1.はじめに
業務で機械学習を使用することが決まり、約3ヶ月前から機械学習の勉強を始めました。
私自身理系大学出身であったため、数式も多少調べればわかるだろう程度に考えていました。
しかし、勉強すればするほど自分の考えが甘かったことに気づきました。
この記事では、当時私が実際にやってしまっていた思い込みへの忠告を書いていきます。
これから機械学習の勉強を始める方々の参考になれば幸いです。
2.4つの忠告
以下4つが機械学習初心者の頃の私へ送る忠告です。
・ディープラーニングだけじゃ機械学習は網羅できない
・学習モデルのことだけではなく、全体像を見る必要がある。
・データ前処理はすぐには終わらない。むしろ機械学習は前処理が8割。
・評価方法は正解率だけではない。
それぞれ詳細について書いていきます。
2-1.ディープラーニングだけじゃ機械学習は網羅できない
機械学習=ディープラーニングというイメージは
機械学習の勉強を始めた人にありがちだと思います。
私が最初に手に取った書籍もオライリーの「ゼロから作るDeep Learning ―Pythonで学ぶディープラーニングの理論と実装」でした。

この書籍を一通り勉強し、「これで機械学習いけるで!」と意気込んでいましたが、
蓋を開けてみると、機械学習はディープラーニングだけではありませんでした。
ディープラーニング以外にもSVMや決定木ベースのモデルなどなど複数の学習モデルが存在しています。
以下の記事を読んでいた際に気づきました。
https://qiita.com/tomomoto/items/b3fd1ec7f9b68ab6dfe2
2-2.学習モデルのことだけではなく、全体像を見る必要がある
ディープラーニング以外にも学習モデルが複数種類があることを知った私は、
どの学習モデルが最適なのかを知るために、各モデルについて調査し始めました。
しかし、調査を進めても機械学習全体像をうまくつかめていなかったため、
どのタイミングでなんの処理をする必要があるのか理解できませんでした。
機械学習の全体像は以下図の通りです。
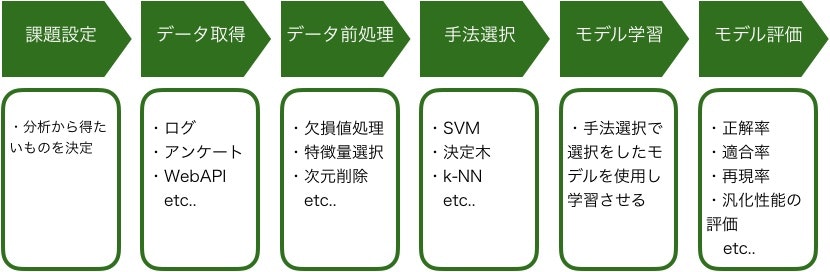
図.機械学習の全体像
2-3.データ前処理はすぐには終わらない。むしろ機械学習は前処理が8割
全体像を掴み、調査を進めていると「前処理が8割」という言葉をよく見かけるようになりました。
この言葉を見た瞬間は、正直半信半疑でした。
しかし、実務をやり始めるとこの言葉の通り、「欠損値をどう埋めるか」や
「他の特徴量を生成した方がいいのでは」、「どの特徴量を使うべきか」などなど
ほとんどの時間が前処理に費やす時間でした。
ちなみにデータの前処理では以下のようなことをやっています。
・欠損値処理
・カテゴリーデータ処理
・特徴量の変換
・ランダムフォレストを用いて特徴量にアクセスする
・次元削除
2-4.モデルの評価方法は正解率だけではない
データ前処理をしモデル学習をさせた後、モデルを評価する必要があります。
この評価方法も正解率だけではなく、適合率や再現率という評価方法がありました。
また汎化性能を測るためにクロスバリデーションという手法も頻繁に使用されています。
評価方法の式について以下簡易的にまとめておきます。
詳細を知りたい方は、以下サイトを参考にしてください。
https://qiita.com/tf-gane/items/31483cc4365eca287d24
| 1 | 0 | |
|---|---|---|
| 1 | TP | FN |
| 0 | FP | TN |
| (横軸:予測値、縦軸:実測値) |
正解率:
\frac{(TP+TN)}{(TP+TN+FP+FN)}
適合率:
\frac{TP}{(TP+FP)}
再現率:
\frac{TP}{(TP+FN)}
3.まとめ
学習開始当時に私がしてきた機械学習の思い込みについての忠告をまとめました。
実際にまだまだ知らないことだらけで勉強不足だと痛感する日々です。
やっと全体がつかめてきたので、今後はKaggleにも積極的にチャレンジしていこうと思います。
不足点等あればご指摘いただけると幸いです。
参考文献
・ゼロから作るDeep Learning ―Pythonで学ぶディープラーニングの理論と実装
・[第2版]Python 機械学習プログラミング 達人データサイエンティストによる理論と実践
・代表的な機械学習手法一覧
(https://qiita.com/tomomoto/items/b3fd1ec7f9b68ab6dfe2)
・機械学習の評価指標を簡単にまとめてみた
(https://qiita.com/tf-gane/items/31483cc4365eca287d24)