はじめに
初めまして,SinkCapitalインターン生の井上です.卒業論文の添削が返ってくる間に,Pytorchを触ってみようということで記事を書いていきます!
今回行ったこと
- Pytorchについての軽いサーベイ
- Pytorchを用いた超簡単なニューラルモデルの実装
Pytorchとは
Pytorchを使う理由
- オープンソースの機械学習ライブラリ
- DeepLearnignの実装が非常に簡単になる!
- Numpyと類似したTensorによりデータを扱う
- TensorはGPUを使用できるため,Google Colaboratoryで実装すると非常に高速な処理が可能
よく使われるモジュール
- autograd Tensorの各要素による微分を自動で行う機能
- optim 様々な最適化アルゴリズムを実装したモジュール
- nn モデルを構築するためによく使われる層を集めたモジュール(ニューラルネットワークを構築)
Pytorchを使ってみる
前提
1.データ
sk-learnのワインデータを使います.
ワインデータの概要
ワインデータは,178個のサンプルに対する13個の説明変数と1つの目的変数から成っており,詳細は以下になります.
<説明変数>
- alcohol:アルコール濃度
- malic_acid:リンゴ酸
- ash:灰
- alcalinity_of_ash:灰のアルカリ成分
- magnesium:マグネシウム
- total_phenols:総フェノール類量
- flavanoids:フラボノイド(ポリフェノールの一種)
- nonflavanoid_phenols:非フラボノイドフェノール類
- proanthocyanins:プロアントシアニジン(ポリフェノールの一種)
- color_intensity:色の強さ
- hue:色合い
- od280/od315_of_diluted_wines:ワインの希釈度合い
- proline:プロリン(アミノ酸の一種)
<目的変数>
14. ワインの品種(3種類)
データ型:(178rows×14columns)
2.行うタスク
1~13の特徴量が与えられたとき,ワインの品種を正確に分類すること
分析
データをインポートする
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from sklearn.datasets import load_wine
wine = load_wine()
df_wine=pd.DataFrame(wine.data)
df_wine["label"]=wine.target
df_wine
ワインデータを訓練データとテストデータに分割する
import torch
from sklearn.model_selection import train_test_split
wine_data = wine.data
wine_label= wine.target
x_train, x_test, t_train, t_test = train_test_split(wine_data, wine_label) # 25%がテスト用
# numpyからtensorに変換
x_train = torch.tensor(x_train, dtype=torch.float32)
t_train = torch.tensor(t_train, dtype=torch.int64)
x_test = torch.tensor(x_test, dtype=torch.float32)
t_test = torch.tensor(t_test, dtype=torch.int64)
簡単なニューラルモデルを構築する.
from torch import nn
net = nn.Sequential(
nn.Linear(13 ,8),
nn.ReLU(),
nn.Linear(8 ,4),
nn.ReLU(),
nn.Linear(4, 3)
)
構築されたモデルの概観はこのようになる.
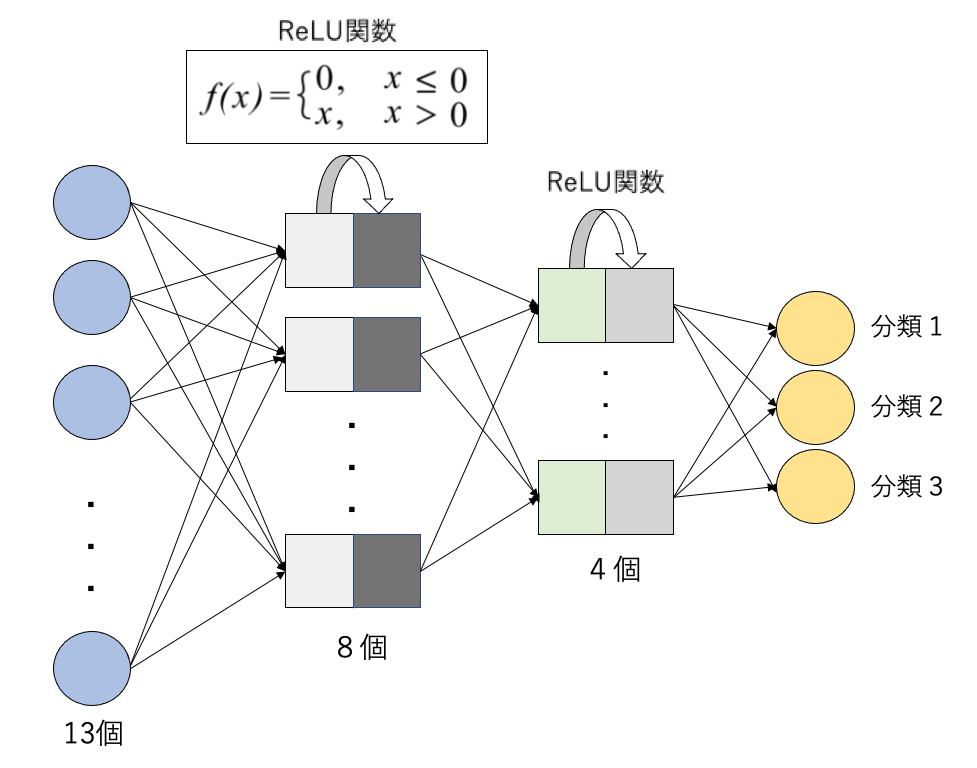
モデルをデータに当てはめ最適化する.
from torch import optim
# 交差エントロピー誤差関数
loss_fnc = nn.CrossEntropyLoss()
# SGD
optimizer = optim.SGD(net.parameters(), lr=0.01) # 学習率は0.01
# 損失のログ
record_loss_train = []
record_loss_test = []
# 1000エポック学習
for i in range(1000):
# 勾配を0に
optimizer.zero_grad()
# 順伝播
y_train = net(x_train)
y_test = net(x_test)
# 誤差を求める
loss_train = loss_fnc(y_train, t_train)
loss_test = loss_fnc(y_test, t_test)
record_loss_train.append(loss_train.item())
record_loss_test.append(loss_test.item())
# 逆伝播(勾配を求める)
loss_train.backward()
# パラメータの更新
optimizer.step()
if i%100 == 0:
print("Epoch:", i, "Loss_Train:", loss_train.item(), "Loss_Test:", loss_test.item())
結果の出力
y_test = net(x_test)
count = (y_test.argmax(1) == t_test).sum().item()
print("正解率:", str(count/len(y_test)*100) + "%")
正解率: 57.78%
なんとも微妙な結果になりました.
一般的に,ニューラルネットワークは層を増やすことで表現力が増すことが知られているので,以下のようなモデルに変更してみます.
net = nn.Sequential(
nn.Linear(13 ,11),
nn.ReLU(),
nn.Linear(11 ,8),
nn.ReLU(),
nn.Linear(8 ,7),
nn.ReLU(),
nn.Linear(7, 4),
nn.ReLU(),
nn.Linear(4, 3)
)
正解率: 64.44%
少し上昇したことがわかります.
感想
使ってみて感動したポイント
1.nnモジュールを使うことで,モデルの記述が直感的でとても楽!
2.optimモジュールを使うことで,最適化が一瞬でできる!
まとめ
モデルの記述が直感的で,ちょっとした工夫を思いついた時に,すぐに反映できるのはとても便利だなと感じました!CNNなどの勉強をしてPytorchで組めるともっと面白いものが作れそうだなと思いました.