なぜこの記事を書くか
Fargateが良いかLambdaが良いかという質問をよく受け付けます。答えは一通りではありません。
すべてシステムやユーザーのワークロードに依存するのでどちらが優位ということは一般に言えません。
ただ、達成したい目的が明確で、こういうコンテキストの上ではどちらの方が相応しいということは言えると思います。そのために、今回Lambdaの起動モデルについて改めて説明を書きました。
Lambdaの実行モデルについて
Thread Model と Function Model
LambdaはFunction Modelとなります。
Provisioned Concurrencyのプラクティスを説明する上でLambdaのFunction Modelを理解した方が良いと思いますので、すこし説明いたします。
Function Model
Lambdaサービスにリクエストがくるとサービスはインスタンスを立ち上げ初回起動であれば、そのインスタンスはColdStartします。Handlerの処理が終わると次のリクエストを受け付けるまでLambdaインスタンスはアイドル状態になります。
アイドル状態のLambdaインスタンスにLambdaサービスから次のリクエストがルーティングするとまたLambdaインスタンスは処理を開始します。このときWarmStartします。
Lambdaインスタンスが処理中の場合LambdaのFunction Modelでは次のリクエストを受け付けることはありません。そのため次のリクエストのために新たにLambdaサービスはLambdaインスタンスを起動します。こちらも初回起動となる場合ColdStartします。
Thread Model
このようにLambdaのFunction Modelの説明を受けると、1プロセスで複数のリクエストをハンドリングできるThread Modelに比べてFunction Modelはオーバーヘッドが大きいように感じます。
しかし、Thread Modelでも1つのプロセスで捌けるThread数(リクエストを同時に受け付けれる数)はCPU/Memoryに依存するため有限です。アプリケーションサーバーではmaxThreadというパラメータを持つことがよくあります。このパラメータで、リソースに合わせて立ち上がるThreadの数を調整することになります。
そして、より多くのThreadを必要とする場合はどうするかと言うと、VM単位でスケールさせたり、今はコンテナ(プロセス)単位のスケールをする場合も多いと思います。
コンテナにしてもVMにしてもリソースが飽和してから、次のリソース確保のためインスタンスやプロセスを起こした場合はColdStartします。ですので、リソースのMetricを監視して事前に起こしておき暖機(クラスのロードなど初期化処理)しておく必要があります。
どのModelが良いのか
どちらかのModelが他方より良いと言うことはありません。
Thread Modelでも、Function Modelでも適切なアーキテクチャを組むことでColdStartを緩和できたり、またThread利用が相応しいシステムやFunction利用が相応しいシステムがそのシステム特性に応じて考え得るので、どちらのModelが優れていると言うことはありません。また、関数、コンテナ、VMのリソース粒度もどれが最適かはシステムや要件によります。
とはいえ違いはあります。まずスケールの違いについてですが、関数、コンテナ、VMのColdStart時間を考えるとリソース規模が小さい方がより俊敏に起動することが期待できます。作りにもよりますが、関数リソースの方がVMリソースよりも立ち上がりが速いことが多いでしょう。
それぞれ暖機されていない環境でのColdStartの頻度を考えると、関数単位ではステップの小さな階段を登るようにスケールするので、リクエストスパイク時に頻度高く、小刻みに小さくColdStartします。そして一番リソース単位の大きいVMが大きなステップの階段を登るように頻度は少なくてもリソース確保単位が大きいためより大きなColdStartをもたらします。コンテナはその中間です。
一度暖まってしまえば、リソースが許容できる範囲の後発のリクエストはWarmStartで処理できるのは、どのリソース単位のシステムでも同様です。
LambdaサービスのFunction Modelの良さ
Function単位でisolation(分離)が保たれています。つまり、同時リクエストは別のLambdaインスタンスで実行されることになるので、お互いがメモリやCPUリソース上で干渉することがありません。Thread Safeな実装が求められていたThread Modelとの違いになります。
そしてThreadの同時実行時の試験は通常のロジック単体試験とは別にきちんと試験する必要があります。特にリクエスト数が増加した場合にだけ顕在化する事象などテストが行いにくいシチュエーションもあるでしょう。Function Modelでは単一プロセス、単一Threadでの処理で実装することがほとんどだと思いますので、このような懸念は緩和されます。
もう一つの利点はメモリリークなどの(本来あってはいけない)課題のあるコードがデプロイされた場合でも、Lambdaインスタンスはマネージドな仕組みで定期的に回収されます。つまりある関数でメモリリークがあり、その関数が不具合を起こしたとしても他のLambdaインスタンスに影響することはありません。不具合のインスタンスもそのうちLambdaサービスに回収されます。
回収された場合、アイドル中や起動中のインスタンス数の総和が低下するので、待機インスタンス量をこえるリクエストがきたら再びColdStartします。しかしこれがプログラミングを簡素にしている理由となっていることがお分りいただけたと思います。関数を小さく保つことで仮にColdStartが起きてもLatency/durationを最小限にすることがLambdaのプラクティスになります。
回収頻度が高いことから、ColdStartもリソース単位が大きいシステムより頻度が高くなることを意味しますが、Lambdaサービス側で頻度よくセキュリティパッチをマネージドな仕組みの中で適用できているのはサービス側で回収を行なっているからです。よりセキュアとも言いかえれます。大きなリソース単位だとセキュリティパッチのためにメンテナンスウインドウを切ってシステムを停止したり、停止が許容できない場合には同等のリソースを余分に立ち上げた上でパッチを当てるなど工夫が必要になります。
Lambdaサービスがこのあたりの面倒をマネージドに見てくれています。
詳しくはAWS Lambdaのセキュリティ概要に書かれていますので興味がありましたらぜひお読みください。
Provisioned Concurrencyのユースケースでもお話しましたが、ユースケースの一つにスパイクするリクエストへの対応があります。このような高スループット環境下で分離されたLambdaインスタンスはリクエストが増加するとデフォルトで1000同時実行までスケールします(Soft limit制限緩和可能)。メモリやCPUのリソース干渉を受ける1000Threadを動かしているシステムと比べてみると分りやすいと思います。
干渉を受けない個々に分離独立したリソース占有プロセスが1000同時実行します(ソフトリミットなので上限緩和できます)。これがLambda関数の良さだと私は考えています。
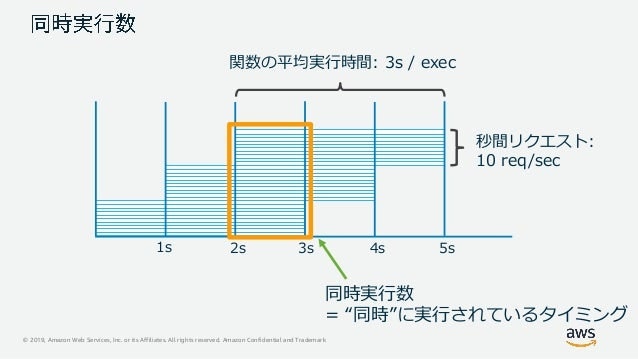
同時実行数についてのおさらい
同時実行数は以下の図にある通り、同時に実行されているタイミングで計算します。たとえば1リクエスト処理に3秒かかる関数に10req/secの秒間リクエストがきた場合、同時実行数は、
3 * 10 = 30
同時実行数=30 になります。
では、同じrps(request per second 秒間リクエスト数)でLambda関数の処理時間を3秒から1秒に縮めた場合を考えます。
1 * 10 = 10
同時実行数=10 になります。つまり、Lambda関数の処理時間を小さくすれば同時実行数の増加を低減できるということです。
さらに、Lambda関数を処理時間を100ms = 0.1sec まで達成できたとします。
0.1 * 10 = 1
同時実行数=1 になります。つまり、10rpsを処理するのに理屈上は1インスタンスで良いケースもあるということです。(実際はリクエスト同時性、つまりタイミングによって複数立ち上がることはあります。)
ですので、1000rpsを処理するのに必要なLambdaインスタンス数が1000ということは必ずしも、そうではないと言うことがご理解いただけたかと思います。100msの処理時間であれば、100インスタンスで処理できてしまいます。
100msの処理のために起こされたLambdaインスタンスはColdStartしますが、立ち上がると10rps処理できるため後続のリクエストがWarmStartする可能性が高くなります。Lambda関数の処理時間を短くするとColdStartを緩和できるのはこう言った理由になります。
この同時実行数の考え方もLambdaを理解する上で非常に重要になります。
まとめ
アーキテクチャやデザインモデルを考えるときに、どちらが優れている、どちらの方がモダンだと言う議論は、自転車か飛行機かどちらが優秀でどちらがモダンかと言う議論に似ています。
ユースケースに応じて、適用するデザインは変わるはずです。デザインやパターン、モデルを適用するにはシステムの特性やプロダクトの要件を知る必要があります。それに応じて適切なアーキテクチャを選択します。これがビルディングブロックの考え方です。
「金槌を持てばすべて釘に見える」一つのライブラリ、言語、インフラストラチャ、デザインパターン、アーキテクチャを持てば、すべてのワークロードにそれを適用したくなるということを言っていることわざになります。適材適所でデザイン、アーキテクチャを適用するのが Well-Architectedと言えると考えています。