はじめに
Azure Synapse Pipeline (Azure Data Factory)のDataFlowで、ある列に重複した値があった場合に、最初の行だけを選択するフローを作ります。
自分用のシンプルなメモです。
方法
-
Aggregate (集約)アクティビティを置きます。
-
「グループ化」タブ「列」の設定項目に重複を除きたい対象の列を指定します。
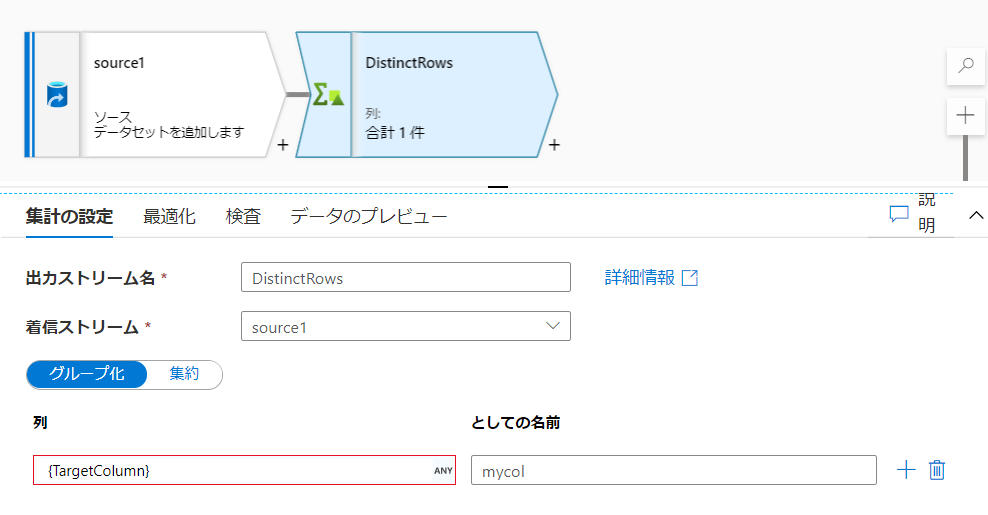
列名の部分は既にある列名と被らないものを指定します。
※今回はデータを入力していないのでエラー表示が出ておりますが、ソースデータセットに列が入っていればエラー表示は消えます。 -
「集約」タブ→「追加」で、「列パターンの追加」を選択します。
-
「式ビルダーを開く」を選択し、下記内容を書きます。
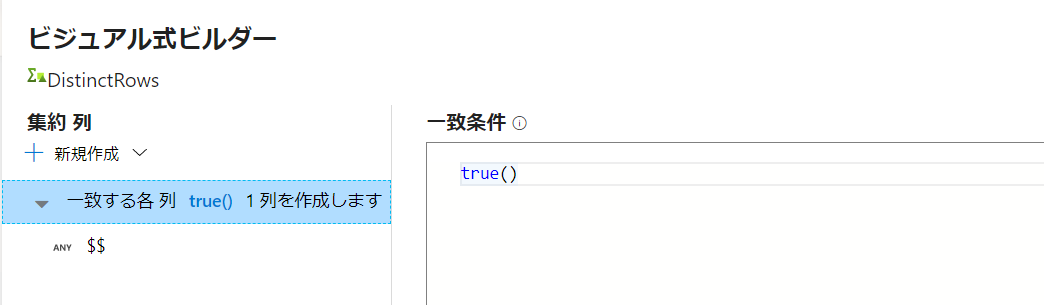
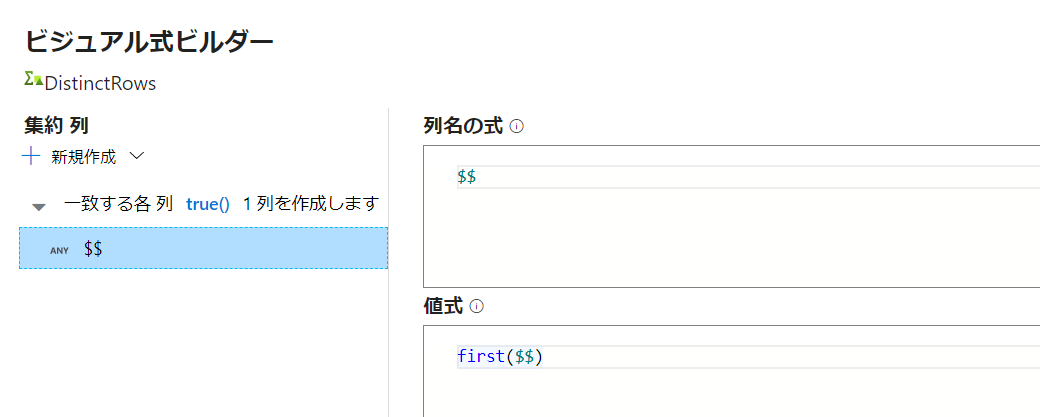
全ての列を対象にし、列名は元をそのまま出力し、重複があった場合はfist($$)によって最初の行が出力される、というイメージです。
'$$' は、一致した列の既存の列値を表します。
おわりに
これで対象列において重複があった場合に、最初の行のみ残すフローが作成できました!
元々はドキュメントのスニペットを参考にしております。
スニペットは全列を対象に重複があった場合に最初の行のみ残す、という形になっていたので、それを特定の行を選択する形でトライしました。
参考
マッピング データ フロー スクリプト - Azure Data Factory | Microsoft Doc
first()