Instance Segmentation のタスクに対する手法を整理・分解し、精度をより向上する Semi-convolutional operators を提案した論文です。

この記事は、Wantedlyの勉強会で取り上げられた論文・技術をまとめたものです。
2018年に読んだ機械学習系論文・技術まとめ at Wantedly Advent Calendar 2018 - Qiita
Reference
- Semi-convolutional Operators for Instance Segmentation [David Novotny, Samuel Albanie, Diane Larlus, and Andrea Vedaldi. ECCV 2018]
- https://arxiv.org/abs/1807.10712
(文中の図表は論文より引用しています)
Instance Segmentation
まずはじめに簡単に Instance Segmentation というタスクと、現在主流とされているアプローチについて述べます。
Instance Segmentation とは、画像の各 Pixel について、 どのクラスに属すか、どのインスタンスに属するか を予測するタスクです。
入力画像を「この領域は人、この領域は車、...」というように色塗りしていくタスクです。
 (Fig. 5 より)
(Fig. 5 より)
Instance Segmentation において重要なのが どのインスタンスに属するか も予測しなければならないという点です。
たとえば人が 3 人で肩を組んでいるような画像の場合、どこからどこまでが 1 人目かを予測しなければなりません。
一方、インスタンスを考慮せず色塗りをしていくようなタスクを Semantic Segmentation といいます。
Semantic Segmentation の場合は、入力画像の各 Pixel について多クラス分類を行えば Segmentation の完成になります。
Instance Segmentation ではそれに加えて個々のインスタンスを区別するような仕組みが必要になります。
propose & verify
Instance Segmentation タスクへのアプローチとして、現在主流とされているのは Mask R-CNN 1 に代表される Region based な手法です。
(Mask R-CNN は FAIR から出ている論文で、 OSS として公開されている Detectron に実装が含まれています。 https://github.com/facebookresearch/Detectron )
Mask R-CNN は、物体のクラスと bounding box だけを予測する Object Detection タスクへのアプローチを応用しています。
まず Object Detection をすることで「この bounding box に人間が 1 人いる」ということを予測し、その後 bounding box 内を色塗りしていきます。
Object Detection として bounding box を予測している時点で Instance を分離することが出来ています。色塗りのフェーズでは、すでに Instance が分離されているので単なる Pixel 単位の 2 クラス分類をやればよいことになります。
はじめに Region を提案し、その中を精査するこれらの手法を、この論文では propose & verify (P&V) と呼んでいます。
ここで、 P&V は必ず一度矩形で切り取ってから色塗りをしなければならない という点が問題になります。
予測したい物体は必ずしも矩形で近似できるような形状をしているとは限りません。
実際の形状と極端にかけ離れた場合、bounding box を予測すること自体が難しく、また Instance の分離も難しくなります。

instance coloring
P&V の問題点を解決する方法として、Pixel ごとに ラベル + Instance の identifier となる何か を予測する方法があります。
これらをこの論文では instance coloring (IC) と呼んでいます。
「Instance の identifier となる何か」 は、連番などではうまく学習できません(どの Object が ID 1 なのか ID 2 なのかわからない)。
そこで、 Pixel ごとに低次元の embedding を出力し、同じ Instance に所属する Pixel の embedding たちが似たものになるように学習します。
入力画像に対して、Pixel ごとのラベルと embedding を出力し、embedding を基に Pixel たちをクラスタリングすることで Instance を分離します。
IC の良いところは、典型的な image-to-image の問題と同じネットワーク構造を利用できるところです。
Semantic Segmetation, Style Transfer など、画像を入力とし同じサイズの feature map を出力とするタスクは他にも数多くあり、それらと同じ構造をシンプルに流用できるのは大きな利点になります。
(P&V の場合は Region Proposal + Region ごとの Coloring が必要で、ネットワーク構造としてはかなり複雑かつ独特なものになります)
一方、IC であまり精度が出ない大きな理由の一つに 画像的に似た領域が繰り返されると Instance の分離に失敗する という問題があります。
image-to-image のネットワークは通常 Convolutional operators をベースにしていますが、CNN の出力は、入力である pixel の特徴量にのみ依存し、 座標は全く結果に影響を及ぼしません 。
そのため、画像的にそっくりな領域が複数あると、それらの pixel に対する embedding は同じような値になってしまい、クラスタリングがうまくいきません。
Semi-convolutional operators
一般的な IC では、出力された embedding が次の条件をみたすことを目標とします。
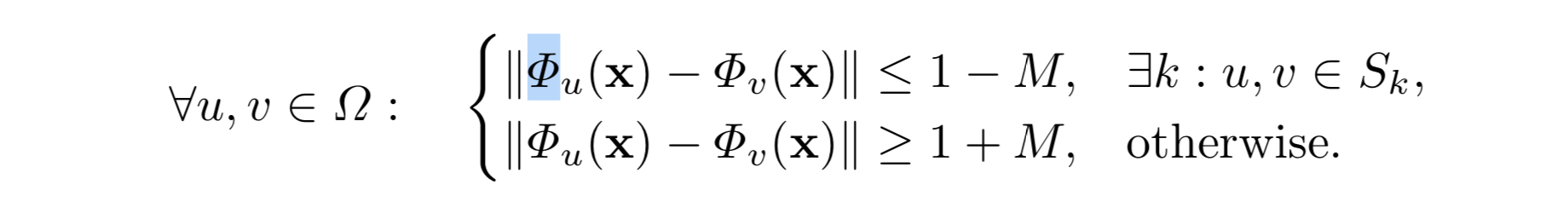
ここで、 $\Omega$ は全 Pixel の集合、 $x$ は入力画像、 $\Phi$ は学習したい関数(NN)、 $S_k$ はクラス k の segmentation mask、 $M$ はマージン (hyperparameter) です。
言葉で説明すると、 同じクラスに属する Pixel $u$, $v$ の embedding の距離をより近づけ、違うクラスに属する場合はより遠ざける という感じです。
$M$ は分離境界をよりくっきりさせるためのパラメータです。
さきほど述べたように $\Phi$ は CNN であり、座標情報を加味できません。
Semi-convolutinal 版では、 $\Phi$ の代わりに次のような $\Psi$ を考えます。
\Psi_u(x) = f(\Phi_u(x), u)
ここで、 $u$ は Pixel の座標を表し、 $f$ は $\Phi$ の結果と座標情報を合成するなんらかの関数です。
$f$ の簡単な例としては、単純な足し算が考えられます。
$\Psi$ は、CNN の結果に加えて座標情報も持ち合わせているため、IC の弱点を克服できています。
$f$ を単純な加算とし、うまく学習が成功した場合、各 Instance ごとに centroid $c_k$ が決定され、
\forall u \in S_k: \Phi_u(x) + u = c_k
となるように $\Phi$ が学習されます。
これを可視化すると次の画像のようになります。

(Fig.2 より)
各インスタンス内の Pixel から、なんとなく中心っぽい場所へベクトルが伸びているのがわかります。
実際の学習の際の損失関数は次のようになります。

同じインスタンスに属する Pixel の embedding たちを平均値になるべく近づける、というのが損失関数になります。
(マージンの考えも含まれていないし、「違うインスタンスとの距離を取る」という損失も含まれていないですが、これで十分に良い学習ができたと述べられています。)
実際にはもうちょっと複雑な $\Psi$ や距離の定義を使っていますが、概要としては上記のようなものを Semi-convolutional operators として提案しています。
Experiments
Mask R-CNN との統合もこの論文の重要な topic なのですが、ぶっちゃけ論文を読んだほうがわかりやすいので飛ばして実験結果をざーっと眺めてみます。
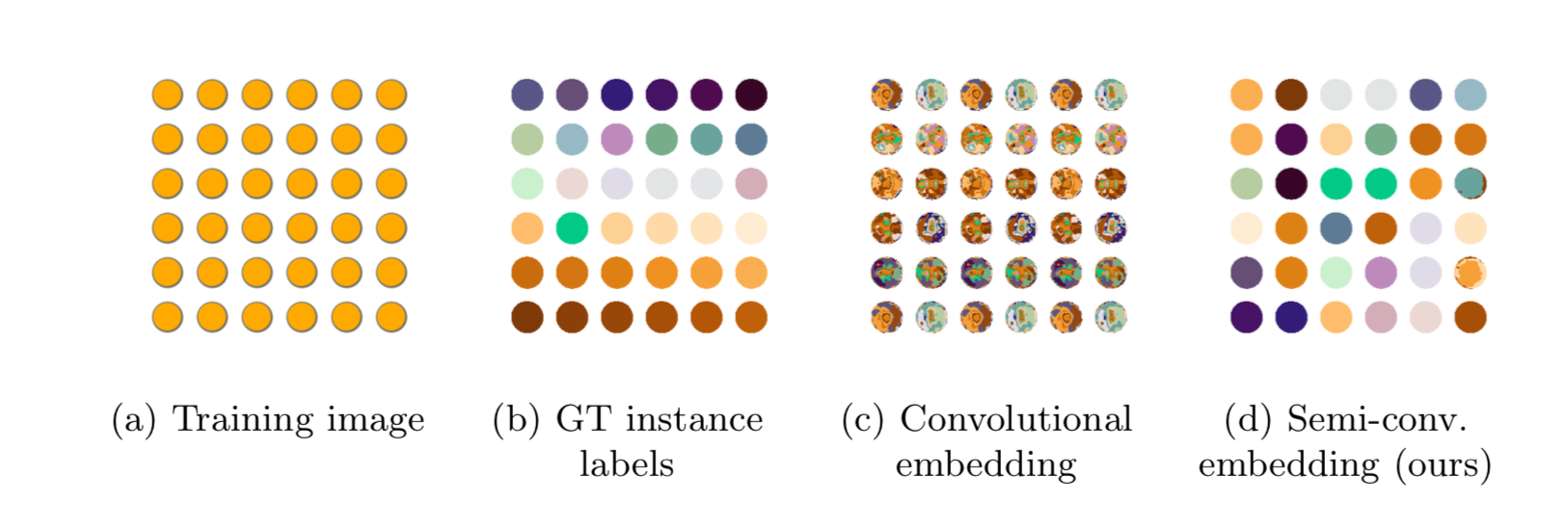 (Fig. 3 より)
(Fig. 3 より)
まずはじめに、 画像的にそっくりな領域が繰り返されてもうまく Instance を分離できることを確認しています。
(c) は通常の Conv. のみを使って IC を行った場合の結果です。クラスタリングに大失敗していることがわかります。
一方 (d) の Semi-conv. 版ではきれいな分離が実現されています。
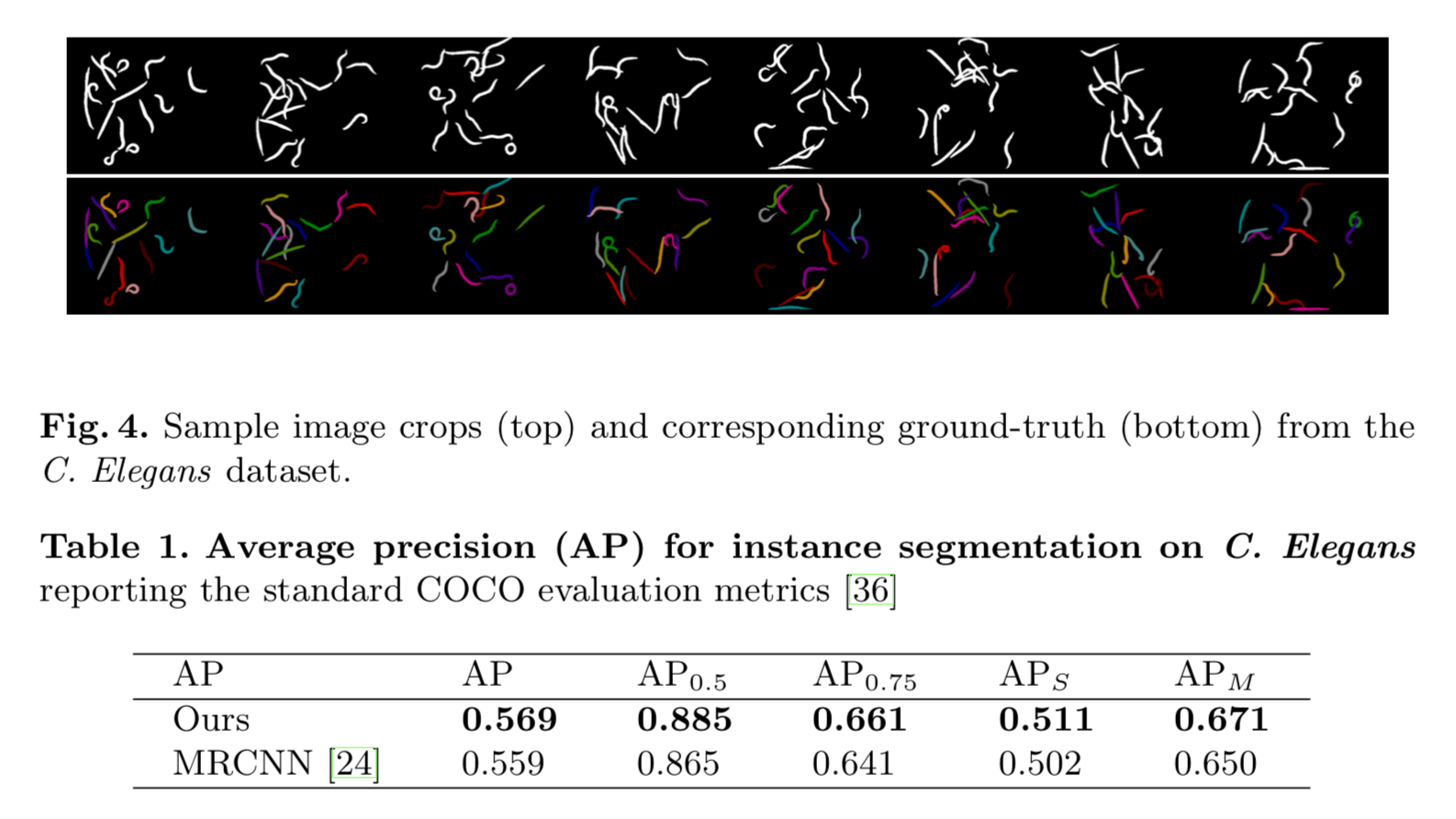
つぎに線虫の segmentation です。こちらは P&V のように矩形で認識するタイプの手法がニガテとするようなタスクです。
現在主流である Mask RCNN よりも良い結果が示されています。
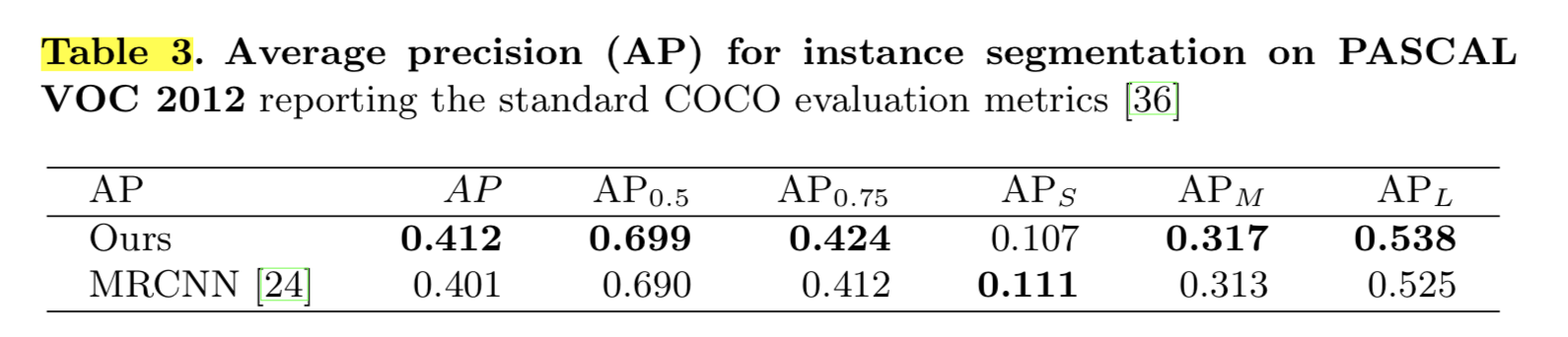
より一般的なデータである PASCAL VOC2012 に対しても Mask RCNN より良い結果となっています(Mask RCNN に Semi-conv. の仕組みを組み込んだもので比較しています。)
まとめと感想
instance coloring の手法をまったく知らなかったのですが、 CornerNet: Detecting Objects as Paired Keypoints で Pixel ごとの embedding をクラスタリングしてペアを作るという手法を知り、興味を持ったのでその関連で読んでみた論文です。
P&V 形式はかなり複雑な構造になるので、それを避けられるならすごく面白いなと思ったのですが、この論文では Mask R-CNN と組み合わせることで精度向上と言っているので、まだまだ IC 単体で勝てる感じではないのでしょうか?
同じタスクに対して全く違う 2 つのアプローチが(比較対象になるくらいには)同じような成果を出しているのも面白いところです。segmentation は主流ではなかった分、まだまだ改善がありそうで楽しみです。
-
K. He, et al., https://arxiv.org/abs/1703.06870 ↩