はじめに
前回の記事では、ALBの構築に必要な設定項目と、それぞれの設定項目がALBの処理プロセスにどう影響を与えるかまとめました。今回はECSにおけるスケーリングについて、前回同様に、設定項目と処理プロセスへの影響をまとめたいと思います。
最後にこちらのサイトを参考に作成したインフラ構成に、オートスケーリングを適用します。
本記事のミッション
- スケーリング方式(ターゲット追跡・ステップ・スケジュールド・手動・オートヒーリング)の役割と違いを把握する。
- ECS上でスケーリングをてきようするさい基本的な設定項目と各設定項目がスケーリングの処理プロセスにどのように作用しているか理解する。
本記事で書いていること
- スケーリングの目的と種類
- ECSのスケーリングにおける各設定項目と処理プロセス
- ターゲット追跡スケーリング
- ステップスケーリング
- ECSにおけるステップスケーリングの構築手順
- 今後の展望
スケーリングの目的と種類
スケーリングの目的は、サーバに負荷がかかったとき、サーバの台数、スペックを増減することで、安定稼働を保つことです。スケーリングの実現方法は複数あり、本章では5パターン紹介します。
※本記事ではスケールイン、スケールアウトについて整理をしています。インスタンスの性能自体を向上させるスケールアップ、スケールダウンについては今回は言及しません
動的スケーリング
動的スケーリングについては、基準値の設定方法の違いから、ターゲット追跡スケーリングとステップスケーリングの2種類あります。
ターゲット追跡スケーリング
概要:指定したCloudWatchメトリクス(CPU使用率など)を目標値に維持するようにタスク数を調整する
用途:安定した負荷変動に対して、最適なパフォーマンスを維持したい場合
その他留意点:ECSでターゲット追跡スケーリングを設定すると、CloudWatchアラームが自動作成されます。この設定は、CloudWatchからは管理できません。
ステップスケーリング
概要:指定したCloudWatchアラームの閾値に基づいて、段階的にタスク数を増減する。(例:CPU使用率が70%を超えたら2タスク追加など)
用途:急激な負荷変動や予測不可能なトラフィックに対応したい場合
その他留意点:ターゲット追跡スケーリングと同様にECSから設定できますが、ステップスケーリングの設定はCloudWatchからも管理可能です。
スケジュールドスケーリング
概要:あらかじめ設定したスケジュールに基づいて、リソースを自動増減させる
用途:特定の時間帯や曜日など、予測可能なトラフィック変動に合わせて調整を行う
手動スケーリング
概要:手作業でスケーリングを行う。
用途:大きなイベント前など、不定期で起きる負荷変動が事前に予測できる場合や予測不可能な負荷変動に対して柔軟な対応が求められる場合
オートヒーリング(厳密にはスケーリングではないが..)
概要:サーバ台数を一定数に保つように、異常なサーバが出たら削除し、新規サーバを追加する形でスケーリングを行う。
用途:コストの観点からサーバを一定数に保ちたい場合など
ECSのスケーリングにおける各設定項目と処理プロセス
ECSではECSのサービスの構築時にスケーリングの設定をすることができ、ECS内ではターゲット追跡スケーリングとステップスケーリングを選択できます。今回はそれぞれの設定項目と各設定項目がどのように処理プロセスに影響を与えるか、まとめました。
ターゲット追跡スケーリングの設定項目
| 設定項目 | 説明 |
|---|---|
| プロトコル | ターゲットと通信するプロトコル(HTTPまたはHTTPSを選択) |
| ポリシー名 | スケジュールポリシーを識別するための名前 |
| ECSサービスメトリクス | 監視対象となるECSサービスの指標(メトリクス)を選択する。 事前定義されたメトリクス(CPU使用率、メモリ使用率)や、カスタムメトリクスを使用できる。 |
| ターゲット値 | ECSサービスメトリクスに対して、維持したい目標値を設定する。 |
| スケールアウトクールダウン期間 | スケールアウト後にスケールアウトを実行しない期間(短時間で頻繁なスケールアウトを防ぐために設定) |
| スケールインクールダウン期間 | スケールイン後にスケールインを実行しない期間(短時間で頻繁なスケールインを防ぐために設定) |
ターゲット追跡スケーリングの処理プロセス
1. 設定したECSサービスメトリクスの値の監視を行い、ターゲット値から乖離しているかどうかチェックを行う。
2. ターゲット値を超えた場合、スケールアウトを行う。ターゲット値を下回った場合はスケールインを行う。
3. 短時間で頻繁なスケーリングが発生することを防ぐために、
スケールインした後、スケールインクールダウン期間で設定した時間分、スケールインを行うことを待機する。スケールアウト時も同様にスケールアウトクールダウン期間に基づいて一定期間待機する。
ステップスケーリングの設定項目
ステップスケーリングの設定では、監視対象を設定するScaling ポリシーとアラート後のアクションを設定するScalingアクションの二つ設定する必要がある。
Scaling ポリシー
| 設定項目 | 説明 |
|---|---|
| ポリシー名 | スケーリングポリシーを識別するための名前 |
| Amazon ECSサービスアラーム | 新しいアラームを作成するか、既存のアラームのどちらを使用するか選択する。新しいアラームを選択する場合は下記設定を行う。 |
| CloudWatchアラーム名 | スケーリングのトリガーとなるCloudWatchアラーム名 |
| Amazon ECS サービスメトリクス | 監視対象となるECSサービスの指標を選択する。事前定義された指標(CPU使用率、メモリ使用率)や、カスタムメトリクスを使用できる。 |
| 統計 | 設定したメトリクスの統計方法を選択する。(平均、最大、最小など) |
| 期間 | メトリクスの値を集計する時間間隔を指定する。(5分間の平均をとるなど) |
| アラームの状態 | 選択したメトリクスと定義されたしきい値を比較する方法を定義する。(しきい値より大きい、小さい…など) |
| メトリクスを比較するためのしきい値 | メトリクスで設定した値のしきい値を設定する。 |
| アラームを開始する評価期間 | ここで指定した回数連続でしきい値を超えたときにアラーム状態に移行する。 |
Scalingアクション
| 設定項目 | 説明 |
|---|---|
| ポリシー名 | スケーリングポリシーを識別するための名前 |
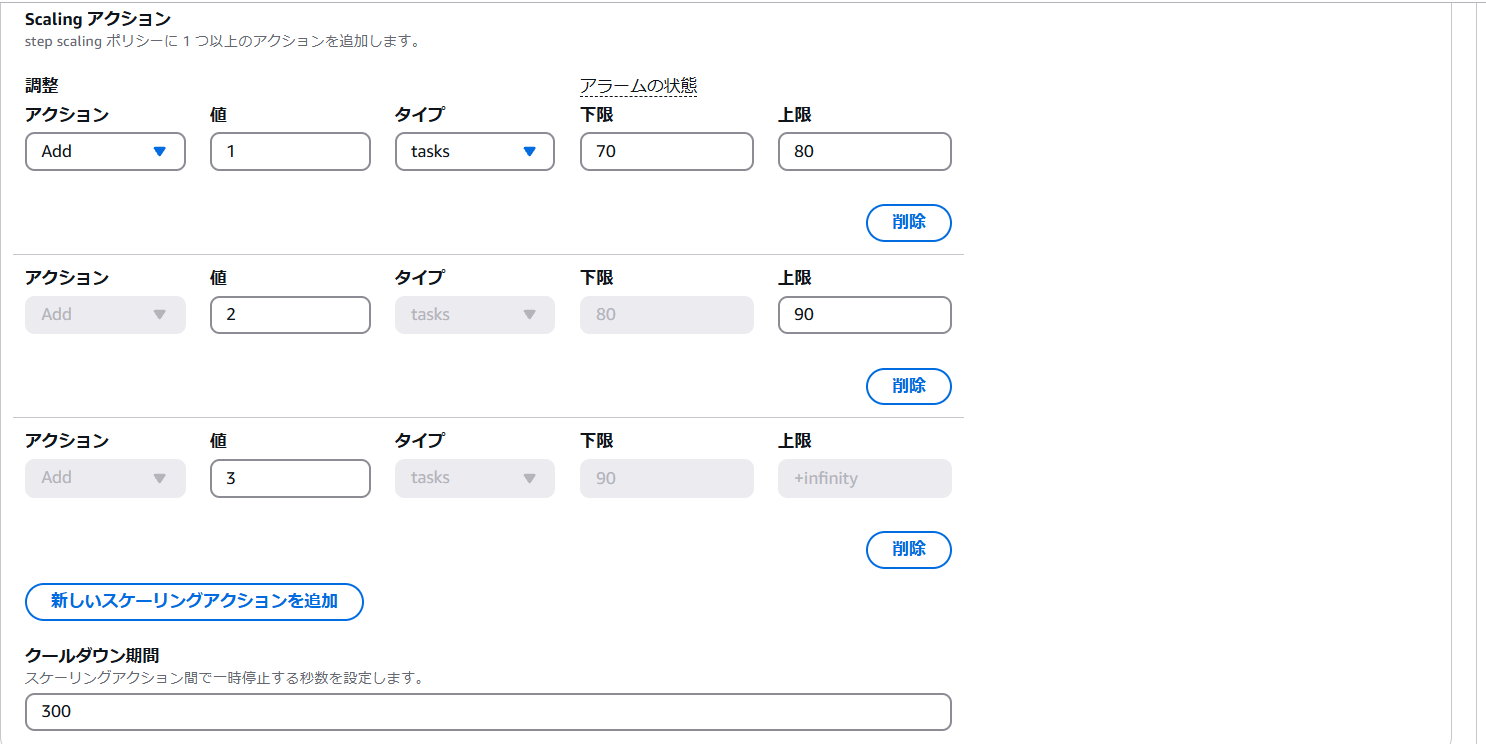
| アクション | アクションは以下3つのアクションから選択する。 追加:タスクを追加する。 次に設定:値に設定したタスク数にする。 削除 : タスクを削除する。 |
| 値 | アクション時、追加、削除するタスク数またはパーセンテージの値を入力する |
| タイプ | タスク数またはパーセンテージを選択する。 タスク数:タスク数の絶対数 パーセンテージ:現在のインスタンス×「値」に設定したパーセンテージ分タスク数を増減させる |
| アラームの状態-下限 | アクションを実行するメトリクスの範囲における下限値 |
| アラームの状態-上限 | アクションを実行するメトリクスの範囲における上限値 |
| クールダウン期間 | スケーリングアクションが行われた後スケーリングを実行しない時間を設定する。 |
ステップスケーリングの処理プロセス
アラームの監視
1. ECS サービスメトリクスで指定されたメトリクス (例: CPU 使用率) を監視し、期間(例:15分)で設定された時間ごとに統計(例:平均、最大、最小・・)で指定された方法で集計する。
2. 1で集計されたメトリクスは、アラームの状態で定義された条件 (例: しきい値より大きい) に基づいて、メトリクスを比較するためのしきい値と比較する。
3.条件を アラームを開始する評価期間で指定した回数、連続して満たすと、 CloudWatch アラームがトリガーされる。
Scalingアクションの実行
アラームがトリガーされると、Scaling アクション で定義されたアクションを実行する。
4. メトリクスの値がアラームの状態-下限とアラームの状態-上限の範囲にあるとき、アクション (追加、設定、削除) と値に基づいて、タスクの数が調整される。
5. クールダウン期間が設定されている場合、前回のスケーリングアクションから指定された時間が経過するまで、次のスケーリングアクションは実行されない。
構築手順
今回はこれまで説明してきたオートスケーリングのうち、より詳細な設定が必要なステップスケーリングの設定を行います。ECSのサービス作成時に設定ができますが、今回はサービスを既に作成済のものとし、サービスの更新から設定を行います。
ECSの設定画面から対象クラスタ>サービスに遷移、対象のサービスを選択し、「更新」をクリックする。
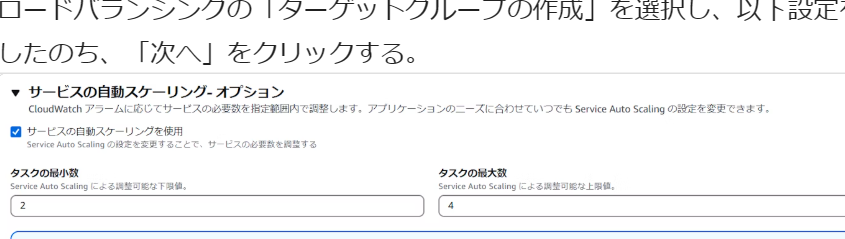
遷移後の画面で、サービスの自動スケーリング-オプションから「サービスの自動スケーリングを使用」を選択する。
自動スケーリングで調整するタスク数の最小数と最大数を入力する。
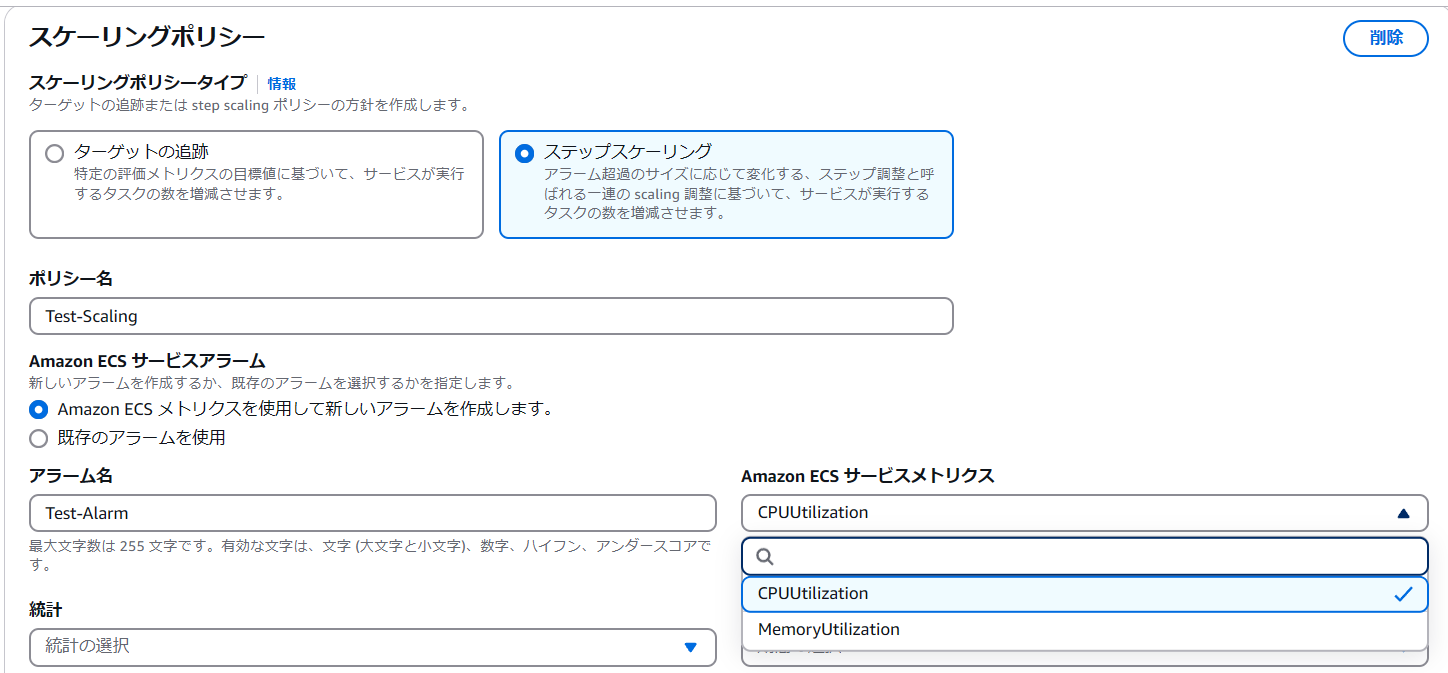
今回はより柔軟な設定が可能なステップスケーリングの設定を行う。
- スケーリングポリシータイプ:ステップスケーリング
- ポリシー名:任意のスケーリングポリシー名を入力
- アラーム名:任意のCloudwatchAlaram名を入力
- ECSサービスメトリクス:CPUutilization(CPU使用率)
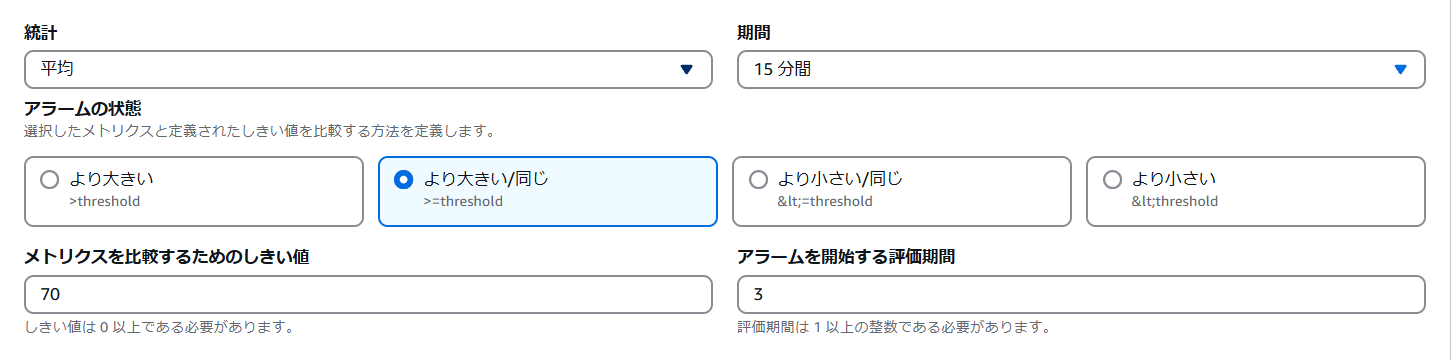
CloudWatchアラームのトリガーを設定する。今回は15分間のCPU使用率の平均が、70%以上となる回数が連続で3回発生した際にアラームを発動する設定とする。 - 統計:平均(時間当たりの平均CPU使用率)
- 期間:15(15分間の平均CPU使用率)
- アラーム状態:より大きい/同じ(CPU使用率がしきい値以上の場合アラームを発動)
- メトリクスを比較するためのしきい値:70(%)
- アラームを開始する評価期間:3(3回連続でしきい値が70を超えた時に発動)
CloudWatchアラーム発動後のアクションを設定する。CPU使用率に応じて以下の挙動となるように、設定を行う。また、クールダウン期間は300秒とし、「更新」をクリックする。 - CPU使用率が70%-80%の場合:タスク数1つ追加
- CPU使用率が80%-90%の場合:タスク数2つ追加
- CPU使用率90%-100%の場合:タスク数3つ追加
CloudWatchアラームに遷移すると作成されたことが確認できた。

今後の展望
今回はスケーリングの目的と種類の説明から始まり、ターゲット追跡スケーリングとステップスケーリングについて、設定項目と処理プロセスの関係についてまとめました。各設定項目が何のために設定するものなのかだいぶ理解が進んだと思います。
今後は以下のような内容について、調査や、ハンズオンを行い、記事にしてみたいと思います。
- オートスケーリングについて
- Apache Benchなどを用いて負荷テストを行う
- その他の機能について
- ALBのやり残し(Cognitoによる認証、HTTPS通信によるリクエストの受信・・)
- Route53+ACMによるHTTPS通信の導入
- 監視設定など
- バックエンドを変更