この記事ではPytorchで学習したモデルをONNX形式に変換し、TouchDesigner上でOpenCVのdnnモジュールを用いた推論に利用する方法について解説します。ONNX形式に変換することで余分なパッケージをインストールせずにTouchDesignerに最初からインストールされているOpenCVだけで推論が可能となります。
今回は例題として、MNISTデータセットを利用した手書き数字の認識を行います。
検証にはMacを利用し、各ツールのバージョンは以下のようになっています。
- Python: 3.11.4
- Pytorch: 2.0.1
- TouchDesinger: 2022.33910
検証に仕様したコードやTouchDesingerファイルはGitHubに置いておきました。
https://github.com/aadebdeb/pytorch-onnx-touchdesinger-demo
筆者はPytorchにもTouchDesingerにもOpenCVにもそこまで詳しくないので、解説には間違っている点や冗長な部分が含まれているかもしれません。その点はご了承ください。
Pytorch環境の作成
Pytorch公式サイトのGetStartedを参考に環境を作成します。pythonのパージョン管理にはpyenv、パッケージ管理にはvenvを用います。
$ pyenv local 3.11.4
$ python -m venv .venv
$ . .venv/bin/activate
$ pip install torch torchvision onnx
Pytorchによる学習とモデルのONNX形式への変換
Pytorch公式サイトのQuickstartチュートリアルを参考にして、学習とONNX形式への変換を行うPythonプログラムを作成します。
import torch
from torch import nn
from torch.utils.data import DataLoader
from torchvision import datasets
from torchvision.transforms import ToTensor
import numpy as np
import torchvision
training_data = datasets.MNIST(
root="data",
train=True,
download=True,
transform=ToTensor(),
)
test_data = datasets.MNIST(
root="data",
train=False,
download=True,
transform=ToTensor(),
)
batch_size = 64
train_dataloader = DataLoader(training_data, batch_size=batch_size)
test_dataloader = DataLoader(test_data, batch_size=batch_size)
for X, y in test_dataloader:
print(f"Shape of X [N, C, H, W]: {X.shape}")
print(f"Shape of y: {y.shape} {y.dtype}")
break
device = "cpu"
class NeuralNetwork(nn.Module):
def __init__(self):
super().__init__()
self.flatten = nn.Flatten()
self.linear_relu_stack = nn.Sequential(
nn.Linear(28*28, 512),
nn.ReLU(),
nn.Linear(512, 512),
nn.ReLU(),
nn.Linear(512, 10)
)
def forward(self, x):
x = self.flatten(x)
logits = self.linear_relu_stack(x)
return logits
model = NeuralNetwork().to(device)
loss_fn = nn.CrossEntropyLoss()
optimizer = torch.optim.SGD(model.parameters(), lr=1e-3)
def train(dataloader, model, loss_fn, optimizer):
size = len(dataloader.dataset)
model.train()
for batch, (X, y) in enumerate(dataloader):
X, y = X.to(device), y.to(device)
pred = model(X)
loss = loss_fn(pred, y)
loss.backward()
optimizer.step()
optimizer.zero_grad()
if batch % 100 == 0:
loss, current = loss.item(), (batch + 1) * len(X)
print(f"loss: {loss:>7f} [{current:>5d}/{size:>5d}]")
def test(dataloader, model, loss_fn):
size = len(dataloader.dataset)
num_batches = len(dataloader)
model.eval()
test_loss, correct = 0, 0
with torch.no_grad():
for X, y in dataloader:
X, y = X.to(device), y.to(device)
pred = model(X)
test_loss += loss_fn(pred, y).item()
correct += (pred.argmax(1) == y).type(torch.float).sum().item()
test_loss /= num_batches
correct /= size
print(f"Test Error: \n Accuracy: {(100*correct):>0.1f}%, Avg loss: {test_loss:>8f} \n")
epochs = 30
for t in range(epochs):
print(f"Epoch {t+1}\n-------------------------------")
train(train_dataloader, model, loss_fn, optimizer)
test(test_dataloader, model, loss_fn)
model.eval()
torch.onnx.export(
model,
torch.randn(1, 1, 28, 28, device=device),
"exports/model.onnx",
)
おそらく、ネットワーク構造を工夫するなどすれば精度がより上がるとは思いますが、そこは今回の本題ではないので省略します。
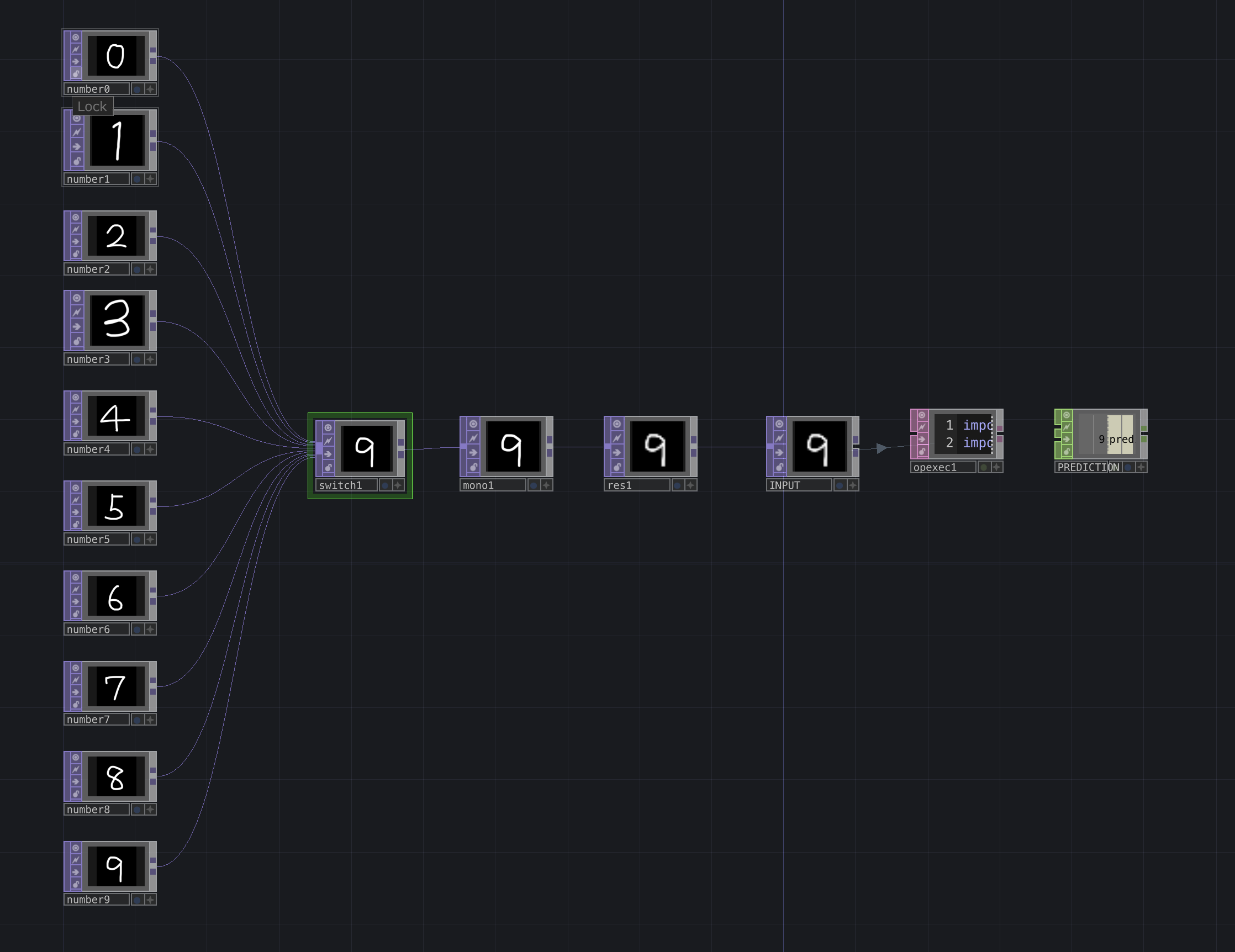
TouchDesignerでの推論
TouchDesinger上で作成したONNXファイルを用いて推論を行うPythonスクリプトを作成します。今回はOp Execute DATを利用しています。
import numpy as np
import cv2
net = cv2.dnn.readNetFromONNX("assets/onnx/model.onnx")
def onPostCook(changeOp):
frame = changeOp.numpyArray()
frame = frame[:, :, 0]
image = (frame * 255.0).astype(np.uint8)
image = np.flipud(image)
blob = cv2.dnn.blobFromImage(image, 1 / 255.0, (28, 28))
net.setInput(blob)
output = net.forward()
prediction = np.argmax(output)
print(f"prediction: {prediction}")
op("PREDICTION").par.value0 = prediction
ネットワークは以下のようになっており、Pythonスクリプトで推論する前に入力画像のグレイスケール化(この例では入力画像がもともとグレイスケールなので不要ですが...)や、ネットワークのインプットに合わせてリサイズ(この例では28x28)をしています。