前置き
日本語文章の分類といえば教師あり学習が代表的ですが、大量の教師データをどうやって集める/作成するのかが大きな障害となってしまうことが現場ではよくあります。
そんなときは半教師あり学習やクラスタリングを試してみたり、Snorkelを試してみたり社内メンバー総出でラベル付けしたり最悪クラウドソーシングでの正解データ作成も選択肢に入ることもあると思いますが、今回はそれらをすべて使うことなくGoogle Colabでも実行可能な教師なし分類の手法をご紹介いたします。
使う技術やデータ
今回使う技術およびデータは以下です:
- Python
- Google Colab
- Huggingface
- Zero-shot Classification用のモデル: https://huggingface.co/MoritzLaurer/mDeBERTa-v3-base-xnli-multilingual-nli-2mil7
- 分類対象のデータ: ライブドアニュースコーパス(https://www.rondhuit.com/download.html#ldcc)
Zero-shot classificationとは
Zero-shot classificationとは、分類ラベル付きのデータでモデルを訓練することなくデータを分類することです。なぜそんなことが可能かというと、今回使用するモデルが自然言語推論(Neural Language Inference, NLI)タスクで訓練されたモデルであり、そのモデルを使うことで例えば「今日、Appleから新しいiPhoneが発売されました」という前提(Premise)に対して「この例文はスマートフォンに関連する文章です」のような仮説(Hypothesis)が正しいかどうかを判断でき、その結果として前提の文章がスマートフォンのカテゴリに分類できるようになります。
巷にあふれているモデルはだいたい英語とかフランス語などのメジャーな言語でしか利用できませんが、上記のモデルは日本語データ(機械翻訳)を含むNLI用のデータセットで訓練されており日本語の文章もゼロショットで分類できるため、今回はこのモデルを使ってライブドアのニュースを分類してみることにします。
簡単な実行コード
とりあえずGoogle Colabですぐ動かせるコードは以下です:
!pip install -q sentencepiece
!pip install -q transformers
import torch
from transformers import pipeline
model_name = "MoritzLaurer/mDeBERTa-v3-base-xnli-multilingual-nli-2mil7"
device = 0 if torch.cuda.is_available() else -1
classifier = pipeline("zero-shot-classification",model=model_name, device=device)
texts = ["今日、新しいiPhoneが発売されました"]
labels = ["スマートフォン", "エンタメ", "スポーツ"]
classifier(texts, labels, hypothesis_template="このニュースは{}に関する文章です.")# 出力:
[{'sequence': '今日、新しいiPhoneが発売されました',
'labels': ['スマートフォン', 'エンタメ', 'スポーツ'],
'scores': [0.9712117910385132, 0.02308950014412403, 0.005698721390217543]}]この例では、分類クラスを["スマートフォン", "エンタメ", "スポーツ"]の3つに設定したときの各クラスの分類確率が出力されています。スマートフォンの確率が一番高く97%となっており、エンタメは2%、スポーツは1%以下になりました。
もちろん分類クラスは任意で設定できるため、たとえば以下のように変えることもでき、それに合わせて出力も変化します:
# クラス定義:
labels = ["Android", "iPhone", "エンタメ", "スポーツ"]# 出力:
[{'sequence': '今日、新しいiPhoneが発売されました',
'labels': ['iPhone', 'エンタメ', 'Android', 'スポーツ'],
'scores': [0.9865162372589111,
0.007182396948337555,
0.004528564400970936,
0.0017726878868415952]}]期待通り、iPhoneクラスの確率が最も高くなりました。
ライブドアニュースの分類
それでは、同じような要領でライブドアニュースの分類をやってみましょう。
ライブドアニュースデータセットには複数のカテゴリがあり、今回は比較的分類しやすそうな次の4カテゴリについて分類を試みることにします:kaden-channel(家電), smax(スマホ), sports-watch(スポーツ), movie-enter(エンタメ)
クラス定義は以下のようにしてみました。
# クラス定義:
labels = ["家電製品", "スマホもしくはスマートフォン", "スポーツ", "エンタメ"]この定義で各カテゴリのニュース記事を100件ずつ予測させてみたところ、正解率と混同行列は以下のようになりました:
smax : 0.47
kaden-channel : 0.6
movie-enter : 0.95
sports-watch : 0.96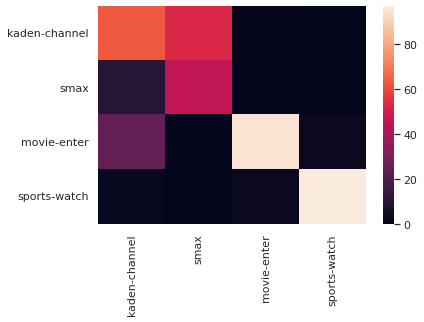
スポーツとエンタメについては素晴らしい結果になっていますが、スマホと家電がなにか様子がおかしいです。どうやらスマホが家電と認識されているようです。
分類に失敗したデータの中身を覗いてみることにしましょう。
スマホカテゴリの記事なのに家電に誤分類されてしまった例
AQUOS PHONE st SH-07Dにソフトウェア更新!
NTTドコモは8日、音楽再生機能をフューチャーした3.4インチサイズのコンパクトなAndroid 4.0(開発コード名:IceCream Sandwich;ICS )搭載防水スマートフォン「AQUOS PHONE st SH-07D」(シャープ製)においてブラウザを長時間利用するとまれに強制終了する不具合などが見つかったとしてネットワーク経由による本体ファームウェアアップデートサービス「ソフトウェア更新」を提供開始したことをお知らせしています。
今回のソフトウェア更新で修正される事象は以下の2点です。AQUOS PHONE st SH-07Dのソフトウェア更新は今回が2回目で、更新にかかる時間は約9分、更新期間は2015年8月31日まで。どう見てもスマホの記事ですが、家電に分類されてしまっています。他にも似たような例があるため、どうやらモデル的にはスマホは家電に含まれる、という認識のようです。
そこで定義を以下のように変更して試してみました:
家電とスマホを分離してみた
クラス定義を変えてみて再度実行してみたところ、以下のような結果になりました:
# クラス定義:
labels = ["スマートフォン以外の家電製品", "スマートフォン", "スポーツ", "エンタメ"]# 結果
smax : 0.8200000000000001
kaden-channel : 0.30000000000000004
movie-enter : 0.92
sports-watch : 0.96
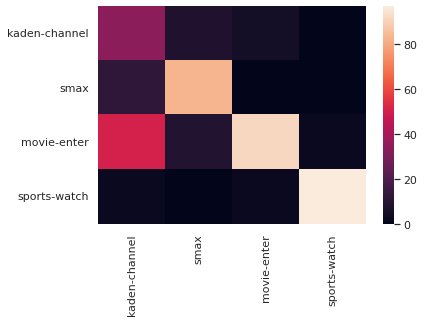
スマホはいくらか改善しましたが、家電がエンタメとうまく区別できなくなってしまったようです。
エンタメをもっと詳細に定義することで対応してみます。
エンタメをもっと細分化してみた
映画以降はすべてエンタメカテゴリ、という想定です:
# クラス定義:
labels = ["スマートフォン以外の家電製品", "スマートフォン", "スポーツ", "映画", "ヒーロー", "漫画やコミック", "アニメ", "ドラマ", "芸能"]
# 結果
smax : 0.85
kaden-channel : 0.6
movie-enter : 0.9
sports-watch : 0.94
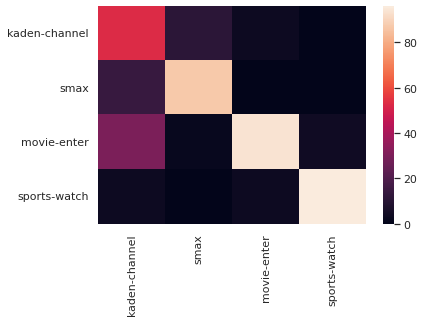
かなり良化しましたが家電がまだエンタメとスマホに誤分類されがちみたいなのでさらに調査してみます。
家電カテゴリの誤分類調査
# エンタメと誤分類された例 その1
単身や夫婦2人だけの家庭が増えていることから、パナソニックはライフスタイルに合わせたコンパクトサイズの「卓上型食器洗い機 プチ食洗」3種と、ムダを省いて自動で節電・節水する「ドラム型洗濯乾燥機 プチドラム」2種を発表した。発表会には、キャンペーンキャラクターを務める歌手の土屋アンナさんが登場した。「プチ食洗」は、コンパクトサイズを求める市場に応え体積が従来品と比べ約40%も小さくなっている。キッチンに調和しやすく圧迫感の感じにくいデザインだ。
また、「プチドラム」は洗濯から乾燥時のムダを省く「エコナビ」を新たに搭載している。衣類の量や水分の抜けやすさを検知して適切なプログラムを設定、これによ# エンタメと誤分類された例 その2
ニッケル水素電池『充電式EVOLTA(エボルタ)』に人気アニメ「ワンピース」の主人公が登場する。「ワンピース バージョン」は11月21日から発売開始だ。水素電池「充電式エボルタ」は、2008年10月の発売以来、環境意識の高まりからか販売が好評で今年度おn販売台数も前年比 約15%増が見込まれている。今回のコラボレーションは複数のキャラクターが夢に向かって成長していく「ワンピース」のストーリーと、充電式エボルタの「進化し続ける電池」というコンセプトが共通するということから実現した。
登場するキャラクターは「ルフィ」と「チョッパー」でそれぞれキリッとした表情の「シリアスバージョン」と笑顔全開の「その1 は明らかに家電の記事ですが、キャンペーン内容の影響かエンタメと判定されてしまっています。
その2 は電池に関する記事なので家電に分類されてもおかしくないですが、エンタメ要素が強いためエンタメに分類されてしまったようです。
# エンタメと誤分類された例 その3
ニューヨーク・マンハッタンのアッパー・イーストサイドを舞台に、“ヤング・セレブ”たちの過激な恋愛とドラマティックな人間関係を描く、大人気海外ドラマ「ゴシップガール」。そのゴシップガールがHuluにて一挙公開になることがわかった。
スキャンダルな内容だけではなく、登場人物のファッションにも注目が集まり、中でもセリーナ役のブレイク・ライブリー、ブレア役のレイトン・ミースターは旬なおしゃれセレブとして大ブレイクしている。
ゴシップガールのシーズン 1〜3 は2012 年 7 月 15 日(日)より “史上初”の一挙配信が行われる。
Hulu コンテンツ&アライアンス本部長 長澤一史氏は「『ゴ# エンタメと誤分類された例 その4
CMを見て、クイズに答えて、ポイントを貯めるスマートフォンアプリ「AD Latte(アドラッテ)」。貯めたポイントはAmazonやスターバックス、iTunesのギフトカードに交換したり、寄付や換金を行うこともできる。
このアプリのWebCMにキャラクターとして起用されたのがお笑い芸人のダンディ坂野だ。起用の理由は「明るく、親しみやすい」彼のキャラクターがアドラッテの目指す方向と近いからだというが、その他に「イメージカラーが黄色だから」というものもあるらしい。確かに、アドラッテのカラーもダンディ坂野の衣装も黄色だ。色が同じということでの起用というのは、なかなかおもしろい。
また、今回のキャラクその3 は明らかにエンタメ的な内容なので、元のカテゴリ分類よりもモデルの出力のほうが正しいと言えます。
その4 はスマートフォンもしくはエンタメ要素が強く、少なくとも家電の記事ではなさそうです。
# スマホと誤分類された例 その1
携帯ショップを見てみると、スマートフォンの数が圧倒的に多い。だが、スマートフォンの普及の陰で、従来型の携帯電話も根強い人気を誇っているという。どうやら、一度はスマートフォンに機種変更したものの「メールが打ちにくい」「こんなに多くの機能はいらない」と従来の携帯電話に戻ってくる人が多いということだ。
たしかに、猫も杓子もスマートフォンという風潮ではあるが、誰にでも便利というわけではないようだ。今までは携帯電話を見ることもなくメールが打てたという人もスマートフォンではそうはいかない。
あなたの周りにもスマートフォンに機種変更してがっかりした人は意外に多いのかもしれない。# スマホと誤分類された例 その2
発売以来、世界中にファンを持つiPhone。海外で、iPhone4Sを購入してどうだったか、というアンケートが実施され購入者のおよそ20%がその購入を後悔していることがわかった。では、いったいどういった点を後悔しているのだろうか。
後悔していると答えた20%のうち43%が「他社のスマートフォンにしておけばよかった」と回答。数多く発売されているアンドロイドに魅力を感じているということだ。そのほかには25%がバッテリーがすぐなくなる問題に不満を抱えていた。
多くのスマートフォンが登場する中で、iPhoneを意識した機種はもちろん多い。iPhone4Sのユーザーにとっても気になっているようだ。# スマホと誤分類された例 その3
ご近所お願い解決アプリと呼ばれる「WishScope」を展開しているザワット株式会社がおもしろいイベントを企画している。7月15日に開催されるスマートフォン開発者向けのハッカソンイベント「第1回ハッカー道場」だ。
このイベントは1日かけて行われ「座学」「実践」「演武」の3つのパートに分かれている。まず、ザワット株式会社をはじめ、イベントに賛同している株式会社エヌプラス及び株式会社VOYAGE GROUPが座学のパートで講義を行い、その後参加者は5時間のハッカソンに挑戦する。そして最後に演武のパートで参加者が賞品を賭けてプレゼンテーションを行うというものだ。
イベントの企画をしたザワット株# スマホと誤分類された例 その4
発売以来、世界中にファンを持つiPhone。海外で、iPhone4Sを購入してどうだったか、というアンケートが実施され購入者のおよそ20%がその購入を後悔していることがわかった。では、いったいどういった点を後悔しているのだろうか。
後悔していると答えた20%のうち43%が「他社のスマートフォンにしておけばよかった」と回答。数多く発売されているアンドロイドに魅力を感じているということだ。そのほかには25%がバッテリーがすぐなくなる問題に不満を抱えていた。
多くのスマートフォンが登場する中で、iPhoneを意識した機種はもちろん多い。iPhone4Sのユーザーにとっても気になっているようだ。これらは家電よりもスマホに分類したほうが良さそうな記事で、内容的にはデータセットの正解よりもモデルの出力のほうが正しいように思えます。
上記以外の誤分類を調べてみてもスマホ要素やエンタメ要素の方が強い記事が多く、そもそも家電カテゴリには「家電製品」についての記事だけが集まっているわけではないようで、内容的にはモデル出力のほうが正しいとも言え、見た目の正解率以上の性能がこのモデルにはありそうです。
まとめ
以上、簡単にですが日本語文章の Zero-shot clasification についてご紹介しました。
クラス定義を工夫する必要があるものの、分類ラベル付きデータで訓練することなく日本語文章を分類することができました。
機械翻訳されたデータセットで訓練したモデルでもこのくらいの性能が出せるというのは私としてはなかなか驚きで、このやり方で正解のないデータセットに正解をつけて「生徒モデル」の学習に利用することもできそうです。Distillationみたいですね。
ちなみに実行速度は文章の長さにもよりますが Google Colab(GPU) では1件あたりだいたい1~数秒くらいでした。1日回し続けて数万件のデータを作れる計算になり、現実的な予算と時間で生徒モデルの訓練に必要な量のデータを集めることができそうです。
では簡単ですがこのあたりで🤗