全体の目的
Talendの超簡単なサンプルジョブを作成して,ETLジョブ開発に必要なスキルを習得することが目的です。
対象者
ETL / EAI技術者
環境
| 使用環境 | バージョン |
|---|---|
| OS | Windows10 |
| Talend | 7.1.1 |
| PostgreSQL | 9.6 |
サンプル一覧
以下の順番で習得していきます
| # | 内容 |
|---|---|
| 1 | はじめてのTalend |
| 2 | ファイルI/O |
| 3 | データベースI/O |
| 4 | tMap |
| 5 | イテレータ |
| 6 | メタデータ(今回) |
| 7 | Context変数 |
| 8 | Global Map |
| 9 | tHashInput/tHashOutput |
| 10 | エラーハンドリング |
| 11 | ロギング |
| 12 | 子ジョブ(ジョブのネスト) |
| 13-1 | 設定ファイル読み込みオリジナル版 |
| 13-2 | 設定ファイル読み込みコンポ版 |
| 14 | tJava |
今回の目的
メタデータについて理解する。
メタデータとは
- 入出力情報の一元管理ができるもの
- 同一プロジェクト内の複数ジョブで利用できる
- 開発効率を上げることができる
メタデータの種類は大きく3種類
| # | 種類 | 対象 |
|---|---|---|
| 1 | DB関連 | DB接続定義 |
| 2 | File関連 | 区切り記号付きファイル、固定長ファイル等 |
| 3 | その他 | LDAP, Salesforce, FTP等 |
サンプルプログラム概要
メタデータを使ったファイルおよびDBの入出力ジョブを作ってみます。
メタデータを利用したジョブ
それではサンプルジョブを作成していきましょう。
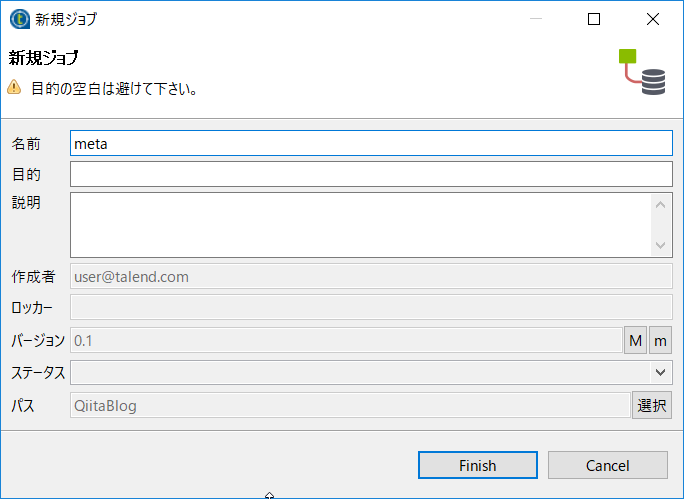
リポジトリの[ジョブ]を右クリックし[ジョブの作成]を選択します。
[名前]にmetaと入力し[Finish]ボタンをクリックします。
入力ソース作成
in.csvというファイルを作成します。
※Talend入門 (2) ~ファイルI/O~と同じものです。
C:\work\meta配下に作成しました。
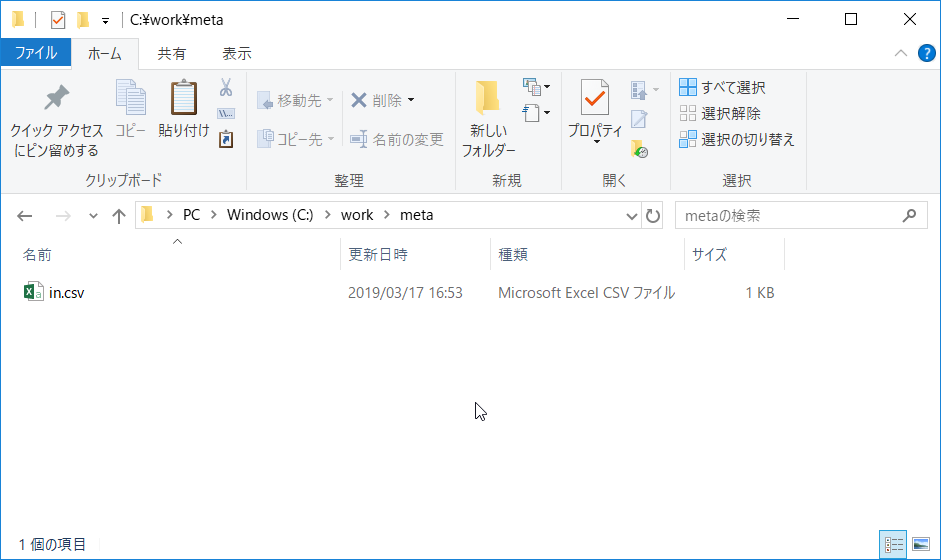
- エンコードはシフトJIS
- 改行コードはLF
id,name,gender
1,kouda,男
2,mori,男
3,kubo,男
4,shimizu,男
5,aya,女
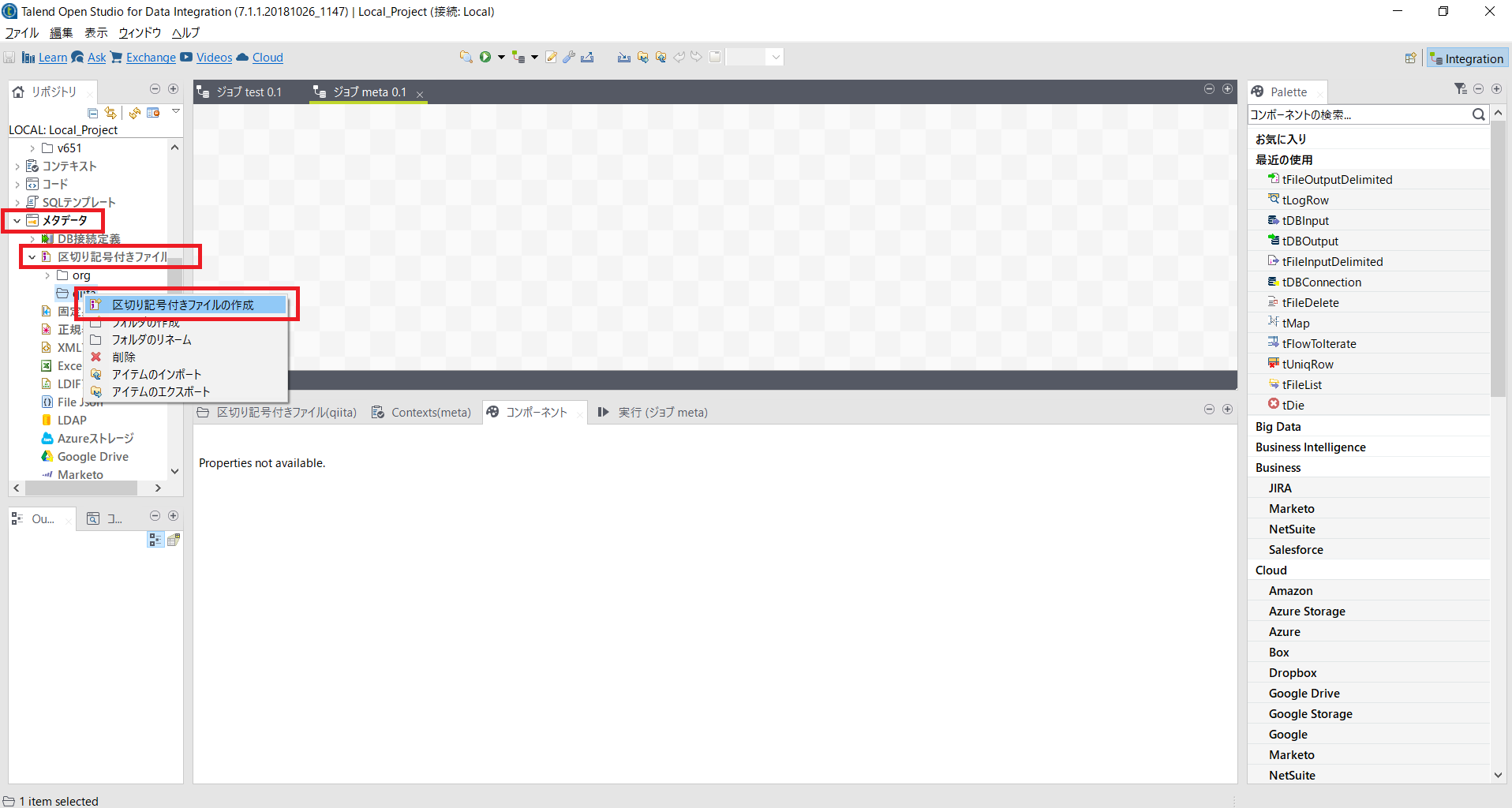
File系メタデータの作成
リポジトリの[メタデータ]にある[区切り記号付きファイル]で右クリックし[区切り記号付きファイルの作成]を選択します。
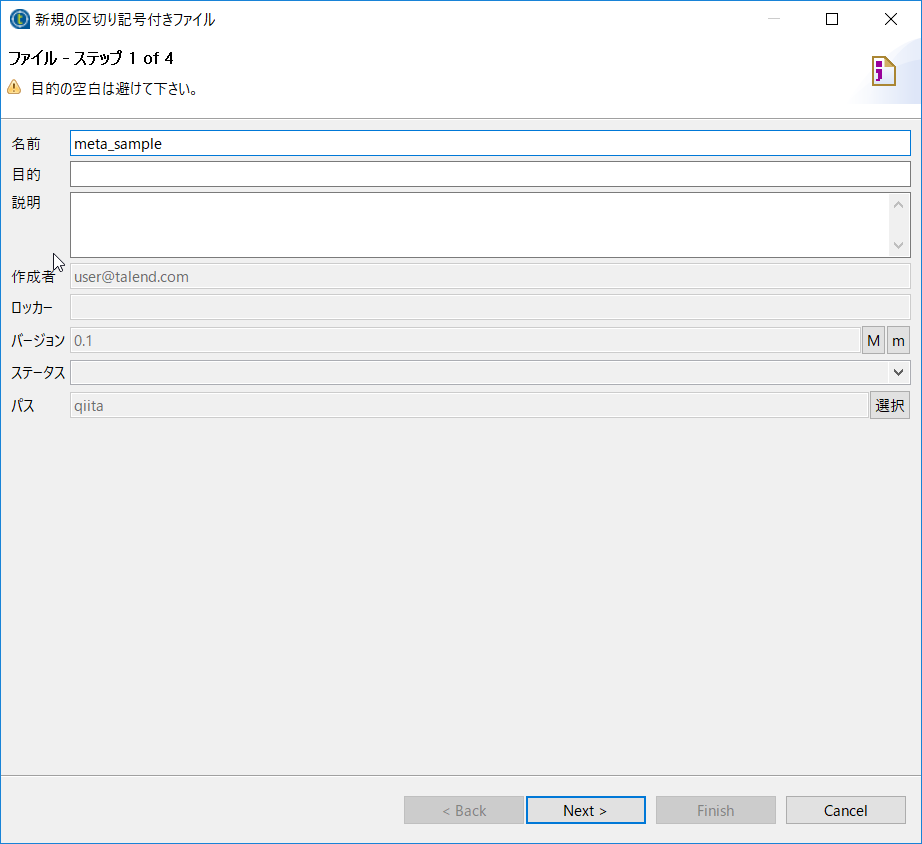
meta_sampleという名前を付けておき、[Next]をクリックします。
ファイルと形式を設定し[Next]をクリックします。
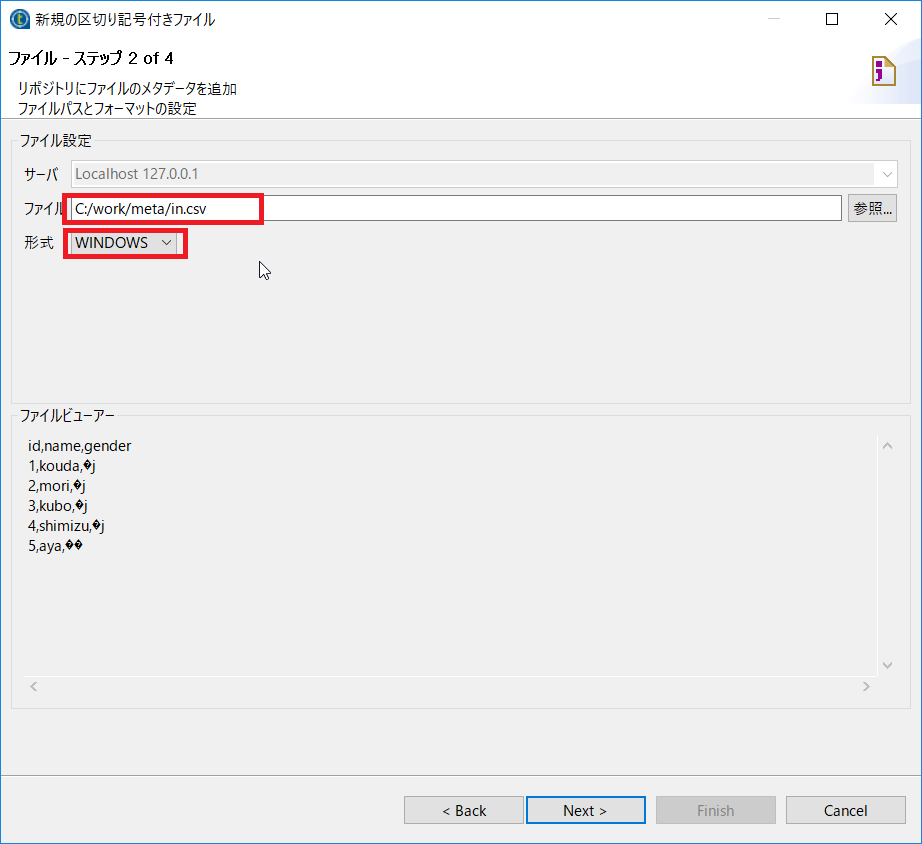
| 項目名 | 設定内容 | 説明 |
|---|---|---|
| ファイル | C:/work/meta/in.csv | 入力ソースを指定 |
| 形式 | WINDOWS |
ステップ3では赤字のパラメータを設定します。[プレビューの更新]をクリックし正しく取得できていることを確認します。
正しく表示されたなら[Next]をクリックし次に進みます。
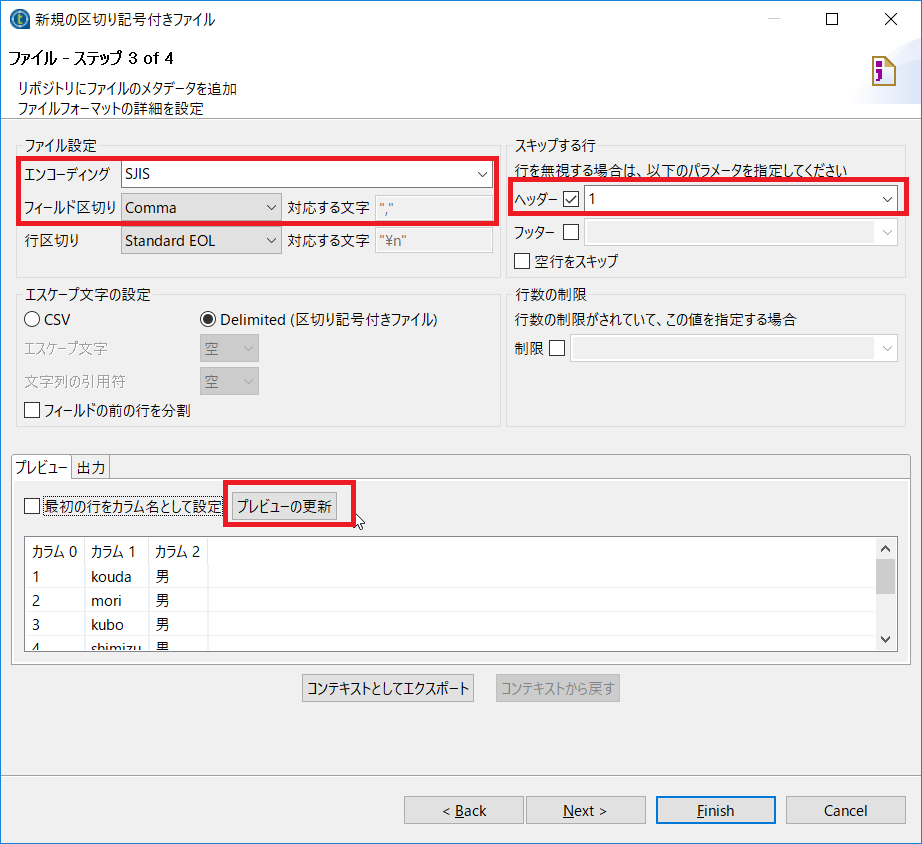
| 項目名 | 設定内容 | 説明 |
|---|---|---|
| エンコーディング | SJIS | |
| フィールド区切り | Comma | |
| ヘッダー | チェックを入れて1 | 先頭行はヘッダということ |
ステップ4では名前とカラム名を定義しておきましょう。
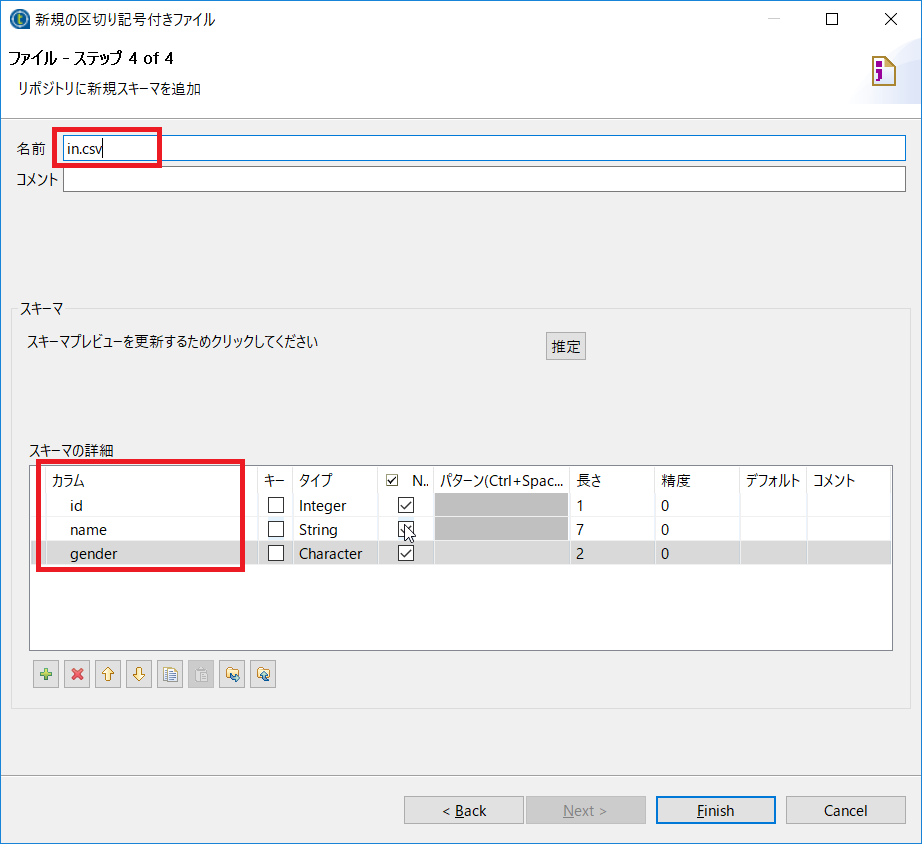
| 項目名 | 設定内容 | 説明 |
|---|---|---|
| 名前 | in.csv | 分かりやすいものにしておく |
| カラム | id,name,gender | それぞれを更新 |
これで今回のcsv用メタデータがリポジトリに作成できました。
DB系メタデータの作成
リポジトリの[メタデータ]にある[DB接続定義]で右クリックし[接続定義]を選択します。
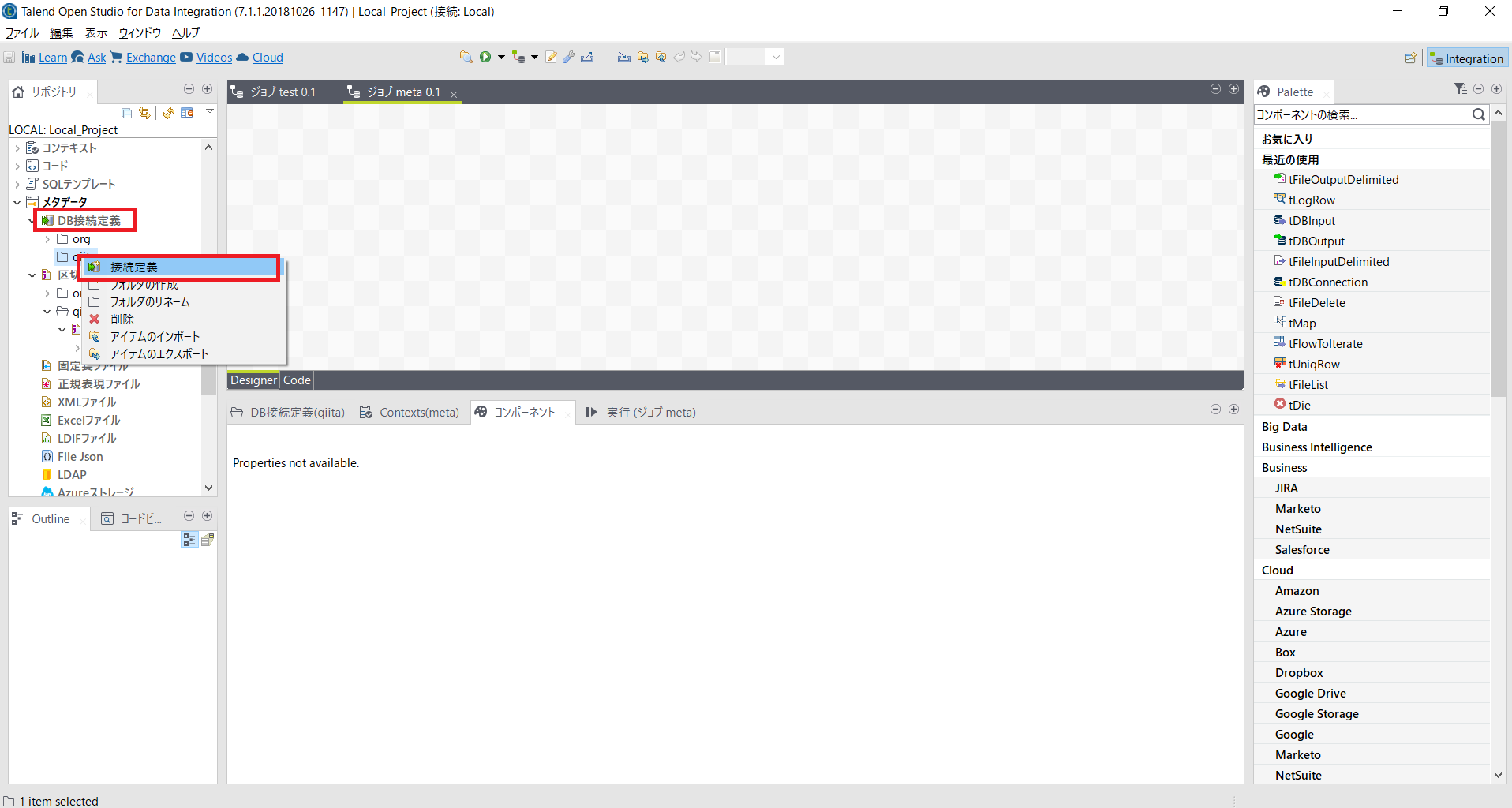
meta_sampleという名前を付けておき、[Next]をクリックします。
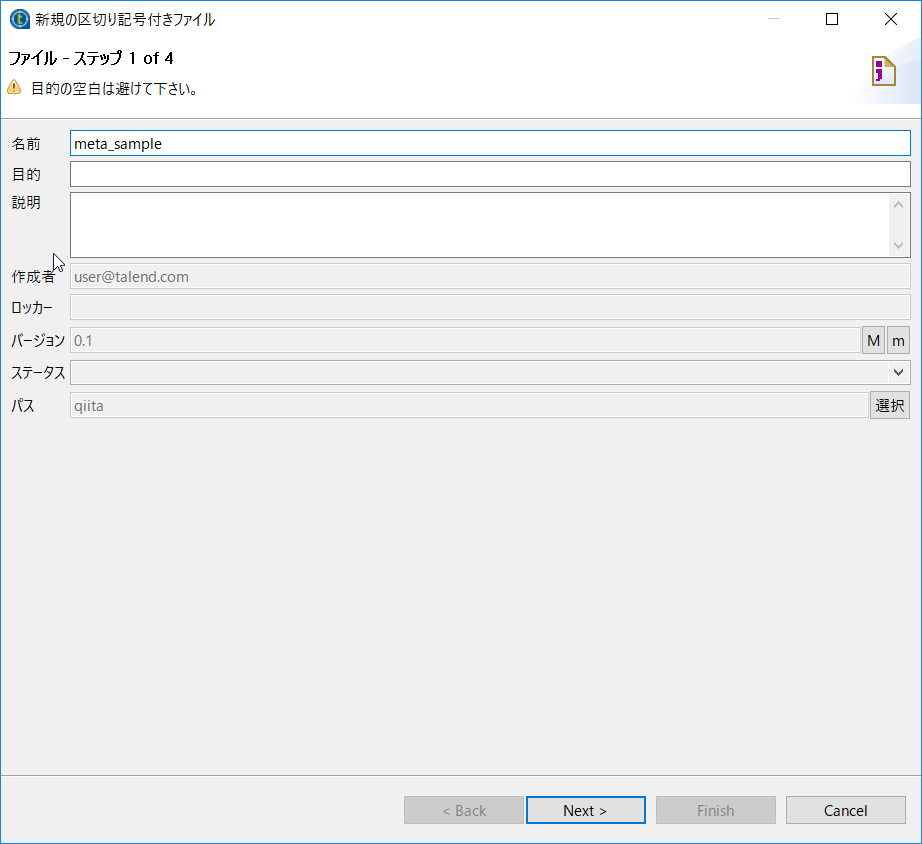
DB接続用のパラメータを設定します。
※今回はTalend入門 (3) ~ データベースI/O~で使ったDBを流用しています。
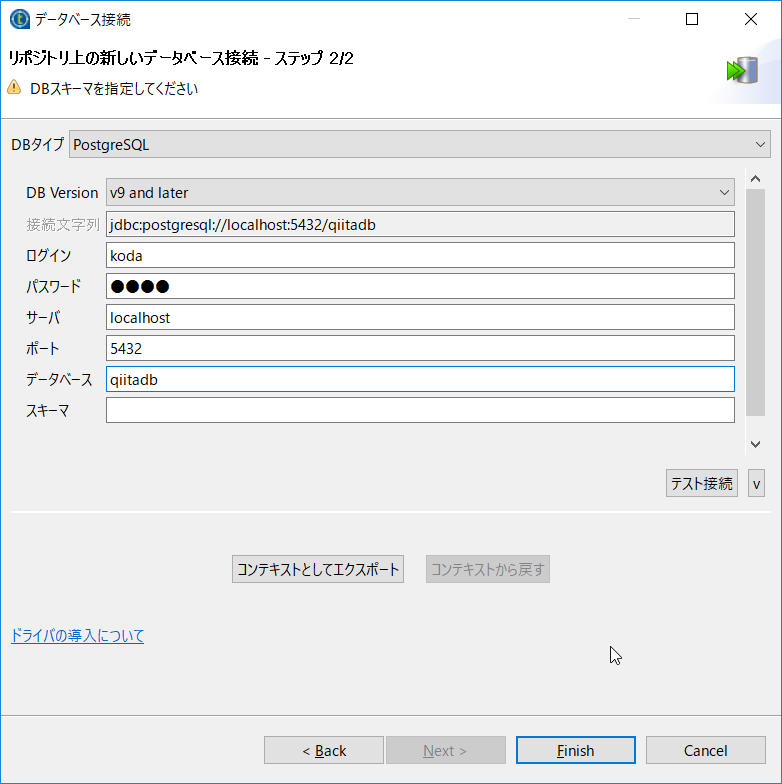
[テスト接続]ボタンをクリックし接続確認しておきましょう。
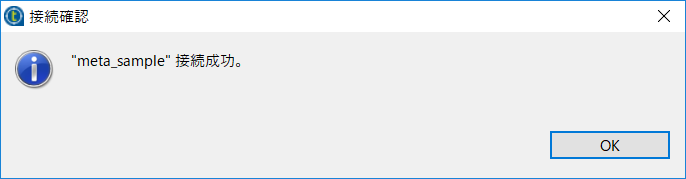
これで今回のDB処理用メタデータがリポジトリに作成できました。
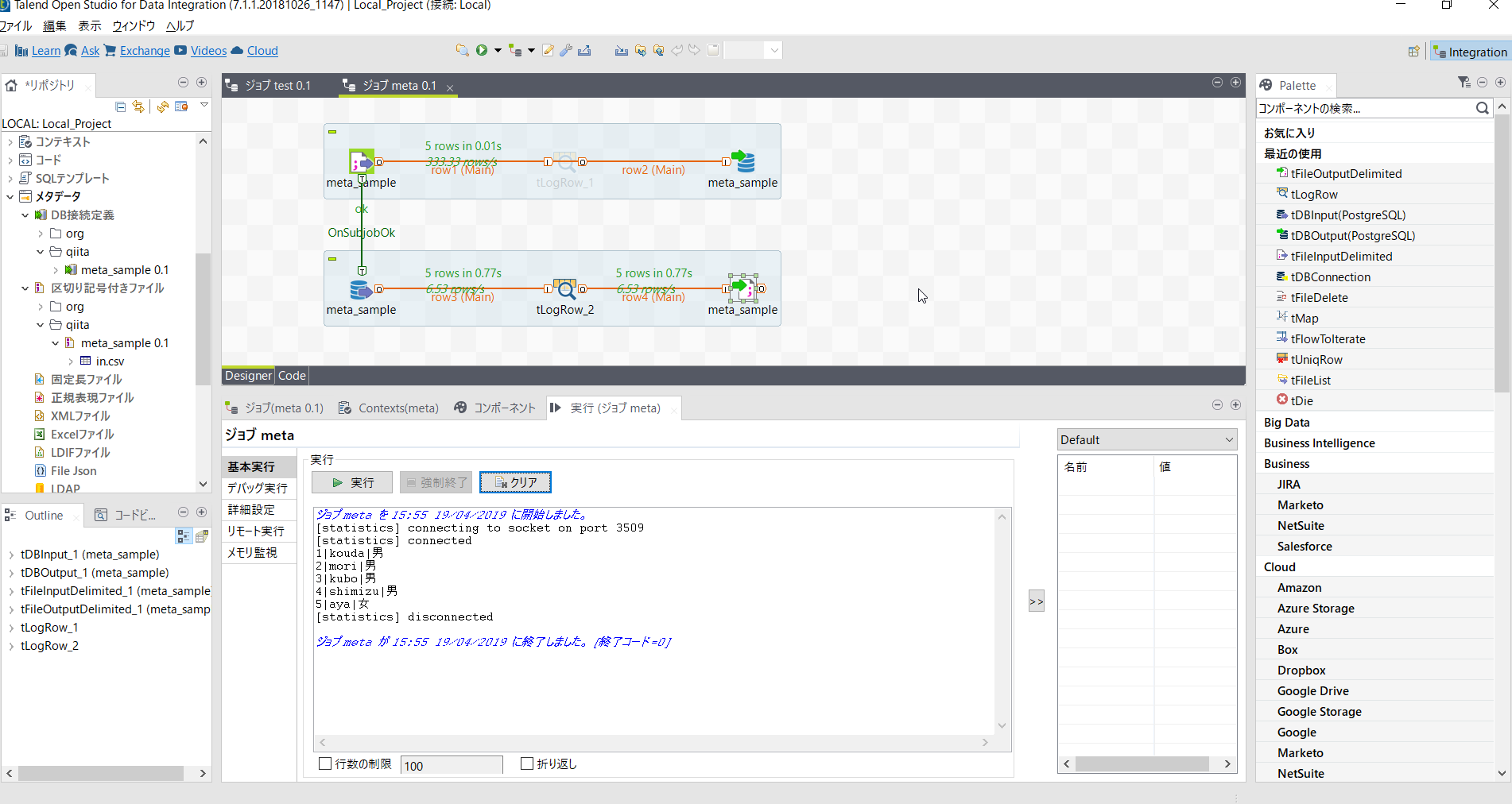
csvファイルを読み込みDBに書き出す
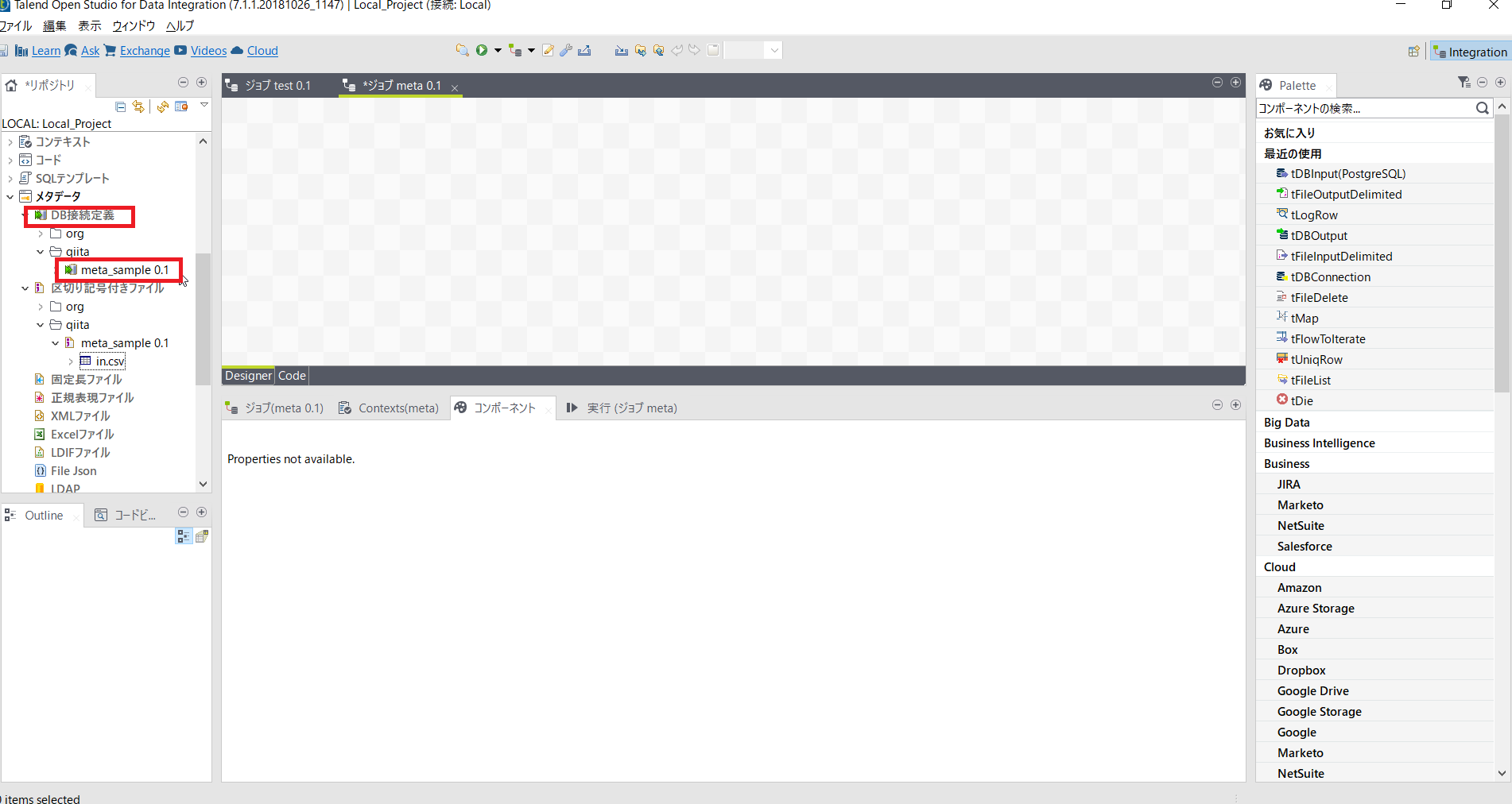
csv用メタデータをジョブのデザインワークスペースにマウスでドラッグアンドドロップします。
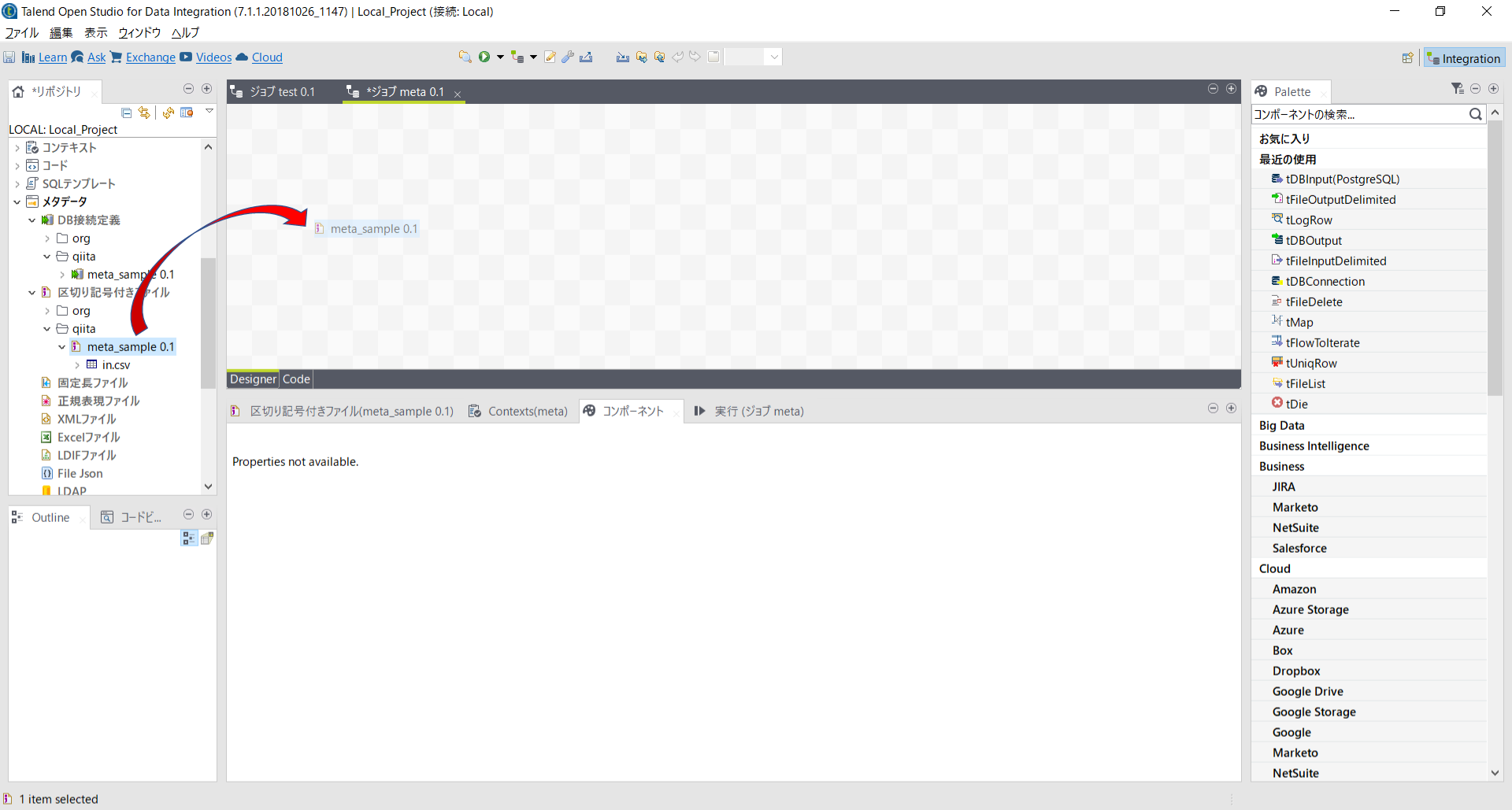
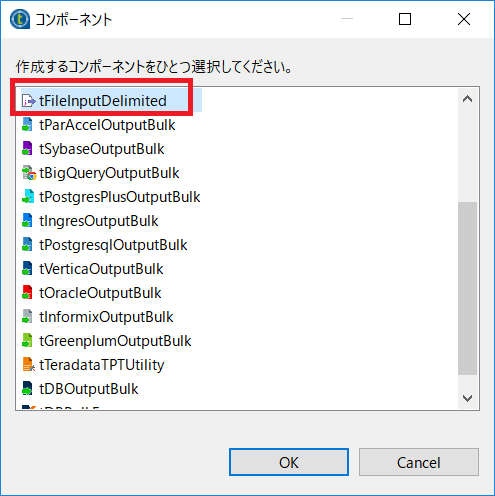
コンポーネントダイアログでは[tFileInputDelimited]を選択します。
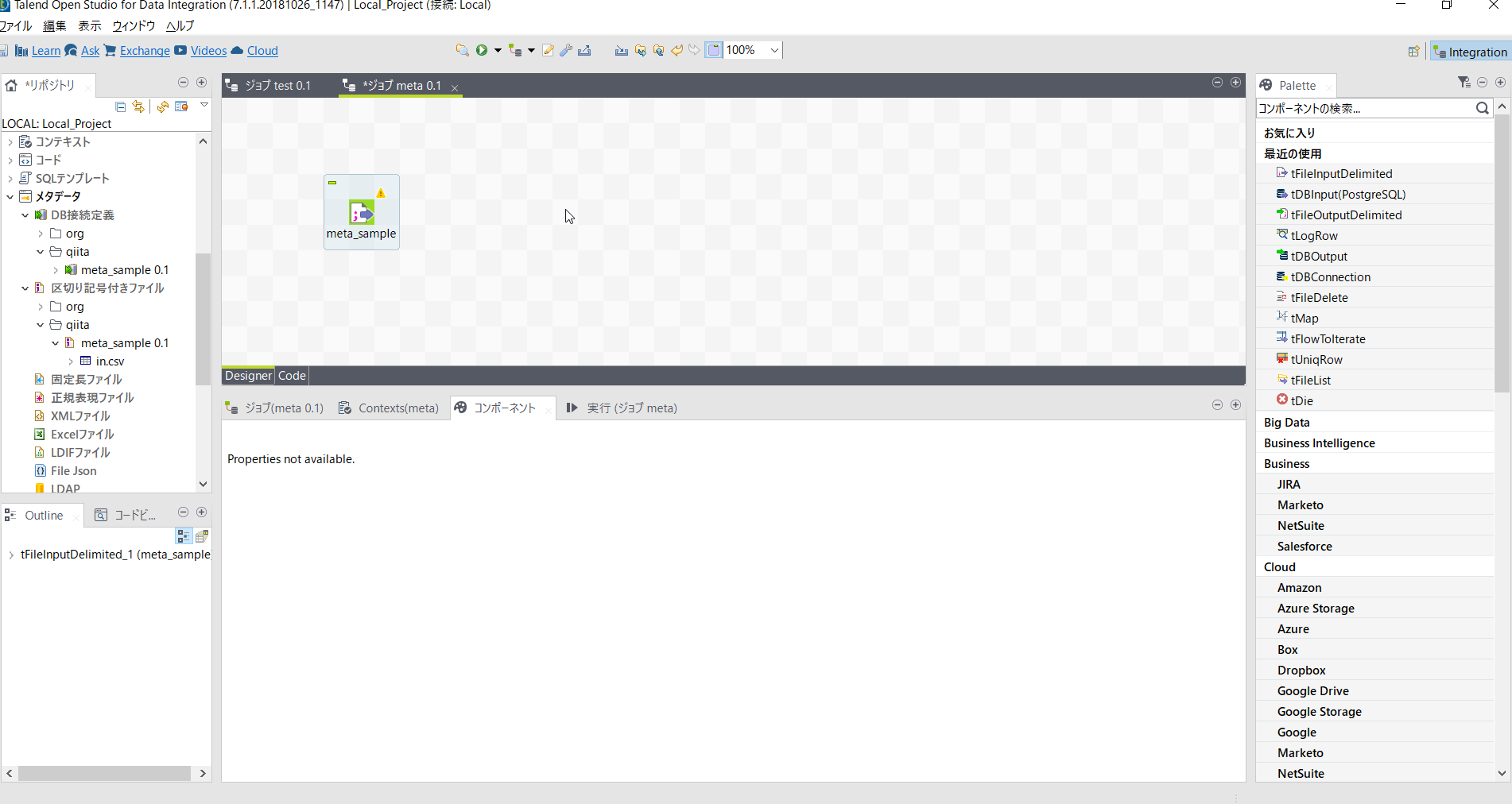
ここで[tLogRow]を配置し動作確認しておきましょう。
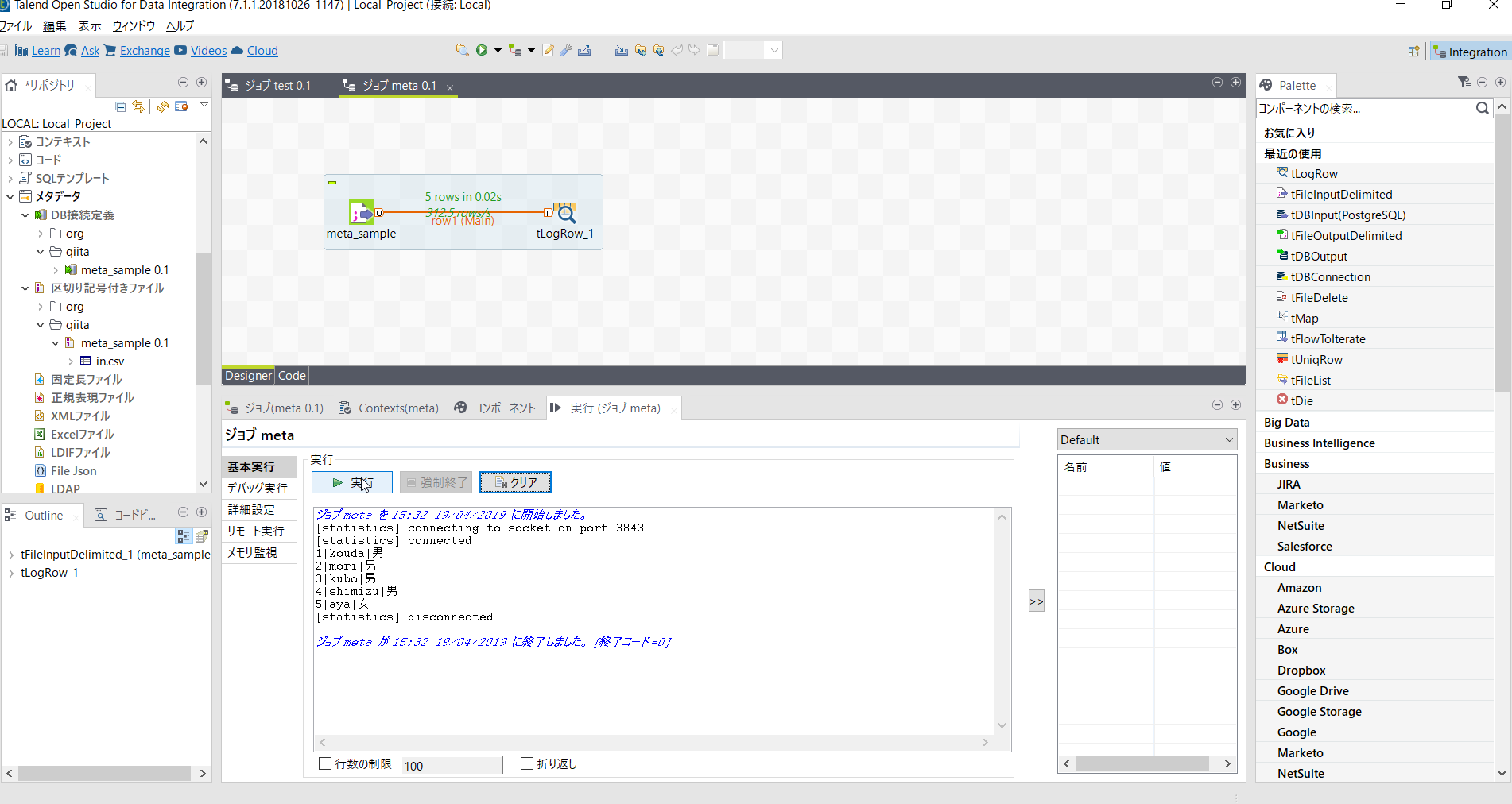
出力ロウが確認できたところで、今度はDB処理用メタデータをデザインワークスペースにマウスでドラッグアンドドロップしDB出力の処理を設定しましょう。
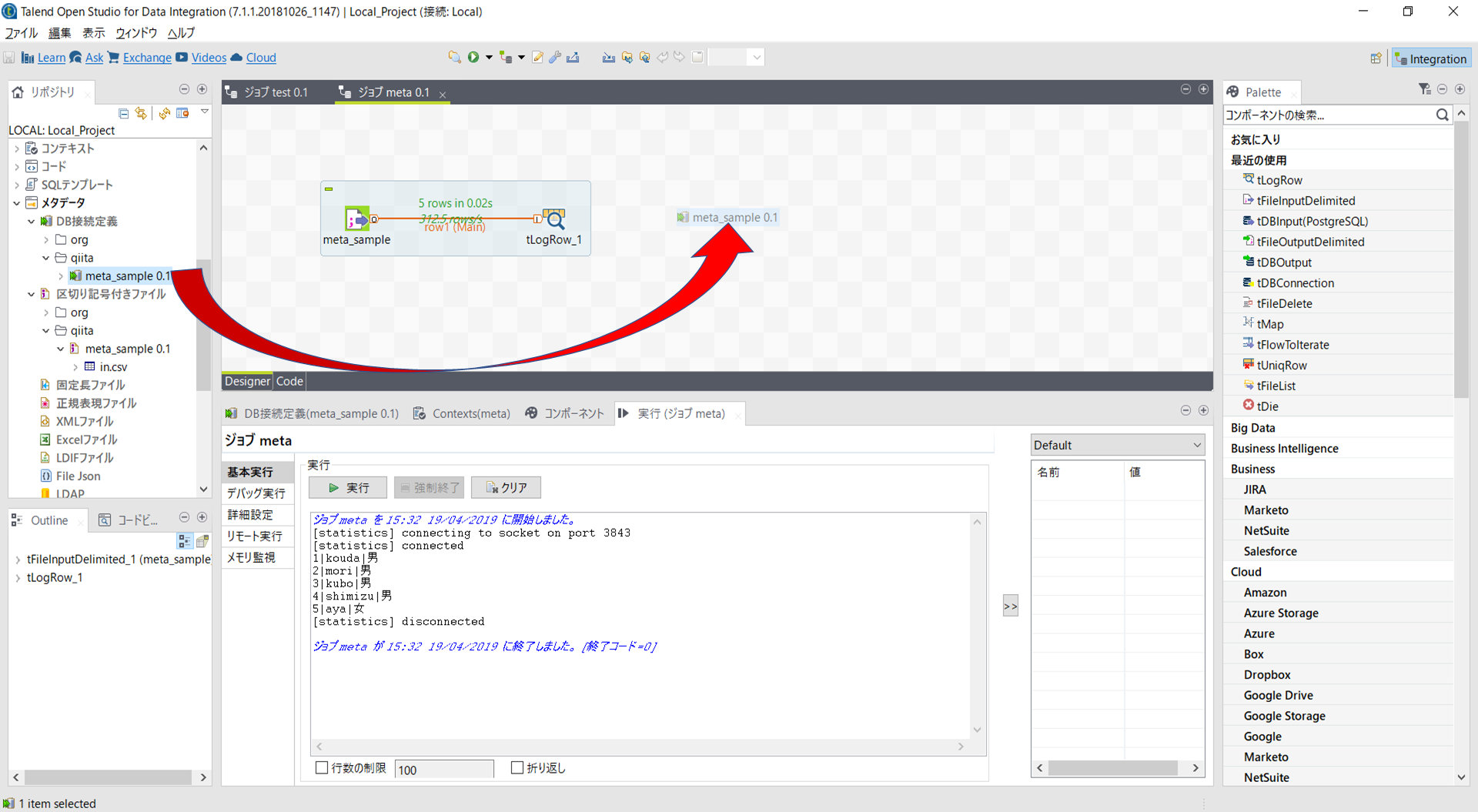
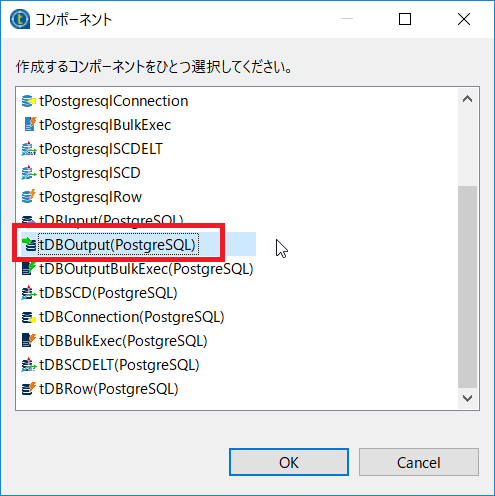
コンポーネントダイアログでは[tDBOutput(PostgreSQL)]を選択します。
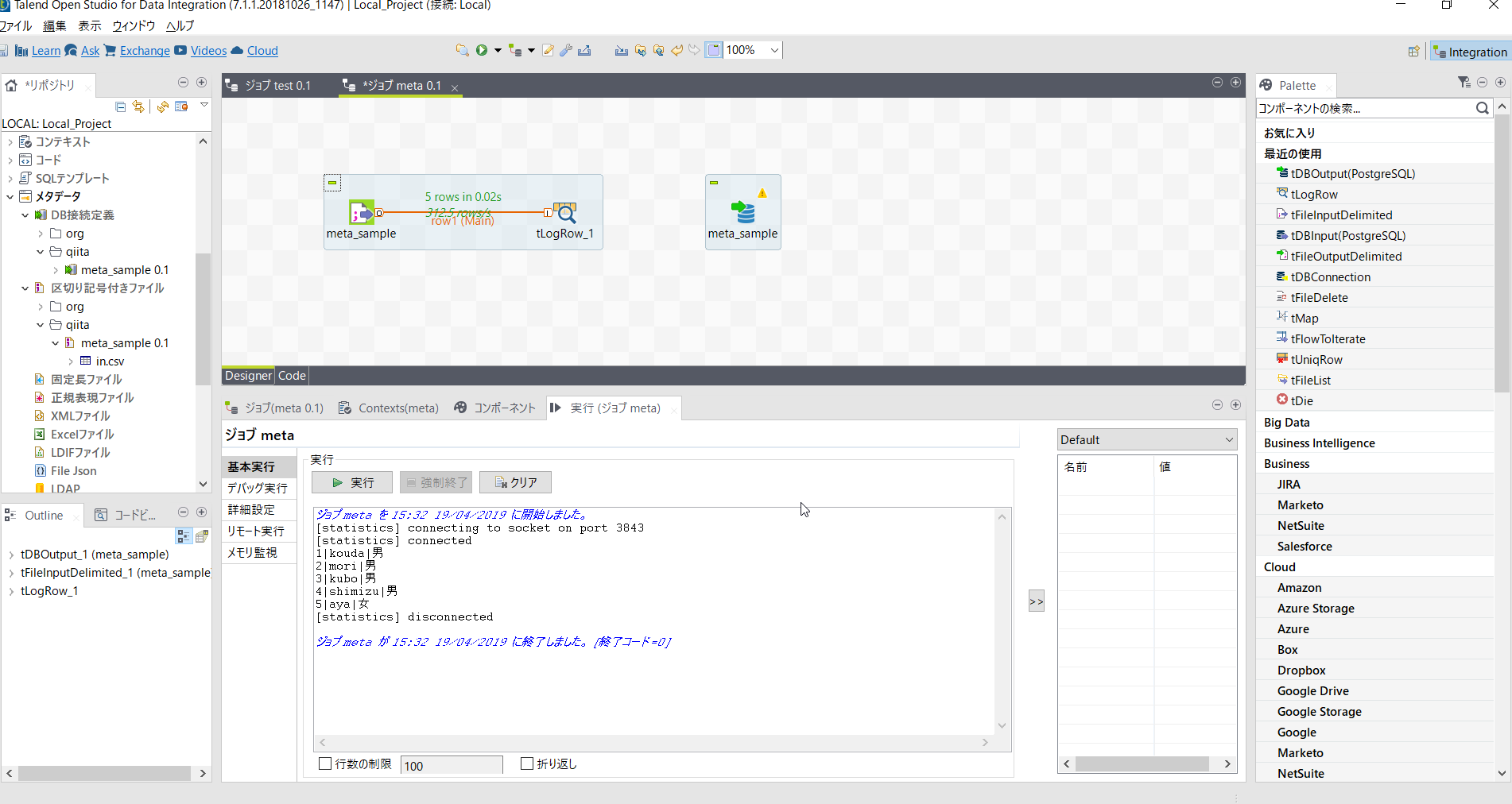
ロウをつなぎます。
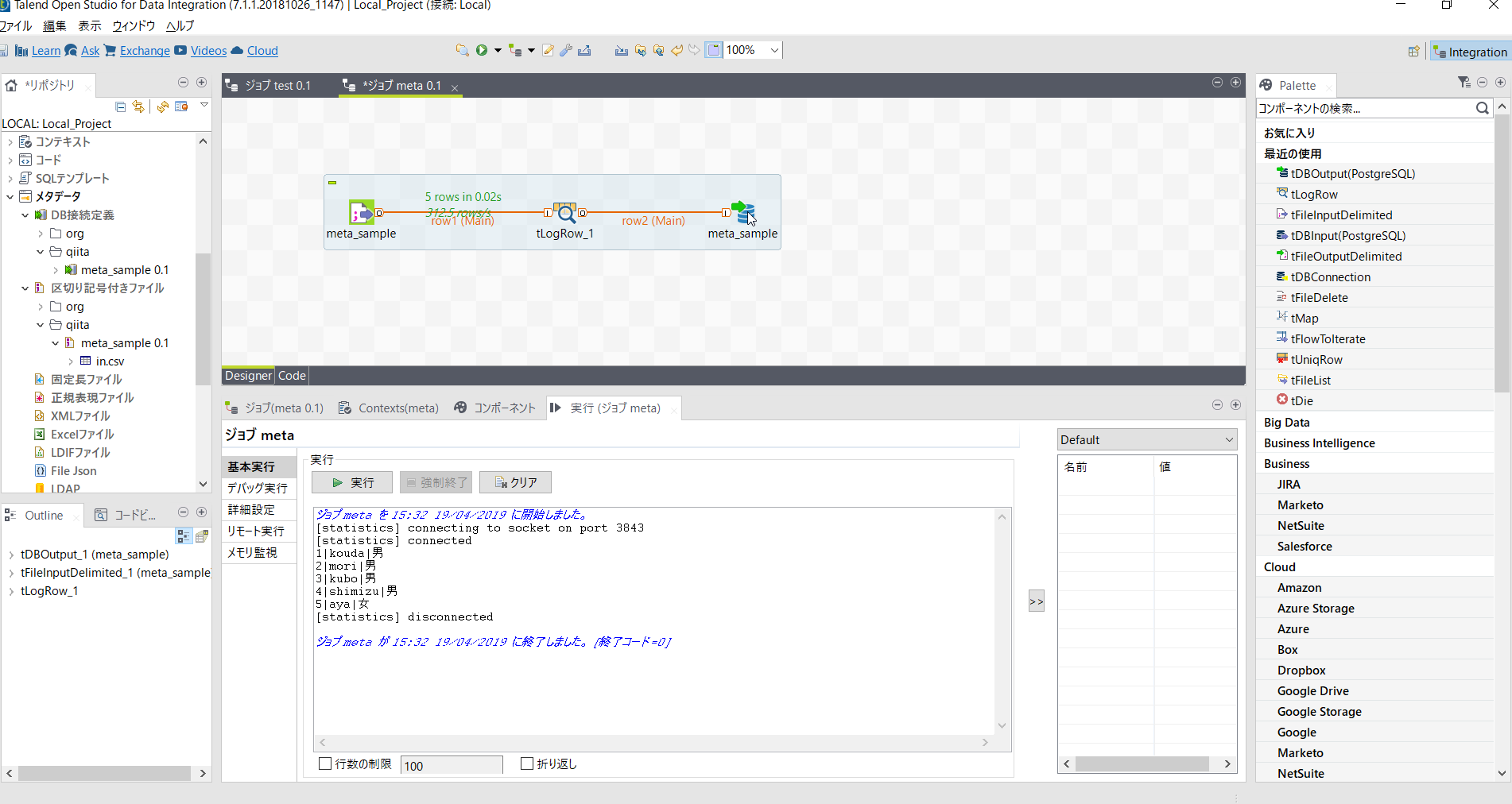
テーブルへの書き出し処理を設定します。
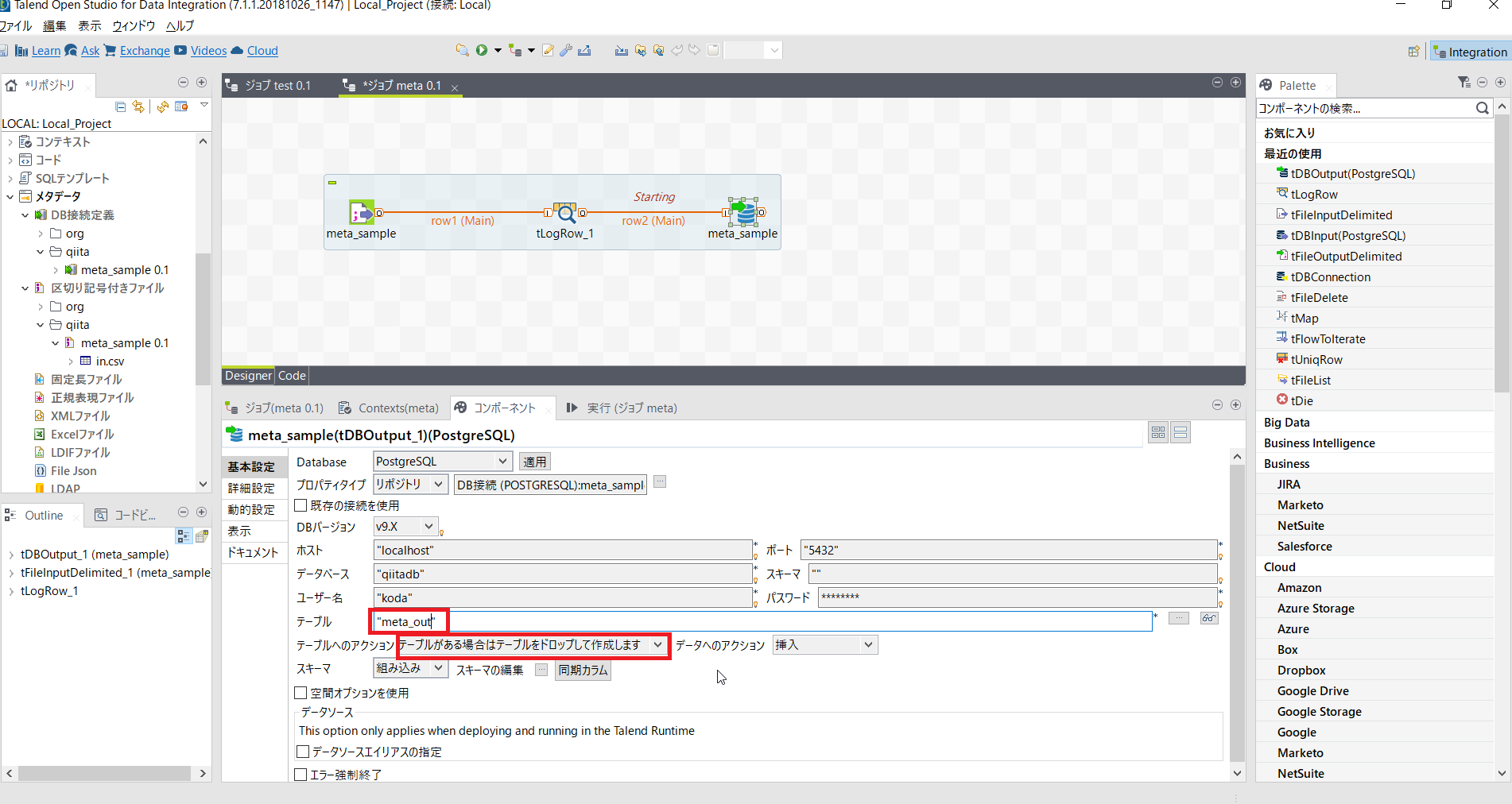
| 項目名 | 設定内容 | 説明 |
|---|---|---|
| テーブル | meta_out | 存在しないテーブルを指定 |
| テーブルへのアクション | テーブルがある場合はテーブルをドロップして作成します |
それでは実行してみましょう。エラーがなければ以下のようにmeta_outテーブルが作成されます。
qiitadb=# \d meta_out
テーブル "public.meta_out"
列 | 型 | 照合順序 | Null 値を許容 | デフォルト
--------+----------------------+----------+---------------+------------
id | integer | | |
name | character varying(7) | | |
gender | character(2) | | |
qiitadb=# select * from meta_out;
id | name | gender
----+---------+--------
1 | kouda | 男
2 | mori | 男
3 | kubo | 男
4 | shimizu | 男
5 | aya | 女
(5 行)
スキーマ情報の保存
次の処理のためにここでスキーマ情報の書き出しをしておきましょう。
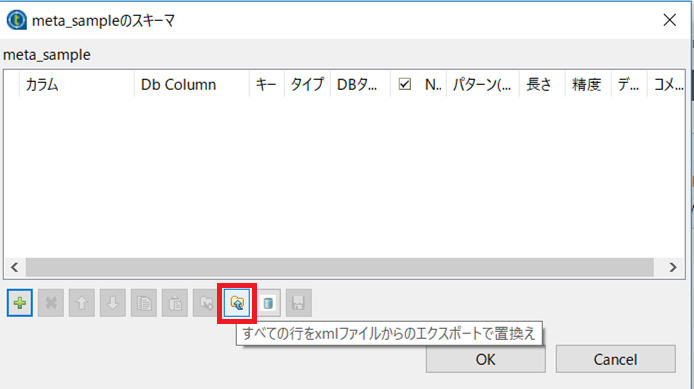
tDBOutput_1コンポーネントの[基本設定]にある[スキーマの編集]ボタンをクリックします。
表示されたダイアログでエクスポートボタンをクリックしスキーマ情報を書き出しておきます。
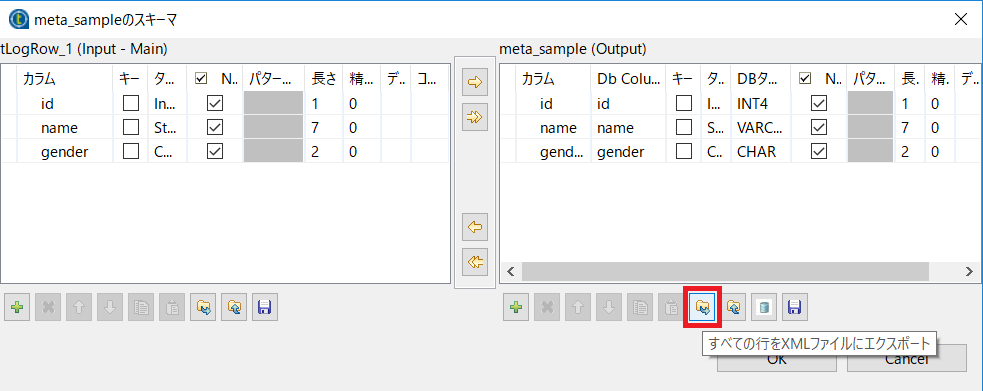
今回は c:\work\meta\schema.xml として書き出しました。
DBのテーブルを読み込みcsvファイルに書き出す
先ほどまでと同じ要領でまずはDB処理用メタデータをデザインワークスペースにマウスでドラッグアンドドロップします。
コンポーネントダイアログでは[tDBInput(PostgreSQL)]を選択します。
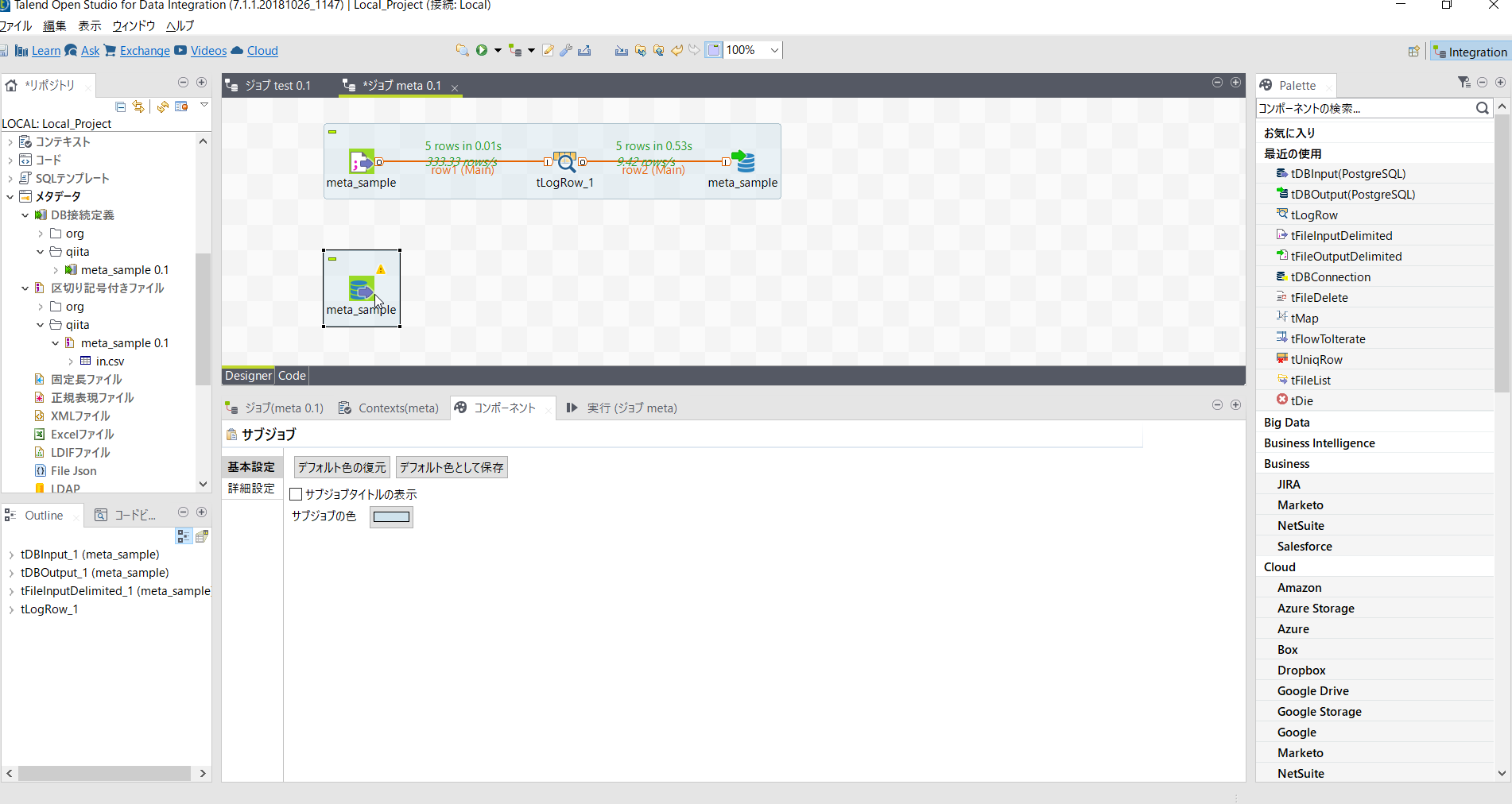
サブジョブOKでつなぎ処理の流れを明確にしておきます。
そのうえで、[tDBInput(PostgreSQL)]の基本設定にある[スキーマの編集]をクリックします。
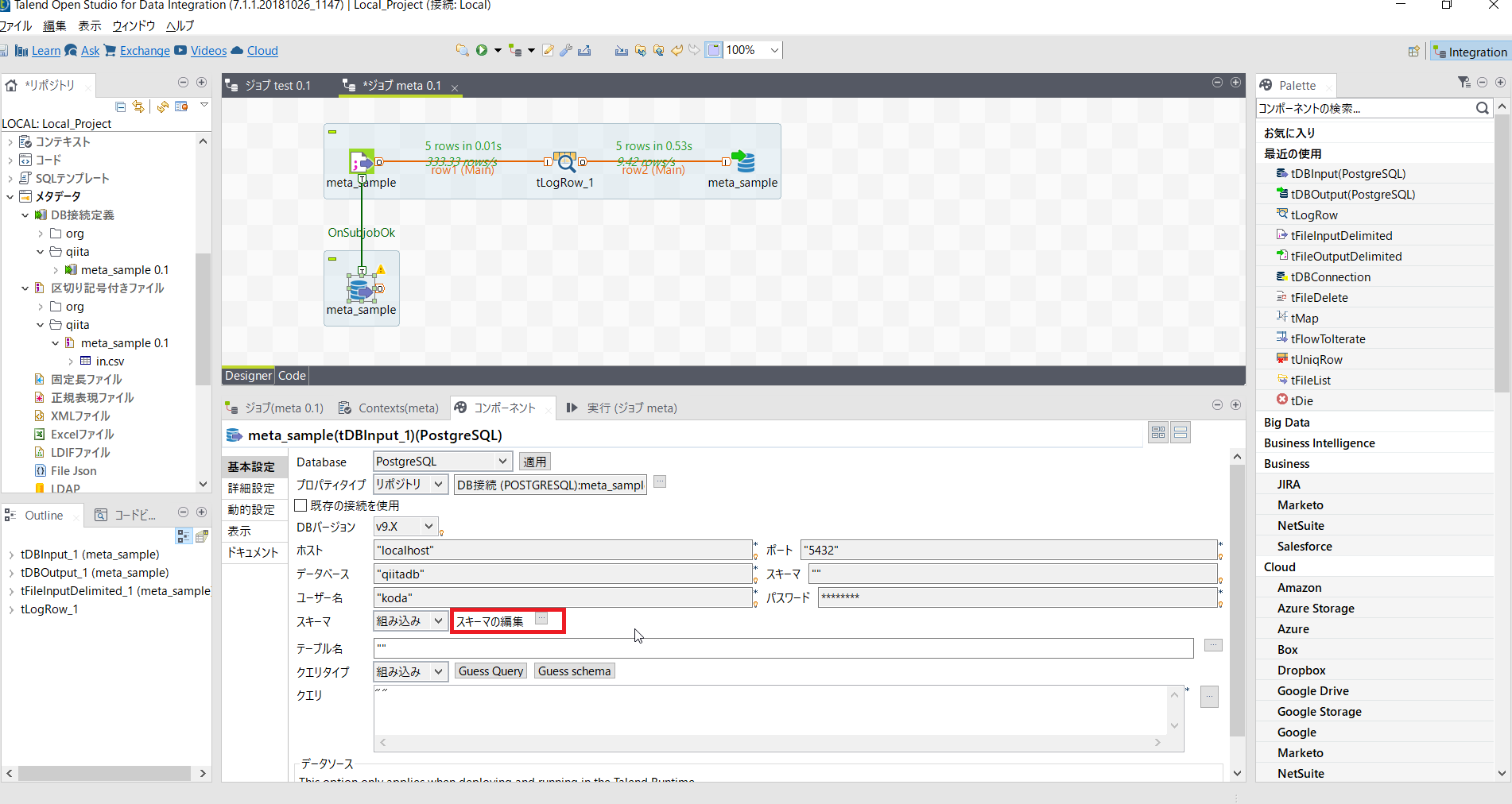
インポートにあたるボタンをクリックし先ほど用意した schema.xml を読み込みます。
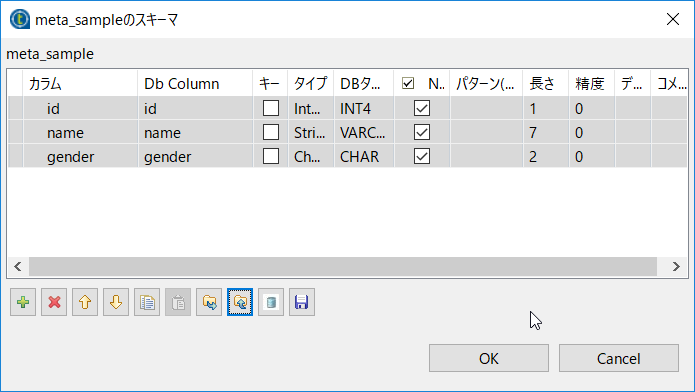
クエリにSQLを記載します。
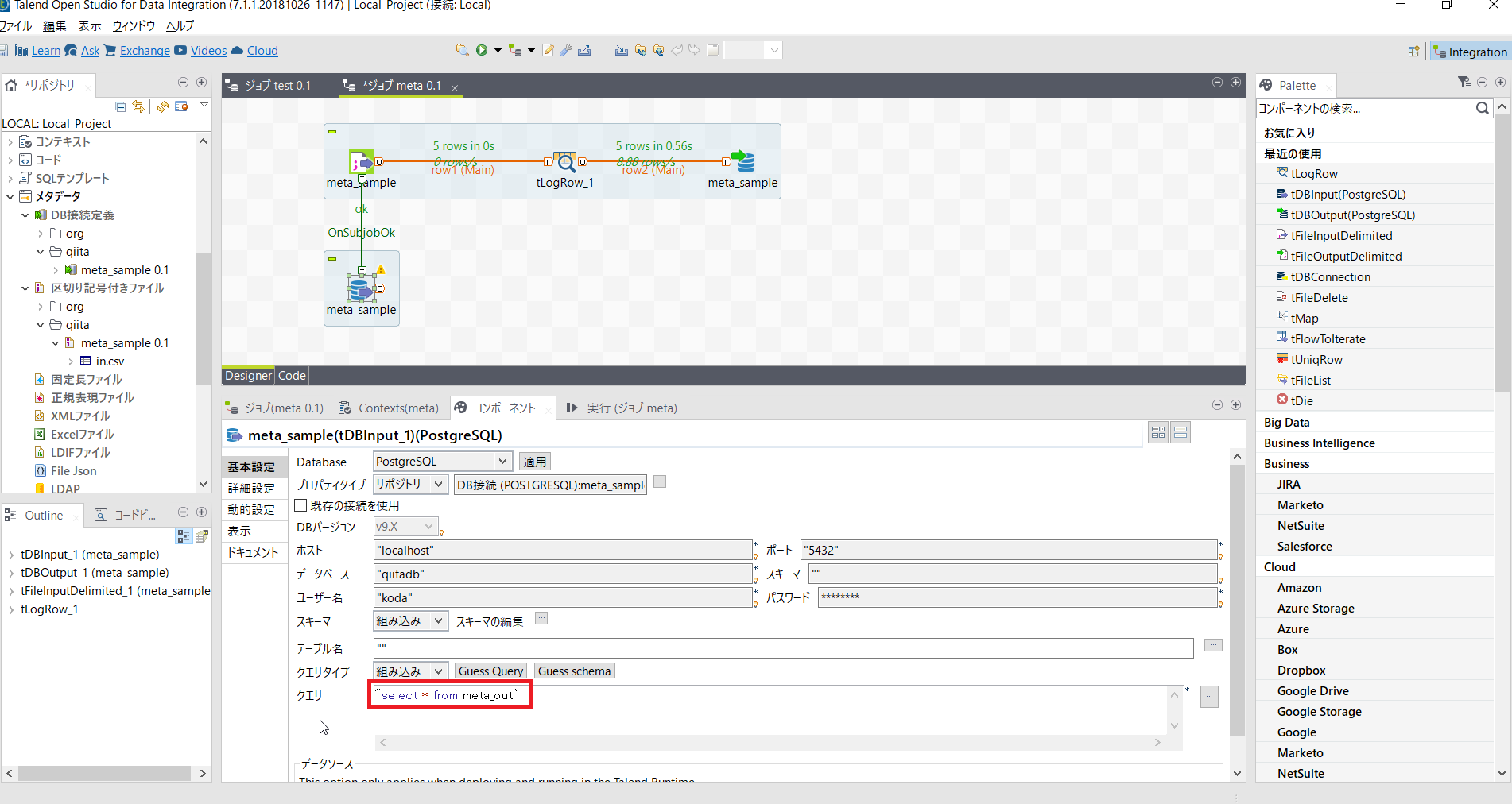
| 項目名 | 設定内容 | 説明 |
|---|---|---|
| クエリ | "select * from meta_out" |
ここで[tLogRow_2]を配置し動作確認しておきましょう。
最初に使った[tLogRow_1]はもう不要なので無効化しておきましょう。
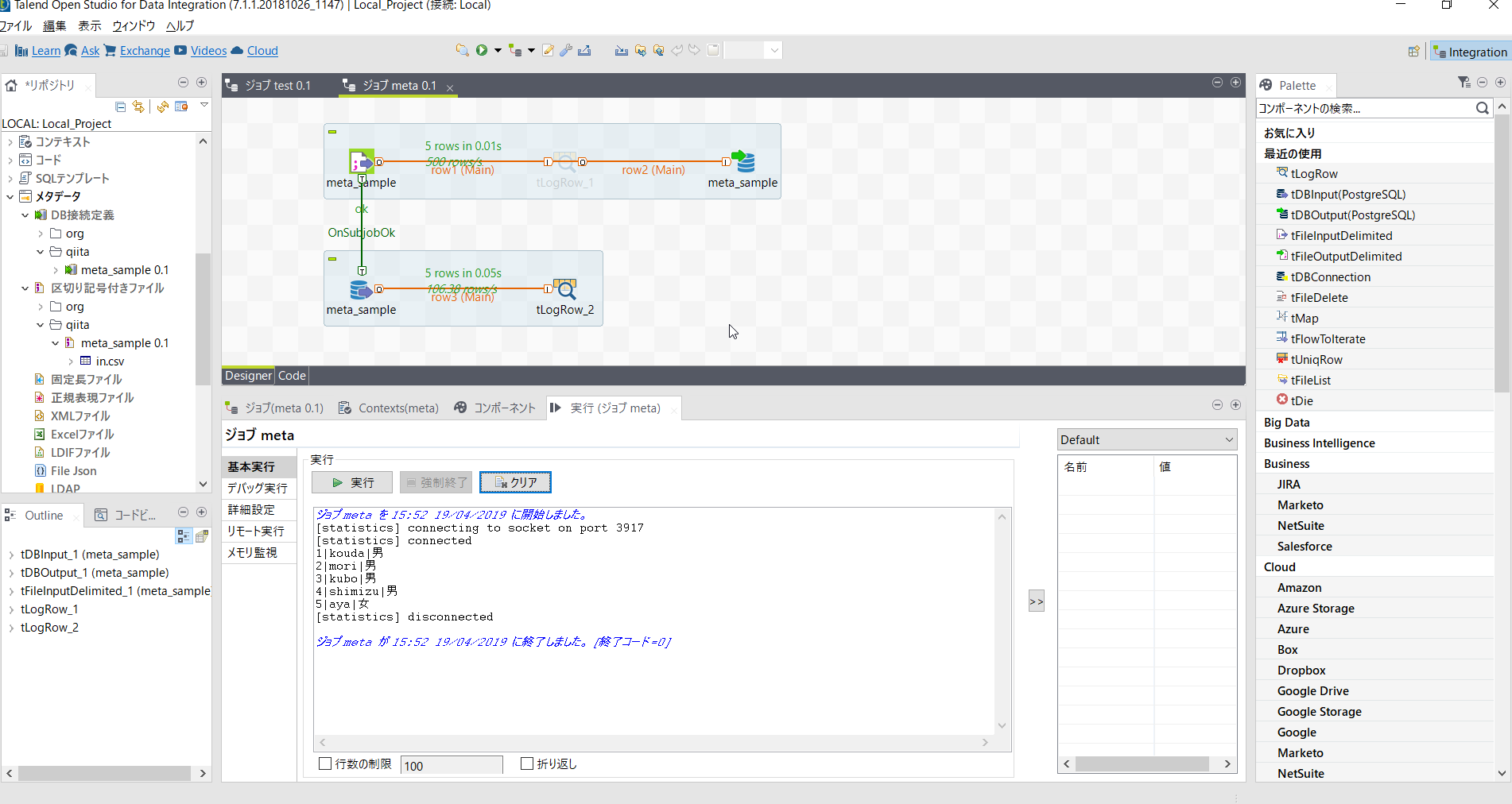
データの取得が確認できたら仕上げです。
csv用メタデータをデザインワークスペースにマウスでドラッグアンドドロップします。
コンポーネントダイアログではファイル出力をしたいので[tFileOutputDelimited]を選択します。
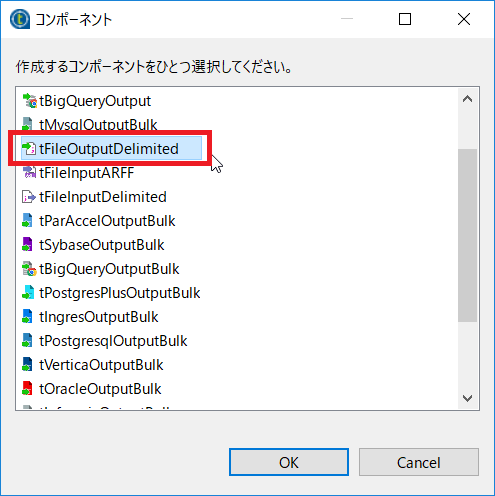
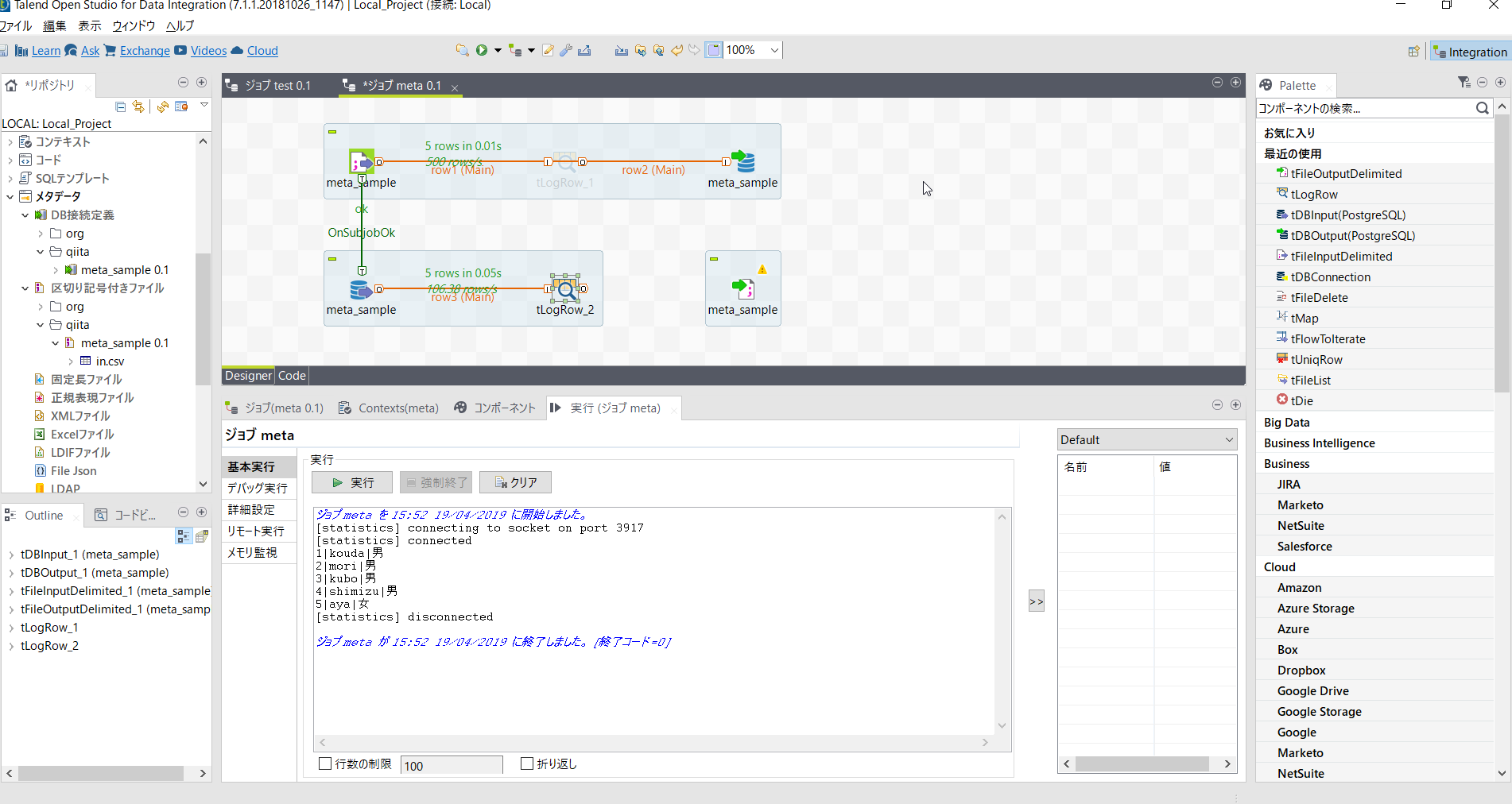
ロウをつなぎます。
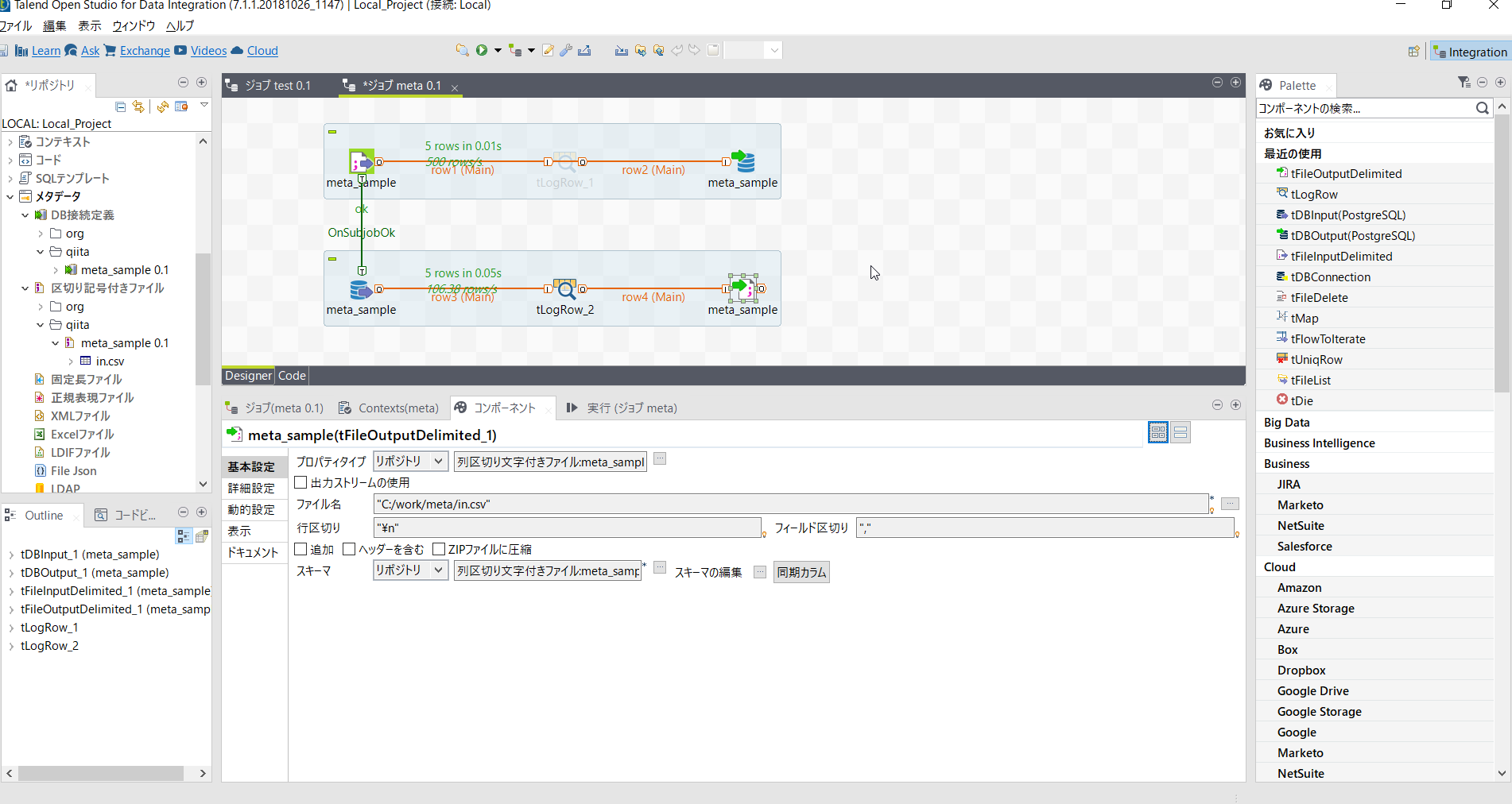
[tFileOutputDelimited_1]の基本設定では以下のように設定します。
プロパティタイプを[組み込み]にすることでリポジトリで定義した内容を流用し一部を書き換えることができます。
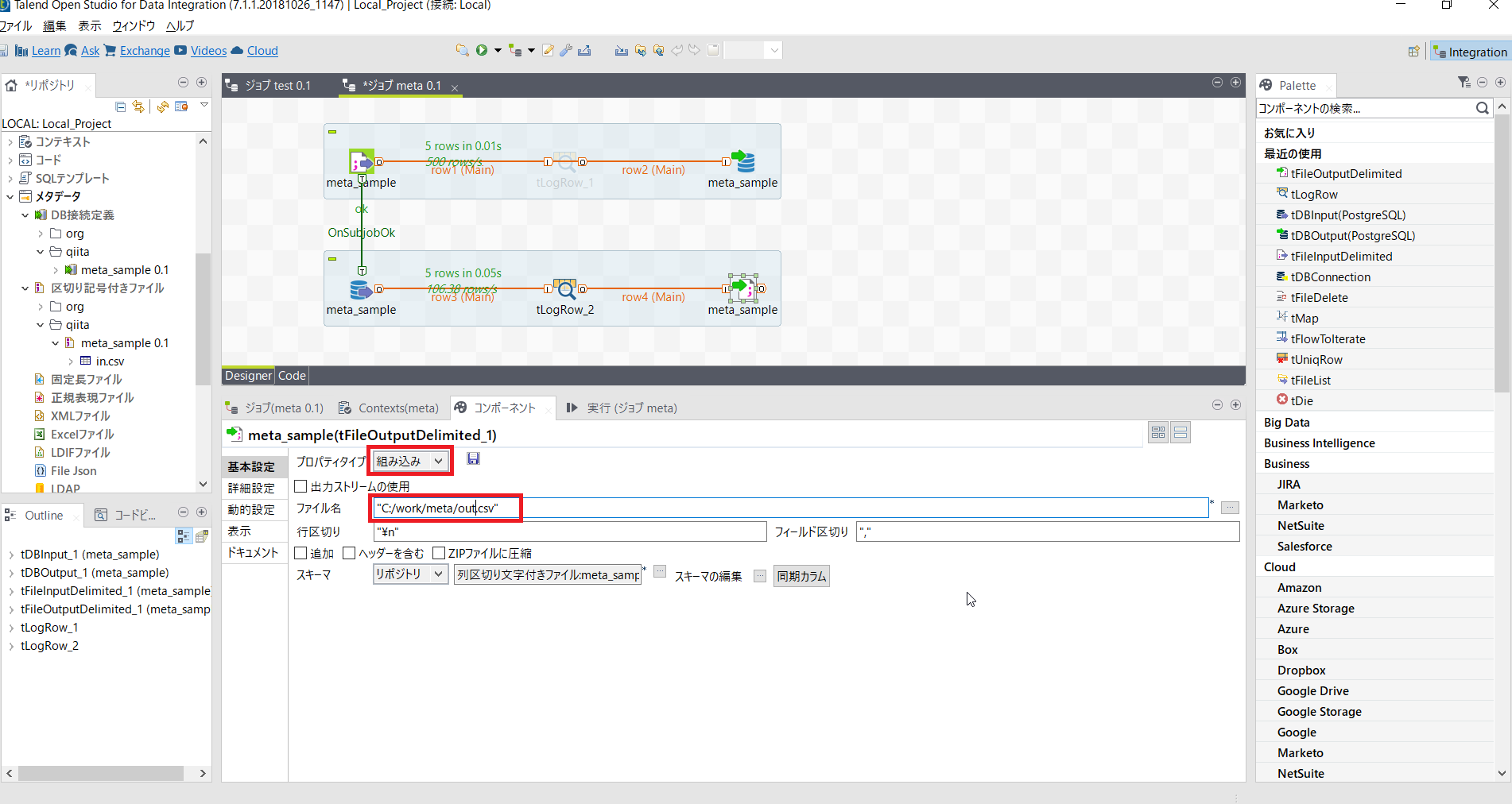
| 項目名 | 設定内容 | 説明 |
|---|---|---|
| プロパティタイプ | 組み込み | |
| ファイル名 | C:/work/meta/out.csv | 出力ファイルとしてファイル名を変更 |
それでは実行してみましょう。
エラーがなければout.csvが作成されるはずです。
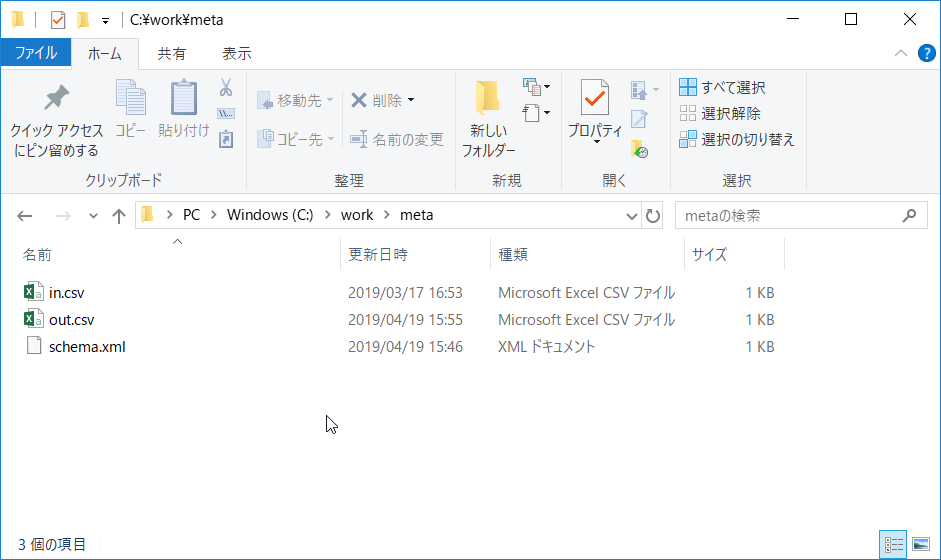
1,kouda,男
2,mori,男
3,kubo,男
4,shimizu,男
5,aya,女
まとめ
今回はメタデータの使い方を確認しました。
あらかじめ入出力を定義することで再利用が可能なことを分かってもらえたのではないでしょうか。
※毎度のことですが、ほんのさわりの部分だけを解説していますのでぜひここから深掘りしてみてください。
お疲れ様でした。
次回以降
次回はContext変数をやっていきます。