はじめに
AWS発のAI IDE「Kiro」を組織で導入すると、気になるのが「誰がどれくらい使っているのか?」という点です。
ライセンスコストの最適化やチーム内の活用促進のためにも、利用状況の可視化は重要ですよね。
本記事では、IAM Identity Center経由でKiro Pro以上のライセンスを利用している環境を前提に、ユーザーごとのデイリー使用量を監視する方法を紹介します。
さらに、出力されたCSVをサーバーレスな簡易ダッシュボードで可視化する方法も解説します。
ちなみに、最近ではAIコードエージェントのクレジット消費量をエンジニアの生産性指標にするチームも出てきているとのことです。
AIエージェントも効率的な利用が求められますが、大前提としてより積極的に活用していくことが求められています。
対象読者
- Kiroを組織で導入済み、または導入検討中の管理者
- チームメンバーのKiro利用状況を把握したい方
- IAM Identity CenterでKiroのライセンスを管理している方
- CSVデータをダッシュボードで可視化したい方
前提条件
| 項目 | 値 |
|---|---|
| Kiroライセンス | Pro以上 |
| 認証方式 | IAM Identity Center |
| IAM Identity Centerリージョン | ap-northeast-1(東京) |
| Kiroプロファイルリージョン | us-east-1(バージニア北部) |
| AWSアカウント | 単一アカウント |
Kiroの使用量監視機能は2種類ある
Kiroコンソールには、使用量を監視するための機能が2つ用意されています。
| Kiro使用状況ダッシュボード | Kiroユーザーアクティビティレポート | |
|---|---|---|
| 確認場所 | Kiroコンソール上のダッシュボード画面 | S3バケットに出力されるCSVファイル |
| 粒度 | チーム全体の集計値 | ユーザー個人単位 |
| 更新頻度 | ほぼ1時間ごと(アクティブユーザーのみ日次) | 日次(UTC 00:00に生成) |
| 主な用途 | チーム全体の利用傾向をざっくり把握 | 個人ごとの利用量を詳細に追跡 |
| 確認できる内容 | ティア別サブスクリプション数、アクティブユーザー数、クレジット消費量(全体) | ユーザーごとのクレジット消費量、メッセージ数、会話数、超過クレジット、クライアント種別など |
| データの二次利用 | コンソール上で閲覧のみ | CSVなのでAthena、QuickSight、Excelなどで自由に分析可能 |
ざっくり言うと、ダッシュボードは「チーム全体の健康診断」、ユーザーアクティビティレポートは「個人のカルテ」というイメージです。
個人単位でデイリーの使用量を追跡したい場合は、ユーザーアクティビティレポートが最適です。
以降では、このユーザーアクティビティレポートの設定手順を解説します。
設定手順
手順1: S3バケットの作成
- AWSマネジメントコンソールにサインイン
- リージョンを us-east-1(バージニア北部) に切り替え
- S3コンソールを開き、「バケットを作成」をクリック
- バケット名を入力(例:
kiro-user-activity-reports-{任意の識別子}) - リージョンが「米国東部(バージニア北部)us-east-1」であることを確認
- その他の設定はデフォルトのままで「バケットを作成」
S3バケットのリージョンについて
S3バケットは Kiroプロファイルのリージョン に作成する必要があります。
IAM Identity Centerのリージョン(今回はap-northeast-1)ではないので注意してください。
Kiroプロファイルのサポートリージョンは、記事執筆時点ではGovCloudを除くと以下の2つのみです:
- US East (N. Virginia) — us-east-1
- Europe (Frankfurt) — eu-central-1
手順2: プレフィックス(フォルダ)の作成
CSVファイルはバケット直下には保存できないため、プレフィックスの作成が必須です。
- 作成したバケットを開く
- 「フォルダの作成」をクリック
- フォルダ名を入力(例:
user-activity-reports) - 「フォルダの作成」をクリック
手順3: バケットポリシーの設定
- 作成したバケットの「アクセス許可」タブを開く
- 「バケットポリシー」の「編集」をクリック
- 以下のポリシーを貼り付け
{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "KiroLogsWrite",
"Effect": "Allow",
"Principal": {
"Service": "q.amazonaws.com"
},
"Action": [
"s3:PutObject"
],
"Resource": [
"arn:aws:s3:::【バケット名】/【プレフィックス名】/*"
],
"Condition": {
"StringEquals": {
"aws:SourceAccount": "【AWSアカウントID】"
},
"ArnLike": {
"aws:SourceArn": "arn:aws:codewhisperer:us-east-1:【AWSアカウントID】:*"
}
}
}
]
}
- 「変更の保存」をクリック
ポリシー内の置き換え箇所
-
【バケット名】→ 手順1で作成したバケット名 -
【プレフィックス名】→ 手順2で作成したフォルダ名 -
【AWSアカウントID】→ 自分のAWSアカウントID(12桁の数字) -
SourceArnのリージョン部分はKiroプロファイルのリージョン(今回はus-east-1)を指定
手順4: Kiroコンソールでレポートを有効化
- AWSマネジメントコンソールのリージョンが us-east-1 であることを確認
- サービス検索で「Kiro」と入力し、Kiroコンソールを開く
- 左メニューから「Settings」を選択
- 「Kiro user activity reports」セクションの「Edit」をクリック
- 「Collect granular metrics per user」をONに切り替え
- 「S3 location」に以下の形式で入力:
s3://【バケット名】/【プレフィックス名】/ - 保存
設定の確認
設定を保存すると、KiroがS3バケットへの書き込み権限を検証するためのテストファイルが自動的に作成されます。
S3バケットの以下のパスにファイルが生成されていれば、設定は成功です。
【バケット名】/
【プレフィックス名】/
AWSLogs/
【アカウントID】/
KiroLogs/
(テストファイル)
テストファイルの中身は以下のような内容になっています:
Service Name: Amazon Q
Timestamp: 2026-03-20T03:39:14.299655299Z
Message: Access validation successful.
「Access validation successful.」と表示されていれば、バケットポリシーの設定が正しく、Kiroからの書き込みが成功しています。
レポートの出力タイミングと確認方法
レポートは毎日 UTC 00:00(日本時間 09:00) に生成されます。
設定した翌日の朝から、以下のパスにCSVファイルが出力されます。
【バケット名】/
【プレフィックス名】/
AWSLogs/
【アカウントID】/
KiroLogs/
user_report/
us-east-1/
YYYY/
MM/
DD/
00/
clientType_【アカウントID】_user_report_timestamp.csv
階層深すぎて、サンプルでデータ入れるのは面倒でした・・・
CSVに含まれる主要メトリクス
| メトリクス名 | 説明 |
|---|---|
| Date | レポート対象日 |
| UserId | ユーザーID |
| Client_Type | KIRO_IDE / KIRO_CLI / PLUGIN |
| Subscription_Tier | サブスクリプションプラン(Pro / ProPlus / Power) |
| Total_messages | 送受信メッセージ数(プロンプト、ツールコール、Kiroの応答を含む) |
| Chat_Conversations | 会話数 |
| Credits_Used | その日に消費したクレジット数 |
| Overage_Enabled | 超過利用が有効かどうか |
| Overage_Cap | 管理者が設定した超過上限 |
| Overage_Credits_Used | 超過クレジット使用量 |
レポートに含まれるのは、その日にKiroを実際に利用したユーザーのみです。
利用がなかったユーザーの行はCSVに含まれません。
また、1,000ユーザーを超える場合はCSVが分割されます(part_1、part_2...)。
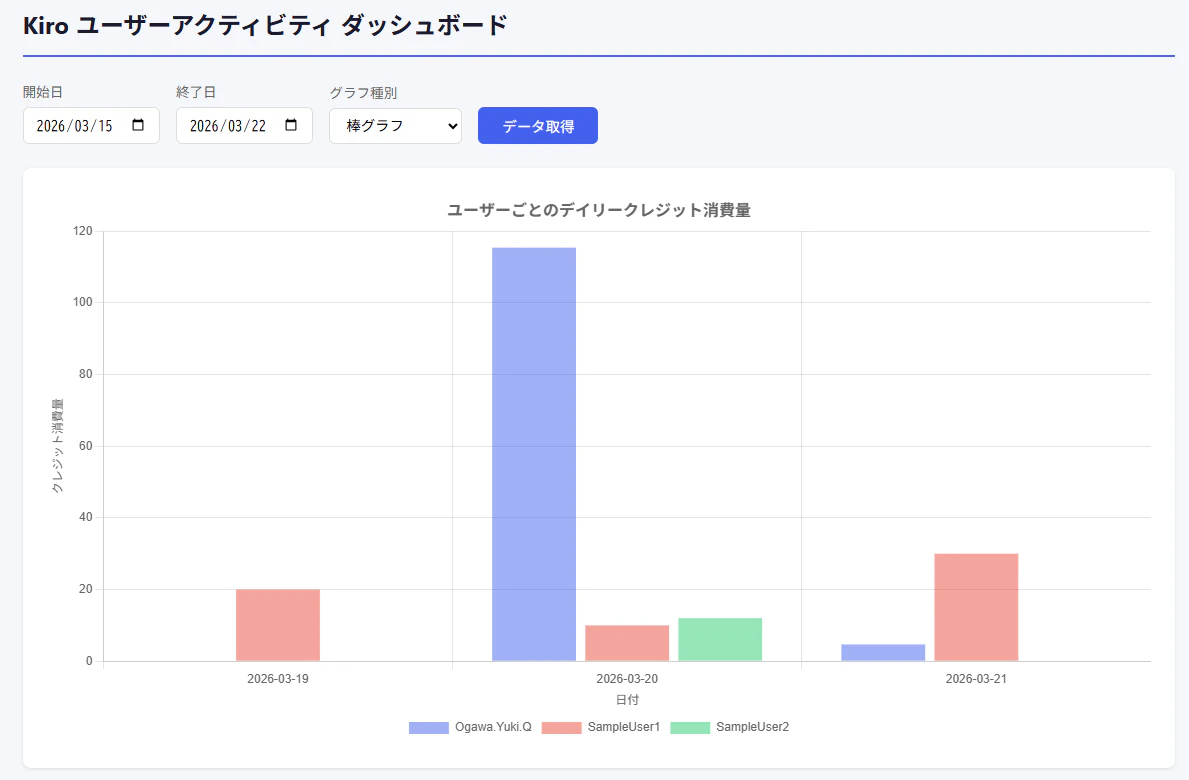
サーバーレスダッシュボードで可視化する
CSVファイルをそのまま眺めるのは正直つらいので、サーバーレスな簡易ダッシュボードを作って可視化してみます。
AthenaやQuickSightを使う方法もありますが、今回はチーム内の少人数向けということで、よりシンプルな構成にしました。
デプロイしてできるダッシュボードはこんな感じです。
棒グラフだけでなく、折れ線表示も可能です。
見切れていますが、ページ下部に1日単位のKiro使用詳細データも確認できます。
ダッシュボードの構築に必要なコードは以下で公開してありますので、ぜひ参考にしてください。
アーキテクチャ
S3 (us-east-1) ap-northeast-1
┌──────────────────┐ ┌───────────────────────────────────────────┐
│ Kiro CSV出力 │ │ │
│ (user_report/) │ │ EventBridge Scheduler (毎日 JST 10:00) │
│ │←───│ ↓ │
│ │ │ Lambda [csv_importer] │
│ │ │ (CSV取得・解析・DynamoDB書込) │
│ │ │ ↓ │
│ │ │ DynamoDB [kiro-user-activity] │
│ │ │ ↑ │
│ │ │ API Gateway → Lambda [api] │
│ │ │ ↑ │
│ │ │ S3 静的ホスティング (HTML+JS+CSS) │
│ │ │ ※ バケットポリシーでIP制限 │
└──────────────────┘ └───────────────────────────────────────────┘
ポイントは以下の通りです:
- KiroのCSVは us-east-1 のS3に出力されるが、ダッシュボード自体は ap-northeast-1(東京) にデプロイ
- CSV取り込みLambdaがクロスリージョンでus-east-1のS3からCSVを取得し、東京のDynamoDBに書き込む
- フロントエンドはS3静的ホスティング + バケットポリシーでのIP制限(簡易認証)
- Chart.jsで折れ線グラフを描画し、ユーザーごとのデイリークレジット消費量を可視化
- インフラはすべてAWS CDKで管理
今回は社内チームだけに限定して閲覧するユースケースだったので、IP制限だけで構築しています。
閲覧ユーザーが社内外ユーザーの両方を含んだりするケースであれば、Cognitoによる認証を追加したほうがよいです。
また、フロントエンドもAmplifyでReactアプリ化など、チームによってカスタマイズしてみましょう!
前提条件
- 前章のユーザーアクティビティレポートの設定が完了していること
- AWS CDK v2 がインストール済みであること
- Python 3.12 以上
- AWS CLIが設定済みで、デプロイ先アカウントへのアクセス権があること
本構成では、複数アカウントのKiroユーザーの監視はスコープ外です。
公式でも、複数AWSアカウントのKiroアクティビティレポートを1つのS3バケットに集約することはできません。
https://kiro.dev/docs/enterprise/monitor-and-track/user-activity
Be in the AWS account where users are subscribed. If users are subscribed in multiple AWS accounts, then you must create buckets in each of those accounts. Cross-account buckets are not supported.
なので、複数AWSアカウントでKiroを運用しているケースでは、各AWSアカウントのS3バケットからS3レプリケーションやLambdaで集約用アカウントのS3にコピーするような処理が必要となります。
プロジェクト構成
kiro-dashboard/
settings.ini 環境設定ファイル(全環境依存値を管理)
cdk/ CDKインフラ定義
app.py CDKエントリポイント
cdk.json CDK設定
requirements.txt CDK依存パッケージ
stacks/
dashboard_stack.py 全リソース定義
lambda/
csv_importer/index.py CSV取り込みLambda
api/index.py データ取得API Lambda
frontend/
index.html ダッシュボード画面
style.css スタイルシート
app.js グラフ描画ロジック(Chart.js)
設定ファイル(settings.ini)
すべての環境依存値は settings.ini で管理しています。自分の環境に合わせて書き換えてください。
[kiro_report]
# KiroユーザーアクティビティレポートのS3バケット名
source_bucket = kiro-user-activity-reports-{任意の識別子}
# レポートCSVのS3プレフィックス
source_prefix = user-activity-reports/AWSLogs/{アカウントID}/KiroLogs/user_report/us-east-1
# レポート元S3バケットのリージョン
source_region = us-east-1
[dashboard]
# ダッシュボード用DynamoDBテーブル名
table_name = kiro-user-activity
# ユーザー名管理用DynamoDBテーブル名
user_names_table_name = kiro-user-names
# フロントエンド用S3バケット名
frontend_bucket_name = kiro-dashboard-frontend-{任意の識別子}
# デプロイ先リージョン
deploy_region = ap-northeast-1
[ip_restriction]
# 許可するIPアドレス(カンマ区切り)
allowed_ips = xxx.xxx.xxx.xxx,yyy.yyy.yyy.yyy
settings.iniの設定値について
-
source_prefixは、前章で設定したS3バケット内のCSV出力パスに合わせてください -
frontend_bucket_nameはグローバルで一意なバケット名にする必要があります -
allowed_ipsにはダッシュボードにアクセスを許可するIPアドレスを指定します
デプロイ手順
1. CDK依存パッケージのインストール
cd kiro-dashboard/cdk
pip install -r requirements.txt
2. CDKブートストラップ(初回のみ)
対象リージョンでCDKを初めて使う場合のみ実行してください。
cdk bootstrap aws://{AWSアカウントID}/ap-northeast-1
3. 初回デプロイ
cdk deploy
デプロイ完了後、以下の出力が表示されます。
Outputs:
KiroDashboardStack.ApiURL = https://xxxxxxxxxx.execute-api.ap-northeast-1.amazonaws.com/prod/
KiroDashboardStack.DashboardURL = http://kiro-dashboard-frontend-xxx.s3-website-ap-northeast-1.amazonaws.com
4. API URLの設定
frontend/app.js の先頭にある API_BASE_URL を、手順3で出力された ApiURL の値に書き換えます。
// 変更前
const API_BASE_URL = "https://xxxxxxxxxx.execute-api.ap-northeast-1.amazonaws.com/prod";
// 変更後(出力されたURLに置き換え。末尾のスラッシュは不要)
const API_BASE_URL = "https://abc1234567.execute-api.ap-northeast-1.amazonaws.com/prod";
5. フロントエンドの再デプロイ
API URLを書き換えた後、再度デプロイしてフロントエンド資材を更新します。
cdk deploy
過去データの取り込み
初回デプロイ直後はDynamoDBにデータがないため、ダッシュボードには何も表示されません。
CSV取り込みLambdaは毎日 JST 10:00 に自動実行されますが、過去分のデータを取り込みたい場合はLambdaを手動実行します。
データの重複について
DynamoDBのキーは UserId + Date なので、同一ユーザー・同一日付のデータは上書き(Upsert)されます。
何度取り込んでも重複する心配はありません。
前日分のみ取り込む場合(デフォルト動作)
aws lambda invoke \
--function-name kiro-dashboard-csv-importer \
--region ap-northeast-1 \
output.json
過去N日分を一括取り込みする場合
例えば過去7日分を取り込む場合:
aws lambda invoke \
--function-name kiro-dashboard-csv-importer \
--region ap-northeast-1 \
--cli-binary-format raw-in-base64-out \
--payload '{"days_back": 7}' \
output.json
日付範囲を指定して取り込む場合
aws lambda invoke \
--function-name kiro-dashboard-csv-importer \
--region ap-northeast-1 \
--cli-binary-format raw-in-base64-out \
--payload '{"start_date": "2026-03-01", "end_date": "2026-03-22"}' \
output.json
取り込み結果は output.json に出力されます。
cat output.json
# {"statusCode": 200, "body": "5ファイルから12件のレコードを取り込みました"}
動作確認
- ブラウザで
DashboardURLにアクセス(IP制限があるため、許可されたIPからアクセスしてください) - 開始日・終了日を指定(デフォルトは直近7日間)
- グラフ種別を選択(折れ線グラフ / 棒グラフ)
- 「データ取得」ボタンをクリック
- ユーザーごとのクレジット消費量がグラフで表示される
- 画面下部のテーブルで詳細データ(メッセージ数、会話数など)を確認可能
ユーザー名の表示
デフォルトではユーザーIDがそのまま表示されますが、ユーザー名管理テーブル(kiro-user-names)にマッピングを登録すると、グラフやテーブルにユーザー名が表示されます。
DynamoDBコンソールの「項目を探索」→「kiro-user-names」→「項目を作成」から登録します。
{
"UserId": "12345678-abcd-1234-efgh-123456789012",
"UserName": "田中太郎"
}
Kiroアクティビティレポートでは、IAM Identity Centerのユーザー名でログが作られます。
そのため、わかりやすくユーザー名を表示するために、ユーザー名テーブルを設けています。
ユーザー名テーブルは以下仕様です。
- マッピングが登録されていないユーザーはユーザーIDがそのまま表示されます
- テーブルにデータがなくてもダッシュボードは正常に動作します
- テーブル名は
settings.iniのuser_names_table_nameで変更可能です
リソースの削除
不要になった場合は以下のコマンドで削除できます。
cd kiro-dashboard/cdk
cdk destroy
DynamoDBテーブルについて
DynamoDBテーブルは RemovalPolicy.RETAIN に設定されているため、スタック削除後も残ります。
テーブルも削除したい場合は、AWSコンソールから手動で削除してください。
まとめ
Kiroのユーザーアクティビティレポートを使えば、チームメンバーごとのデイリー使用量をCSVで取得できます。
設定自体はS3バケットの作成とKiroコンソールでの有効化だけなので、10分もあれば完了します。
さらに、サーバーレスな簡易ダッシュボードを構築することで、CSVデータをグラフで直感的に確認できるようになります。
CDKでインフラを管理しているので、環境の再現やチーム内での共有も容易です。
ポイントとして押さえておきたいのは以下の点です:
- S3バケットはKiroプロファイルのリージョン(IAM Identity Centerのリージョンではない)に作成する
- バケットポリシーの
SourceArnにもKiroプロファイルのリージョンを指定する - レポートはUTC 00:00(日本時間 09:00)に日次で生成される
- ダッシュボードの初回デプロイ後は、過去データの手動取り込みを忘れずに実行する
今回は自分でダッシュボードを作成しましたが、そのうちチームマネージャー向け機能としてKiroダッシュボードがリリースされるかもしれませんね。