Google AutoMLとは
機械学習エンジニアなどのリソースが足りていない会社や組織でも、高度かつ高品質でカスタマイズされた機械学習モデルの構築が可能なクラウドサービス
とあるように、ユーザーはコードを書くことが全くせずとも機械学習モデルを構築することができます。
GCPには以前から、Cloud VIsion APIなどのいくつかの機械学習用のAPIがありますがそれとAutoML APIはどのように違うのでしょうか。
説明のために、 Cloud VIsion APIと AutoML Vision APIを比較します。
Cloud Vision APIは画像をアップロードするだけで、画像に何が写っているかなどがわかります。しかし、それはGoogleが設定した、いわば「お仕着せ」のキーワードでしか情報を示すことしかできません。これに対しAutoML VIsion ではユーザーが画像をアップロードし、その画像にラベル情報をつけることで自動的に訓練し、物体のイメージとラベル情報の関係を覚え込ませることができます。
従来のGCPの機械学習API
Cloud Vision API
画像認識のためのAPIで、画像のラベリングや顔や物体の検出、光学式文字認識(画像内の文字を判別)、不適切なコンテンツへのタグ付けなどができます。またGoogle 画像検索を活用しウェブ上で類似している画像を表示させることもできる。
Cloud Neural Language API
自然言語処理のためのAPIで、感情分析やエンティティ(著名人、ランドマークなどの固有名詞)分析、構文解析、コンテンツ分類などが可能です。
Cloud Translation API
翻訳のためのAPIで、テキストを任意の言語に翻訳したり言語の検出が可能です。Bloombergなどのニュース配信ではこのAPIを用いて数秒で各言語に翻訳し一斉に配信している。
その他
動画のラベルやコンテンツの検出をおこなうVideo Intelligence APIや音声ファイルから文字を生成するSpeech API、
対話生成をおこなうDialogflow Enterprise Editionなどがあります。またMachine Learning Engineというトレーニング済みのモデルをエンドポイントにデプロイしてAPIとして利用するMachine Learning Engineというものもあります。
AutoML API
ベータ版で以下の3つがサポートされています。基本的に教師ラベルのついていないデータセットは学習に使用しません。
語弊があるかもしれませんが、AIがAIのモデルを作るというイメージでしょうか。 Deep Learning モデルの試行錯誤を自動化し
ハイパーパラメータのみならず、層の結合方法や演算方法も含めたより広い探索を自動化していきます。
下の図がイメージ図ですが、Controller と Child Network という機械学習モデルが存在し、Child Network が実際にタスクを解くモデルで、Controller はそれを最適化していきます。

出典 https://ai.googleblog.com/2017/05/using-machine-learning-to-explore.html
AutoML Vision API
画像にラベルをユーザが指定することで、任意のラベルによる画像分類のモデルを構築します。
画像をアップロードしラベルをつけるだけでモデルの構築ができます。画像の前処理や、アーキテクチャの思考、パラメータチューニングなどはする必要がありません。
AutoML Natural Language API
テキストにラベルをつけることで、テキストの分類モデルを構築します。
具体的な用途として、テキストにラベルとして感情を表す単語をつけて 口コミの投稿などを分類することなどが考えられます。
AutoML Translation API
3つのAPIのうち唯一GUIでの操作にまだ対応していない。
データセットは以下のようにタブで区切られ、左が翻訳前,右が翻訳後の文章になるような
tsvファイルやtmv, csvファイルなどがサポートされている。
GUIでAutoML Vision APIを利用する
以下で、手順を説明していきます。何度も言いますが一切コードは書きません。
あらかじめ、判別させたい画像を大量にダウンロードしておいてください。
筆者の場合, サル・イノシシ・カラスの判別をおこなっていきます。画像数は各ラベル170枚集めました。
GCP Console で[リソースの管理] ページに移動し、新しいプロジェクトを選択または作成する。
他でプロジェクトの作成については詳しい説明があるので割愛します。
参考 https://www.magellanic-clouds.com/blocks/guide/create-gcp-project/
プロジェクトに対する課金を有効にします。
$300 相当のクレジットがあるのでしばらくは無料で使えます。
Cloud AutoML and Storage API(複数)を有効にする。
GCPのAutoML VIsionに入り、「Get started with AutoML」をクリックします。
数分待つと利用ができるようになりました。
データセットを作成する。
NEW DATASETをクリックし、データセットの名前をクリックし新規のデータセットを作成します。
ローカルから画像をアップロードする方法とCloudからアップロードする方法がありますが,
今回はローカルから画像をアップロードします。
「Upload images from your computer」をクリックすると画像が選択できます。
アップロードが終了すると以下のような画面に遷移します。この中でラベルに関係のないものが写っているなどのノイズとなる画像は手動で取り除いてあげます。
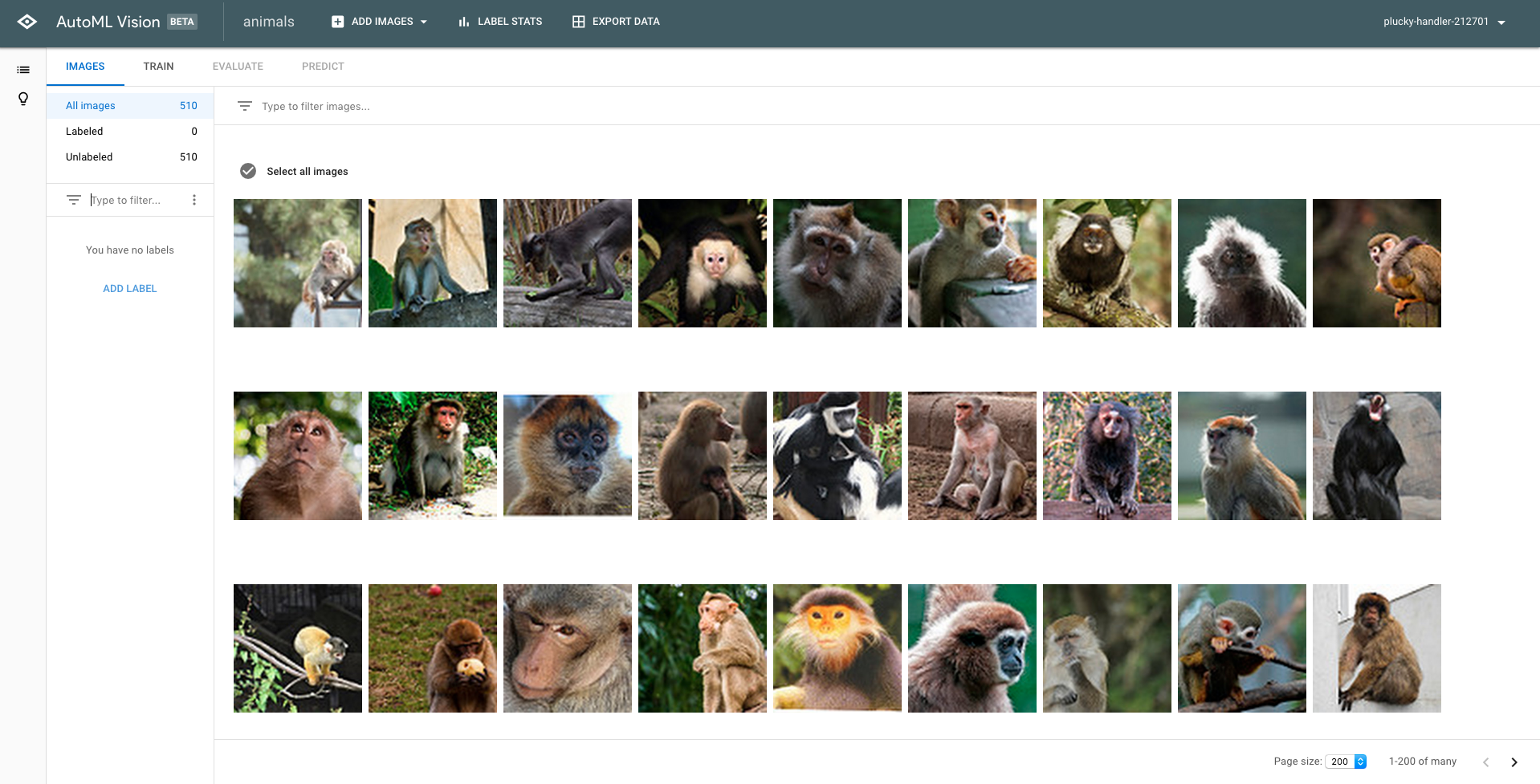
ラベルをつける
学習を行うために、ラベルをつけてあげます。「Add Label」 をクリックしてあげるとラベルをつけることができます。
公式ドキュメントによると1つのラベルにつき100枚程度の画像を用意することが推奨されているそうです。
また10枚のサンプルを選ぶと自動で残りのラベルを付けてくれる機能もあるようでしたが、筆者の環境ではなぜかエラーになってしまい利用することができず結局手動で各ラベル80枚ずつ付けました。

学習を開始する
いよいよ学習開始です。TRAINというボタンをクリックし、「TRAIN NEW MODEL」を押すことで学習を開始することができます。
筆者の環境では5分ほどで学習が終わりました。前処理やハイパーパラメータのチューニングなどの面倒臭い作業は一切ないです。
結果を確認する
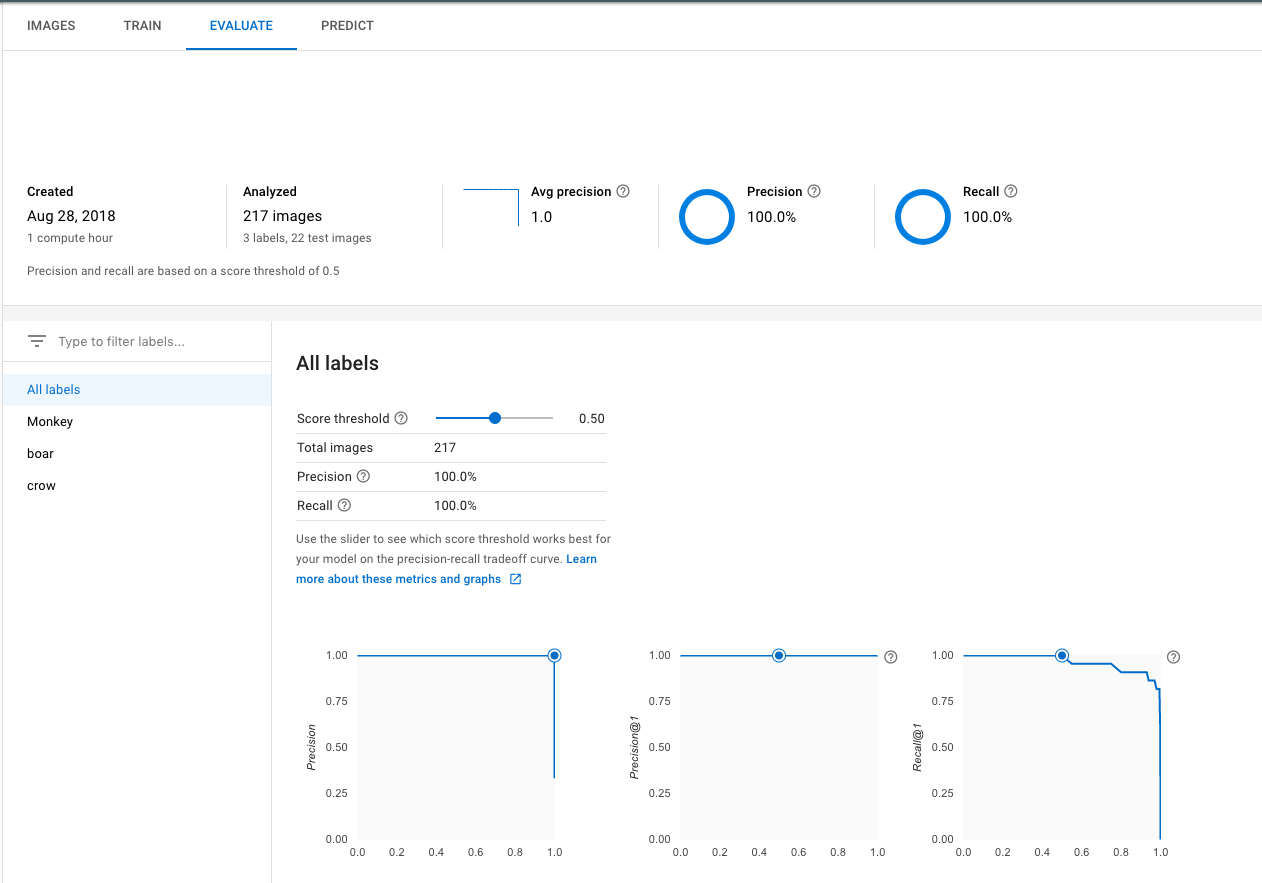
学習が終了したら「EVALUATE」をみてあげましょう。
217個の画像を学習し、22個の画像でテストした結果
適合率・再現率が共に100%となりました。テスト画像に関しては完璧に分類できたことがわかります。
新規画像を、モデルで予測する
「PREDICT」ボタンを押すと、作成したモデルに対し ローカル上の新規画像でもラベルの予測ができます


合ってることが確認できました。モデルはかなり精度が高いものになったようです。
まとめ
AutoMLで画像認識モデルを構築しました。全くコードを書くことがなく画像のアップロードとボタン操作だけで高い精度を持つモデルを構築することができました。唯一面倒だったところといえばラベルを手動で付けていくところでしょうか。非エンジニアの方には視覚的にわかりやすく画像認識が楽しめる点で画期的だと思います。エンジニアの方にはAPIを用いてサービス等の開発に活かせる点でも魅力的だと思います。