想定読者 / 前提
- 読者: Web/バックエンド/フロントエンド開発に携わるエンジニア・リード・EM
- 前提:
- GitHub/GitLab/Bitbucket で Pull Request ベースの開発
- レビュー工数短縮 / 指摘の属人化課題あり
結論 (Point)
自動ソースレビューを導入し「最低限の品質基準チェック」「レビュー待ち時間短縮」「心理的安全性向上」を同時に実現することで、手戻りと属人化を削減し、開発サイクルを高速化できる。
理由 (Reason)
- 標準化: 機械がまず共通ルールを適用 → 人的レビューは設計意図/トレードオフ等の高付加価値に集中できる。
- 工数削減: 初期フィードバックが PR 作成直後に返るため「待ち」「再Push→再度待機」ループが減る。
- 心理的安全性: 初歩的/指摘しづらい事項(命名/スペース/nits)を bot が指摘し、指摘者の心理コストを軽減。
- 継続的改善: ルールをYAMLでコード化し PR で審議→学習サイクルをチームの資産化。
- メトリクス可視化: 自動指摘件数/種類/推移を追うことで技術的負債エリアや教育テーマを客観視。
具体例 (Example)
ツール: CodeRabbit
-
設定方法
- GUI でルール/モデル/閾値を簡易設定
- リポジトリ直下に
.coderabbit.yamlを置けばコードベースでバージョン管理
-
使用例
- GitHub - Pull requests
- IDE - VS Code
- GitHub - Pull requests
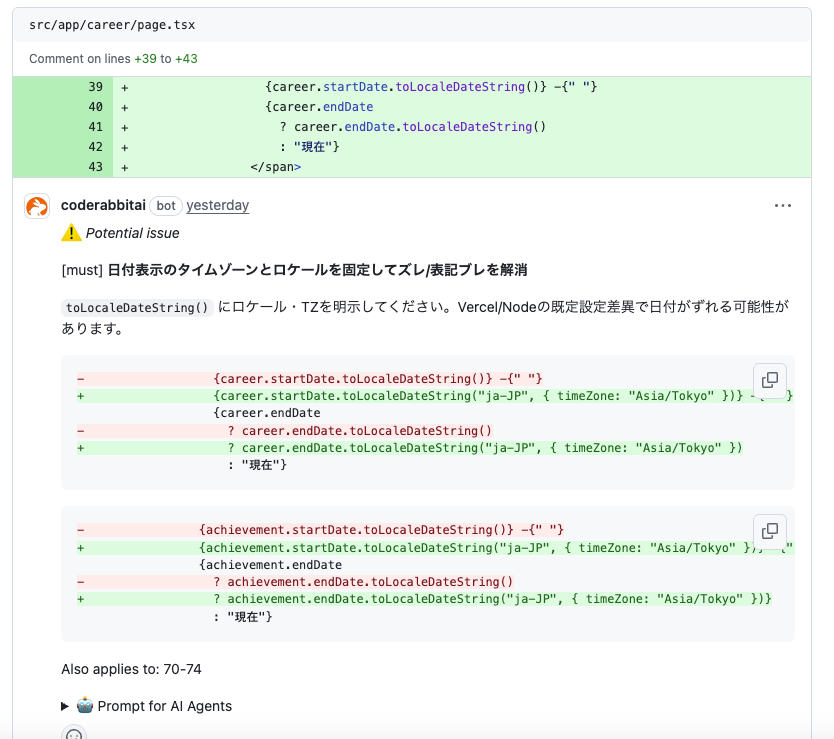
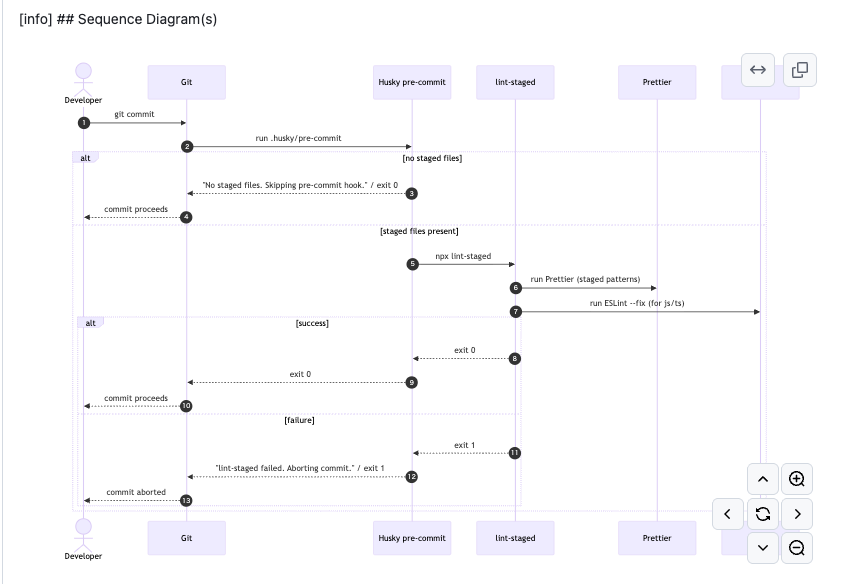
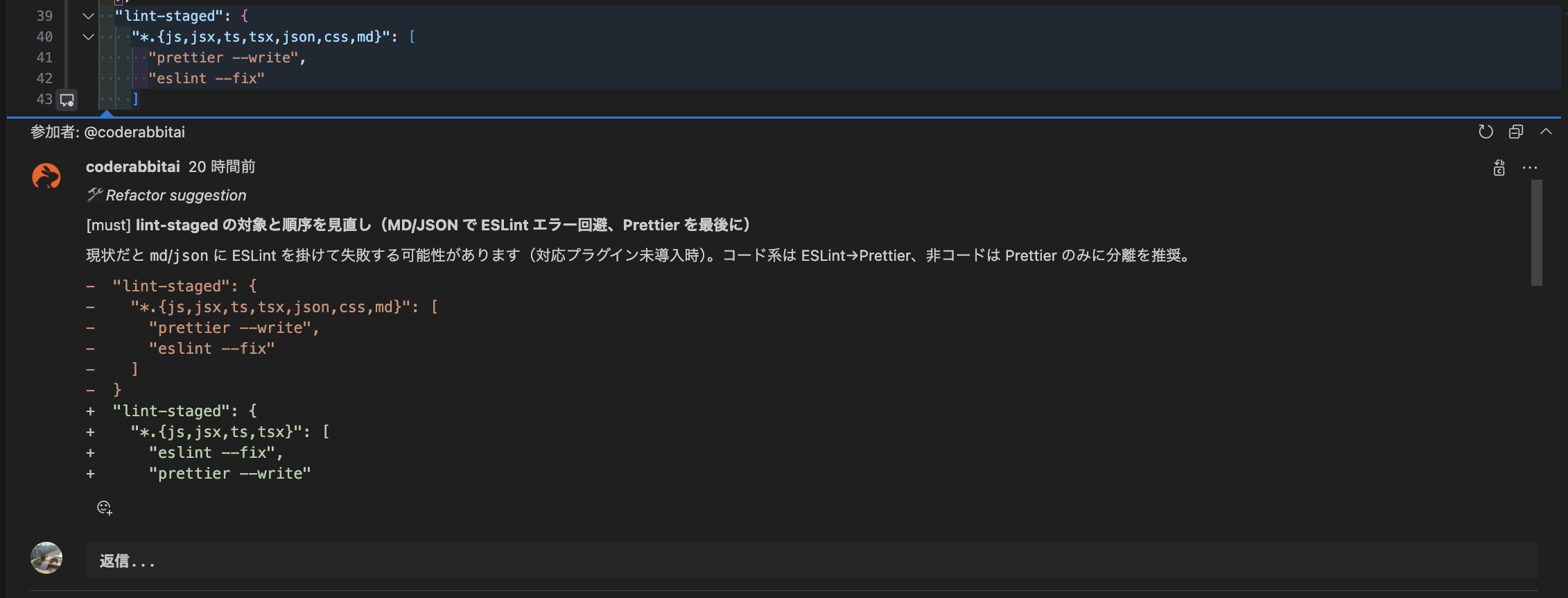
運用フロー(最小)
- PR 作成 → Bot が初回レビュー (数十秒)
- 自動コメントを開発者が即時修正 / 却下
- 人的レビューは設計・境界条件・ドメイン妥当性に集中
- 誤検知/追加したいルールをレトロスペクティブでチケット化 → YAML 更新
導入ステップ
- 現状計測: LOC / 平均レビュー待ち時間 / 1PRあたり指摘回数 / リード負荷
- 小規模(1~2サービス)で Read-only コメントのみ + 誤検知率記録
- ルールを調整/除外。逆に検出漏れを追加
- 拡大: 共通テンプレ + サービス固有差分
期待指標例
- PR 待ち時間: -30%(例: 平均6h→4h)
- 自動指摘 fix までの中央値: < 15分
補足 (心理的安全性の具体)
- 初学者が「この程度は聞きづらい」項目を bot が吸収 → 会話は建設的な設計議論にシフト
- 指摘を個人ではなくルールに紐付け → 人間関係ダメージ低減
リスク & 対策
| リスク | 影響 | 対策 |
|---|---|---|
| 誤検知 (False Positive) | 不要コメントが増え Bot 信頼性低下 → 有益指摘までスルーされ品質低下 | 誤検知率=誤検知件数/総指摘件数 を計測し閾値超過ルールはPR化し、変更履歴と指標推移を記録し継続改善 |
| 過剰ルール化 | 思考停止 / 創造性阻害 | "自動=最低限" 原則。設計/アーキは人的レビューを明文化 |
| 秘匿情報リーク | セキュリティ事故 | SaaS 設定でシークレットマスク / private scope 権限最小化 |
| 形骸化 | 改善停滞 | 月次で: 自動指摘 Top5 / 未対応割合 レビュー会実施 |
再結論 (Point 再提示)
自動ソースレビューは「品質基盤の自動化レイヤー」を設け、人の創造的レビュー領域を拡張しチームの心理的安全性とスループットを同時に押し上げる。
まとめ
- 自動化は目的ではなく「レビュー価値の再配分」手段
- まず計測 → 小さく導入 → ノイズ低減 → 指標運用で継続改善
- 標準化 + 心理的安全性 + スピード を一度に底上げできる投資価値が高い領域
余談
他選択肢メモ
- Cursor / AI IDE 内臓レビュー: ローカル文脈深掘りは強いが、ルールのチーム共有/トレーサビリティは薄め → 併用余地
- 自前 LLM + GitHub Actions: 拡張性◎ だが モデル管理 / コスト / 維持運用負荷が初期から重い