機械学習・深層学習において,実験条件(モデル・ハイパーパラメータ・損失関数 など)とそれに対応する実験結果(予測性能・損失の経時変化・CPU/GPU/RAM 利用率 など)を適切に管理する「実験管理」は,非常に重要です.特に以下のような場面において,実験管理が重要となります.
- 実験再現: 以前に実施した実験の条件を取り出して実験結果を再現
- 複数実験条件比較: どちらの条件がより望ましい予測性能を得られるかを比較
- ハイパーパラメータ感度調査: ハイパーパラメータの変動に対して予測性能がどの程度変化するかを調べる
- ハイパーパラメータ探索: 高い予測性能が得られるハイパーパラメータを探す
実験管理を行うツールはいくつか知られており,そのうちの1つである Weights & Biases については 以前の記事 で非常に簡単に紹介しましたが,今回はその中でも Neptune.ai にについて紹介します.
Neptune.ai とは何か? から始まり,とりあえず動かすところから,自身の既存のモデル学習実装への取り込み方,さらにはハイパーパラメータ探索での利用まで,紹介できればと思います.
何ができるか?
Neptune.ai は前述の通り,実験条件とそれに対応する実験結果とをまとめて適切に管理する,実験管理ツールの一つです.
- 実験で設定したパラメータ と それに対応する結果(各種指標) と一箇所にまとめて比較できるようにするツールです.
- 他の類似ツールとして,MLflow,Weights & Biases などがあります.それらとの比較については,@fam_taro さんの記事 を参照すると良いです.
「何ができるか?」を理解するには,ユーザ登録直後に出てくる tour contents でわかりやすいと思います.そのため,まずは先にユーザー登録をします.
まずはユーザ登録
公式ページ https://neptune.ai から “Stat logging for free” もしくは “Sign up” で進めば,ユーザ登録ができます.個人で利用するのであれば,商用・非商用にかかわらず無料で利用できます.
- チームでプロジェクトや結果を共有したい場合には,一定程度の課金が必要です.詳細は https://neptune.ai/pricing を参照.
- 大学等公的研究機関の学術利用 および Kaggle利用は,無料でストレージ以外無制限のアカウントを使えるようです.https://neptune.ai/researchers
- また,個人利用の場合には,実験結果を観測できるのは 1ヶ月当たり延べ200時間(8日と1/3)までという制約があります.大規模なハイパーパラメータ探索を行うと,同時刻に複数の観測を行う必要が出るため,思っているよりもあっという間に使い切る可能性があります.
- さらに,ストレージ 100GBまでという制約があります.後述の通り,ソースやモデル,入力データなども保存できたりするので,使い方次第ではストレージ容量が足かせになるかもしれません.
ユーザ登録をしたあとで,右側にメッセージが出てきます.ここで,自分の手持ちのソースにどのように組み込むかの簡単なチュートリアルが含まれています.これを見るだけで,使える人は使えると思います.
Start managing your model building metadata in minutes!
Create a free account
Install Neptune client library
pip install neptune-client
- Add logging to your script
import neptune.new as neptune run = neptune.init_run(project='', api_token='')# your credentials run["JIRA"] = "NPT-952" run["parameters"] = {"learning_rate": 0.001, "optimizer": "Adam"} run["f1_score"] = 0.66
ツアーコンテンツを眺める
Tour contents として,プロジェクト example-project-tensorflow-keras ができています.ツアーでは,この内容を指示に従って眺めながら,「Neptune.ai で何ができるか?」を教えてくれます.
- 一般的な実験管理ツールと同様,1回分の実験 (run) を単位として,その際に利用したパラメータと対応する結果を一覧で表示できます.
- 中の見た目は,以前紹介した Weights & Biases によく似ています.

- 中の見た目は,以前紹介した Weights & Biases によく似ています.
- Runs のフィルタやソートは表の上で実施できます.

- 個別の run をクリックすると,run単独での各種情報を詳細に確認できます.

- Run 情報の中には,CPU・GPU利用率や各メモリの利用率,標準出力やエラー出力も含まれています.

- Run に対応する実験で利用したメインのソースコードも確認できます.

- 左側の Compare runs を選択すると,複数の runs を比較して見ることができます.
- 左袖の Runs table で比較したい runs を visible にする(目のマークのスラッシュを消す)と,比較対象として選択できます.
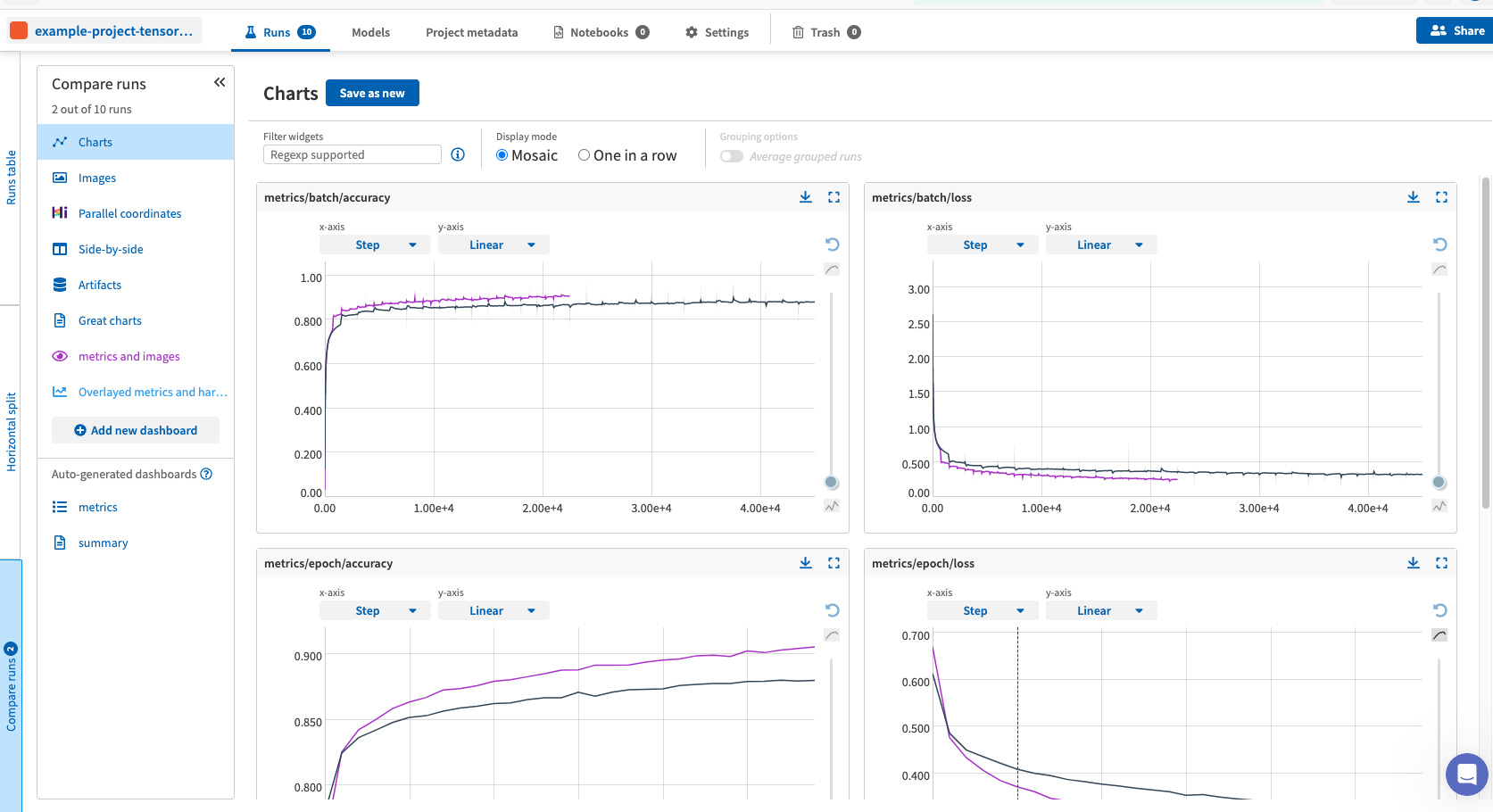
- 左袖の Runs table で比較したい runs を visible にする(目のマークのスラッシュを消す)と,比較対象として選択できます.
- 新しいプロジェクトを作ろうとすると,メジャーどころのライブラリでどのように組み込むかの情報が出てくる.
- tensorflow/Keras,pytorch,lightning,scikit-learn,optuna,XGBoost などなど
- そのまま動くサンプルコードが出てきますので,これを手始めに進めていくのが良いと思います.

ひとまず動かしてみる
ツアーで表示されたサンプルコードをまずは動かしてみて,どのようになるかを確かめてみます.
必要パッケージのインストール
-
neptune のインストールは pip でも conda でもできます
- ただし,conda-forge の方が少しだけバージョンが遅れていることが多いので,最新版が必要な方は pip でインストールする方が良いと思います.
# conda install conda install -c conda-forge neptune-client # pip install pip install neptune-client
サンプルソースを動かしてみる
ツアーで出てきたサンプルソースを動かしてみます.
サンプルソース全文
import torch
import torch.nn as nn
import torch.optim as optim
from torchvision import datasets, transforms
import neptune.new as neptune
run = neptune.init_run(
project="[your username]/[your project name]",
api_token="[your API token]",
)
params = {
"lr": 1e-2,
"bs": 128,
"input_sz": 32 * 32 * 3,
"n_classes": 10,
}
run["parameters"] = params
transform = transforms.Compose(
[
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225]),
]
)
trainset = datasets.CIFAR10("./data", transform=transform, download=True)
trainloader = torch.utils.data.DataLoader(
trainset, batch_size=params["bs"], shuffle=True
)
class BaseModel(nn.Module):
def __init__(self, input_sz, hidden_dim, n_classes):
super(BaseModel, self).__init__()
self.main = nn.Sequential(
nn.Linear(input_sz, hidden_dim * 2),
nn.ReLU(),
nn.Linear(hidden_dim * 2, hidden_dim),
nn.ReLU(),
nn.Linear(hidden_dim, hidden_dim // 2),
nn.ReLU(),
nn.Linear(hidden_dim // 2, n_classes),
)
def forward(self, input):
x = input.view(-1, 32 * 32 * 3)
return self.main(x)
device = torch.device("cuda")
model = BaseModel(params["input_sz"], params["input_sz"], params["n_classes"])
model.to(device)
criterion = nn.CrossEntropyLoss()
optimizer = optim.SGD(model.parameters(), lr=params["lr"])
for i, (x, y) in enumerate(trainloader, 0):
x, y = x.to(device), y.to(device)
optimizer.zero_grad()
outputs = model.forward(x)
_, preds = torch.max(outputs, 1)
loss = criterion(outputs, y)
acc = (torch.sum(preds == y.data)) / len(x)
run["train/batch/loss"].append(loss)
run["train/batch/acc"].append(acc)
loss.backward()
optimizer.step()
model.eval()
correct = 0
for X, y in trainloader:
X, y = X.to(device), y.to(device)
pred = model(X)
correct += (pred.argmax(1) == y).type(torch.float).sum().item()
run["valid/acc"] = correct / len(trainloader.dataset)
run.stop()
まず,python ソースを自分の環境に合わせて改変します.サンプルソースの中で,動作を理解するポイントとなる部分について追加で説明します.
-
neptune 初期設定
-
Project name と API token は最低限設定する必要があります.
-
ただし,ソースコードも neptune.ai に引き抜かれるので,特に結果を他人と共有する場合などには API token をソースに直書きしない方が良いと思います.その方法の一つは後ほど記載.
import neptune.new as neptune run = neptune.init_run( project = "[user name]/[project name]", api_token = "[API token]" )
-
-
Run ごとに変動させるパラメータ
-
以下のように dict で設定 して run に渡します.
params = { "lr": 1e-2, # learning rate "bs": 128, # batch size "input_sz": 32*32*3, # input size (width * height * channels) "n_classess": 10, # number of classes } run["parameters"] = params
-
-
Run での実験結果指標
-
以下のようにして,モデル学習の iteration ごとに loss や 正答率 などの結果を run に送り込みます.
for _ in trainloader: run["train/batch/loss"].append(train_loss) run["train/batch/acc"].append(train_acc) run["val/batch/loss"].append(val_loss) run["val/batch/acc"].append(val_acc)
-
-
その他
-
neptune.init_run で作成した run オブジェクトは,通常の dict と同様に利用できると考えて問題ありません.
- そのため,key や value に対しての制約はほぼないと思って良いと思います.
- 先ほどの結果送付のように,スラッシュを利用して階層構造を作ることもできます.
run["hogera/fugera"] = "hogehoge"
-
ここまでできたら,ソースを実行します.そうすると,結果が自動的に neptune の指定したプロジェクトに送り込まれます.プロジェクトの中で実行結果を確認すれば,動作を確認できるはずです.(下の図の例では,同じソースを3回実行しています.1回のときは1行のみが表示されます.)
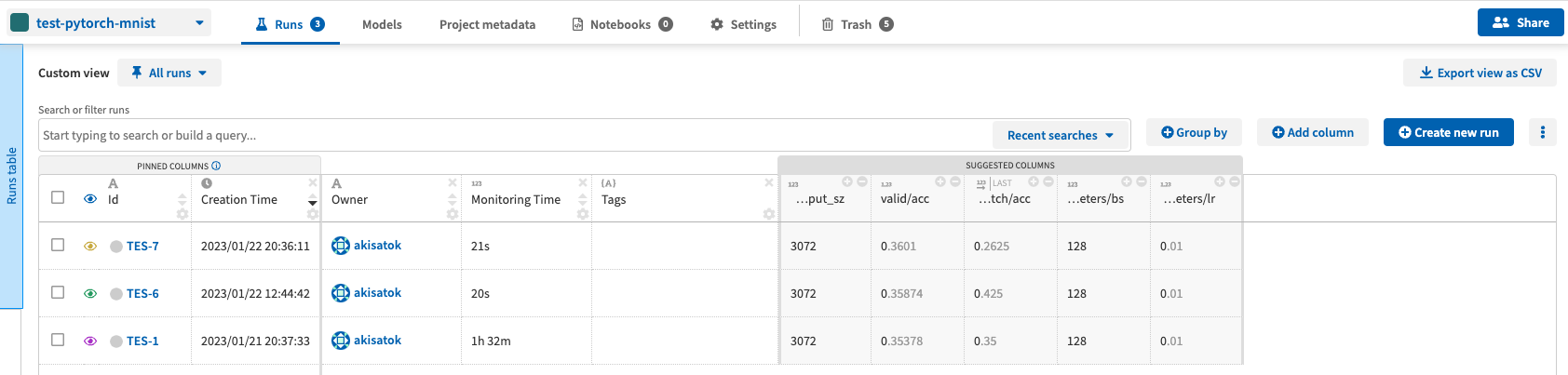
PyTorch 既存実装への組み込み
ここまでで,ひとまず Neptune.ai がどのように動いているかの雰囲気は感じられたかと思います.以降では,PyTorch での手持ちの実装をどのように Neptune.ai へ取り込むか? について紹介します.
Neptune 組み込み前の実装
例として用いるソースは GitHub にアップしました. → https://github.com/akisatok/neptune-test
ここでは,以降の説明で必要となるメインスクリプトのみ折りたたんで記載します.
メインスクリプト → main_no_neptune.py
from tqdm import tqdm
import os
from typing import Any, Callable
import hydra
from omegaconf import OmegaConf, DictConfig
import torch
from torch import Tensor
import torch.nn as nn
import torch.optim as optim
import torch.utils.data
from torch.utils.data import Dataset, DataLoader
import myutils
import mymodels
def common_step(net: nn.Module, inputs: Tensor, labels: Tensor,
device: torch.device, optimizer: optim.Optimizer,
criterion: nn.Module) -> tuple[Tensor, Tensor]:
inputs, labels = inputs.to(device), labels.to(device)
optimizer.zero_grad()
outputs: Tensor = net(inputs)
loss: Tensor = criterion(outputs, labels)
return outputs, loss
def test_step(net: nn.Module, inputs: Tensor, labels: Tensor,
device: torch.device, optimizer: optim.Optimizer,
criterion: nn.Module) -> tuple[float, Tensor, int]:
with torch.no_grad():
outputs, loss = common_step(
net, inputs, labels, device, optimizer, criterion)
loss_value: float = loss.item()
_, predicted = torch.max(outputs.data, 1)
correct: int = (predicted==labels.to(device)).sum().item()
return loss_value, predicted, correct
def train_step(net: nn.Module, inputs: Tensor, labels: Tensor,
device: torch.device, optimizer: optim.Optimizer,
criterion: nn.Module) -> tuple[float, Tensor, int]:
outputs, loss = common_step(
net, inputs, labels, device, optimizer, criterion)
loss.backward()
optimizer.step()
loss_value: float = loss.item()
_, predicted = torch.max(outputs.data, 1)
correct: int = (predicted==labels.to(device)).sum().item()
return loss_value, predicted, correct
def train_loop(loader: DataLoader, net: nn.Module,
device: torch.device, optimizer: optim.Optimizer,
criterion: nn.Module, lr_scheduler: Any=None,
train: bool=True, use_tqdm: bool=True) -> tuple[float, float]:
sum_loss: float = 0.0; sum_correct: float = 0; sum_total: float = 0
step: Callable = train_step if train else test_step
if not train: net.eval()
loader_loop: DataLoader = tqdm(loader) if use_tqdm else loader
for (inputs, labels) in loader_loop:
loss_value, _, correct = step(
net, inputs, labels, device, optimizer, criterion)
sum_loss += (loss_value * labels.size(0))
sum_total += labels.size(0)
sum_correct += correct
if train: lr_scheduler.step()
if not train: net.train()
now_train_loss: float = sum_loss/sum_total
now_train_acc: float = sum_correct/float(sum_total)
return now_train_loss, now_train_acc
def train(configs: dict[str, Any], options: dict[str, Any],
) -> tuple[nn.Module, optim.Optimizer, list[float], list[float], list[float], list[float]]:
# load data
trainvalset, trainset, valset, testset = myutils.load_data(
options['dataset']['dir'],
train_val_ratio=options['dataset']['train_val_ratio'])
options['dataset']['train']: Dataset = eval(options['dataset']['train'])
options['dataset']['val']: Dataset = eval(options['dataset']['val'])
options['dataset']['test']: Dataset = eval(options['dataset']['test'])
# data loader
trainloader: DataLoader = DataLoader(
options['dataset']['train'],
batch_size=configs['batch_size'],
num_workers=options['num_workers'], shuffle=True)
valloader: DataLoader = DataLoader(
options['dataset']['val'],
batch_size=configs['batch_size'],
num_workers=options['num_workers'], shuffle=False)
# network, loss functions and optimizer
device: torch.device = torch.device(options['device'])
net: nn.Module = mymodels.WideResNet(
depth=options['resnet']['depth'],
num_classes=options['num_classes'],
widen_factor=options['resnet']['widen'],
dropRate=configs['dropout_rate'],
require_intermediate=False)
net = net.to(device)
criterion: nn.Module = nn.CrossEntropyLoss()
optimizer: optim.Optimizer = optim.SGD(
net.parameters(),
lr=configs['lr_init'],
weight_decay=configs['weight_decay'],
momentum=0.9, nesterov=True)
lr_scheduler: Any = optim.lr_scheduler.StepLR(
optimizer,
step_size=configs['lr_stepsize'],
gamma=configs['lr_gamma'])
# training
train_losses: list[float] = list()
train_accs: list[float] = list()
val_losses: list[float] = list()
val_accs: list[float] = list()
for epoch in range(options.max_epochs):
print('Epoch {}'.format(epoch+1))
# training
now_train_loss, now_train_acc = train_loop(
trainloader, net, device, optimizer, criterion,
lr_scheduler=lr_scheduler, train=True,
use_tqdm=options['use_tqdm'])
print('Train loss={}, acc={}'.format(now_train_loss, now_train_acc))
train_losses.append(now_train_loss)
train_accs.append(now_train_acc)
# testing with validation data
now_val_loss, now_val_acc = train_loop(
valloader, net, device, optimizer, criterion,
lr_scheduler=lr_scheduler, train=False,
use_tqdm=options['use_tqdm'])
print('Val loss={}, accuracy={}'.format(now_val_loss, now_val_acc))
val_losses.append(now_val_loss)
val_accs.append(now_val_acc)
# checkpoints
if now_val_loss==min(val_losses):
myutils.save_model(
options['checkpoint_dir'], 'checkpoint_{}.pt'.format(epoch),
net, optimizer, val_losses, val_accs, epoch)
# save the final model
myutils.save_model(
options['checkpoint_dir'], 'checkpoint_final.pt',
net, optimizer, val_losses, val_accs,
options.max_epochs)
return net, optimizer, train_losses, train_accs, val_losses, val_accs
# main function
@hydra.main(version_base=None, config_path='hydra_conf',
config_name='neptune_test')
def main(cfg: DictConfig) -> None:
# configs and options
options: dict[str, Any] = OmegaConf.to_container(cfg.options)
configs: dict[str, Any] = OmegaConf.to_container(cfg.configs)
# settting dafault options
options['dataset']['dir'] = os.getcwd() + '/dataset'
options['checkpoint_dir'] = os.getcwd() + '/checkpoints'
# optimization
ret: tuple = train(configs, options=options)
train_losses, train_accs, test_losses, test_accs = ret[2:]
# showing the result
print('Current trial config: {}'.format(configs))
print('Current trial final train loss: {}'.format(train_losses))
print('Current trial final train accuracy: {}'.format(train_accs))
print('Current trial final test loss: {}'.format(test_losses))
print('Current trial final test accuracy: {}'.format(test_accs))
if __name__=='__main__':
main()
実験条件各種 → hydra_conf/neptune_test.yaml
- options と configs に分かれている点については後述します. Ray Tune との統合の際に重要になります.
options:
dataset:
train: 'trainvalset'
val: 'testset'
test: 'testset'
train_val_ratio: 0.9
num_classes: 10
resnet:
depth: 40
widen: 2
num_workers: 4
device: 'cuda'
max_epochs: 120
use_tqdm: False
configs:
dropout_rate: 0.5
weight_decay: 1e-4
batch_size: 512
lr_init: 1e-2
lr_gamma: 0.1
lr_stepsize: 40
- ユーティリティ関数(データ読み込み・モデル保存 等) → myutils.py
- WideResNet モデル → mymodels.py
プロジェクトの作成
実装を改変する前に,まず,neptune のトップページ https://app.neptune.ai/[username]/-/projects で New project を押して新しいプロジェクトを作成します.
Project name と project keyを設定すると作成できます.Project key は,各runの名前のテンプレートと思えば良いと思います.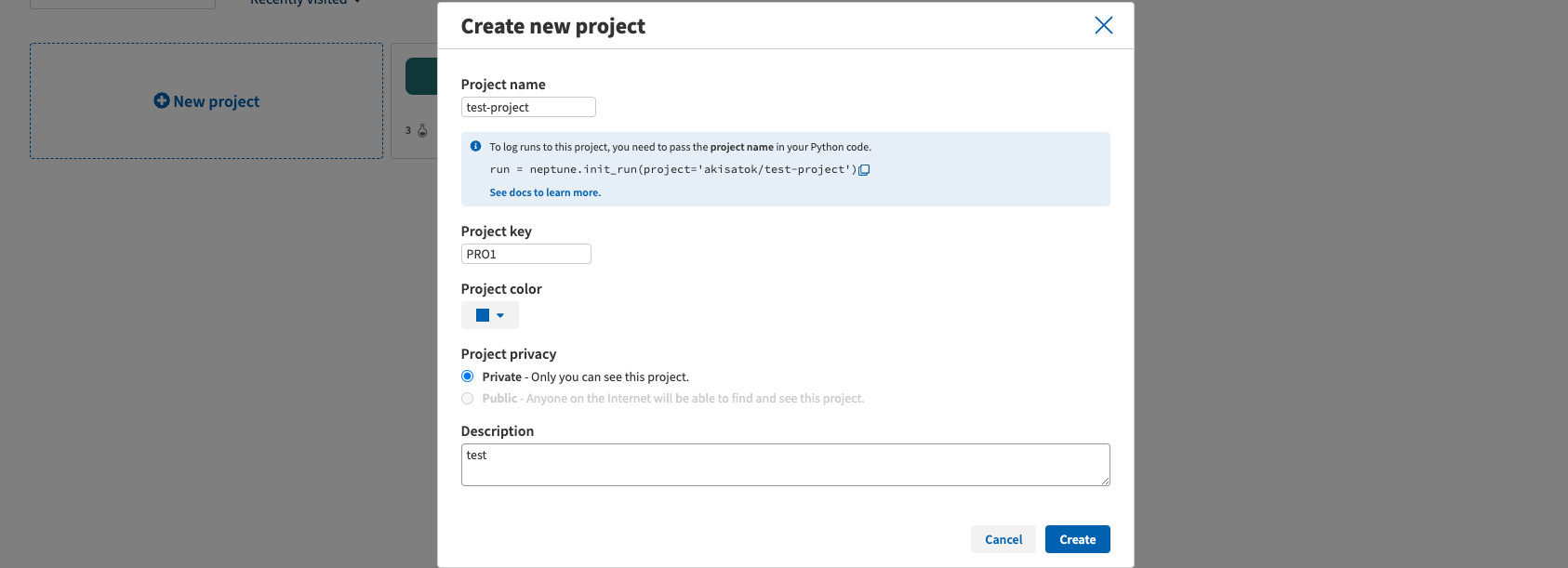
Neptune を組み込む
実装改良の最初の手順として,実際の学習プロセスを実装した train 関数で Neptune の初期設定を行い,run を作成します.
そのためには,以下のように neptune.init_run 関数を追加します.Neptune の API token は hydra で読み取る yaml に追記する方式とします.
(Neptune の Best practices では,API token は OS の環境変数として記載すべき,との記載がありますので,それでも良いと思います.)
import hydra
from omegaconf import DictConfig
import neptune.new as neptune
from neptune.new.metadata_containers.run import Run
def train(configs: dict[str, Any], options: dict[str, Any], api_token: str=None,
) -> tuple[nn.Module, optim.Optimizer, list[float], list[float], list[float], list[float]]:
# Neptune initialization
run: Run = neptune.init_run(
project = '[your username]/[your project name]',
api_token = api_token,
)
...
# main function
@hydra.main(version_base=None, config_path='hydra_conf', config_name='neptune_test')
def main(cfg: DictConfig) -> None:
...
# optimization
_, _, train_losses, train_accs, test_losses, test_accs = train(configs, options=options, api_token=cfg.neptune.api_token)
...
neptune:
api_token: '[your API token]'
...
上記では init_run に必要最低限の引数しか渡していませんが,これ以外にも数多くの引数を渡すことができます.詳細は API リファレンス を見ていただくのが良いですが,例えば,以下のような項目を渡すことができます.
import neptune.new as neptune
from neptune.new.metadata_containers.run import Run
run: Run = neptune.init_run(
project = '[your username]/[your project name]', # プロジェクト名
api_token = api_token, # APIトークン
name = 'run name', # 個別の run に付与する名前(指定しないと適当に決まる)
source_files = ['main_with_neptune.py'], # Neptune に渡すソースファイル(ワイルドカードも使用可能)
description = 'Any descriptions', # 任意の説明文
tags = ['tag1', 'tag2'], # runを識別するタグを複数つけられる
)
続いて,この run で利用するモデル・学習のパラメータを run に添付します.これを添付することで,パラメータの異なる複数の runs を比較する際に,どのパラメータが寄与しているかなどを調べることができます.
from omegaconf import OmegaConf
def train(configs: dict[str, Any], options: dict[str, Any], api_token: str=None,
) -> tuple[nn.Module, optim.Optimizer, list[float], list[float], list[float], list[float]]:
...
# set options to the run
run['options'] = options
run['configs'] = configs
...
def main(cfg: DictConfig) -> None:
...
# configs and options
options: dict[str, Any] = OmegaConf.to_container(cfg.options)
configs: dict[str, Any] = OmegaConf.to_container(cfg.configs)
...
最後に,結果指標を run に添付します.
def train(configs: dict[str, Any], options: dict[str, Any], api_token: str=None,
) -> tuple[nn.Module, optim.Optimizer, list[float], list[float], list[float], list[float]]:
...
# training
train_losses: list[float] = list()
train_accs: list[float] = list()
val_losses: list[float] = list()
val_accs: list[float] = list()
for epoch in range(options['max_epochs']):
print('Epoch {}'.format(epoch+1))
# training
now_train_loss, now_train_acc = train_loop(
trainloader, net, device, optimizer, criterion, lr_scheduler, train=True, use_tqdm=options['use_tqdm'])
# testing with validation data
now_val_loss, now_val_acc = train_loop(
valloader, net, device, optimizer, criterion, train=False, use_tqdm=options['use_tqdm'])
# appending measures onto the run
run["metrics/train/loss"].append(now_train_loss)
run["metrics/train/acc"].append(now_train_acc)
run["metrics/val/loss"].append(now_val_loss)
run["metrics/val/acc"].append(now_val_acc)
...
ここでは損失や分類率を run に渡していますが,それ以外にも様々なものを渡すことができます.例えば,以下のようにすると,モデルパラメータを渡すことができます.
run['model'].upload('model.pt')
画像を渡すこともできます.
# 自分で作ったROC曲線のファイルをアップロード
run['roc_curve'].upload('roc_final.png')
# データを画像にして渡す
run['misclassified_examples'].upload(neptune.types.File.as_image(misclassified_imgs))
これで必要な実装が終わりましたので,動作させます.
python main_with_neptune.py
そうすると,Neptune の UI でプロジェクトを指定すると,先ほど走らせた実験が表示されます. 
列に着いている「歯車」マークを押すことで列の表示名や色などを変更したりでき,ドラッグで列の順序を入れ替えることもできます.
ハイパーパラメータ探索での利用
ここまでで,特定のパラメータでの実験の実行,その結果の Neptune への記録,および Neptune Web UI での確認までを行いました.以降では,その応用編として,ハイパーパラメータ探索での利用を考えます.
ハイパーパラメータ探索では,パラメータとそれに対応する実験結果指標とを適切に管理して,それらの優劣や関係性を調べることが重要となります.そのため,Neptune.ai などのような実験管理ツールが必須となります.
ハイパーパラメータ探索のためのライブラリには,主に Optuna と Ray Tune がありますが,Neptune + Optuna の組合せについては 公式Webに具体的な解説がある ことから,本記事では Ray Tune との組合せについて紹介していきます.
Ray Tune そのものの解説については 以前の記事 で紹介していることからここでは割愛し,実験管理ツールとして(以前の記事で紹介した Weights & Biases ではなく)Neptune を利用する際の重点ポイントについて紹介します.
まず,Hydra で読み取るパラメータ YAML の中に,探索したいハイパーパラメータの範囲を Ray Tune 形式で記載します.
- 先ほど パラメータを configs と options に分離しておいたのはこのためです.
- configs: ハイパーパラメータ探索の対象となるパラメータ
- options: ハイパーパラメータ探索の対象ではない固定のパラメータ
- Hydra で取り込めるオブジェクトの種類は限定されているため,YAML にはソースに記載する生テキストを埋めて文字列として読み込み,読み込んだ後で eval 関数を用いてインスタンス化します.
configs:
dropout_rate: 'tune.quniform(0.0, 0.5, 0.1)'
weight_decay: 'tune.qloguniform(1e-4, 1e-2, 5e-5)'
batch_size: 'tune.choice([32, 64, 128, 256, 512, 1024])'
r_init: 'tune.qloguniform(1e-3, 5e-1, 5e-4)'
lr_gamma: 'tune.quniform(0.1, 1.0, 0.1)'
lr_stepsize: 'tune.qrandint(10, 100, 5)'
続いて,メイン関数内でパラメータを読み込み,configs の中身をインスタンス化します.
from ray import tune
@hydra.main(version_base=None, config_path='hydra_conf', config_name='neptune_ray_test')
def main(cfg: DictConfig) -> None:
...
# configs and options
options: dict[str, Any] = OmegaConf.to_container(cfg.options)
configs: dict[str, Any] = OmegaConf.to_container(cfg.configs)
...
## instanciating every element in configs
configs['dropout_rate'] = eval(configs['dropout_rate'])
configs['weight_decay'] = eval(configs['weight_decay'])
configs['batch_size'] = eval(configs['batch_size'])
configs['lr_init'] = eval(configs['lr_init'])
configs['lr_gamma'] = eval(configs['lr_gamma'])
configs['lr_stepsize'] = eval(configs['lr_stepsize'])
さらに,Ray Tune でのハイパーパラメータ探索に必要な scheduler / search algorithm / reporter の準備をします.
from ray.tune import CLIReporter
from ray.tune.schedulers import ASHAScheduler
from ray.tune.search import ConcurrencyLimiter, Searcher
from ray.tune.search.optuna import OptunaSearch
def main(cfg: DictConfig) -> None:
...
# scheduler
scheduler: ASHAScheduler = ASHAScheduler(
metric='loss', mode='min', max_t=options['max_epochs'],
grace_period=5, reduction_factor=2)
# search algorithm
search_alg: Searcher = OptunaSearch(metric='loss', mode='min')
search_alg: Searcher = ConcurrencyLimiter(search_alg, max_concurrent=4)
# Progress reporter
reporter: CLIReporter = CLIReporter(
metric_columns=['loss', 'accuracy', 'training_iteration'],
max_progress_rows=5, max_report_frequency=5)
...
最後に,ハイパーパラメータ探索を実行します.
from ray import tune
from ray.air.config import RunConfig
from functools import partial
def main(cfg: DictConfig) -> None:
...
# optimization
ray_tuner: tune.Tuner = tune.Tuner(
tune.with_resources(
partial(train, options=options),
resources={'cpu': 4, 'gpu': 1},
),
tune_config=tune.TuneConfig(
scheduler=scheduler,
search_alg=search_alg,
num_samples=2,
),
param_space=configs,
run_config=RunConfig(
name='raytune_only',
local_dir='./ray_results',
progress_reporter=reporter,
)
)
ray_result: tune.ResultGrid = ray_tuner.fit()
実行してみると,プロジェクトに続々と結果が投入されてきます.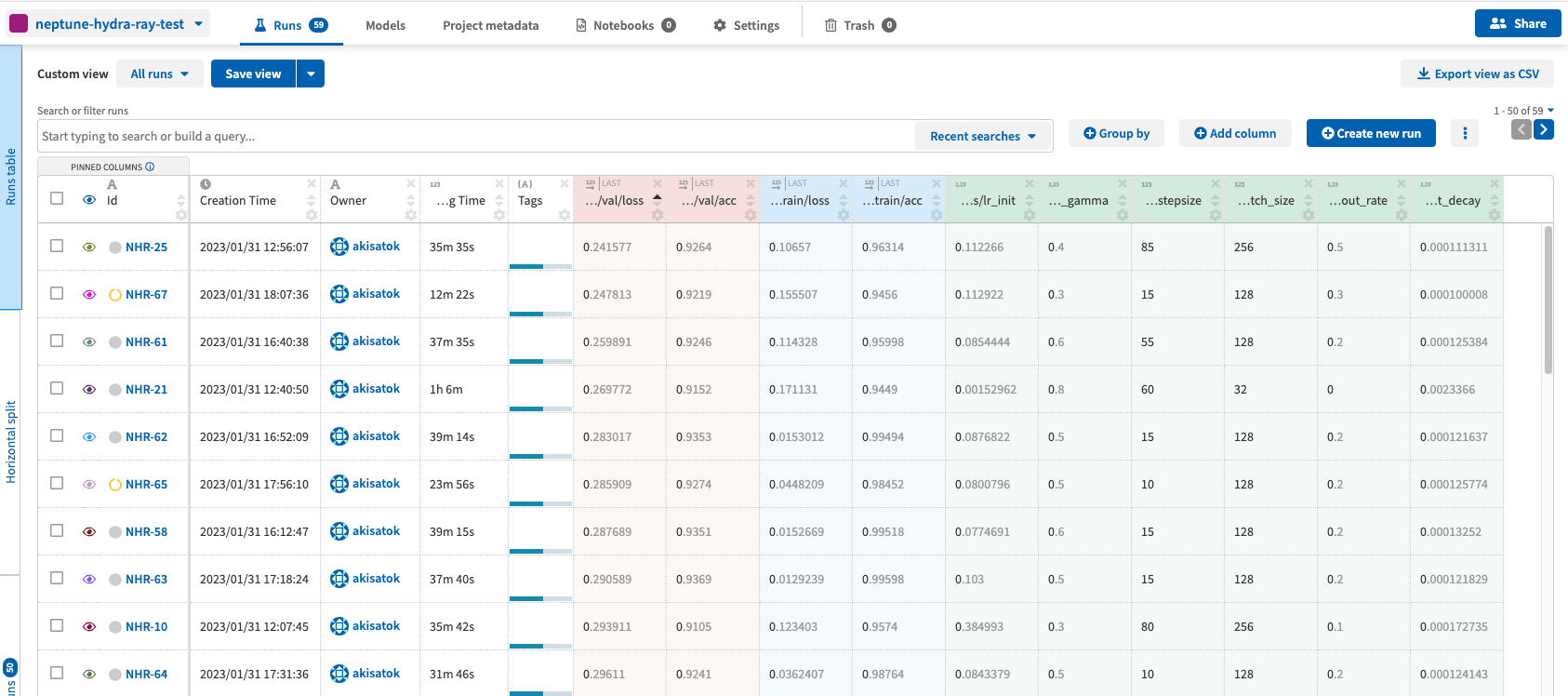
検証データでの損失や分類率を比較することができ,parallel coordinates を利用することで有望そうなパラメータの範囲を調べることもできます. 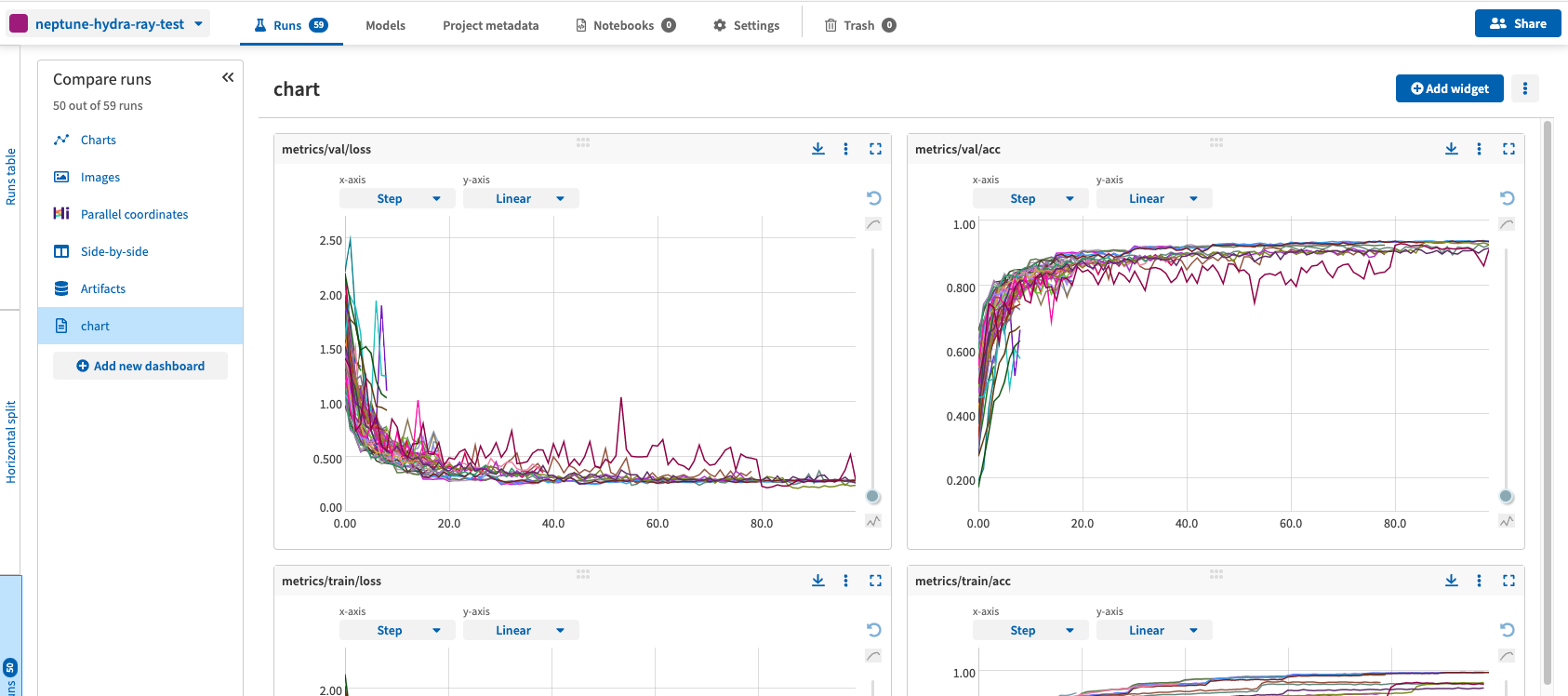

おわりに
本記事では,機械学習の実験管理を行うツールとして, Neptune.ai を紹介致しました.個人で小規模に利用するのであれば無料で充実した機能を利用できますし,大学等所属の方やKagglerは利用時間制限も外れますので,非常に有用ではないかと思います.
また,今回紹介した PyTorch だけではなく,様々な機械学習ライブラリと統合でき,そのためのリソースも十分に提供されているので,様々なプロジェクトで利用できそうです.
より深い内容を知りたい場合には, 公式ドキュメント や サンプルコード などを見ていくと良いかと思います.
皆様も素敵な実験管理ライフをお過ごし下さい.