機械学習におけるハイパーパラメータの最適化は,高い予測性能を実現する上で重要なステップの一つである.古くは scikit-learn などでも実装されるグリッドサーチが標準的であったが,深層学習全盛の現在ではベイズ最適化に基づく最新技術を実装したパッケージがいくつも利用可能になっている.
このハイパーパラメータ最適化を行う python パッケージとして日本で最も有名なものは,Qiitaで見る限りにおいては optuna と思われるが,おそらく全世界的に見れば Ray Tune だろう.PyTorchの公式チュートリアル にも採用されるなど,代表的なハイパーパラメータ最適化ライブラリとしての地位を確立しており,既存の学習用実装をそれほど大きく変更することなくハイパーパラメータ最適化が実現できるなどの御利益もあるが,残念なことに日本語の資源がほとんどない.
そこでこの記事では,Ray Tuneを用いた PyTorch 深層学習モデルのハイパーパラメータ最適化をどのように実装するかについて,PyTorch 公式チュートリアルよりももう少し踏み込んで 解説する.
ちなみに,Ray Tune は PyTorchだけではなく,scikit-learn・PyTorch Lightning・XGBoost・MLFlow など様々な機械学習ライブラリと併用できる.詳細は Ray Tune チュートリアル を参照.
(2023/01/30: Ray Tuneのアップデートに対応するため,ソースを大幅に改変致しました.)
全体的な流れ
ハイパーパラメータ最適化を含んでいない実装が手元にある場合には,以下の5つの改良を加えることでハイパーパラメータを最適化できる.
- 学習に関わる部分を関数として切り出す
- 最適化したいハイパーパラメータを関数の引数として与える
- 学習の途中経過を保存する処理を追加する
- ハイパーパラメータを探索する範囲を定義する
- ハイパーパラメータを探索・評価するアルゴリズムを選ぶ
以下では,上記5点をどのように実装するかを解説することになる.
インストール
pip でインストールできる.Ray Tune は Ray と呼ばれる並列分散計算用ライブラリの一部として提供されている(並列分散計算については@waffooさんの記事を参照).Rayをすべて入れると今回の目的には大きすぎるので,以下のようにして Ray Tune に必要な分のみ入れる.
$ pip install -U ray[default] ray[tune]
本稿最新版更新時点 (2023/01/30) では Ver 2.2.0 がインストールされる.anaconda の conda-forge にも似たようなパッケージはあるが,バージョンが古いことが大半なので,あまり推奨しない.
それ以外のインストールの詳細については,公式リファレンスを参照.
Ray Tune を利用する際には以下のようにすれば良い.
from ray import tune
学習部分を関数で定義
学習に関わる部分を関数 train(config, options) として定義する.引数の定義は以下の通り.
-
config: 最適化 したい ハイパーパラメータを保存した辞書.必須. -
options: 最適化 しない ハイパーパラメータを保存した辞書.なくても良い.
例えば,関数は以下のように定義しておく.今回は学習するモデルとして WideResNet を採用している.モデル実装はこの記事の一番最後に付録として掲載する.また,途中で出てくる train_loop() は学習を1エポック回す独自関数,save_model() は学習途中のモデルのパラメータを保存する独自関数,load_data()はデータセットをロードする独自関数だと思っておけば良い.これも実装は最後の付録を参照.
train関数の実装
from filelock import FileLock
from typing import Any
import torch
import torch.nn as nn
import torch.optim as optim
import torch.utils.data
from torch.utils.data import Dataset, DataLoader
from ray import tune
from ray.air import session
def train(
configs: dict[str, Any],
options: dict[str, Any]
) -> tuple[nn.Module, optim.Optimizer, list[float], list[float], list[float], list[float]]:
# load data
with FileLock(options['dataset']['dir']+'.lock'):
trainvalset, trainset, valset, testset = load_data(options['dataset']['dir'], train_val_ratio=0.9)
options['dataset']['train'] = eval(options['dataset']['train'])
options['dataset']['val'] = eval(options['dataset']['val'])
options['dataset']['test'] = eval(options['dataset']['test'])
# data loader
trainloader: DataLoader = torch.utils.data.DataLoader(
options['dataset']['train'],
batch_size=configs['batch_size'],
num_workers=options['num_workers'], shuffle=True)
valloader: DataLoader = torch.utils.data.DataLoader(
options['dataset']['val'],
batch_size=configs['batch_size'],
num_workers=options['num_workers'], shuffle=False)
# network, loss functions and optimizer
device: torch.device = torch.device(options['device'])
net: nn.Module = WideResNet(
depth=options['resnet']['depth'],
num_classes=options['num_classes'],
widen_factor=options['resnet']['widen'],
dropRate=configs['dropout_rate'],
require_intermediate=False)
net = net.to(device)
criterion: nn.Module = nn.CrossEntropyLoss()
optimizer: optim.Optimizer = optim.SGD(
net.parameters(),
lr=configs['lr_init'],
weight_decay=configs['weight_decay'],
momentum=0.9, nesterov=True)
lr_scheduler: Any = optim.lr_scheduler.StepLR(
optimizer,
step_size=configs['lr_stepsize'],
gamma=configs['lr_gamma'])
# training
train_losses: list[float] = list()
train_accs: list[float] = list()
val_losses: list[float] = list()
val_accs: list[float] = list()
for epoch in range(options['max_epochs']):
print('Epoch {}'.format(epoch+1))
# training
now_train_loss, now_train_acc = train_loop(
trainloader, net, device, optimizer, criterion, train=True, use_tqdm=False)
lr_scheduler.step()
print('Train loss={}, acc={}'.format(now_train_loss, now_train_acc))
train_losses.append(now_train_loss)
train_accs.append(now_train_acc)
# testing with validation data
now_val_loss, now_val_acc = train_loop(
valloader, net, device, optimizer, criterion, train=False, use_tqdm=False)
print('Val loss={}, accuracy={}'.format(now_val_loss, now_val_acc))
val_losses.append(now_val_loss)
val_accs.append(now_val_acc)
# checkpoints
if now_val_loss==min(val_losses):
print(options['checkpoint_dir'], epoch)
myutils.save_model(
options['checkpoint_dir'], 'checkpoint_{}.pt'.format(epoch),
net, optimizer, val_losses, val_accs,
options['max_epochs'])
# report
session.report({'loss': now_val_loss, 'accuracy': now_val_acc})
# save the final model
myutils.save_model(
options['checkpoint_dir'], 'checkpoint_final.pt',
net, optimizer, val_losses, val_accs,
options['max_epochs'])
return net, optimizer, train_losses, train_accs, val_losses, val_accs
学習ループの最後の方にある session.report({'loss': now_val_loss, 'accuracy' now_val_acc}) を除けば,特別なことは何もしていない普通通りの pytorch 学習ループとなっている.このsession.report() は,検証データでの損失や正答率など,パラメータ探索・評価アルゴリズムに渡すべき metric を報告する関数となっている.これについては後ほど説明する.
ハイパーパラメータ探索範囲の設定
ハイパーパラメータの探索範囲は,以下のように辞書として与える.
from ray import tune
config = {
'dropout_rate': tune.quniform(0.0, 0.5, 0.1),
'weight_decay': tune.qloguniform(1e-4, 1e-2, 5e-5),
'batch_size': tune.choice([32, 64, 128, 256, 512, 1024]),
'lr_init': tune.qloguniform(1e-3, 5e-1, 5e-4),
'lr_gamma': tune.quniform(0.1, 1.0, 0.1),
'lr_stepsize': tune.qrandint(10, 100, 5)
}
ここで用いたパラメータ設定関数について簡単に紹介しておく.
-
tune.quniform(lower, upper, q): lowerとupperの間の実数を間隔qでサンプリング.q間隔で量子化しない連続一様分布が欲しい場合にはtune.uniform(lower, upper)を用いる. -
tune.qloguniform(lower, upper, q): サンプリング間隔の軸が対数軸になる以外はquniform(lower, upper, q)と同じ. -
tune.choice(list): listの中からどれか一つの要素をサンプリング.上記のように数値のリストとするだけではなく,任意のリストを受け付ける.これを使えば,例えばどの optimizer にすれば良いか,などの探索もできる. -
tune.qrandint(lower, upper, q): quniformの整数バージョン.upperの値もサンプリングの対象となることに注意.こちらも uniform 同様にtune.randint(lower, upper)があるが,この randint はなぜか upperの値はサンプリングの対象にならない.
パラメータ設定関数の詳細については 公式リファレンス (Random Distribution API) で確認すると良い.
ハイパーパラメータ探索についての注意点として,深層学習モデルの層の数やカーネルのサイズなどのモデル構造探索はエラーとなる可能性が非常に高い,という点がある.全結合層のユニット数や dropout の割合などは操作できることを確認しているが,モデルそのものを変更するようなパラメータ探索は AutoML など別の手段に頼った方が良い.
最適化アルゴリズム
ハイパーパラメータパラメータの最適化は,基本的に以下のような手順で進むことになる.
- ハイパーパラメータの初期値を決める.
- 現在のハイパーパラメータで学習を少しずつ進める.
- 学習の途中結果を見て,見込みのあるハイパーパラメータなのかを判断する.見込みがなければ学習を途中で打ち切り.
- これまでの学習結果の集合を見渡して,次に学習を進めるべきハイパーパラメータを決める.
- 2に戻る.
この手順で重要となるのは,3のパラメータ評価と4のパラメータ探索.Ray Tune では,それぞれ trial schedulers (tune.schedulers) と search algorithms (tune.search) と呼ばれている.この2つの要素の選び方で探索の結果と速度は大きく変化する.
パラメータ評価 (Trial schedulers)
パラメータの評価では,学習エポックごとの損失や正答率などの絶対値や変化を確認し,見込みがないと思われるパラメータでの学習を打ち切る.
パラメータ評価アルゴリズムの一覧及び使用方法は 公式リファレンス (Trial Schedulers) で見ることができるが,以下ではそのうち代表的な3つだけ紹介する.
-
Asynchronized HyperBand - ASHA (
tune.schedulers.ASHAScheduler)- 基本的にはこれを選んでおけば間違いはないというデフォルト.
- 仮にすべての考えられるハイパーパラメータについて並列に学習ができたと考えたときに,学習ステップごとに生き残るハイパーパラメータを一定割合ずつ減らしていくようにするアルゴリズム.
- アルゴリズムの詳細は,https://arxiv.org/abs/1810.05934 を見ると良い.
- 損失を基準に,どんなにダメでも最低5エポックは学習を進め (grace_period),それ以降 $5\times 2^n$ステップごとに概ね$2^{-n}$の割合で生き残らせる (reduction_factor) ように,最大1000エポックまで学習を続ける (max_t) 場合には,以下のような感じになる.
from ray.tune.schedulers import ASHAScheduler
scheduler = ASHAScheduler(
metric='loss', mode='min', max_t=1000,
grace_period=5, reduction_factor=2)
-
Median Stopping Rule (
tune.scheduers.MedianStoppingRule)- ルールが簡単な評価アルゴリズム.
- 各学習ステップにおいて,これまで学習を進めたハイパーパラメータの結果の中央値よりも大きいかどうかを評価して,小さくなったときにはそこで打ち切る.
- 最初の10個のハイパーパラメータに対しての学習 (min_samples_required) はどんなにダメでも最後(1000エポック (max_t) )まで続け,以降は損失を基準にどんなにダメでも最低5エポックは学習を進め (grace_period),損失が中央値より下回ったら打ち切る場合には,以下のような感じになる.
from ray.tune.schedulers import MedianStoppingRule
scheduler = MedianStoppingRule(
metric='loss', mode='min', max_t=1000,
grace_period=5, min_samples_required=10)
-
Population-based training - PBT (
tune.schedulers.PopulationBasedTraining)- 現時点で良さそうなハイパーパラメータだけを生き残らせ,そのハイパーパラメータを少しだけ摂動させたコピーをいくつか作りながら探索.
- パラメータ探索もこの中に内在しているので,別途のパラメータ探索アルゴリズムの設定は不要(というかできない).
- 最適化したいハイパーパラメータの数が多い場合には,あまり有効なパラメータ探索アルゴリズムがないため,このPBTを採用することも有力な選択肢の一つとなる.
ちなみに,パラメータ評価をせずに,どのハイパーパラメータについても最後まで学習を続ける,という選択ももちろん可能.良いハイパーパラメータを見つけられる可能性は高まるが,学習時間が非常に増えてしまう.
パラメータ探索 (Search algorithms)
パラメータの探索では,これまでのハイパーパラメータとその学習経過を確認し,次に学習をした方が良さそうなハイパーパラメータを決定する.
パラメータ探索アルゴリズムの一覧及び使用方法は 公式リファレンス (Search Algorithms) で見ることができるが,以下はそのうち代表的な3つだけ紹介する.どのアルゴリズムを選ぶべきか? というガイドが FAQ に記載されているので,参考にすると良い.
-
Grid search (
tune.search.basic_variant.BasicVariantGenerator)- 探索範囲をすべてしらみ潰しに調べる.つまりパラメータ探索の意味では「何もしない」.
- 探索範囲が離散的でかつそれほど広くない場合,あるいは学習対象のモデルが小さくて最後まで学習を進めても大して時間が掛からない場合には,これでも十分.
- パラメータ探索アルゴリズムを指定しないと,自動的にこれが選択される.
-
ベイズ最適化 (
tune.search.bayesopt.BayesOptSearch)- ガウス過程を用いたベイズ最適化でパラメータ探索.
- 一般的に grid search よりも探索回数を削減することが期待できる.
- ガウス過程を利用するため,探索するハイパーパラメータの数が少ない方が望ましく,かつ探索範囲が連続的であることが望ましい.
- 別途 bayesian-optimization を pip でインストールする必要がある.
-
Optuna (
tune.search.optuna.OptunaSearch)- Optuna で採用されている探索アルゴリズム.
- ベイズ最適化が苦手にしている場合でも比較的安定かつ高速に動作する.
- 別途 optuna を pip でインストールする必要がある.
使い方はいずれも簡単で,探索評価基準となる metric(とその metric が大きい方が良いのか小さい方が良いのか)を指定すれば十分である.また,同時並列で実行する学習の数を ConcurrencyLimiter で制限することができる.
from ray.tune.search.optuna import OptunaSearch
from ray.tune.Search import ConcurrencyLimiter
search_alg = OptunaSearch(metric='loss', mode='min')
search_alg = ConcurrencyLimiter(search_alg, max_concurrent=4)
ハイパーパラメータ最適化
以降でハイパーパラメータ最適化の実際の実装を示す.実装の大枠は以下の通り.
- ハイパーパラメータの探索範囲を指定
- パラメータ探索アルゴリズムを指定
- パラメータ評価アルゴリズムを指定
- データセットを読み込み
- 最適化開始
- 結果を回収して最も良いハイパーパラメータを決定
- そのハイパーパラメータでもっと長く学習
上記の5番目の手順では,tune.Tuner() を利用する.詳細は リファレンス に譲るが,
-
num_samplesで探索試行回数(異なるハイパーパラメータの組合せを何通り試すか?) -
resourcesで1試行で利用するCPUコア数及びGPUの数
を決めておくことが重要となる.また,学習関数 train() にパラメータ探索範囲 config 以外の引数を渡さないといけない場合には,functools.partial を利用する.
from ray.air.config import RunConfig
ray_tuner: tune.Tuner = tune.Tuner(
tune.with_resources(
partial(train, options=options),
resources={'cpu': 4, 'gpu': 1},
),
tune_config=tune.TuneConfig(
scheduler=scheduler,
search_alg=search_alg,
num_samples=1000,
),
param_space=configs,
run_config=RunConfig(
name='raytune_only',
local_dir='./ray_results',
)
)
ray_result: tune.ResultGrid = ray_tuner.fit()
Reporter を用いることで,最適化の途中経過をリアルタイムで確認できる.コマンドライン版 (tune.CLIReporter) とJupyter版 (tune.JupyterNotebookReporter) がある.
from ray.tune import CLIReporter
reporter = CLIReporter(
metric_columns=['loss', 'accuracy', 'training_iteration'],
max_progress_rows=10, max_report_frequency=5)
ray_tuner: tune.Tuner = tune.Tuner(
...
run_config=RunConfig(
name='raytune_only',
local_dir='./ray_results',
progress_reporter=reporter,
)
Jupyter版の出力結果は以下のような形で表示される.コマンドライン版もほぼ同様.
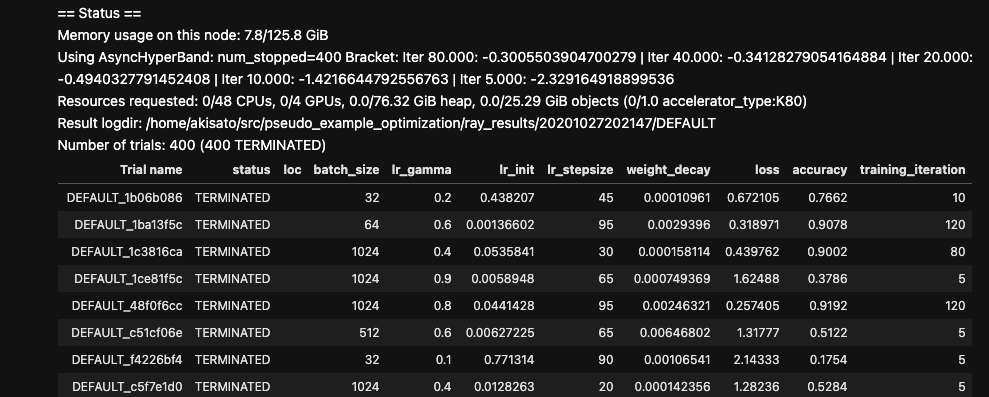
tune.Tuner.fit() の出力結果(下記ソースでは ray_result)から,最良ハイパーパラメータ及びそれを用いた学習での損失や正答率など(要は学習関数の中のsession.report()で渡されていた metric)を得ることができる.詳細はリファレンスを参照するのが良い.
from ray.air.result import Result
best_trial: Result = ray_result.get_best_result('loss', 'min', 'last')
print('Best trial config: {}'.format(best_trial.config))
print('Best trial final validation loss: {}'.format(best_trial.last_result['loss']))
print('Best trial final validation accuracy: {}'.format(best_trial.last_result['accuracy']))
ハイパーパラメータ最適化部分をまとめた全実装を以下に示す.
すべての実装
import torch
import torch.nn.functional as F
import torchvision.transforms as transforms
from torchvision.datasets import CIFAR10
import torch.utils.data
from torch.utils.data import Dataset
import os.path
class ApplyTransform(Dataset):
def __init__(self, dataset: Dataset, transform: torch.nn.Module=None, target_transform: torch.nn.Module=None):
self.dataset: Dataset = dataset
self.transform: torch.nn.Module = transform
self.target_transform: torch.nn.Module = target_transform
def __getitem__(self, idx: int) -> tuple[torch.Tensor, torch.Tensor]:
sample, target = self.dataset[idx]
if self.transform is not None:
sample: torch.Tensor = self.transform(sample)
if self.target_transform is not None:
target: torch.Tensor = self.target_transform(target)
return sample, target
def __len__(self) -> int:
return len(self.dataset)
def load_data(data_root: str='./dataset', train_val_ratio: float=0.9) -> tuple[Dataset, Dataset, Dataset, Dataset]:
dset: Dataset=CIFAR10; num_classes: int=10; num_examples: int=50000
# transforms
mean: tuple[float, float, float] = (0.4914, 0.4822, 0.4465)
std: tuple[float, float, float] = (0.2023, 0.1994, 0.2010)
transform_train: torch.nn.Module = transforms.Compose([
transforms.ToTensor(),
transforms.Lambda(lambda x: F.pad(x.unsqueeze(0), (4, 4, 4, 4), mode='reflect').squeeze()),
transforms.ToPILImage(),
transforms.RandomCrop(32),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
transforms.Normalize( mean, std )
])
transform_test: torch.nn.Module = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize( mean, std )
])
# datasets
trainvalset: Dataset = dset(
root=data_root, train=True, download=True, transform=None)
testset: Dataset = dset(
root=data_root, train=False, download=True, transform=transform_test)
num_examples_train: int = int(len(trainvalset)*train_val_ratio)
num_examples_val: int = int(len(trainvalset)) - num_examples_train
trainset, valset = torch.utils.data.random_split(
trainvalset, [num_examples_train, num_examples_val] )
# transformations, including several data augmentations for training
trainvalset: Dataset = ApplyTransform(trainvalset, transform=transform_train)
trainset: Dataset = ApplyTransform(trainset, transform=transform_train)
valset: Dataset = ApplyTransform(valset, transform=transform_test)
#
return trainvalset, trainset, valset, testset
def save_model(save_dir: str, filename: str, net: torch.nn.Module, optimizer: torch.optim.Optimizer,
losses: list[float], accs: list[float], num_epochs: int) -> None:
path: str = os.path.join(save_dir, filename)
torch.save({
'epoch': num_epochs,
'model_state_dict': net.state_dict(),
'optimizer_state_dict': optimizer.state_dict(),
'val_loss': losses[-1],
'val_accs': accs[-1],
}, path)
import math
## ResNet basic block
class BasicBlock(nn.Module):
def __init__(self, in_ch: int, out_ch: int, stride: int=1, drop_rate: float=0.3, kernel_size: int=3):
super(BasicBlock, self).__init__()
self.in_is_out: bool = (in_ch==out_ch and stride==1)
self.drop_rate: float = drop_rate
self.shortcut: torch.nn.Module = nn.Conv2d(in_ch, out_ch, 1, stride=stride, padding=0, bias=False)
self.bn1: torch.nn.Module = nn.BatchNorm2d(in_ch)
self.c1: torch.nn.Module = nn.Conv2d(in_ch, out_ch, kernel_size, stride=stride, padding=1, bias=False)
self.bn2: torch.nn.Module = nn.BatchNorm2d(out_ch)
self.c2: torch.nn.Module = nn.Conv2d(out_ch, out_ch, kernel_size, stride=1, padding=1, bias=False)
def forward(self, x: torch.Tensor) -> torch.Tensor:
# steps: BN, ReLU, Conv, BN, ReLU, DropOut, Conv, shortcut plus
if self.in_is_out:
h = F.relu(self.bn1(x), inplace=True)
h = self.c1(h)
else:
x = F.relu(self.bn1(x), inplace=True)
h = self.c1(x)
h = F.relu(self.bn2(h), inplace=True)
if self.drop_rate > 0:
h = F.dropout(h, p=self.drop_rate, training=self.training)
h = self.c2(h)
return torch.add(x if self.in_is_out else self.shortcut(x), h)
## a sequence of ResNet blocks, each of which is a copy of a given 'block'
class NetworkBlock(nn.Module):
def __init__(self, nb_layers, in_planes, out_planes, block, stride, dropRate=0.0):
super(NetworkBlock, self).__init__()
# a single building block ('block' is supposed to be an instance of BasicBlock class)
self.layer = self._make_layer(block, in_planes, out_planes, nb_layers, stride, dropRate)
def _make_layer(self, block, in_planes, out_planes, nb_layers, stride, dropRate):
# stack #nb_layers copys of a given building block
layers = []
for i in range(int(nb_layers)):
layers.append(block(i==0 and in_planes or out_planes, out_planes, i==0 and stride or 1, dropRate))
return nn.Sequential(*layers)
def forward(self, x):
return self.layer(x)
## Wide ResNet
class WideResNet(nn.Module):
def __init__(self, depth, num_classes, widen_factor=1, dropRate=0.0, require_intermediate=False):
super(WideResNet, self).__init__()
self.require_intermediate = require_intermediate
# definition of #channels
nChannels = [16, 16*widen_factor, 32*widen_factor, 64*widen_factor]
# depth (= #layers in total) should satisfy the following constraint
assert((depth - 4) % 6 == 0)
# n = #stacks in each block
n = (depth - 4) / 6
block = BasicBlock
# 1st conv before any network block
self.conv1 = nn.Conv2d(3, nChannels[0], kernel_size=3, stride=1, padding=1, bias=False)
# 1st block
self.block1 = NetworkBlock(n, nChannels[0], nChannels[1], block, 1, dropRate)
# 2nd block
self.block2 = NetworkBlock(n, nChannels[1], nChannels[2], block, 2, dropRate)
# 3rd block
self.block3 = NetworkBlock(n, nChannels[2], nChannels[3], block, 2, dropRate)
# global average pooling and classifier
self.bn1 = nn.BatchNorm2d(nChannels[-1])
self.relu = nn.ReLU(inplace=True)
self.fc = nn.Linear(nChannels[-1], num_classes)
self.nChannels = nChannels[-1]
# module initialization
for m in self.modules():
if isinstance(m, nn.Conv2d):
n = m.kernel_size[0] * m.kernel_size[1] * m.out_channels
m.weight.data.normal_(0, math.sqrt(2. / n))
elif isinstance(m, nn.BatchNorm2d):
m.weight.data.fill_(1)
m.bias.data.zero_()
elif isinstance(m, nn.Linear):
m.bias.data.zero_()
def forward(self, x):
# 1st conv before Res Block
out = self.conv1(x)
# 1st block
out = self.block1(out)
activation1 = out
# 2nd block
out = self.block2(out)
activation2 = out
# 3rd block
out = self.block3(out)
activation3 = out
# ReLU, AvgPooling & FC for classification finally
out = self.relu(self.bn1(out))
out = F.avg_pool2d(out, 8)
out = out.view(-1, self.nChannels)
if self.require_intermediate:
return self.fc(out), activation1, activation2, activation3
else:
return self.fc(out)
from typing import Any, Callable
import os
from tqdm import tqdm
from filelock import FileLock
import torch
from torch import Tensor
import torch.nn as nn
import torch.optim as optim
import torch.utils.data
from torch.utils.data import DataLoader
import ray
from ray import tune
from ray.air import session
from ray.air.result import Result
from ray.air.config import RunConfig
from ray.tune import CLIReporter
from ray.tune.search.optuna import OptunaSearch
from ray.tune.search import ConcurrencyLimiter, Searcher
from ray.tune.schedulers import ASHAScheduler
from functools import partial
import mymodels
import myutils
def common_step(net: nn.Module, inputs: Tensor, labels: Tensor,
device: torch.device, optimizer: optim.Optimizer, criterion: nn.Module) -> tuple[Tensor, Tensor]:
inputs, labels = inputs.to(device), labels.to(device)
optimizer.zero_grad()
outputs: Tensor = net(inputs)
loss: Tensor = criterion(outputs, labels)
return outputs, loss
def test_step(net: nn.Module, inputs: Tensor, labels: Tensor,
device: torch.device, optimizer: optim.Optimizer, criterion: nn.Module) -> tuple[float, Tensor, int]:
with torch.no_grad():
outputs, loss = common_step(net, inputs, labels, device, optimizer, criterion)
loss_value = loss.item()
_, predicted = torch.max(outputs.data, 1)
correct = (predicted==labels.to(device)).sum().item()
return loss_value, predicted, correct
def train_step(net: nn.Module, inputs: Tensor, labels: Tensor,
device: torch.device, optimizer: optim.Optimizer, criterion: nn.Module) -> tuple[float, Tensor, int]:
outputs, loss = common_step(net, inputs, labels, device, optimizer, criterion)
loss.backward()
optimizer.step()
loss_value: float = loss.item()
_, predicted = torch.max(outputs.data, 1)
correct: int = (predicted==labels.to(device)).sum().item()
return loss_value, predicted, correct
def train_loop(loader: DataLoader, net: nn.Module, device: torch.device, optimizer: optim.Optimizer,
criterion: nn.Module, lr_scheduler: Any=None, train: bool=True, use_tqdm: bool=True) -> tuple[float, float]:
sum_loss: float = 0.0; sum_correct: float = 0; sum_total: float = 0
step: Callable = train_step if train else test_step
if not train: net.eval()
loader_loop: DataLoader = tqdm(loader) if use_tqdm else loader
for (inputs, labels) in loader_loop:
loss_value, _, correct = step(net, inputs, labels, device, optimizer, criterion)
sum_loss += (loss_value * labels.size(0))
sum_total += labels.size(0)
sum_correct += correct
if train: lr_scheduler.step()
if not train: net.train()
now_train_loss: float = sum_loss/sum_total
now_train_acc: float = sum_correct/float(sum_total)
return now_train_loss, now_train_acc
def train(
configs: dict[str, Any],
options: dict[str, Any]
) -> tuple[nn.Module, optim.Optimizer, list[float], list[float], list[float], list[float]]:
# load data
with FileLock(options['dataset']['dir']+'.lock'):
trainvalset, trainset, valset, testset = myutils.load_data(options['dataset']['dir'], train_val_ratio=0.9)
options['dataset']['train'] = eval(options['dataset']['train'])
options['dataset']['val'] = eval(options['dataset']['val'])
options['dataset']['test'] = eval(options['dataset']['test'])
# data loader
trainloader: DataLoader = torch.utils.data.DataLoader(
options['dataset']['train'],
batch_size=configs['batch_size'],
num_workers=options['num_workers'], shuffle=True)
valloader: DataLoader = torch.utils.data.DataLoader(
options['dataset']['val'],
batch_size=configs['batch_size'],
num_workers=options['num_workers'], shuffle=False)
# network, loss functions and optimizer
device: torch.device = torch.device(options['device'])
net: nn.Module = mymodels.WideResNet(
depth=options['resnet']['depth'],
num_classes=options['num_classes'],
widen_factor=options['resnet']['widen'],
dropRate=configs['dropout_rate'],
require_intermediate=False)
net = net.to(device)
criterion: nn.Module = nn.CrossEntropyLoss()
optimizer: optim.Optimizer = optim.SGD(
net.parameters(),
lr=configs['lr_init'],
weight_decay=configs['weight_decay'],
momentum=0.9, nesterov=True)
lr_scheduler: Any = optim.lr_scheduler.StepLR(
optimizer,
step_size=configs['lr_stepsize'],
gamma=configs['lr_gamma'])
# training
train_losses: list[float] = list()
train_accs: list[float] = list()
val_losses: list[float] = list()
val_accs: list[float] = list()
for epoch in range(options['max_epochs']):
print('Epoch {}'.format(epoch+1))
# training
now_train_loss, now_train_acc = train_loop(
trainloader, net, device, optimizer, criterion, lr_scheduler, train=True, use_tqdm=False)
print('Train loss={}, acc={}'.format(now_train_loss, now_train_acc))
train_losses.append(now_train_loss)
train_accs.append(now_train_acc)
# testing with validation data
now_val_loss, now_val_acc = train_loop(
valloader, net, device, optimizer, criterion, train=False, use_tqdm=False)
print('Val loss={}, accuracy={}'.format(now_val_loss, now_val_acc))
val_losses.append(now_val_loss)
val_accs.append(now_val_acc)
# checkpoints
if now_val_loss==min(val_losses):
print(options['checkpoint_dir'], epoch)
myutils.save_model(
options['checkpoint_dir'], 'checkpoint_{}.pt'.format(epoch),
net, optimizer, val_losses, val_accs,
options['max_epochs'])
# report
session.report({'loss': now_val_loss, 'accuracy': now_val_acc})
# save the final model
myutils.save_model(
options['checkpoint_dir'], 'checkpoint_final.pt',
net, optimizer, val_losses, val_accs,
options['max_epochs'])
return net, optimizer, train_losses, train_accs, val_losses, val_accs
# initializing ray
ray.init(num_cpus=16, num_gpus=2)
# hyper-parameter configurations
configs: dict[str, Any] = {
'dropout_rate': tune.quniform(0.0, 0.5, 0.1),
'weight_decay': tune.qloguniform(1e-4, 1e-2, 5e-5),
'batch_size': tune.choice([32, 64, 128, 256, 512, 1024]),
'lr_init': tune.qloguniform(1e-3, 5e-1, 5e-4),
'lr_gamma': tune.quniform(0.1, 1.0, 0.1),
'lr_stepsize': tune.qrandint(10, 100, 5)
}
options: dict[str, Any] = {
'dataset': {'dir': os.getcwd()+'/dataset', 'train': 'trainset', 'val': 'valset', 'test': 'testset'},
'num_workers': 1, 'device': 'cuda', 'num_classes': 10,
'resnet': {'depth': 40, 'widen': 2},
'max_epochs': 120, 'checkpoint_dir': os.getcwd()+'/checkpoints',
}
# scheduler
scheduler: Any = ASHAScheduler(
metric='loss', mode='min', max_t=options['max_epochs'],
grace_period=5, reduction_factor=2)
# search algorithm
search_alg: Searcher = OptunaSearch(metric='loss', mode='min')
search_alg = ConcurrencyLimiter(search_alg, max_concurrent=4)
# Progress reporter
reporter: CLIReporter = CLIReporter(
metric_columns=['loss', 'accuracy', 'training_iteration'],
max_progress_rows=5, max_report_frequency=5)
# optimization
ray_tuner: tune.Tuner = tune.Tuner(
tune.with_resources(
partial(train, options=options),
resources={'cpu': 4, 'gpu': 1},
),
tune_config=tune.TuneConfig(
scheduler=scheduler,
search_alg=search_alg,
num_samples=1000,
),
param_space=configs,
run_config=RunConfig(
name='raytune_only',
local_dir='./ray_results',
)
)
ray_result: tune.ResultGrid = ray_tuner.fit()
# showing best result
best_trial: Result = ray_result.get_best_result('loss', 'min', 'last')
print('Best trial config: {}'.format(best_trial.config))
print('Best trial final validation loss: {}'.format(best_trial.metrics['loss']))
print('Best trial final validation accuracy: {}'.format(best_trial.metrics['accuracy']))
# training with train+val set and best configuration
trainvalset, trainset, valset, testset = myutils.load_data('./dataset', train_val_ratio=0.9)
options['datasets'] = {'train': trainvalset, 'val': testset}
net, optimizer, train_losses, train_accs, test_losses, test_accs = train(best_trial.config, options=options)
print('Best trial test set accuracy: {}'.format(test_accs[-1]))
# Save the final model
myutils.save_model('./model', 'model_final.pt', net, optimizer, test_losses, test_accs, options['max_epochs'])
最適化結果の可視化
Optuna とは異なり,Ray Tune にはそれ自身に可視化のツールが含まれていない.可視化をするにはWeights & Biases (wandb) を利用する.
wandbセットアップの方法の詳細については公式ガイドに譲るが,pip で wandb をインストールし, https://wandb.ai のSign upでアカウントを作成すればOK.個人利用であれば無料で利用できる.
Ray Tune で実装したハイパーパラメータ最適化に wandb を組み込むためには,
- 環境変数 WANDB_API_KEY に API key を設定
-
session.report()で渡している結果をwandb.log()を用いて同様に渡す -
tune.Tuner()に渡す RunConfig に wandb を初期化するためのいくつかの変数を追加
実装の概要としては以下のような形.API keyは wandb のサイトにログオンした後に Settings https://wandb.ai/settings で確認できる.また, project については,あらかじめ wandb のサイトで作成しておき,その名前を指定する.
from ray import tune
from ray.air.integrations.wandb import WandbLoggerCallback
import wandb
import os
def train(config, options):
...
tune.report(loss=now_val_loss, accuracy=now_val_acc)
wandb.log({'loss': now_val_loss, 'acc': now_val_acc})
os.environ['WANDB_API_KEY'] = 'put_your_api_key_text_here'
ray_tuner: tune.Tuner = tune.Tuner(
...
run_config: RunConfig(
...
# wandb configurations
callbacks = [
WandbLoggerCallback(project='Any_name_you_can_designate')
]
)
)
上記のように実装を修正して最適化を実行すると, wandb サイトの自分自身が指定したプロジェクトのページで,リアルタイムに最適化の進行状況を可視化できる.
wandb の可視化のサンプルは https://wandb.ai/carey/pytorch-sweep から確認できる.以下は引用画像.
自分のプロジェクトへどのように適用するかのイメージをつけるには,サンプルColabNotebook を確認すると良い.
より詳細な Ray Tune と wandb との統合については,YouTube動画,Ray Tune側のドキュメント や wandb側のドキュメントを参照.