この記事は、"ちゅらデータアドベントカレンダー"の20日目です。
遅刻なのにまだ中途半端な記事です。明日完成させます。
概要
ここ最近はMLOpsに興味があり、情報をあさったり本読んだりしているうちなーんちゅです。
ちゅらデータの周年祭で披露したゴジラ画像分類APIですが、VGG16のモデルをファインチューニングして適当にGoogle画像検索で集めた画像を使って学習したところゆるーい感じで分類することができるようになりました。
こんなやつ
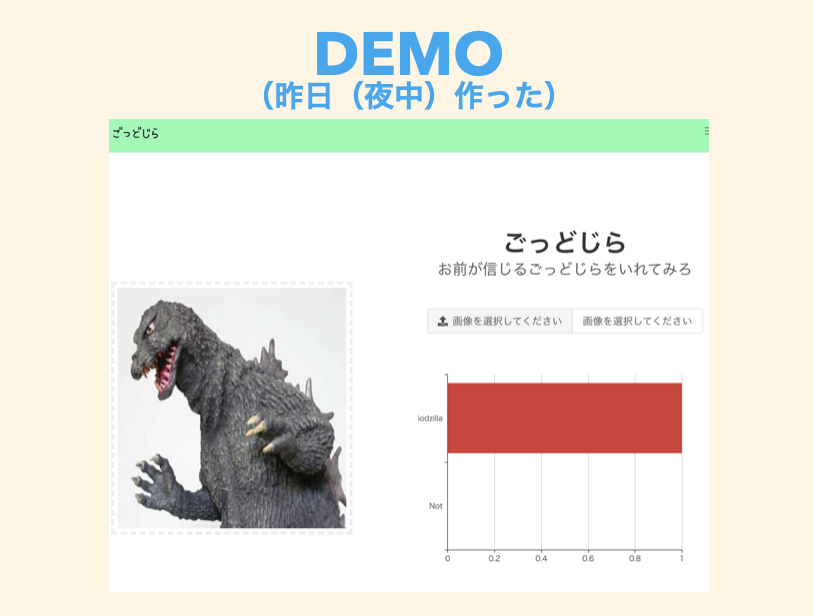
ただ、披露したところ、黒い人がゴジラと分類されたり、ガメラがゴジラに分類されたりとまだまだ学習やデータが足りない感じです。
①データ集める → ②ラベル付与 → ③データ配置 → ④学習用のJupyter notebookを上から叩く → ⑤結果を確認する
の、サイクルを手動でやるのですが、何度も実行するのは面倒ですよね。ってことでワークフロー化したいなーと考えました。
①に関してはすでにコードで実装済み、②については初回は人がやらないと難しそうなので③と合わせて人手でやることにします。今回は④⑤だけワークフロー化できればなと思いました。
また、このぐらいの規模感ならsklearnのpipelineでもいい感じにできそうですが、データのダウンロード処理とか改めて実装するのが面倒なのでいい感じのフレームワークないかなと探していました。
そんでこの記事を見つけた。
↑の記事確認すると、Kedro + Mlflowが良いぞ的なことが書いてあるので、まずはこれで初めてみようかなと思った次第です。
というわけで、用意しましたので実装方法について書いていきます。
シュッと用意したかったけど、シュッとできなかった。
環境
ローカル環境
$ sw_vers
ProductName: Mac OS X
ProductVersion: 10.15.7
BuildVersion: 19H15
$ docker -v
Docker version 19.03.13, build 4484c46d9d
$ docker-compose -v
docker-compose version 1.27.4, build 40524192
準備
AWS
オレゴンで遊びます。
IAMユーザーの用意
-
AWS_ACCESS_KEY_IDとAWS_SECRET_ACCESS_KEYを後から使うのでメモしておく - S3書き込み読み込み権限つけておいてください
S3
- とりあえずバケットを用意します
- 今回は
godzilla-hogehoge-1234で用意しました(どうせすぐ消します)
EC2
- p2.xlargeを使います(涙)
- スポットインスタンスだと安いよ!!!
- Deep Learning AMI (Ubuntu 18.04)
- セキュリティグループでインバウンド80ポートを許可しておいてください(IP制限はしたほうが良い)
- mlflowをブラウザから確認するために利用します
- 全公開でnginxを使って認証画面を用意するのでもいいと思います(でもやっぱりIP制限したほうが安全かなとは思う)
Dockerfile用意
dockerでやります
.env
さっきメモしてたAWSの情報を追加する。
# Postgresの情報
POSTGRES_USER=user
POSTGRES_PASSWORD=password
# 作成したs3 bucket名を用意
S3_BUCKET=s3://godzilla-hogehoge-1234/
# AWSの情報
AWS_ACCESS_KEY_ID=hogehoge
AWS_SECRET_ACCESS_KEY=fugafuga
AWS_DEFAULT_REGION=us-west-2
AWS_DEFAULT_OUTPUT=json
kedro用 Dockerfile
Dockerfile_kedro で作成します。
FROM hoto17296/anaconda3-ja
RUN pip install kedro==0.17.0 \
fsspec==0.6.3 \
s3fs==0.4.0 \
botocore==1.19.36 \
mlflow==1.12.1 \
tensorflow-gpu
mlflow server 用 Dockerfile
Dockerfile_mlflow で作成します。
ちなみにコード等は↓から パクリ リスペクトしました。
FROM conda/miniconda3:latest
RUN mkdir -p /mlflow/mlruns
WORKDIR /mlflow
ENV LC_ALL=C.UTF-8
ENV LANG=C.UTF-8
RUN echo "export LC_ALL=$LC_ALL" >> /etc/profile.d/locale.sh
RUN echo "export LANG=$LANG" >> /etc/profile.d/locale.sh
RUN apt-get update && apt-get install -y \
build-essential \
python3-dev \
libpq-dev
RUN pip install -U pip && \
pip install --ignore-installed google-cloud-storage && \
pip install psycopg2 mlflow boto3
COPY ./mlflow_start.sh ./mlflow_start.sh
RUN chmod +x ./mlflow_start.sh
EXPOSE 80
EXPOSE 443
CMD ["./mlflow_start.sh"]
./mlflow_start.sh
# !/bin/bash
set -o errexit
set -o nounset
set -o pipefail
mlflow server \
--backend-store-uri $DB_URI \
--host 0.0.0.0 \
--port 80 \
--default-artifact-root ${S3_BUCKET}.env
docker-compose.yml
コメントアウトしているところはgpu環境で実行するときにコメントを外します。
version: '3'
services:
waitfordb:
image: dadarek/wait-for-dependencies
depends_on:
- postgresql
command: postgresql:5432
postgresql:
image: postgres:10.5
container_name: postgresql
ports:
- 5432:5432
environment:
POSTGRES_USER: ${POSTGRES_USER}
POSTGRES_PASSWORD: ${POSTGRES_PASSWORD}
POSTGRES_DB: mlflow-db
POSTGRES_INITDB_ARGS: "--encoding=UTF-8"
hostname: postgresql
restart: always
mlflow:
build:
context: .
dockerfile: Dockerfile_mlflow
container_name: mlflow
expose:
- 80
- 443
ports:
- "10006:80"
depends_on:
- postgresql
- waitfordb
environment:
DB_URI: postgresql+psycopg2://${POSTGRES_USER}:${POSTGRES_PASSWORD}@postgresql:5432/mlflow-db
VIRTUAL_PORT: 80
S3_BUCKET: ${S3_BUCKET}
AWS_ACCESS_KEY_ID: ${AWS_ACCESS_KEY_ID}
AWS_SECRET_ACCESS_KEY: ${AWS_SECRET_ACCESS_KEY}
kedro:
# runtime: nvidia
build:
context: .
dockerfile: Dockerfile_kedro
container_name: kedro
environment:
MLFLOW_TRACKING_URI: http://mlflow/
AWS_ACCESS_KEY_ID: ${AWS_ACCESS_KEY_ID}
AWS_SECRET_ACCESS_KEY: ${AWS_SECRET_ACCESS_KEY}
# NVIDIA_VISIBLE_DEVICES: all
depends_on:
- mlflow
volumes:
- ./:/app
build
用意ができたのでbuildしましょー
$ docker-compose up
ワークフロー組み立て
ここからはコンテナ(kedro)上で作業していきます。
コンテナを起動したら下記コマンドを実行してコンテナで作業できるようにします。
$ docker-compose exec kedro /bin/bash
(base) root@hogehoge:/app#
おk
Kedroとは
情報だけ載せておきます。どうでもいいけど「けーどろ」と思ってたけど、全然違う意味らしい。
- リポジトリ: https://github.com/quantumblacklabs/kedro
- ドキュメント: https://kedro.readthedocs.io/en/stable/
- pipeline比較記事: https://qiita.com/Minyus86/items/70622a1502b92ac6b29c
communityもあるので、なにか困ったことあったら質問してみると良いかなと。
kedro new
ワークフローが動作するプロジェクトを用意します。
(base) root@hogehoge:/app# kedro new
/opt/conda/lib/python3.7/site-packages/jinja2/utils.py:485: DeprecationWarning: Using or importing the ABCs from 'collections' instead of from 'collections.abc' is deprecated, and in 3.8 it will stop working
from collections import MutableMapping
/opt/conda/lib/python3.7/site-packages/jinja2/runtime.py:318: DeprecationWarning: Using or importing the ABCs from 'collections' instead of from 'collections.abc' is deprecated, and in 3.8 it will stop working
from collections import Mapping
/opt/conda/lib/python3.7/site-packages/requests/__init__.py:91: RequestsDependencyWarning: urllib3 (1.26.2) or chardet (3.0.4) doesn't match a supported version!
RequestsDependencyWarning)
Project Name:
=============
Please enter a human readable name for your new project.
Spaces and punctuation are allowed.
[New Kedro Project]: workflow
Repository Name:
================
Please enter a directory name for your new project repository.
Alphanumeric characters, hyphens and underscores are allowed.
Lowercase is recommended.
[workflow]:
Python Package Name:
====================
Please enter a valid Python package name for your project package.
Alphanumeric characters and underscores are allowed.
Lowercase is recommended. Package name must start with a letter or underscore.
[workflow]:
Change directory to the project generated in /app/workflow
A best-practice setup includes initialising git and creating a virtual environment before running `kedro install` to install project-specific dependencies. Refer to the Kedro documentation: https://kedro.readthedocs.io/
(base) root@hogehoge:/app# ls -l workflow/
total 12
-rw-r--r-- 1 root root 4033 Dec 23 15:52 README.md
drwxr-xr-x 5 root root 160 Dec 23 15:52 conf
drwxr-xr-x 10 root root 320 Dec 23 15:52 data
drwxr-xr-x 3 root root 96 Dec 23 15:52 docs
drwxr-xr-x 4 root root 128 Dec 23 15:52 logs
drwxr-xr-x 3 root root 96 Dec 23 15:52 notebooks
-rw-r--r-- 1 root root 341 Dec 23 15:52 pyproject.toml
-rw-r--r-- 1 root root 47 Dec 23 15:52 setup.cfg
drwxr-xr-x 6 root root 192 Dec 23 15:52 src
おk(Pythonのバージョンが3.7なので大変なことにはなっている)
kedro実装の概要
本当にざっくり説明すると、これからいじるのは5つのファイルです。
- 定義するファイル
-
~/workflow/conf/base/parameters.yml- node(後述)で扱う処理の引数などを定義するファイル
-
~/workflow/conf/base/catalog.yml- 入力するデータ、生成される中間データ、評価データなどを定義するファイル
-
- workflowを組み込むスクリプト
-
~/workflow/src/workflow/nodes/- ワークフロー上で処理させたい関数やクラスはnodeとして扱います
- 処理はここで実装する、またはmoduleをimportしてロジックを実装すればおkです
- 今回は元の処理がすべてnotebookに詰まっているので、notebookからサルベージしたものをnodeに突っ込みます
-
~/workflow/src/workflow/pipelines/- 実行したい処理をnodeへ食わせたり、nodeAの結果をnodeBに食わす〜などの組み立てなどを定義するスクリプトです
-
~/workflow/src/workflow/hooks.py- 用意したpipelineをここでこねこね組み立てます
- ちなみに、実行する順番はkedro実行時にinput,output名を確認し順序が組み立てられるので、もし違う名前を設定したりしていると順序通りに実行してくれない場合があります。前のpipelineのoutput名と次のpipelineのinput名は合わせるようにしてください
-
parameters.yml
ワークフロー上で実行する関数(node)に渡すパラメータを定義します。
my_train_test_split:
test_size: 0.2
random_state: 71
catalog.yml
ワークフロー上で扱うデータ情報を定義します。
今回はs3上に画像データのzipをアップロードしているのでそれを指定します。
また、中間データなど、途中で生成されるデータについても定義することができます。
通常 text.TextDataSet はテキストファイルなどを想定していると思いますが、zipファイル用のtypeがないので(多分)、fs_argsを使ってbinaryデータを読み書きできるように定義しました。
10_84_godzilla.zip:
type: text.TextDataSet
filepath: s3://godzilla-hogehoge-1234/workflow/data/01_raw/10_84.zip
fs_args:
open_args_load:
mode: 'rb'
open_args_save:
mode: 'wb'
10_GMK_godizlla.zip:
type: text.TextDataSet
filepath: s3://godzilla-hogehoge-1234/workflow/data/01_raw/10_GMK.zip
fs_args:
open_args_load:
mode: 'rb'
open_args_save:
mode: 'wb'
10_SOS_godzilla.zip:
type: text.TextDataSet
filepath: s3://godzilla-hogehoge-1234/workflow/data/01_raw/10_SOS.zip
fs_args:
open_args_load:
mode: 'rb'
open_args_save:
mode: 'wb'
10_first_godzilla.zip:
type: text.TextDataSet
filepath: s3://godzilla-hogehoge-1234/workflow/data/01_raw/10_first.zip
fs_args:
open_args_load:
mode: 'rb'
open_args_save:
mode: 'wb'
99_other.zip:
type: text.TextDataSet
filepath: s3://godzilla-hogehoge-1234/workflow/data/01_raw/99_other.zip
fs_args:
open_args_load:
mode: 'rb'
open_args_save:
mode: 'wb'
classes_text:
type: text.TextDataSet
filepath: s3://godzilla-hogehoge-1234/workflow/data/01_raw/classes.txt
X_train:
type: pickle.PickleDataSet
filepath: s3://godzilla-hogehoge-1234/workflow/data/02_intermediate/X_train.pkl
X_test:
type: pickle.PickleDataSet
filepath: s3://godzilla-hogehoge-1234/workflow/data/02_intermediate/X_test.pkl
y_train:
type: pickle.PickleDataSet
filepath: s3://godzilla-hogehoge-1234/workflow/data/02_intermediate/y_train.pkl
y_test:
type: pickle.PickleDataSet
filepath: s3://godzilla-hogehoge-1234/workflow/data/02_intermediate/y_test.pkl
データセットのtypeは色々あるので確認してみてください。
さらに、~/workflow/conf/local/credentials.yml に認証情報を載せた場合、key名をcatalog.ymlにも指定する必要がありますが、今回は .env ですでに指定しているので必要ありません。
node
nodeに食わせる関数は ~/workflow/src/workflow/nodes/ に用意します。
ただ、nodeを書くところは ~/workflow/src/workflow/pipelines/ なので、次のセクションで説明します。
処理する関数群はgithubを確認してください。
pipeline
はい。pipelineです。nodeに食わせる関数群が用意できたら実際にpipelineを組み立てていきましょう。
前処理は①zipファイル展開 → ②画像読みこみ → ③訓練とテストに分ける順番を想定しています。
ってなわけではいどーん
~/workflow/src/workflow/pipelines/preprocess_pipeline.py
from kedro.pipeline import node, Pipeline
from workflow.nodes.preprocess import unzip_image_data, load_image_data, my_train_test_split
def create_pipeline(**kwargs):
return Pipeline(
[
node(
func=unzip_image_data,
inputs=[
'10_84_godzilla.zip',
'10_GMK_godizlla.zip',
'10_SOS_godzilla.zip',
'10_first_godzilla.zip',
'99_other.zip'
],
outputs='unzip_path'
),
node(
func=load_image_data,
inputs=[
'unzip_path',
'classes_text'
],
outputs=[
'X',
'Y',
'classes'
]
),
node(
func=my_train_test_split,
inputs=[
'X',
'Y',
'params:my_train_test_split'
],
outputs=[
'X_train',
'X_test',
'y_train',
'y_test'
]
),
],
tags=['preprocess'],
)
こんな感じで組みます。
少し情報を減らして確認してみます。
def create_pipeline(**kwargs):
return Pipeline([
node(), # ①
node(), # ②
node() # ③
])
こんな感じですね。Pipelineクラスに実行したいnodeをlistで渡しています。
それでは、①の処理のnodeを確認してみます。
node(
func=unzip_image_data,
inputs=[
'10_84_godzilla.zip',
'10_GMK_godizlla.zip',
'10_SOS_godzilla.zip',
'10_first_godzilla.zip',
'99_other.zip'
],
outputs='unzip_path'
),
funcで実行したい関数を指定します。inputsは指定した関数の引数になります。この場合、unzip_image_data に5つの引数を定義する必要があります。また、inputsの名前に対応するデータはcatalog.ymlで定義したデータになります。字ワークフロー実行中にKedroが自動でバインド(?)してくれます。
outputsは関数の返り値です。inputsと同様、catalog.ymlに対応するデータがあった場合は、中間データとして保存されます。(ローカルならローカルへ、s3ならs3に保存される)。catalog.ymlに対応しない場合は、kedro.io.MemoryDataSetとして、ワークフロー実行中、Kedroがメモリ上に保管するようになっています。
ただ、返り値がない処理とかあると思うんだけど、その場合はどうすればいいのか正直まだよくわかっていないです(もし知っているひといたら教えてほしい)
次に②のnodeを確認してみます。
node(
func=load_image_data,
inputs=[
'unzip_path',
'classes_text'
],
outputs=[
'X',
'Y',
'classes'
]
),
①のoutputsが②のinputsに含まれているのがわかります。前のnodeの出力を次のnodeに必ずセットする必要はないですが、Kedroはnodeの実行順番をinputsとoutputsの名前で紐付けて組み立てるので、もし②より先に①を実行したい場合は、↑のように実装すると良いです。
おさらいですが、classes_textはcatalog.ymlで定義しているので、これはワークフロー実行中にKedroが勝手に読み込んで用意してくれます。
ここまで説明した処理は前処理のpipelineですが、別途ファイルをわけてモデル学習用のpipelineを用意しています。pipelineが複数ファイルで用意した場合、それぞれどうやって結合するのかは、~/workflow/src/workflow/hooks.py で定義します。
hooks.py
複数存在するpipelineをつなげる定義をここでやります。
注意してほしいのは、前述でも説明しましたがnodeが実行される順番はinputsとouputsの整合で決まるので、ここで順番を定義することはできません。
~/workflow/src/workflow/hooks.py
class ProjectHooks:
@hook_impl
def register_pipelines(self) -> Dict[str, Pipeline]:
"""Register the project's pipeline.
Returns:
A mapping from a pipeline name to a ``Pipeline`` object.
"""
pp = preprocess_pipeline.create_pipeline() # 前処理用
tp = train_pipeline.create_pipeline() # 訓練用
return {
'preprocess': pp,
'train': tp,
'__default__': pp + tp
}
return で辞書型を返していますが、keyについてはコマンドライン上で実行したいpipelineを指定することができます。そのときに利用するkeyになります。
__default__については、その名の通り、pipeline名を指定しない場合は、__default__で定義したpipelineが実行されます。
実行してみる
$ docker-compose exec godzilla_kedro /bin/bash -c 'cd /app/workflow; kedro run'
実行できました。s3で生成物を確認してみましょう。
TBD
Mlflowとの連係
TBD
hookとは
hookを使ってmlflowと連係してみる
結果の確認
Kedroを使ってみて
良さそうな点
- データ連係は楽
- Pythonのモジュール開発になれてたら簡単にワークフローが組める
- 大丈夫、notebookも叩ける!
- 簡単にdata catalogのバージョン管理(?)が導入できる
正解かわからんけどとりあえず実装できた編
- パラメータでnodeを分岐したいとき TBD
- catalog.ymlよんで、keyを取り出したい TBD
ここも変更したいけど、内部いじらないと難しそうな編
- バージョニングのディレクトリ構成を変更したい
-
--load-versionのデータ指定を簡単にしたい- 複数ある場合、複数してしないといけないめんどくさい
- またログではちゃんとそのバージョンを読み込んでいるかわからない
- バイナリデータのcatalog typeがない???
- pytorch用のcatalog typeがない(多分)
雑感
MLOps楽しいね!!これからもがんb・・・ってじょ・・・・うほ・・・う・・・( ˘ω˘)スヤァ