著者: 株式会社 日立ソリューションズ 柳村 明宏
監修: 株式会社 日立製作所
はじめに
計画最適化とは、限られたリソースの中で、守るべき制約や効率を考慮しながら、最も良い計画(組合せ計画)を立案することです。
ここで、対象となる計画の規模(例:人員のシフト計画の場合、対象となる人員数や割り当てるシフト枠数)が増加すると、その組合せ数も増加し、良い計画を立案できるまでの時間も増加します。
そのため、計画最適化を行う場合は、以下の内容を検討する必要があります。
- どれくらいの規模の最適化を行うのか
- どれくらいの計算時間をかけられるのか
- どれくらいのマシンスペックが必要か
本稿では、人員の日次シフト計画のモデルケースについてRed Hat Decision Managerを利⽤して計画を最適化する性能検証を紹介します。
本稿が以下のような点でお役に立てれば幸いです。
- 計画最適化が、規模の大きいケースでも現実的な計算時間で対応できることを確認する
- 計算時間やマシンスペックの概算見積時の参考値として利用する
- 設計開発時に調整する最適化アルゴリズムやパラメタのベース値として参照する
なお、Red Hat Decision Managerを利⽤した計画最適化の概要や活用イメージについては、以下の記事を参考にしてください。
結果の理由が分かるAIで計画最適化
結果の理由が分かるAIで計画最適化「活用イメージ」
モデルケース
計画の概要
1つの勤務エリアで複数の業務が存在する人員の日次のシフト計画を立案します。具体的には、各シフト枠に対して業務を遂行する人員を、制約や効率を考慮しながら割り当てます。
シフトデータ(⼈員割当後のシフト枠)の作成イメージを以下に示します。
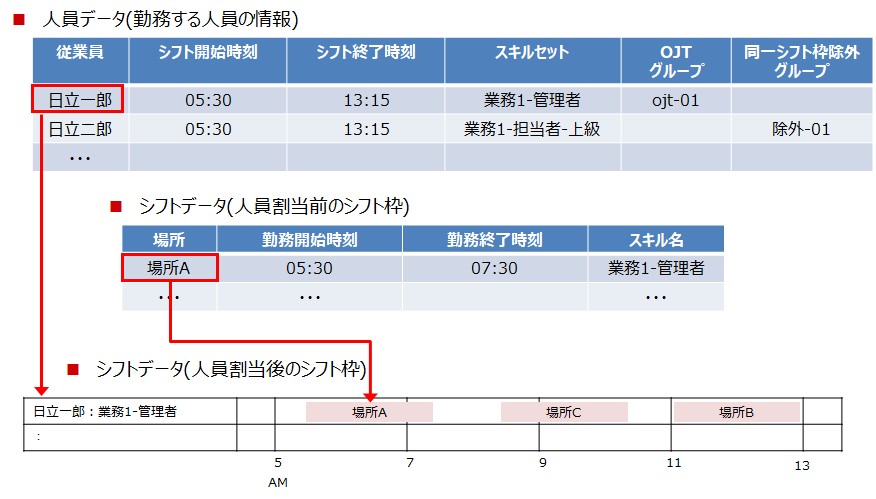
今回のモデルケースでは以下の3パターンの人員数とシフト枠数があるものとします。
| # | 人員数 | シフト枠数 |
|---|---|---|
| 1 | 1000 | 4212 |
| 2 | 500 | 2106 |
| 3 | 250 | 1053 |
制約ルール
本モデルケースでは以下の制約ルールを設定しています。
| # | 制約ルール | 制約種別 | 制約種別説明 | レベル |
|---|---|---|---|---|
| 1 | シフト枠に必ず人員を割り当てる。 | 絶対制約 | 必ず遵守する制約ルール。 | Hard |
| 2 | 同じ人員を、同じ勤務時間帯の複数のシフト枠に割り当てない。 | |||
| 3 | 各人員の勤務時間帯を遵守する(早出、残業をさせない)。 | 考慮制約 | 可能な限り遵守する制約ルール。 ただし、他の制約ルール、評価指標との兼ね合いで遵守しないケースもある。 |
Soft |
| 4 | 業務に必要なスキルを持つ人員を割り当てる。 | |||
| 5 | スキルレベルが低い人員をスキルレベルの高いシフトに割り当てない。 | |||
| 6 | OJTグループが同じ人員(指導係と新人)は、同じ勤務時間帯+同じ勤務場所とする。 | |||
| 7 | 同一シフト枠除外グループが同じ人員(相性が合わない人など)は、同じ勤務時間帯+同じ勤務場所にしない。 | |||
| 8 | 勤務エリアの移動回数を少なくする。 | 評価指標 | より良い組合せを算出するための制約ルール。 | |
| 9 | 人員の作業時間を平準化する。 |
モデルケースの規模(探索空間のサイズ)と目標スコア
スコアは最適化計算を評価する指標値です。
本モデルケースでは、すべての制約ルールでスコアにペナルティ値(負の値)を付与するため、0(0hard/0soft)が最良のスコアとなります。しかし、限られたリソース(人員数、シフト枠数)や、計画にかけられる時間などの制限がある中で、どこまで最適化できれば良しとするかを目標スコアとして設定します。
本モデルケースで設定する規模(探索空間のサイズ)に対する目標スコアは以下の通りです。
| # | 規模(探索空間のサイズ) | 目標スコア | |
|---|---|---|---|
| 人員数 | シフト枠数 | ||
| 1 | 1000 | 4212 | 0hard/-69000soft |
| 2 | 500 | 2106 | 0hard/-34500soft |
| 3 | 250 | 1053 | 0hard/-17250soft |
目標スコアの考え方は以下の通りです。
| 制約種別 | 目標スコア | 目標スコアの計算式 |
|---|---|---|
| 絶対制約 | 0 | ― |
| 考慮制約 | 0 | ― |
| 評価指標 |
本モデルケースでは、以下の目標で最小化します。
|
|
| 合計 0hard/-(69 × 人員数)soft | ||
探索空間のサイズ
探索空間のサイズは、計画に対して考えられる組合せ数であり、探索空間のサイズが大きいほど計算時間がかかります。
本モデルケースにおける探索空間のサイズは、「人員数」の「シフト枠数」乗となります。
| # | 人員数 | シフト枠数 | 探索空間のサイズ |
|---|---|---|---|
| 1 | 250 | 1053 | 2501053 ≧ 102525 |
| 2 | 500 | 2106 | 5002106 ≧ 105684 |
| 3 | 1000 | 4212 | 10004212 ≧ 1012636 |
Red Hat Decision Managerの探索空間のサイズの仕様は、OptaPlanner User Guide の Search space size に記載されていますので、参考にしてください。
本稿の検証結果を参考値として利用する場合は、この探索空間のサイズを十分に考慮してください。
検証環境
本検証では以下のような検証環境を利用して検証を実施しました。
マシン環境
| 項目 | 値 |
|---|---|
| OS名 | Microsoft Windows10 Pro |
| プロセッサ | Intel® Core™ i7-6700 CPU @ 3.40GHz、3408 Mhz、4個のコア、8個のロジカルプロセッサ |
| 物理メモリ | 16GB |
| ソフトウェア名称 | バージョン |
|---|---|
| Red Hat Decision Manager | 7.6.0 |
| OpenJDK | 1.8.0 |
設定情報
| 項目 | 値 |
|---|---|
| Javaの初期ヒープ・サイズ | 4096 MB |
| Javaの最大ヒープ・サイズ | 4096 MB |
| 利用スレッド数 | 6 |
Multithreaded incremental solvingの詳細な仕様は、OptaPlanner User Guide の Multithreaded incremental solvingを参照してください。
検証方法
最適化アルゴリズムとチューニングパラメタ
Red Hat Decision Managerは、様々な最適化アルゴリズムをサポートしています。
目標スコアに到達するまでに必要な計算時間は、選択した最適化アルゴリズムとそのアルゴリズムのチューニングパラメタの指定値によって変わります。
本検証では、よく利用される以下の3つの最適化アルゴルズムを利用して検証を行います。
- Tabu Search
- Late Acceptance
- Simulated Annealing
アルゴリズムの詳細な仕様や、Red Hat Decision Managerで利用できる他のアリゴリズムに関して知りたい方は、OptaPlanner User Guideを参照してください。
また、Red Hat Decision Managerには、アルゴリズム、パラメタの最適化計算結果をレポートで出力する機能として、ベンチマーク機能があります。ベンチマーク機能を利用し、各アルゴリズム、パラメタの構成を比較することで、パラメタチューニングを効率よく推進することができます。
ベンチマーク機能の詳細な仕様は、OptaPlanner User Guide の Benchmarking and Tweakingを参照してください。
最適化計算の終了条件
本検証では、最適化計算の終了条件として、以下の2つのどちらかを満たした場合に終了する設定としています。
- 規定時間到達
- ベストスコアが5分間未更新
「目標スコアに到達」という終了条件も設定できますが、どの程度までスコアが上昇するかも確認したかったため、上記の終了条件としています。実際のシステムでも、目標スコアに到達したらすぐ計算終了させることよりも、許容される時間内でより良い結果を得られるように、上記のような終了条件を設定することも多いと思います。
評価ポイント
本検証では以下の結果をまとめています。
- 目標スコアに到達した時間
- 30分経過後のベストスコア
- 60分経過後のベストスコア(250名規模は30分までしか検証しなかったため、500名規模、1000名規模のみ記載。)
250名規模のような小規模の最適化計算では、可能な限り速く目標スコアに到達することを一番の評価ポイントと考え、1 で評価(順位付け)します。
500名、1000名規模のような大規模の最適化計算では、目標スコアに到達する時間も重要な評価ポイントですが、限られた時間で最適な解を導くことを最も重要な評価ポイントと考え、2 で評価(順位付け)します。
検証結果
検証したパターンが非常に多いため、上位の検証結果を抜粋して紹介します。
「30分/60分経過後のベストスコア」列の下段の括弧内の数値は、終了条件「ベストスコアが5分間未更新」を満たし、最適化計算が終了した際の時間(秒)を表します。「目標スコアに到達した時間[秒]」列の太字になっている箇所は、各検証パターンで最速で目標スコアに到達した時間です。
1000名(目標スコア : 0hard/-69000soft)
Tabu Search
| 順位 | パラメタ | 目標スコアに 到達した時間[秒] |
30分経過後の ベストスコア |
60分経過後の ベストスコア |
|
|---|---|---|---|---|---|
| entityTabuSize | acceptedCountLimit | ||||
| 1 | 9 | 4000 | 602 | 0hard/-55780soft | 0hard/-53928soft (3559[秒]) |
| 2 | 9 | 2000 | 687 | 0hard/-57125soft | 0hard/-56419soft (2545[秒]) |
| 3 | 5 | 4000 | 668 | 0hard/-57476soft | 0hard/-55623soft |
| 4 | 7 | 2000 | 1154 | 0hard/-57586soft | 0hard/-57208soft (2317[秒]) |
Late Acceptance
| 順位 | パラメタ | 目標スコアに 到達した時間[秒] |
30分経過後の ベストスコア |
60分経過後の ベストスコア |
|
|---|---|---|---|---|---|
| lateAcceptanceSize | acceptedCountLimit | ||||
| 1 | 3 | 1 | 731 | 0hard/-51909soft | 0hard/-50175soft |
| 2 | 1 | 1 | 306 | 0hard/-53840soft | 0hard/-52862soft |
| 3 | 5 | 1 | 1239 | 0hard/-54752soft | 0hard/-51532soft |
| 4 | 1 | 4 | 1270 | 0hard/-55282soft | 0hard/-53976soft |
Simulated Annealing
| 順位 | パラメタ | 目標スコアに 到達した時間[秒] |
30分経過後の ベストスコア |
60分経過後の ベストスコア |
|
|---|---|---|---|---|---|
| simulatedAnnealing StartingTemperature |
acceptedCountLimit | ||||
| 1 | 0hard/10soft | 4 | 348 | 0hard/-53457soft | 0hard/-52426soft |
| 2 | 0hard/5soft | 4 | 1113 | 0hard/-55198soft | 0hard/-53803soft |
| 3 | 0hard/50soft | 4 | 477 | 0hard/-55700soft | 0hard/-52170soft |
| 4 | 0hard/100soft | 4 | 1210 | 0hard/-58192soft | 0hard/-51499soft |
1000名規模のデータでは、最速306秒で目標スコアに到達しました。
また、目標スコア到達後も最適化計算を行うことで、ベストスコアが更新されました。
以下は、前述の表でのアルゴリズムごとのNo1のSoftスコア遷移です。
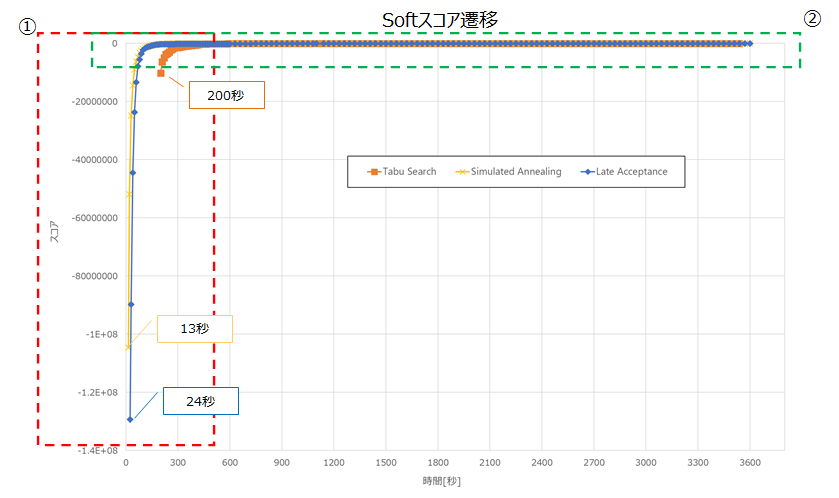
各アルゴリズムの始点はHardスコアが0hardとなった地点です。
①の吹き出しのとおり、Simulated Annealingが最も速く0hardに収束しました。
以下に②を拡大した図を記載します。
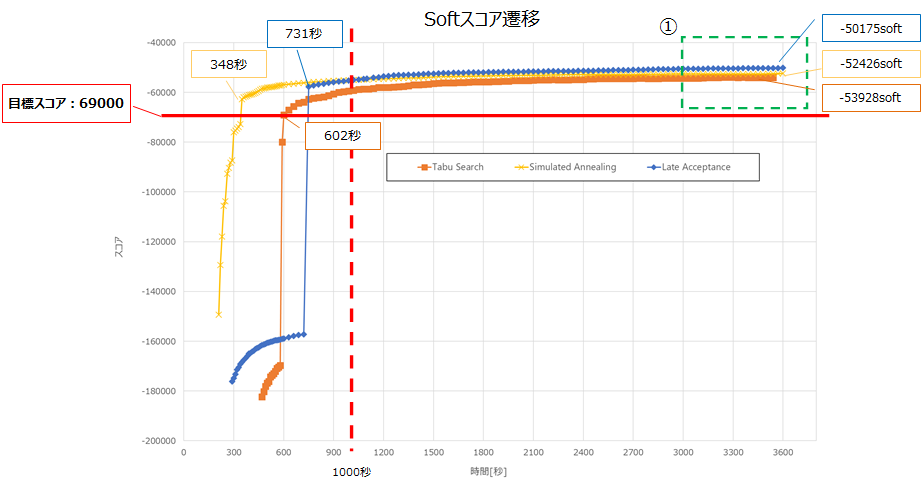
目標スコアへの到達が最も速いアルゴリズムは、Simulated Annealingでした。
1000秒程度までは、Simulated Annealingが最も良いスコアですが、以降はLate Acceptanceが最も良いスコアとなりました。
①の3000秒から最適化計算終了までのスコア上昇に関しては、各アルゴリズムで数100程度となっており、これ以上最適化計算を行っても大幅なスコア改善は見込まれないと想定します。
500名(目標スコア : 0hard/-34500soft)
Tabu Search
| 順位 | パラメタ | 目標スコアに 到達した時間[秒] |
30分経過後の ベストスコア |
60分経過後の ベストスコア |
|
|---|---|---|---|---|---|
| entityTabuSize | acceptedCountLimit | ||||
| 1 | 7 | 2000 | 436 | 0hard/-27506soft | 0hard/-27506soft (2027[秒]) |
| 2 | 5 | 4000 | 263 | 0hard/-28082soft | 0hard/-27701soft (2584[秒]) |
| 3 | 7 | 4000 | 464 | 0hard/-28222soft | 0hard/-27649soft (3237[秒]) |
| 4 | 9 | 2000 | 170 | 0hard/-28585soft (1129[秒]) |
― |
Late Acceptance
| 順位 | パラメタ | 目標スコアに 到達した時間[秒] |
30分経過後の ベストスコア |
60分経過後の ベストスコア |
|
|---|---|---|---|---|---|
| lateAcceptanceSize | acceptedCountLimit | ||||
| 1 | 5 | 1 | 188 | 0hard/-24991soft | 0hard/-24621soft |
| 2 | 3 | 1 | 153 | 0hard/-25755soft | 0hard/-25625soft (2712[秒]) |
| 3 | 100 | 4 | 517 | 0hard/-25983soft | 0hard/-25213soft |
| 4 | 50 | 4 | 284 | 0hard/-26562soft | 0hard/-26196soft |
Simulated Annealing
| 順位 | パラメタ | 目標スコアに 到達した時間[秒] |
30分経過後の ベストスコア |
60分経過後の ベストスコア |
|
|---|---|---|---|---|---|
| simulatedAnnealing StartingTemperature |
acceptedCountLimit | ||||
| 1 | 0hard/5soft | 4 | 244 | 0hard/-26071soft | 0hard/-25384soft |
| 2 | 0hard/10soft | 4 | 685 | 0hard/-26438soft | 0hard/-25791soft |
| 3 | 0hard/5soft | 1 | 468 | 0hard/-27423soft | 0hard/-26365soft |
| 4 | 0hard/50soft | 4 | 151 | 0hard/-27932soft | 0hard/-26146soft |
以下は、前述の表でのアルゴリズムごとのNo1のSoftスコア遷移です。
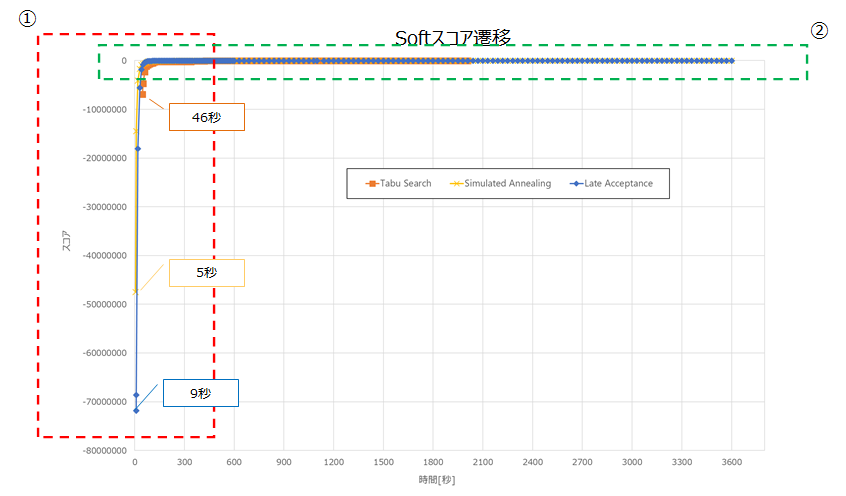
各アルゴリズムの始点はHardスコアが0hardとなった地点です。
①の吹き出しのとおり、Simulated Annealingが最も速く0hardに収束しました。
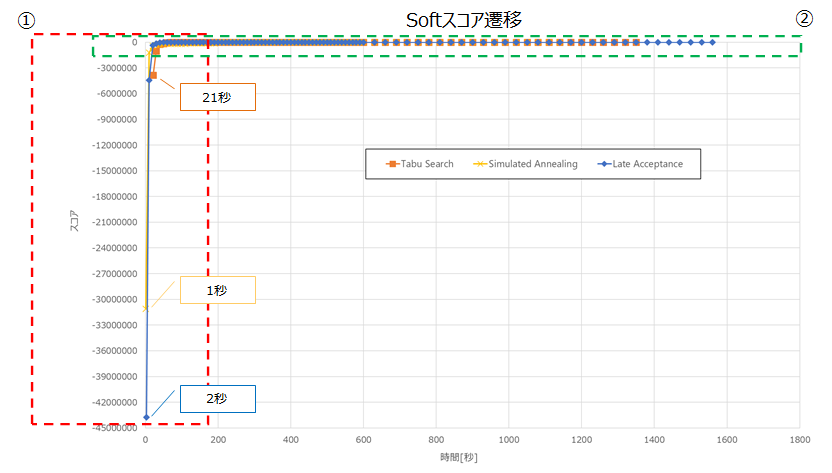
以下に②を拡大した図を記載します。
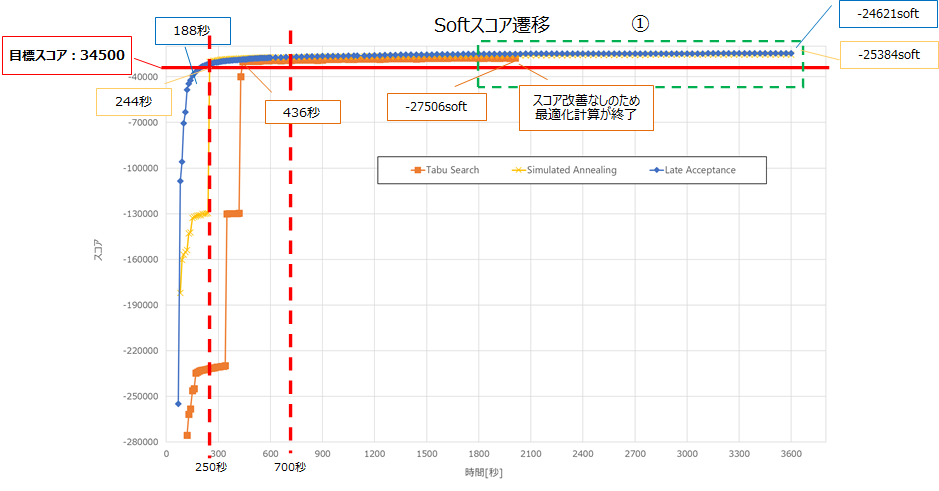
目標スコアへの到達が最も速いアルゴリズムは、Late Acceptanceでした。
250秒から700秒程度までは、Simulated Annealingが最も良いスコアですが、以降はLate Acceptanceが最も良いスコアとなりました。
①の1800秒から最適化計算終了までのスコア上昇に関しては、各アルゴリズムで数100程度となっており、これ以上最適化計算を行っても大幅なスコア改善は見込まれないと想定します。また、Tabu Searchに関しては、2000秒程度でスコアの改善が見られず最適化計算が終了しています。
250名(目標スコア : 0hard/-17250soft)
Tabu Search
| 順位 | パラメタ | 目標スコアに 到達した時間[秒] |
30分経過後の ベストスコア |
60分経過後の ベストスコア |
|
|---|---|---|---|---|---|
| entityTabuSize | acceptedCountLimit | ||||
| 1 | 11 | 2000 | 167 | 0hard/-15400soft (1378[秒]) |
ー |
| 2 | 9 | 2000 | 224 | 0hard/-15265soft (1722[秒]) |
ー |
| 3 | 5 | 1000 | 244 | 0hard/-16190soft (686[秒]) |
ー |
| 4 | 7 | 4000 | 262 | 0hard/-15850soft | ― |
Late Acceptance
| 順位 | パラメタ | 目標スコアに 到達した時間[秒] |
30分経過後の ベストスコア |
60分経過後の ベストスコア |
|
|---|---|---|---|---|---|
| lateAcceptanceSize | acceptedCountLimit | ||||
| 1 | 5 | 1 | 98 | 0hard/-14755soft (1775[秒]) |
ー |
| 2 | 20 | 1 | 182 | 0hard/-14681soft | ー |
| 3 | 10 | 1 | 216 | 0hard/-14534soft (1739[秒]) |
ー |
| 4 | 10 | 4 | 248 | 0hard/-15118soft (1499[秒]) |
ー |
| 順位 | パラメタ | 目標スコアに 到達した時間[秒] |
30分経過後の ベストスコア |
60分経過後の ベストスコア |
|
|---|---|---|---|---|---|
| simulatedAnnealing StartingTemperature |
acceptedCountLimit | ||||
| 1 | 0hard/5soft | 4 | 193 | 0hard/-15151soft (1159[秒]) |
ー |
| 2 | 0hard/100soft | 4 | 325 | 0hard/-14977soft | ー |
| 3 | 0hard/50soft | 1 | 1215 | 0hard/-14584soft | ー |
| 4 | 0hard/500soft | 4 | 1355 | 0hard/-15122soft | ー |
250名規模のデータでは、最速98秒で目標スコアに到達しました。
また、目標スコア到達後も最適化計算を行うことで、ベストスコアが更新されました。
以下は、前述の表でのアルゴリズムごとのNo1のSoftスコア遷移です。
各アルゴリズムの始点はHardスコアが0hardとなった地点です。
①の吹き出しのとおり、Simulated Annealingが最も速く0hardに収束しました。
以下に②を拡大した図を記載します。
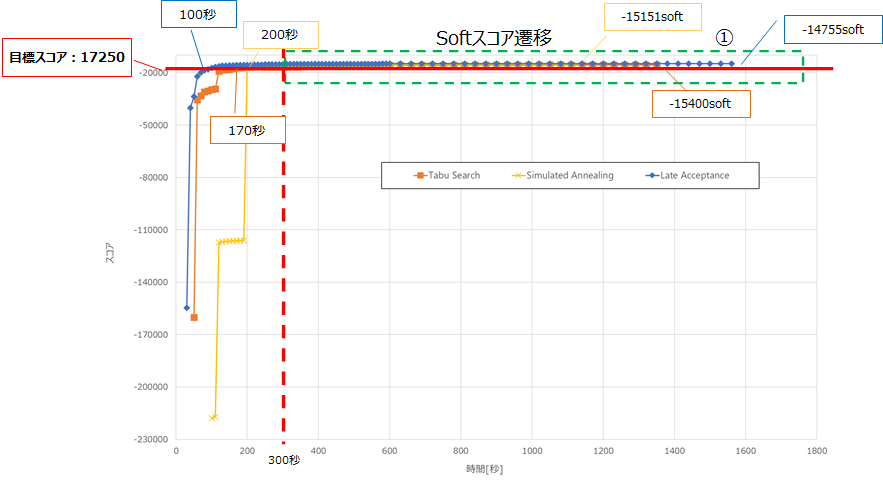
目標スコアへの到達が最も速いアルゴリズムは、Late Acceptanceでした。
開始から終了までLate Acceptanceが最も良いスコアとなりました。
①の300秒から最適化計算終了までのスコア上昇に関しては、各アルゴリズムで数100程度となっており、これ以上最適化計算を行っても大幅なスコア改善は見込まれないと想定します。
考察
今回の検証では、Red Hat Decision Managerで1000名規模の計画最適化を現実的な時間の範囲内で実現できることが確認できました。ここでは、検証から見えてきた内容を考察します。
各アルゴリズムの計算時間とスコアの特性
本検証のモデルケース、規模(探索空間のサイズ)および制約ルールの重み値では、各アルゴリズムの計算時間のスコアの特性(傾向)は見られませんでした。
各アルゴリズムのチューニングのしやすさ
| # | 最適化アルゴリズム | 検証から見られる特性 | 検証結果からの考察 |
|---|---|---|---|
| 1 | Tabu Search | チューニングパラメタの値の範囲が広い。 | 多くのパラメタを検証してチューニングすれば、最高スコアを出せる可能性は高いと想定します。 ただし、入力データは毎回同じではないため、汎用的な調整は難しいと想定します。 |
| 2 | Late Acceptance | チューニングパラメタの値の範囲が比較的狭い。 | パラメタの変更に伴うスコアの改善・悪化の傾向が見えやすく、本検証で利用した3つのアルゴリズムの中では、最も調整しやすいと想定します。 |
| 3 | Simulated Annealing | 本検証の検証結果では、チューニングパラメタの値の範囲が比較的狭い。 ただし、チューニングパラメタ「simulatedAnnealingStartingTemperature」で「受け入れを許可するスコア値の初期値」を指定するため、制約ルールの重み値に依存する。 |
規模(探索空間のサイズ)だけでなく、制約ルールの重み値も考慮して調整する必要があり、Late Acceptanceより調整が難しいと想定します。 |
チューニングパラメタの調整方法
| # | 最適化 アルゴリズム |
チューニングパラメタ | 指定範囲 |
|---|---|---|---|
| 1 | Tabu Search | entityTabuSize | 5~12 |
| 2 | acceptedCountLimit | 1000~4000 | |
| 3 | Late Acceptance | lateAcceptanceSize | 1~600 |
| 4 | acceptedCountLimit | 1 または 4 | |
| 5 | Simulated Annealing | simulatedAnnealingStartingTemperature | (制約ルールの重み値に依存。) |
| 6 | acceptedCountLimit | 1 または 4 |
指定値が大きい場合は、評価対象の組合せ数が多くなり、問題を解く時間が長くなりますが、最高スコアが高くなります。
指定値が小さい場合は、評価対象の組合せ数が少なくなり、問題を解く時間が短くなりますが、最高スコアが低くなります。 **#1 :** 傾向は明確ではありませんが、7,9が比較的よく、規模(探索空間のサイズ)が小さい場合は、値を大きくすると良いと想定します。 **#2,#4,#6 :** 傾向が不明なパラメタのため、実測することを推奨します。
Tabu Size の entityTabuSize の指定範囲は5~11の範囲で検証しましたが、以下のサイトに「5~12の値が良い」と記載がありました。
https://ja.wikipedia.org/wiki/%E3%82%BF%E3%83%96%E3%83%BC%E3%82%B5%E3%83%BC%E3%83%81
どのアルゴリズムでもチューニングパラメタを変更することで結果が大きく変わりますが、調整次第で良い結果を得られることがわかりました。
各アルゴリズムのチューニングパラメタの調整方法を紹介しましたが、Late Acceptance が他のアルゴリズムと比較して調整しやすいと感じました。そのため、実測する時間が十分に確保できない場合は、Late Acceptance から調整してみるのも良いと想定します。
規模(探索空間のサイズ)ごとに基礎値として利用できそうなパラメタ
本検証では、各規模で約60パターンの検証を行いました。
同様のモデルケース、規模(探索空間のサイズ)および制約ルールの重み値で最適化計算を行う場合は、以下の最適化アルゴリズム・パラメタの組合せの範囲から、パラメタのチューニングを行うことで、効率よくチューニングを行うことできると想定します。
| 規模 (探索空間のサイズ) |
最適化アルゴリズム | パラメタ | |
|---|---|---|---|
| 人員数 | シフト 枠数 |
||
| 1000 | 4212 | Tabu Search | entityTabuSize : 7~9 acceptedCountLimit : 1000~4000 |
| Late Acceptance | lateAcceptanceSize : 1~10 acceptedCountLimit : 1 |
||
| Simulated Annealing | simulatedAnnealingStartingTemperature : 0hard/5soft~0hard/100soft acceptedCountLimit : 4 |
||
| 500 | 2106 | Tabu Search | entityTabuSize : 5~9 acceptedCountLimit : 1000~4000 |
| Late Acceptance | lateAcceptanceSize : 3~10 acceptedCountLimit : 1 |
||
| lateAcceptanceSize : 30~100 acceptedCountLimit : 4 |
|||
| Simulated Annealing | simulatedAnnealingStartingTemperature : 0hard/5soft~0hard/100soft acceptedCountLimit : 4 |
||
| 250 | 1053 | Tabu Search | entityTabuSize : 11 acceptedCountLimit : 1000~4000 |
| Late Acceptance | lateAcceptanceSize : 5~20 acceptedCountLimit : 1 |
||
| Simulated Annealing | simulatedAnnealingStartingTemperature : 0hard/5soft acceptedCountLimit : 4 |
||
おわりに
本稿では、250名、500名、1000名規模の計画最適化における性能検証結果を紹介しました。
紹介したチューニングパラメタの調整方法や、基礎値として利用できそうなパラメタを参考にすることで、Red Hat Decision Managerがより使いやすくなると思いますので、是非お試しください。