はじめに
この記事は、機械学習の推定結果を評価する際に用いる評価指標について、どの場面でどの指標を利用すればよいか毎回迷ってしまうので、一度まとめます。今回紹介する指標以外にも多々ありますが、自身が良く利用するものを紹介していること、機械学習のコーディングなどではないため、悪しからず。
混同行列(Confusion Matrix)
混同行列とは、クラス分類の推定結果をまとめた表のことを言い、下記のように「行」に実測値、「列」に推定値をおきます。
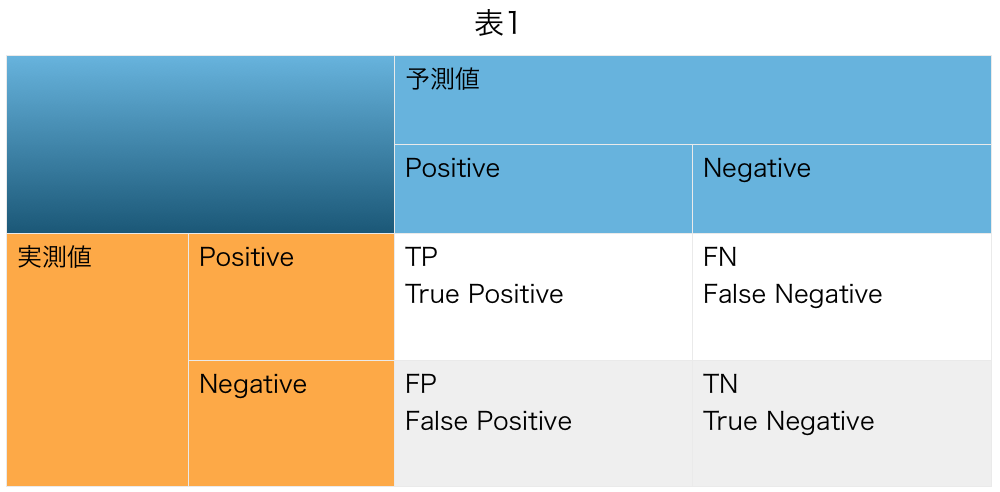
TP(True Positive) 正しく正(陽性)と判断された。
TN(True Negative) 正しく負(陰性)と判断された。
FP(False Positive) 誤って正(陽性)と判断された。
FN(False Negative) 誤って負(陰性)と判断された。
例えば・・・
ある一人の患者が、ある医者に「あなたは病気にかかっています」と診断されました。
しかし、後にとある検査によって、この患者は病気にかかっていないことが判明しました。
この時の医者の判断は「TP、TN、FP、FN」のどれに分類されるでしょう。
病気にかかっていることを陽性、かかっていないことを陰性とします。
![]() 正解は、「FP」誤って陽性と判断されたとなります。
正解は、「FP」誤って陽性と判断されたとなります。
以下、この混同行列を利用した評価指標をまとめます。
正解率(Accuracy)
全体のうち、予測通り正誤分類できた割合を表します。
計算式 ![]()
![]() TP+TN / 全体
TP+TN / 全体
どのような時の指標に利用するのか?
![]()
分類を適切にできた数の割合のため、直感的に一番分かりやすいが、FP、FNを無視して良い場合に利用する。(オレンジとみかんが混ざってしまった時に分類など。)
適合率(Precision)
予測値で陽性である判断された時、実際に陽性のサンプルである割合を表します。
計算式 ![]()
![]() TP / TP+FP
TP / TP+FP
どのような時の指標に利用するのか?
![]()
検索サイトである単語に対して、適合するサイトを表示させるなど、FPが低ければ良い検査の場合に利用する指標となります。
再現率(Recall)
実際に陽性であるサンプルのうち、陽性であると判断されたサンプルの割合を表します。
計算式 ![]()
![]() TP / TP+FN
TP / TP+FN
どのような時の指標に利用するのか?
![]()
FNが低ければ低いほど、良い結果になるため、病院の検査結果や、空港での海外からの流行病検査などには有効な指標となります。
上記の適合率と再現率は、一方の数値を高めると、もう一方の数値が低くなるトレードオフの関係にあります。
※たくさん陽性を出す検査➡️再現率が高まり、適合率が低くなる。
※たくさん陰性を出す検査➡️適合率が高まり、再現率が低くなる。
このため、下記のような「F値」と呼ばれる指標が利用されます。
F値 (f1-score)
適合率と再現率の調和平均を表します。
計算式 ![]()
![]() 2Precision × recall / precision + recall
2Precision × recall / precision + recall
おわりに・・・
今回取り上げた指標以外にも、「不正解率」や「特異度」など、検査や利用したい結果によって、評価指標が変わってきますので、今後も利用するたびに、まとめて挙げていきたいと思います![]()