Azure Open AIの新機能「Add your data」の使用方法の概説、試してみた結果、そして私なり感じた4つの所感とその解決策?を紹介いたします。
※本領域は変化が激しいです。この内容は23年6月24日時点の情報となります
【記事の目次】
-
23年Buildでのデータサイエンス・AI系のアップデータについて
-
Azure Open AI「Add your data」のシンプル設定方法
-
Azure Open AI「Add your data」を使用した結果と、ChatGPT、
Bing AIチャットの比較 -
私の4つの所感と解決案?
4.1 引用元の引用部分について
4.2 データマネジメント、とくにファイルの賞味期限について
4.3 「Add your data」をセキュアに使用するための権限切り分けの難しさ
4.4 Azure Storage ExplorerでBLOBにファイルをアップロードが面倒すぎる
1. 23年Buildでのデータサイエンス・AI系のアップデータについて
Azure OpenAI Serviceの「Add your data」機能は、インターネット上の記事ではなく、自身(や自社、自部門など)のネット上に未公開であるファイルに対して、ChatGPTが扱うように、それらのファイルに関する情報を質問したりすることができる機能です。
23年のBuildで注目を浴びていました。
6月19日にPublic Previewになったので [1] 、試してみた結果、所感を紹介します。
なおその他、先日のBuildでのAI系の情報は、日本MSの皆様が先日発表くださった次の資料がおすすめです [2,3]。
[1] Introducing Azure OpenAI Service On Your Data in Public Preview
[2] Microsoft Build 2023 Azure AI&ML 最新アップデート
[3] Microsoft Fabric - Next Generation Cloud Data Analytics Solution
2. Azure Open AI「Add your data」の使用方法概説
2.1 はじめに
「Add your data」の使用方法については、既に丁寧にまとめてくださっている方が多いので、詳細は以下の参考記事をご参照ください。本記事ではシンプルに記載します。
【使用方法の解説が丁寧な参考文献】
[4] 独自ナレッジをノーコードでChatGPTに連携!Azure Open AI「Add your data」
[5] Azure Open AIの「Add your data」をAPIとして使う!
[6] Azure OpenAI on your data でノーコードで ChatGPT 対応エンタープライズサーチを構築する
[7] Azure OpenAIで独自データ追加機能(Add your data)を試してみた
[8] Azure OpenAI Service “on your data” でChatGPTに自社データを組み込む
[9] 公式ドキュメント:Azure OpenAI on your data (preview)
とくに、[6] ではエンタープライズ向けを想定したセキュアに設定についても解説して下さっているのでおすすめです(以下図引用)。

2.2 「Add your data」の使用方法
「Add your data」の使用方法をシンプルに概説しますと、
(1) Azure OpenAIが使用できるように、「Azure OpenAI Serviceへのアクセス申請」を提出し、使用できる状況にしておく(アクセス申請フォームはこちら)
(2) Cognitive Servicesから「Azure OpenAI」を作成する
(3) ストレージ アカウントから、「ストレージアカウント」を作成し、使用したいyour dataとなるファイルを入れるためのコンテナー(BLOBストレージ)を作成する
(4) 「Azure Storage Explorer」[link]をダウンロードして、ローカル環境にインストールする(ダウンロード方法が分かりにくいのですが、「Azure 上のクラウド ストレージを管理する」の横にある、青い四角に白地で「オペレーティングシステム」と書かれているボタンをクリックし、OSを選択するとダウンロードが開始されます)
(5) 「Azure Storage Explorer」でローカルからファイルをAzure上のBlob Containersにアップロードする(今回は以下のように、DQN論文の最初のarxiv版とNature版、そしてMPO論文と3つの論文PDF(英語)を用意してみました(DQN_arixv_pdf、DQN_Nature、MPO)

(6) Azureに戻り、「Cognitive Search」を作成する
(7) 「Cognitive Search」の「データの接続(インポート)」をクリックし、「Azure BLOB ストレージ」を選択し、(3)で作成したBLOBストレージを選択し、インデックス名(例えばazureblob-index)をメモしておき、インデクサーの作成で、インデックを作成します
※ 今回は3ファイルなので一瞬で終わりますが、ファイル数が多いと時間がかかります

(8) これでCognitve Searchと「your data」が繋がりました。次はAzure OpenAIと繋げます。「Azure OpenAI」から「Azure OpenAI Studioに移動する」をクリックして、Azure OpenAI Studioを開きます
(9) 「Bring your own data」をクリックします
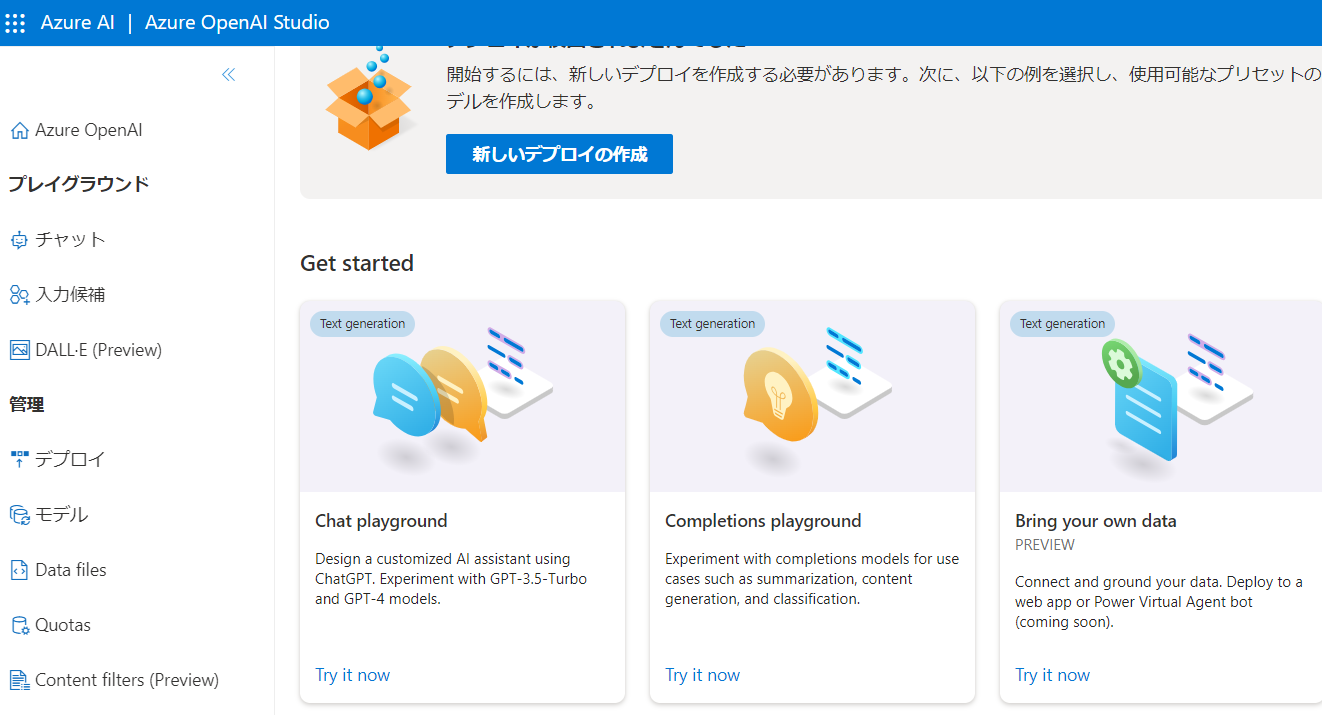
(10) 「新しいデプロイの作成」をクリックします。ベースモデルは「gpt-35-turbo」しか選べないと思います(GPT-4は別途申請が必要かと)。適当・適切な名称でWeb Appsを作成します
(11) 本命の「Add your data」の部分まで来ました。「Select or add data source」の画面になるので、「Select data source」で今回のBLOBを、その他、Cognitive Searchの設定を入力します。この際、「Enter the index name」に、メモしておいた作成したIndexe名を記載します

(12) 以上で完了です。「ChatGPT プレイグラウンド (プレビュー)」画面になり、画面左側には、「アシスタントのセットアップ」が記載されているかと思います。「Add your data (preview)」部分の処理が終わるのを待ちます
これで設定完了です。次章では今回登録した3つのPDFに関する質問を試していきます。
3. Azure Open AI「Add your data」を使用した結果と、ChatGPT、Bing AIチャットの比較
今回your dataとして、「DQN論文のarxiv版、Nature版」、「MQN論文」と、3つのPDFを加えました。
これらについて、「Add your data」で質問した結果と、ChatGPTに質問した結果、Bing AIチャットの結果を比較してみます。
「Add your data」のパラメータ設定はデフォルトのままです。
「過去のメッセージを含む」は10件、「温度」は0で、「上位p」を1としました。
質問内容と回答の様子を以下に掲載します。今回とくにプロンプトに工夫はせず、シンプルに質問しました。続いて、会話のやり取りを詳細に見ていきます。
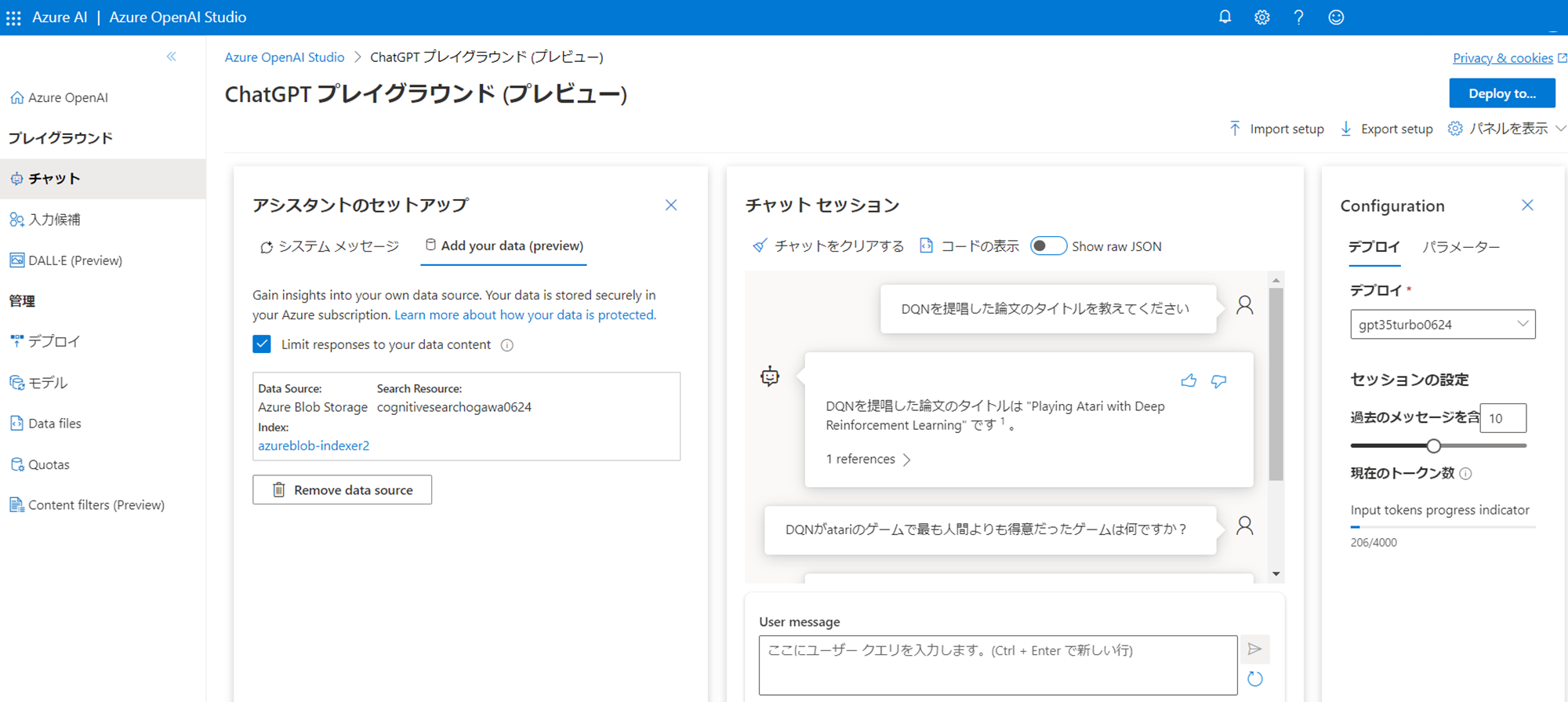
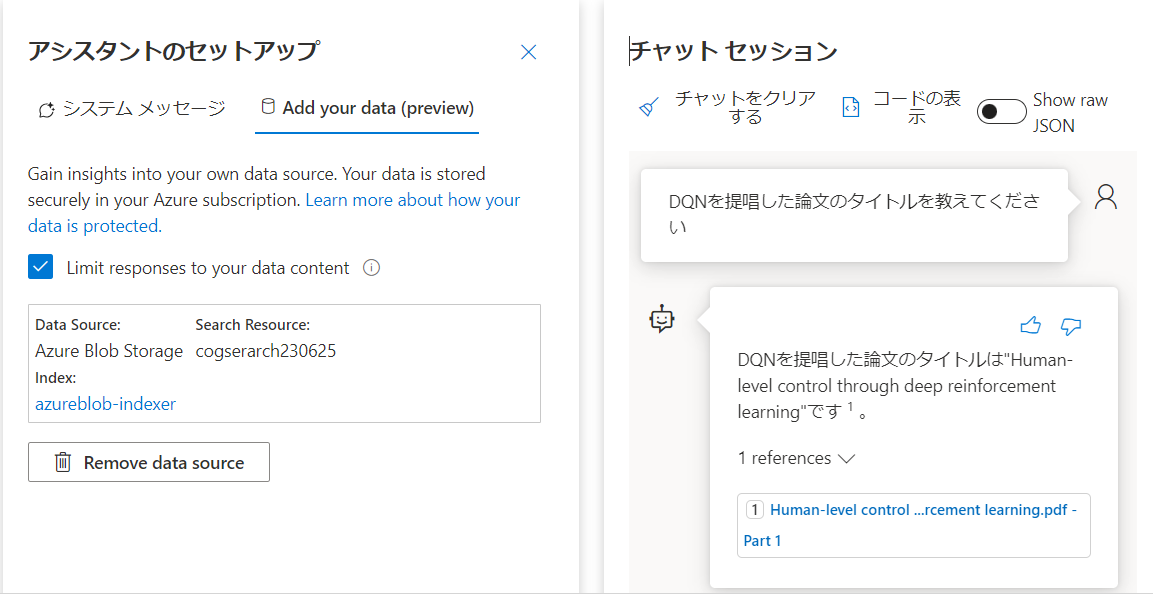
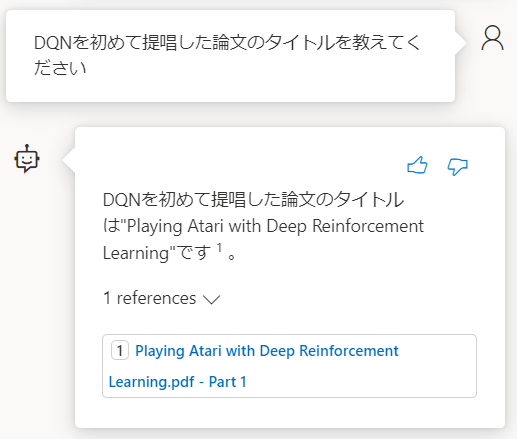
質問と回答結果の様子です。まずは「DQNを提唱した論文」について尋ねました。
すると以下のように回答が返って来ました。またその回答がどのファイルに基づいているのか、referenceも提示されています。
今回ですと、Nature版のDQN論文(Human-level control・・・)を参照して回答したようです。この点については後ほど、「4つの所感」で振り返ります。
それでは次々と質問していきます。
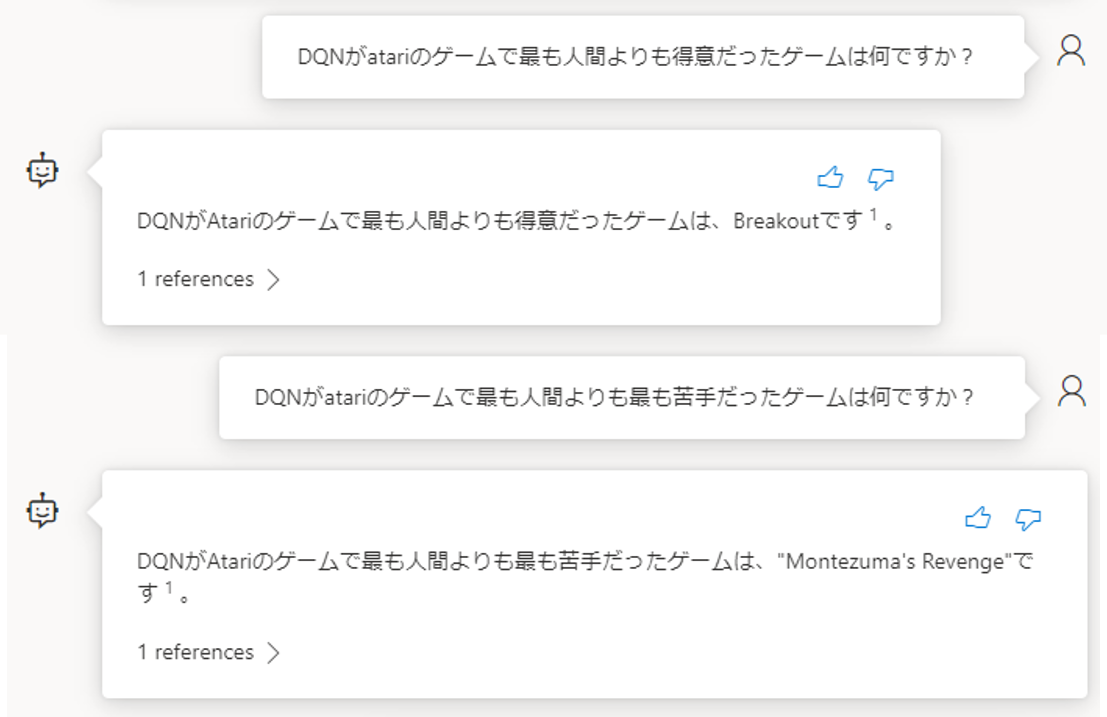

この最後の質問、「下から2番目にスコアが悪かったゲーム」については、きちんと回答が返ってくるときと返ってこないときがありました。
この回答の情報は、論文の図3にしかありません(論文中にBreakoutやMontezuma’sRevengeについては良い成績だった、悪い成績だったと解説がありますが、Private Eyeについては図3にしか文字の掲載がありません)。
そのため、図3の並びをきちんと返せるかが際どいところです。
上記の会話例はうまくいったパターンです(GPT-4を使えばもっと間違えずに答えてくれるかもしれません)

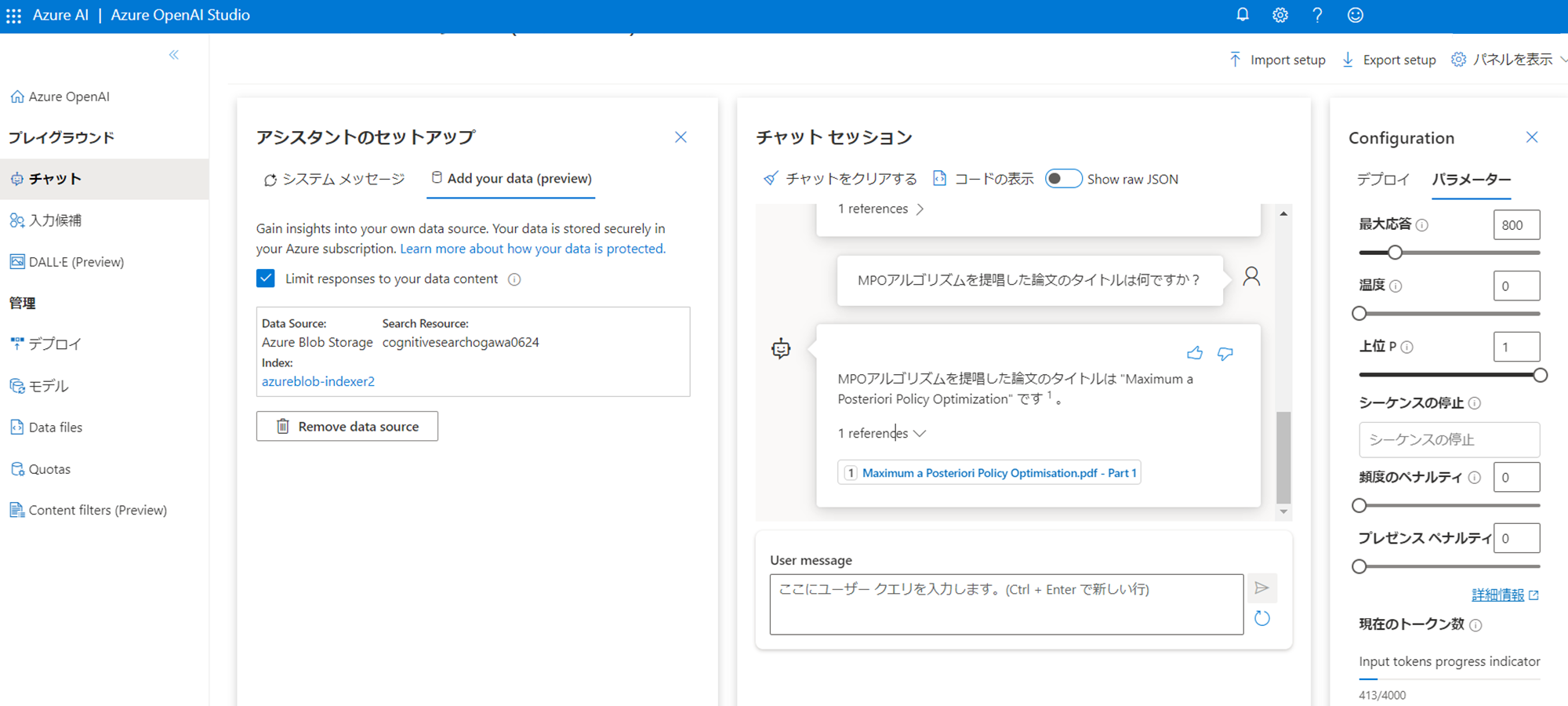
次にMPOアルゴリズムに話題を変えます。

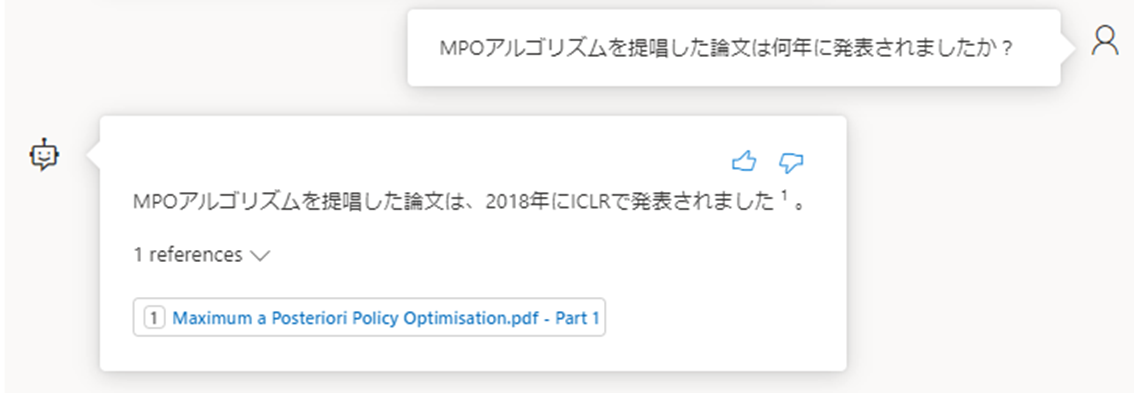
なお、MPOアルゴリズムのタイトルはぼちぼち間違えることがありました。
"Maximum a Posteriori Policy Optimization"ではなく、
"Maximum a Posteriori Policy Optimization for Reinforcement Learning"と回答するなど。
以上、手元のyour dataをアップロードして、Azure OpenAIに質問し回答を得た結果となります。
続いて、同じ質問を、ChatGPT、Bing AIチャットに行った結果を掲載します。
ぼちぼち間違いがありました。
【ChatGPT】MPOアルゴリズムの論文の著者名、発行年が間違っていました。論文タイトルは正しいので、その他の部分が間違っているとユーザーは気付きづらいかもしれません。
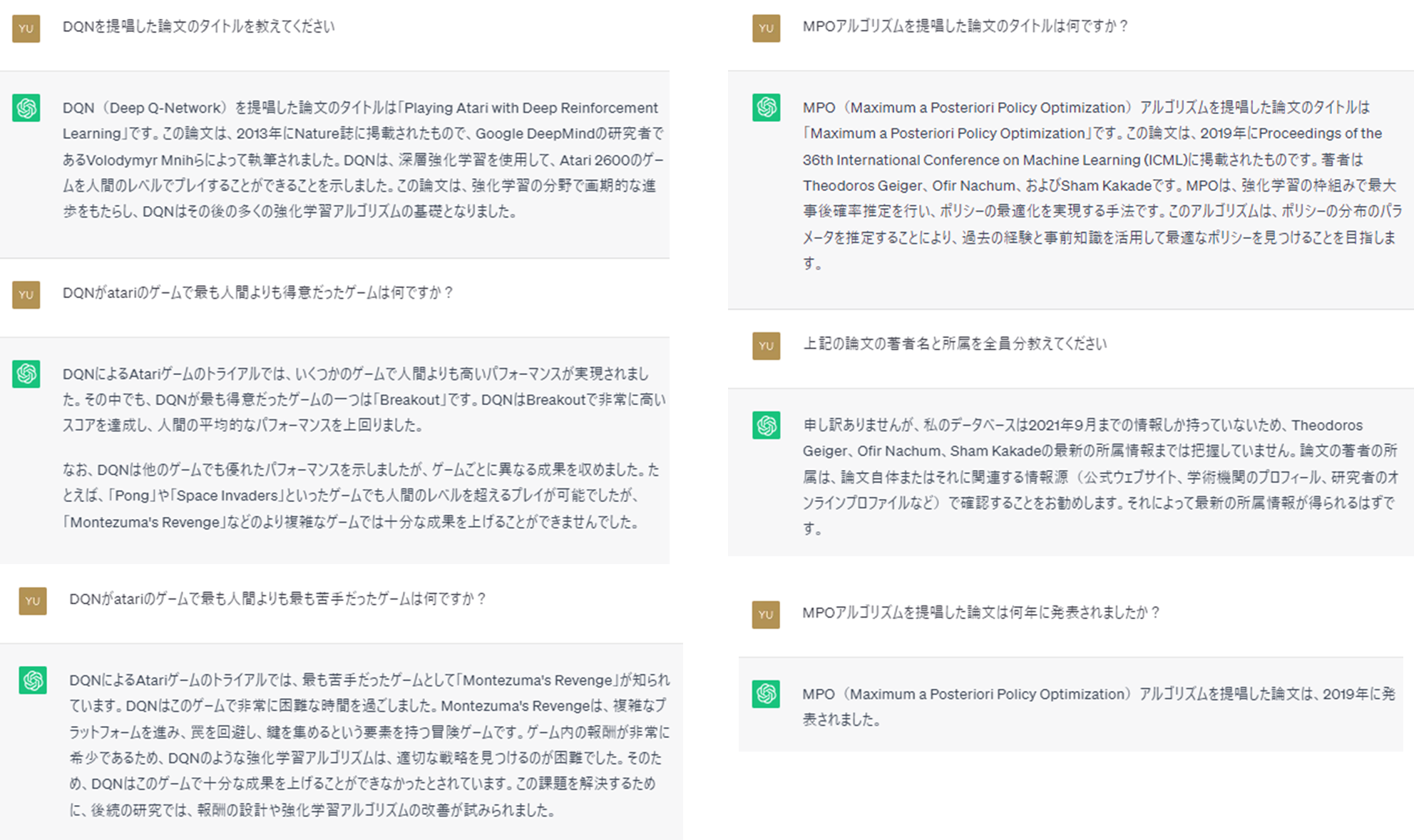
【Bing AIチャット】MPOアルゴリズムの部分ですが、最初はきちんと著者名を答えられているのに再度聞き返すと、全然違う誤った答えが返ってきて、かつ引用元がないです・・・
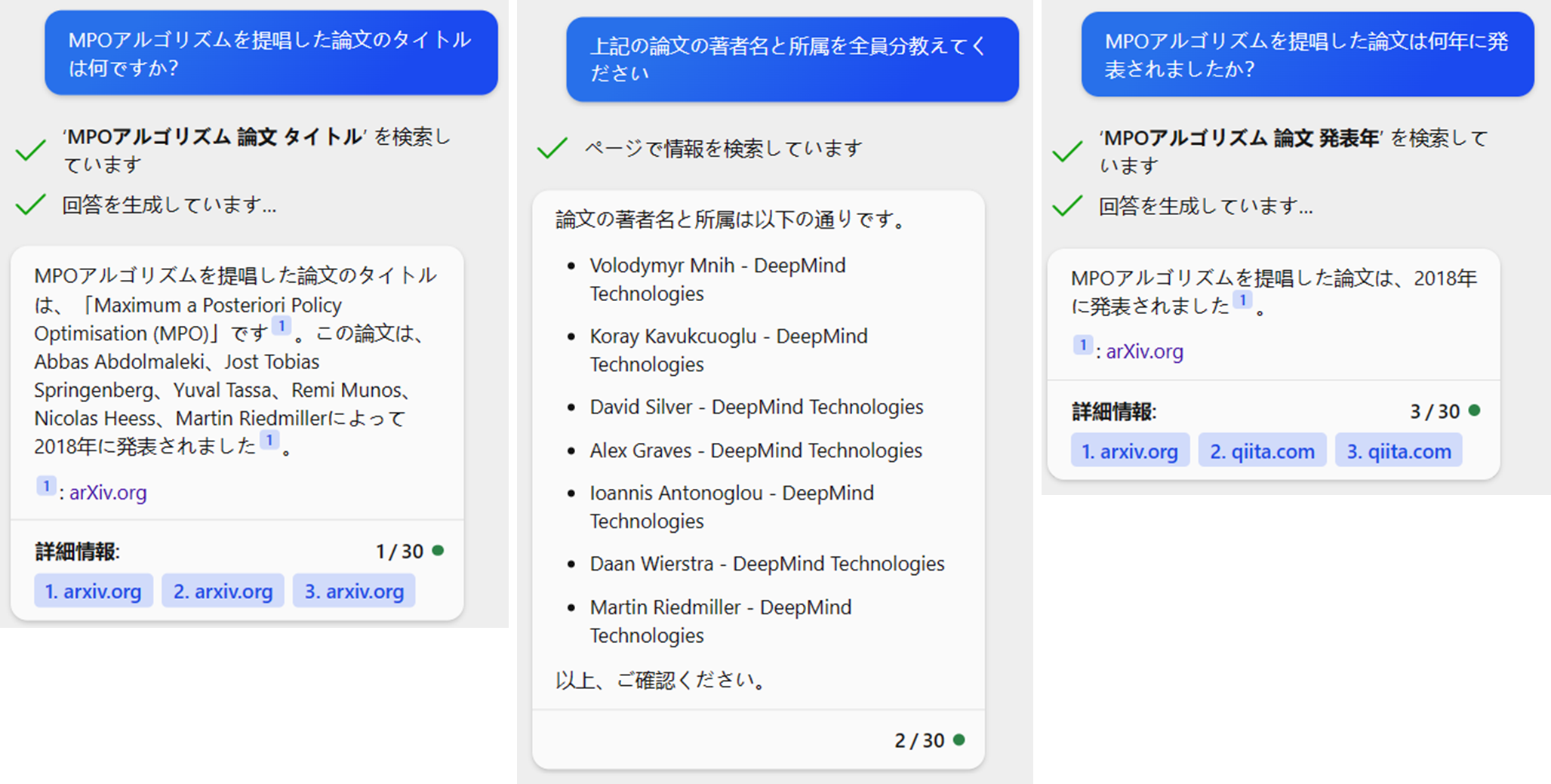
以上、「Add your data」を使用してみた様子と、ChatGPT、Bing AIとの比較でした
4. 私の4つの所感と解決案?
4.1 簡単操作で、自前のデータについて質問や要約やらできるのは嬉しい。引用元の引用部分が分かるともっと嬉しい
ChatGPTとは異なり、Bing AIチャット、そして「Add your data」は回答の元となったサイトや文書ファイルをreferenceとして提示してくれます。
これはその回答が本当に正しいのかをチェックするためにはとても重要なので、嬉しいです。
一方でBing AIチャットも「Add your data」も引用文献を提示するに留まり、回答のカギになった部分を引用文献から提示してはくれません。
例えば、最初の質問「DQNを提唱した論文のタイトルを教えてください」に対しては、論文中の
To achieve this,we developed anovel agent, a deep Q-network
(DQN), which is able to combine reinforcement learning with a class
of artificial neural network16 known as deep neural networks.
の部分を明示的に示し、このファイルで上記の記載があるため、「DQNを提唱した論文のタイトルはhogehogeです」、と回答があると嬉しいです。
社内で社内規定やルールの文書を「Add your data」に放り込んで、チャットで回答を得ても、
文書内のどの部分を見て回答したのか、その引用部分が明示されない現状では、チャットの回答が本当に正しいのか信じられず、結局、そのファイルの中身を見て確認することになるでしょう。
(ただし、膨大なファイルから、そのファイルを見れば良い、だいたいの回答はこんな感じか、と分かるだけでも助かる場面はあるでしょう)
4.2 「Add your data」をうまく使用するには「データマネジメント」、とくにファイルの賞味期限が重要になりそうに感じます
今回この仮説を検証するために、あえて、DQN論文は最初のarxiv版(2013年)と後発のNature版(2015年)の2つを使用しました。
そして上記の結果のように、「DQNを提唱した論文のタイトルを教えてください」と聞くと、後発のNature版「Human-level control through deep reinforcement learning」と回答されました。
本当は最初にDQNを提唱したArxiv版の「Playing Atari with Deep Reinforcement Learning」を回答して欲しいところです。
以下のように明示的に聞くと、期待通りに答えてくれます。
この、「同じ情報が2つ以上のファイルに記載されている状態」 というのは非常にやっかいです。
例えば、社内文書で「Add your data」を使用するとして、ユーザーが「リモートワークは週に何回可能か?」を知りたいとします。
そこで、「リモートワークは週に何回可能ですか?」と尋ねると以下のように回答が返ってきたとします。
「週に4回可能です」reference リモートワークガイド_23年度.pdf
上記の回答によると、ファイル「リモートワークガイド_23年度.pdf」 では週4回と記載されているようですが、新型コロナウイルス感染症が5類感染症に5月8日から引き下げられているので、そのタイミングで規定も変わっている可能性があります。
例えば、「リモートワークガイド_23年度_5月改定.pdf」というファイルがあり、
「リモートワークは週に3回可能です。しかし上長の許可があればこれまで通り4回以上も可能です」
と改訂されていたら、チャットで得た回答は間違っていたことになります。
さらに、「リモートワークガイド_23年度_5月改定.pdf」が最新と思ったら、この7月から夏に向けて、「リモートワークガイド_23年度_7月改定.pdf」が存在する可能性もあります。
ユーザーにとって、どのファイルが最新の情報が記載されているものであると確定するのは難しい問題です。
この、「最新の正確な情報を記載しているのはどのファイルか問題」
そして、「古い情報のファイルは消してくださいと、ユーザーへ周知・徹底」
は、実運用上、なかなかに難しいと感じるところです。
4.3 「Add your data」をセキュアに使用するための権限切り分けの難しさ(例:部長以上のみ閲覧可能ファイル、特定の部署のみ閲覧可能ファイル)
エンタープライズに使用する際に、Addしたいファイルが「社員全員が閲覧可能な権限のファイル」であれば問題はありません。
また個人利用の範囲においても問題は発生しないでしょう。
一方で、社内の上下(部長以上のみ閲覧可能ファイル)や社内の左右(特定部署のみ閲覧可能ファイル)に対して、権限を切り分けながら「Add your data」を作り込むのは、なかなか大変かもしれないと感じました。
部長以上のみ閲覧可能なファイル内の情報を、一般社員がチャットから得られると困ります。
AzureのBLOBストレージ、Cognitive Searchでは「Azure ロールの割り当て」にて、閲覧権限を設定することが多いです。
ただし、私の認識ではCognitive Searchやそれを呼び出すホスト元へのアクセス許可は「Azure ロールの割り当て」で対応できますが、特定の文書だけ検索結果から権限に応じて表示・非表示をユーザーごとに切り分けるは、かなり難しいという認識です(以下参考)。
(Azure Cognitive Search のセキュリティの概要 > コンテンツへのアクセスを承認する)
(Azure Cognitive Search のセキュリティの概要 > ドキュメントへのアクセスを制限する)
ドキュメント レベルのユーザーアクセス許可 ("行レベルのセキュリティ" とも呼ばれます) は、Cognitive Search ではネイティブにサポートされていません。
そこを強引に頑張ってみた記事例は以下などがあります。
Azure Cognitive Searchで権限制御してみた
「Add your data」はAzure OpenAI Serviceであり、「Cognitive Search」に基づいて「Add」されるデータが決まるので、「Cognitive Search」でしっかりと権限処理しておくことが重要だと感じています。
簡単に終わらせるなら、
①上下、権限が変わる文章については誰でも閲覧可能文書のみを「Add your data」で扱う
②左右、部署ごとに閲覧権限が変わる文章については、部署ごとのBLOBを設定し、部署ごとのCognitieve SearchとOpenAI Add your dataを作成する
は一案のように感じます
本気で考えるとこの問題は相当難しいです。
複雑になりすぎるので、「Add your data」は「めちゃ大きな範囲に作る or めちゃ小さな範囲に作る」が実はセキュアかもしれない?と感じるところです。
- めちゃ大きな範囲:社内誰でも閲覧可能
- めちゃ小さな範囲:個人レベルから自分の課レベルくらい
中くらいのサイズ(対象ユーザー数)に対しては、権限整理が大変過ぎるのでは、という所感でした。
4.4 Azure Storage ExplorerでBLOBにファイルをアップロードが面倒すぎる
O365ユーザーであれば、ファイル群はOneDrive(もしくはローカル)にあることが多いかと思います。
OneDriveとAzure BLOBを同期させるのは、「Azure Logic Apps」もしくは「Power Automate」で簡単にできますが、ファイルが2箇所に重複して存在する場合や、アクセスしにくくなる場合があります。
面倒です。
「BLOB」ではなく「Azure File」であれば、共有ファイルサーバーにできるため、ローカル環境にマウントできます。
しかし「Azure File」はCognitive SearchやAzure OpenAIからアクセスできません(コンテナー:BLOBのみ対応。コマンドラインからならAzure FileでもCongnitive Searchはできそうですが、Azure OpenAIが対応できるかは分からないです [link])。
例)Azure 第15回『やってみようシリーズ:Azure Files/Azure File Syncを使ってみよう!』
Azure Fileではなく、BLOBのローカルマウントは結構面倒です。
【作戦1】
Windows 10 Proであれば、NFS(network file system)が使えるようなのでいける可能性があります(だが私の手元のPCはwin 10 home。WSL使う手もあるが面倒か・・・)
【作戦2】
NFSでなく、SFTP(SSH File Transfer Protocol)もBLOBで使えるようなので、こちらを使う作戦。
上記の参考記事をご覧いただくと分かりやすいかと思います。
手順としては、本記事のはるか前に記載した、「「Add your data」の使用方法をシンプルに概説しますと、」の部分の、
(3) ストレージ アカウントから、「ストレージアカウント」を作成し・・・
にて、Blobを作成する際の設定で「階層型名前空間」を有効にし、「SFTP」を有効にしてストレージアカウントを作成します。
そして上記1つ目の記事を参考にユーザーを追加し、SSHパスワードを取得します。
次に、クラウドストレージ・FTPサーバ等をPCのドライブにできるソフトを用意します。
上記の記事では「RaiDrive」が使用されていますが、同様の機能(SFTPをサポート)であれば他のものでも大丈夫かとは思います。
「RaiDrive」 クラウドマウンターの一種です。
※Google Drive, OneDrive, Dropbox, WebDAV, SFTP, FTP, AWS S3, Google Cloud Platform などのクラウドストレージやサーバを Windows のネットワークドライブとして扱うことができる、Windows 向けのクラウドサービス管理ソフト
※【免責】RaiDriveの商用利用やセキュリティについては各自最新情報と使用するプランに応じてお調べください。本記事では、上記の参考記事と同じくひとまず無料版を使用しました
上記の参考記事通りに進めると、ローカルのZあたりにBLOBがマウントされ、そのフォルダにファイルをコピーしたり作成したりできるようになります。

そして、Azure側でBLOBの内容を確認すると、以下のように同期されていることが分かります。

これで、BLOBとPCのローカル環境からのフォルダがすぐに連携できるようになりました。
個人利用で簡単にデータをどんどん溜めていって、Auzre Open AI「Add your data」を使用し、そのデータ群にGPT-3.5turboやGPT-4を利用してチャットベースで情報検索するにはこれが一番簡単かな?と思います
【注1】 ストレージアカウント作り直したので、Cognitive Searchのインデクサーと「Add your data」も作り直しです
【注2】 Cognitive Searchでうまくストレージアカウントを自動検出してくれない場合は、接続文字列を直接打ち込むと良いです。Azure OpenAIでCongnitive Searchを検出してくれない場合も直接、名前打ち込むと良いです。なぜかうまくいかないときは、Azure OpenAI Studioを再起動するのも良いです。とくに、起動させてから別のAzureリソース作ると、うまく読み込んでくれないときがあります。
【注3】 インデクサーを再度設定しますが、ファイル追加のたびにインデックを作り直しは普通はしないです。定期実行になります。そのため、Azure OpenAI「Add your data」側に反映されるにはインデクサーが更新される時間を待つ必要があります(すぐに反映させたい場合は手動でindexerを実行し、indexを作ります)
【注4】 普通はインデクサーの再実行で新たなファイルをindexしますが、何故か私の環境ではうまくいかないことがありました(Congnitive Serviceの使い方の問題か?)。そこで面倒なので、再度indexとindexerを作り直しましたが、それでもうまく行かず、Cognitive Searchから作り直しました。ここまでやれば、追加した新しいファイルにも質問応答が処理してもらえましたが、何らバグっている気がします(おそらくAzure OpeAI Studio内が怪しい)。継続的にファイルを追加して「Add your data」を安定稼働させるには、一苦労がありそうな予感です
さいごに
以上、Azure OpenAIの「Add your data」の設定・使用方法の概説、そして私の4つの所感でした。
私の所感と解決案?を整理し再掲いたします。
4.1 簡単操作で、自前のデータについて質問や要約やらできるのは嬉しい。引用元の引用部分が分かるともっと嬉しい
➡ユーザー側では解決しづらいので改善待ちか
4.2 「Add your data」をうまく使用するには「データマネジメント」、とくにファイルの賞味期限が重要になりそうに感じます
➡古い情報のファイルは消す、最新版のみを置く
4.3 「Add your data」をセキュアに使用するための権限切り分けの難しさ(例:部長以上のみ閲覧可能ファイル、特定の部署のみ閲覧可能ファイル)
➡権限切り分けが複雑過ぎる状態においては「Add you data」の使用はひとまず様子見
4.4 Azure Storage ExplorerでBLOBにファイルをアップロードが面倒すぎる
➡BLOBのSFTPを有効にしたストレージアカウントを作成し、クラウドマウンターを利用して、ローカルにマウントしておく
「Add your data」をはじめ、様々なサービスが登場したばかりであり、これからどんどんと改善されていくと思うと、とても楽しみです。
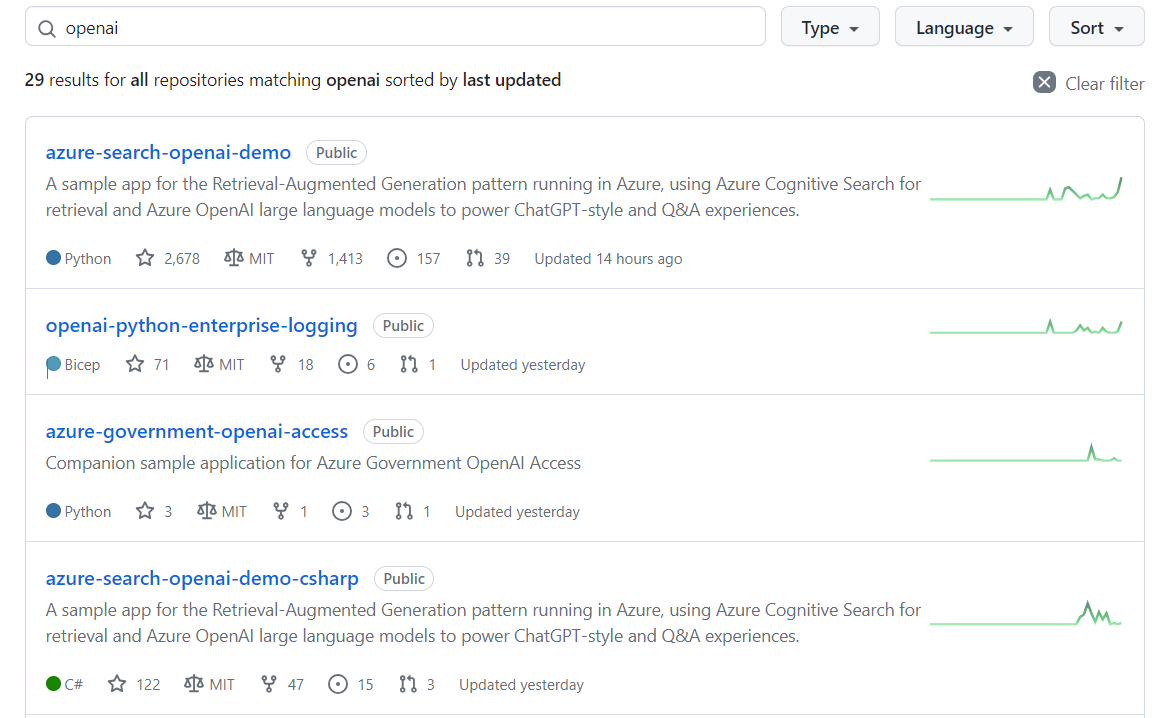
なお、AzureとAzure OpenAIを利用した各種アーキテクチャは以下のGitHub「Azure Samples」
にて、openaiという名前が入っているリポジトリを参考にするのも良いでしょう。
本記事執筆時点では29個のリポジトリがあります
以上、長文となりました。
ご一読いただき、ありがとうございました。
小川 雄太郎
【免責】
本記事の内容は執筆者の意見/発信であり、執筆者が属する企業等の公式見解ではございません