OR-Toolsとは
Googleが作っているフリーの最適化ツールです。OR-ToolsにはLPやMIPのソルバーもありますが、本記事ではCPソルバーを用いて配送計画問題を解く例を紹介します1。CP(Constraint Programming)とは言ってもかなり配送計画などのルーティング問題向けに使いやすいものになっているので、CPとは何か知っていなくても全然使えます(私もそんなに知らないですし、本記事でもCPの説明はしません)
なおOr-ToolsはC++で書かれており、それのJavaやC#のwrapperが存在しますが、本記事はPythonのwrapperを用います
配送計画問題を解くときにOr-Toolsをおススメする理由
最適化のツールは色々あって、pythonだとpulpなどは有名ですが、こと配送計画問題に関してはOR-Toolsを使うことを断然おススメします。理由はいくつかありますが、以下の3点は大きいです
- 無料
- 速い(大規模な問題でも現実的な時間内に解ける)
- 最適化の数学的な理解が不要(あるに越したことはないが)
なんか数式が出てきてよく分からない、だとか、規模が大きいので全然解き終わらない、みたいな苦悩を解消してくれます。趣味や研究でやるならばともかく、実務で使うならばOR-Toolsが最もバランスがとれていると思います(ウン百万円払える場合を除く)
(補足)なんで速いのか2
最適化のソルバーにも得意不得意があって、配送計画問題のような順番を選ぶタイプの問題はMIPのソルバーで愚直に解こうとすると(専門家の持つ凄技を使わないと)非常に時間がかかると聞いたことがあります。Or-Toolsはメタヒューリスティクスを用いて解を求めており、そもそもの解法が速さ重視なものを使っているため速いというわけです。そのため、OR-Toolsで解くと厳密な最適解を求められるとは限りません
ちなみに理由の3点目ですが、MIPのソルバーを使おうとすると数式をそのまま記述するような形になるため、組合せ最適化の数学的な理解が必須です。OR-Toolsだとそれが必須ではなく、本記事でも数式は一切出てきません
参考になるサイト
-
公式のガイド
- これを順番に読むのが一番てっとり早い
-
ortools.pywrapcpのドキュメント
- ほとんど説明はないですが...
-
Activimetrics LLC
- 神Blog。かなり深いところまで解説がある
環境
Python: 3.7.3
ortools: 8.1.8487
ortoolsは、pip install ortoolsで簡単にインストールできます
問題設定
いわゆる**CVRP(capacitated vehicle routing problem、容量制約付き配送計画問題)**という問題を解いていきます。それぞれの地点に届けるべき量が決まっていて、トラックの容量に収まるように運ぶルートを見つける、という制約の元でコストを最小にする問題です。
CVRPについては「容量制約有りの配送計画問題(CVRP)を量子アニーリングで解く」なども参考になります
具体的には川崎市の図書館(12館)を巡る問題を考えます。OR-Toolsの速さを誇示するにはもっと大規模のものでやるのがいいと思うのですが、緯度と経度が持ってきやすかったので 例としては数が多すぎると分かりにくいので、このくらいで説明していきます
データ準備
import pandas as pd
# 川崎の図書館のデータを使用
url = 'https://www.city.kawasaki.jp/170/cmsfiles/contents/0000116/116229/141305_public_facility_library.csv'
df = pd.read_csv(url, encoding='cp932')
print(df.shape) # (12, 39)
ということで、データを持ってきました
今回使うデータは以下のようになっています
| 名称 | 緯度 | 経度 | 絵本の蔵書数 | |
|---|---|---|---|---|
| 0 | 川崎市立川崎図書館 | 35.531938 | 139.698569 | 12,810 |
| 1 | 川崎市立川崎図書館大師分館 | 35.534118 | 139.725388 | 5,783 |
| 2 | 川崎市立川崎図書館田島分館 | 35.519115 | 139.716468 | 5,718 |
| 3 | 川崎市立幸図書館 | 35.544238 | 139.687591 | 14,463 |
| 4 | 川崎市立幸図書館日吉分館 | 35.546673 | 139.668448 | 7,148 |
| 5 | 川崎市立中原図書館 | 35.575876 | 139.659184 | 28,228 |
| 6 | 川崎市立高津図書館 | 35.605215 | 139.615114 | 30,653 |
| 7 | 川崎市立高津図書館橘分館 | 35.570123 | 139.623863 | 5,277 |
| 8 | 川崎市立宮前図書館 | 35.589403 | 139.579885 | 24,839 |
| 9 | 川崎市立多摩図書館 | 35.619590 | 139.562008 | 19,099 |
| 10 | 川崎市立麻生図書館 | 35.604387 | 139.505354 | 20,858 |
| 11 | 川崎市立麻生図書館柿生分館 | 35.591171 | 139.495023 | 7,508 |
図示するとこんな感じです
import plotly.graph_objs as go
trace = go.Scattermapbox(
lon = df.経度,
lat = df.緯度,
mode = 'markers + text',
text = df.名称,
marker = dict(size=df.絵本の蔵書数/1000,
color="red",
),
)
data = [trace]
fig = go.Figure(data)
fig.update_layout(mapbox_style="open-street-map",
mapbox_center_lat=35.6,
mapbox_center_lon=139.6,
mapbox={'zoom': 10},
margin={"r":0,"t":0,"l":0,"b":0},
)
fig.show()

赤い丸が図書館です。丸のサイズは絵本の蔵書数に比例するようにしています。川崎駅のあたりにある川崎図書館の蔵書数が少ないのが意外ですね
川崎は横長の市なので、ぱっと見そこまで難しくはなさそうに見えます。ちなみに、人間でも15くらいまでのTSPは最適解を求められることが多いらしいです
図示する際はplotlyを用いていますが、このあたりの解説は本筋と外れるのでよそに任せます
(https://plotly.com/python/scattermapbox/#basic-example)
OR-Toolsの使い方
本題です。最初にコード全体を載せておきます
import pyproj
from ortools.constraint_solver import pywrapcp
# index managerを作成
manager = pywrapcp.RoutingIndexManager(len(df), 2, 0)
# routing modelを作成
routing = pywrapcp.RoutingModel(manager)
# 移動距離のcallbackを作成、登録
def distance_callback(from_index, to_index):
"""Returns the distance between the two nodes."""
# Indexの変換
from_node = manager.IndexToNode(from_index)
to_node = manager.IndexToNode(to_index)
# 2点間の距離を計算
g = pyproj.Geod(ellps='WGS84')
distance = g.inv(
df['経度'][from_node], df['緯度'][from_node],
df['経度'][to_node], df['緯度'][to_node]
)[2]
return distance
transit_callback_index = routing.RegisterTransitCallback(distance_callback)
# 移動コストを設定
routing.SetArcCostEvaluatorOfAllVehicles(transit_callback_index)
# 配送量のcallbackを作成、登録
def demand_callback(index):
"""Returns the demand of the node."""
node = manager.IndexToNode(index)
return df['絵本の蔵書数'][node] / 100
demand_callback_index = routing.RegisterUnaryTransitCallback(demand_callback)
# 積載量の制約
routing.AddDimensionWithVehicleCapacity(
demand_callback_index,
0, # null capacity slack
[1500, 500], # vehicle maximum capacities
True, # start cumul to zero
'Capacity')
capacity = routing.GetDimensionOrDie('Capacity')
# 最適化の実行
search_parameters = pywrapcp.DefaultRoutingSearchParameters()
search_parameters.time_limit.seconds = 1
solution = routing.SolveWithParameters(search_parameters)
# 解を確認
print(solution.ObjectiveValue())
1. IndexManagerを作成
from ortools.constraint_solver import pywrapcp
# index managerを作成
manager = pywrapcp.RoutingIndexManager(len(df), 2, 0)
最初にIndexManagerというものを作成します
VRPを解く際に、実はソルバーの内部では地点が複製されて求解されています。そのため、ソルバー内部で扱われているindexと我々が認識できるindexが異なるケースがあります(例えばdepotなどはソルバーの中でコース数分複製されます)
ガイドではそれぞれIndexとNodeと区分して記述されているため、本記事でも以降はそれに準じます
つまりIndexManagerとは、「ソルバー内部で使われているIndexを意識することなく、自分が用意したNodeで扱えるようにするためのもの」です
RoutingIndexManagerの引数は順に、地点数、乗り物の数、デポのNode、です。ここでは地点数を図書館の数、台数を2台に設定しています。デポとは、各ルートの一番最初/最後にいるべき場所を指します。ここでは0なので川崎図書館を出発して、最後もそこに到着するような設定です
最初と最後を違う場所にしたり、任意の場所から出発したりするような設定にすることもできます
2. RoutingModelを作成
# routing modelを作成
routing = pywrapcp.RoutingModel(manager)
次にRoutingModelを作成します。先ほど作成したRoutingIndexManagerインスタンスを引数にとります
3. 2点間の移動距離を計算する関数を作成
import pyproj
# 移動距離のcallbackを作成、登録
def distance_callback(from_index, to_index):
"""Returns the distance between the two nodes."""
# Indexの変換
from_node = manager.IndexToNode(from_index)
to_node = manager.IndexToNode(to_index)
# 2点間の距離を計算
g = pyproj.Geod(ellps='WGS84')
distance = g.inv(
df['経度'][from_node], df['緯度'][from_node],
df['経度'][to_node], df['緯度'][to_node]
)[2]
return distance
ortoolsではtransit callbackを用意する必要があります。出発・到着の2点のインデックスを渡すと、そのパスを通るコストを返してくれるような関数です。ここでは2点間の距離をコストとして設定します。最適化問題を解く際にソルバーがこの関数を呼び出すことになります
この関数では最初に、先ほど作成したIndexManagerを使用します。ソルバーはソルバー内部のインデックスを用いてこの関数を呼び出しますが、距離の計算をする際には自分が用意したNodeを用いる必要があるため、 manager.IndexToNodeを用いてsolver内部のインデックスをNodeに変換します
次に、2点間の距離を計算します。ここはどのように計算しても良いのですが、ここではpyprojというライブラリを用いて2点間の直線距離を計算しています。単位はメートルです。ちなみに詳細は「[GPS]pyprojを使用してGPSの緯度経度から距離、方位角、仰角を算出する」
等を参照ください
距離を計算する他の方法としては以下のようなものもあります
- ガイドでは距離行列が用いられています
- Google map APIも使えるようです(お高いですが)
- 無料で道のりの距離を取りたいときはosmnxなどは有力な候補になるでしょう
- 移動距離ではなく移動時間で良ければそれを使うこともできます
- 京都とかならマンハッタン距離で十分でしょう
4. 移動距離をコストとして設定
transit_callback_index = routing.RegisterTransitCallback(distance_callback)
# 移動コストを設定
routing.SetArcCostEvaluatorOfAllVehicles(transit_callback_index)
まず、RegisterTransitCallbackで先ほど作成した距離callbackをRoutingModelに登録します
次に、SetArcCostEvaluatorOfAllVehiclesで登録した距離callbackをコスト(最適化の目的関数)としてセットします。実際に解く際に、ここでセットしたもの(ここでは距離)を最小にするようなルートをソルバーは見つけにいきます。距離以外に時間などをこのArcCost(地点間を結ぶ辺に対応するコスト)としてセットすることも可能です。
5. 配送量の制約を設定
# 配送量のcalbackを作成、登録
def demand_callback(index):
"""Returns the demand of the node."""
node = manager.IndexToNode(index)
return df['絵本の蔵書数'][node] / 100
demand_callback_index = routing.RegisterUnaryTransitCallback(demand_callback)
# 積載量の制約
routing.AddDimensionWithVehicleCapacity(
demand_callback_index,
0, # null capacity slack
[1500, 500], # vehicle maximum capacities
True, # start cumulative to zero
'Capacity')
capacity = routing.GetDimensionOrDie('Capacity')
CVRPでは各地点で決まった量を届ける必要があるため、ここでその制約を記述します
OR-Toolsでは、ルートに沿って蓄積するような変数を追うのに、Dimensionを用います。ここの例における積載量や、時間や到着順などをDimensionを用いて表現できます
RoutingModelにDimensionを追加するのはAddDimensionWithVehicleCapacityで行います。引数は順に、(登録済みの)callback、slackの最大値、最大値(それ以上accumulateされることはない)、0からスタートするか否か、名前、の5つです
callbackについては、先ほどの距離callbackと同じように作成します。出発地/到着地のある距離と違い、配送量は1地点のみで決まるものなので、RegisterUnaryTransitCallbackを使って登録します。各地点を通るたびにこの量だけcapacity dimensionに追加されていきます。ここでは適当に絵本の蔵書数の100分の1ずつ届ける設定にしています
次にslackが正の場合は、Dimensionの値の蓄積がcallbackで返ってきた値に加えて、少しゆるみがあっても良いことを意味します3。例えば時間のDimensionを考えた時に、途中で休憩を挟めるならばcallbackで返ってきた値以上にDimensionの値にプラスされていても問題はないです。今回は途中で本が増えたり減ったりするようなイリュージョンは起こってほしくないので、0にします。
**最大値(ここでは乗り物ごとの最大積載量)**は、ここでは2台それぞれ1500, 500にしています。実質的に制約になっているのはここの部分ですね。1500のほうで全部回りきれるならば1台で済ませることになります。ちなみにDimensionで追っている値が負になることはありません
4つ目はDimensionの蓄積される量が0からスタートするか否かを表すboolです。時間のように必ずしも0からスタートする必要がない場合はFalseにします
最後がDimensionの名前です
6. 最適化の実行
# 最適化の実行
search_parameters = pywrapcp.DefaultRoutingSearchParameters()
search_parameters.time_limit.seconds = 1
solution = routing.SolveWithParameters(search_parameters)
解く際のパラメータを設定して、求解します
search parameterはとりあえずはデフォルトのままでいいかと思います。search parameterで解き方を変えることができるので、解いている問題が難しそうなら試してみるのはありかと思います。ここではtime_limit.secondsだけ1秒で設定しています
で、設定したparameterを引数にとってSolveWithParametersすることで、解を求めてくれます
7. 解の確認
print(solution.ObjectiveValue())
上のコードで最適化した目的関数の値をprintしてくれます
結果は56162でした(単位はメートル)。これで今回の配送最適化問題が解けたことになります
が、目的関数の値だけ言われてもそれが良いのか悪いのかもよう分からん、ということで、結果を詳細に見ていきます
解の出力
def get_solution(manager, routing, solution):
"""Get optimization results"""
result = dict()
for vehicle_id in range(2):
index = routing.Start(vehicle_id)
route_distance = 0
route_load = 0
while not routing.IsEnd(index):
node_index = manager.IndexToNode(index)
route_load = solution.Value(capacity.CumulVar(index))
previous_index = index
index = solution.Value(routing.NextVar(index))
route_distance += routing.GetArcCostForVehicle(
previous_index, index, vehicle_id
)
result[previous_index] = {'地点': node_index, '累積積載量': route_load, '累積距離': route_distance, 'vehicle_id': vehicle_id}
return result
# Print solution on console.
if solution:
result = get_solution(manager, routing, solution)
result_table = pd.DataFrame(result).T
このように結果を辞書に格納していきます。ここは我流で書いている箇所なので、もっとスマートな書き方はあるかと思いますが
何をしているかイメージしやすいように先に結果を見てみましょう。result_tableは以下のような表となります
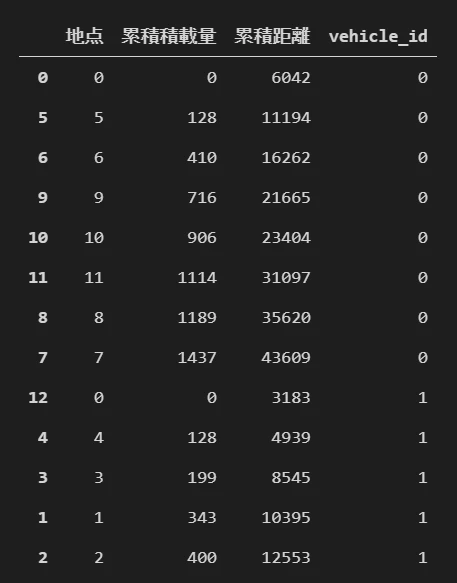
この表の上から順に巡っていきます。地点0(デポですね)からスタートし、5→6→9→10→...と回ることが分かります。またvehicle1のほうは、0からスタートし、4→3→1→2→0と戻ってきます
累積の積載量や距離もい感じに累積されているように見えます。1台目は1500、2台目は500以下に収まっています。2台の累積距離を足すと目的関数の最適値(56162)に一致することが確認できます
はい、ということでこれを作るのが上のコードがやっていることです。ここではOR-Toolsに関連したポイントだけ何点か記します
-
routing.Start(vehicle):その乗り物のスタート地点を取得 -
routing.IsEnd(index):その地点がエンド地点か否かを取得 -
solution.Value(x):解でのxの値を取得 -
capacity.CumulVar(index):その地点でのcapacityの累積量-
capacityは前にGetDimensionOrDieでとってきておいたDimension。このように後で解を確認する際に使うので、Dimensionはgetしておくのが無難
-
-
routing.NextVar(index):その地点の次に訪れる地点のIndexを取得- これをEnd地点まで繰り返すことで一連のルートを取得できる
例によってsolverと会話するときはIndexを用いる必要があるので、地点がどこかを確認するためにNodeに変換する必要があることは注意が必要です
地図上にプロット
result_table['到着順'] = result_table.groupby('vehicle_id').cumcount()
route_v0 = result_table.query('vehicle_id==0').merge(df, left_on='地点', right_on=df.index)
route_v1 = result_table.query('vehicle_id==1').merge(df, left_on='地点', right_on=df.index)
route_v0 = route_v0.append(route_v0.iloc[0])
route_v1 = route_v1.append(route_v1.iloc[0])
depot = route_v0.iloc[0:1]
depot['累積距離'] = 0
trace = []
for route, color, name in zip([route_v0, route_v1, depot],
['red', 'blue', 'black'],
['vehicle1', 'vehicle2', 'depot']):
trace_route = go.Scattermapbox(
lon = route['経度'],
lat = route['緯度'],
mode = 'markers + text + lines',
text = route['名称'] + '<br>' +
'到着順: ' + route['到着順'].astype(str) + '<br>' +
'ここまでの累積載量: ' + route['累積積載量'].astype(str) + '<br>' +
'次地点到着までの累積距離: ' + route['累積距離'].astype(str),
marker = dict(size=route['絵本の蔵書数']/1000),
line = dict(color=color),
name=name
)
trace.append(trace_route)
data = trace
fig = go.Figure(data)
fig.update_layout(mapbox_style="open-street-map",
mapbox_center_lat=35.6,
mapbox_center_lon=139.6,
mapbox={'zoom': 10},
margin={"r":0,"t":0,"l":0,"b":0},
)
fig.show()
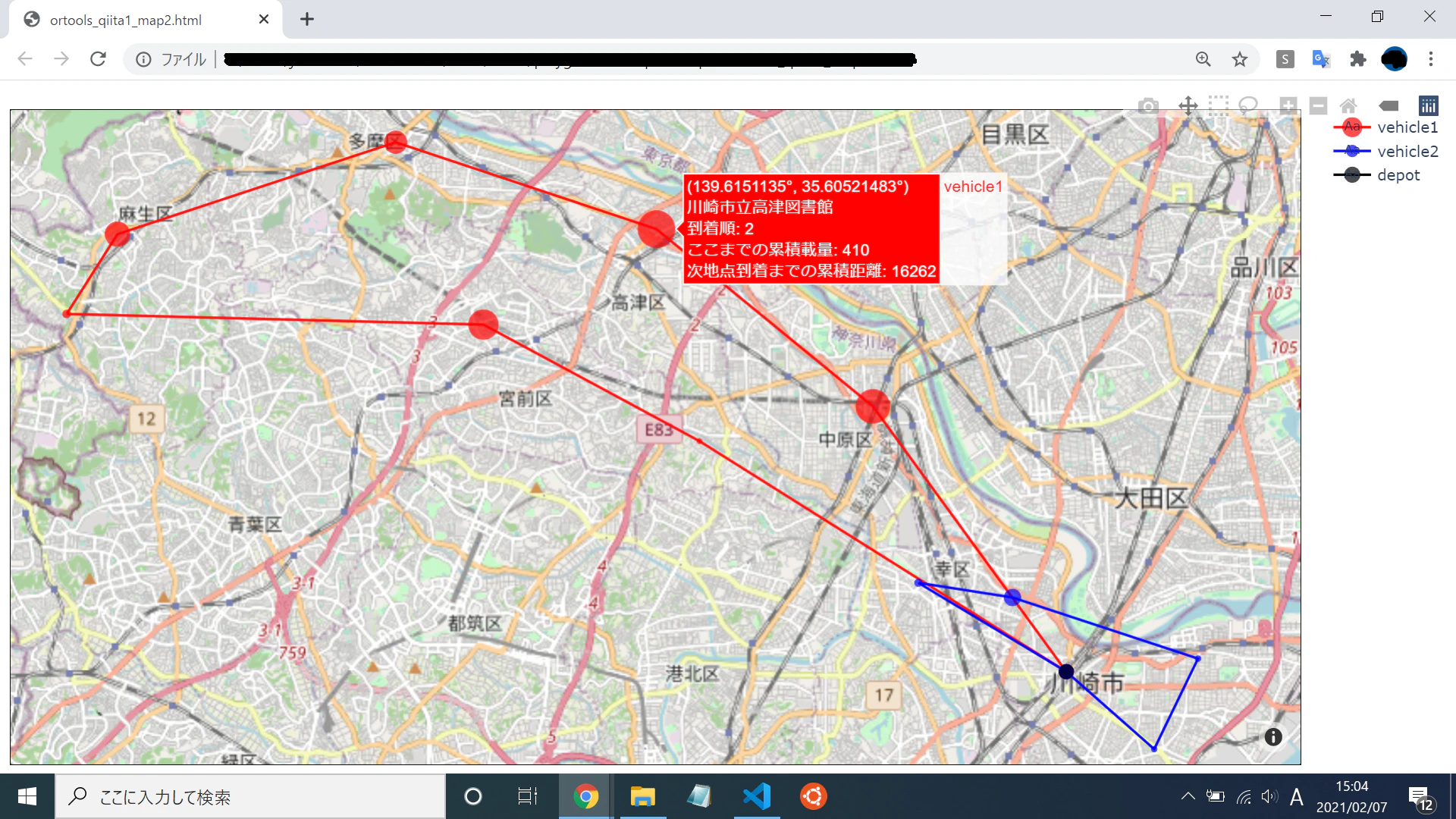
こんな結果になりました。なんというか、まあ特に面白みはない妥当な結果ですね。でもこれが出来るってことはあんなことやこんなことも、と妄想が広がります
おわりに
OR-Toolsは他にも、VRPTW(VRP with Time Windows)やVRPPD(Vehicle Routing Problem with Pickup and Delivery)を解いたり、受入車両制約、労働時間制約、任意の地点からの出発、FIFO制約などなど、もっと色々な制約を入れられます
ちなみにこの手の問題は熟練した人間が頑張って計画を立てるケースも多いらしいですが、最適化を行うことで10%くらいコストを抑えられると聞いたことがあります4。物流に関する本でも配送ルートの最適化は全然触れられていなかったりもしますが、DXが叫ばれている今日ですから、十分検討する価値はあると個人的には思っています
-
OR-ToolsにはCPソルバーが2つ(CP-SATとOriginal CP)あり、現在はCP-SATが推奨されています。本記事で使うRoutingModelはOriginal CPのほうのCPソルバーを使っていますが、こっちは実質Routingにだけ使われている想定っぽいです。OR-Toolsのページを見てもrouting solverって書いてあったり、CP solverを使ってるって書いてあったり、この辺り正確にどういうことになのかはよく分からないですが... ↩
-
有償の最適化ソルバーの中でも有名どころのGurobiよりも速いです(MIPソルバーで解く際は書き方で大きく異なるため、専門家が気合入れて書いたら分かりませんが)。感覚的には、妥当な解を出してくれる地点数の桁がGurobiと比べてひとつ、pulp(solverとしてはCBC)と比べるとふたつ大きい程度には強力です ↩
-
ドキュメントのslackについての説明:https://developers.google.com/optimization/routing/dimensions#slack_variables ↩