実行環境の全体像
Spark dirver
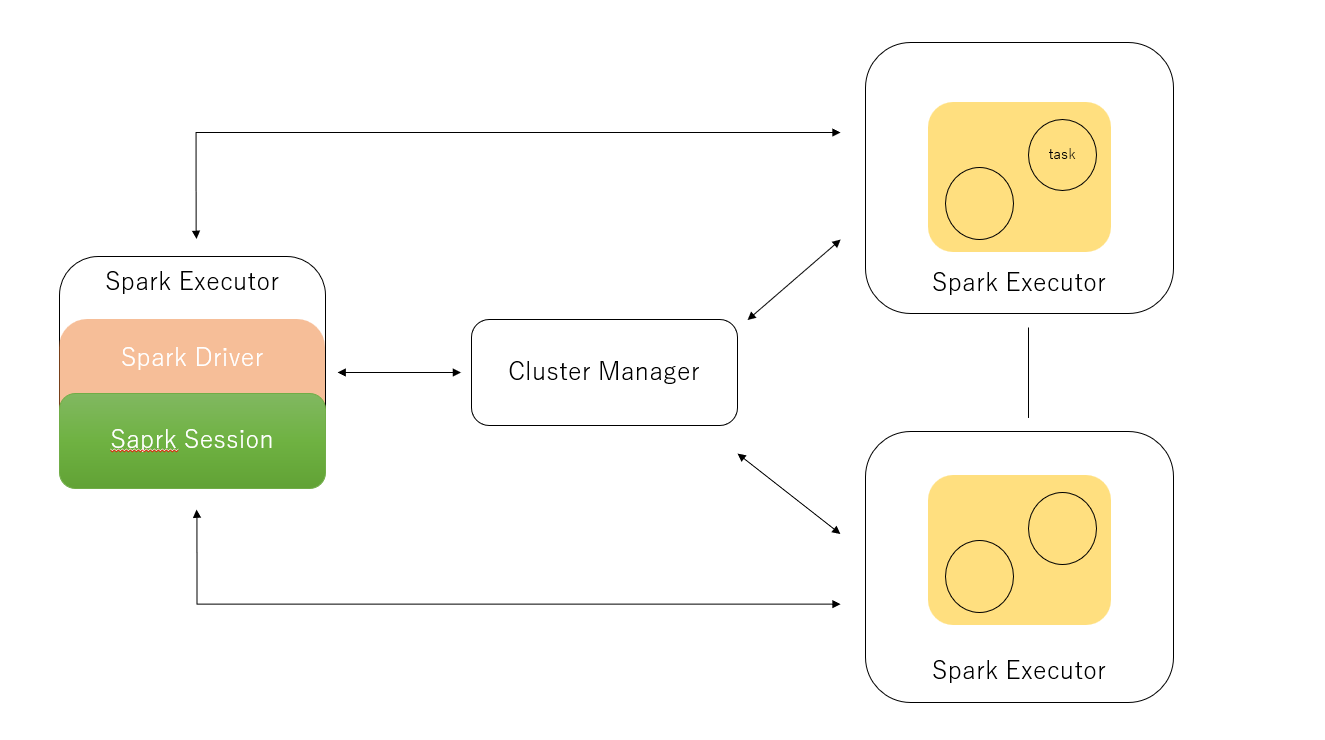
Spark driverには、いくつかの役割がある
- cluster Managerへ情報の伝達をする
- Sparkを実行するJVMのためのcluster Managrからの、メモリなどのリソースの要求
- DAGコンピューティング、スケジュール、それらをタスクとして配布することをSaprkの操作で行う
- 再びリソースを配布
- それらをSpark executerに伝達
Spark Session
Sparkのエントリーポイント
//ライブラリの読み込み
import org.apache.spark.sql.SparkSession
//SparkSessionの構築
val spark = SparkSession
.builder
.appName("appName")
.config("spark.sql.shuffle.partition", 6)
.getOrCreate()
//Jsonの読み込み
val people = spark.read.json("fileName")
cluster Manager
役割
- Sparkのアプリケーションの実行のリソースの管理や割り当ての役割
以下でのクラスターを管理できる
- Apache Hadoop YARN
- Apache Mesos
- Kubernetes
Spark executor
Spark executorは、プログラムのドライバーに情報の伝達をし、
executorのタスクにおいて大事な役割を果たしています
Deployment modes
Sparkには様々なデプロイモデルがある。
cluster ManagerはSpark's exeuter,リソースの要求を満たす限り、環境に依存はせず、
Apache Hadoop YARNやKubernetesなどでデプロイすることが出来る
データとパーティション
データは、様々な場所に祖損されているが、
Saprkでは、論理的にパーティションやデータを扱うことが出来る
ただし、それらはネットワークが閉じ、パーティションが読み込まれたタスクのみ可能である