記事内容を三行で
- EC2とフレームワークを利用してやろう
- サーバレスでは組めない(組めるけど容量制限でNG)
- API Gateway便利(難しい)
追記
なるほど署名付き・・・
概要
容量が大きいファイルを共有するとき、メールではだいたい8MBを超えるとメールサーバなのでブロックされたりします。ブロックされてなくてもそもそも大容量のファイルをメールで送るにはサーバへ負荷を与えたりなど結構迷惑かなと思ったりします。なので、ストレージサービスを利用したいですが、Gigaファイル便だとセキュリティ規約で怒られそうだし(過去よく使ってましたが)、GoogleDriveはGoogleアカウントがないと共有に不安(URLを知っていないとアクセスできないとはいえ、全員がアクセスできる状態は厳しい)があります。
ほしいのは、一時的にID&パスをかけて、大容量ファイルをシェアできるURLがほしいだけなのに...(おわったら削除 or タイムリミット過ぎたら非公開になるとか)
そこで、最近awsのSAAに受かったことだし、復習もかねてawsで楽にファイル共有する仕組みできないかなとチャレンジしたのがこの記事が生まれたきっかけになります。
個人的にはサーバーのon/offであったり、監視もしたくなかったので、サーバーレスで組めないかなと進めました。
ちなみに、共有したいファイルの容量は約100MBのzipファイルです。
API GatewayとLambdaとS3で組む
各サービスのそれぞれの役割
API Gateway
Lambdaを公開するためと、公開するURLにBasic認証をかけたいため。調べたらAPI Gatewayにはアクセスキーで認証させる方法と、Lambdaを用意しそれを使ってAPIのアクセスを制御することができる「API Gateway Lambda オーソライザー」という機能があります。
Lambda
「API Gateway Lambda オーソライザー」を使用するためにBasic認証をかけるLambda関数の用意と、Basic認証後にzipファイルをダウンロードさせるためのページ2つをLambda関数で用意。
1つはHTMLを表示して、ダウンロードするファイルを選択してもらう。最初はURL踏んだらダウンロードで良いと考えていたが、複数ファイルがあった場合どうすべ?ってなったのでHTMLページを用意することにした。(今考えるとquery parameterでよかったっすね。はい。。。 → って思ったけど、やっぱだめだったわ。後述。)
もうひとつはS3からファイルダウンロード & zipファイル(バイナリ)を返すLambda関数を用意。
S3
ダウンロードしたいzipファイル置き場、またHTMLテンプレート置き場として利用。
構成図
TODO: 図を作って貼る
実装・設定
Lambda
関数名: download___auth
basic認証を行うlambda
import json
import os
import base64
def lambda_handler(event, context):
policy = {
'principalId': 'user',
'policyDocument': {
'Version': '2012-10-17',
'Statement': [
{
'Action': 'execute-api:Invoke',
'Effect': 'Deny',
'Resource': event['methodArn']
}
]
}
}
if not basic_auth(event):
print('Auth Error!!!')
return policy
policy['policyDocument']['Statement'][0]['Effect'] = 'Allow'
return policy
def basic_auth(event):
if 'headers' in event.keys() and 'authorization' in event['headers'].keys():
auth_header = event['headers']['authorization']
# lambdaの環境変数から情報を取得.
user = os.environ['USER']
password = os.environ['PASSWORD']
print(os.environ)
_b64 = base64.b64encode('{}:{}'.format(user, password).encode('utf-8'))
auth_str = 'Basic {}'.format(_b64.decode('utf-8'))
return auth_header == auth_str
raise Exception('Auth Error!!!')
関数名: download___index
ダウンロードできるファイルをHTMLで表示するlambda。HTMLのテンプレートはS3から取得。テンプレートエンジンはjinja。
from jinja2 import Template
import boto3
from botocore.exceptions import ClientError
import os
import logging
logger = logging.getLogger()
S3 = boto3.resource('s3')
TEMPLATE_AWS_S3_BUCKET_NAME = 'hogehoge-downloader'
BUCKET = S3.Bucket(TEMPLATE_AWS_S3_BUCKET_NAME)
def get_object(bucket, object_name):
"""Retrieve an object from an Amazon S3 bucket
:param bucket_name: string
:param object_name: string
:return: botocore.response.StreamingBody object. If error, return None.
"""
try:
response = bucket.Object(object_name).get()
except ClientError as e:
# AllAccessDisabled error == bucket or object not found
logging.error(e)
return None
# Return an open StreamingBody object
return response['Body'].read()
def main():
index_html = get_object(BUCKET,
os.path.join('template', 'index.html')) \
.decode('utf8')
li_html = get_object(BUCKET,
os.path.join('template', 'file_li.html')) \
.decode('utf8')
index_t = Template(index_html)
insert_list = []
objs = BUCKET.meta.client.list_objects_v2(Bucket=BUCKET.name,
Prefix='files')
for obj in objs.get('Contents'):
k = obj.get('Key')
ks = k.split('/')
if ks[1] == '':
continue
file_name = ks[1]
print(obj.get('Key'))
li_t = Template(li_html)
insert_list.append(li_t.render(
file_url='#',
file_name=file_name
))
output_html = index_t.render(file_li=''.join(insert_list))
return output_html
def lambda_handler(event, context):
output_html = main()
return {
"statusCode": 200,
"headers": {
"Content-Type": 'text/html'
},
"isBase64Encoded": False,
"body": output_html
}
関数名: download___download
s3からファイルをダウンロードするlambda
import boto3
from botocore.exceptions import ClientError
import os
import logging
import base64
logger = logging.getLogger()
S3 = boto3.resource('s3')
TEMPLATE_AWS_S3_BUCKET_NAME = 'hogehoge-downloader'
TEMPLATE_BUCKET = S3.Bucket(TEMPLATE_AWS_S3_BUCKET_NAME)
def get_object(bucket, object_name):
"""Retrieve an object from an Amazon S3 bucket
:param bucket_name: string
:param object_name: string
:return: botocore.response.StreamingBody object. If error, return None.
"""
try:
response = bucket.Object(object_name).get()
except ClientError as e:
# AllAccessDisabled error == bucket or object not found
logging.error(e)
return None
# Return an open StreamingBody object
return response['Body'].read()
def lambda_handler(event, context):
file_name = event['queryStringParameters']['fileName']
body = get_object(TEMPLATE_BUCKET, os.path.join('files', file_name))
return {
"statusCode": 200,
"headers": {
"Content-Disposition": 'attachment;filename="{}"'.format(file_name),
"Content-Type": 'application/zip'
},
"isBase64Encoded": True,
"body": base64.b64encode(body).decode('utf-8')
}
API Gateway
初期構築
- APIタイプはREST APIを選択
こんな感じで構築。
オーソライザーの設定
Basic認証を行うlambda関数と連携するよう設定する。
下記のように設定する。認可のキャッシュのチェックを外すのに注意。(チェック入れたままだと複数リソースを設定した場合、変な動き方をする)

authの設定はこれで完了です。あとは各メソッドで設定すればおkです。
リソース・メソッドの作成
下記のようにリソース・メソッドを用意する。
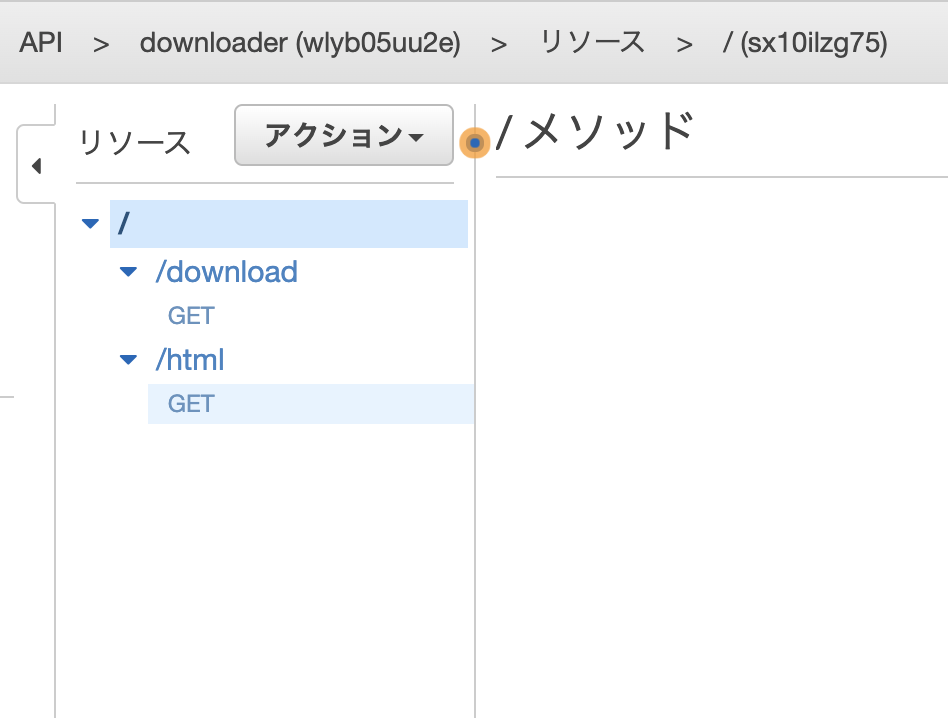
それぞれの詳細の設定についてはこれから説明する。
/html
lambdaプロキシ統合の使用にチェックをいれる。これをいれることで、lambda側でheaderなどを定義できるようにする。
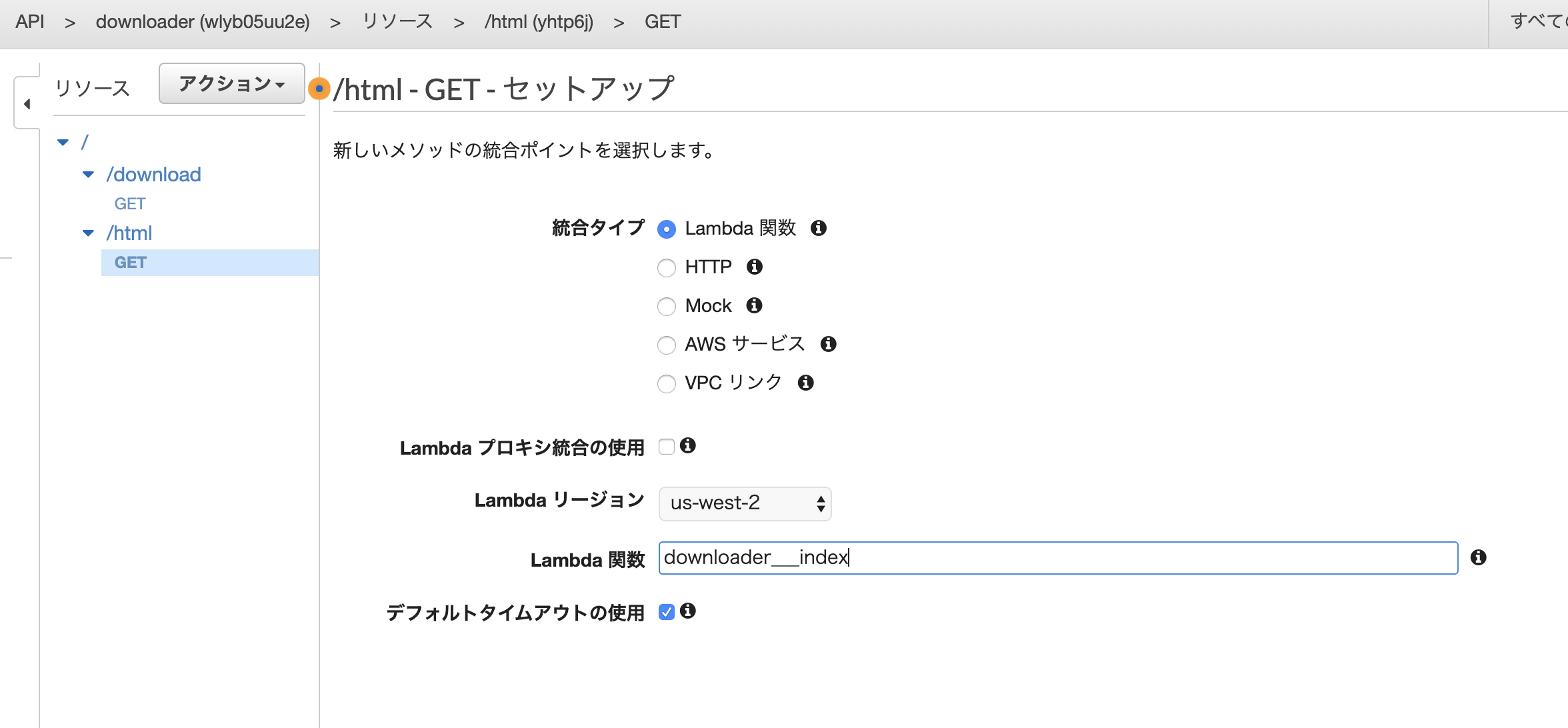
メソッドリクエストにBasic認証で認証するように設定。
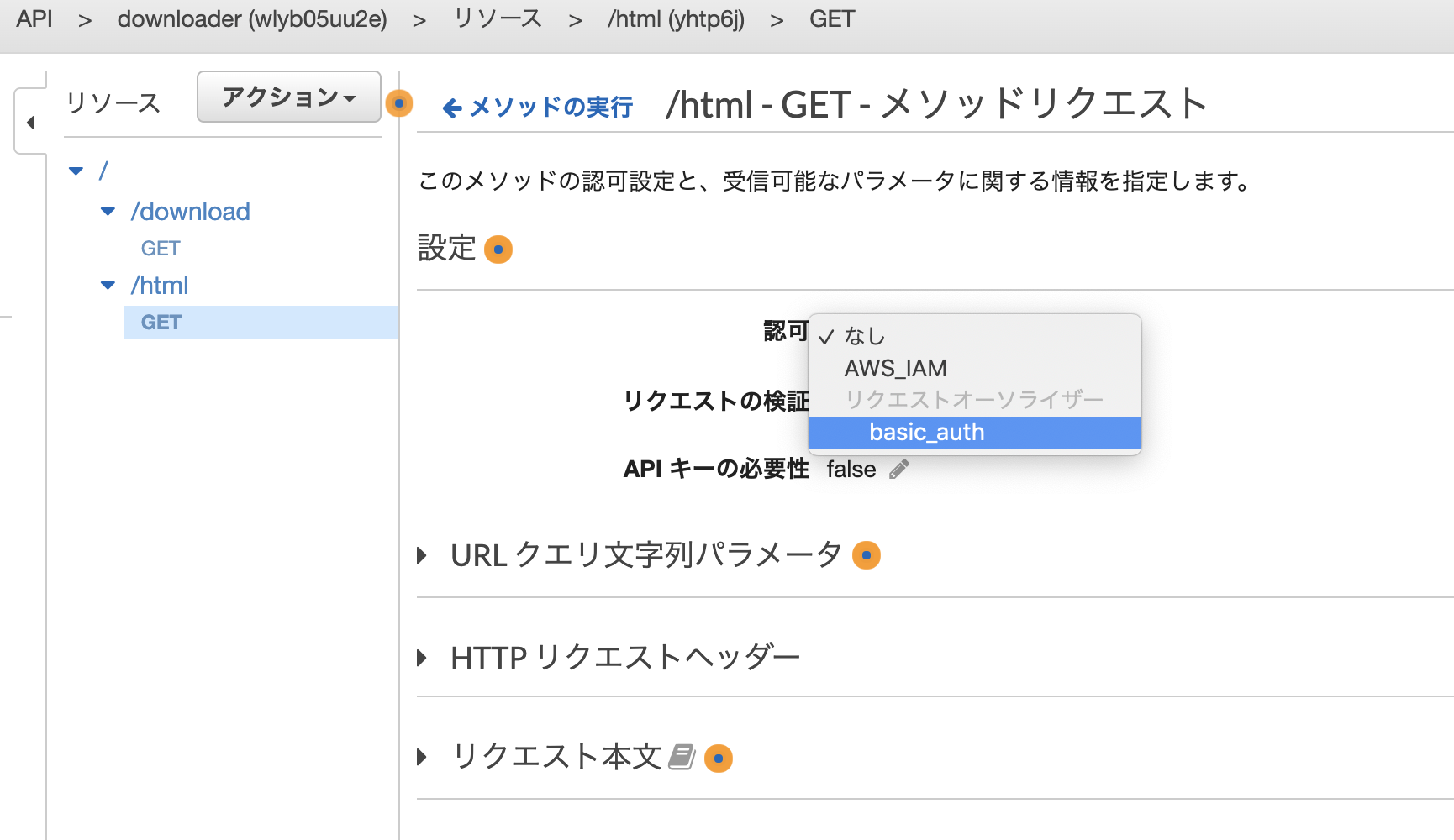
メソッドレスポンスにて、htmlを認識できるように修正。レスポンス本文のコンテンツタイプを text/html に修正する。
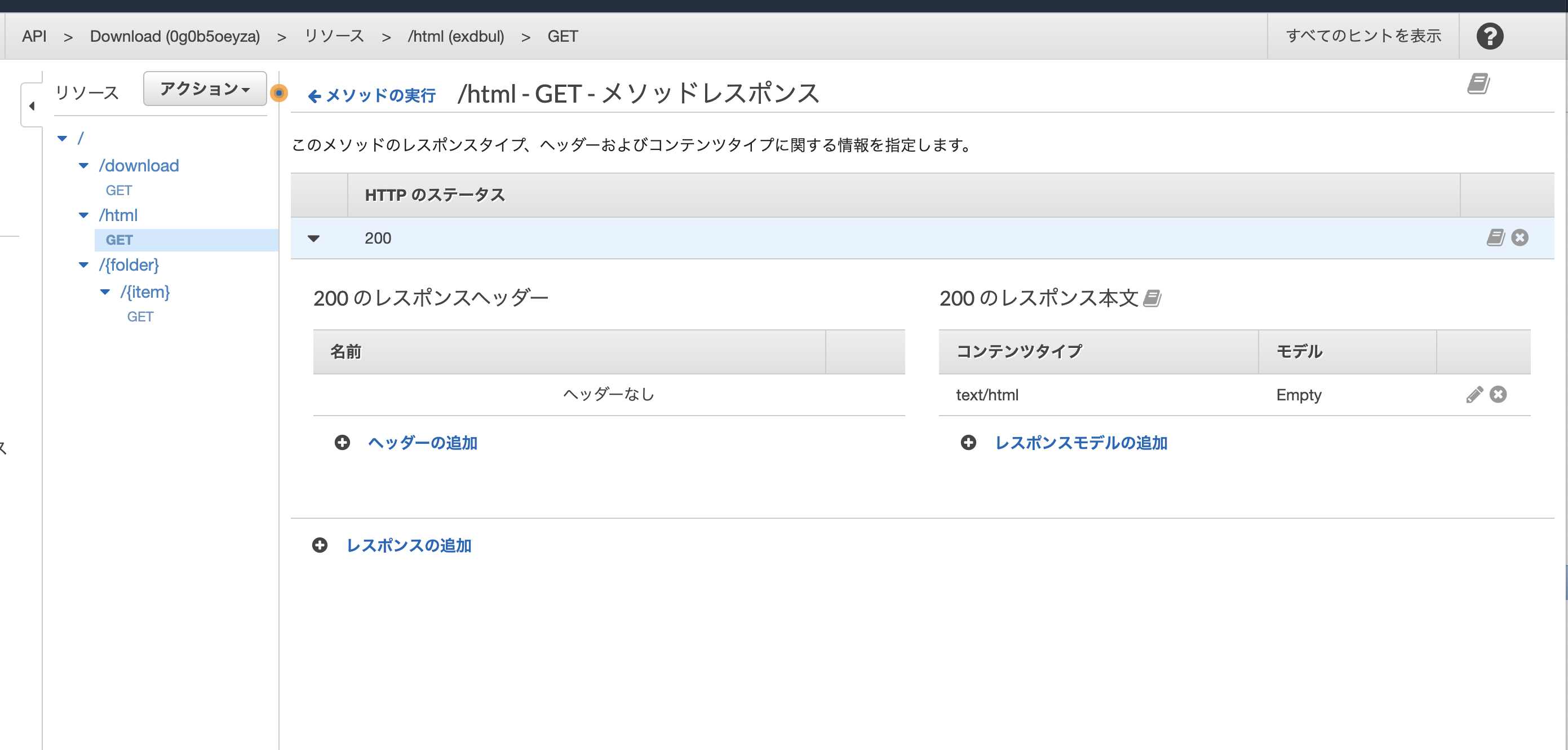
これで設定完了。
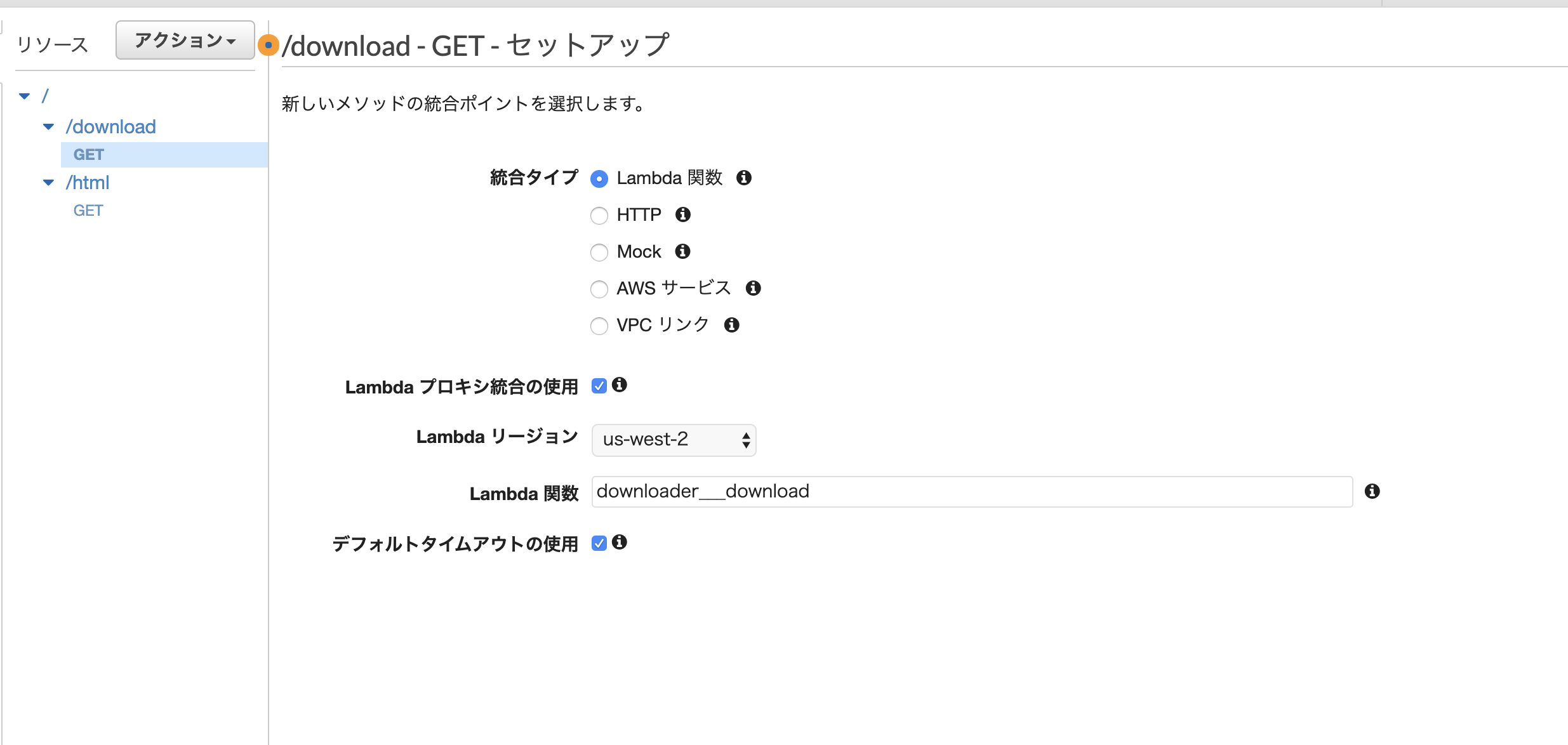
/download
HTML側と同様に、lambdaプロキシ統合の使用にチェックをいれる。
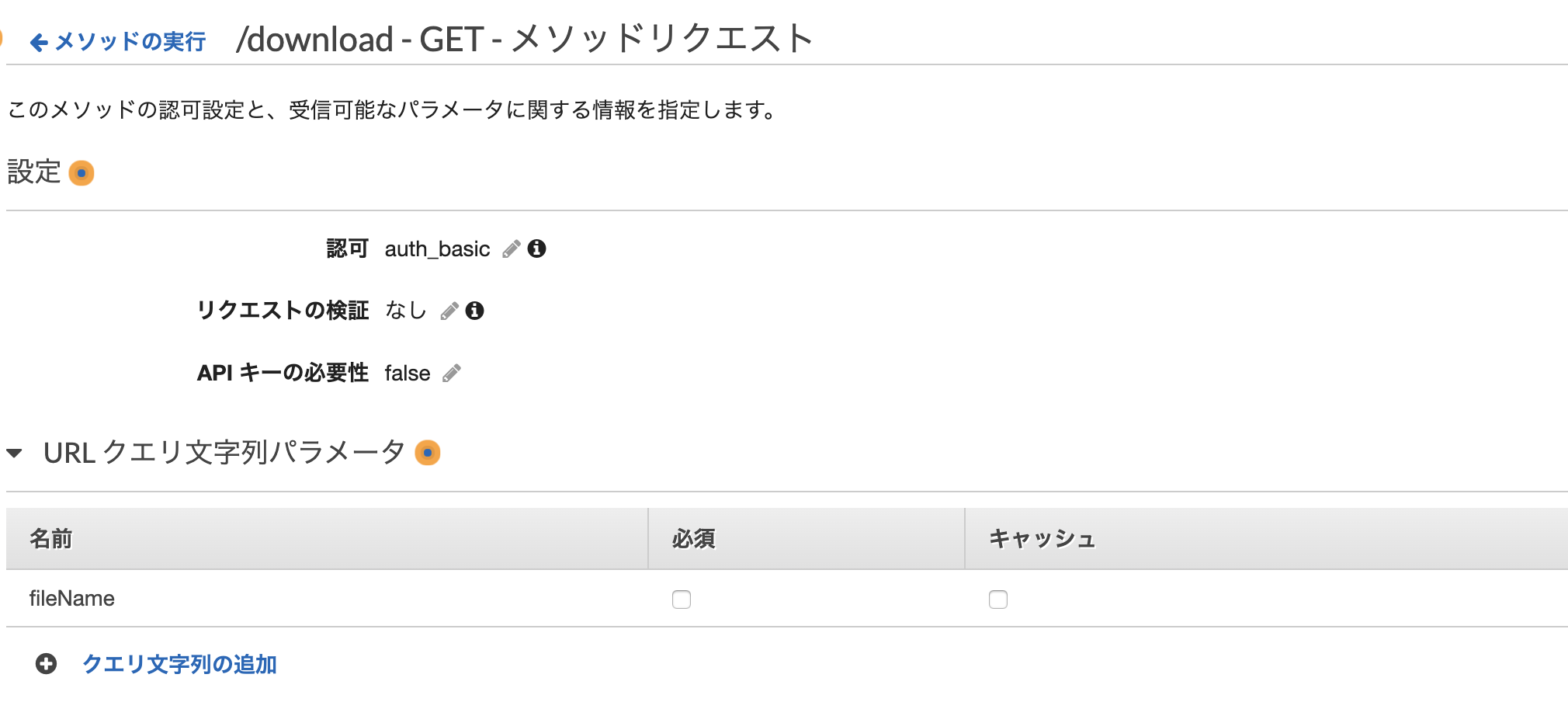
ここも同様にBasic認証を設定。
また、ダウンロードするファイル名をパラメータで受け取りたいため、URLクエリ文字列パラメータに fileName という名前のパラメータを設定。(必須にしたい場合はチェックを入れればよい)
zipファイルをダウンロードさせたいため、メソッドレスポンスのコンテンツタイプを変更。
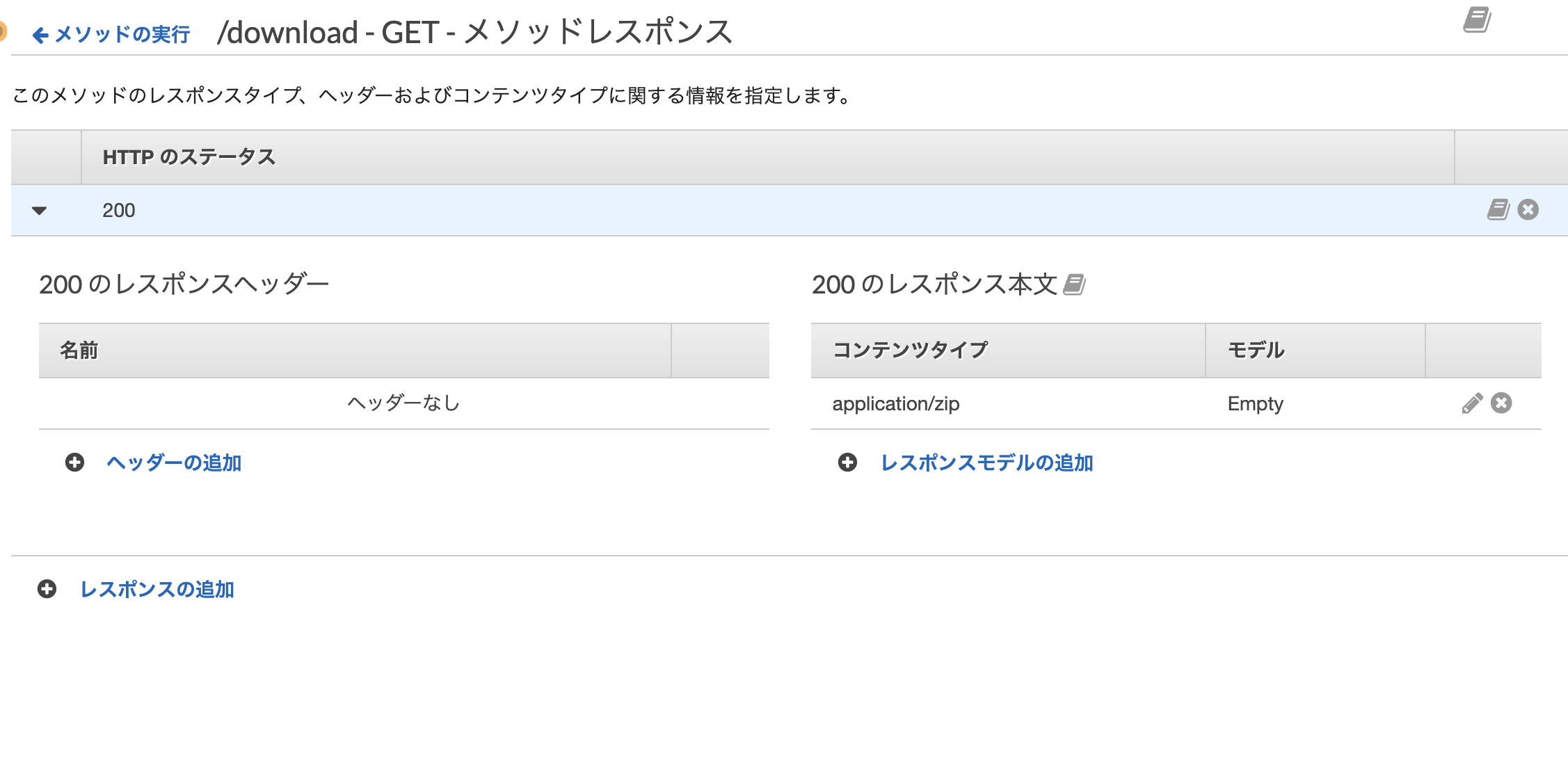
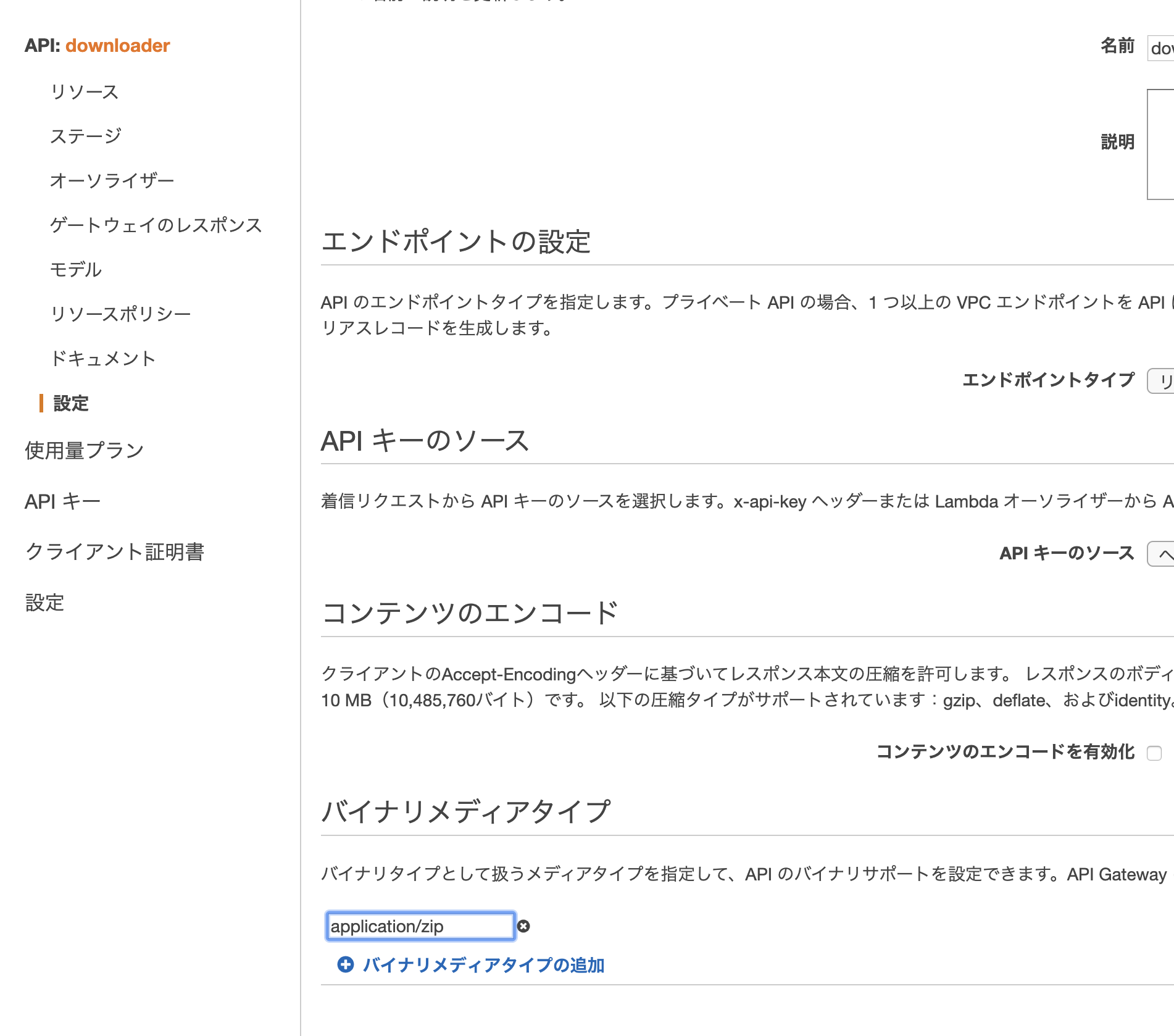
最後に、左メニューにある設定からバイナリメディアタイプを追加。ここに対象のコンテンツタイプを設定することで、lambdaからの返却値(base64)がバイナリに変換されるようになる。(ただし、リクエストヘッダーにContent-type、またはAcceptに application/zip を追加してあげないといけない)
S3
bucket名: hogehoge-downloader を作成し、下記ディレクトリを作成.
-
files: zipファイルを格納 -
template: HTMLテンプレートファイルを用意
HTMLテンプレートは適当に作った下記。
index.html
<!DOCTYPE html>
<html>
<head>
<meta charset="utf-8">
<meta name="viewport" content="width=device-width, initial-scale=1">
<title>ダウンローダー</title>
<link rel="stylesheet" href="https://cdn.jsdelivr.net/npm/bulma@0.8.0/css/bulma.min.css">
<script defer src="https://use.fontawesome.com/releases/v5.3.1/js/all.js"></script>
</head>
<body>
<section class="section">
<div class="container">
<div class="container">
<ul>{{ file_li }}</ul>
</div>
</div>
</section>
</body>
<script src="https://unpkg.com/axios/dist/axios.min.js"></script>
<script>
function download(e) {
const zipUrl = 'https://xxx.aws.com/prod/download?fileName=' + this.filename;
const blob = axios.get(zipUrl, {
responseType: 'blob',
headers: {
Accept: 'application/zip'
},
}).then(response => {
window.URL = window.URL || window.webkitURL;
const uri = window.URL.createObjectURL(response.data);
const link = document.createElement('a');
link.download = this.filename;
link.href = uri;
link.click()
}).catch(error => {
console.log(error);
});
}
var links = Array.from(document.getElementsByClassName('downloadLink'));
links.map(l => l.addEventListener('click', {filename: l.dataset.filename, handleEvent: download}));
</script>
</html>
file_li.html
<li>
<a href="{{ file_url }}" class="downloadLink" data-filename="{{ file_name }}">{{ file_name }}</a>
</li>
ハマったこと
- オーソライザーのキャッシュ許可するとなぜかリソースごとに認証おk・NGがでてくる → キャッシュしないようにすると回避できる
- 設定の バイナリメディアタイプ はレスポンスにはフィルタ(?)されない。リクエストヘッダーのContent-typeとAcceptで処理される
- content-dispositionを使用する場合、lambdaでheaderを用意&Lambda プロキシ統合の使用にチェックいれると良い
問題点
しかし、この構成ではだめである。組むまで僕は気づかなかった。。。
実際組んでエラーを確認するまで気づかなかった。
このページを確認してほしい。
呼び出しペイロード (リクエストとレスポンス) 6 MB (同期)
ファッ!!???!!6MB???!!???
Dead end.
〜完〜
EC2で組む
はい
構成図
EC2だけです。Ubuntu18.04で用意しました。
実装・設定
Dockerで用意したPythonコンテナにBottleのAPIを用意しました。Basic認証、zipファイルダウンロードの工程はすべてBottleに任せています。
カレントディレクトリに配置したzipファイルをダウンロードします。
app.py
import bottle
# BASIC認証のユーザ名とパスワード
USERNAME = "user"
PASSWORD = "pass"
def check(username, password):
u"""
BASIC認証のユーザ名とパスワードをチェック
@bottle.auth_basic(check)で適用
"""
return username == USERNAME and password == PASSWORD
@bottle.route("/zip")
@bottle.auth_basic(check)
def zip():
zip_filename = 'files.zip'
with open(zip_filename, 'rb') as f:
body = f.read()
response.content_type = 'application/zip'
response.set_header('Content-Disposition', 'attachment; filename="{}"'.format(zip_filename))
response.set_header('Content-Length', len(body))
response.body = body
return response
if __name__ == '__main__':
bottle.run(host='0.0.0.0', port=80, debug=True)
$ docker run -p 80:80 -v $(pwd):/app -it docker-image-hogehoge python3 /app/app.py
これで大容量(時間かかるけど)でもダウンロードするURLができました!!!!!!!
雑感想
勉強のため!サーバーレスだ!って意気込んでやったけど、最初からEC2でやればよかった。。。。。。。