内容
Fluentd で S3 に送ったログを Amazon Athena で集計する方法を記します。
td-agent3(Fluentd v1.0)でS3に「LTSV形式のログ」を保存する の続きですが 一部設定を変えます
一部変える設定の内容
-
<match>に以下3点を追加output_tag falseoutput_time false- S3のkeyにhostname追加
-
<filter>でhostnameを付与する設定を追加
# hostname追加
<filter ltsv.log>
@type record_transformer
<record>
hostname ${hostname}
</record>
</filter>
<match ltsv.log>
@type s3
...
# S3のkeyにもhostnameを追加
s3_object_key_format %{path}%{hostname}/%{time_slice}_%{index}.%{file_extension}
# 以下の2つの設定を入れることで、S3に保存されるログがJSONのみになる
output_tag false
output_time false
...
</match>
追記:
-
%{hostname}は deprecated -
#{Socket.gethostname}を使う- 旧:
s3_object_key_format %{path}%{time_slice}_%{hostname}%{index}.%{file_extension} - これから:
s3_object_key_format "%{path}%{time_slice}_#{Socket.gethostname}%{index}.%{file_extension}"
- 旧:
この設定を入れるとhostnameの情報が付与された、JSONのみのログがS3に保存されます
{"datetime":"2018-03-26 08:20:12","id":"16509","hostname":"ubuntu-xenial"}
{"datetime":"2018-03-26 08:20:32","id":"6217","hostname":"ubuntu-xenial"}
Amazon Athena でselectするまでの流れ
Get Started
AWS マネジメントコンソールで設定していきます。
「Get Started」で開始します。
AWS Glue Data Catalogへ遷移
今回selectするためのDBとテーブルを作っていきます。
上部のメニュー「AWS Glue Data Catalog」から設定していきます。

Add tables
(この後の作業は AWS Glue での作業です)
「Add tables」から作成します。
「Add information about your crawler」で設定していきます
メニュに沿って設定していきます
crawler nameを入れる
data storeの設定
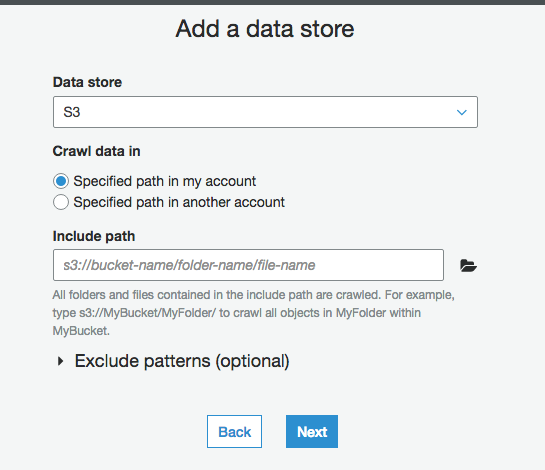
Include path にはS3のkeyの途中まで(prefix)を入れておけば良いです
「Add another data store」は「No」
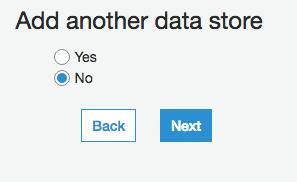
今回はIAM roleを新規作成してみました
(role名を入力しました)
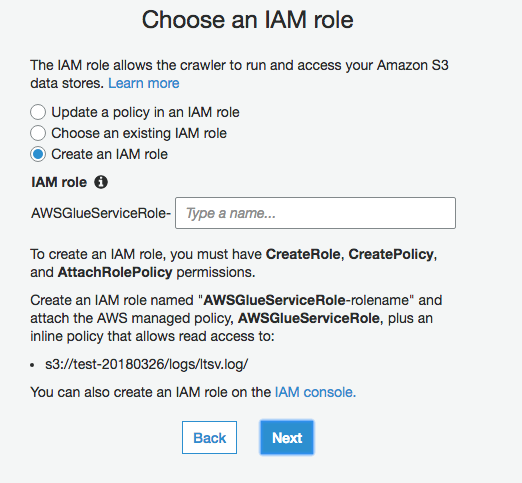
「Create a schedule for this crawler」はとりあえず「Hourly」に
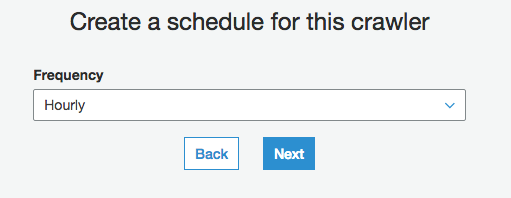
新しいDBを追加しました
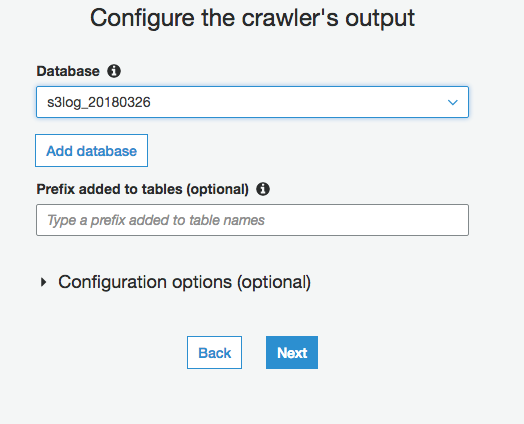
次は確認画面でした。「Finish」して完了です。
Crawlerをrunする
Glueの「Crawlers」メニューに今追加したCrawlerが表示されると思います。
選択して、「Run Crawler」を押すと手動でCrawlerが動きます。
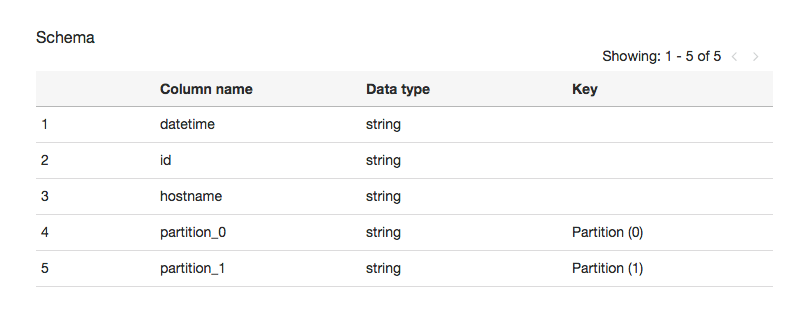
Cralerが動くと、Glueの「Databases > Tables」にtableが追加されます。
JSONだけを送るように設定したので、Schemaもよしなに設定されています。
Amazon Athena に戻ってselect
Glueでここまで作業が終わればAthenaでselectできます。
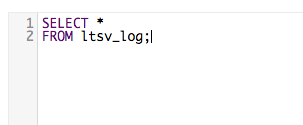
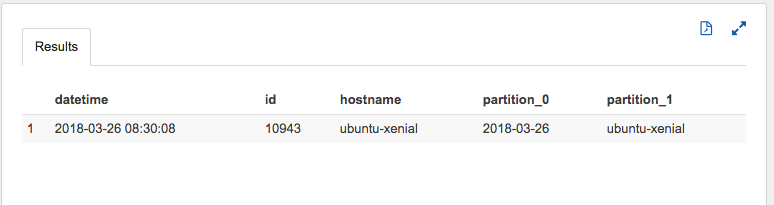
すこぶるシンプルなselect
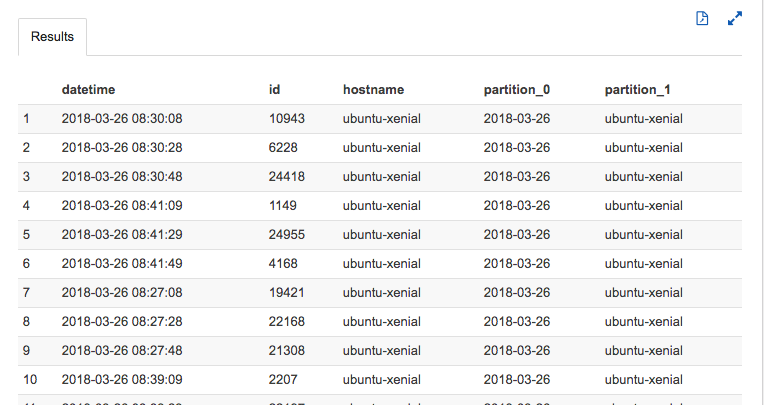
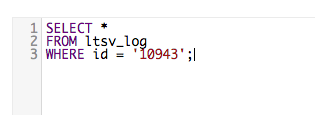
すこぶるシンプルなwhere
まとめ
簡単にではありますが、FluentdでS3に送ったログをAmazon Athenaで集計 select する方法について書きました。
ここまでくればあとは普通にSQLを書くだけなので集計もできるでしょう!