※Keras用の記事です
セッション切れ問題
Google Colaboratoryの90分セッション切れ対策【自動接続】
Google Colaboratoryでは以下の条件を満たす場合、実行中のプログラムがあってもインスタンスの状態がすべてリセットされていまいます。
- 【12時間ルール】新しいインスタンスを起動してから12時間経過
- 【90分ルール】ノートブックのセッションが切れてから90分経過
の制限があり、ブラウザ拡張を使って自動リロードして再接続することで90分ルールを回避します。
セッション切れ回避の自動リロードの問題
jupyter上でmodel.fit()などしている際に標準出力が発生すると、
進捗のログ
Epoch 1/3
90/90 [==============================] - 1s 7ms/step - loss: 1.1098 - acc: 0.3111
Epoch 2/3
90/90 [==============================] - 0s 98us/step - loss: 1.0822 - acc: 0.4444
Epoch 3/3
90/90 [==============================] - 0s 60us/step - loss: 1.0699 - acc: 0.5556
リロード時にダイアログが発生します。
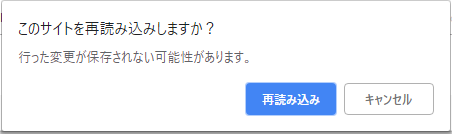
なのでmodel.fit(verbose=0)として、訓練進捗などの出力をOFFにしないといけません。
警告が発生してログが出てしまう場合
model.fit()時に警告がでる場合がある。
UserWarning: Converting sparse IndexedSlices to a dense Tensor of unknown shape.
この場合はプログラム冒頭に以下を追加して、警告無視をします。
import warnings
warnings.filterwarnings('ignore')
進捗どうですか?
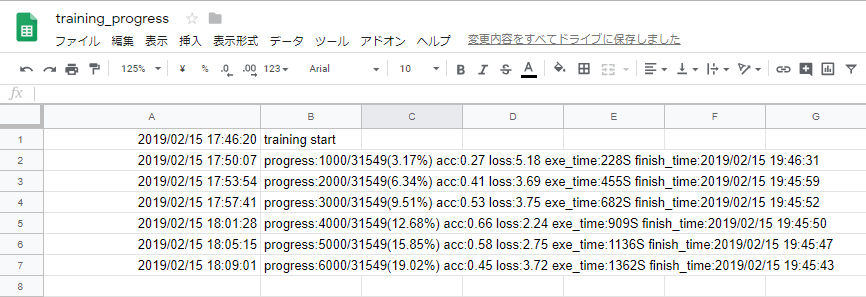
進捗が確認できないのは辛いので、今回はGoogleスプレッドシートにログ出力することにしました。
まずはこの手順でPythonからスプレッドシートへ接続できるようにします。
あとは自作Callbackでスプレッドシートにログ出力します。
callback.py
!pip install --upgrade -q gspread
!pip install --upgrade -q oauth2client
from tensorflow.python.keras.callbacks import Callback
import time
import datetime
import math
import gspread
from gspread.exceptions import APIError
from oauth2client.service_account import ServiceAccountCredentials
google_api_scope = [
'https://spreadsheets.google.com/feeds',
'https://www.googleapis.com/auth/drive'
]
class MyCallback(Callback) :
def __init__(self) :
self.start_time = None
self.credentials = ServiceAccountCredentials.from_json_keyfile_name("<サービスアカウント>.json", google_api_scope)
self.rowNum = 1
self._open()
def _jp_datetime(self) :
# colab上では標準時なので+900した日時を取得する
return datetime.datetime.now() + datetime.timedelta(hours=9)
def _open(self):
self.gc = gspread.authorize(self.credentials)
self.wb = self.gc.open_by_url("<シートのURL>")
self.ws = self.wb.get_worksheet(0)
def _clear(self, retry_count = 0):
# 1時間ごとにgoogleAPIのセッションが切れるのでAPIErrorが発生したらリトライ
try :
self.ws.clear()
except APIError as e:
if retry_count > 10:
raise
self._open()
self._clear(retry_count + 1)
def _write(self, text, retry_count = 0):
# 1時間ごとにgoogleAPIのセッションが切れるのでAPIErrorが発生したらリトライ
try :
self.ws.update_acell('A%d' % self.rowNum, self._jp_datetime().strftime("%Y/%m/%d %H:%M:%S"))
self.ws.update_acell('B%d' % self.rowNum, text)
self.rowNum += 1
except APIError as e:
if retry_count > 10:
raise
self._open()
self._write(text, retry_count + 1)
def on_train_begin(self, logs=None):
self.start_time = time.time()
self.training_count = self.params['steps']
self._clear()
self._write("training start")
def on_test_begin(self, logs=None):
self.start_time = time.time()
self.training_count = self.params['validation_steps']
self._write("test start")
def on_batch_end(self, batch, logs = None) :
# batchは0開始なので、人間感覚に合わせるために+1しておく
# 後続処理で0除算を回避する意味でも都合がいい
batch += 1
# 今回は1000回に1度ログ出力
if batch % 1000 != 0:
return
# 今までにかかった秒数
exec_time = time.time() - self.start_time
# 予想完了秒数
# 最後に" - exec_time"しているのは、既にこれまでの訓練で経過した秒数は不要で、
# これからかかる秒数だけを現在時に加算しないと、予想完了秒数にはならない
finish_time = math.floor((self.training_count / batch) * exec_time - exec_time)
# 予想完了日時
finish_date = self._jp_datetime() + datetime.timedelta(seconds=finish_time)
finish_date = finish_date.strftime("%Y/%m/%d %H:%M:%S")
progress_rate = batch / self.training_count * 100
log_text = "progress:%d/%d(%.2f%%) acc:%.2f loss:%.2f exe_time:%dS finish_time:%s" % ( batch, self.training_count, progress_rate, logs['acc'], logs['loss'], exec_time, finish_date)
self._write(log_text)
これで進捗ログが出力できるようになりました。