1.どんなもの?
UCF101やHMDB51動画データセットではデータ数が少ないので,優れたビデオアーキテクチャを特定するのは困難
データ数が多いKinetics動画データセットで最先端のアーキテクチャを再評価(KineticsでpretrainingしてUCF101やHMDB51の精度をみる)
再評価したアーキテクチャと提案手法であるTwo-Stream Inflated 3DConvNetとの比較検証
2.先行研究と比べてどこがすごいの?
Inception、VGG-16、ResNetのような画像分類ネットワークを時空間特徴抽出器に膨らませたこと.
以前の3DConvNetはパラメータの高次元化とラベル付きビデオデータの欠如のために、最大でも8層だった.
3.技術や手法のキモはどこにあるか?
2DConvNetを3Dに拡張させる
2Dアーキテクチャの畳み込みとプーリングのカーネルサイズを時間方向も考慮.NxNのカーネルはNxNxNになる.
2DConvNetで学習したフィルタの重みを3DConvNetに拡張させる
画像を複数コピーして静止画のような動画を作る
動画上のpoolingの活性化関数は、元の単一画像入力と同じでなければならない.
2Dの重みを時間次元に沿ってN回繰り返し、Nで割ることによって達成できる.
Inception-v1ベースの3DCNN
依然としてtwo-streamの手法は有効であるため,この論文に従った方法 https://arxiv.org/pdf/1604.06573.pdf でInception-v1を適用して実験を行った
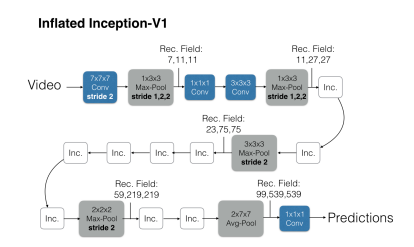
4.どうやって有効だと検証した?
(a)~(d)と提案手法の(e)を比較
3D-ConvNetを除き,基本ネットワークとしてImageNet pretrained-v1を使用
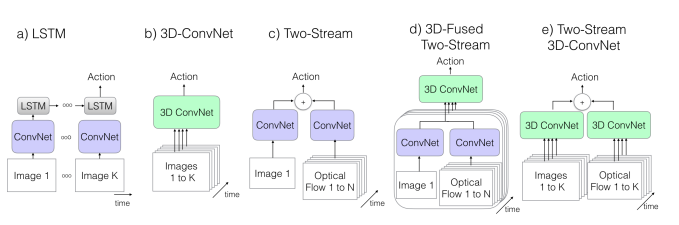
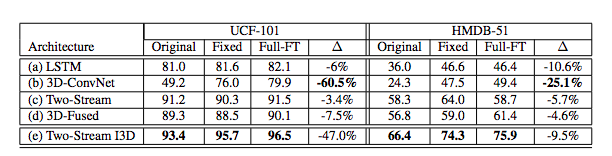
http://openaccess.thecvf.com/content_cvpr_2017/papers/Carreira_Quo_Vadis_Action_CVPR_2017_paper.pdf
5.議論はあるか?
6.次に読むべき論文はあるか?
Learning Spatio-Temporal Features with 3D Residual Networks for Action Recognition (https://arxiv.org/pdf/1708.07632.pdf)