画像中の文字領域検出における 2 つの主流な手法のいいとこ取りを目指した論文、 Multi-Oriented Scene Text Detection via Corner Localization and Region Segmentation を読んでみました。
この記事は、Wantedlyの勉強会で取り上げられた論文・技術をまとめたものです。
2018年に読んだ機械学習系論文・技術まとめ at Wantedly Advent Calendar 2018 - Qiita
Reference
- Multi-Oriented Scene Text Detection via Corner Localization and Region Segmentation [Pengyuan Lyu, Cong Yao, Wenhao Wu, Shuicheng Yan, Xiang Bai. CVPR 2018]
- https://arxiv.org/abs/1802.08948
(文中の図表は論文より引用しています)
Scene Text Detection
Scene Text Detection は、風景写真のなかにある文字領域(かんばん、ポスターなど)を検出するタスクです。

(Figure 6.)
CNN を活用した研究が進んでおり、現在では 2 つのアプローチが主流となっています。(このあたりは 【論文読み】Semi-convolutional Operators for Instance Segmentation や [論文紹介] Focal Loss for Dense Object Detection でもすこし触れています)
1つ目は、文字領域検出を、一般的な物体検知(Object Detection)の特殊系とみなして解く手法です。
物体検知に対するアプローチとして主流なのは bounding box の座標を regression として解くというものです。
この場合、bounding box 形式で当てに行くので、歪んだ形状への対応が難しく、縦横比が大きく偏った文字領域に弱いといった問題があります。
EAST: An Efficient and Accurate Scene Text Detector [X. Zhou et al., CVPR 2018] はこちらのアプローチを採用しています。
2つ目は、Instance Segmentation として解くアプローチです。
ピクセル単位で文字領域かどうかの 2 クラス分類 + なんらかの方法でインスタンスの分離を行うという方法ですが、インスタンスの分離には複雑な後処理を要するケースが多く、複雑さや実行時間に問題があります。
PixelLink: Detecting Scene Text via Instance Segmentation [D. Deng et al., AAAI 2018] が代表例です。(論文中で refer されているのは Multi-oriented Text Detection with Fully Convolutional Networks [Z. Zhang et al., CVPR 2016])
この論文ではこれらの 2 つの手法をいいとこ取りした Scene Text Detector を提案しています。
Network Architecture
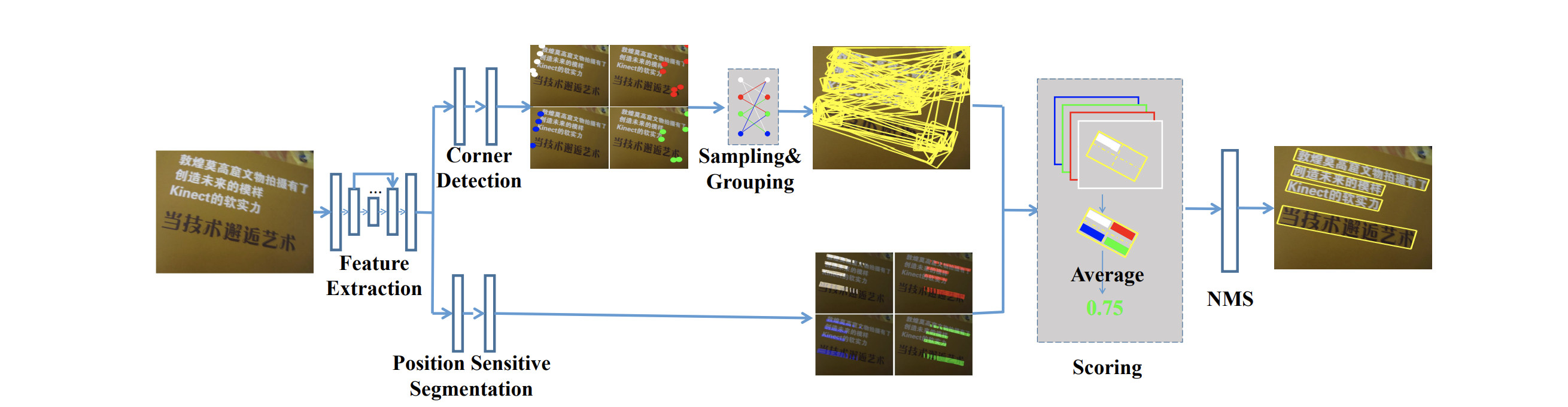
全体像は↑の図のようになっています。
Corner Detection と Position Sensitive Segmentation の2つからなる architecture です。
Corner Detection はその名の通り、文字領域の角の位置を予測します。ただし、「角である」ことだけを考慮し、「どの 4 つの組み合わせが 1 領域を表しているのか」は考えません。
Corner Detection が予測した大量の「角」たちを sampling & grouping し、大量の「文字領域候補」をつくります。
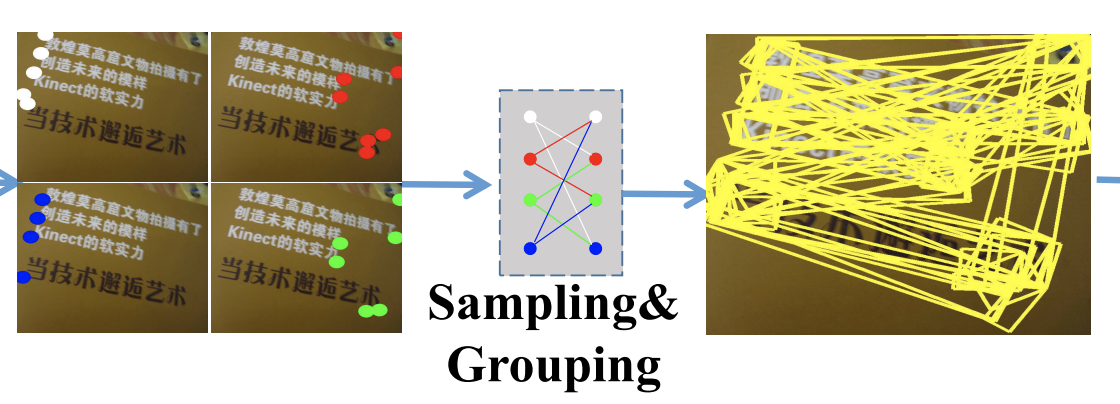
(Corner Detection は概念的にはわかりやすいですが、実際には default box を用意して offset 計算して...と、SSD や YOLO と同程度には複雑なことをしています。詳細は論文をご参照ください...)
Corner Detection と並行して、Position Sensitive Segmentation 側では、各ピクセルを「文字領域の右上」「右下」「左上」「左下」の 4 クラス(+ 背景)に分類します。

それぞれ、白が「左上」、赤が「右上」、青が「左下」、緑が「右下」に分類された領域です。
さいごに、Corner Detection によって生成された大量の「文字領域候補」を、Position Sensitive Segmentation の結果との整合性に応じてスコアづけします。
「文字領域候補」の左上にあるピクセルが Segmentation によって「左上」に分類されていればいるほど高いスコアになります。

感想
Instance Segmentation 方式は後処理が複雑すぎる、という問題提起のわりには、提案手法の後処理も相当大変そうという印象があります。
また、Corner Detection 部分はやけに複雑で、なぜこんなに複雑なことをしているのかあんまり理解できませんでした。
一方、Object Detection 系のやり方と Segmentation 系のやり方を組み合わせる手法としては概念的にもわかりやすい構成で面白かったです。
Position Sensitive Segmentation というアプローチもこの論文を読むまで知らなかったので勉強になりました。
この論文の少しあとに ECCV 2018 に通った論文で関連していそうなものとして、CornerNet と PixelLink という論文があります。
CornerNet: Detecting Objects as Paired Keypoints は、 Corner を予測 + ピクセル単位の Embedding を計算 → Embedding の距離に応じて Corner のペアを作っていくという手法で、よりシンプルに Corner のグルーピングを実現しています。
また、PixelLink: Detecting Scene Text via Instance Segmentation は text/non-text の segmentation + 隣接ピクセルと連結するかしないかの 2 クラス分類を組み合わせて Instance Segmentation をし、文字領域検出を行っています。
どちらもとてもおもしろい論文なのでおすすめです。