BigQueryではDDLでテーブルやカラムのDescriptionを書いたり、クラスタ列や各種制約を記述できたりします。dbtやdataformを使っていない場合にもコードと近い場所にドキュメントやテーブルの設計書を置くことで、一元管理や修正時のずれ防止が期待できます。
本記事ではCTASによるテーブル作成におけるDDL記述を中心に紹介します。全体感は公式ドキュメントなどを見てください。
また、テーブル設計やドキュメントの管理方法としてこの記事の書き方がもっとも良いという主張ではなく、BigQueryのSQLだけでもここはできるよ、という紹介記事になります。
ゴール
本記事では、以下のクエリを説明していきます。
CREATE OR REPLACE TABLE `sample.user` (
user_id INT64 NOT NULL OPTIONS(description = "ユーザーID(アプリ内で一意)"),
created_at TIMESTAMP NOT NULL OPTIONS(description = "アカウント作成日時(サーバー時刻)"),
communities ARRAY<STRING> OPTIONS(description = "所属コミュニティ名の一覧。正規化せず簡易保持"),
profile STRUCT<
display_name STRING OPTIONS(description="アプリ内での表示名(ユーザー設定)"),
birth_year INT64 OPTIONS(description="誕生年(ユーザー入力。未入力の場合はNULLになる)")
> OPTIONS(description = "ユーザーのプロフィール情報(本人入力・設定値)"),
study_history ARRAY<STRUCT<
studied_at TIMESTAMP OPTIONS(description = "学習日時(イベント発生時刻)"),
material STRING OPTIONS(description = "学習対象(教材名や範囲などの識別子/表示名)"),
correct BOOL OPTIONS(description = "当該学習の正誤(TRUE=正解、FALSE=不正解)")
>> OPTIONS(description = "学習履歴(直近N件など、用途に応じて保持範囲を定義)"),
PRIMARY KEY (user_id) NOT ENFORCED
)
CLUSTER BY user_id
OPTIONS(
description = "ユーザーマスタ。アプリのユーザー基礎情報を集約したテーブル。XXXのソースを加工して作成し、日次バッチで上書き更新(サンプル)",
labels = [("owner", "data-team"), ("certificate", "experimental")]
)
AS
SELECT
-- ※以下は適当なサンプルデータ
1 AS user_id,
TIMESTAMP("2026-01-11 00:00:00+09") AS created_at,
["SQL", "BigQuery"] AS communities,
STRUCT("田中 太郎" AS display_name, 2000 AS birth_year) AS profile,
[STRUCT(
TIMESTAMP("2026-01-01 20:00:00+09") AS studied_at,
"BigQuery: chapter1" AS material,
TRUE AS correct
)] AS study_history
;
上記で作成したテーブルの画面はこのように見えます。
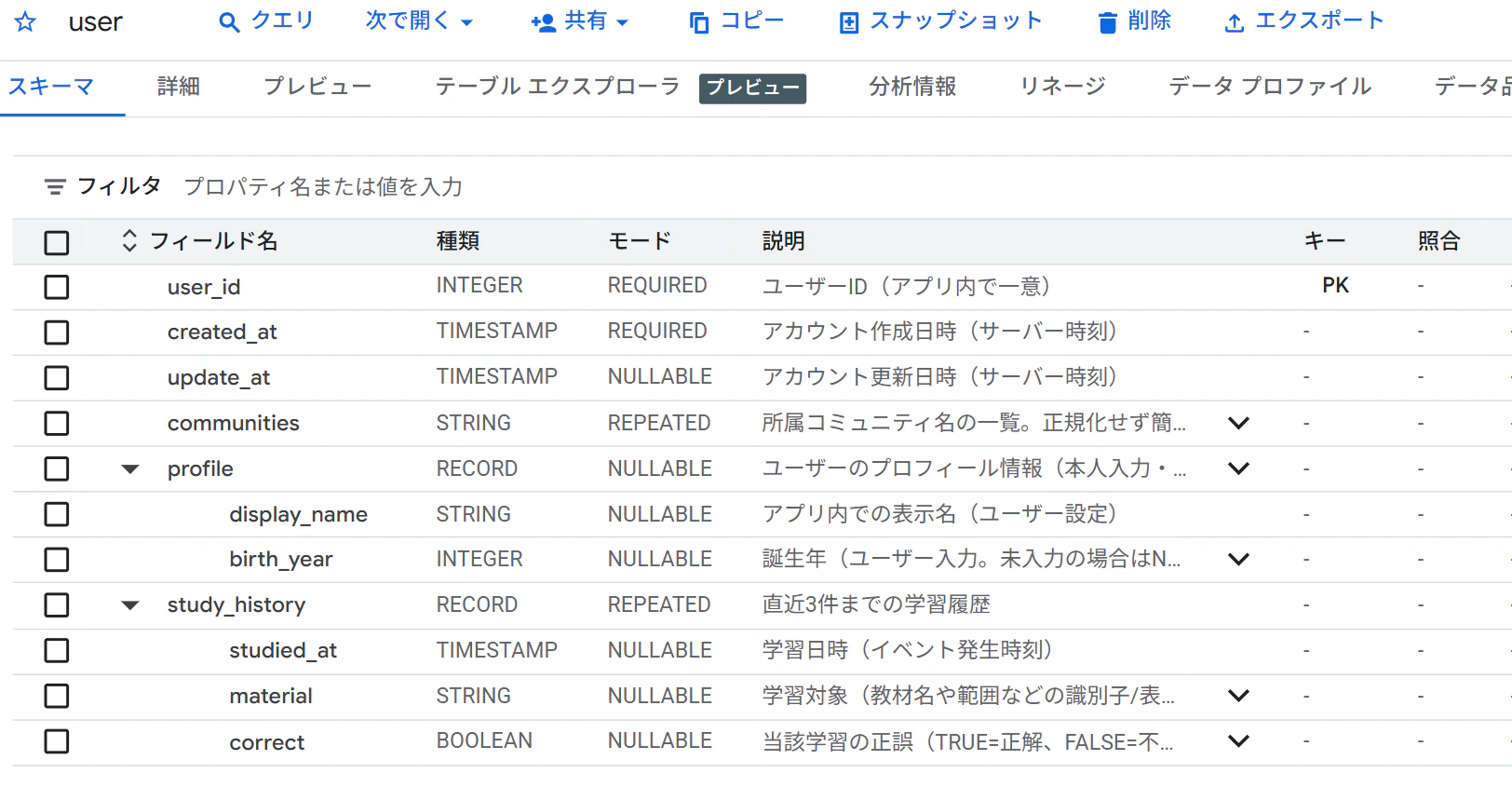
公式ドキュメントには折りたたんだ中の感じで書いてあるのですが、これをひとつずつ説明していきます。
CREATE [ OR REPLACE ] [ TEMP | TEMPORARY ] TABLE [ IF NOT EXISTS ]
table_name
[(
column | constraint_definition[, ...]
)]
[DEFAULT COLLATE collate_specification]
[PARTITION BY partition_expression]
[CLUSTER BY clustering_column_list]
[WITH CONNECTION connection_name]
[OPTIONS(table_option_list)]
[AS query_statement]
column:=
column_definition
constraint_definition:=
[primary_key]
| [[CONSTRAINT constraint_name] foreign_key, ...]
primary_key :=
PRIMARY KEY (column_name[, ...]) NOT ENFORCED
foreign_key :=
FOREIGN KEY (column_name[, ...]) foreign_reference
foreign_reference :=
REFERENCES primary_key_table(column_name[, ...]) NOT ENFORCED
基本の書き方1
CREATE OR REPLACE TABLE `sample.sample_user` (
-- カラムの記述:カラム名 型 [OPTION]
user_id INT64 OPTIONS(description = "ユーザーID")
)
OPTIONS(
-- テーブルオプションの記述:KEY=VALUE
description = "ユーザーマスタ"
)
AS
SELECT -- ※以下は適当なサンプルデータ
1 AS user_id,
;
CREATE文に、カラムの記述とテーブルオプションの記述をすることができます。
注意:カラムの順番に注意が必要です。列リスト + AS ... の両方があると、AS 側の列名は無視され、式の並び順で列リストに割り当てられます。したがって、以下のクエリはエラーが起きずに実行されてしまいます。
CREATE OR REPLACE TABLE `sample.sample_user` (
user_id INT64 OPTIONS(description = "ユーザーID"),
birth_year INT64 OPTIONS(description = "ユーザーの生年"),
)
AS
SELECT -- ※以下は適当なサンプルデータ
1997 AS birth_year,
1 AS user_id, -- 順番が逆!!!
;
意図と違うカラム名になってしまい、このテーブルを用いたクエリのバグの温床となってしまうため、注意が必要です。
なお、SELECT文のカラムの順番とDDLのカラムの順番で、型などの整合性が付かない場合はエラーが出ます。DDLでドキュメントを書くことで、「クエリを書き換えたけどドキュメントを書き換えそびれた」というよくある作業ミスを、一部は機械的に検知できることになります。

注意: OPTIONS() の中は , で終わるとエラーが出ます。カラム定義のなかはそんなことないです2。

NOT NULL の制約
各カラムに非NULLの制約をつけることができます。指定したカラムにNULLがあると、実行時にエラーとなります。
CREATE OR REPLACE TABLE `sample.sample_user` (
user_id INT64 NOT NULL OPTIONS(description="ユーザーID"),
)
AS
SELECT -- ※以下は適当なサンプルデータ
NULL AS user_id, -- NULLなので実行時にエラーとなる!!
;

なお、BigQueryではデフォルトがNULLABLEです。明示的にNULLABLEを指定することはできないので、非NULLの制約を置かない場合は何も書かないことになります。
使える型の一覧
テーブルスキーマの定義で使える型の一覧は以下に記載があります。
STRUCT/ARRAY
ネストしたカラムの定義は以下で行えます。
CREATE OR REPLACE TABLE `sample.sample_user` (
user_id INT64 OPTIONS(description="ユーザーID"),
profile STRUCT<
display_name STRING,
birth_year INT64
>,
communities ARRAY<STRING>,
)
AS
SELECT -- ※以下は適当なサンプルデータ
1 AS user_id,
STRUCT("田中 太郎" AS display_name, 2000 AS birth_year) AS profile,
["SQL", "BigQuery"] AS communities,
;
OPTIONS などの記述は、ネストしていない普通のカラムと同様にできます。
STRUCTの場合、ネストの内側・外側それぞれに対して書くことができます。
CREATE OR REPLACE TABLE `sample.sample_user` (
user_id INT64 OPTIONS(description="ユーザーID"),
profile STRUCT<
display_name STRING NOT NULL OPTIONS(description="アプリ内での表示名"), -- 内側
birth_year INT64 OPTIONS(description="誕生年(ユーザー未入力の場合NULL)")
> OPTIONS(description = "ユーザーのプロフィール情報"), -- 外側
communities ARRAY<STRING> OPTIONS(description = "所属コミュニティ名の一覧"),
)
AS
SELECT -- ※以下は適当なサンプルデータ
1 AS user_id,
STRUCT("田中 太郎" AS display_name, 2000 AS birth_year) AS profile,
["SQL", "BigQuery"] AS communities,
;

ARRAY型の列は NOT NULL をサポートしていないので以下はエラーです。また、配列要素は概念上NULLにならないので、ARRAY<INT64> と ARRAY<INT64 NOT NULL> は同等です3。

クラスタ列の指定
適切に設定されたクラスタリングは、フィルタや結合で頻繁に使う列の読み取り範囲を絞り込み、スキャン量(=コスト)と実行時間の削減に寄与します。クラスタの嬉しさについては、例えばここを参照ください:https://docs.cloud.google.com/bigquery/docs/clustered-tables?hl=ja
CREATE OR REPLACE TABLE `sample.sample_user` (
user_id INT64 OPTIONS(description = "ユーザーID"),
account_id STRING,
)
CLUSTER BY user_id
AS
SELECT -- ※以下は適当なサンプルデータ
1 AS user_id,
"hoge" AS account_id
;
「詳細」タブからクラスタを設定できたかが確認できます。

複数カラムをクラスタに指定する場合は以下の書き方になります。4つまでクラスタ列に指定できます。
CLUSTER BY user_id, account_id
-- NG: CLUSTER BY user_id account_id
-- NG: CLUSTER BY (user_id, account_id)
PKの設定
列リストの末尾に PRIMARY KEY (列名) NOT ENFORCED を記述して、PKを設定することができます。なお、VIEWの場合は設定できないようです。
CREATE OR REPLACE TABLE `sample.sample_user` (
user_id INT64 OPTIONS(description = "ユーザーID"),
account_id STRING,
PRIMARY KEY (user_id) NOT ENFORCED
)
AS
SELECT -- ※以下は適当なサンプルデータ
1 AS user_id,
"hoge" AS account_id
;
BigQuery は、強制されない主キーのみをサポートします。そのため、NOT ENFORCED は必須です。
強制はされないので、以下のようなクエリもエラーとなりません。
CREATE OR REPLACE TABLE `sample.sample_user` (
user_id INT64,
PRIMARY KEY (user_id) NOT ENFORCED
)
AS
SELECT user_id
FROM UNNEST([
STRUCT(1 AS user_id),
STRUCT(2 AS user_id),
STRUCT(1 AS user_id) -- PKに指定した列が重複している!!!
]);
検証されないのに何故ここを設定したいかというと、
- テーブルを使用する人が参考にする情報として
- 設定するとJOINが効率化される4
というメリットがあります。ただし嘘の情報になりうるので、クエリのレビューやデータの品質チェックは必要になるでしょう。
Googleもこう言ってます5
BigQuery ではキー制約は適用されません。制約を維持する責任はお客様にあります。制約に違反しているテーブルに対するクエリは、誤った結果を返すことがあります。
なお、複数列をPKに指定する場合は以下の書き方になります。僕はクラスタ列の指定との書き方の違いにハマったことが10回くらいあります。
PRIMARY KEY (user_id, account_id) NOT ENFORCED
-- NG: PRIMARY KEY user_id, account_id NOT ENFORCED
-- NG: PRIMARY KEY (user_id, account_id) -- ENFORCEDは指定できない
FKの設定
外部キーの設定も可能です。
CREATE OR REPLACE TABLE `sample.parent` (
parent_id INT64 NOT NULL,
PRIMARY KEY (parent_id) NOT ENFORCED -- 必須
)
AS
SELECT 1 AS parent_id;
CREATE OR REPLACE TABLE `sample.child` (
child_id INT64 NOT NULL,
parent_id INT64 NOT NULL,
CONSTRAINT fk_child_parent FOREIGN KEY (parent_id) REFERENCES sample.parent(parent_id) NOT ENFORCED
)
AS
SELECT
10 AS child_id,
1 AS parent_id -- sample.parent.parent_idに含まれるID
;
CONSTRAINT 句を記述して指定します。親側(上記クエリだと sample.parent.parent_id )はPKに設定されている必要があります。
こちらも扱いとしてはPKと同様に強制ではなく(つまり検証はされない)、設定するメリットもPKと同じです。
また、child.parent_id はNULLでもよいので、NOT NULLにしたければ別途設定する必要があります。

テーブルオプションの設定
テーブルに対してもDESCRIPTIONやラベルの設定ができます。
CREATE OR REPLACE TABLE `sample.sample_user` (
user_id INT64 OPTIONS(description = "ユーザーID"),
)
OPTIONS(
description = "ユーザーマスタ",
labels = [("owner", "data-team"), ("certificate", "experimental")]
)
AS
SELECT
1 AS user_id,
;
なお、ラベルには以下の制約があります
- ラベルのキーと値はそれぞれ 63 文字以内
- 使用できる文字:小文字の英字、数字、アンダースコア(_)、ダッシュ(-)
- 日本語も使用できる
- 値は省略可能
- キーは文字で始まる必要があり、リスト内の各ラベルは互いに異なるキーを持つ必要がある
BigQuery Studio上は「詳細」タブに表示されます。

その他設定できるものは以下に一覧があります。
ちなみに謎なものとして、friendly_name という項目があるのですが、単にテーブルの別名のようです。詳細タブに記載されるだけで、この名前でクエリできたりする訳ではないので、たぶんそんなに使う必要はない項目だと思われます6
その他記載できること
※目についたものだけ備忘代わりに記載します
自律型エンベディング生成
ソース列に基づいてテーブルのエンベディング列を維持できる機能がプレビューですがあるらしいです。
パーティションの設定
日本語ではこの記事などが詳しい気がします。
列レベルのマスキング
プレビューの機能かつ検証はできていないのですが、たぶんこんな感じで書けそうです。事前にdata policyの作成は必要です。
CREATE OR REPLACE TABLE `sample.sample_user` (
user_id INT64 NOT NULL,
email STRING OPTIONS(
description = "メールアドレス(機微情報)",
data_policies = [
"{'name':'myproject.region-us.data_policy_email_mask'}"
]
),
)
AS ...
Reference
-
自分にとって一番シンプルなカラムの書き方、というだけで公式にこれが基本ということが明言されているわけではない ↩
-
DDL以外でもコンマの扱いの一貫性のなさがたまにストレスポイントだったりする。
ORDER BYはダメとか。 ↩ -
https://docs.cloud.google.com/bigquery/docs/reference/standard-sql/load-statements#:~:text=as%20column%20names.-,NOT%20NULL,-%3A%20When%20the%20NOT ↩
-
https://cloud.google.com/blog/ja/products/data-analytics/join-optimizations-with-bigquery-primary-and-foreign-keys/ ↩
-
https://docs.cloud.google.com/bigquery/docs/primary-foreign-keys?hl=ja#optimize_queries ↩
-
https://stackoverflow.com/questions/51496378/practical-use-of-the-friendly-name-field-in-bigquery-views-tables ↩