
はじめに
AIエージェントに長期記憶を持たせると、次に必ず出てくる問題があります。記憶の検索精度ではなく、記憶の混在です。
個人で使っているうちは、ひとつの memory/ ディレクトリにMarkdownを置くだけでも動きます。しかし、ユーザーが増え、AIパートナーが増え、仕事用と個人用の文脈が分かれてくると、「誰の、どのAIの、どの用途の記憶か」を取り違えない設計が必要になります。
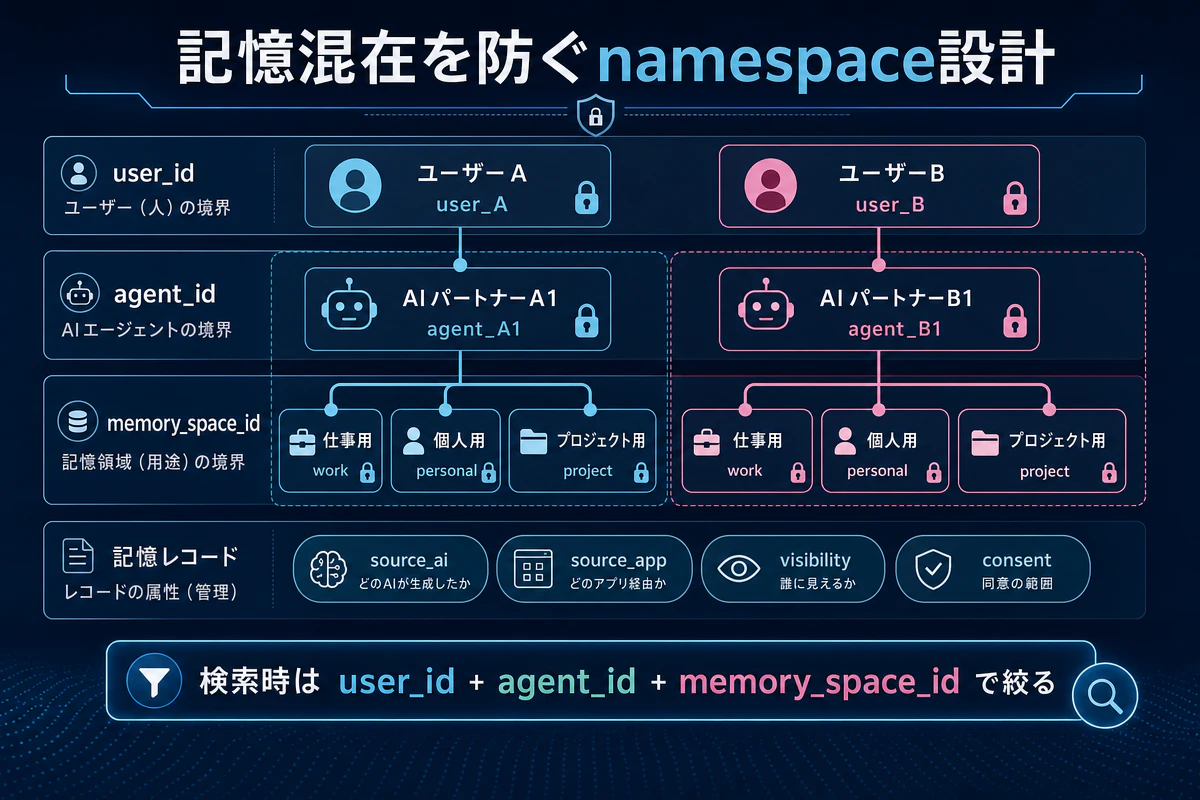
この記事では、Agent Memoriesで採用している基本方針として、次の3つのキーで記憶を分離する設計を紹介します。
-
user_id: 記憶の所有者 -
agent_id: どのAIパートナーの記憶か -
memory_space_id: 仕事用、個人用、プロジェクト用などの区画
記憶混在は検索精度の問題ではない
ベクトル検索を入れると、似た内容の記憶がよく引けるようになります。ただし、それは「引いてよい記憶」だけが検索対象になっている場合の話です。
検索対象に他ユーザーの記憶が混ざっていると、検索精度が高いほど危険です。似ているが別人の記憶を、自信を持って返してしまうからです。
そのため、記憶検索ではまずフィルタをかけます。検索スコアはその後です。
type MemoryScope = {
user_id: string;
agent_id: string;
memory_space_id: string;
};
type MemoryRecord = MemoryScope & {
id: string;
title: string;
body: string;
source_ai: "claude" | "codex" | "chatgpt" | "gemini" | "manual";
source_app: string;
visibility: "private" | "shared";
consent: "owner_only" | "team_allowed";
created_at: string;
};
この形にしておくと、検索の入口で必ずscopeを要求できます。
検索時はscopeを必須にする
検索関数の引数に query だけを渡せる設計にしないことが重要です。必ずscopeとセットで受け取ります。
type SearchInput = MemoryScope & {
query: string;
limit?: number;
};
async function searchMemories(input: SearchInput): Promise<MemoryRecord[]> {
const candidates = await vectorSearch({
query: input.query,
filter: {
user_id: input.user_id,
agent_id: input.agent_id,
memory_space_id: input.memory_space_id,
},
limit: input.limit ?? 8,
});
return candidates.filter((memory) => memory.visibility === "private");
}
実装によっては、ベクトルDB側のfilterだけに頼らず、アプリケーション側でも同じ条件を再確認します。二重に見えますが、記憶混在は事故の影響が大きいため、最後の出口でも守ります。
共有記憶は例外扱いにする
チームで使う場合、共有記憶も必要になります。ただし、共有を既定にすると混在が起きます。共有は例外扱いにして、明示的な許可を持たせます。
function canRead(memory: MemoryRecord, scope: MemoryScope): boolean {
const sameOwner = memory.user_id === scope.user_id;
const sameAgent = memory.agent_id === scope.agent_id;
const sameSpace = memory.memory_space_id === scope.memory_space_id;
if (sameOwner && sameAgent && sameSpace) return true;
return (
memory.visibility === "shared" &&
memory.consent === "team_allowed" &&
memory.memory_space_id === scope.memory_space_id
);
}
共有記憶も、少なくとも用途の区画は合わせます。仕事用の共有記憶が、個人用AIパートナーの会話に混ざるべきではありません。
source_aiとsource_appを残す
記憶はどこから来たかも重要です。Claude Codeで作業中に保存した記憶なのか、ChatGPTとの会話から持ってきた記憶なのか、手動で登録した方針なのかで信頼度が変わります。
const memory: MemoryRecord = {
id: "mem_20260623_001",
user_id: "user_123",
agent_id: "asuna",
memory_space_id: "agentmemories_ops",
title: "Qiita/Zenn記事はAlice QC後に公開する",
body: "tech-dailyの原稿はcontent/techに置くが、公開にはAliceの承認ファイルが必要。",
source_ai: "codex",
source_app: "openclaw",
visibility: "private",
consent: "owner_only",
created_at: new Date().toISOString(),
};
あとで「この記憶は本当に採用してよいのか」を判断する時、出所が残っているとレビューしやすくなります。
MCPツールの入力にもscopeを持たせる
MCPサーバーにする場合も同じです。memory_search や memory_store の入力にscopeを必須で持たせます。
const ScopeSchema = z.object({
user_id: z.string().min(1),
agent_id: z.string().min(1),
memory_space_id: z.string().min(1),
});
server.registerTool(
"memory_search",
{
title: "Search memories",
inputSchema: ScopeSchema.extend({
query: z.string().min(1),
limit: z.number().int().min(1).max(20).default(8),
}).shape,
},
async (input) => {
const parsed = ScopeSchema.extend({
query: z.string(),
limit: z.number().default(8),
}).parse(input);
const results = await searchMemories(parsed);
return {
content: [{ type: "text", text: JSON.stringify(results, null, 2) }],
};
},
);
ここでscopeをサーバー側が補完する設計にする場合でも、最終的には呼び出しごとに確定したscopeをログへ残します。後から混在事故を調査できるようにするためです。
まとめ
AIエージェントの記憶基盤では、検索精度より先に分離設計が必要です。
最小構成は次の3つです。
user_idagent_idmemory_space_id
この3つで検索対象を絞り、共有記憶は明示許可制にする。さらに source_ai、source_app、visibility、consent を残すと、複数AI・複数ユーザーでも記憶を安全に扱いやすくなります。
記憶は便利なほど、混ざった時の被害が大きくなります。だからこそ、Agent Memoriesでは「どのAIでも記憶を使える」ことと同じくらい、「使ってはいけない記憶を混ぜない」ことを重視しています。