データ活用の現場でよく耳にする言葉があります。「データ品質が悪くて使えない」。
確かにデータ品質は重要な課題です。ただ、私がいくつかの提案やプロジェクト遂行を経験してきた中で感じるのは、「データ品質の問題」というラベルが少し安易に使われすぎているのでは?ということです。
例えば、
- そもそもユースケースがはっきりしない
- データの仕様やビジネス背景を誤解していただけだった
など、実はデータ品質とは別の問題が「データ品質の問題」と呼ばれているケースが、かなりあるのかなと思っています。
この記事では、この問題意識を自身の経験や聞いた話、関連する記事に触れながら述べていきたいと思います。
技術的な話が少ないほぼポエム的(というか愚痴?)な記事ですが、興味があれば読み進めていただければと思います。
1. データ品質の重要性と定義
本題へ入る前の導入として、データ品質の重要性と定義について振り返っておこうと思います。
1-1. データ品質の重要性
まず、データ品質が重要であることは間違いありません。
データ分析の世界には "Garbage in, garbage out" という有名な言葉があります(データ分析に限った言葉ではありませんが)。品質の悪いデータをインプットとすれば、どれだけ優れた分析モデルを使っても、アウトプットは信頼できないものになる。そして間違った分析結果がビジネス上の意思決定のインプットとなれば、ビジネス上の損害に繋がることすらあります。
特に最近注目されている生成 AI 活用においてもデータ品質の課題は注目されています。例えば、PwCの調査レポート「生成AIに関する実態調査 2025 春 5カ国比較」では、生成AIの導入効果が「期待を上回った企業」と「期待を下回った企業」の双方で、その理由の1位・2位として「ユースケース設定」と「データ品質」が挙がっています。
成否を問わずこの2つが上位に来るというのは、後ほど触れる議論とも深くつながっています。
(本題から外れますが、生成 AI のインプットとなるデータはドキュメントなどの非構造化データがより多くなるため、非構造化データのデータ品質を改めて考えないとなぁと最近考えています)
1-2. データ品質とは何か
ここで一度、データ品質の定義を整理しておきたいと思います。
データマネジメントの国際的な知識体系である DAMA-DMBOK では、データ品質に対して以下の品質評価軸に触れています。
| 評価軸 | 説明 |
|---|---|
| 有効性(Validity) | データの値が想定されている範囲、形式、条件などを満たしているか |
| 完全性(Completeness) | 必要なカラムの値やレコードが欠けずに揃っているか |
| 一貫性(Consistency) | 異なるレコード間や異なるデータセット間でデータが同じルールに従っているか |
| 整合性(Integrity) | カラム間やデータセット間の値が矛盾していないか |
| 適時性(Timeliness) | 必要なタイミングで必要なデータにアクセスできるか |
| 最新性(Currency) | データが実体の変化に追従しているか |
| 妥当性(Reasonableness) | データが期待したパターンに収まっているか |
| 一意性/重複排除 (Uniqueness/Deduplication) |
データセット内に同じ実体を表すレコードが2件以上ないか |
| 正確性(Accuracy) | データが実体を正しく表しているか |
これ以外にも、「分かりやすさ」や「メタデータの充実」などもあります。このあたりは以下の書籍で補うことができます。
ただ、これらのデータ品質評価基準を検討する上で前提となる重要な考え方があります。それは、 データ品質とは「目的のユースケースを達成するのに足りているか」 だということです。
同じデータでも、ある用途には十分な品質であっても、別の用途には不十分ということはよくあります。つまり、ユースケースが定まって初めて、何が「高品質」で何が「低品質」かが決まるのです。
DAMA-DMBOK においても「高品質なデータとはデータ利用者の目的に合致するデータである」と記載があります。つまり、データ利用者の目的に依存するということです。
この定義を念頭に置いた上で、次のセクションを読んでいただけると、主張がより伝わりやすいかなと思います。
2. 実は「データ品質の問題」ではなかったパターン
「データ品質の問題を解決・改善したい」という相談をたびたび受けることがあるのですが具体的に話を聞いていくと「それはデータ品質の問題ではないのでは」と思った事例や、似たこと・関連したことに触れている記事などを以下で紹介したいと思います。
この記事には 3 つのパターンに分けて述べますが、MECE になっているわけではなく互いに強く関係しているものもあるので、その点はご了承ください。
パターン (1) ユースケースや分析アプローチの問題
データ品質基準はユースケースによって定まる——ということは、ユースケースや使い方がはっきりしていなければ、データ品質の問題かどうかすら判断できないということでもあります。
「このデータ、品質が悪くて使えない」という発言をよく聞くのですが、「何のためにどう使うのですか?」と聞き返すと、「なんとなく分析に使えれば……」という答えが返ってくることが少なくありません。利用目的が曖昧なまま、漠然とデータ品質に不満を持っているケースです。
そもそもとして、データ品質の向上には時間やコストが掛かります。「なんとなく使えれば」のために投資を続けることは、なかなか難しいのではないでしょうか。
以下では、そんなパターンの経験を述べたいと思います。
(ちなみに、私の経験の話はかなりぼかしている部分もあり、その結果として細かい矛盾もあります。その点はご容赦ください。)
ケース ①:販売実績の収集・加工頻度を上げたい
以下は私が相談を受けたプロジェクトの話です。
このお客様は直営店、FC 点、他社の店舗含めて自社の商品を販売しており、1 日数回、販売実績データを DWH に収集して分析できるように加工していました。次期 DWH を検討する段階になって、1 日数回ではなくより高頻度にデータを収集・加工したいというニーズが上がっていました。当時はリアルタイムのデータ活用が世間では喧伝されていていたという背景もあるのかなと思っています。
この「データ収集・加工の頻度を上げたい」というのはデータ品質でいう「適時性」の向上と解釈することができます。
ただ、この DWH はデータ量が非常に多く、かつデータマートを大量に作っているので、収集・加工頻度を上げるのは技術的にはなかなか辛いものがあり、実現のためにはアーキテクチャを見直す必要性が高かったです。
また、そもそもデータ収集・加工頻度を上げて何を実現したいのか明確になっていなかったため、どの程度の頻度が目標なのか、そのためにどれぐらいコストをかけて良いかというこことを決めることができませんでした。
「リアルタイム性」という要件に関してよくお伝えすることがあるのですが、データ活用は単純化すると以下の流れになっており、データ収集・加工のみリアルタイムにしてもあまり意味がないんですよね。
特に、「結論に基づいたアクション」までの時間を短縮できないとビジネス上の価値になかなかつながらない一方、これを実現するためには業務やビジネスを変える必要があるので一筋縄ではいかないんですよね。
データリアルタイムで集計・加工して何がしたいかというユースケースが明確に描けなかった結果としての、このプロジェクトではデータ収集・連携頻度は変えないという判断になりました。
ケース ②:研修報告レポートをテキスト分析したい
以下は私自身が分析で失敗した事例です。テキストを扱う事案ですが、時期は 10 年以上前で LLM はまだない時期でした。
うちの会社では新人向け研修を外部の会社にお願いしていたのですが、そこで問題になっていたことが、理解度が全く問題ないと講師に評価されていた受講生が実は全く理解できていなかったことが研修後に判明することが少なくなかったことです。端的に言うと研修講師の定量評価と実際の理解度に大きな乖離のある受講生がいるということです。
講師にヒアリングしてもその原因がよく分からなかったため、講師の定量評価だけではなく、受講生に関する講師の日々のコメントや受講生の日報などのテキストを分析して何が起こっているか分析することにしました。ただ、研修生の数も多く、日数も3か月近くのため、結構な量になります。そのため、1つずつ読んでいくのではなく、テキストマイニングを行うことにしました。
ただ、そのままではテキストマイニングをするのが難しかったため、
- PDF からのテキスト抽出(元データを PDF ファイルとして渡されていた)
- 誤字脱字の修正
- 書いた人による表現揺れの吸収
- ネガポジ分析のスコア付与
- 単語の頻出度を分析し、注目すべき単語の抽出
など分析しやすいように様々な加工を行いました。これは DMBOK のデータ品質評価軸のどれに当たるのかというと結構難しいのですが、正確性、有効性、妥当性など複数の軸に関わってくる問題とも言えます。
このあたりに結構手間を掛けながらさまざまな前処理と分析を行っていたのですが、実はそれは無駄骨でした。たどり着いた結論は実にシンプルで、講師のコメントが短い受講生は講師評価と実際の理解度が乖離していたというものでした。(つまり、講師の目が届いていなかっただけではと結論付けしました)
分析の目的(講師評価と実際の理解度の乖離原因を把握したい)は明確にしていましたが、そのための分析のアプローチを詰められていなかったために、そのために無駄なデータ前処理を頑張ってしまったという失敗事例でした。(10年前なので許して…)
パターン (2):非現実的なデータ品質要件
次に示すパターンは、やりたいことは決まっているのですが、それを実現するためのデータ品質を達成するのがそもそも困難なパターンです。つまり実は「やりたいこと」自体が現実的ではない場合です。
ケース ③:生産管理の計画の粒度をより細かくしたい
以下は私が関わったプロジェクトの話です。
製造系における生産管理において、製造の予定数・量と実績数・量を比較する予実管理という業務があります。目的としては以下のようなものが含まれます。
- 製造進捗の悪い製品・工程を早期に把握したい
- 次のサイクルにおける予定立案の精度を上げたい
予実管理自体は行われて当然の業務ですが、この業務を難しくしている 1 つの要因が予定と実績のデータの粒度(製品軸や時間軸、製造設備軸など)が異なるということです。
例えば、以下のように製品軸が異なるということはよくあります。
予定(製品カテゴリごと)
| 製品カテゴリ | 製造予定数 |
|---|---|
| A | 100 |
| B | 150 |
| C | 200 |
実績(製品ごと)
| 製品カテゴリ | 製品 | 製造実績数 |
|---|---|---|
| A | A-1 | 60 |
| A | A-2 | 50 |
| B | B-1 | 100 |
| B | B-2 | 20 |
| C | C-1 | 180 |
| C | C-2 | 150 |
粒度が異なる予定と実績を比較するには、粒度が荒い方に合わせる必要があります。このケースでは、製品カテゴリ単位で製造実績数を集計することで初めて比較できるようになります。ただし、これは製品カテゴリという荒い粒度でしか分析ができないということに繋がります。
そのため、予実管理の全体を見ている人から予定をより細かい粒度で管理したいというニーズをよく聞くことがあります。
これは DMBOK のデータ品質評価軸のどれに当たるかは若干微妙ですが、必要な粒度の情報が欠けているという観点では「完全性」に問題があると捉えらることもできます。
ただ、この問題の解決が現実的かというと、
- 予定立案の担当者としては、不確実性を含む予定を細かい粒度で設定することはできない
- そもそも同じ製品カテゴリ内の異なる製品は設備の設定やごく一部の材料の変更で製造し分けることができるため(かつその柔軟性が組織の競争力の源泉になっている)、製品単位で予定を立てることに意味がない
など、予定を細かい粒度で管理するということが現実的ではないというケースは何度か経験したことがあります。
もちろん、それでもより細かい粒度で予実管理をすべきというケースもありますが、細かい予実管理をすることで得られるメリットが、より細かく予定管理をするコストを上回るかは当たりをつけてから取り組むべきなのかなと思います。
ケース④:個人情報の入力率を上げたい
以下は私が直接関わった話ではないですが、周りの人の話や文献などを参考にしています。
マーケティングの文脈では、「顧客の個人情報をより多く集めて詳細な分析をしたい」というニーズを持ちつつも、実際には個人情報の取得率が低いという不満を持つアナリストも少なくありません。
身近なところでいうと「ポイントカード」の提示率が低いというのは多くの人が感じるところではないでしょうか。以下の記事の冒頭でも触れられていますが、以下のような理由でポイントカードを持っていない人、持っていても提示しない人は多いと思います。
- 個人情報を提供することに抵抗感がある
- 還元率が低くて提示するメリットを感じない
- ポイントカートの提示がめんどくさい
(そもそもポイントカードってリピート率向上が主目的で、それ以外の分析に使えるのかというとかなり難しい気も個人的にはするのですが…)
提示率が低いため、販売履歴と顧客属性の紐付け率が低く十分な分析を行えないという問題は、必要なデータが欠けているという観点では「完全性」、データの取得率が低いという観点では「妥当性」とも考えられます。
ただ、そもそもとして個人情報を集めることに関しては、個人情報保護法を遵守しているか以上に、
- 筋は通っているのか
- 顧客の不安感や手間に寄り添えているのか
- 集めた結果として(自社のメリットではなく)顧客に見合うメリットを返せているのか
ということを考慮する必要があります。それを踏まえて、個人情報の個人情報の充足率向上が現実的か(技術面だけではなく倫理面や説明責任として)というのは冷静に考える必要があります。
このあたり、一部業界の人は情報をいらでも集めて当然みたいなノリがあって、若干話がかみ合わないことも多いのですが…
この話は、元々は上の記事ではなく、あるイベントでの発表資料(情報銀行や Personal Data Store の文脈だったはず)で触れられていた課題感に触発されて作ったのです。ただ、該当の資料のソースを見つけられていないです。似た資料を知っているという方がいたら教えてください。
パターン (3):データ理解の問題
3つ目は、データの仕様を十分に理解していないことから「データ品質が悪い」と勘違いしているケースです。
ケース ⑤:営業履歴が顧客マスタと紐づかない
以下は私が関わったプロジェクトの話です。
とあるお客様の CRM では、営業履歴をシステムに登録する際は、入力を担当する営業の手間などを考慮して顧客名に自由記述を許しています(顧客マスタに登録された顧客を選択するのではなく)。ただし、それだと顧客横串の分析(顧客 360° ビューなど)ができないため、定期的に名寄せを行い営業履歴データと顧客マスタのデータを紐付くようにしていました。ちなみに名寄せ作業自体は私たちではなく別ベンダーが実施しています。
極端に単純化すると以下のようになります。
- 顧客マスタ
| 顧客ID | 顧客名 |
|---|---|
| 1001 | ABC商事株式会社 |
| 1002 | XYZ物産有限会社 |
- 名寄せ前の営業履歴
| 営業履歴 ID | 顧客ID | 顧客名 |
|---|---|---|
| 2001 | null | ABC商事㈱ |
| 2002 | null | ABC |
| 2003 | null | (有)XYZ物産 |
| 2004 | null | XYZ物産 |
- 名寄せ後の営業履歴
| 営業履歴 ID | 顧客ID | 顧客名 |
|---|---|---|
| 2001 | 1001 | ABC商事株式会社 |
| 2002 | 1001 | ABC商事株式会社 |
| 2003 | 1002 | XYZ物産有限会社 |
| 2004 | 1002 | XYZ物産有限会社 |
とある時に、にお客様のアナリストから「営業履歴と顧客マスタがあまり紐付かず、うまく分析できない」という不満をお聞きしました。私もそのアナリストから聞いた方法で営業履歴と顧客マスタを紐付けてみましたが、確かに顧客マスタに紐付かない営業履歴が結構ありました。その時は、名寄せの精度が低いのかな、名寄せの方法を再考しないといけないかなと思っていました。
これはデータ品質評価軸でいうと「正確性」や「整合性」に関わる問題です。
ただ、いろいろ調べてみると、そもそも紐付け方法が間違っていただけでした。上に示したサンプルデータでいうと、名寄せした結果はブリッジテーブルを介して顧客 ID とは別のキーで紐付けると顧客マスタと紐付くという状況でした。(これはどのドキュメントにも書かれておらず、データから推測して得られた結論というのがまた悲しいですが)
なぜそのアナリストが名寄せをしたベンダーから紐付け方法を聞いていなかったのかは今となっては理由は分かりませんが、普段から自身が使っているデータですら仕様を把握できていないことがあるんだなということで印象に残っています。
ケース⑥:医療データが仕様に沿ってない
以下は、又聞きの話です。
病院や診療所でパッケージソフトに入力された医療系のデータはデータの仕様は公開されているのですが、実際のデータがその仕様に合っていないというケースが多々あるそうです。
もちろん、入力者がルールに従わずに入力しているために仕様を満たしていないデータということもあるのですが、それ以外にも仕様が年ごとに変化しており、2024年のデータが2023年の仕様に沿って作成されていた(2024年の仕様には合致していない)ということも多々あるそうです。
2024年のデータは2024年の仕様に沿って作成されるべきだろうと言えば理想としてはその通りなのですが、現実として医療データを作成している病院などにおいてパッケージソフトをタイムリーに更新できるかといえば現実的ではないため、そこはデータを使う側で理解して吸収しなければいけないという話でした。
ケース⑦:雇用統計を過大評価している
以下の話は、以下の記事を元に起こしています。私の経験ではありません。また、この記事のタイトルを参考にこの節のタイトルをつけています。
記事の中で引用されている例として、米国の雇用統計は「一人が複数の職を持つ場合に重複計上される」という仕様を持っていますが、多くのアナリストがこれを把握せずに誤用しているとのことです。結果として、雇用されている人の数を過大評価しており、それが株価などに影響を与えているのではという話です。
データには定義だけでなく「実際に何が含まれ、何が含まれていないか(範囲)」を理解することが必要で、"データ品質を批判する前に、データを理解する責任を果たすべき" という論点は、私自身も共感するところです。
3. データ品質に対してとりたい姿勢
ここまでの話を踏まえ、データ品質についてどう向き合えばいいのか、私がぼんやり考えていることを以下に述べます。上で述べたケースに1対1で対応しているというわけではないですが、関係する部分は大きいと思っています。
(1) データ分析とデータ品質向上のロードマップを合わせて検討する
データ品質に限らず、データマネジメント一般に言えることなのですが、事を進める上での大きな障壁として、「データ品質を向上する人」と「データ品質向上でメリットを享受する人」が多くの場合で異なるため、平たく言えば「なんでお前のために頑張らなければいけないのか」という利益対立が起きるということです。
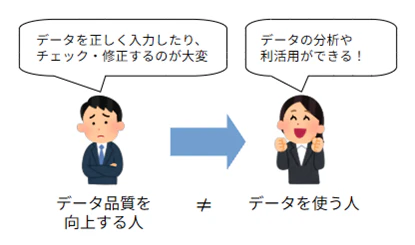
この関係は技術者(データエンジニアなど)とビジネスユーザという違いだけではなく、以下のようなビジネス部門同士でも起きる話です。
- 「各部門の現場社員」と「本社共通部門(財務部や企画部など)」
- 「製造部門」と「販売部門」(販売部門の需要予測のデータをもとに製造部門が生産計画を立てる場合など)
この利益対立を解決するために、「経営トップのコミットが必要」とか「インセンティブ設計が必要」とか言われているのですが、日本の組織においてはそのようなトップダウンのアプローチだけではあまりうまくいかないように思います(間違いなく必要なことではあるのですが)。
特にデータ分析の分野においては、実際にやってみないとどれだけメリットが得られるか分からないケースも多いため、データ品質を向上する側からすると「そのデータ分析、やる意味あんの?意味ないことのために頑張るの嫌なんだけど…」となりやすいです。
この問題を解消するために必要なことは、以下のようにデータ分析のビジネス成果を少しずつ実現してくことに合わせて、データ品質も少しずつ向上していくことかなと思っています。
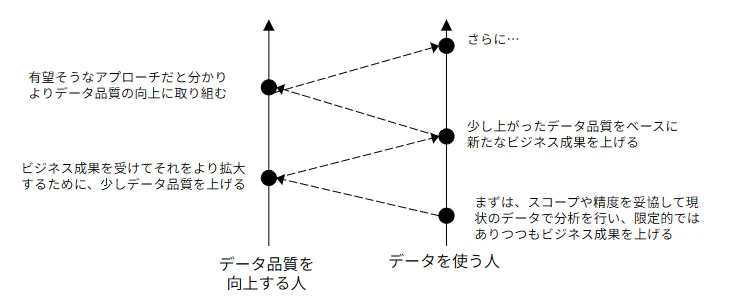
(最初の一歩がどちらかというのは非常に難しい問題ですが、ここではひとまず「データを使う人」側としています)
こうすることで、以下のような効果があると思っています。
- いきなりデータ品質向上のために大きなコストを掛けることを回避する
- データ分析の意義を徐々に理解してもらう
- 実現できたビジネス成果を元にデータ品質を向上する人へのインセンティブを考えられるようになる
この「データ分析」と「データ品質向上」のサイクル(ロードマップ)を合わせて検討することが非常に重要なのかなと思います。
ちなみに、機械学習などをデータ分析の手法として用いようとしている場合、最初から比較的高いデータ品質を求められることが多いように感じますが、そういった場合は「初手から機械学習に着手するのが本当に正しいのか」というのは常に問いたいですね。
(2) データ品質の問題を分類する
「データ品質の問題」と言われているものが実際にデータ品質の問題か違うのかに関わらず、問題の具体化・明確化を図ることが重要だと思っています。
一般論として問題を具体化・明確化するには分類・細分化するのが良いのですが、ポイントはデータ品質の問題においてはどのように分類・細分化するのが良いのかという話です。よく、以下の点で分類しようとしているケースを見かけます。
- どのデータが問題か
- どのデータ品質評価軸が問題か
ただ、前者の「どのデータ」というのは良いとして、後者の「どのデータ品質評価軸」というのはあまり良いアプローチではないと思っています。それが分かったからといって、どう改善するのがよいのか、どの程度改善するのが良いのかという検討に繋がりづらいからです。
問題の分類の方法に正解はないのですが、私はよく加えて以下の軸で分類しています。
- データ分析はどのフェーズか(PoC、開発、運用など)
- データ品質の問題はどこで発生しているのか(データ入力者、対向システム、データパイプライン、データ分析者など)
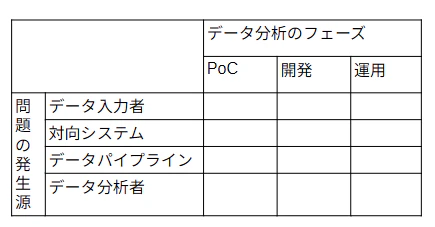
前節の話とも絡むのですが、データ分析のフェーズがどこかによって、採用できる現実的な対策や対策の種類など大きく変わってくるため、特に押さえておきたいです。
また、問題の発生源に関しては、直近対応としては必ずデータ発生源で対応する必要があるとは限らないのですが(そうできるのが本来理想ではあるのですが)、中長期的に見た時には発生源での根本対応に踏み込む必要があるので、押さえておく必要があります。
(3) データオーナーのいうことを鵜呑みにせず、実データを泥臭くチェックする
データメッシュなどではデータオーナー(チーム含む)がデータの管理を各自で実施できるような環境やプロセス、文化を重要視しています。データオーナーがドメインエキスパートとして該当のデータに一番詳しいので、組織としてスケールさせるにはそれが最適という考え方に基づいています。
では、データの仕様や品質に関してデータオーナーが責任を持つべきかというと、私は以下の理由でデータオーナー 「のみ」 が責任を持つのは結構難しいと思っています。
- データオーナー(外套のビジネス部門)がデータに一番詳しいとは限らない
- 私の経験上、そうではないケースが多いです
- 日本のシステムの多くを SIer が構築しており、ビジネス部門と SIer で必要な知識が分散してしまっているという背景も原因のひとつかもしれません
- データ品質は利用のユースケースに依存する
- データオーナーが知らないユースケースに対して品質を担保することは困難
データオーナーがある程度データの仕様の共有やデータ品質の担保について責任を持つべきなのは間違いありませんが、データ利用者側もデータオーナー側の情報を鵜呑みにせず、自身で泥臭く仕様通りかチェックしたり、品質のモニタリングやデータ修正に積極的に行うべきかと思います。
ここで改めて言うまでもなく、ビジネスアナリストはデータを使う際に俯瞰しておかしな点がないかチェックしますし、データサイエンティストはデータプロファイリングを必ずします。こういうことを徹底的にやるのが必要なのではないかと思っています。
話は脇に逸れますが、これらのタスクは手間もかかりますし、チェック漏れも発生しやすいのは事実です。この分野に AI エージェントを活用できないかという点に最近私は興味を持っています。(まだいろいろ調べ始めた段階ですが)
まとめ
「データ品質」は間違いなく重要な課題です。
ただし、実際に「データ品質の問題」と言われている問題を紐解いていくと、「データ入力者が適切にデータを入力していない」、「データパイプラインでデータを壊している」といったシンプルな話ではなく、複雑な事情が絡んでおり、そもそも別の問題ではと思うことも多いことを、複数のケースを例に紹介しました。
DMBOK でも知識領域は互いに関連するということが言われていることを考えると別に不思議なことではないのですし、対策も他の領域の取り組みに関わることが多いと思います。
結局はラベル付けして満足せず、問題を分解・具体化して地道に取り組むことが重要なのかなと考えています。