本記事では、様々なシステムからデータを収集・蓄積・加工してデータ分析用に提供するデータパイプラインにおいて、処理の単位を考える上での考慮すべき点をいくつか書き殴ってみようと思います(書き殴りなので重大な抜けはあると思います)。
ここでの処理の単位というのはちょっと曖昧ですが、外部から呼び出されるスクリプトをどの単位で書くかということを指してると思ってください。Airflowを使っていればタスクを、JP1を使っていればジョブをどの単位にするかということと言い換えても良いかもしれません。
処理の単位を決める観点は複数あり、要件や制約に応じて判断するものなので、常にこうすべきという方針があるわけではないことはご了承ください。
1. 想定する処理内容
具体的な例がないと説明しづらいので、以下のようなシステムAとシステムBからデータを取得して、汎用的に分析に利用可能なテーブルを作成し、その後に特定の分析用のデータマートを作成する簡単なデータパイプラインを想定します。
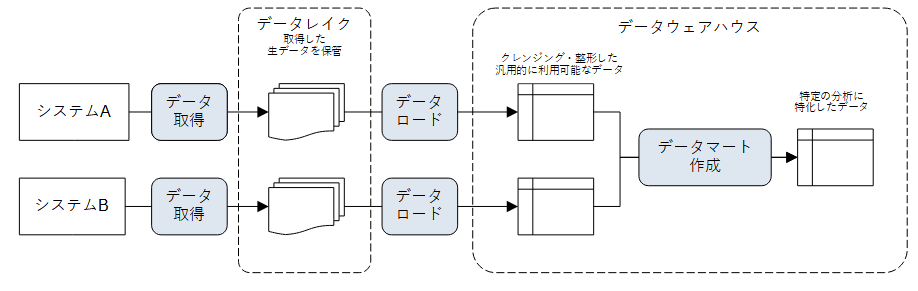
青い角丸の四角が処理を表しています。
- システムAとシステムBから取得したデータは、そのままの形でデータレイク(S3などのオブジェクトストレージ)に保管します(なので誤データや重複があるかもしれません)。
- データレイクのデータをデータウェアハウス(SnowflakeやRedshiftなど)にクレンジング・整形してロードします。この時点では、、汎用的な分析に利用できる構造でデータを作成します。
- ここではクレンジング・整形含めて「データロード」としています。リアルなら処理を分けるような気もしますが、説明を簡単にするために1つにしています。
- ロードされたデータから分析に特化した集計済みデータマートを全件洗い替え(truncate/insert)で作成します。
2. 処理の単位を決める上での考慮点
- 処理の内容/役割
- データパイプラインに限らず、処理の目的が違うものは1つにまとめたくない。
- 例えば、システムAからデータを取得する処理と、システムBからデータを取得する処理は、そもそも違う処理なので1つにしたくない。
- 1つのシステムから複数の種類のデータを取得する場合は状況による。
- 例えば、顧客マスタの取得処理と商品マスタの取得処理は、そもそも別々のデータなので別の処理としたい。
- ただし、依存関係にあるデータ(注文と注文明細など)は1つにする場合もある(1つにまとめた方が1トランザクションで整合性を保ってデータを取得しやすいという利点もあるかも)。
- データ取得とデータロードも役割が違うと言えば違うが、ここは主観的な判断なので、別の考慮点から判断。
- データパイプラインに限らず、処理の目的が違うものは1つにまとめたくない。
- 実行タイミング
- 処理を実行するタイミングが別々なもの、もしくは別々に実行することがあるものは、別の処理にしたい。
- 上の例でいえば、システムAとシステムBはデータを取得するタイミングが違うはずなので、別々の処理にする。
- 通常は同じタイミングで処理すればよいが、システム障害時に別々のタイミングで処理しないといけないものもあるので見極めが必要。
- よく、データソース側の障害の都合で、この処理だけ先に進めたいみたいなケースがある(システムAは止まっているけど、システムBは稼働しているのでシステムBからのデータ取得&データロードは実行したいなど)。
- データソース側のデータ生成過程やデータオーナー、データ提供先にある業務などを知っておくと判断の助けになる。
- 処理を実行するタイミングが別々なもの、もしくは別々に実行することがあるものは、別の処理にしたい。
- システムの境界
- 他システムと連携する処理はできれば小さくしたい。
- 今回の例でいえば、データ取得はデータソース(システムA/B)と絡むが、データロードはデータソースとは絡まないので、別々の処理にしたい。
- 今回の例にはないが、データを提供する方も同じ。
- 他システムと連携する処理はできれば小さくしたい。
- テストのしやすさ
- 一般に処理は小さいほうが単体テストはやりやすい。
- データ取得とデータロードを1つの処理にしてしまうと、データソースとデータレイクとデータウェアハウスがテスト実行に必要だが、別々に分けておけば、データ取得はデータソースとデータレイクがあれば、データロードはデータレイクとデータウェアハウスがあればテスト可能。
- ここでの要/不要はインフラの準備だけではなく、その上のデータ準備まで含む。
- ただし、処理を分けることで、前の処理が直前に正しく実行されたことを前提にできなくなるため、テストケースが増える。
- 例えば、データロードはデータレイク上にファイルがないケースもテストすべき(そもそも論として、処理を1つにする/しないに関わらずチェックすべきという考え方もある)
- データ取得とデータロードを1つの処理にしてしまうと、データソースとデータレイクとデータウェアハウスがテスト実行に必要だが、別々に分けておけば、データ取得はデータソースとデータレイクがあれば、データロードはデータレイクとデータウェアハウスがあればテスト可能。
- 一般に処理は小さいほうが単体テストはやりやすい。
- リラン(再実行)のしやすさ
- 基本は失敗した処理からリランすればOKとなるようにしたい。
- データマート作成はtruncateとinsertの2つに処理単位を分けることができるが、insertが失敗した場合は(通常は)truncateからリランすべきなので、できれば同じ処理としたい。
- 処理の冪等性を保つためには一般には何かしらの初期化処理が必要で、その初期化処理と本体の処理は分けない方が良いのではと思う。
- データ取得とデータロードを1つの処理にすることもできるが、データロードが一時的なエラー(例えば一時的なサービスダウンや容量不足など)で失敗した場合、データ取得からやり直すことになり、データソース側に迷惑が掛かるので、この2つは別の処理にしたい。
- データロードとデータマートの処理も1つにまとめると、データマート失敗時のリランがデータロードからになるので、リラン時間が伸びる。
- データマート作成はtruncateとinsertの2つに処理単位を分けることができるが、insertが失敗した場合は(通常は)truncateからリランすべきなので、できれば同じ処理としたい。
- 厳密にはリランと違うが、ネットワークやサービスの瞬断などのエラーに対して自動リトライさせたい場合、リトライのロジックはジョブ管理ツールやフレームワーク側で持たせたい。この観点でも処理単位を考慮する必要がある。
- 基本は失敗した処理からリランすればOKとなるようにしたい。
- 運用のしやすさ
- どの処理でエラーになったか分かり易くするためには、細かめに処理を分割した方が良い。
- 処理のログをちゃんと出力すれば分かるという話もあるが、ジョブ管理ツールのGUI上で一見してエラーとなった箇所が分かるのは、運用者(≠開発者)にとってはありがたい。(ただ、これはジョブ管理ツールがどれだけ分かり易いGUIを提供しているかに大きく依存する)
- その処理がどれだけ時間が掛かったかも、ジョブ管理ツール側で一元管理するのであれば、処理時間を確認したい単位で処理を分けるという考えもあり。
- リランする際も、障害の原因が解決したら失敗した処理から再実行すればOKであればシンプル(プログラムのバグやデータに起因する障害の場合はそうもいかないケースが多いですが)
- どの処理でエラーになったか分かり易くするためには、細かめに処理を分割した方が良い。
- 後続処理への影響
- 例えば、データロードで作成されたデータをユーザーに提供することを想定している場合は、データロードとデータマート作成は別の処理にしたい。
- データマートの作成処理が何かしらの理由で処理時間が伸びた場合、処理を別々にすることでデータロードで作成されたデータは既に提供できる状態にあることが分かり易い。
- 処理を1つにすると、データロードが完了して、データマート作成が失敗した場合に、先にデータロードで作成したデータをユーザーに提供しずらい(後のリランの際にデータが変わるかもしれない)。
- 例にはないが、データマート作成後にデータマートテーブルのオプティマイザ統計情報収集処理がある場合(Oracleなど)、データマート作成と統計情報収集処理の処理を分かるかどうかは悩ましい。
- 統計情報収集してからしかユーザーに提供したくないなら、分けない。
- 統計情報収集が終わっていなくとも(エラーになっても)ユーザーにデータ提供したいなら、分ける。
- 処理の結果としてエラーと警告を使い分けることがあるが(エラー時は後続処理を実行しない。警告時は後続処理を進める)、
- 例えば、データロードで作成されたデータをユーザーに提供することを想定している場合は、データロードとデータマート作成は別の処理にしたい。
- 処理量
- 複数の小さい処理(例えば、大量にあるコード系テーブルを取得するなど)は1つの処理にまとめた方が処理が減って分かり易い。
- 利用する言語・テクノロジ
- データ取得はPythonなどのスクリプト、データロードはSQLなど、利用する言語やテクノロジや違うタスクは別の処理にした方が良い。
- あまり良くないが、利用する言語・テクノロジが特定の開発者に結びついてしまう場合は、開発者/チーム単位で処理を分けざるを得ない場合も。(そもそも開発を担当する会社が違う場合とか)
個人的にはリランとか運用時の分かり易さを優先して処理の単位を決めますが、富豪的プログラミング的なアプローチで気にせず全体を毎回実行すればよいという世界に早くならないかな(データパイプラインは対向システムがある都合上、中々そういう世界にはならないだろうと思っていますが)。