全体の目的
Talendの超簡単なサンプルジョブを作成して,ETLジョブ開発に必要なスキルを習得することが目的です。
対象者
ETL / EAI技術者
環境
| 使用環境 | バージョン |
|---|---|
| OS | Windows10 |
| Talend | 7.1.1 |
サンプル一覧
以下の順番で習得していきます
| # | 内容 |
|---|---|
| 1 | はじめてのTalend |
| 2 | ファイルI/O |
| 3 | データベースI/O |
| 4 | tMap |
| 5 | イテレータ(今回) |
| 6 | メタデータ |
| 7 | Context変数 |
| 8 | Global Map |
| 9 | tHashInput/tHashOutput |
| 10 | エラーハンドリング |
| 11 | ロギング |
| 12 | 子ジョブ(ジョブのネスト) |
| 13-1 | 設定ファイル読み込みオリジナル版 |
| 13-2 | 設定ファイル読み込みコンポ版 |
| 14 | tJava |
今回の目的
イテレータを理解する
サンプルプログラム概要
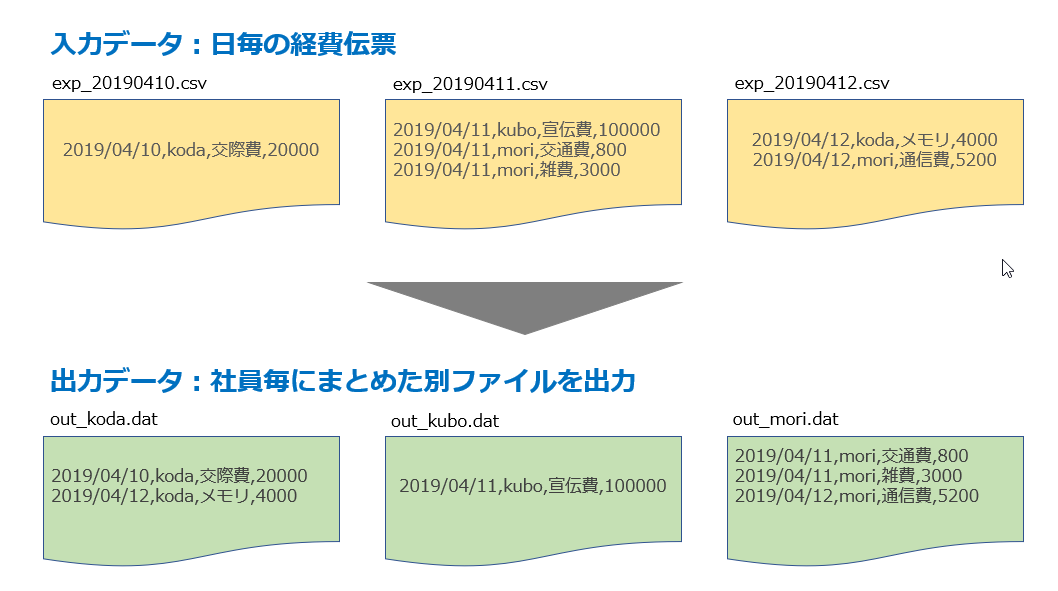
複数ファイルにわかれた経費伝票を社員毎にまとめる処理を実装してみます。
反復処理を理解する
以下の流れで実装します。
- tFileListでイテレータを理解
- 複数の入力ファイルの内容を一つのファイルにまとめる
- ユニークデータを生成
- ユニークデータ単位でloop
- ファイルを生成
- 対象データのみを出力
入力ファイル準備
C:/work/Iteration 配下に次の3ファイルを準備します。(UTF-8,LFで作成)
2019/04/10,koda,交際費,20000
2019/04/11,kubo,宣伝費,100000
2019/04/11,mori,交通費,800
2019/04/11,mori,雑費,3000
2019/04/12,koda,メモリ,4000
2019/04/12,mori,通信費,5200
tFileList
それではサンプルジョブを作成していきましょう。
リポジトリの[ジョブ]を右クリックし[ジョブの作成]を選択します。
[名前]にiterationと入力し[Finish]ボタンをクリックします。
[tFileList]コンポーネントを配置しパラメータを設定します。
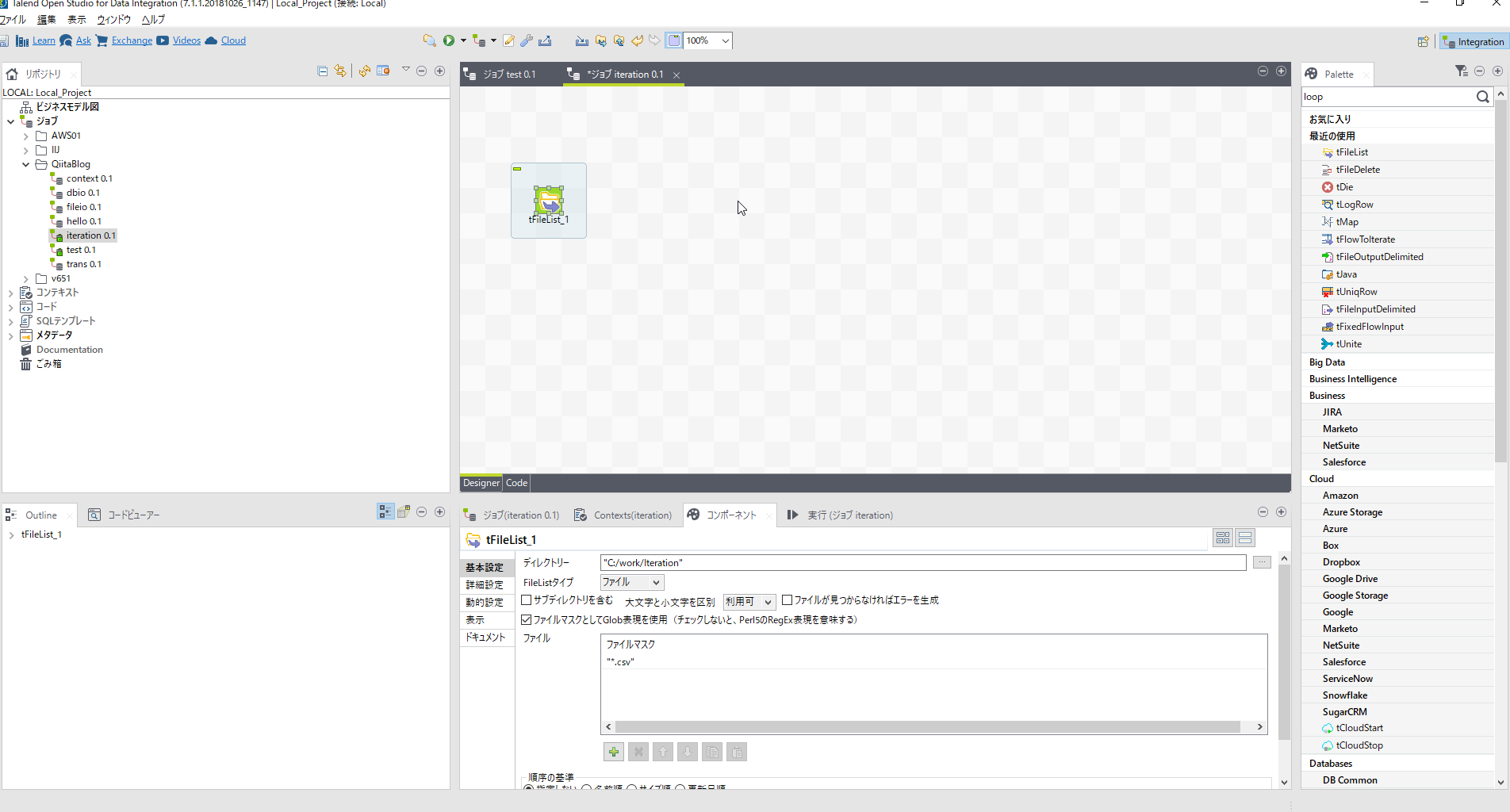
| 項目名 | 設定内容 | 説明 |
|---|---|---|
| ディレクトリ | "C:/work/Iteration" | |
| ファイルマスク | "*.csv" | 拡張子csvだけを読み込む |
[tFileInputDelimited]コンポーネントを配置しパラメータを設定します。
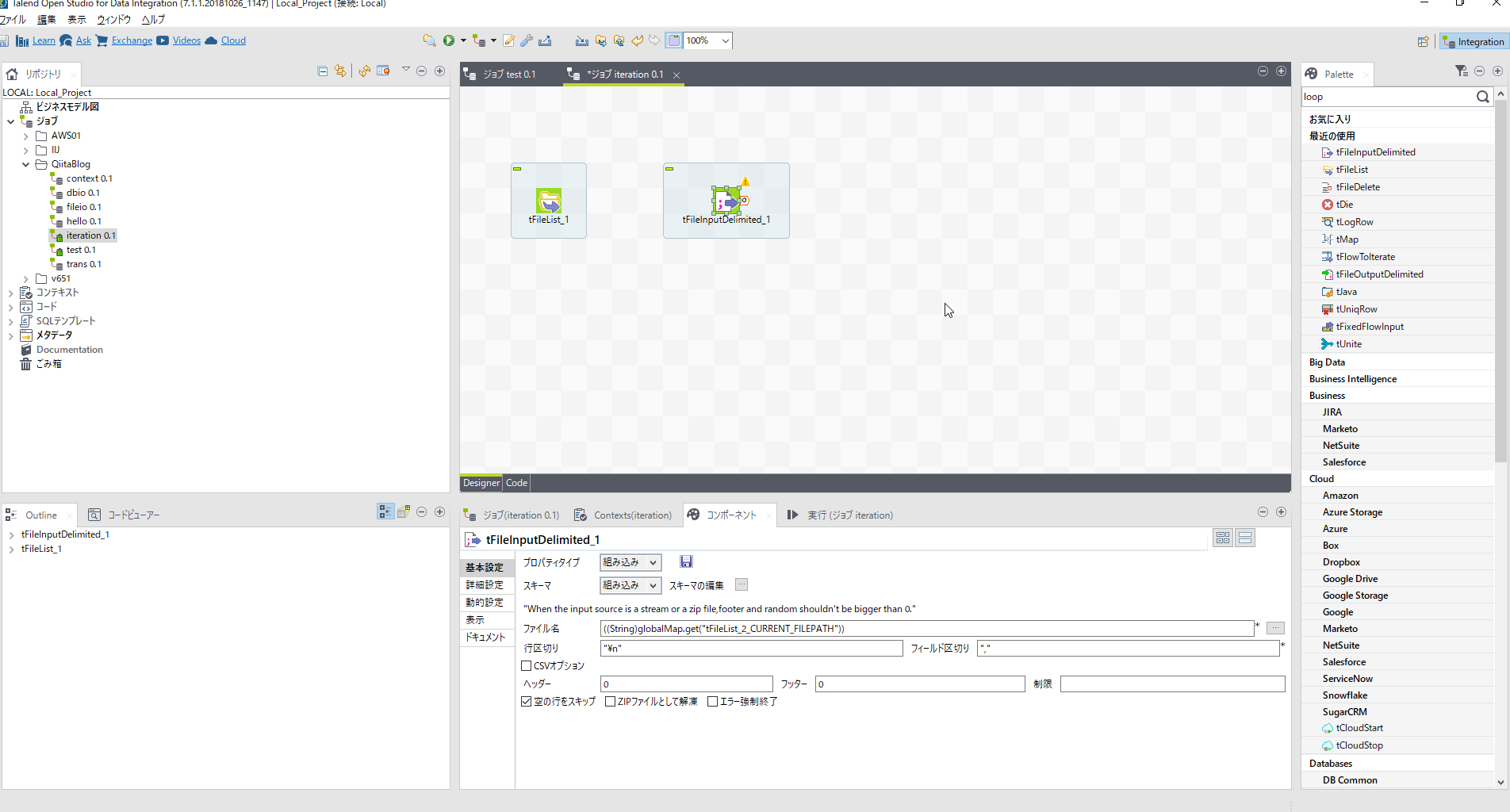
| 項目名 | 設定内容 | 説明 |
|---|---|---|
| ファイル名 | ((String)globalMap.get("tFileList_1_CURRENT_FILEPATH")) | Global Mapは第8回で別途説明しますので今回はコピペで。 |
| フィールド区切り | "," | |
| エンコーディング | UTF-8 | 詳細設定タブ |
| スキーマ編集 | 下記 | 下記参照 |
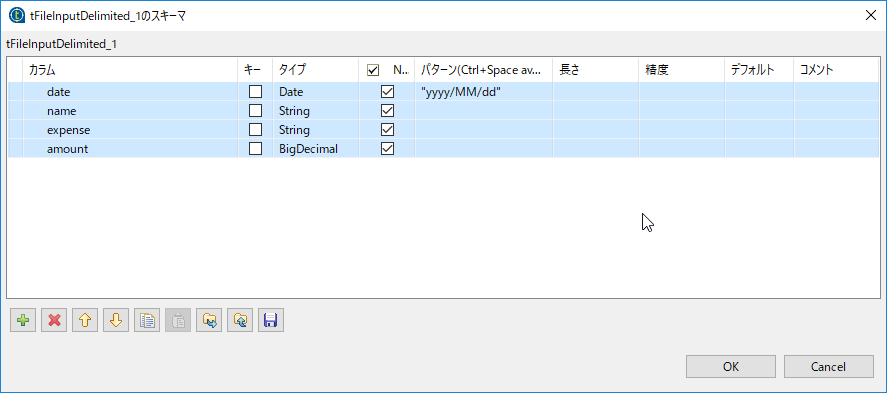
| 列 | カラム | タイプ |
|---|---|---|
| 1列目 | date | Date "yyyy/MM/dd" |
| 2列目 | name | String |
| 3列目 | expense | String |
| 3列目 | amount | BigDecimal |
[tFileList]コンポーネントを右クリックし[ロウ]-[反復]を選び[tFileInputDelimited]につなぎます。
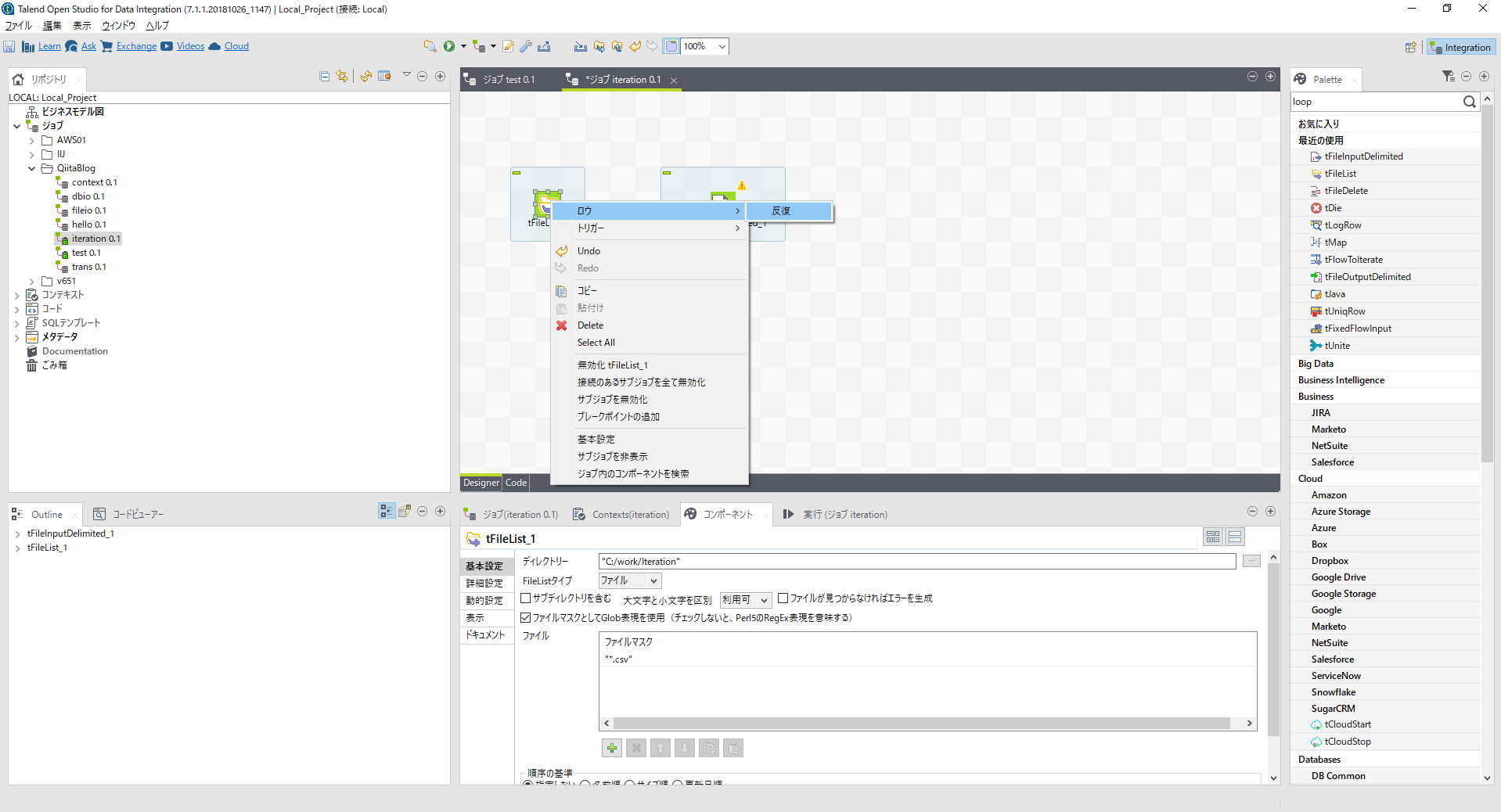
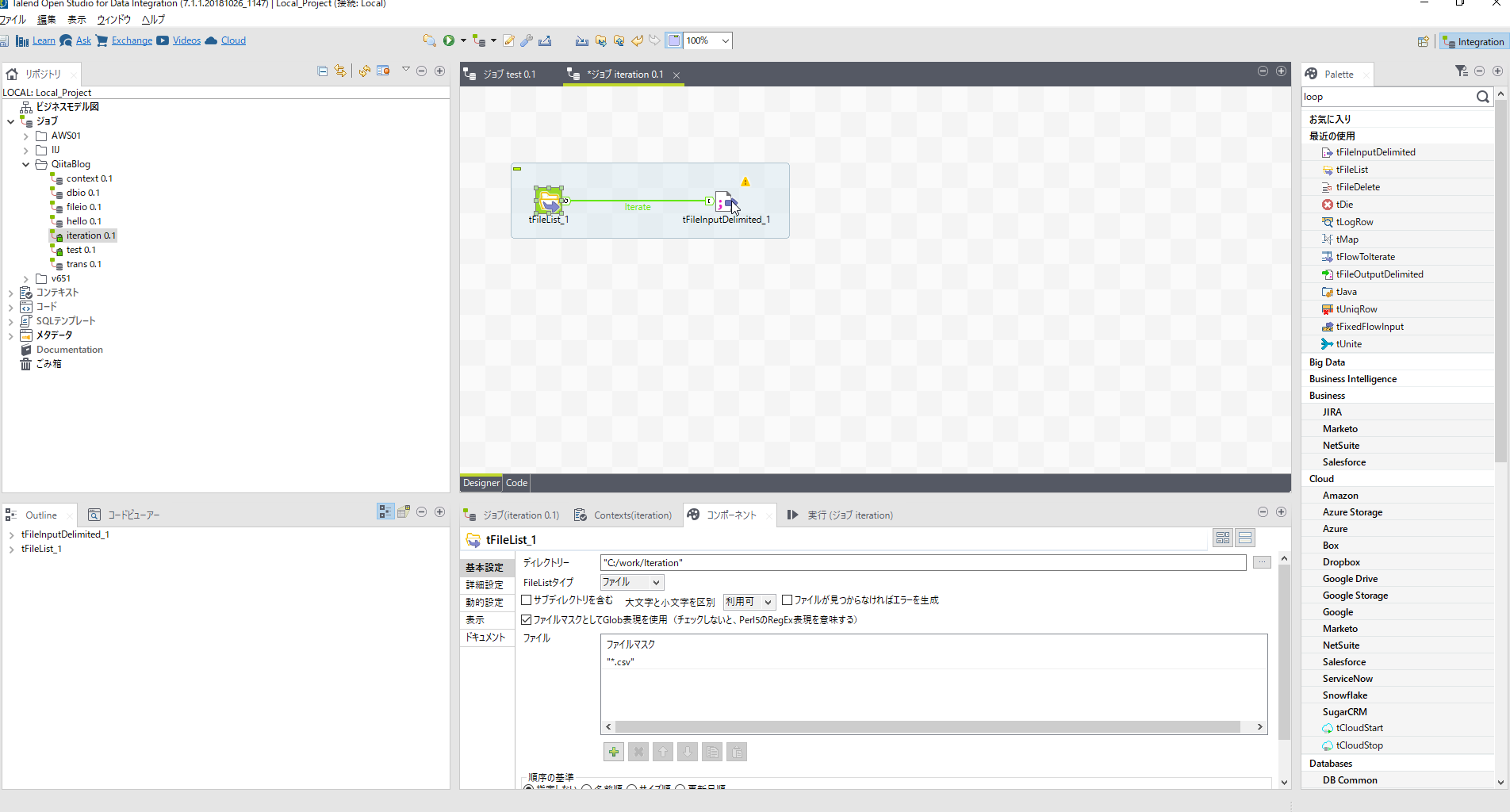
ここで[tLogRow]を配置し一度出力を確認してみましょう。すべてのcsvファイル読込みを確認できました。
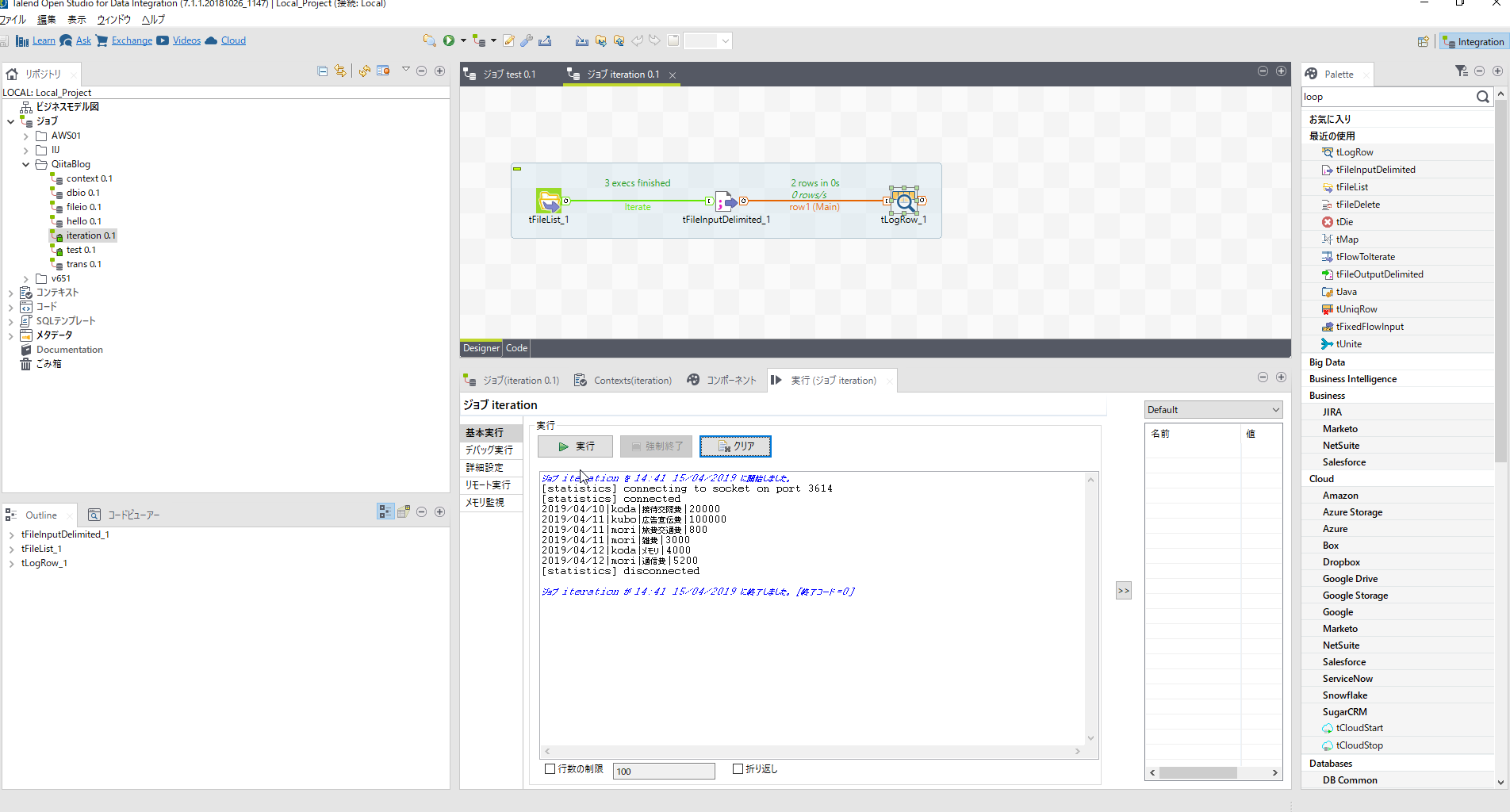
マージファイルを作成するために[tFileOutputDelimited]コンポーネントを配置しパラメータを設定します。
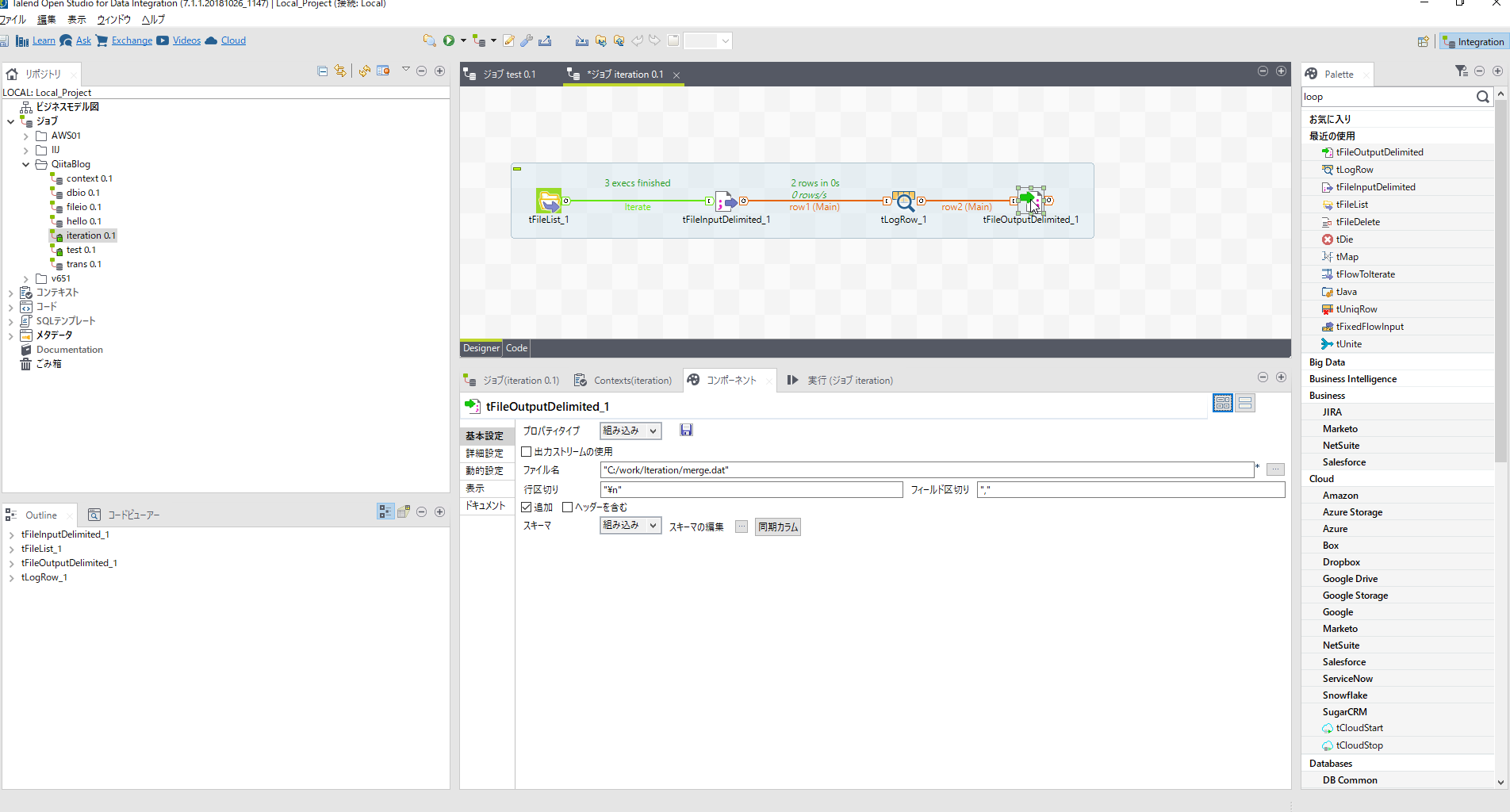
| 項目名 | 設定内容 | 説明 |
|---|---|---|
| ファイル名 | "C:/work/Iteration/merge.dat" | |
| フィールド区切り | "," | |
| 追加 | チェック | |
| エンコーディング | UTF-8 | 詳細設定タブ |
[tLogRow]と[tFileOutputDelimited]をロウをつなぎ実行します。
merge.datが作成できました。
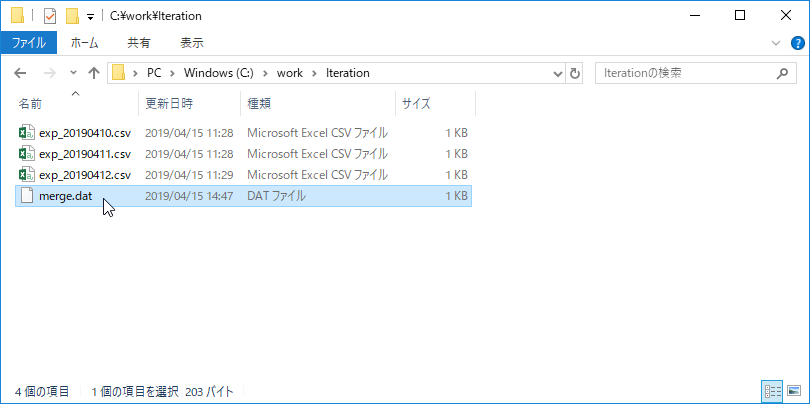
ファイル削除処理
このままだとmerge.datが実行するたびに追記されてしまうので処理前に削除するようにしておきます。
[tFileDelete]コンポーネントを以下パラメータで配置します。
| 項目名 | 設定内容 | 説明 |
|---|---|---|
| ファイル名 | "C:/work/Iteration/merge.dat" | |
| エラーで失敗 | チェックを外す |
[tFileDelete]コンポーネントを右クリックし[トリガー]-[サブジョブがOKの場合]を選び最初に配置した[tFileList]につなぎます。
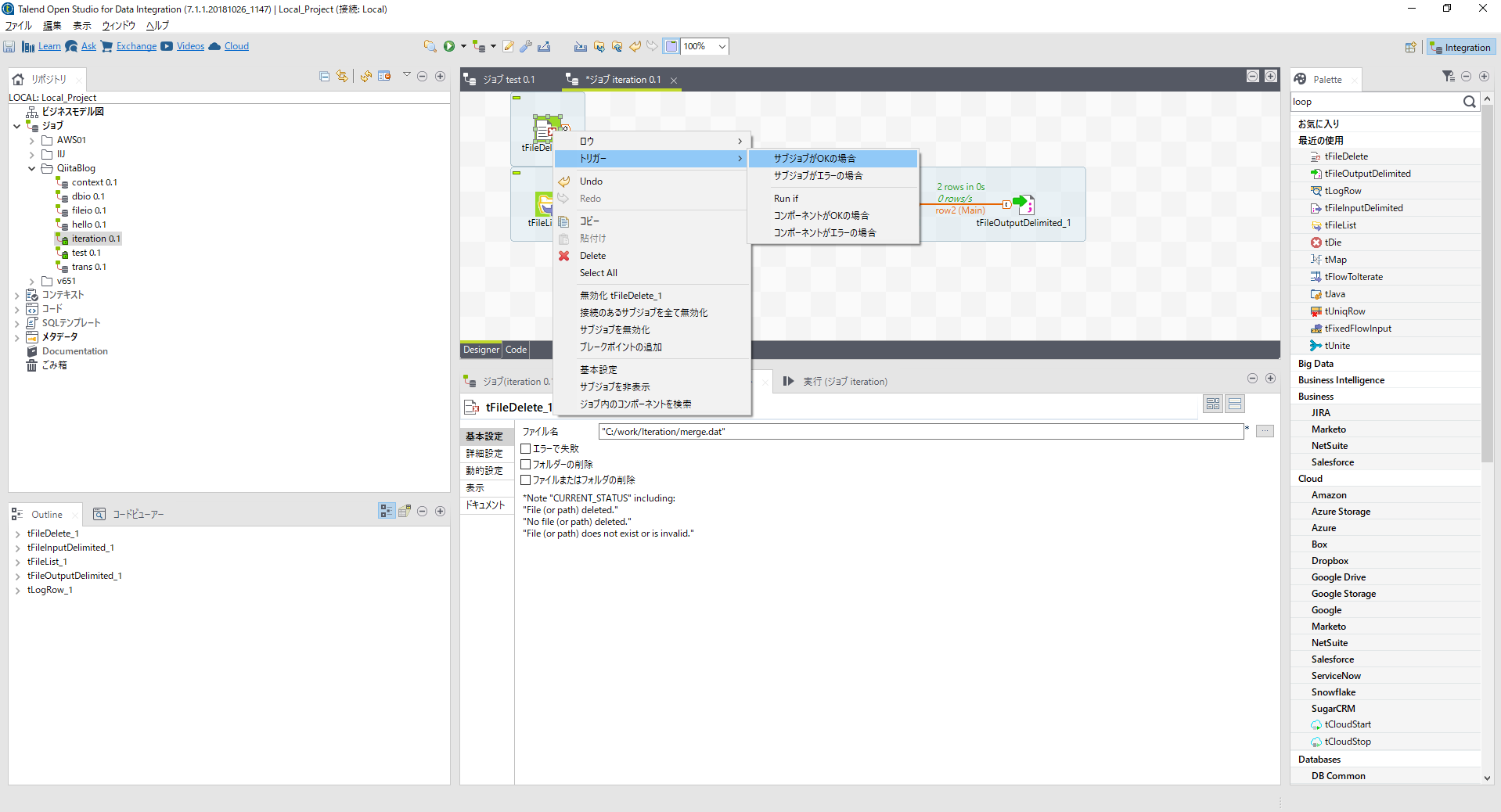
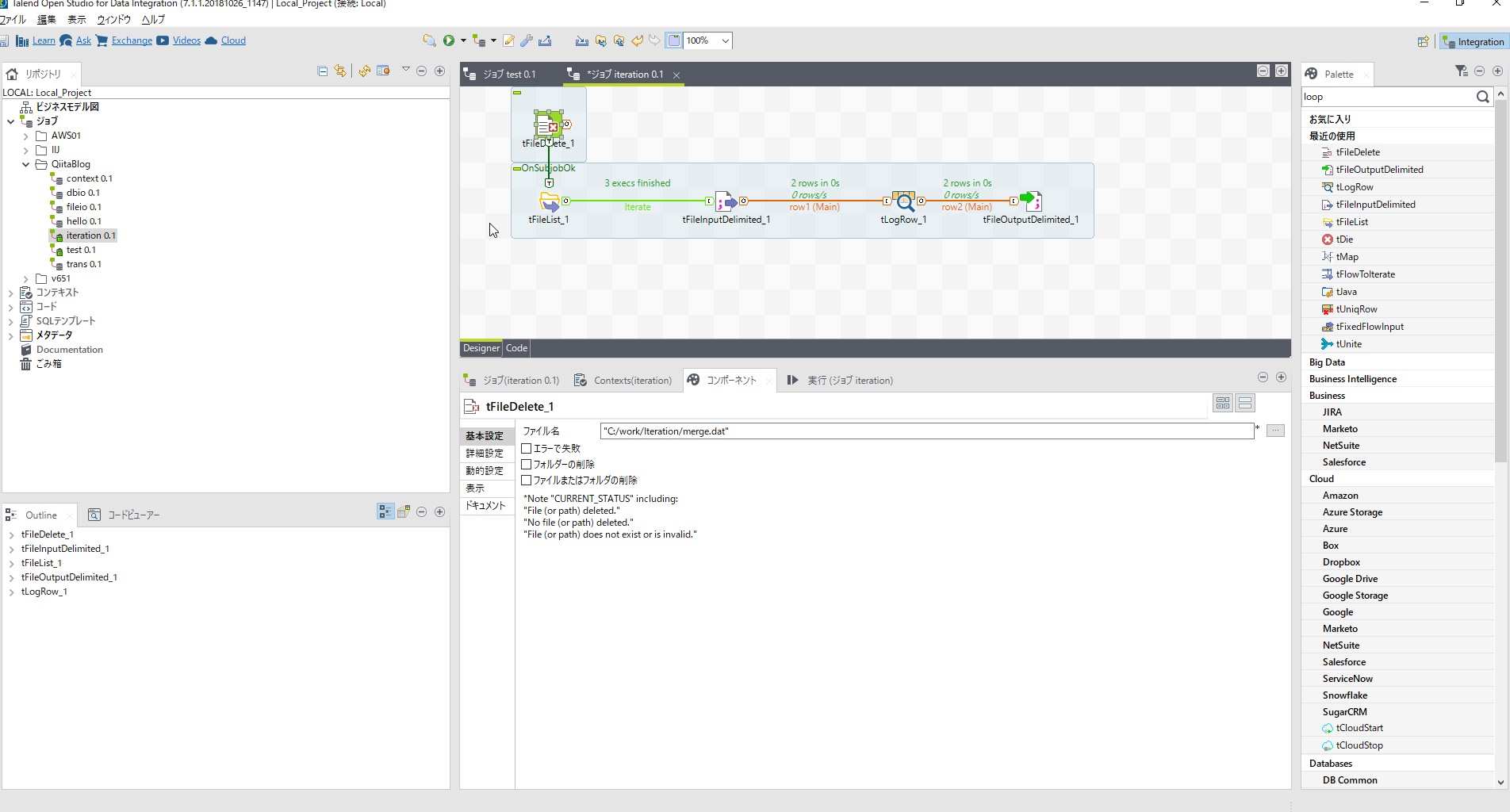
毎回削除(初期化)されているか念のため実行確認しておきましょう。
社員毎のユニークデータを生成
[tFileInputDelimited]コンポーネントを配置しパラメータを設定します。
※最初の[tFileInputDelimited_1]をコピペすると楽です。
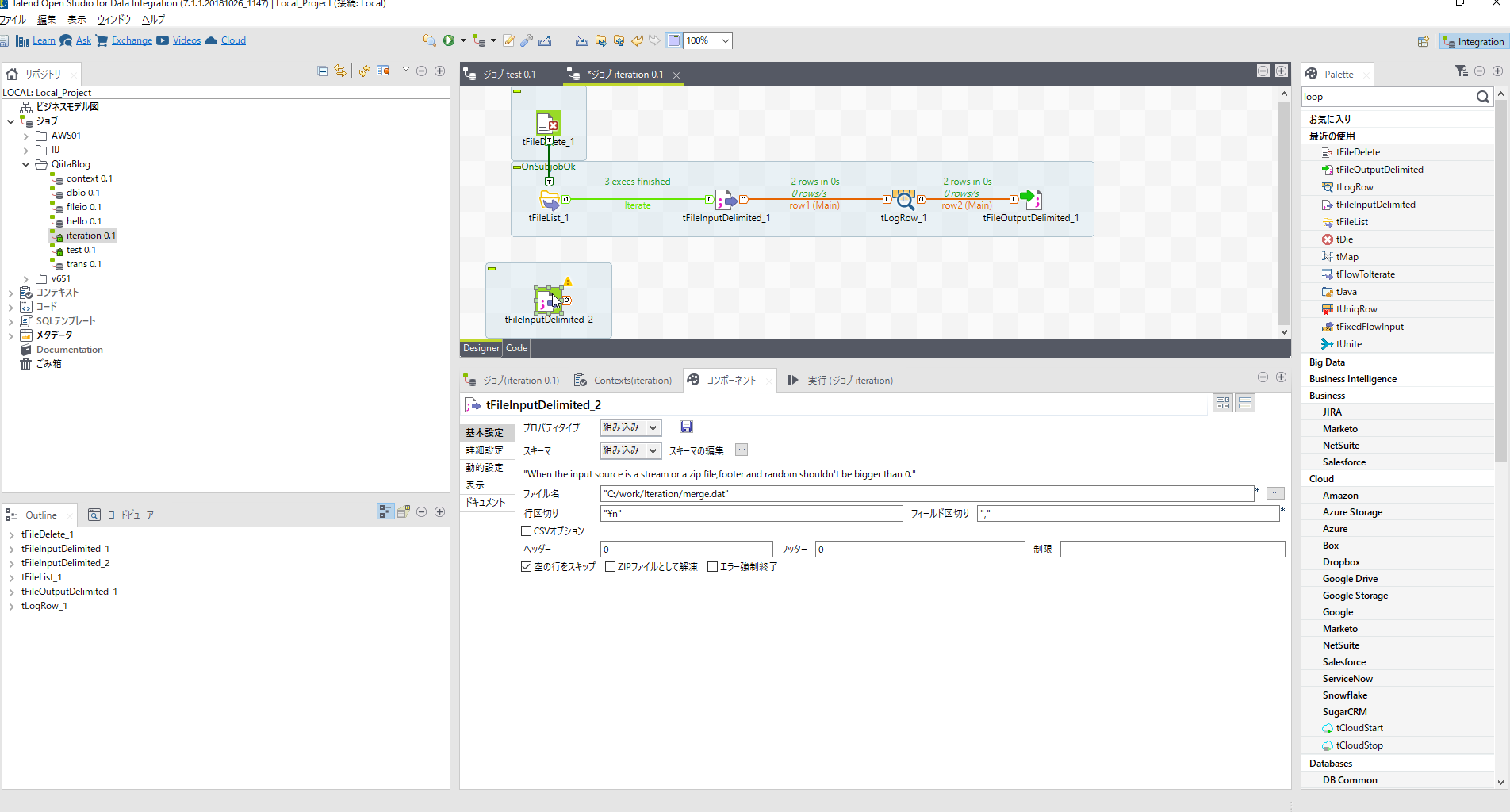
| 項目名 | 設定内容 | 説明 |
|---|---|---|
| ファイル名 | "C:/work/Iteration/merge.dat" | |
| フィールド区切り | "," | |
| エンコーディング | UTF-8 | 詳細設定タブ |
| スキーマ編集 | 上記参照 | [tFileInputDelimited]と同じ |
[tFileList_1]コンポーネントを右クリックし[トリガー][サブジョブがOKの場合]を選び[tFileInputDelimited_2]につなぎます。
[tUniqRow]を配置し、[tFileInputDelimited_2]とロウでつなぎます。
そのうえでパラメータを設定します。
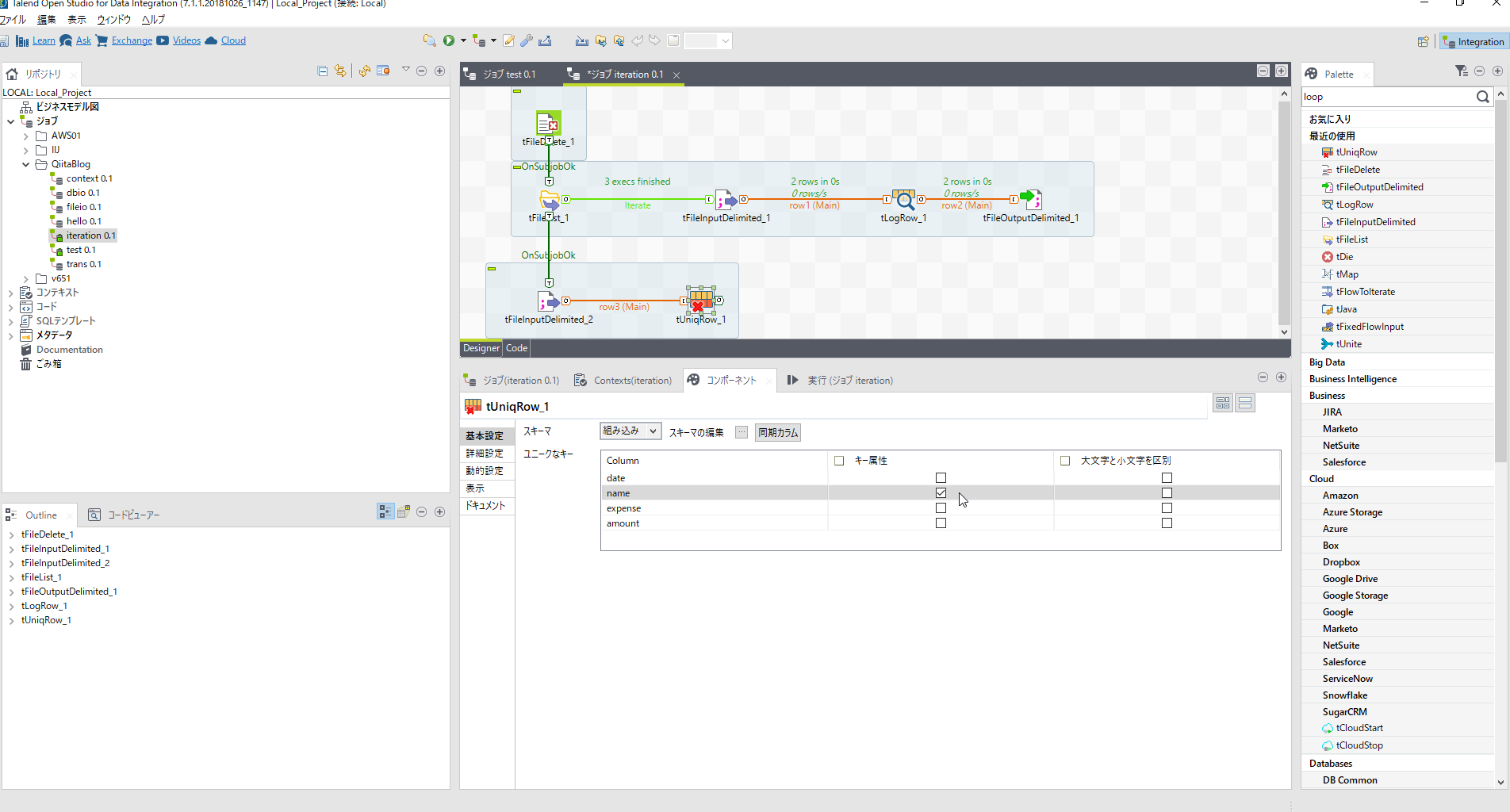
| 項目名 | 設定内容 | 説明 |
|---|---|---|
| ユニークなキー | nameのキー属性にチェック |
ここで[tLogRow]を配置し[tUniqRow]とつないだうえで一度出力を確認してみましょう。nameでユニークなデータを作れたことが確認できます。
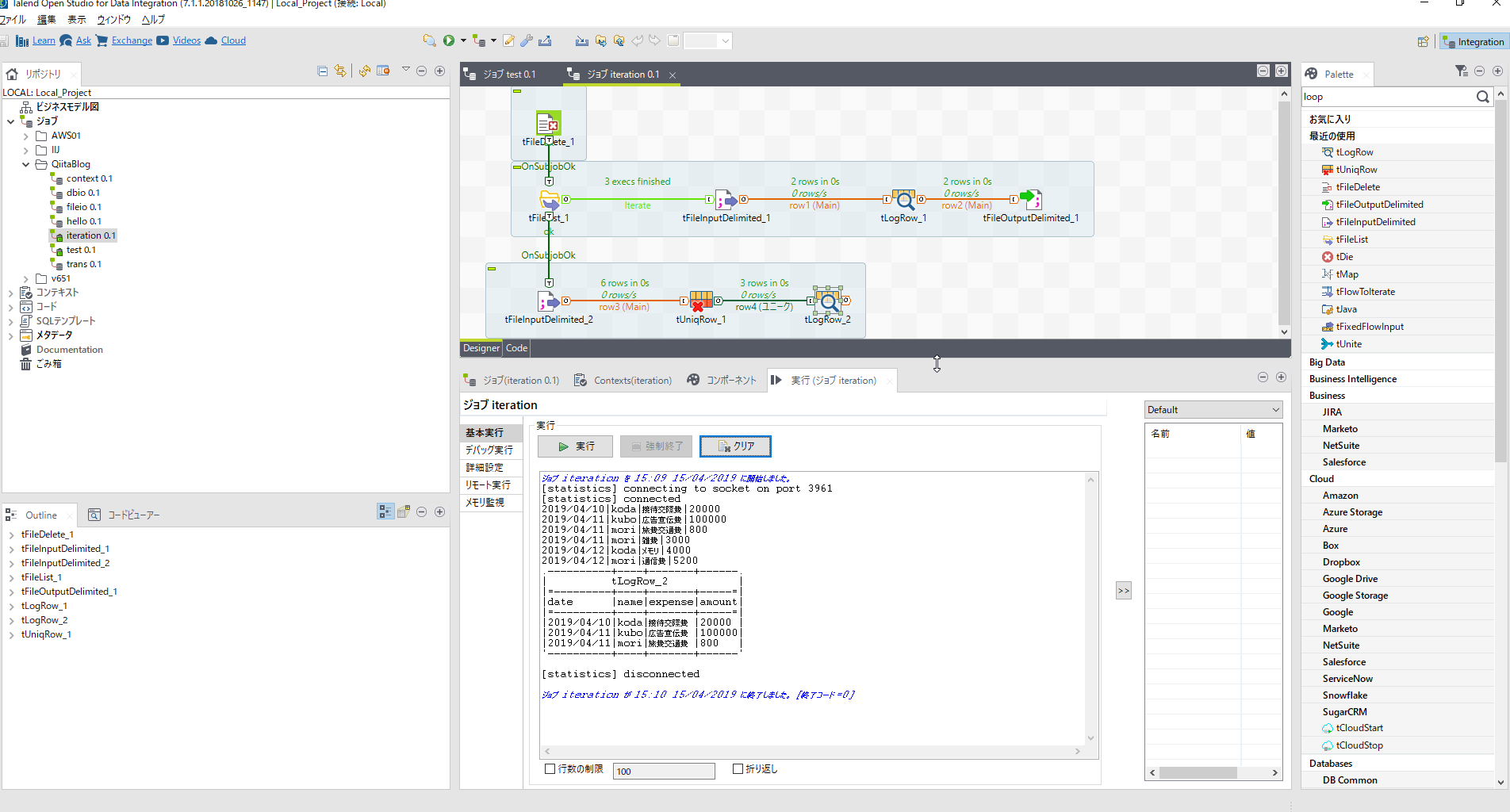
ロウ毎にイテレート
本日2回目のイテレートの登場です。
[tFlowToIterate]コンポーネントを配置し[tLogRow_2]とロウでつなぎます。
これでname毎のloop処理ができます。
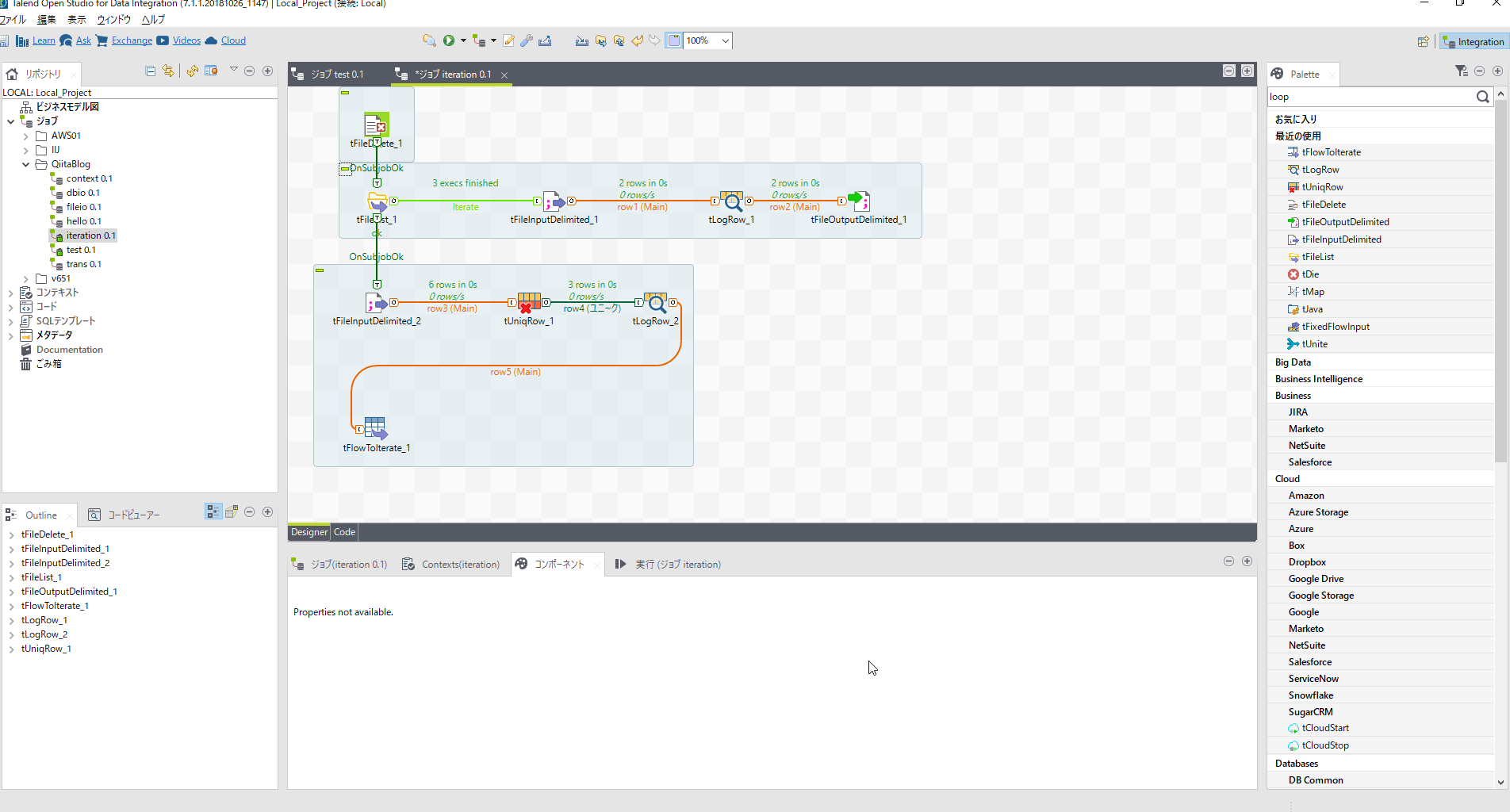
再度merge.datを読み込みます。
[tFileInputDelimited_3]は[tFileInputDelimited_2]と同じ内容なのでコピペでOKです。
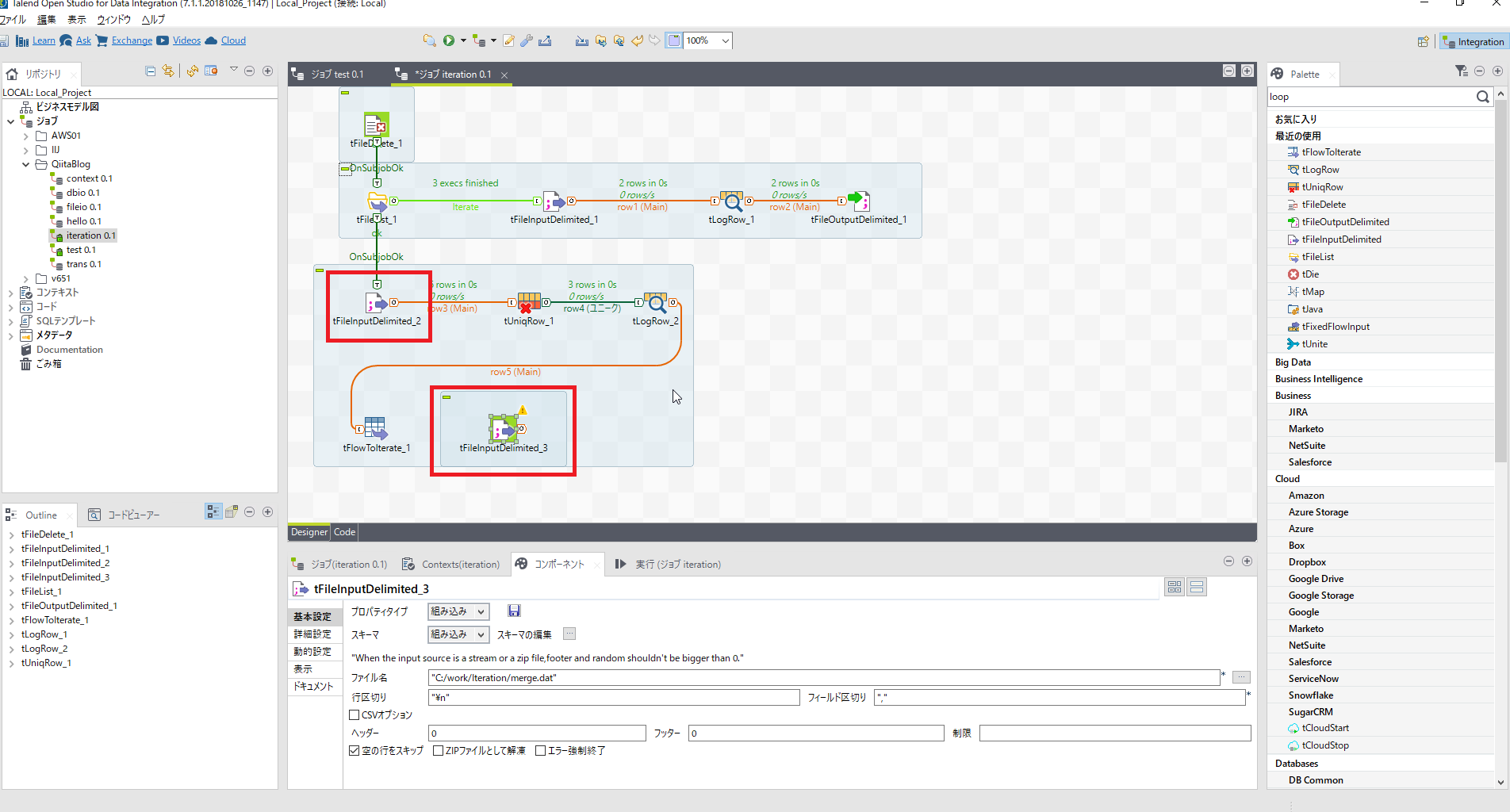
[tFlowToIterate_1]コンポーネントを右クリックし[ロウ]-[反復]を選び[tFileInputDelimited_3]につなぎます。
name単位の処理をするために[tMap]コンポーネント配置し[tFileInputDelimited_3]とロウをつなぎます。
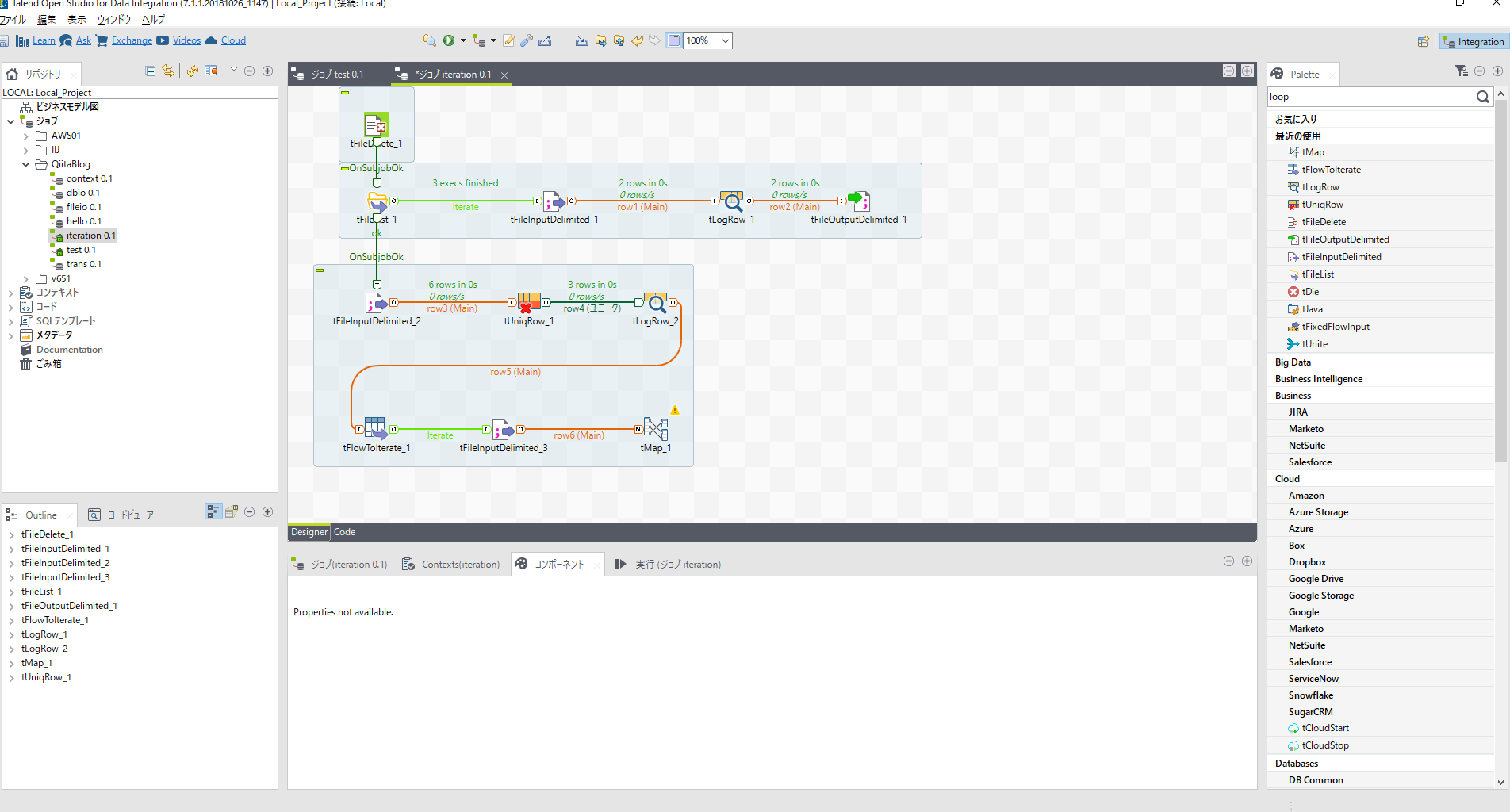
[tMap]をダブルクリックし、マッピング設定画面を開きます。
row6の式フィルターボタンをクリックし式を記入します。
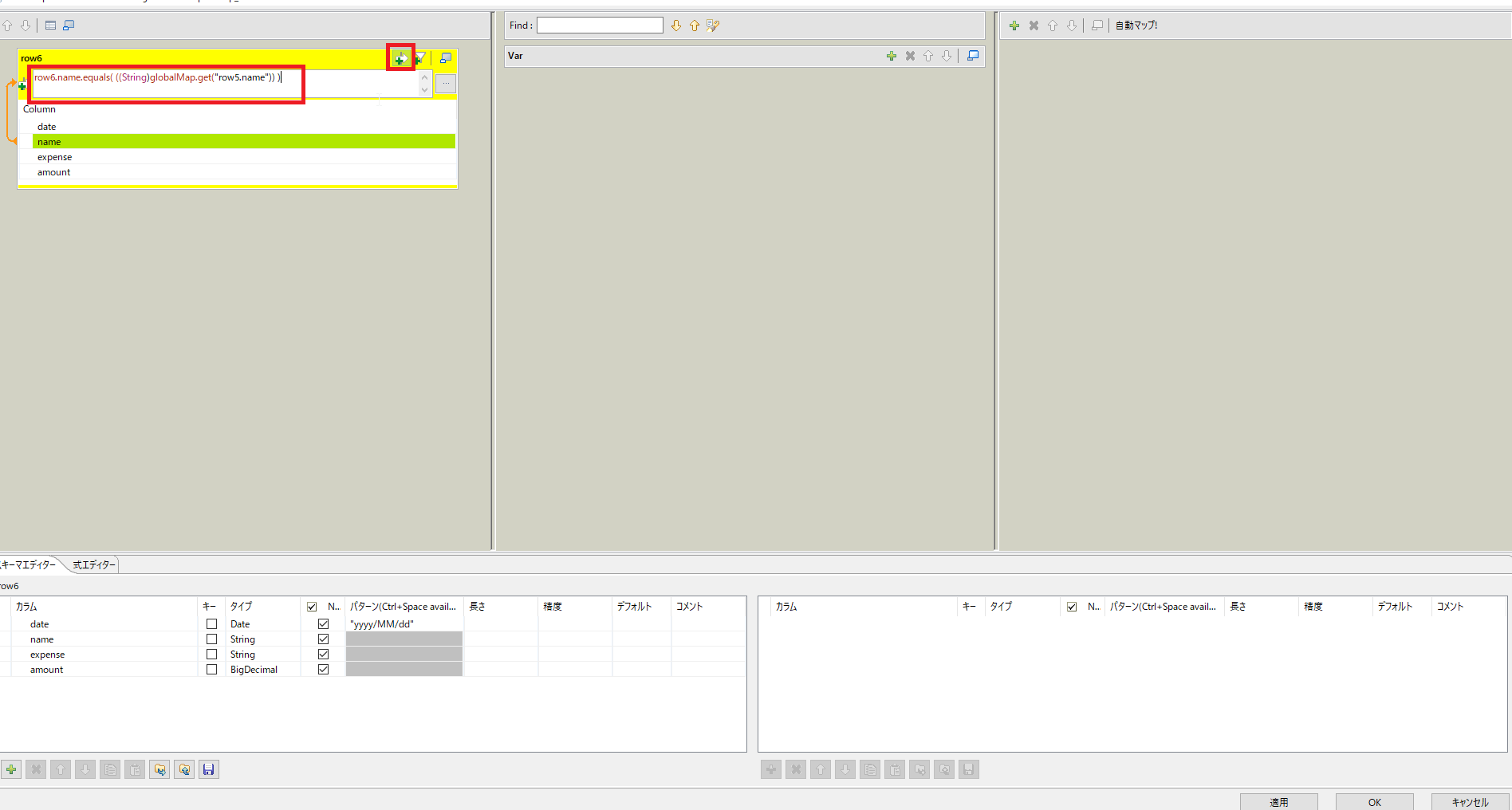
| 項目名 | 設定内容 | 説明 |
|---|---|---|
| row6の式フィルタ | row6.name.equals( ((String)globalMap.get("row5.name")) ) | イテレート処理中のnameとマッチさせる |
出力用のロウout1を作成します。
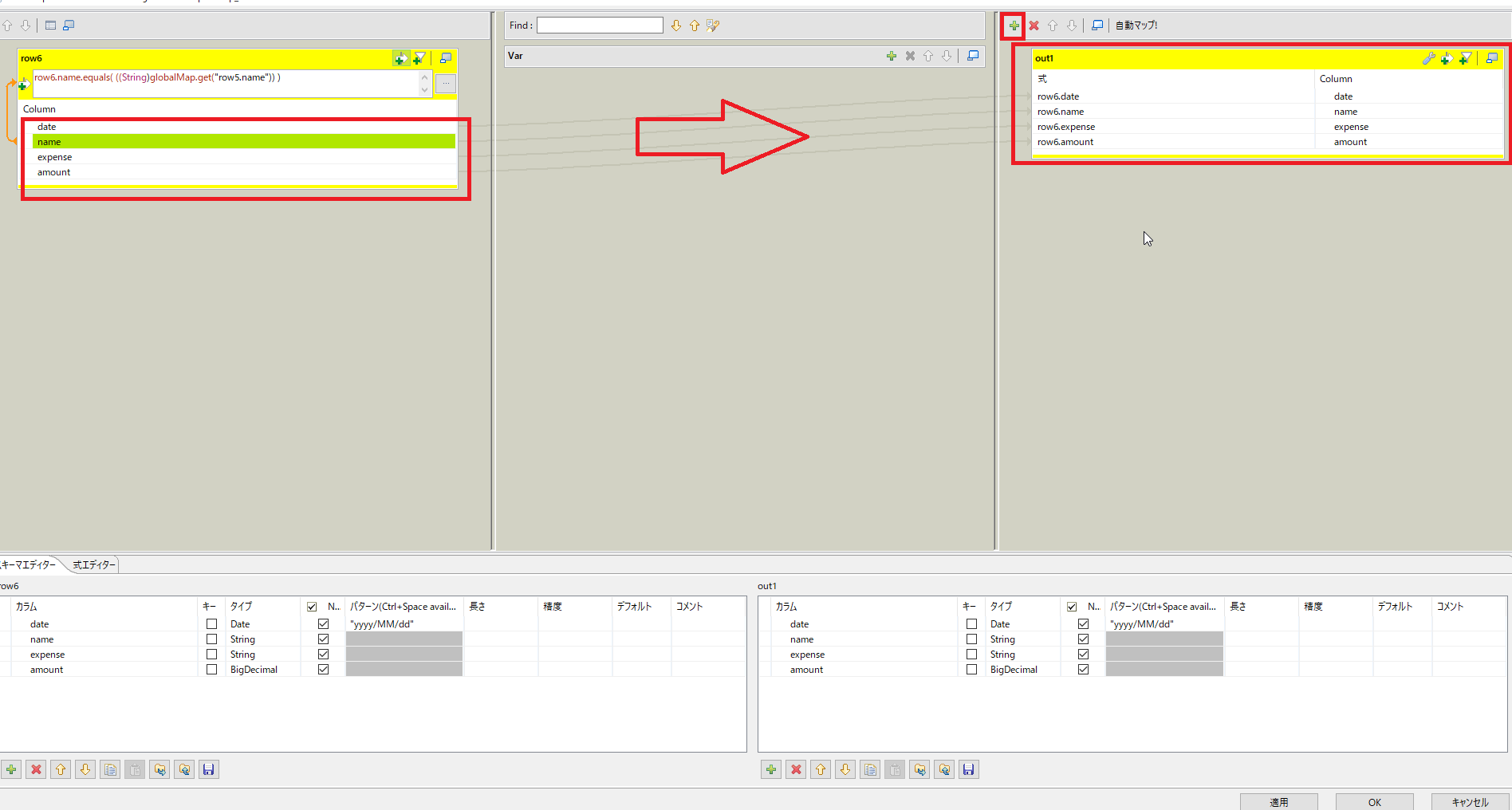
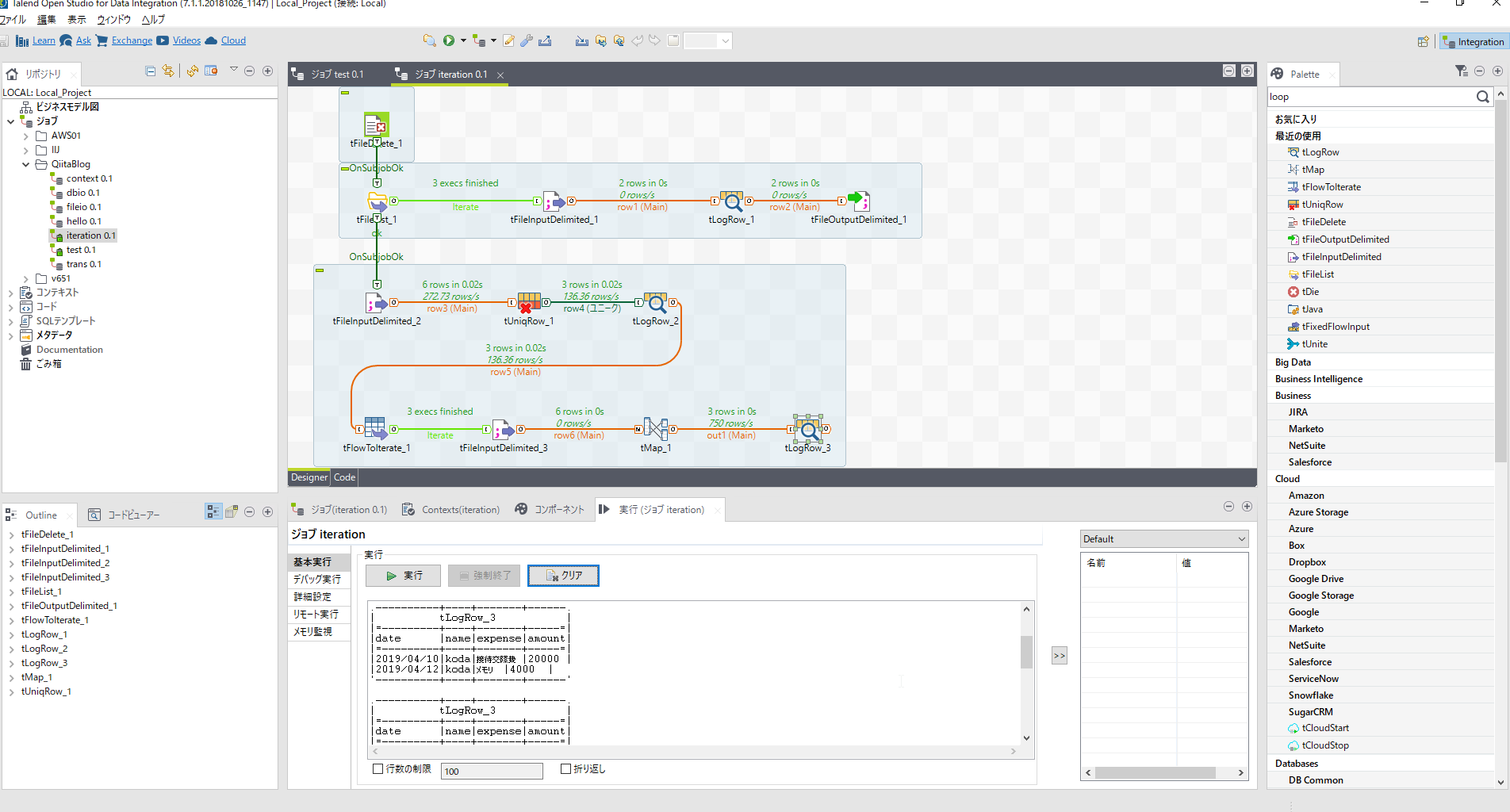
ここで[tLogRow]を配置し[tMap]のout1ロウとつないだうえで実行して出力を確認してみましょう。
name単位で経費明細を抽出できたことをログ出力で確認できます。
.----------+----+-------+------.
| tLogRow_3 |
|=---------+----+-------+-----=|
|date |name|expense|amount|
|=---------+----+-------+-----=|
|2019/04/10|koda|交際費 |20000 |
|2019/04/12|koda|メモリ |4000 |
'----------+----+-------+------'
.----------+----+-------+------.
| tLogRow_3 |
|=---------+----+-------+-----=|
|date |name|expense|amount|
|=---------+----+-------+-----=|
|2019/04/11|kubo|宣伝費 |100000|
'----------+----+-------+------'
.----------+----+-------+------.
| tLogRow_3 |
|=---------+----+-------+-----=|
|date |name|expense|amount|
|=---------+----+-------+-----=|
|2019/04/11|mori|交通費 |800 |
|2019/04/11|mori|雑費 |3000 |
|2019/04/12|mori|通信費 |5200 |
'----------+----+-------+------'
ここまで来たらあとは実際のファイルに出力するだけです。
[tFileOutputDelimited_2]コンポーネントを配置しパラメータを設定します。
※[tFileOutputDelimited_1]をコピペすると楽です。
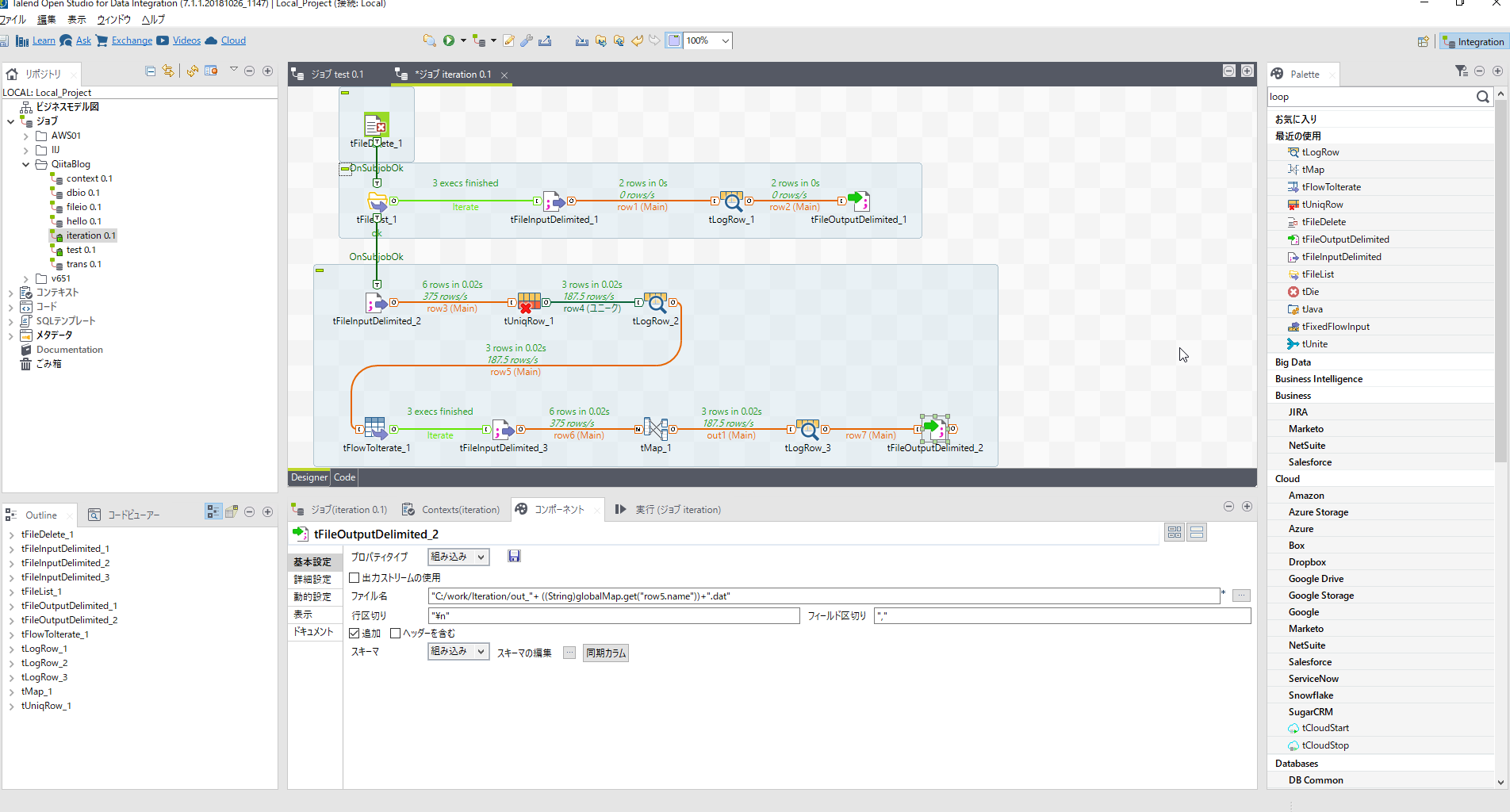
| 項目名 | 設定内容 | 説明 |
|---|---|---|
| ファイル名 | "C:/work/Iteration/out_"+ ((String)globalMap.get("row5.name"))+".dat" | |
| フィールド区切り | "," | |
| エンコーディング | UTF-8 | 詳細設定タブ |
| スキーマ編集 | 上記参照 |
それでは実行してみましょう。
name(従業員名)毎のファイルを作成できました。
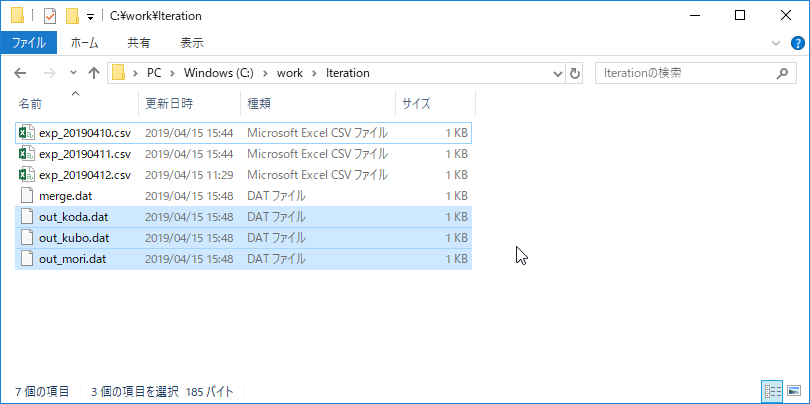
2019/04/10,koda,交際費,20000
2019/04/12,koda,メモリ,4000
2019/04/11,kubo,宣伝費,100000
2019/04/11,mori,交通費,800
2019/04/11,mori,雑費,3000
2019/04/12,mori,通信費,5200
仕上げ
同じジョブを複数回実行してもファイルの都度上書きが起こらないよう対応しましょう。
出力ファイルの初期化処理を設定します。
[tFileDelete]コンポーネントを配置しパラメータを設定します。
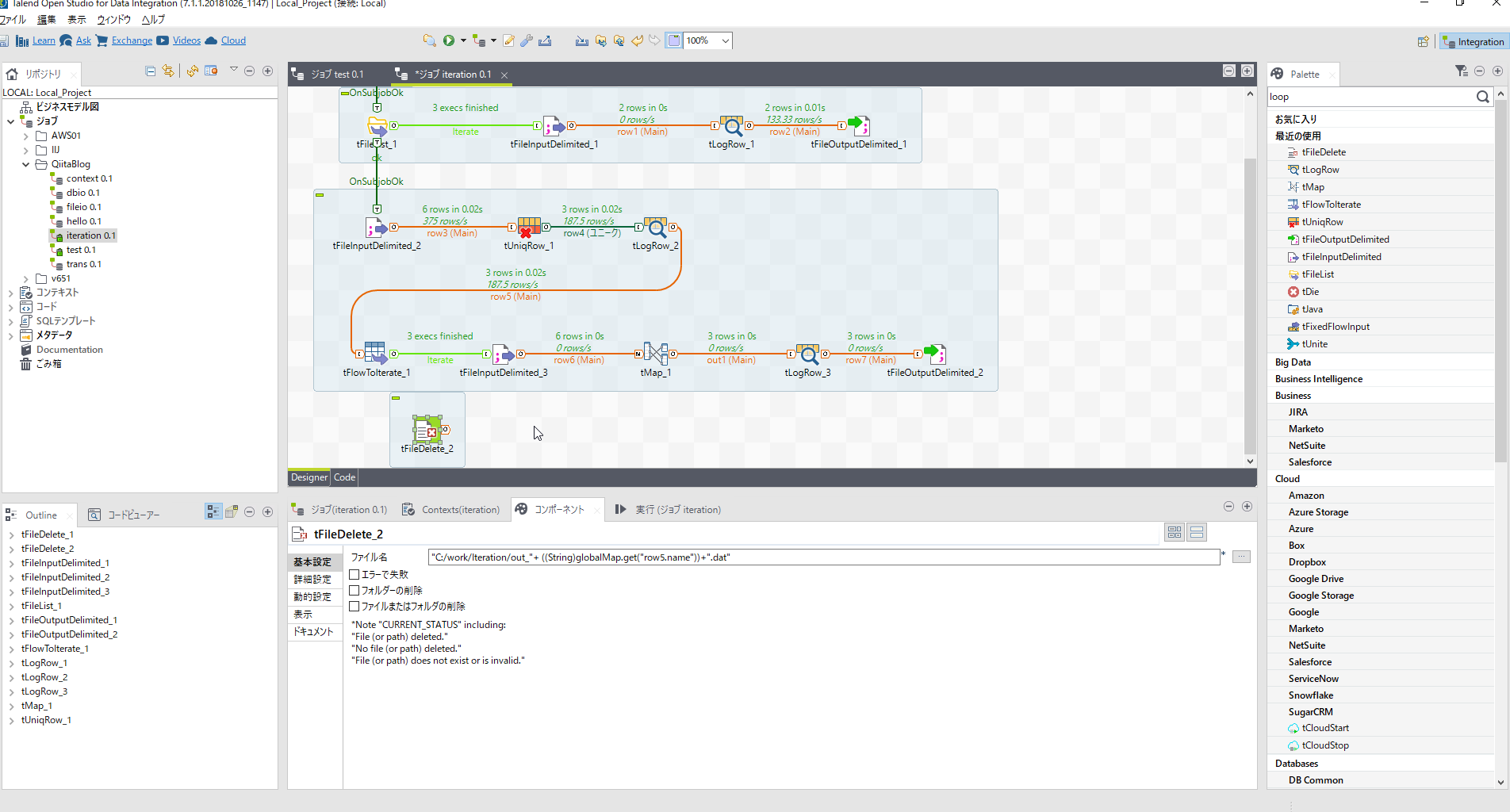
| 項目名 | 設定内容 | 説明 |
|---|---|---|
| ファイル名 | "C:/work/Iteration/out_"+ ((String)globalMap.get("row5.name"))+".dat" | |
| エラーで失敗 | チェックを外す |
[tFlowToIterate_1]と[tFileInputDelimited_3]の間に割り込ませます。
[tFileDelete_2]と[tFileInputDelimited_3]は[トリガー][コンポーネントがOKの場合]の線でつなぎます。
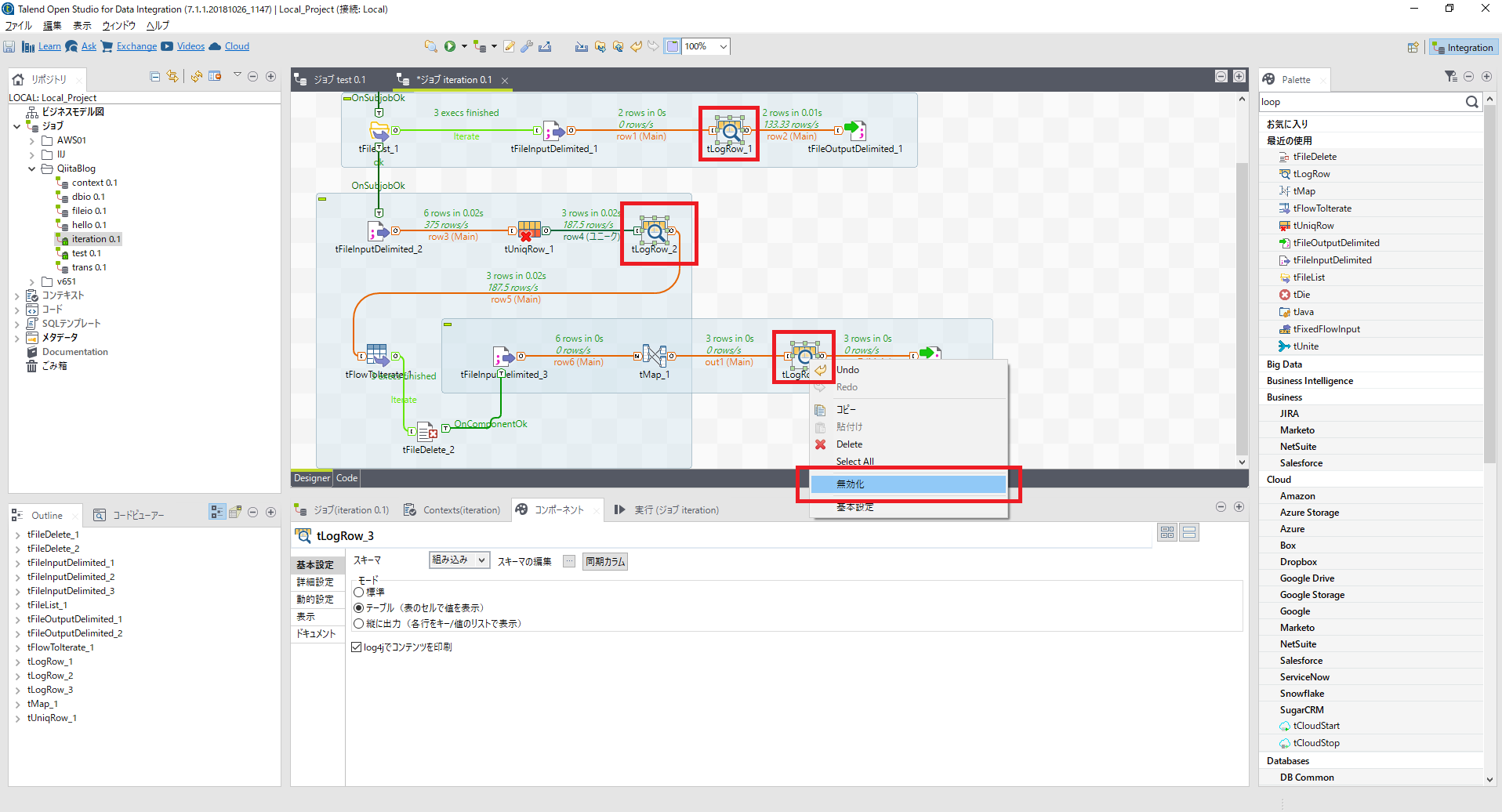
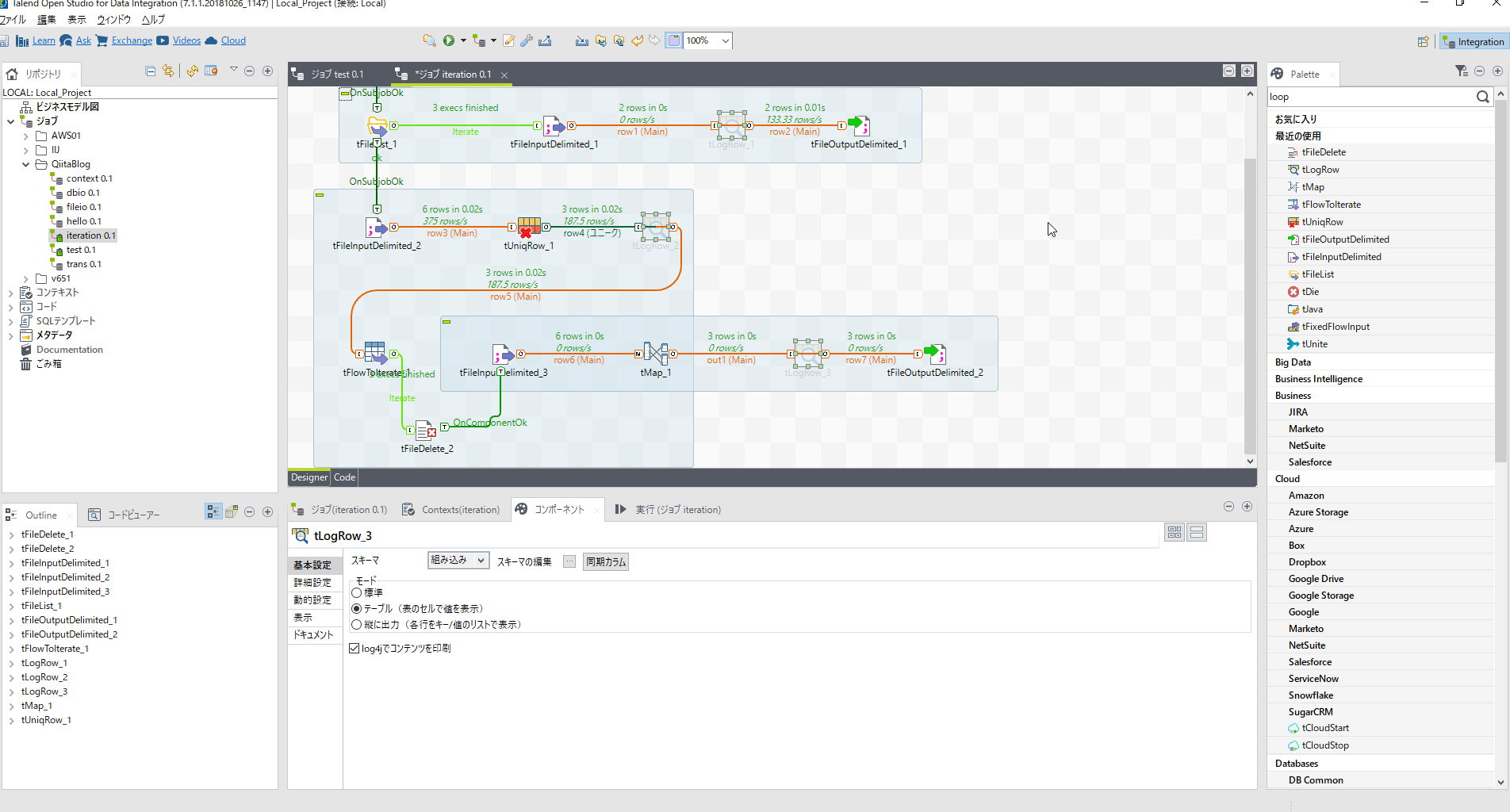
最後に[tLogRow]の出力も不要なので止めてしまいましょう。
[tLogRow]で右クリックし[無効化]を選択します。
まとめ
今回はイテレータの使い方を確認しました。
ロウとイテレータの使い分けで様々なデータ生成ができることをわかってもらえたと思います。
あらたに利用したコンポーネントと用途をおさらいしておきます。
- tFileList
- ファイル一覧取得
- tFileDelete
- ファイル削除
- tUniqRow
- キーを指定してユニークロウを作る
- tFlowToIterate
- 文字通りなんですが、ロウデータをイテレータに変換すると覚えておけばOK
毎度のことですが、ほんのさわりの部分だけを解説していますのでぜひここから深掘りしてみてください。
次回以降
次回はメタデータをやっていきます。