概要
Pepperをアイドルオタク化して、アイドルグループ・・・・・・・・・のライブ「Tokyo in Sightseeing」に観客として参加させてみました。
Pepperは「いま、どの曲を演奏しているか」を聞き分け、その曲にあった振る舞いをします。
実際の動画はこちら
https://www.youtube.com/watch?v=DhuoG1qYE2k
ソースコード
a-r-i/OtakuPepper - GitHub

ゴールデンウィークにおこなわれた、・・・・・・・・・の第11回定期公演 Tokyo in Sightseeing
やりたかったこと
Pepperのコンセプトは「人間との共生」です。
Pepperが人間と共生している社会では、彼らは人を楽しませるだけではなく、人がすることを見て楽しんでいるはず。
しかし、ステージで演者としてパフォーマンスをしたり、お店で店員として働くPepperはいても、コンテンツやサービスの受け手として振る舞うPepperは少ないように感じました。
そこで、アイドルのライブをオタクとして楽しむPepperをつくってみました。
Pepperは、人間と共生するよう開発された初のロボットです。
Pepper "Let the future begin." | SoftBank Robotics
.
生産性を高めたり、労働効率の向上のために作られたロボットではありません。
ソフトバンクが制作したPepperのホームページにはこんなコピーが載っていました。
空中飛行もできません。ロケットパンチも出せません。ただ、あなたともっと仲よくなりたいなあ、なんて考えている、人間みたいなロボットです
実行環境
macOS Sierra 10.12.6
Python 2.7.10
Pepper SDK pynaoqi-python2.7-2.5.5.5-mac64
流れ
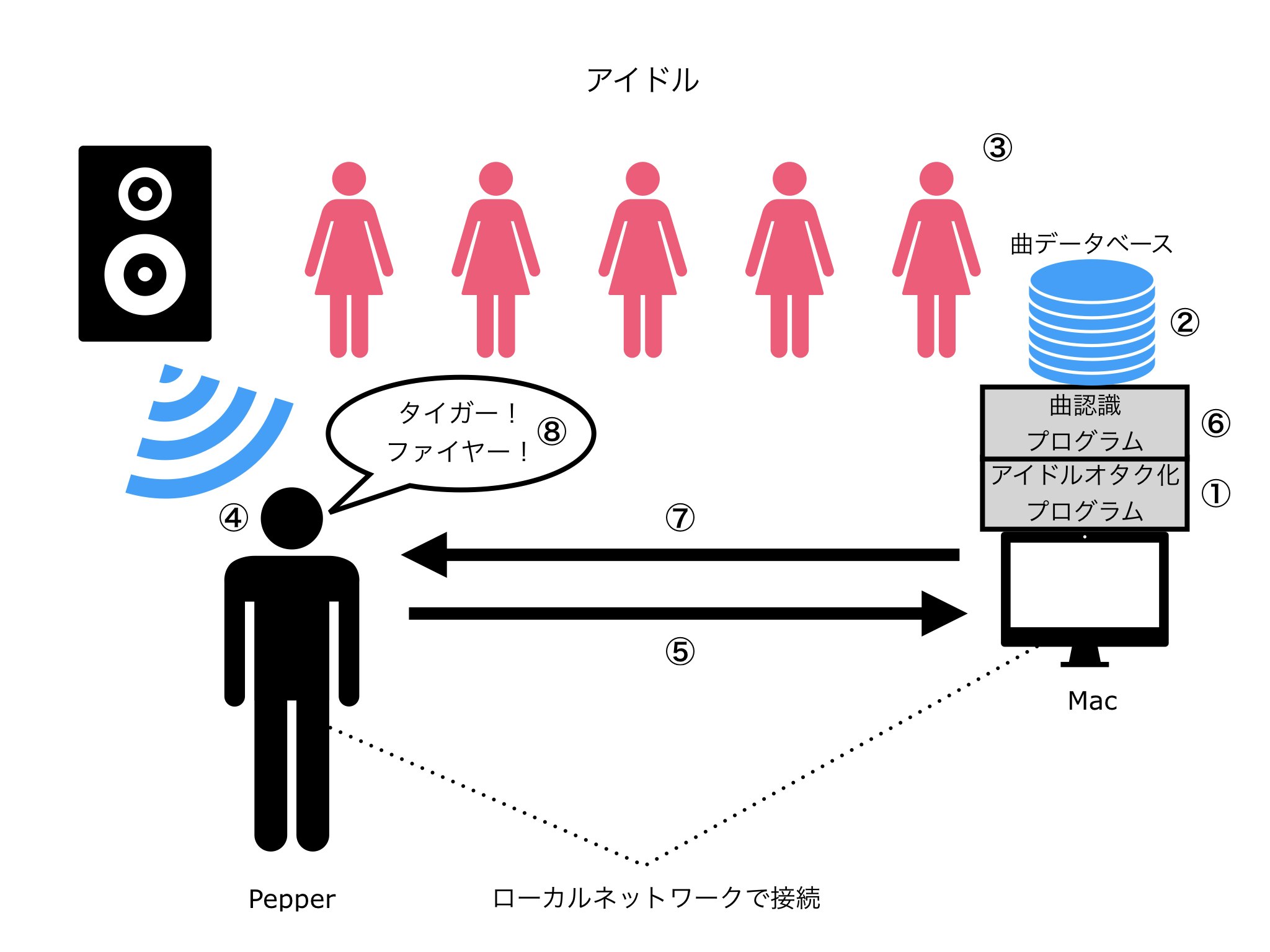
- アイドルオタク化プログラムをつくる
- 楽曲をデータベースに登録
- ライブ開始
- Pepperが周囲の音を録音
- 録音データをMacに送信
- 録音データをデータベースと照合
- データベースに録音データに一致する楽曲があれば、アイドルオタク化プログラムを実行
- アイドルオタク化したPepperが、MIXやコール、口上をする
①アイドルオタク化プログラムをつくる
アイドルオタク化とは?
まずは、・・・・・・・・・の「サテライト」という曲のライブ動画をご覧ください。

MIX、コール、口上
曲中、オタクが何か叫んでいるのが分かると思います。その内容は、大きく3種類に分けられます。
MIXとは,アイドルライブにおいて曲の前奏や間奏などで叫ぶ特定の掛け声のことです.
コールとは,アイドルライブにおいて曲中の要所要所で合いの手のように入れたり,わざと歌詞に被せて叫んだりすることです.
口上(こうじょう)とは,アイドルライブにおいて歌詞のない間奏などで,気持ちの高まったファンが特定の文章を叫ぶことです.
本来の歌唱部分を,全員で歌詞の通りに合唱する場合は含みません.
よく使われる口上は,所謂「ガチ恋口上」と呼ばれるものです.
オタクは、アイドルを応援する目的で、あるいは、気分や場の空気をもり立てるために、はたまた、高まる気持ちを抑えきれずに、MIX、コール、口上を叫びます。
MIX、コール、口上は、アイドルオタクの文化として根付いています。
そこで、Pepperをアイドルオタク化させる初手として、アイドルグループ・・・・・・・・・のライブでMIX、コール、口上をさせることにしました。
「サテライト」のMIX、コール、口上をプログラムに落とし込む
まず、・・・・・・・・・のライブ動画を参考に、「サテライト」のMIX、コール、口上タイムラインをつくります。
| 時間 | 振る舞い |
|---|---|
| 0:22 - 0:29 | うっ!おい!×6 |
| 0:31 - 0:32 | しゃーいくぞ! |
| 0:33 - 0:43 | タイガ!ファイヤ!サイバ!ファイバ!ダイバー!バイバー!ジャージャー!ファイボ!ワイパ!ファーマ!ジャスパ!ホワイパー!クーパー!イエスクレイパー! |
| 1:43 - 1:51 | うっ!おい!×12 |
| 1:51 - 2:54 | イエッタイガファイボワイパア! |
| 2:12 - 2:15 | はいっせーの!はーいはい!はいはいはいはい! |
| 3:48 - 3:56 | うっ!おい!×12 |
| 3:56 - 3:58 | イエッタイガファイボワイパア! |
| 4:17 - 4:20 | はいっせーの!はーいはい!はいはいはいはい! |
| 4:43 - 5:03 | ガチ恋口上 |
| 5:03 - 5:06 | うっ!おい!×4 |
| 5:07 - 5:09 | しゃーいくぞ! |
| 5:10 - 5:14 | タイガ!ファイヤ!サイバ!ファイバ!ダイバー!バイバー!ジャーーージャーーー! |
| 5:15 - 5:19 | 虎!火!人造!繊維!海女!振動!化繊! |
| 5:20 - 5:30 | チャペ!アペ!カラ!キナ!ララ!トゥスケ!ウィスパー!ケスィ!スィスパーーーー! |
これを、プログラムに落とし込みます。
(Pepperの発話が追いつかないため、一部カット)
# -*- coding: utf-8 -*-
from naoqi import (ALProxy, ALBroker, ALModule)
PEPPER_IP = ""
PORT = 9559
phrases = {"oi": "おい!",
"mix": "タイガ!ファイヤ!サイバ!ファイバ!ダイバー!バイバー!ジャーーージャーーー!"
"ファイボ!ワイパ!ファーマ!ジャスパ!ホワイパー!クーパー!イエスクレイパーーー!",
"mix_short": "タイガ!ファイヤ!サイバ!ファイバ!ダイバー!バイバー!ジャーーージャーーー!",
"mix_veryshort": "イエッタイガファイボワイパア!",
"mix_japanese": "虎!火!人造!繊維!海女!振動!化繊!",
"ainu": "チャペ!アペ!カラ!キナ!ララ!トゥスケ!ウィスパー!ケスィ!スィスパーーーー!",
"haisseno": "はいっせーの!はーいはい!はいはいはいはい!",
"haihai": "はーいはい!はいはいはいはい!",
"gachikoikojo": "言いたいことがああるんだよお! やっぱり点ちゃんかわいいよお! すきすき大好きやっぱ好きい! やっとぉ見つけたお姫様あ!"
"俺がぁ生まれてきた理由! それはあ点ちゃんに出会うため! 俺とお一緒に人生歩もう、世界で一番愛してる! あいしてるーーーーー!!!"
}
try:
tts = ALProxy("ALTextToSpeech", PEPPER_IP, PORT)
except Exception,e:
print(e)
class Otaku():
def __init__(self):
print("")
def speech(self, title, speed_value):
tts.say("\\rspd=%s\\%s" % (speed_value,phrases[title]))
# -*- coding: utf-8 -*-
import time
import otaku
otaku = otaku.Otaku()
# 0:00
# time.sleep(22)
# 0:22
# for i in range(4):
# otaku.speech("oi", 100)
# 0:30 ここで曲認識すると仮定
otaku.speech("mix", 150)
time.sleep(59)
# 1:43
for i in range(8):
otaku.speech("oi", 100)
otaku.speech("mix_veryshort", 100)
time.sleep(16)
# 2:12
otaku.speech("haisseno", 100)
time.sleep(92)
# 3:48
for i in range(8):
otaku.speech("oi", 250)
otaku.speech("mix_veryshort", 100)
time.sleep(18)
# 4:17
otaku.speech("haisseno", 100)
time.sleep(22)
# 4:42
otaku.speech("gachikoikojo", 100)
for i in range(4):
otaku.speech("oi", 100)
otaku.speech("mix_short", 200)
otaku.speech("mix_japanese", 200)
otaku.speech("ainu", 100)
発話
Pepperを喋らせるには、ALTextToSpeech APIを使います。
文頭に\\rspd=speedvalue\\を挿入するととで、発話速度を変えられます。デフォルトは100、範囲は50-400です。
# -*- coding: utf-8 -*-
from naoqi import (ALProxy, ALBroker, ALModule)
PEPPER_IP = ""
PORT = 9559
try:
tts = ALProxy("ALTextToSpeech", PEPPER_IP, PORT)
except Exception,e:
print(e)
tts.say("\\rspd=100\\タイガ!ファイヤ!サイバ!ファイバ!ダイバー!バイバー!ジャーーージャーーー!")
このコードを実行すると、下の動画のようにPepperがMIXを打ちます。
MIXを打つペッパーくん
②楽曲をデータベースに登録
楽曲を聞き分け、「サテライト」のときだけプログラムを実行をするために、audfprintという曲認識ライブラリを使います。
dpwe/audfprint: Landmark-based audio fingerprinting
audfprintは、鼻歌認識アプリ「Shazam」で使われているLandmark-based fingerprintingという技術を実装したシステムです。
Shazamを起動し画面をタップすると、iPhoneは内蔵のマイクで周囲の音を聞き取り、波形データとして数値化します。いくつかの企業は世界中の曲を分析して波形データとして蓄えており、Shazamでは自社のデータベースにアクセスし、聞き取った曲の波形データと照合します。すべての曲は固有の波形データを持っていますから、一部でもパターンが一致する曲がある場合、流れている曲だと判定できます。
あのアプリ、どうして音楽を聞かせると曲名を当てられるの? - いまさら聞けないiPhoneのなぜ
Shazamの基本技術となるLandmark-based fingerprintingを実装したシステムはgithubで公開されてます。
Shazamのしくみをちょっと理解してみる
データベース新規作成
$ python audfprint.py new --dbase fpdbase.pklz ./sounds/satellite.mp3
既存のデータベースに楽曲を追加
$ python audfprint.py add --dbase fpdbase.pklz ./sounds/satellite.mp3
④Pepperが周囲の音を録音 ⑤録音データをMacに送信 ⑥録音データをデータベースと照合
Pepperのマイクから、30秒ごとに周囲の音を録音し、Macに送信。
録音データを、①でつくったデータベースに照合します。
録音時間が長ければ長いほど照合の精度が上がりますが、それだけ結果が出るのが遅くなります。
while True:
#録音開始
PepperModule.startRecord()
# 30秒録音
time.sleep(30)
#録音終了
check = PepperModule.stopRecord()
def stopRecord(self):
self.pepperMicrophone.unsubscribe(self.getName())
self.saveFile.close()
commands.getoutput("sox -r 16000 -b 16 -e signed-integer ./sounds/pepper_record.raw ./sounds/pepper_record.wav") #raw→wav変換
check = commands.getoutput("python audfprint.py match --dbase fpdbase.pklz ./sounds/pepper_record.wav") #録音データをデータベースに照合。
return check #実行結果を返す
曲が見つかった場合の実行結果
Sun Apr 22 13:32:37 2018 Reading hash table fpdbase.pklz
Read fprints for 3 files ( 22283 hashes) from fpdbase.pklz (0.00% dropped)
Sun Apr 22 13:32:40 2018 Analyzed #0 ./sounds/pepper_record.wav of 2.833 s to 299 hashes
[[ 0 14 578 19 0 0 0]]
./sounds/satellite.wav
Matched ./sounds/pepper_record.wav 2.8 sec 299 raw hashes as ./sounds/satellite.wav at 13.4 s with 14 of 19 common hashes at rank 0
Processed 1 files (2.9 s total dur) in 2.3 s sec = 0.805 x RT
曲が見つからなかった場合の実行結果
Sun Apr 22 13:32:23 2018 Reading hash table fpdbase.pklz
Read fprints for 3 files ( 22283 hashes) from fpdbase.pklz (0.00% dropped)
Sun Apr 22 13:32:25 2018 Analyzed #0 ./sounds/pepper_record.wav of 3.808 s to 41 hashes
NOMATCH ./sounds/pepper_record.wav 3.8 sec 41 raw hashes
Processed 1 files (5.0 s total dur) in 2.3 s sec = 0.462 x RT
⑦データベースに録音データに一致する楽曲があれば、アイドルオタク化プログラムを実行
曲が見つかった場合、実行結果には楽曲ファイルのパス(./sounds/satellite.wav)が含まれ、見つからなかった場合には含まれません。
なので、実行結果に楽曲ファイル名(satellite)が含まれていたら、曲が見つかったと判断し、オタク化プログラムを実行します。
#録音終了
check = PepperModule.stopRecord()
index = check.find("satellite") #実行結果にファイル名が含まれているか検索
if index != -1: #ファイル名が含まれている = 曲が見つかったら
commands.getoutput("/usr/bin/python satellite.py") #アイドルオタク化プログラムを実行
myBroker.shutdown()
sys.exit(0)
else:
print "not found"
やってみた結果
曲認識に失敗した
ライブが始まっても曲認識に成功しなかったので、手動でアイドルオタク化プログラムを実行しました。
おそらく学習教材として用いた「サテライト」のレコーディング音源が、ライブハウスで実際に聞こえた音と大きくズレていたからで、教材としてライブ音源をデータベースに追加することで、認識精度を上げられると思います。
タイミングがズレまくった
アイドルオタク化プログラムの実行が遅れたので、MIX、コール、ケチャのタイミングが大幅にズレました。
Pepperの音量が小さかった
Pepperの音量を最大にしても他の音(演奏音、人間のオタクのMIX、コール、口上)に負けてしまうため、マイクを使いました。
Pepperに話しかけるひとが多かった
ライブが始まるまで&終わったあとの待機時間に、Pepperに話しかけるひとが多かったです。
ライブ動画

当日のライブ動画です。
「きみにおちるよる」「サテライト」 - Tokyo in Sightseeing - YouTube
0:00- きみにおちるよる(手動でアイドルオタク化プログラムを実行)
4:14- サテライト(曲を認識してプログラムを自動実行……に失敗し、曲途中で手動実行)
ライブのレポートと写真
入場したら最前ドセンにペッパーくんが立ってた。
— コウイチ (@rbkouichi) 2018年5月4日
「ボクは撮可です」って喋ってる#dotstokyo pic.twitter.com/IfpSoqziLk
ペッパー君に最前管理されましたΣ(゚д゚lll) pic.twitter.com/pSxxmS8auk
— ももきちレコード (@emoemokichi) 2018年5月4日

最前ドセンでズレズレのMIX打ってくる強い心を持ったオタク、Pepperくん!#dotstokyo pic.twitter.com/H56KwIE7MB
— QQのQ🚫 (@popit1998) 2018年5月4日



ペッパーくんが、僕後方彼氏ヅラがしたいな。とか言い出しました… pic.twitter.com/bW8Xfui172
— みんさま (@minsama) 2018年5月4日
参考文献
Pepper
- Pepper "Let the future begin." | SoftBank Robotics
- 『Pepperの衝撃!パーソナルロボットが変える社会とビジネス』(神崎洋治, 日経BP社)
- 音声データをストリーミングで取得する。
リファレンス
audfprint
- あのアプリ、どうして音楽を聞かせると曲名を当てられるの? - いまさら聞けないiPhoneのなぜ
- Shazamのしくみをちょっと理解してみる
- dpwe/audfprint: Landmark-based audio fingerprinting