Provisioned Concurrencyのおさらい
「LambdaのProvisioned Concurrencyと1年付き合ってみて思ったこと。」を前回書いたので、そこにProvisioned Concurrencyとは何で、なんのために誕生したかが書かれています。また、どんなとことで使えるかというユースケースもまとめておきました。
簡単に言うと、LambdaのColdStartの課題を解決するために生まれました。つまり、Lambdaのインスタンスを事前暖機しておく機能と言えます。

この絵のように、Provisioned Concurrencyを利用して事前暖機しておくと、最初の呼び出し時点ですでに暖まった状態でリクエストを受け付けれるため、WarmStartします。
Lambdaの実行モデルについて
AWS Lambdaの実行モデルについて考えてみるに詳しい説明を書きました。こちらを参照ください。
Provisioned Concurrency のプラクティス
以前プレゼンテーションで使ったものがありますので、こちらをクリックするとデッキに飛びます。

さて、ここからはProvisioned Concurrencyのプラクティスについて触れておきたいと思います。
本稿でご紹介するのは以下の3つになります。
- デプロイに関するプラクティス
- 実装に関するプラクティス
- デザインパターンに関するプラクティス
デプロイに関するプラクティス
Lambdaのalias荷重について
Lambda関数にはversionとaliasという機能があります。Lambdaサービスに関数をデプロイすると、その関数はLambdaサービス内でimmutable(不変)に管理されます。
そして、deployした関数にversion数値をつけることができます。(1からインクリメント)
さらに、versionに対してalias(別名)をつけることもできます。(例. 5=prod, 7=dev)

この上の図でfuncAと言う関数は、version 5, 6, 7 がProvisioned Concurrencyによって3インスタンスずつ暖機された状態になっています。とくに、version 5 のaliasがprod, version 7 のaliasがdevとつけられており、alias指定でProvisionedされた状態です。

一方、funcBはprodというaliasにversion 3, 4が混在しています。aliasは複数のversionを包含でき、それぞれのversionに荷重をかけることができます。funcBのprodはversion3に60%, version4に40%の荷重がかかっています。荷重がかかったaliasに対してリクエストがくると、その割合でリクエストトラフィックがルーティングされます。
このaliasの荷重機能に着目します。
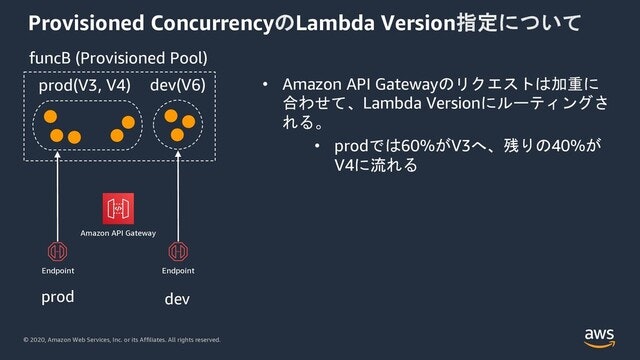
API GatewayにはLambdaとの統合時にaliasやversionを指定して設定しておくことができます。この図ではLambdaのprodに対して、API Gatewayのprodステージを設定しています。こうすると、API Gatewayに到達した100%のリクエストが 60% だけversion 3へ、のこりの40%が version 4に流れることになります。
荷重を利用したデプロイ方法
もし、この荷重を利用せずにaliasを新versionに一気に切り替えるようなリリースをしたらどうなるでしょうか。
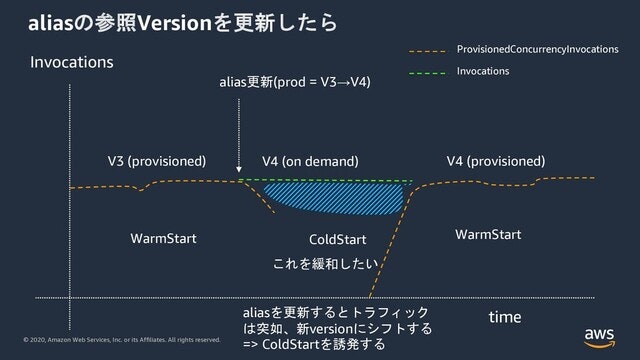
この例ではprodが参照しているversionを3から4へ一気に切り替えています。そうするとLambdaサービスに到達したリクエストがすべて一気に、新versionの4へ流れ込んできます。Provisioned Concurrencyの機能としてはversion 4を暖機開始しますが、readyになる前にリクエストがversion 4にルーティングされ処理を行うためにon-demandインスタンスが利用されることになります。つまり暖まっていないon-demandインスタンスがColdStartする結果になります。
これを緩和していきたいというの課題になります。
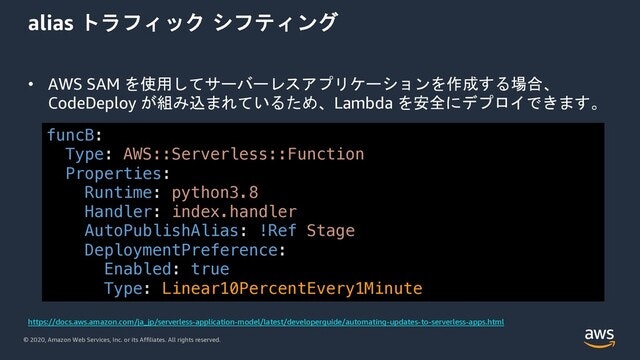
そこで利用できるのがaliasトラフィックシフティングになります。この機能ではaliasの荷重を線形に変化させていくなどデプロイの戦略を選ぶことができます。
たとえばこのAWS SAMの例では、毎分10%ごとトラフィックをversion上位に移動していく設定になります。
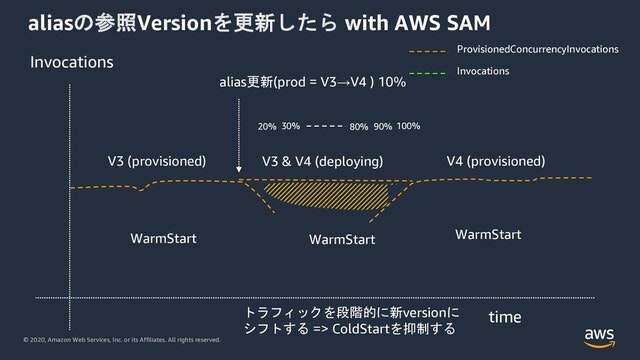
こうすることで、ColdStartを緩和し、暖機されたインスタンスを必要量保ちながらトラフィックをシフトすることができます。
実装に関するプラクティス
全てのRuntime言語共通

Provisioned Concurrencyの基本は、できるだけHandler関数が呼ばれる前のinitializeのフェーズで処理を実施することです。
- Handlerのdurationを下げれる(Hadlerの中で計算する必要がないものはGlobalな処理にしてしまう)
- ClassのロードなどもGlobal領域やStatic領域で実施する。( Lazy Loadingはしない )
- DBコネクションや、外部APIとのTLSハンドシェイクなども暖機フェーズで実施してしまう
Handlerの処理量を減らすこように心がけましょう。
それぞれのRuntime言語ごとのTipsも紹介して起きます。
Java

Python

Node.js

2020.12.09時点ではLambdaはNode.js12.xまでの対応ですが、Node.js 14.xでは Top-Level awaitが対応されるので、Lambdaが14.xをサポートすると同期的に外部APIを呼ぶような利用がし易くなると思います。
デザインパターンに関するプラクティス
同時実行クオータについて

Provisioned Concurrencyで設定できるのはLambdaの最大同時実行数から100を引いた数までです。default 1000だと900までになりますが、上限緩和して10000同時実行数まで可能なアカウントでは9900が最大値になります。
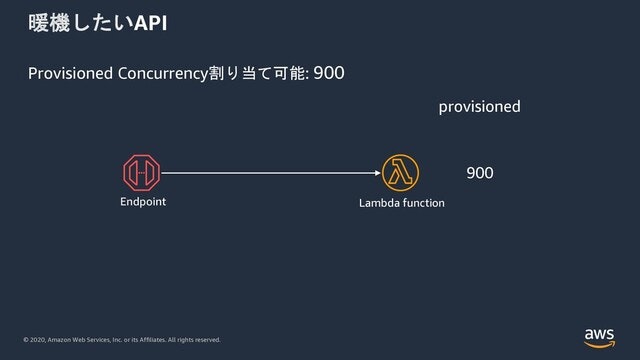
このように暖機したいAPIのバックエンドLambdaが一つの場合はさほど問題になりません。最大900までひとつのLambda関数に割り当てることもできるかもしれません。(実際は、Provisionedしない他の関数ももちろん考慮するべきです。)
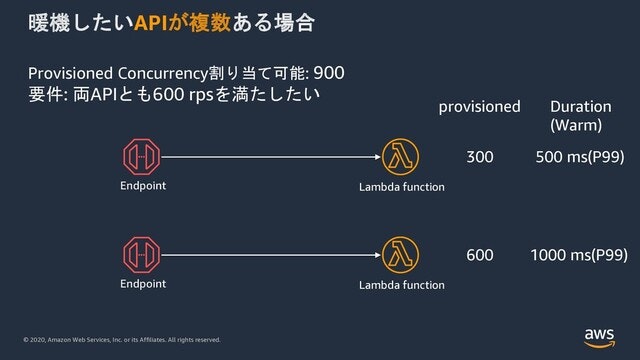
問題になるのは暖めたい関数が複数ある場合です。この場合、900と言う数を上限緩和するか、按分して関数に割り当てるしかありません。
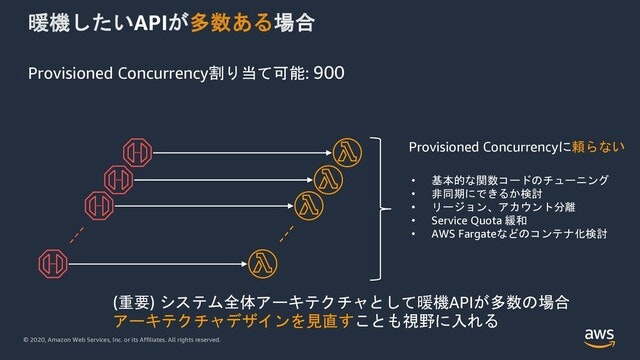
もっともっと暖めたい関数の数が増えたらどうでしょうか。
按分された一つの関数に与えられるProvisioned Concurrencyの数は非常に少なくなってきます。
よって、暖機したい関数が多い場合、アーキテクチャデザインをSQSを用いた非同期アーキテクチャにできないか検討してみてください。できるだけ暖めが必要な関数の数を最小化することを心がけましょう。
Dispatch Patternについて
多くの関数を暖める必要がある場合、Dispatch Patternが一つの選択肢になるかもしれません。(あとで出てきますが利用には注意が必要)
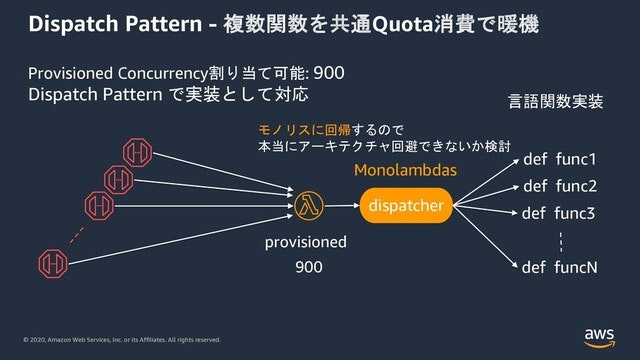
このパターンでは、API Gatewayのバックエンド関すを単一にして、その関数内の実装でDipatchロジックを記述し、言語内関数を呼び出すと言う形になります。
これにより暖めるLambdaの数が減らせるので一点集中的にProvisioned Concurrencyが適用できます。
しかし、Lambdaがモノリスに回帰してしまうので、積極的にこのパターンをお勧めするものではありません。
Dispatch Pattern実装例

かつて、個々のLambda関数であったものをそのまま単一のLambda関数にポーティングした例になります。内部routerのロジックはそれぞれの仕様に応じて記述しますが、たとえばEventデータのあるフィールドにDispatch用の情報が入っているなどするはずなのでその情報を元にDispatchします。
このモノリスなLambdaを揶揄する単語として Monolambda モノラムダ という言葉があります。モノラムダにならないように気をつけましょう。
まとめ

Provisioned Concurrencyを使わなくても、Lambdaはリクエストがくればマネージドにスケールします。その仕組みを活かしてアーキテクチャを設計しましょう。また、本当に暖機が必要な同期処理が必要かどうか常に非同期アーキテクチャの検討をしてください。
ColdStartはVMでもコンテナでも関数でも、Thread ModelでもFunction Modelでの100%避けるのは困難です。スパイクのピークトラフィックを推定するのが難しかったり、スパイクタイミングがわからなかったり、また予想より低いピークであった場合、固定的にリソース確保するのはコスト増加につながります。
そこで、P99やP95(パーセンタイル) でLatencyを計測するようにして、ColdStartを100%避けることに投資するよりSLAを設定してP99でDurationが500msを下回れば良いとするなど、達成したいSLA設定をパーセンタイルで考えるのも一つの基準になると思います。
Provisioned Concurrencyの説明を多くしてきましたが、できるだけProvisioned Concurrencyに頼らない設計にしていただくことをお勧めして、終わりにしたいと思います。