込んでいきます。
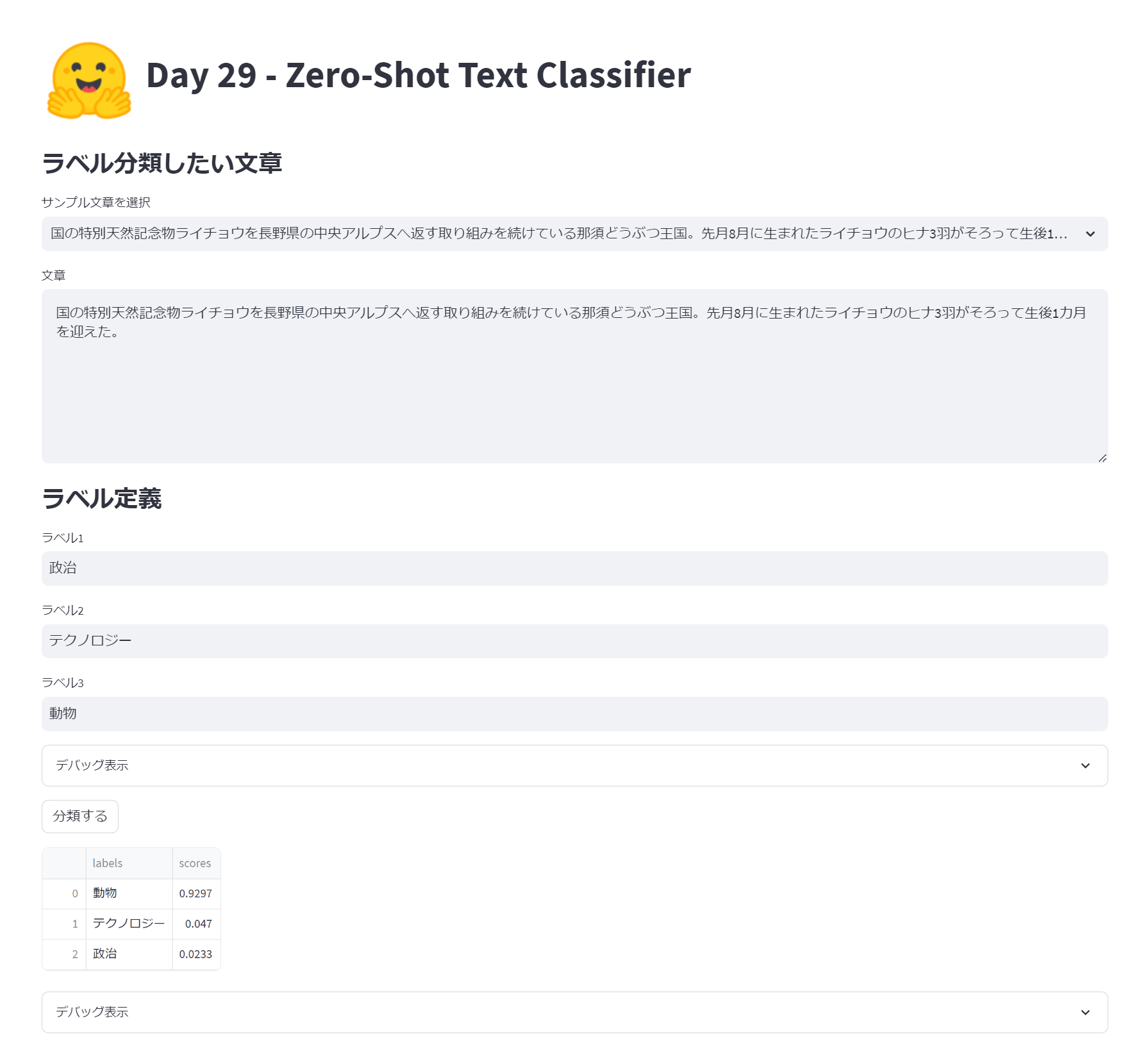
具体的には、入力した文章がどういう話題についての文章なのかをラベル付けする、というものになっています。
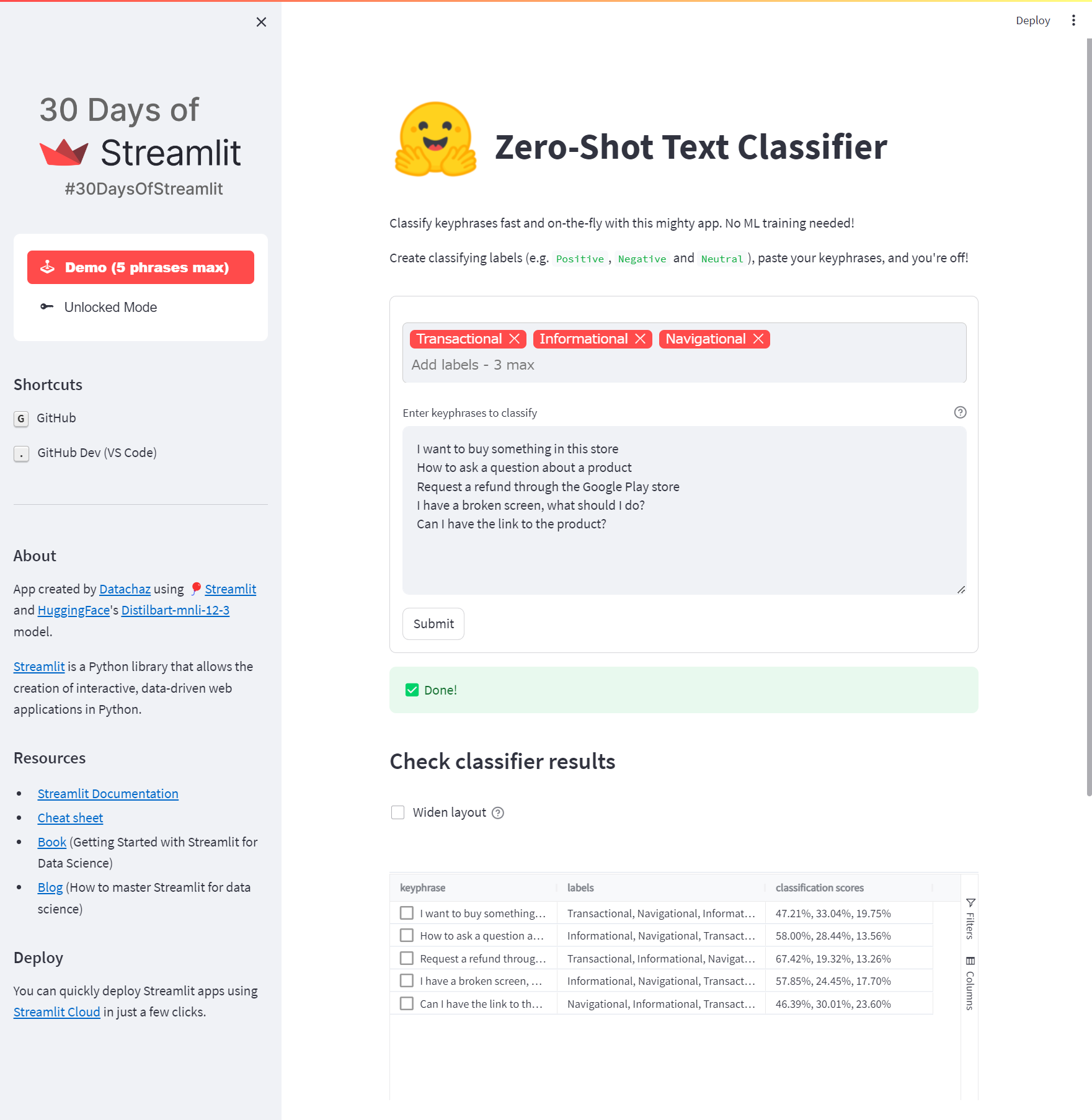
Day 29はこれまでと違って外部のブログを読みながらの演習なのでいくつかハマリポイントがあります。
- Hugging Faceへのアカウント登録とAPIキーの取得
- 実行してみるとパッケージが足りない
- 実行してみるとファイルが足りない
Day 29の補足:Hugging Faceへのアカウント登録とAPIキーの取得
Hugging Faceにアカウント登録してログインしたら以下の手順でAPIキー(Access Token)を取得できます。
まず右上のアイコンからSettingsを選択します。

次にAccess Tokensを開いて、``````をクリックします。
適当な名前を入力してGenerate a tokenをクリックすればAPIキーを生成できます。Roleはreadを選択しましょう。

生成したAPIキーは黒丸で隠されていますが、テキストボックス右端のアイコンからクリップボードにコピーすることができます。

クリップボードにコピーしたAPIキーは.streamlit/secrets.toml(先頭にドットが付いた.streamlitディレクトリを作成してその中にsecrets.tomlを配置する)に書いておきましょう。
API_KEY = "hf_で始まるAPIキーをここにコピペする"
ちなみに、APIキーがおかしいと実行中に以下のようなエラーが発生します。
ValueError: If using all scalar values, you must pass an index
Day 29の補足:実行してみるとパッケージが足りない
3rd-Partyコンポーネントを含むいくつかのパッケージを事前に導入しておく必要があります。
ブログではコマンドが途中で改行されているので分かりづらいのですが、streamlit-tagsとstreamlit-aggridも導入する必要があります。
streamlitは既に導入されているので、以下のようなコマンドを実行することになります。
pip install streamlit-option-menu requests streamlit-tags streamlit-aggrid
Day 29の補足:実行してみるとファイルが足りない
多くの場合はブログの解説を読みながらGitHubで公開されているstreamlit_app.pyを書き写すのですが、これだけだとファイルが不足しています。
ファイルが不足していると例えば以下のようなエラーが発生します。
MediaFileStorageError: Error opening 'logo.png'
これを解決するために一番手っ取り早い方法は、streamlit_app.pyだけではなくGitHubからプロジェクトを丸ごとコピーすることです。
<> Codeボタンからプロジェクトをダウンロードしましょう。

GitHubに慣れているプログラマだと自然とそうするような気がするのですが、プログラミング初心者だとここまでコツコツ写経してきたこともあってそういう発想にならないのでハマリがちです。
プロジェクトを丸ごとコピーしない場合は、以下のファイルをダウンロードしてstreamlit_app.pyと同じディレクトリに配置する必要があります。
logo.png30days_logo.png-
dashboard_utils/gui.py(dashboard_utilsディレクトリを作成してその中にgui.pyを配置する)
Day 29の補足:日本語の文章で試してみたい
Day 29のサンプルコードではDistilBart-MNLIというモデルを利用しています。
このモデルは日本語に対応していないので、日本語の文章だと上手く分類してくれません。その結果、この文章はそのラベルじゃないのでは?みたいな出力になります。
多言語対応のモデルとしてmDeBERTa-v3-base-xnli-multilingual-nli-2mil7が使えるということなので、モデルをこれに差し替える(APIを書き換える)と日本語の文章でも上手く分類してくれるようになります。
参考:教師なしで日本語文章を分類するZero-shot Classificationを試す🤗
モデルを差し替えたり処理の流れをシンプルにしたりしたサンプルコードを用意しました。参考にしてください。
Day 30
Day 30はYouTubeのサムネイル画像を表示するアプリです。
技術的な解説ではなく「実現したい機能があるときにどうするのか?」という考え方の解説になっています。
YouTubeのサムネイル画像を表示すること自体は力業で実現しています。
# ユーザが指定した動画のURLからビデオIDを取得して、サムネイル画像のURLを生成する
yt_img = f'http://img.youtube.com/vi/{ytid}/{img_quality}.jpg'
st.image(yt_img)
「YouTubeのサムネイル画像を表示する」というアプリを実現するために、
- サムネイル画像はビデオIDが分かっていればURLを生成できる
- どの動画のサムネイル画像を表示するのかはユーザに動画のURLを入力をさせればいい
- ビデオIDは動画のURLから取得することができる
というように設計・実装に落とし込んでいけばいい、というデモンストレーションになっています。
30 Days of Streamlitのコンテンツには含まれていませんが、例えば「対話型AIにデータ検索をしてもらう」というアプリを実現したいのであれば、
- データベースからデータの詳細な情報(スキーマ)を取得する
- 対話型AIにデータの詳細な情報を渡す
- ユーザに自然言語でデータ検索リクエストを入力してもらう
- 対話型AIにデータ検索リクエストに対応したSQL文を生成させる
- 正しいSQL文が生成されたらデータベースで実行する
というように設計・実装すれば実現できそうですね。
感想
以上で30 Days of Streamlitを完走です!
私は有志が毎週末に集まる勉強会の中でコツコツ進めて3ヵ月くらいで完走しました。
30 Days of Streamlitの記載は色々と分かりにくいところもあるのですが(特にプログラミング初心者には…)、Streamlitの手軽さやAI/MLとのシナジーはかなり感じることができました。
機能面では公式ドキュメントがそれなりに充実しており、またデザイン面やアイディア面ではたくさんの人がStreamlitを使ったアプリを公開しているので、それらを参照していけばさらにレベルアップできそうだと感じました。
2023年9月現在、データクラウド(SaaS型データプラットフォーム)のSnowflakeがStreamlitを買収して、Snowflake上でStreamlitを使えるようになっています。これはSnowflake内のデータに対してプログラマブルにアクセスするI/Fとしてかなり使えそうです!
Streamlitはますます面白くなっていますのでぜひ30 Days of Streamlitにチャレンジしてみてください。
参考:About Streamlit in Snowflake
-
MongoDB+Express+Vue.js+Node.js ↩