はじめに
Microsoft Build 2023 で発表された次世代の SaaS 型のデータ分析プラットフォームである Microsoft Fabricを紹介します。
内容は多いため、後でも読むように、ブックマークやストックをお勧めします。
Microsoft Fabric は Azure Service Fabric ではありません!
違うプロダクトなので、名前を間違えないようにお願いいたします。
すべてのデータ、すべてのチーム、すべてを 1 か所で

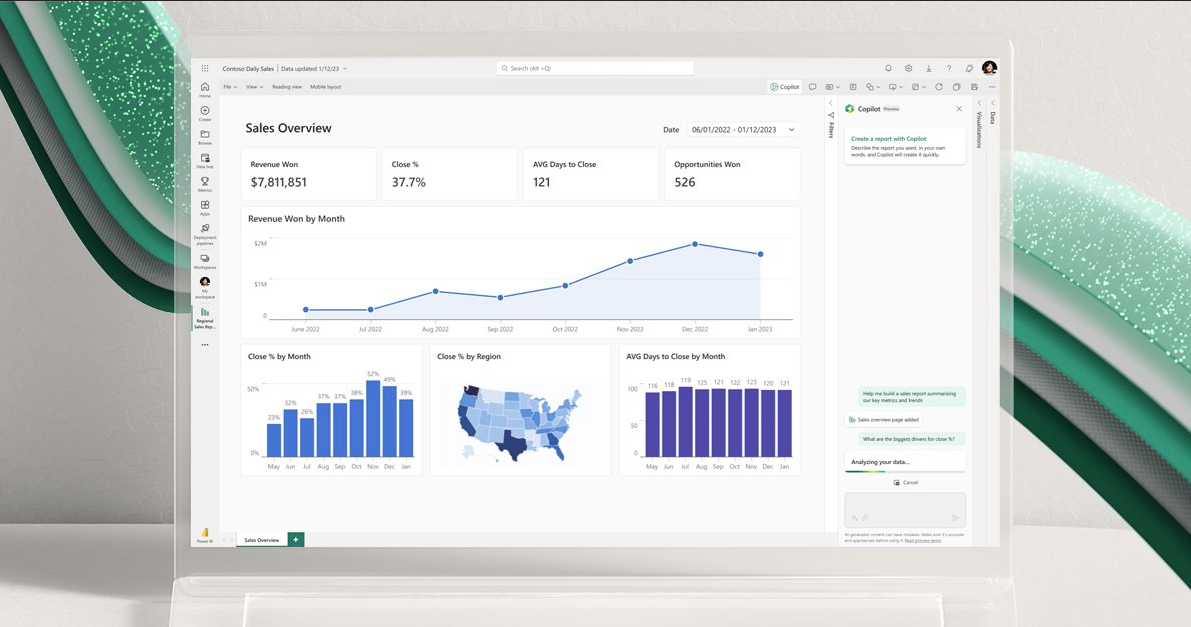
この記事を書く時点では、Microsoft Fabric はパブリックプレビューの段階であり、今後、機能追加、機能改善、または変更などもありますので、期待しましょう。
詳細に関しては、Microsoft Fabric Docsをご参考ください。
Microsoft Fabric とは?
Microsoft Fabricは、レイクセントリックのオープンで全面的な SaaS データ、分析、AI プラットフォームを提供し、データ資産の全領域に対応する統合製品を提供します。Microsoft Fabric を通じて、初心者から経験豊富な専門家まで、Microsoft OneLake を基盤にした使いやすい共有 SaaS エクスペリエンスを通じて、データベース、分析、メッセージング、データ統合、ビジネスインテリジェンスのワークロードを利用できます。
そして、Microsoft Fabric では、データ駆動型組織におけるすべての Data & AI ペルソナ及び要件に対するワンストップソリューションです。
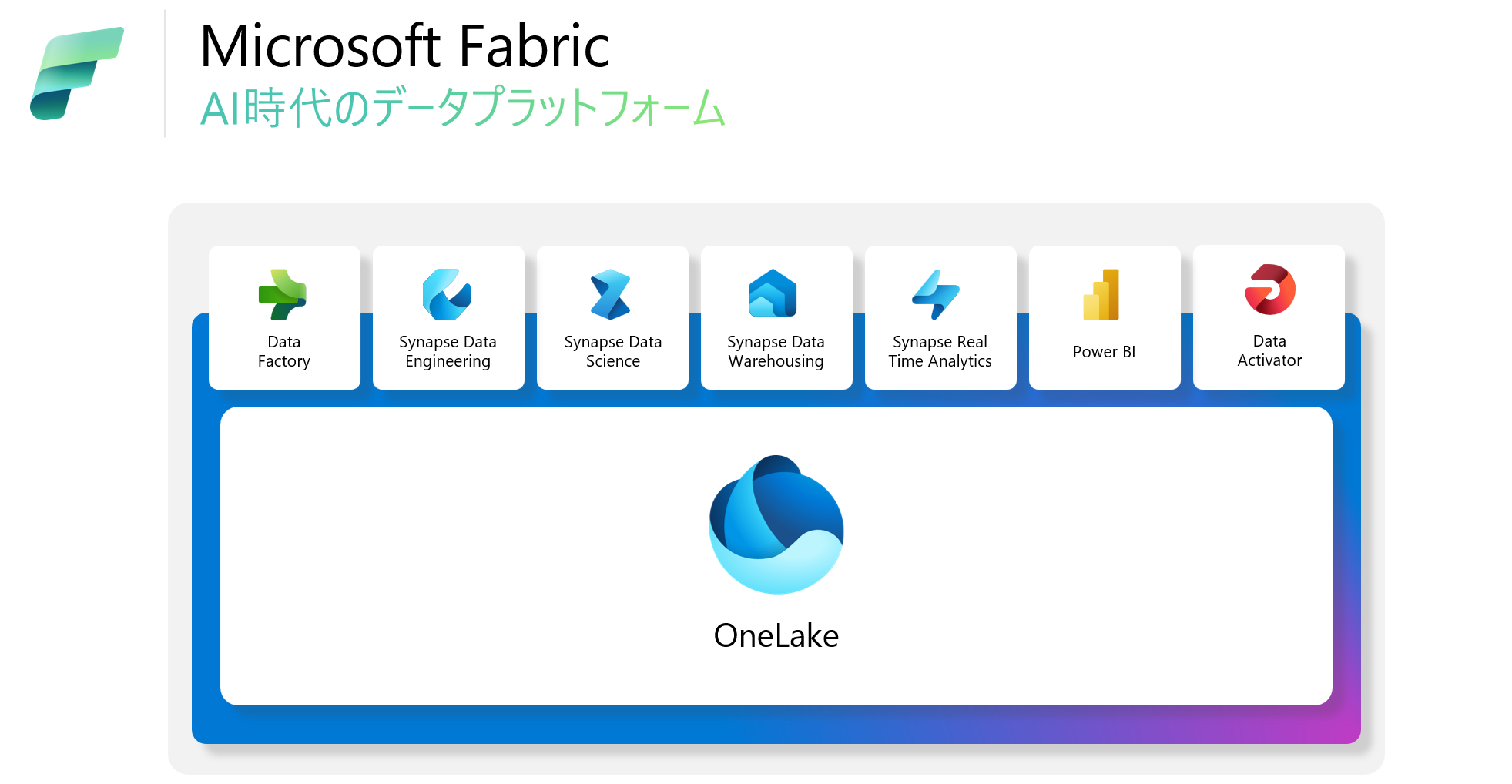
例えば、下記のようなことができます。
- データのオーケストレーションや変換のための、Data Factory機能
- PySpark、R、Scala、SparkSQLなどの言語を使って、ノードブック上で開発しながら、レイクハウスを操作するための、Synapse データエンジニアリング機能
- T-SQL ユーザー向けのSQLデータウェアハウスで、変換、スタースキーマを構成していくための、Synapse データウェアハウス機能
- データサイエンスエクスペリエンスペルソナ向けに構築やAzure ML を活用したモデル管理や実験追跡を含むエンドツーエンドのデータサイエンスエクスペリエンスを提供しつつ、SynapseML ライブラリを介した Spark 用の ML ツールのための、Synapse データサイエンス機能
- ストリーミング、取り込みからクエリまでのほぼリアルタイムでありながら、あるゆる規模のデータに対して、高性能、低レイテンシー、高鮮度のソリューションのための、Synapse リアルタイム分析機能
- 次世代のデータフローGen2、新たに DirectLake モードを追加した Web 上のままで、Power BIユーザ向けの、Fabric ビジネスインテリジェンス (BI) 機能
- データのリアルタイムの検出と監視を提供し、データ内の指定されたパターンを検出したときに通知とアクションをトリガーできるための、Data Activator (まもなく公開) 機能 (プライベートプレビューの参加エントリー)
- すべてのデータを OneDrive のように保存、同期できるための、データ専用の OneLake機能
- データのガバナンスやセキュリティ、データの系統を確認できる Purview機能
今後、他の機能も徐々に追加されていく見込みです。
Why Microsoft Fabric?
お客様の進化するデータ管理要求に対応するために、最小の労力で多種多様なデータ活動を処理可能な一元化されたソフトウェアベースのクラウドソリューションが強く必要とされています。Azure PaaS ではデータ統合、データウェアハウス、ビッグデータ分析の解答を提供する Azure Synapse Analytics が、SaaS ではビジネスインテリジェンスとレポートソリューションの Power BI が提供されています。これらの両方が組織のデータ管理において価値を証明しています。Microsoft Fabric はこれらの製品が進化した形で、Power BI Premium インフラストラクチャ上に構築され、Azure Synapse Analytics の全ての経験をホストするとともに、成長するデータ管理要求を満たす完全な SaaS プラットフォームソリューションを提供します。
データおよびアナリティクスの今でも発生している課題は何かありますか。
- サイロ化されたシステムとデータ
- 高度なスキルを必要とするテクニカルプラットフォーム
- 限られたリソースでアナリティクスの約束を果たす
- コストのかかる統合と継続的なメンテナンス
- セキュリティリスクのあるデータ
- AI時代への備え
過去1年間にデータリーダーたちはいくつかの重要な問題に直面しています。これにはシステムのサイロ化によるデータの分散 (データスプロール)、不整合なデータセットと未管理のデータ共有、限られたチームとスキルセットでの分析提供、ビジネスチームとIT組織間のデータ配信のギャップ、新しい技術ツールやプラットフォームの導入とそれに伴う高度なスキル要求、そして非統合システムの高コストな統合と継続的なメンテナンスが含まれます。これらの課題は、ビジネスインテリジェンスの採用によるデータ共有の効率化をさらに重要なものにしています。これらに対処しない企業は、競争の不利に加え、データ漏洩やその他のセキュリティリスクにさらされる可能性があります。したがって、現代のデータリーダーはこれら全ての要素を考慮に入れ、AI時代の事業全体の拡張可能なデータと分析のニーズをバランスよく満たすことが求められています。
そして、2023年版のML、AI、データのOSSやソリューションのまとめた図があります。

Firstmark Venture Capitalが作成したこのスライドは、素晴らしい表現です。
顧客にはすべての技術を理解し、専門知識を習得し、それらを接続し、管理および運用するという膨大な負担が生じました。こんなたくさんソリューション、OSS の中で、ただの一つ組織のために、どれを選べばいいか、選んだとしたら、どのように連携させればいいか、ほとんどのお客様のボイスを引用すると、「私たちはチーフ・データ・オフィサーになりたいのです。チーフ・インテグレーション・オフィサーではありません。」ということです。

数年から数十年にわたり、データエステートが進化し、最近では各チームがデータの価値を認識し、組織全体でデータセットを作成しています。マーケティングや営業チームはカスタムデータベースを使用し、サプライチェーン、Eコマース、オペレーション等の部門も独自のデータツールを利用しています。しかし、データの量が多すぎて管理が難しく、データの不整合やデータリスクの問題が頻発しています。これらの問題はデータリーダーにとって大きな悩みとなっています。
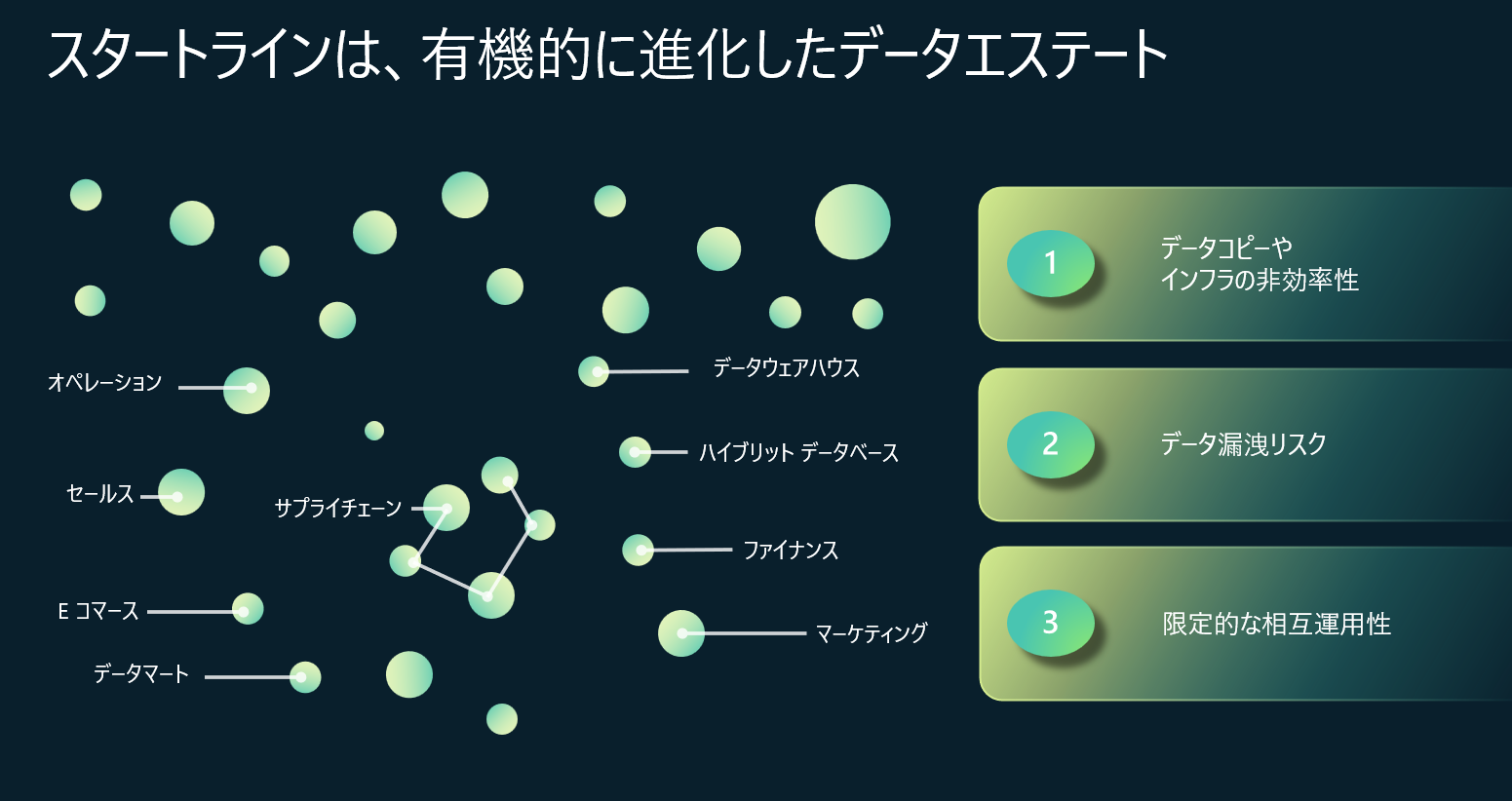
上記の課題などを解決するように、Microsoft Fabricが発表され、すべてのデータ分析プロセスを1か所に…

これはMicrosoft Cloud向けの業界をリードする統合SaaSプラットフォームで、使いやすさ、スケーラビリティ、エンタープライズ対応性に重点を置いています。ビジネスインテリジェンス、データウェアハウス、データサイエンス、データ統合、データガバナンスなどのデータおよび分析ワークロードを統合SaaS製品として提供し、新しいクラウドデータプラットフォームの新たな時代(ジャーニー)を切り開きます。
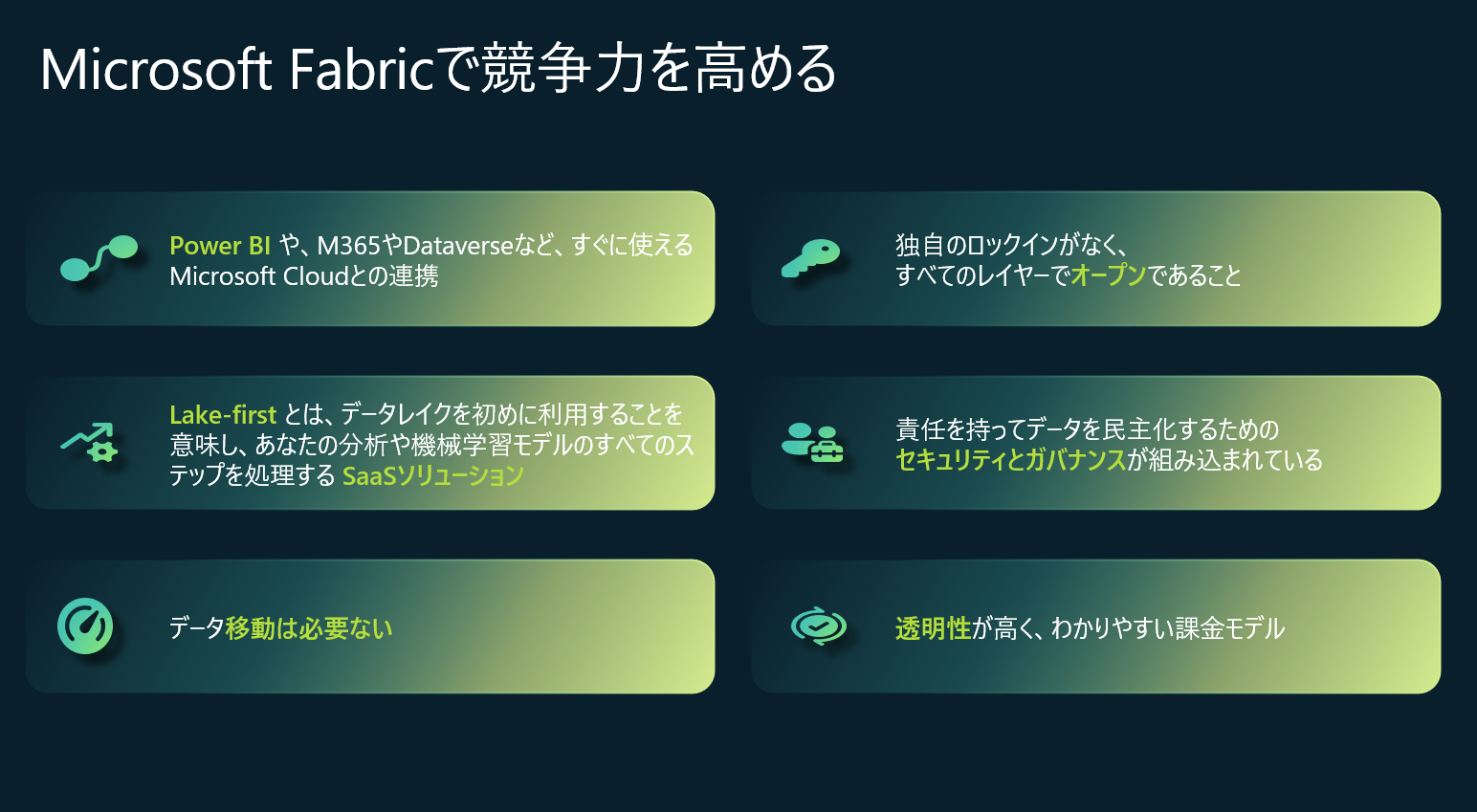
Microsoft Fabric を活用すると、データを移動させずに全てのデータ要求をレイクファーストSaaSソリューションで処理し、競争上の優位性を得ることが可能です。このツールはすべてのレベルでオープンで、専有ロックインがないため、柔軟に利用できます。また、組み込まれたエンタープライズレベルのセキュリティとガバナンスにより、チームがデータ共有と協力を行うことが可能になります。Microsoft Fabricは、Microsoft OfficeとTeamsと深く統合されており、ビジネスユーザーを強化します。さらに、AI Copilot機能が含まれており、分析の効率を高め、洞察を早期に発見し、カスタムAI強化ソリューションへのデータの準備を向上させます。
アナリティクスのためのハイブリッドとマルチクラウド企業データエステートを統一する
すべてのビジネスデータを集約し、整理する規制されたハブを設立し、革新的な分析のための基盤を作り出します。ワークロードを最適化し、データエンジニアがこれまで以上に迅速に分析ソリューションを立ち上げることを可能にします。
目的に合った分析モデルを構築する
データの移動がない接続された基盤上でMLとAIモデルを構築することで、データの全ての可能性を活用します。データサイエンティストが、既知のツールと言語を活用して、大量のデータに対するリアルタイム分析を実行することを可能にします。
データガバナンスを用いて分析を責任ある形で民主化する
セキュリティとガバナンスが組み込まれた開放的でスケーラブルな分析プラットフォームを有効にする必要なサービスを接続します。データエンジニア、データサイエンティスト、データアナリストが、必要なデータに、適切なタイミングでアクセスすることを可能にし、民主化を容易にします。
変革的な分析アプリケーションをスケールアップする
データアナリストとデータ市民に強力な自己サービス分析ツールを提供し、リアルタイムの洞察によるイノベーションを促進します。すべてのアプリケーションにつながるインテリジェンスを作り出し、より良い意思決定と変革的な影響を可能にします。
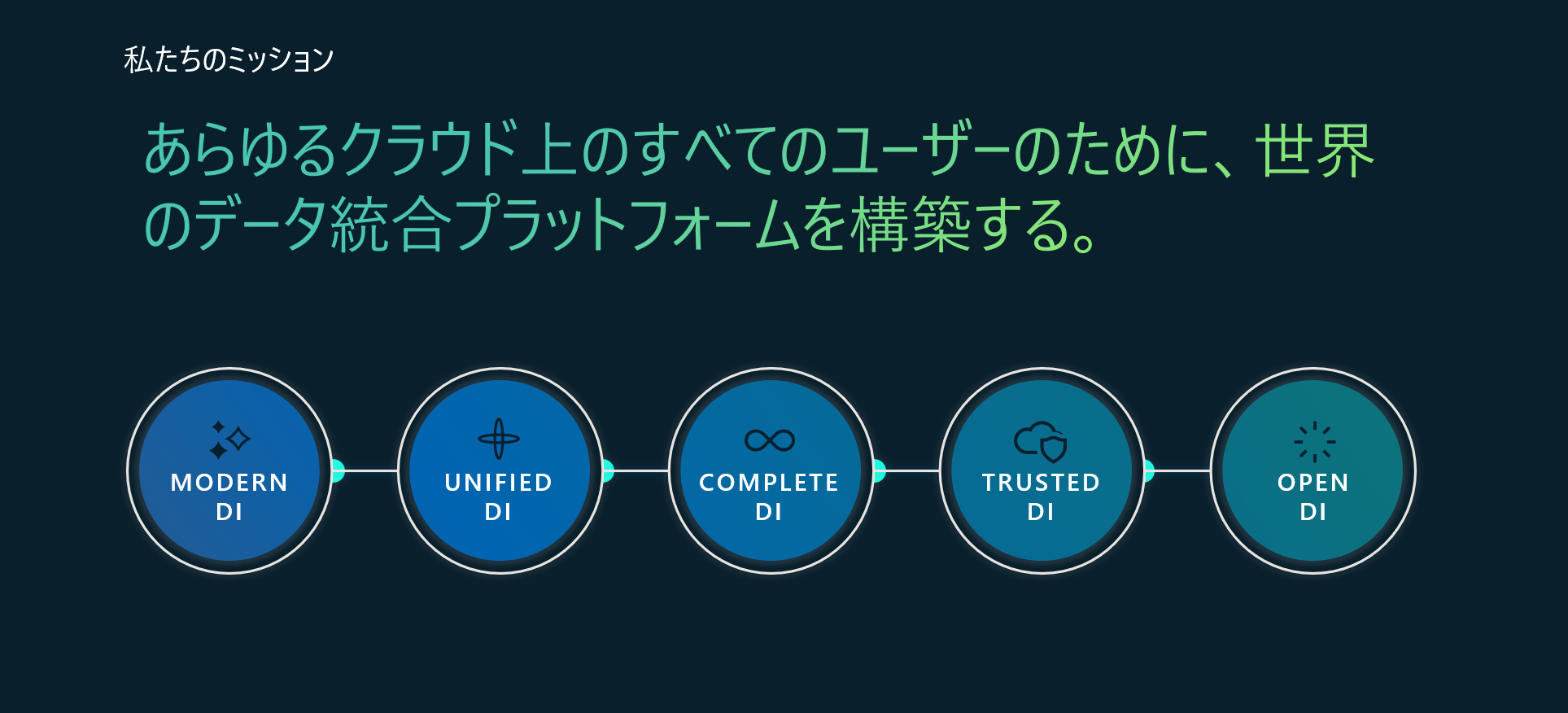
ここに書いた通りに、Microsoft は 「あらゆるクラウド上のすべてのユーザーのために、世界のデータ統合プラットフォームを構築する」 ことになっています。
Microsoft Fabric の特徴

Microsoft Fabricには4つの主要な投資領域が存在します。
完全な分析プラットフォーム
Microsoft Fabric は完全なアナリティクスプラットフォームを提供します。このプラットフォームは、データレイクからビジネスユーザーまで必要な全てのワークロードをカバーします。これは自動的に統合・最適化され、セキュリティとガバナンス機能も持ち合わせている SaaS として提供されます。
レイクセントリックとオーブン
Microsoft Fabric はデータレイク中心かつオープンなアプローチを採用します。OneLake はSaaS データレイクで、ストレージを提供し、ADLS Gen2、AWS S3、Google Storage等の全てのデータを統合する仮想化レイヤーとして機能します。また、オープンデータフォーマットを採用し、Microsoft はparquetとdelta lakeに基づくオープンなフォーマットを利用します。
すべてのビジネスユーザーを支援する
Microsoft Fabricは、OneLakeの全データをOffice 365とネイティブに統合することを目指しています。この統合により、Power BIを介してExcel、Teams、SharePoint、PowerPointに全てのデータが統合され、ビジネスはこれらの毎日使うツールを通じてデータを活用することが可能になります。
AI 搭載
Microsoft FabricはAzure OpenAIと統合しています。これにより、各ワークロードは開発者と並行して作業することができます。
Microsoft Fabric AI Copilot

2023年はAIの時代の幕開けとなり、Azure OpenAIなどが大きな役割を果たしました。これは、仕事の全般に対して大きな影響を与える変化で、特にデータの取り扱い方法において重要なプラットフォームの変革が起きています。
AIのパフォーマンスはデータに大きく依存しているため、正確なデータを取得することがより重要になります。また、Azure OpenAIのような大規模言語モデルの力を借りて、AIは開発者の生産性を簡素化し、加速させることが可能です。つまり、AIは複雑性を理解するのに有効であるということです。

自然言語で、Microsoft Fabricと会話し、データのインサイトやビジネスを加速化します。
AI Copilotは、Microsoft Fabricの各ピラーでそれぞれ順序にサポートするようになります。パブリックプレビュー時点では、まだ使えないため、もう少し待つことになります。とても、期待値が高い AI 機能です。
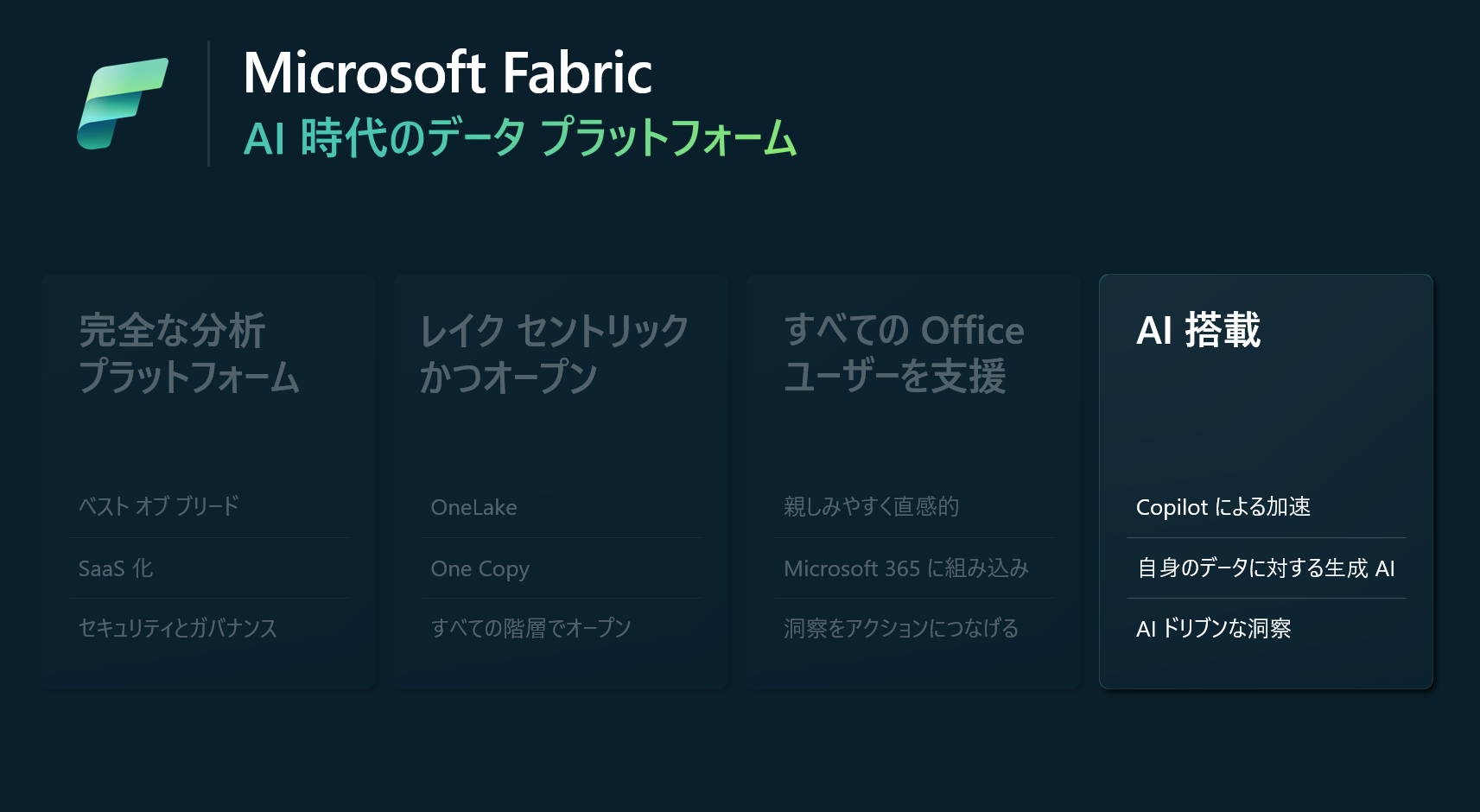
AI Coplilotは、Microsoft Fabricの4つ大きい柱のうちの1つです。

Microsoft Fabric に AI Copilotを搭載することで、より今まで生産性をアップでき、深いインサイトもできるようになります。

AI Copilotは働き方を革新するツールで、ユーザーが特定の製品やツールの専門知識に固執することなく、アイデアを具現化することに集中できます。現在のデータや分析ツールは複雑で、その最適な使い方を理解するだけでも難しいですが、Copilotの利用により、ユーザー自身の言葉を強力な生産性向上ツールに変換できます。
これにより、複雑なツールの操作から解放され、クリエイティブアシスタントとしてのCopilotと共に仕事を行う新しい環境が提供されます。これは製品特有の作業から横断的な作業へのシフトを意味し、手作業で成果物を作成する代わりに自動生成されたコンテンツの洗練に注力できます。
最も重要なのは、Copilotを使用するときでも、ユーザー自身が全てをコントロールできることです。どの情報を保持し、何を修正し、何を破棄するかは全てユーザーが決定できます。
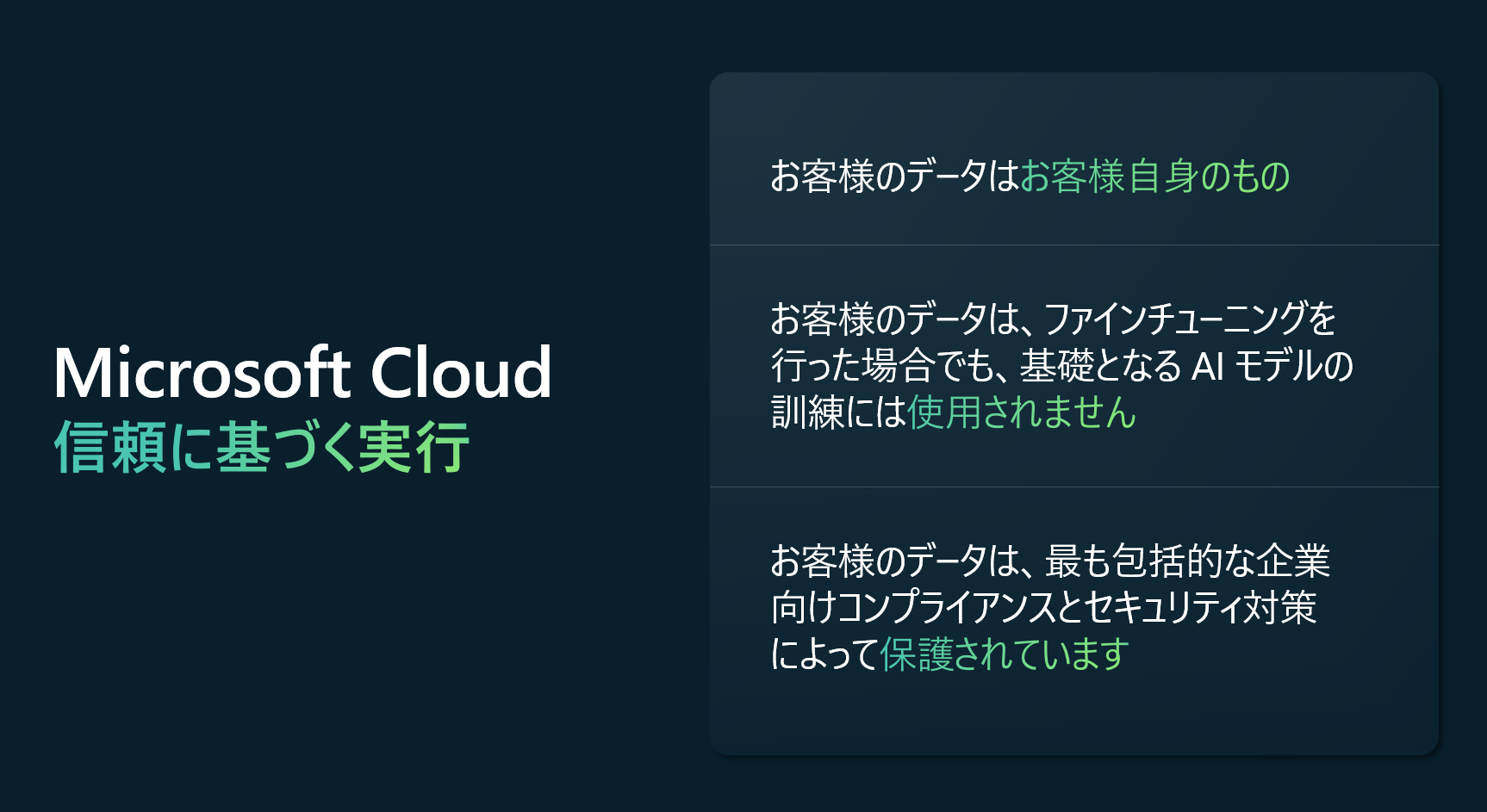
Microsoft Cloudの基本的な考えとしては、信頼が最も重要であり、それが当初から組み込まれているということです。データはAIテクノロジーの基盤であり、テクノロジーパートナーによるデータの取り扱いを信頼する必要があります。
この信頼性を確かなものにするために、Microsoft Cloudは3つの基本的な約束を提供しています。
- 顧客のデータは顧客自身のもので、Microsoftのものではなく、顧客が所有し管理します。
- 顧客のデータは、他者のAIモデルの訓練や改善には使用されず、顧客の組織だけがそのデータとプロセスから利益を得ることができます。
- 顧客のデータとAIモデルは、組織全体が業界で最も包括的な企業のコンプライアンスとセキュリティ制御により、全ての段階で保護されています
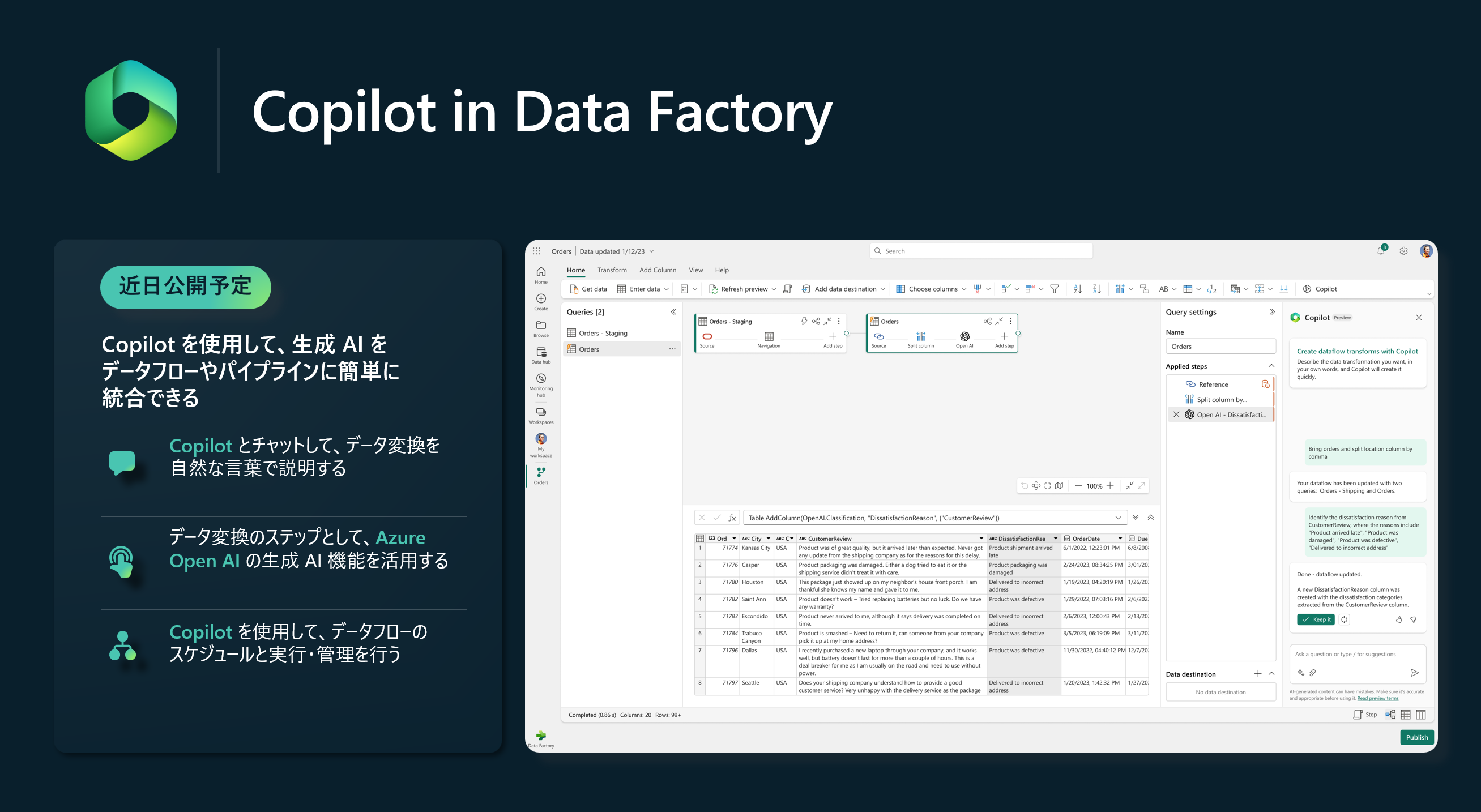
Copilotは、データの準備と変換を行うためのまったく新しいパラダイムを生み出すことがおわかりいただけると思います。また、それだけでなく、Azure Open AI のLarge Language models (LLM) を直接活用するための新しい変換ステップも統合されています。
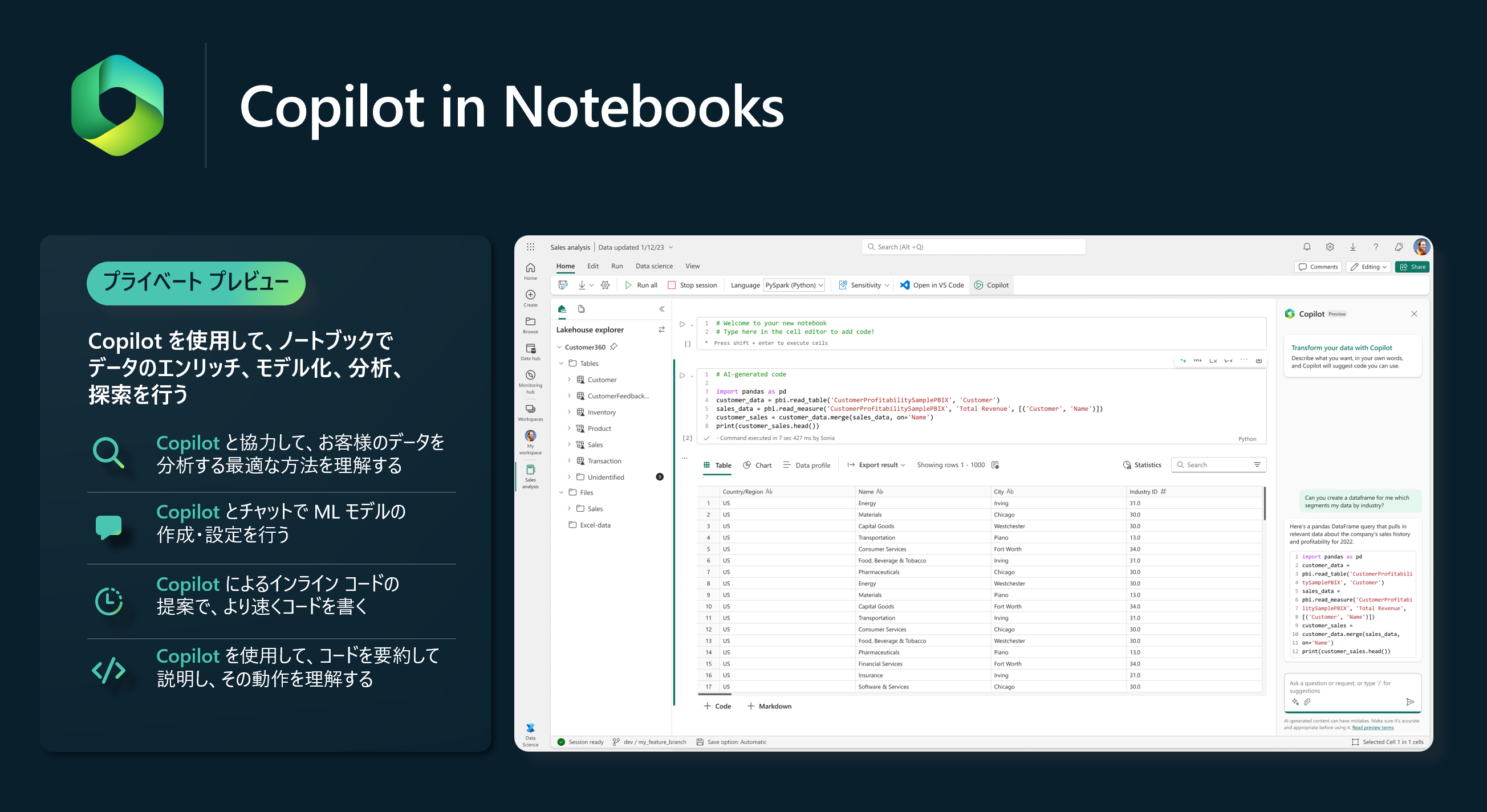
ノードブックの Copilot は、データエンジニアやデータサイエンティストがデータをより迅速にリッチ化し、モデル化し、分析し、探索することを支援します。また、Copilot は単にコードを速く書けるようにするだけでなく、コードの動作状況を把握したり、データの最適な分析方法をユーザーと一緒に考えたりできるようになります。
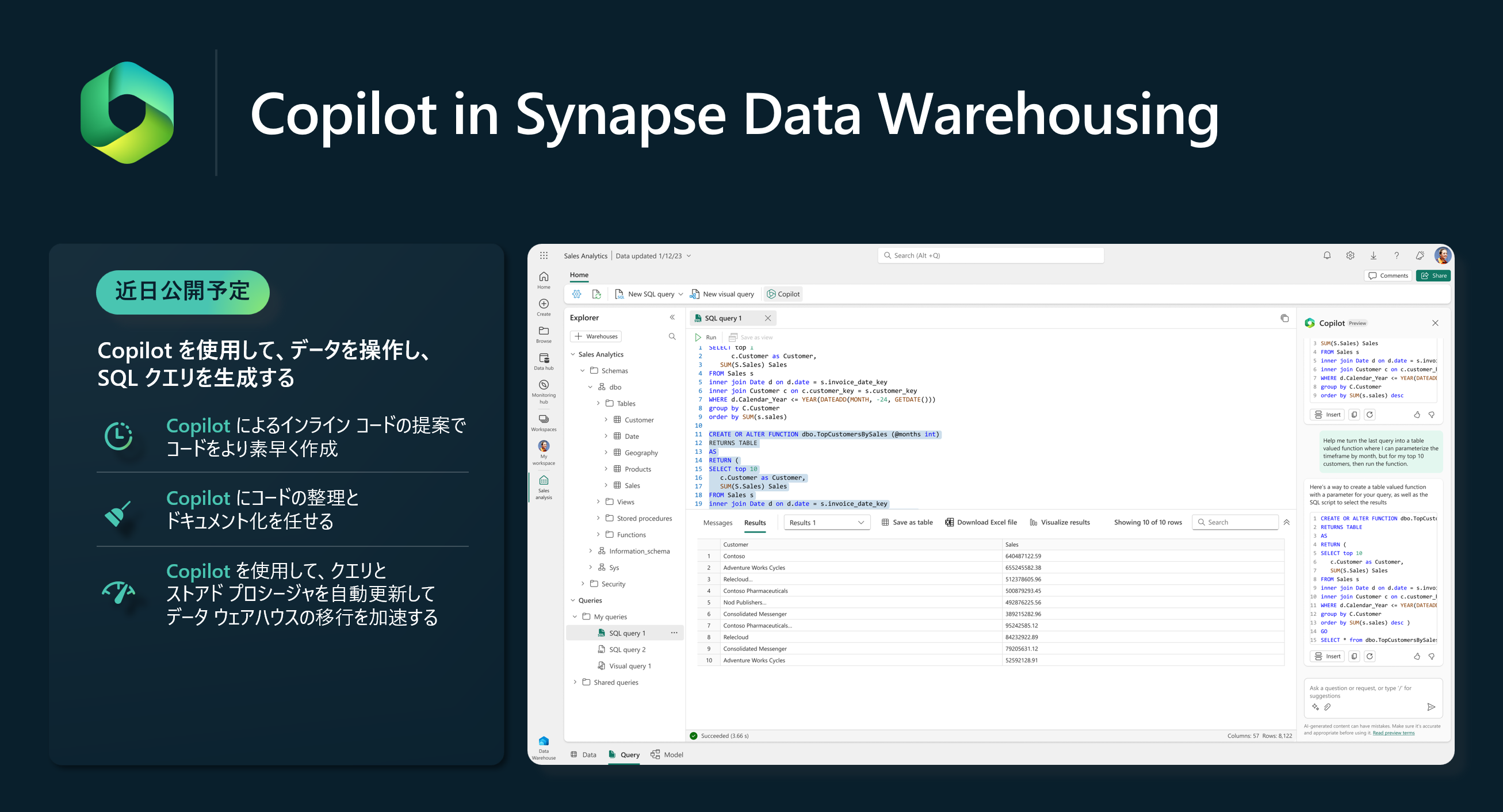
エキサイティングなこととして、Copilot を使用することでデータウェアハウスの移行を加速させる機能が近々登場します。
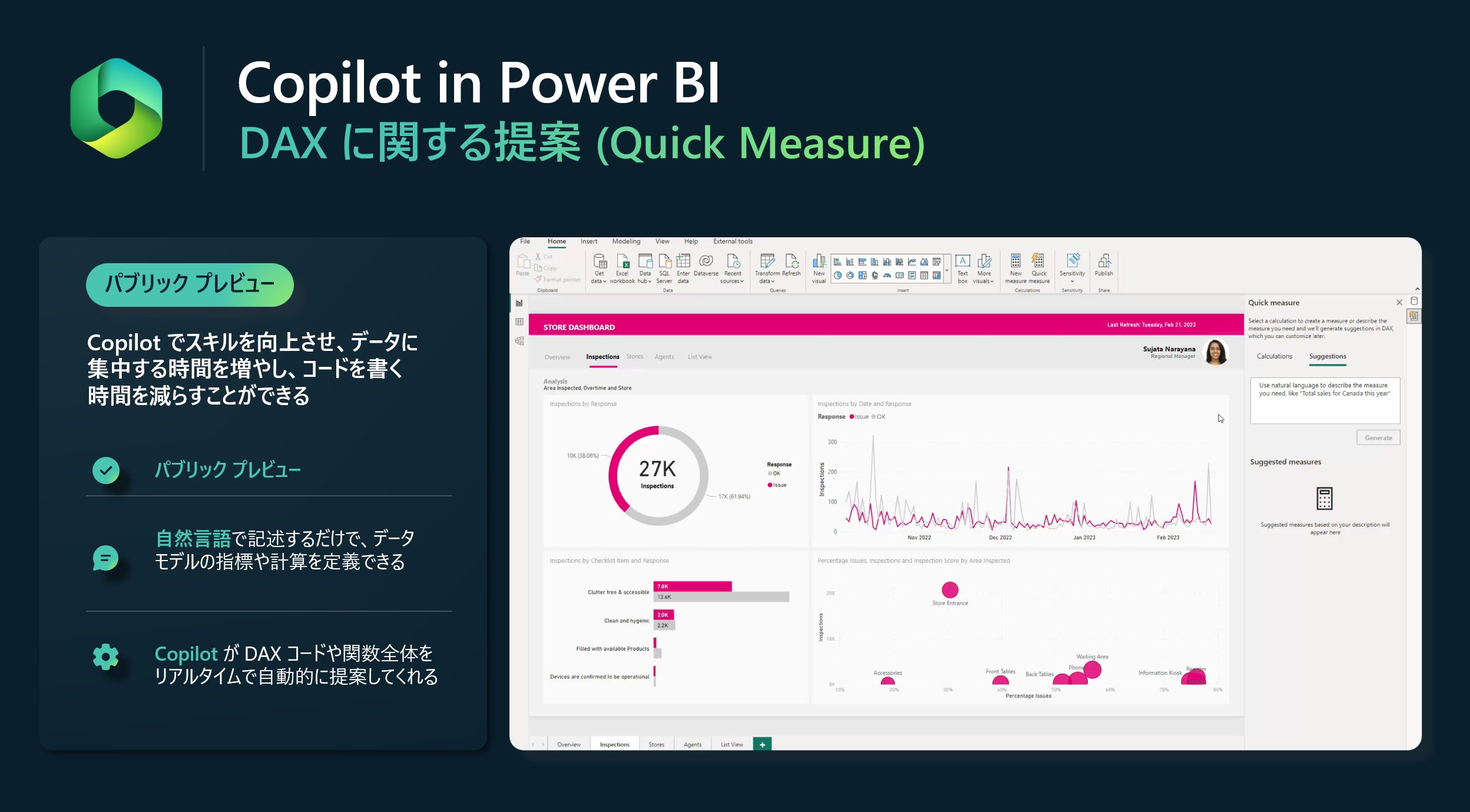
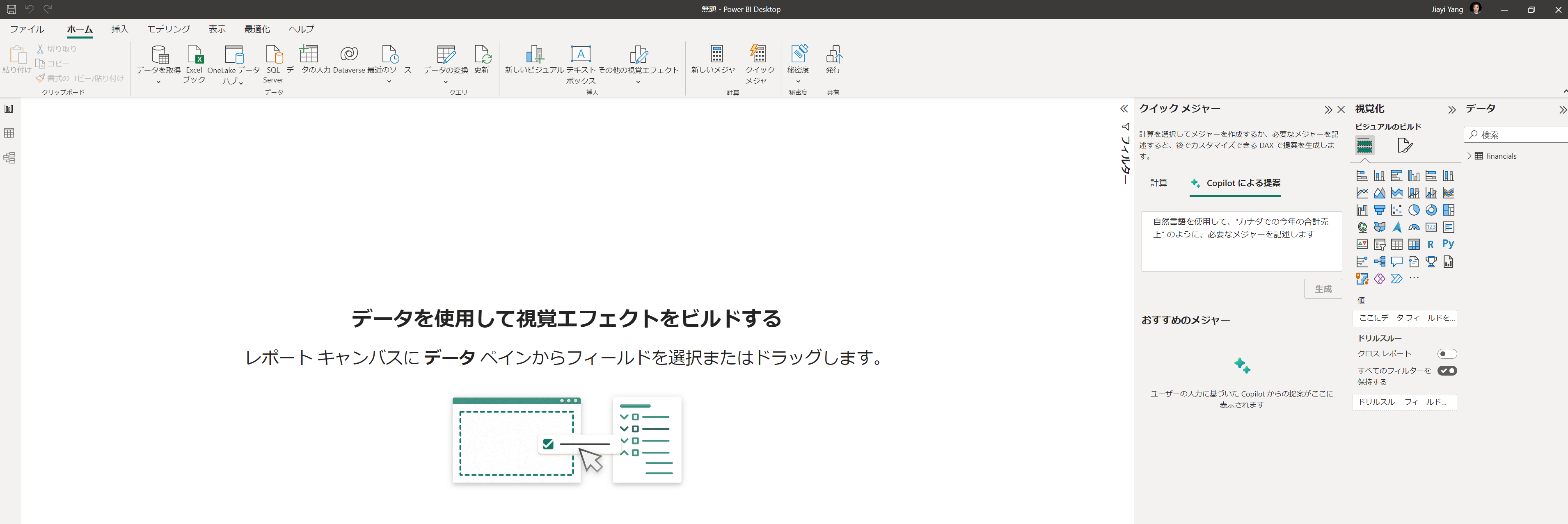
Power BI では、すでに GPT3.5 ベースの自然言語による DAX メジャー作成機能(Quick Measure)をパブリックプレビューで公開しています。
この機能により、アナリストは、探しているものを自然言語で記述するだけで、ローリングアベレージなどの計算を作成することができます。
Power BI の非常に強力な DAX 言語を利用する上で、大きな助けとなります。
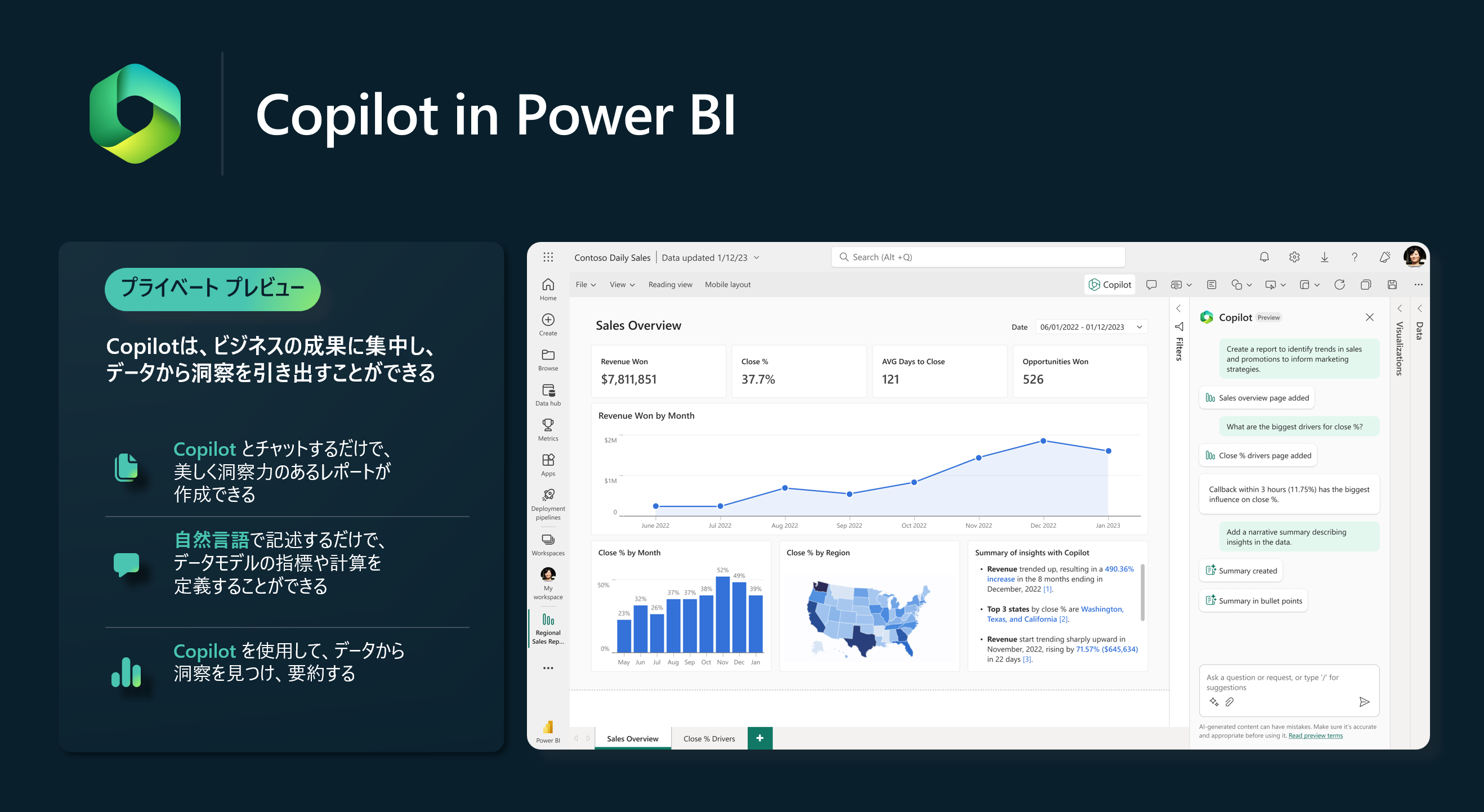
まだまだあります。Power BIにはエキサイティングな Copilot の新機能が大量に用意されています。
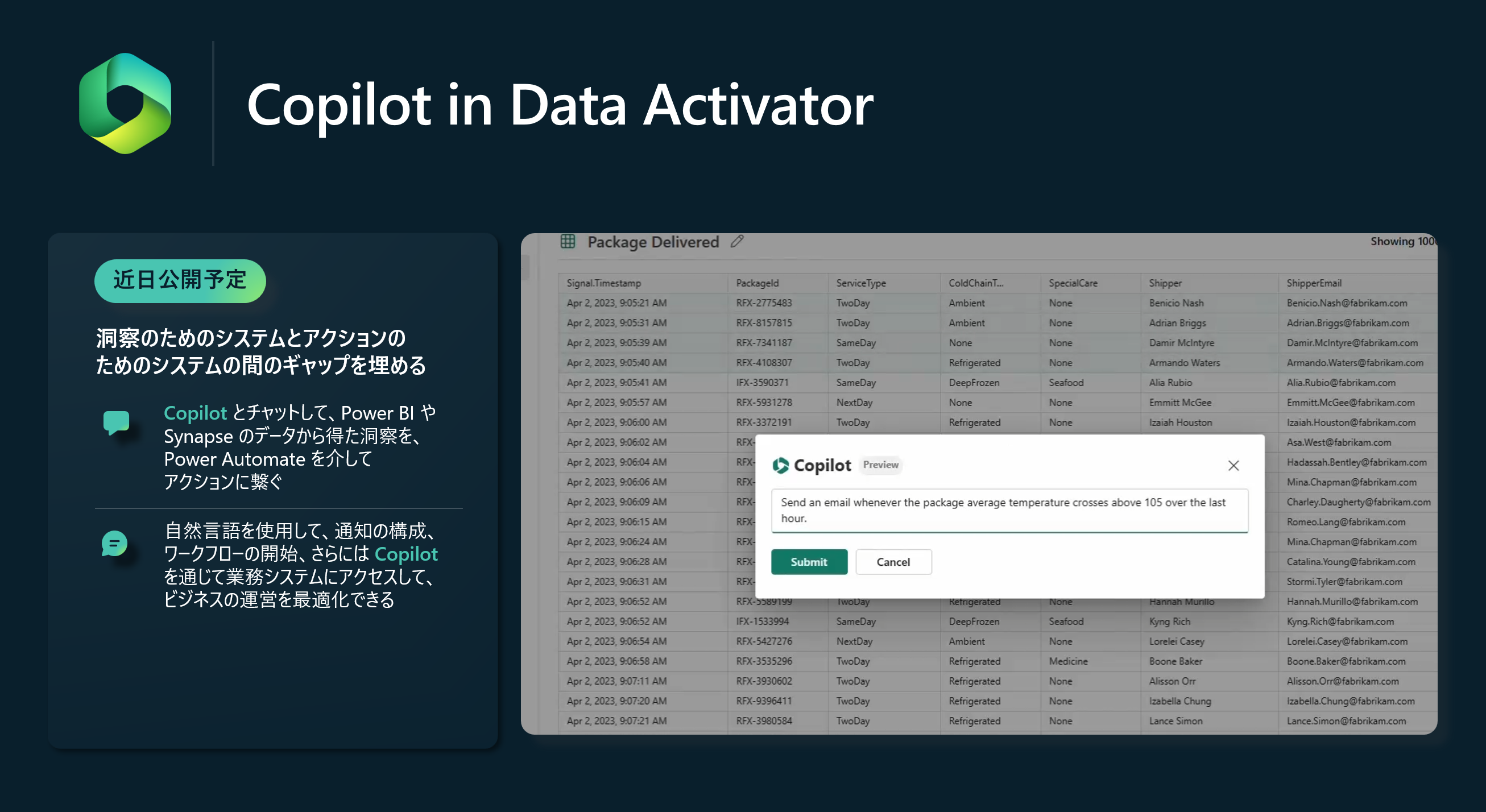
Microsoft Fabric には、Power BI や Synapse でデータを収集、分析、可視化するためのインテリジェンスシステムがありますが、Data Activator を使用すると、電子メール、チームチャット、Power Automate、さらにはカスタム業務アプリケーションなどのアクションシステムで、発生した洞察を結びつけることができます。
Copilotは、自然言語でルールを記述するだけで、インサイトとアクションの間のギャップを簡単に埋めることができます。
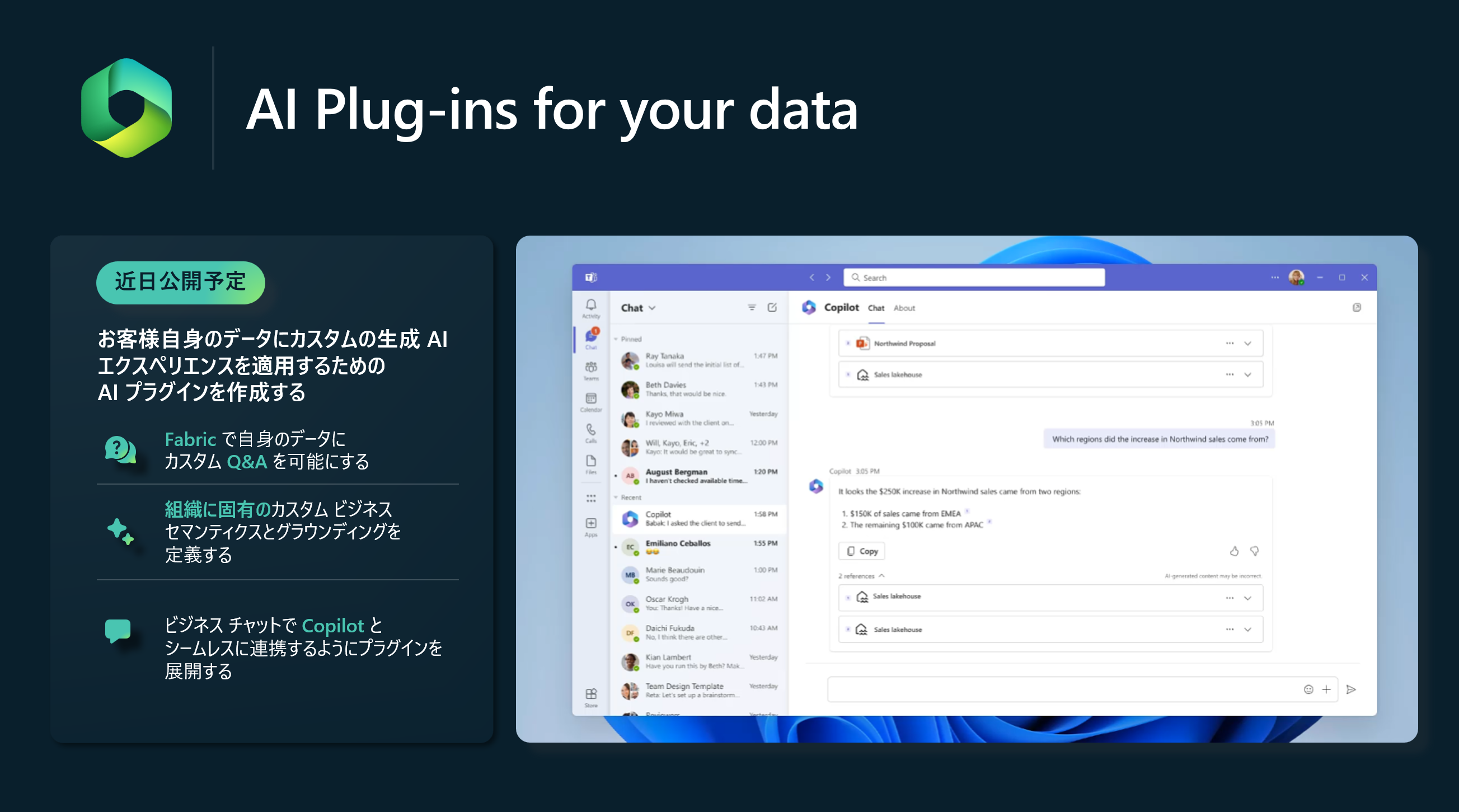
AI プラグイン、例えばデータに対する Q& A機能を可能にすることで、ユニークな価値や体験を提供することができます。また、これは Microsoft のデータベースプラットフォーム全体にわたる追加データにも拡張されます。

あなたの言葉で、あなたのデータと会話し、あなたのデータだからこそ、あなたのことを理解してくれます。それが Microsoft Fabric AI Copilot です。
Microsoft Fabric 完全な分析プラットフォーム
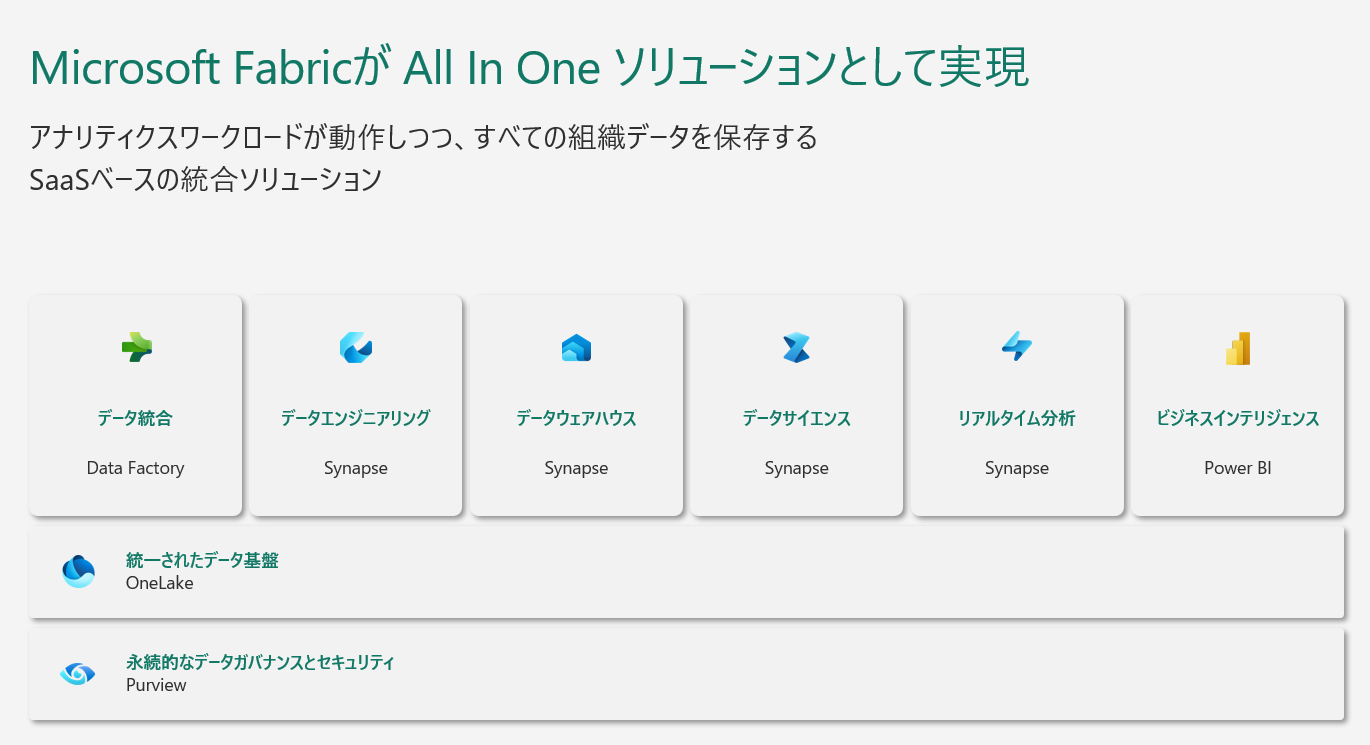
冒頭の Microsoft Fabric とはのように、データの収集、変換、SQLワークロードとSparkワークロード、そしてリアルタイム分析ためのDBエンジン、BI、セキュリティ、ガバナンス、All in one のデータ SaaS ソリューションです。

Microsoft Office では、OneDrive ですべてのドキュメントデータを管理します。
Microsoft Fabric では、OneLake ですべての組織の構造化、半構造化、非構造化のデータを管理します。
Microsoft Fabric OneLake

すべてのデータはオーブンなデータフォーマットで、一つレイク上に保存と管理します。そこで、OneLakeの発表となります。
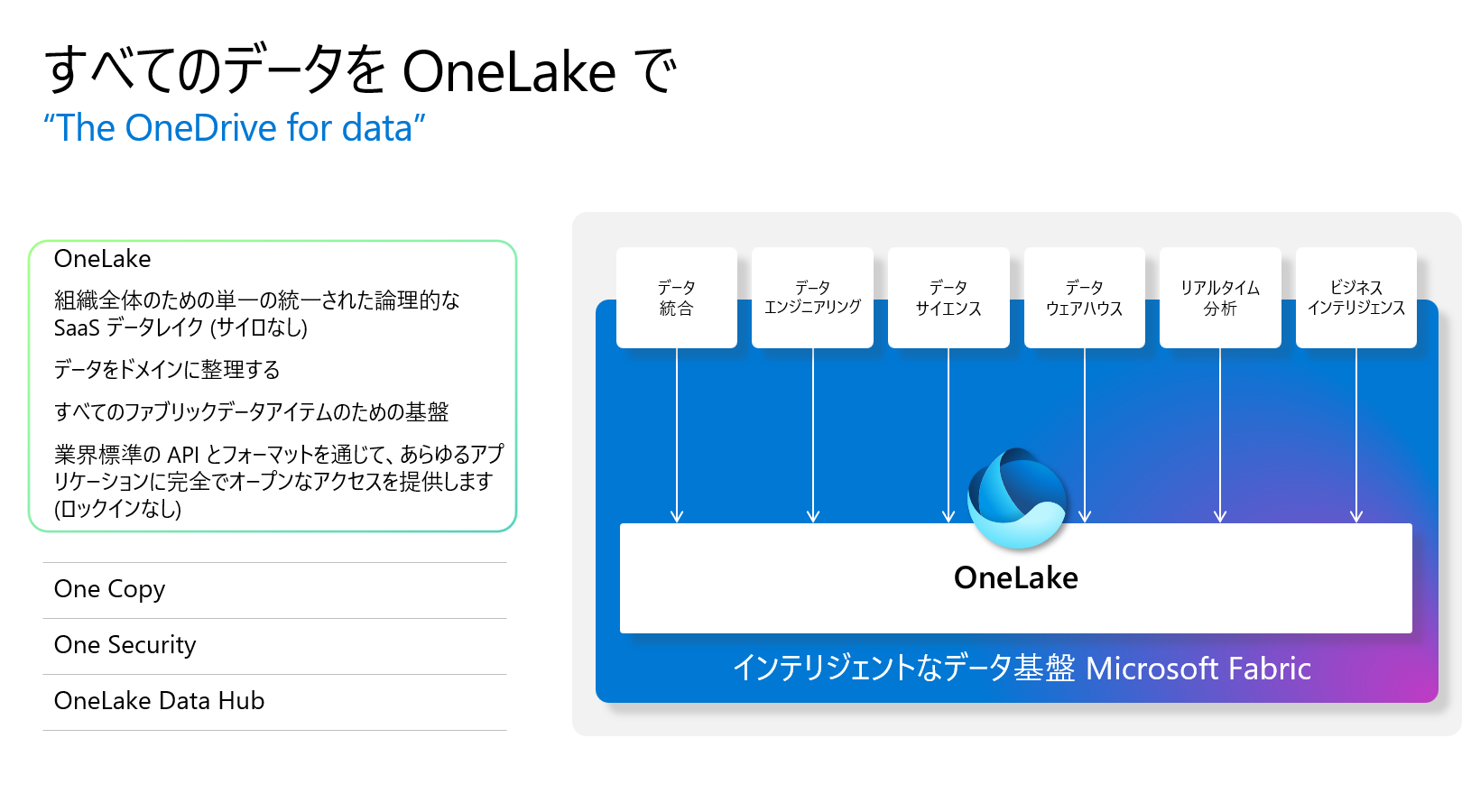
Microsoft Fabric OneLakeは、組織全体のための単一の統合されたSaaSデータレイクです。テナントの OneLake は、そのテナント内のすべてのアーティファクトのデータを保持します。レイクハウス、データウェアハウス、その他のアーティファクトのいずれであっても、OneLakeは、データを移動または複製することなく、Microsoft Fabric のすべての分析エンジンの1つのデータソースになります。
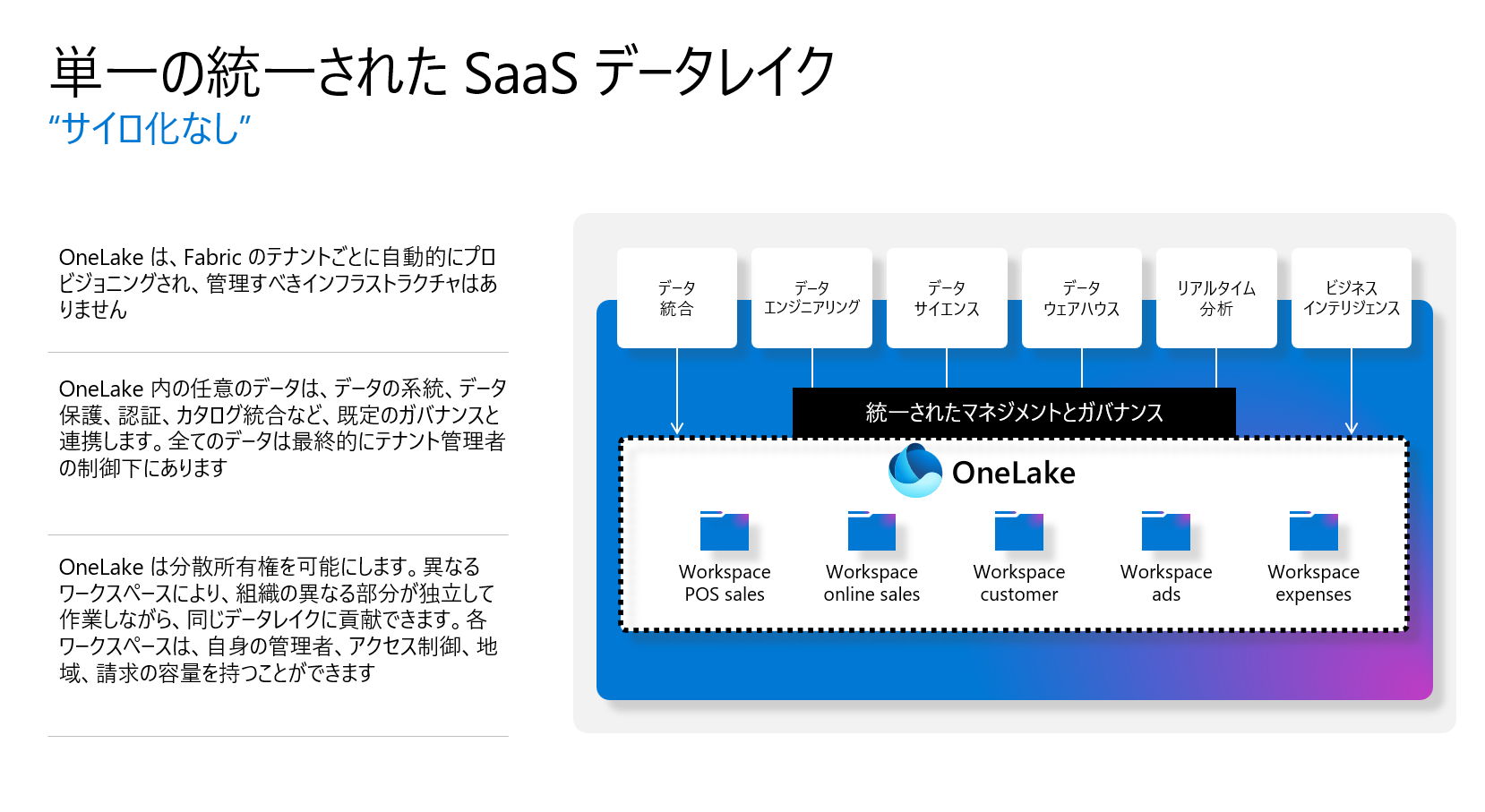
各リージョンが離れていも、テナント上では、一つのレイクしかありませんので、データ加工などのためのサイロ化を無くします。
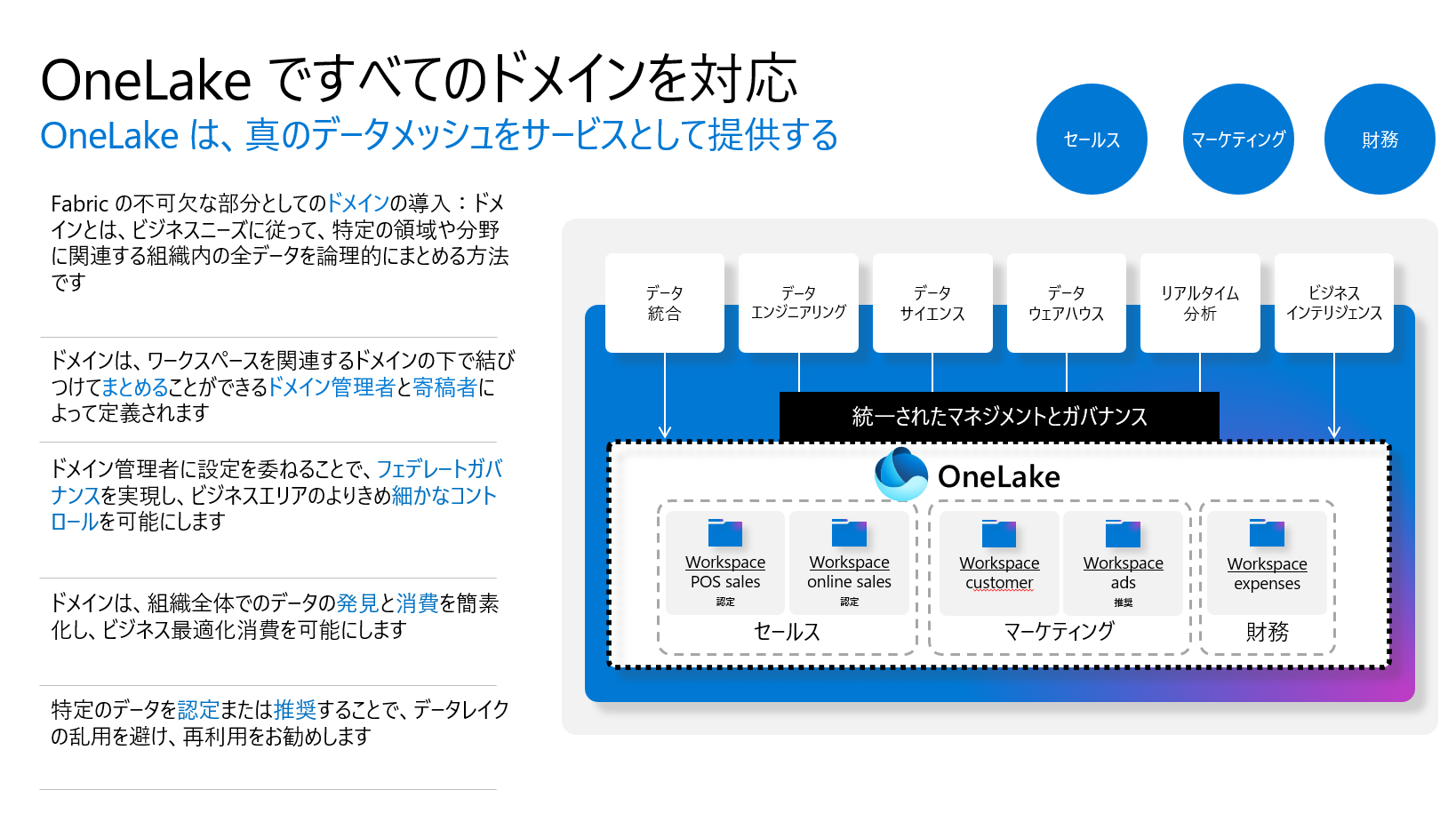
ビジネスグループは同じデータレイクで独立して作業することが可能で、それぞれが異なるストレージリソースを管理する手間を省くことができます。データメッシュパターンの効率的な実装も可能になり、OneLakeはドメインを第一級の概念として導入することでこれを推進します。ドメインとは、関連するデータを論理的にまとめる概念で、ドメイン管理者と寄稿者により定義されます。また、ドメインは複数のワークスペースの管理境界を提供し、管理者に細かい制御を可能にします。
しかし、全てのユーザーがデータレイクに追加できることで、データの混乱やデータサイロの形成を避けるための課題があります。この問題は、ユーザーがOneLakeからブロックされると新たなデータレイクを作成し、そのデータの管理や使用が不明確になる可能性があるためです。これに対し、OneLakeにデータを追加すると自動的に管理され、使用状況の洞察を得ることが可能です。
データサイロを避けるためのOneLakeの提案は、データの推奨を通じて行います。ドメインの所有者がデータを公式に認定または推奨することで、重要なデータを浮き彫りにし、不要なデータを排除することが可能になります。
Microsoft OneLake file explorer for Windows
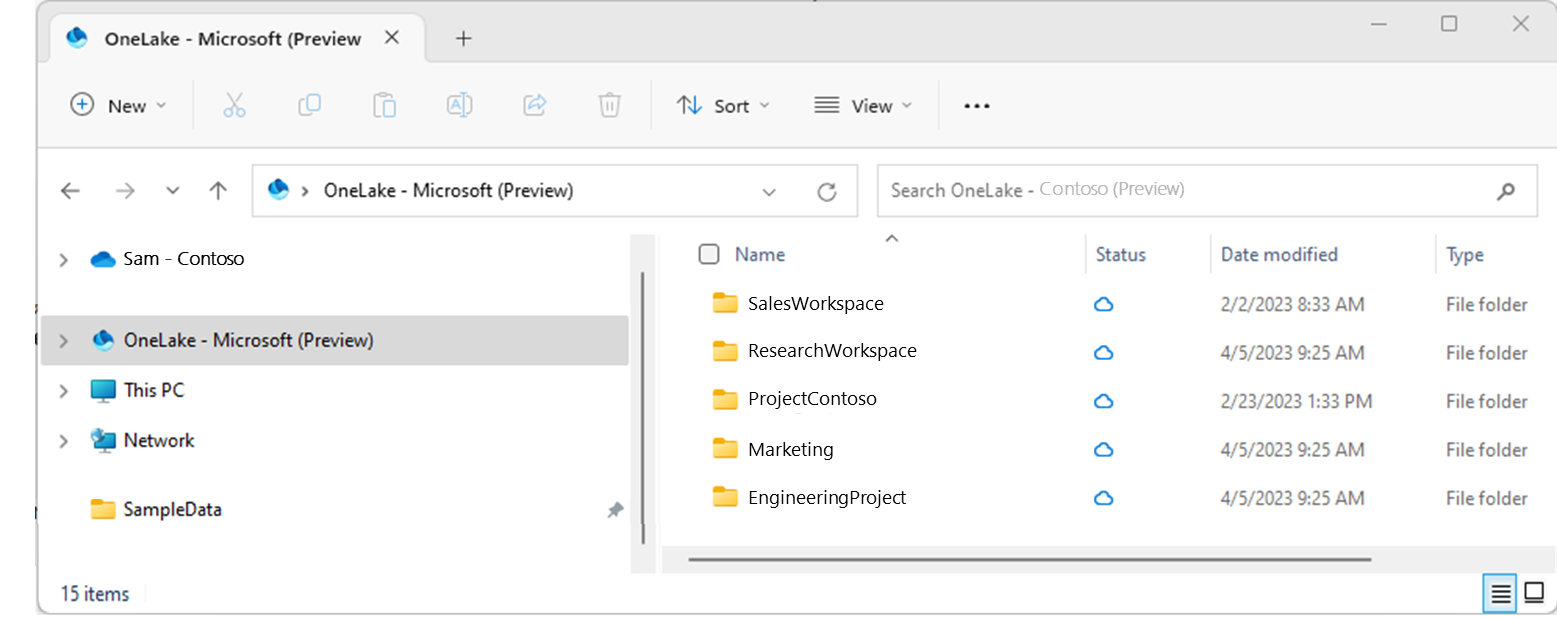
OneLakeファイルエクスプローラーアプリケーションは、WindowsファイルエクスプローラーとOneLakeをシームレスに統合します。このアプリケーションは、Windowsファイルエクスプローラーでアクセス可能な全てのOneLakeアイテムを自動的に同期します。ここでの「同期」は、ファイルやフォルダの最新のメタデータを取得し、ローカルで行われた変更をOneLakeサービスに送信することを意味します。同期はデータのダウンロードを意味するものではありません。代わりにプレースホルダーが作成されます。データをローカルにダウンロードするには、ファイルをダブルクリックする必要があります。
ファイルエクスプローラーを通じてファイルを作成、更新、または削除すると、変更が自動的にOneLakeサービスに同期されます。ファイルエクスプローラー外部で行われたアイテムの更新は自動的には同期されません。これらの更新を取得するためには、Windowsファイルエクスプローラーでアイテムやサブフォルダを右クリックし、OneLakeから同期を選択する必要があります。
Download Microsoft OneLake file explorer for Windows
https://www.microsoft.com/en-us/download/confirmation.aspx?id=105222
Microsoft Fabric One Copy
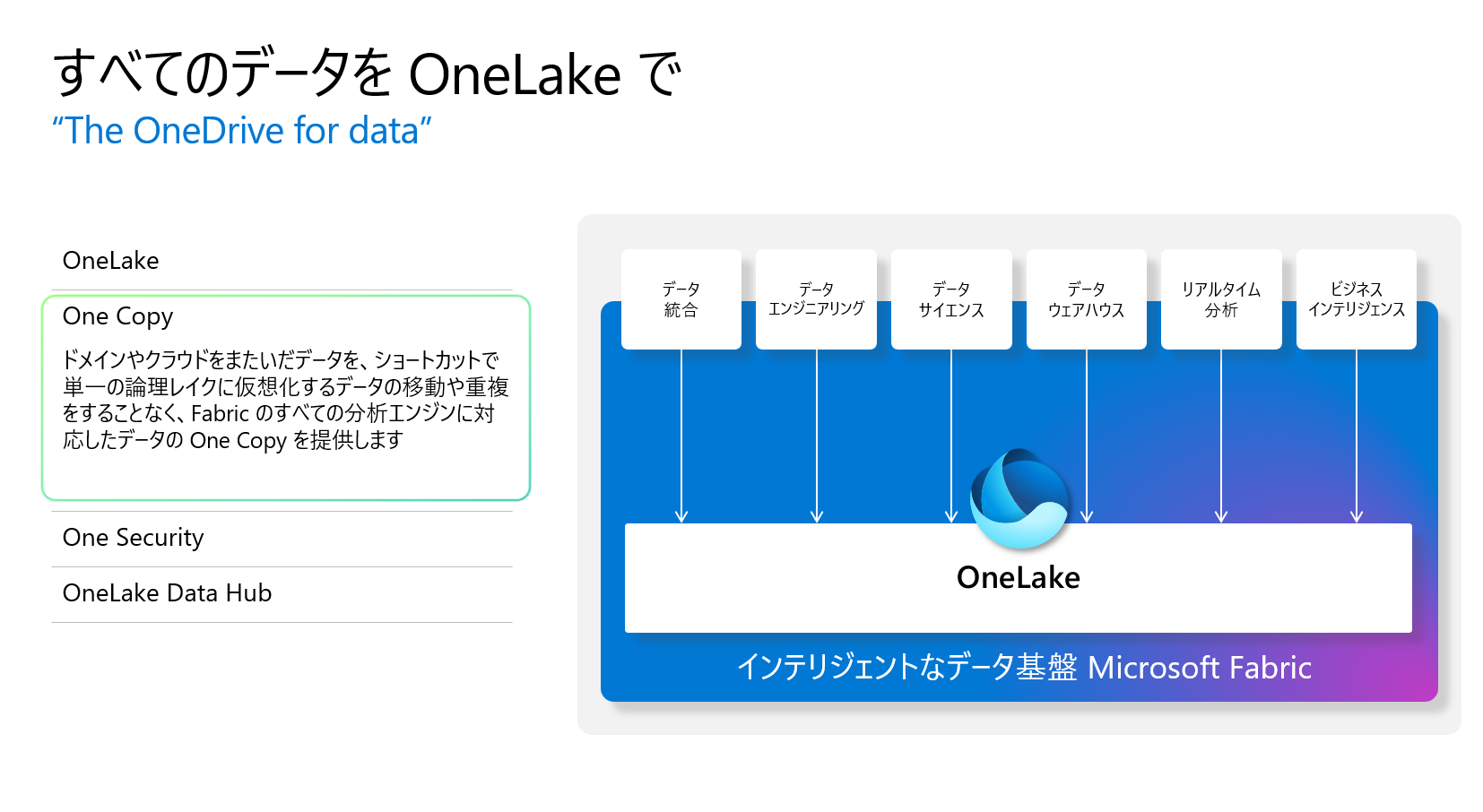
データのサイロを排除するために、レイクやクラウド間でデータをコピーすることを余儀なくされています。また、ユーザーやアプリケーションにデータを提供するために、レイク自体から異なるデータエンジンにデータをコピーすることを余儀なくされています。OneLake with One Copyは、重複のデータ移動なしに、1つのデータのコピーから可能な限り大きな価値を引き出すことを目的としています。
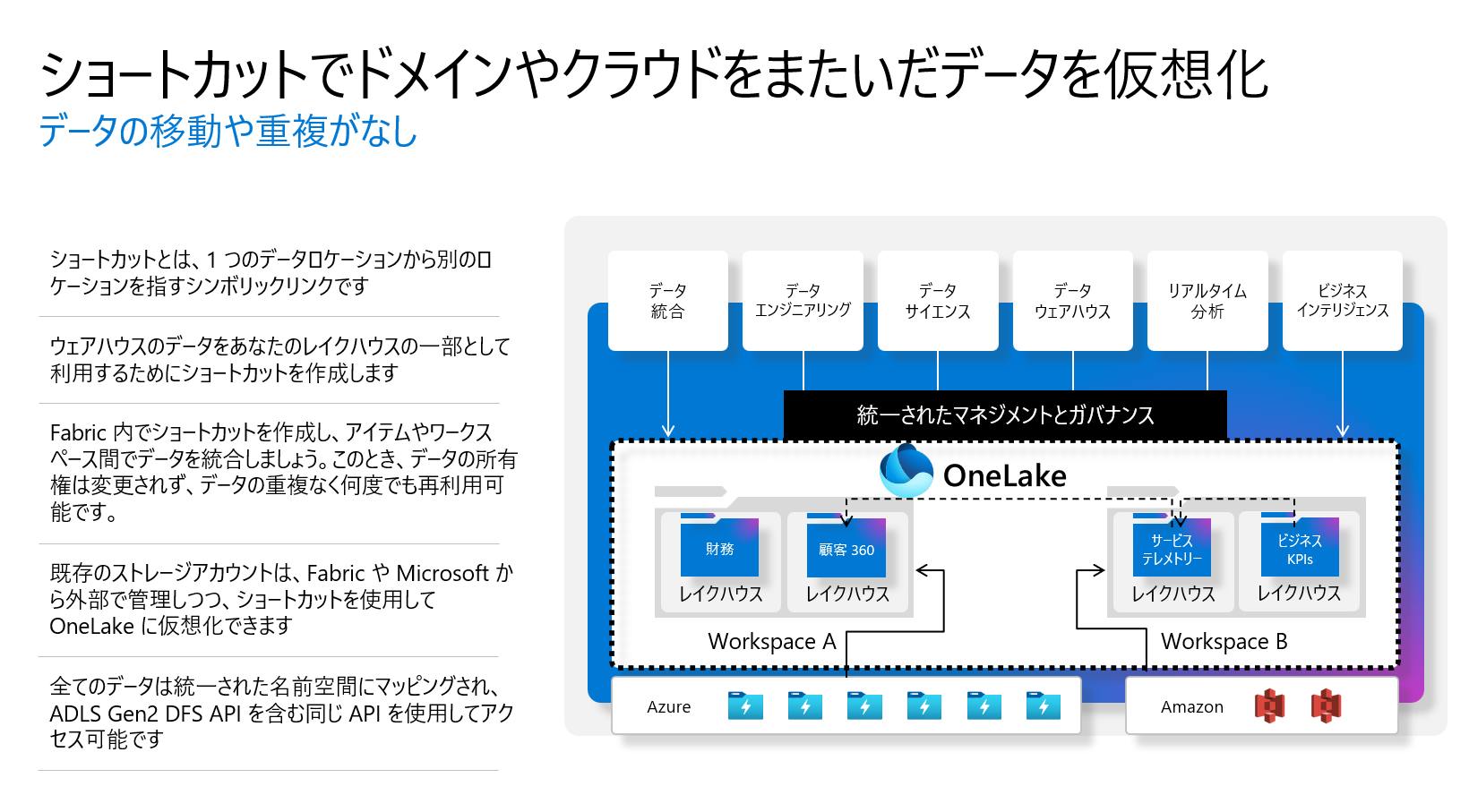
ショートカットは、あるデータロケーションから別のロケーションを指すシンボリックリンクで、WindowsやLinuxなどで作成できます。データウェアハウスにあるテーブルをレイクハウスで使いたい場合、OneLakeではウェアハウスを指すショートカットをレイクハウスに作成するだけで、データを物理的にコピーせずに利用可能です。また、ショートカットはデータの所有権を変更せずに、異なるワークスペースやドメイン間でデータの統合を可能にします。
外部のデータレイク、例えばADLS gen2やAmazon S3バケットを持つ場合、OneLakeではショートカットを使ってこれらのレイクを仮想化できます。このショートカットは既存のADLS gen 2アカウントやAmazon S3バケットを含むことが可能で、これらのデータも同一の統一名前空間にマッピングされます。これにより、S3からのデータであってもADLS gen2 APIを使ってアクセスできるようになります。
Microsoft Fabric のレイクセントリックのアプローチは、データ サイロの解消に役立ちます。アプリケーションやデバイス (Web サイト、モバイル アプリ、センサー、倉庫や工場からの信号) からのデータと、Dynamics 365 のビジネス プロセス (販売、サポート案件、在庫、注文) のデータを組み合わせて、顧客との約束を守ることに影響する潜在的な遅延や不足を予測します。Dataverse と Microsoft Fabric を直接統合することで、時間と労力を大幅に節約できます。つまり、Fabric OneLake には、Dataverse ショートカットを作成することができます。該当プログラムはプレビューの参加が必要です。
Microsoft Fabric One Security

Build 2023の時点では、まだ絶賛開発途中ということです。
One Security は、OneLake で定義する共有のユニバーサルセキュリティモデルをもたらすでしょう。これらのセキュリティ定義は、データそのものと一緒に生きています。これは重要な点です。セキュリティは、サービス層やプレゼンテーション層の下流にあるのではなく、データと共に生きることになります。このため、OneLakeは、幅広い分析シナリオをサポートするために、レイク自体で必要なセキュリティ機能を提供する必要があります。
OneLake では、より詳細なデータセキュリティをデータアイテムに定義することができます。これには、データウェアハウスに対して、テーブル、列、行レベルのセキュリティが含まれます。このセキュリティは、そのデータを参照するすべてのショートカットに適用されます。
このセキュリティは、T-SQLを使用するビジネスアナリストを含むすべてのエンジンによって自動的に適用されます。Spark を使用するデータエンジニアやデータサイエンティスト、Power BI でレポートを閲覧するビジネスユーザー、そしてADLS Gen2 DFS APIを使用する非 Fabric エンジンを含む OneLake でこのデータにアクセスするすべてのエンジンで、自動的に適用されます。
Microsoft Fabric OneLake Data Hub
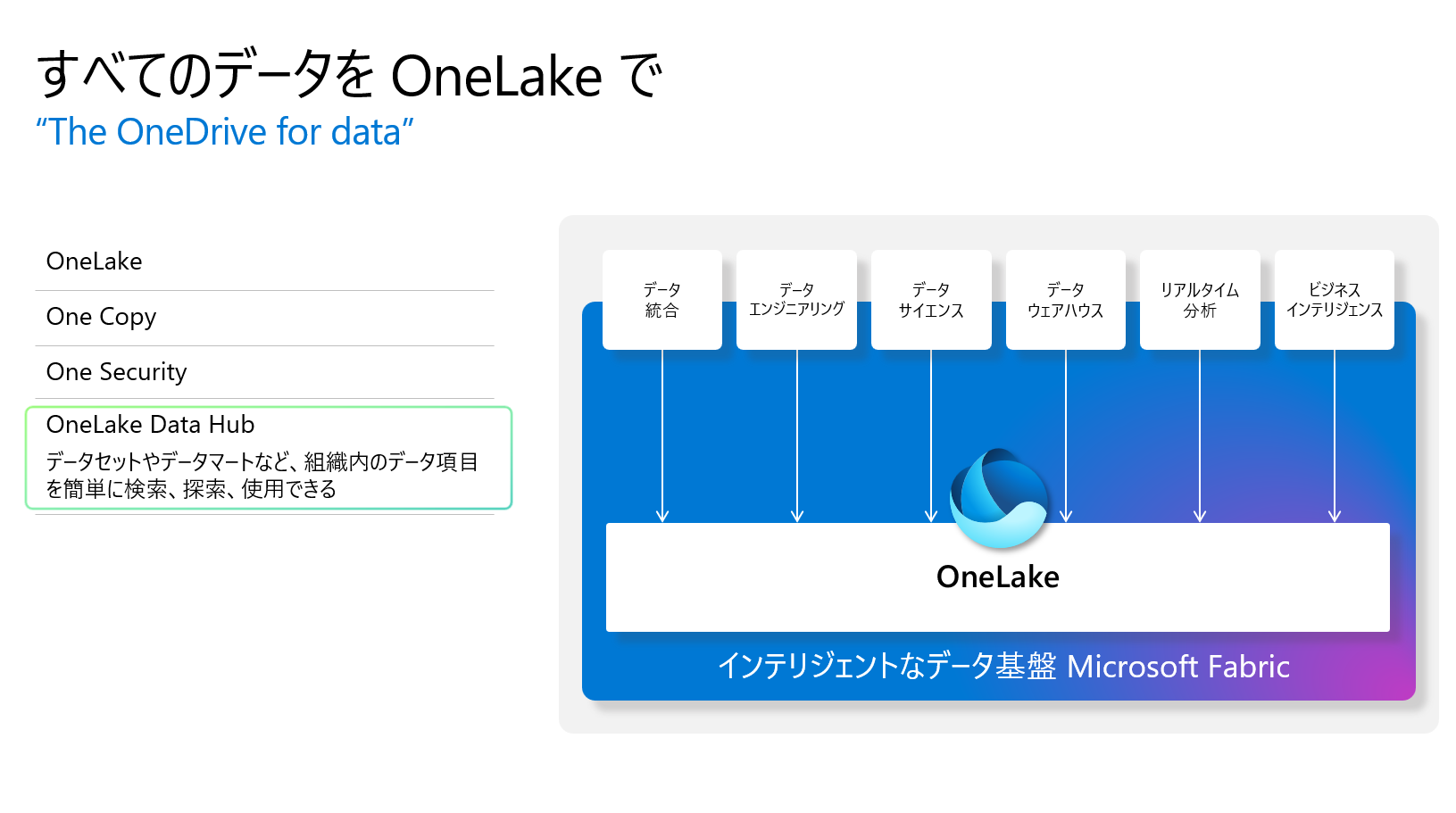
データの発見、管理、活用を一元的に行うことができるHub機能です。Power BI Service Data Hubと同じ発想です。
データを発見、管理、再利用するための Microsoft Fabric 内の中心的な場所となります。もちろん、フィルター、ソート、検索もできます。つまり、Microsoft Fabric 全体で一貫したデータ発見体験として、OneLake Data Hub は、ユーザーがデータを発見するあらゆる場所で利用できます。
Microsoft Fabric Data Factory

Data Factory in Microsoft Fabricは、Pro Data IntegrationとCitizen Data Integrationの良いところを、SaaSで提供するものです。

Microsoft Fabric Data Factory は、データベース、データウェアハウス、レイクハウス、リアルタイムデータなどの豊富なデータソースからデータを取り込み、準備、変換するための現代的なデータ統合環境を提供します。
市民開発者またはプロの開発者であっても、知的な変換によってデータを変換し、豊富な活動を活用することができます。
Microsoft Fabric Data Factory を使用することで、データフローとデータパイプラインの両方に高速なコピー (データ移動) 機能を提供します。Fast Copyを使用すると、お気に入りのデータストア間でデータを高速に移動することができます。最も重要なのは、Fast Copy によって、Microsoft Fabric のレイクハウスやデータウェアハウスにデータを取り込み、分析することができることです。
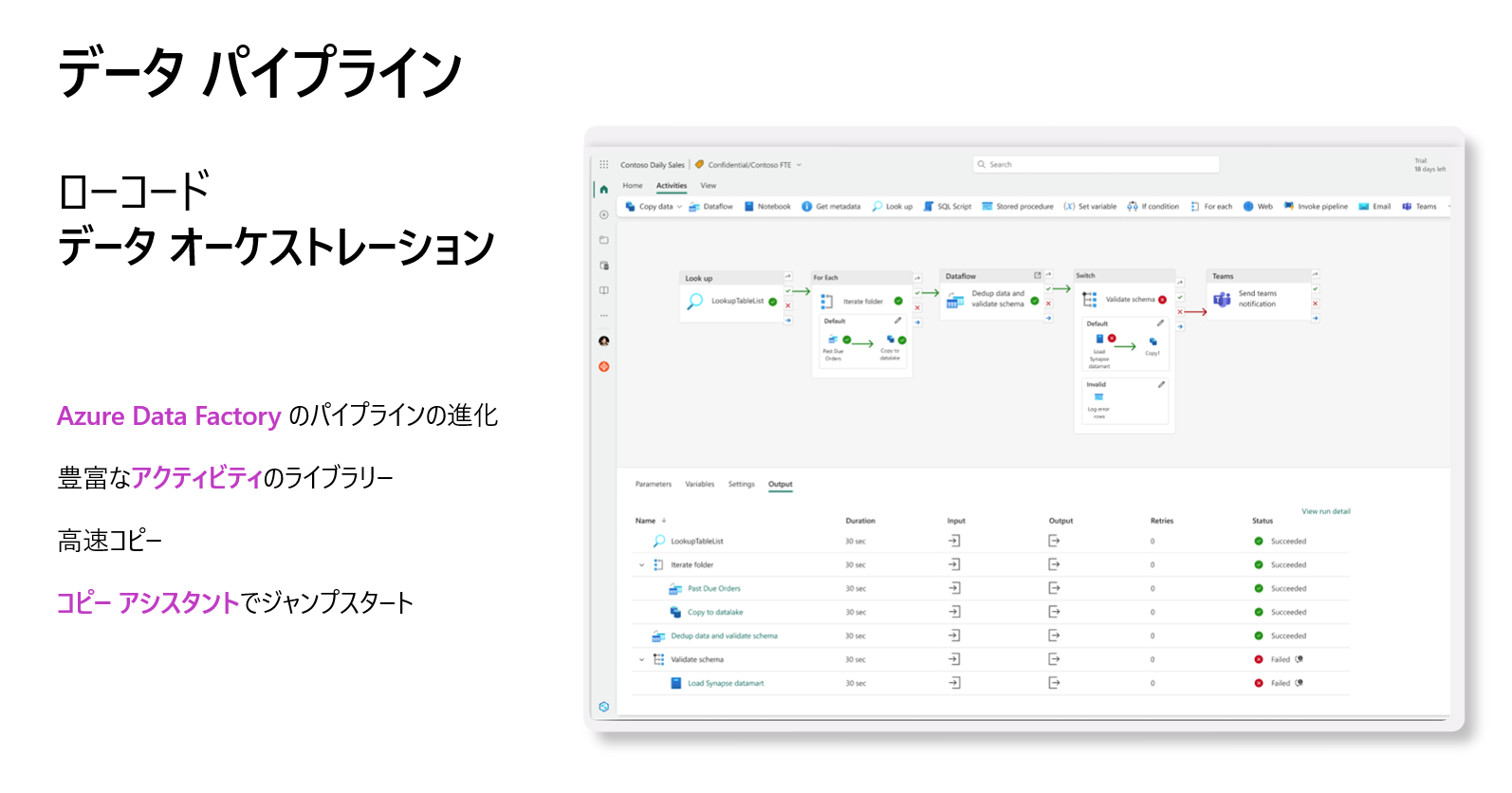
Microsoft Fabricのデータパイプラインは、Azure Data Factory (ADF) / Synapseのパイプラインを進化させたもので、多機能なアクティビティライブラリにアクセス可能です。データをレイクに高速で取り込む機能や、ノートブック、ストアドプロシージャなどの実行をオーケストレーションする機能があります。また、お気に入りのデータソースからデータ宛先(データウェアハウスなど)へのデータコピーには、コピーアシスタントを使用でき、即時に作業を開始することが可能です。
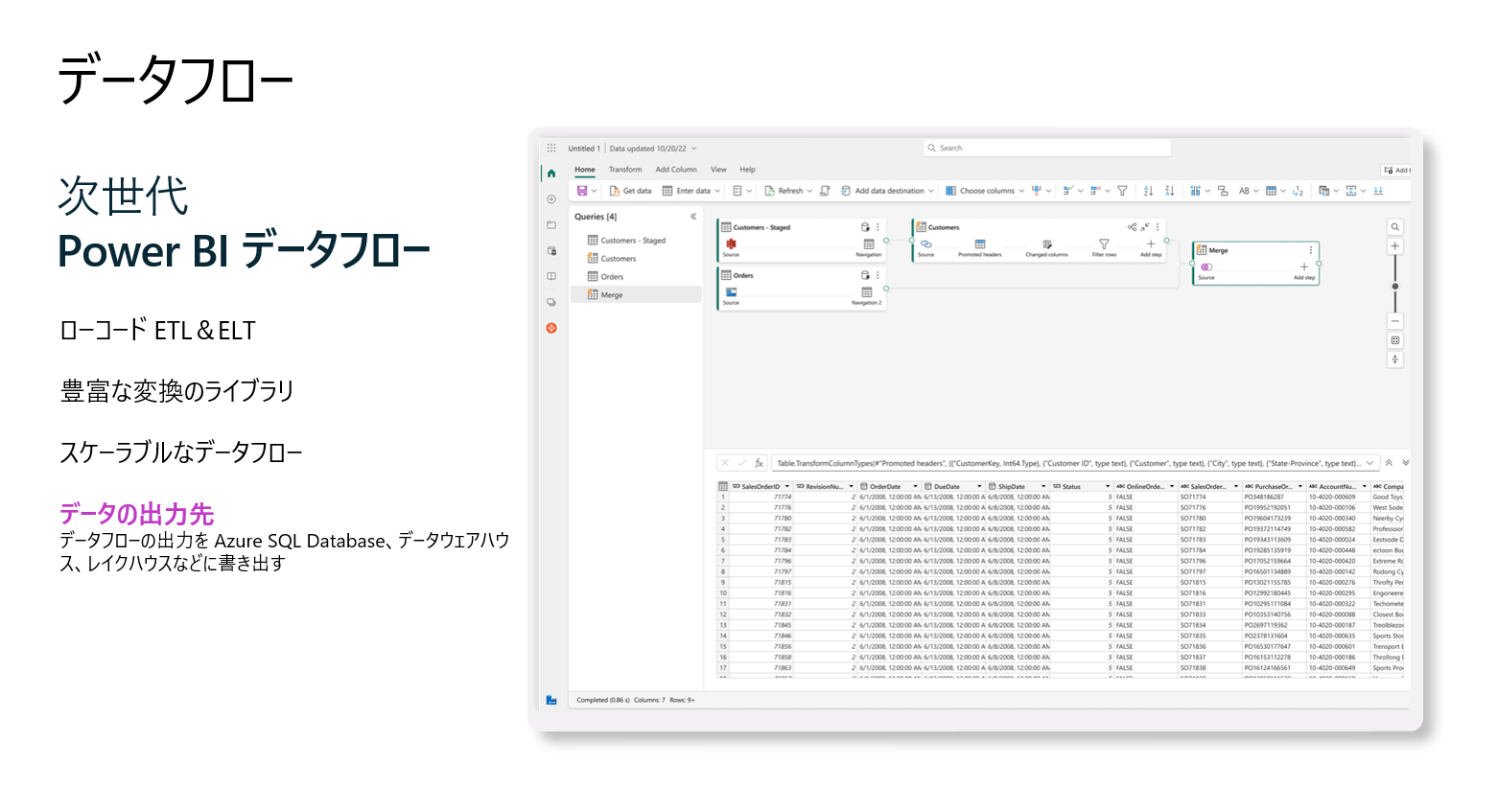
Dataflows Gen2 は、Power BIの次世代 Dataflows で、ETLとELTの両方をローコードのPower Queryを活用して実行することが可能です。これはMicrosoft Fabricコンピュートの強化により、現在以上の高レベルのスケーリング能力を提供します。データフローは豊富な変換セットを活用でき、最も複雑な変換タスクのスケーリングも可能です。また、ユーザーフィードバックを基に、データフローの結果を任意のデータ送信先に保存できるようになりました。Microsoft Fabricのデータファクトリーは、データフローの出力先を選択し、好みの場所にデータ出力を永続化することが可能となりました。

クラウド上の全ユーザーに対してグローバルレベルのデータ統合プラットフォームを提供するためには、ビジネスにとって重要な全てのデータソースへの自由な接続性が求められます。この目的のために、Data FactoryとPower Queryが 170以上のコネクタをサポートし、オンプレミスやクラウドのデータベース、分析プラットフォーム、ビジネスアプリケーションに直ちに対応します。
Microsoft Fabric Synapse Data Engineering

Microsoft Fabric のデータ エンジニアリングを使用すると、ユーザーは、組織が大量のデータを収集、保存、処理、および分析できるようにするインフラストラクチャとシステムを設計、構築、および保守できます。
例えば、下記のようなことを行うことができます。
- レイクハウスを使用したデータの作成と管理
- レイクハウスにデータをコピーするパイプラインを設計する
- Spark ジョブ定義を使用してバッチ/ストリーミング ジョブを Spark クラスターに送信する
- ノートブックを使用して、データの取り込み、準備、変換のためのコードを記述する
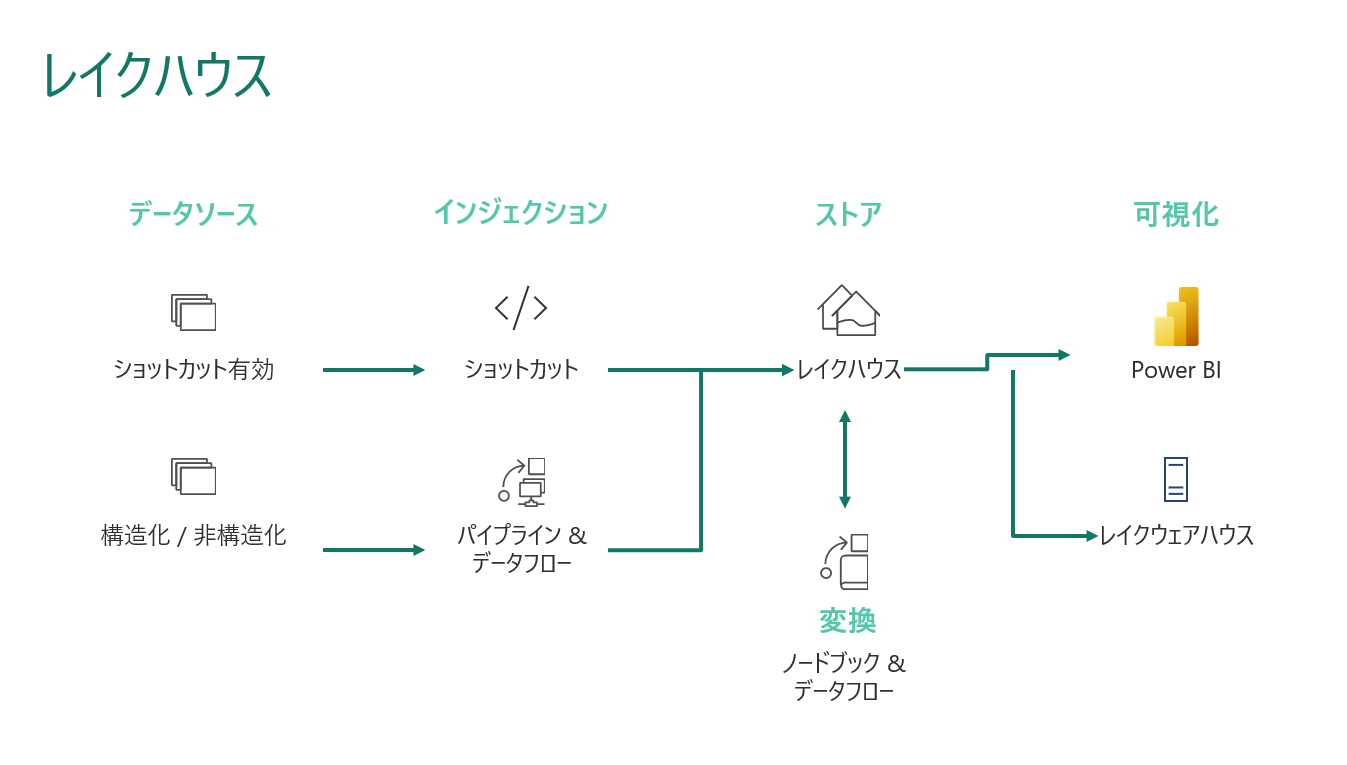
Microsoft Fabric の Lakehouse 分析シナリオでは、エンドユーザーが他のデータを活用できるように、他のクラウドのリポジトリ、パイプライン、データフローへのショートカットを使用してOneLakeにデータを取り込むことができるようになっています。
Microsoft Fabricにデータが取り込まれると、ユーザーはノートブックを活用してOneLakeでデータを変換し、メダリオン構造を持つLakehousesに保存することができます。
そこから、ユーザーはシースルーモードやSQLエンドポイントを使って、Power BIでデータの分析・可視化を開始することができます。
Synapse Data Engineeringでは、レイクハウスの操作をすべてサポートし、データのETLをさらに加速します。
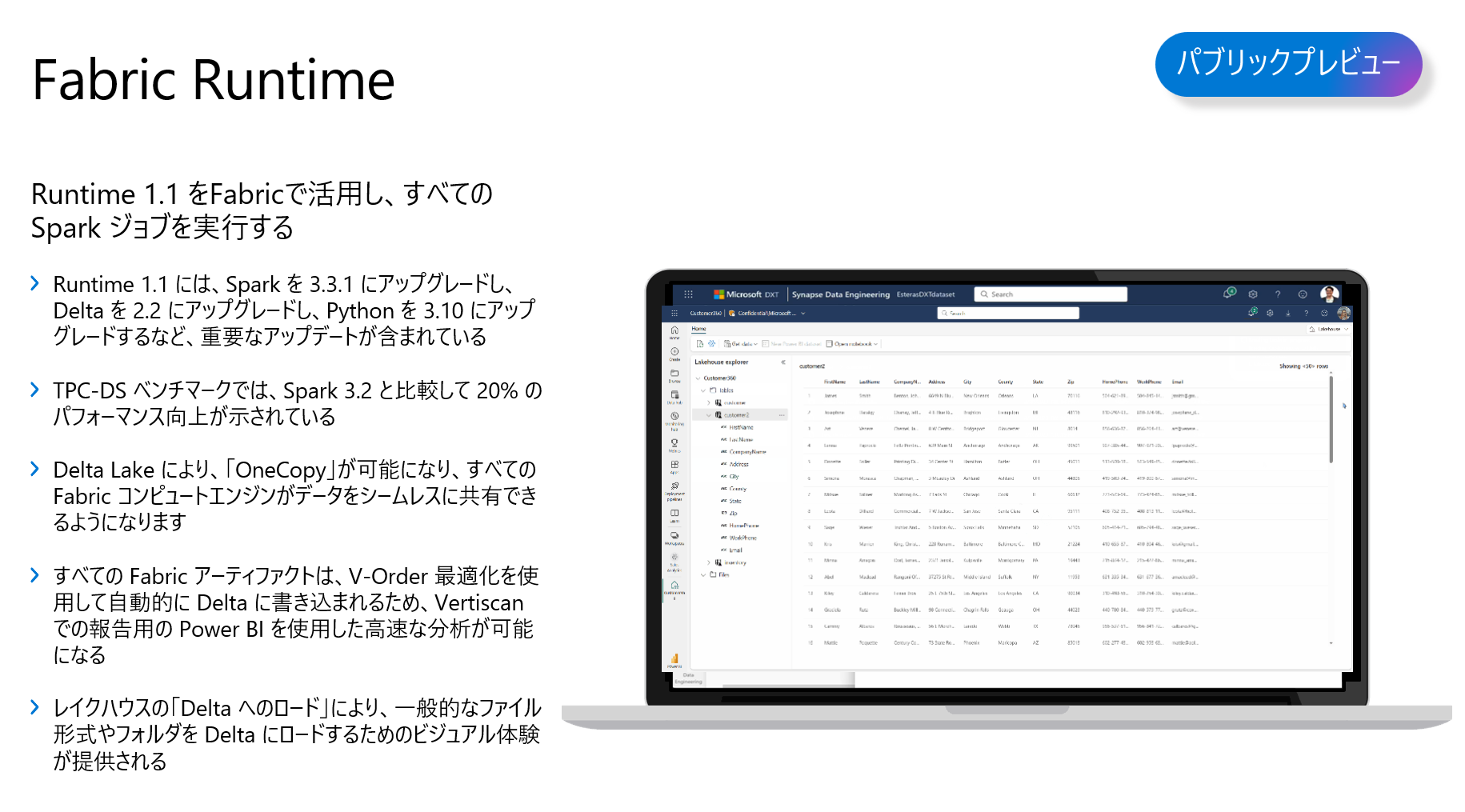
Microsoft Fabric は、Fabric Runtimeを提供します。そのRuntimeの中には、Spark 3.3.1とDelta 2.2をさらにupgradeし、さらにPython 3.10などを組み合わせています。つまり、デフォルトでは、3 in 1のイメージです。そこに足りなかったライブラリはさらにカスタマイズ可能です。
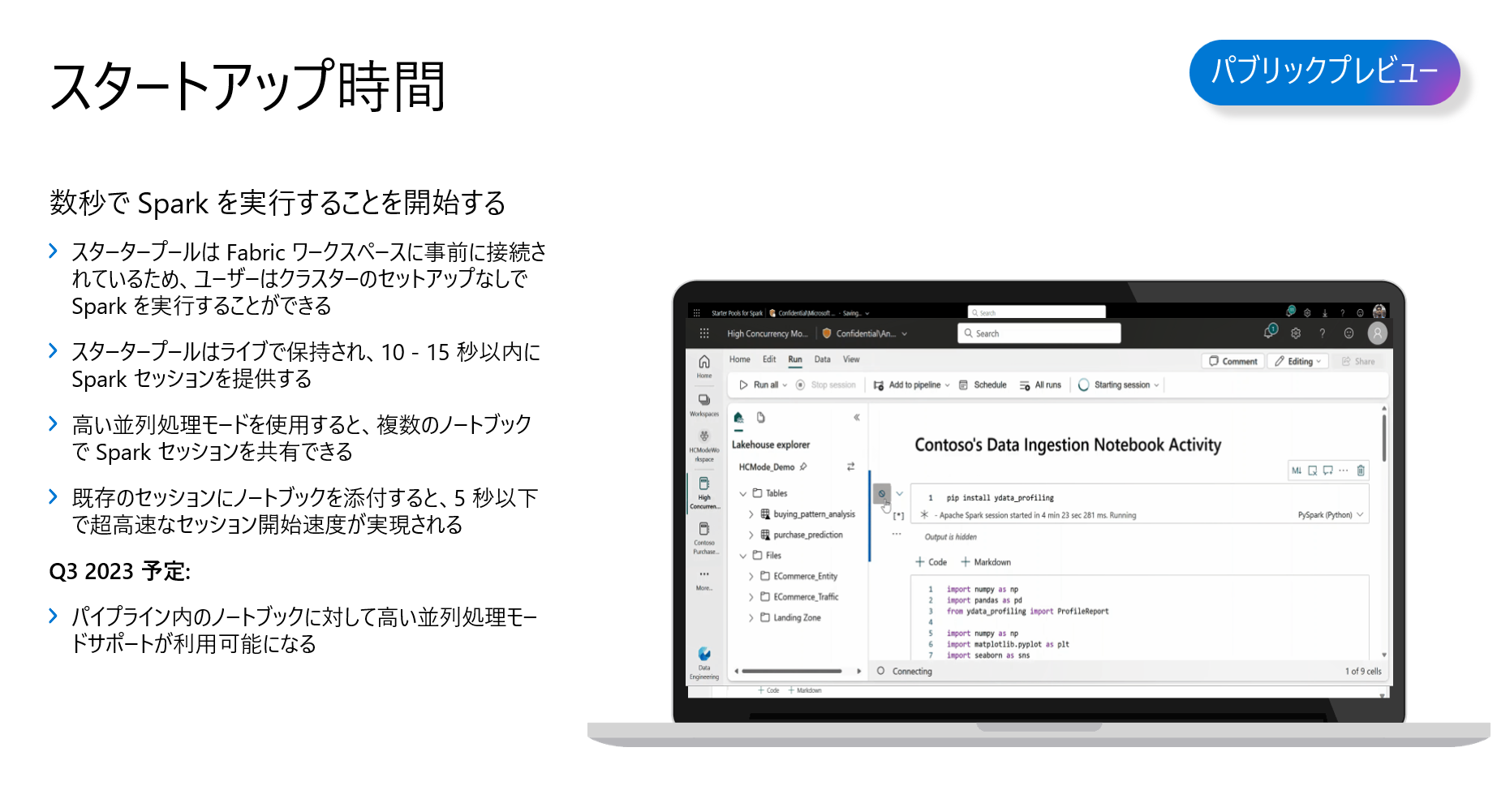
ノードブックを使っている方はすぐにわかりますが、Spark クラスタを起動するのに、初回は少なくても2、3分間かかってしまします。
Microsoft Fabric は、デフォルトでスタータープールと呼ばれているSpark クラスタインスタンスがあらかじめに搭載されています。そして、ライブで保持されているため、ノードブックで実行するためのクラスタ立ち上げは、わずか10数秒です。

Data Wrangler は、探索的データ分析を実行するための没入型エクスペリエンスをユーザーに提供するノートブックベースのツールです。この機能は、グリッドのようなデータ表示と動的な要約統計、およびクリックするだけで適用できる一連の一般的なデータクレンジング操作を組み合わせたものです。各操作では、再利用可能なスクリプトとしてノートブックに保存できるコードが生成されます。
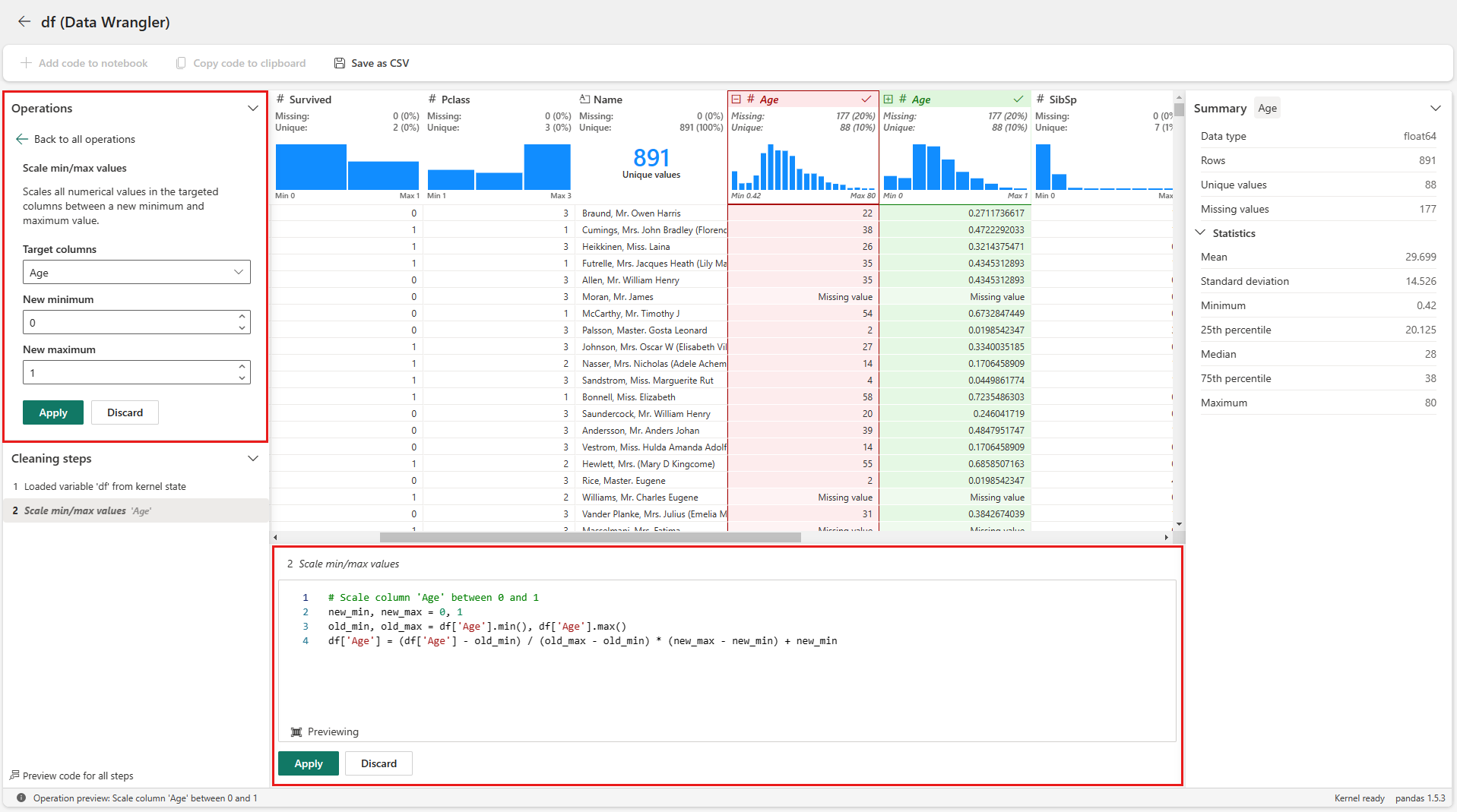
ノードブックのリボンボタンで起動するか、コードセルで、Pandas DFを Print する方法で、Data Wrangler を起動できます。Pandas DF の Power Query 版のようなイメージです。今後、Spark DFもサポートされることを期待します。
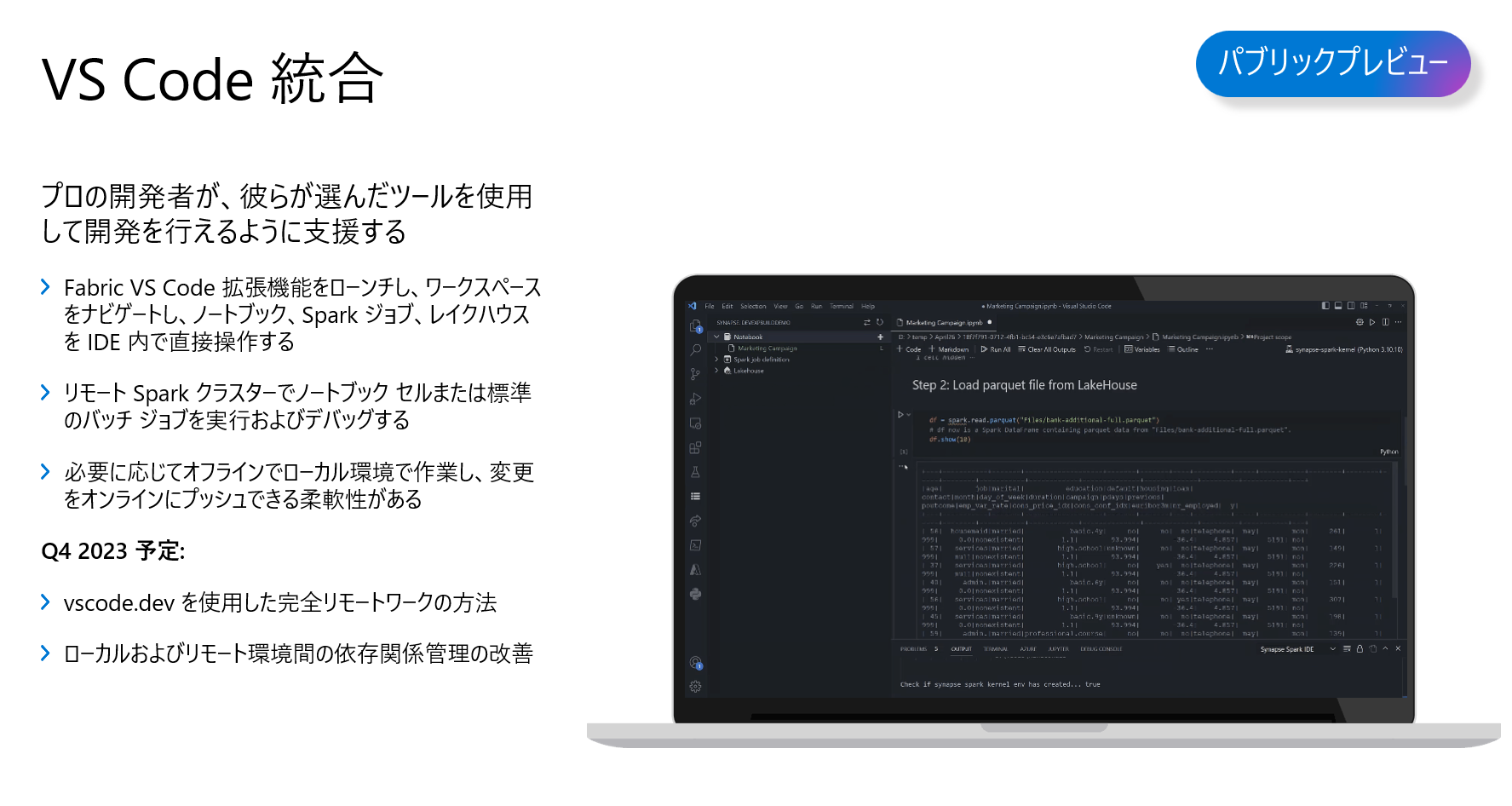
Synapse ノードブックはVS Code統合はできなかったのですが、Microsoft Fabric ノードブックは、VS Codeと統合も可能となります。

Microsoft Fabric のノードブックのUIで、「Open in VS Code」ができるようになります。
Microsoft Fabric Synapse Data Science

Microsoft Fabricは、データエンリッチメントとビジネス分析情報を目的として、ユーザーがエンドツーエンドのデータサイエンスワークフローを完了できるようにするデータサイエンスエクスペリエンスを提供します。データの探索、準備、クレンジングから実験、モデリング、モデルスコアリング、予測分析情報の提供からBIレポートまで、データサイエンスプロセス全体にわたる幅広いアクティビティを完了できます。
Microsoft Fabric ユーザーは、データサイエンスのホームページにアクセスできます。そこから、さまざまな関連リソースを見つけてアクセスできます。たとえば、機械学習の実験、モデル、ノートブックを作成できます。また、データサイエンスのホームページで既存のノートブックをインポートすることもできます。
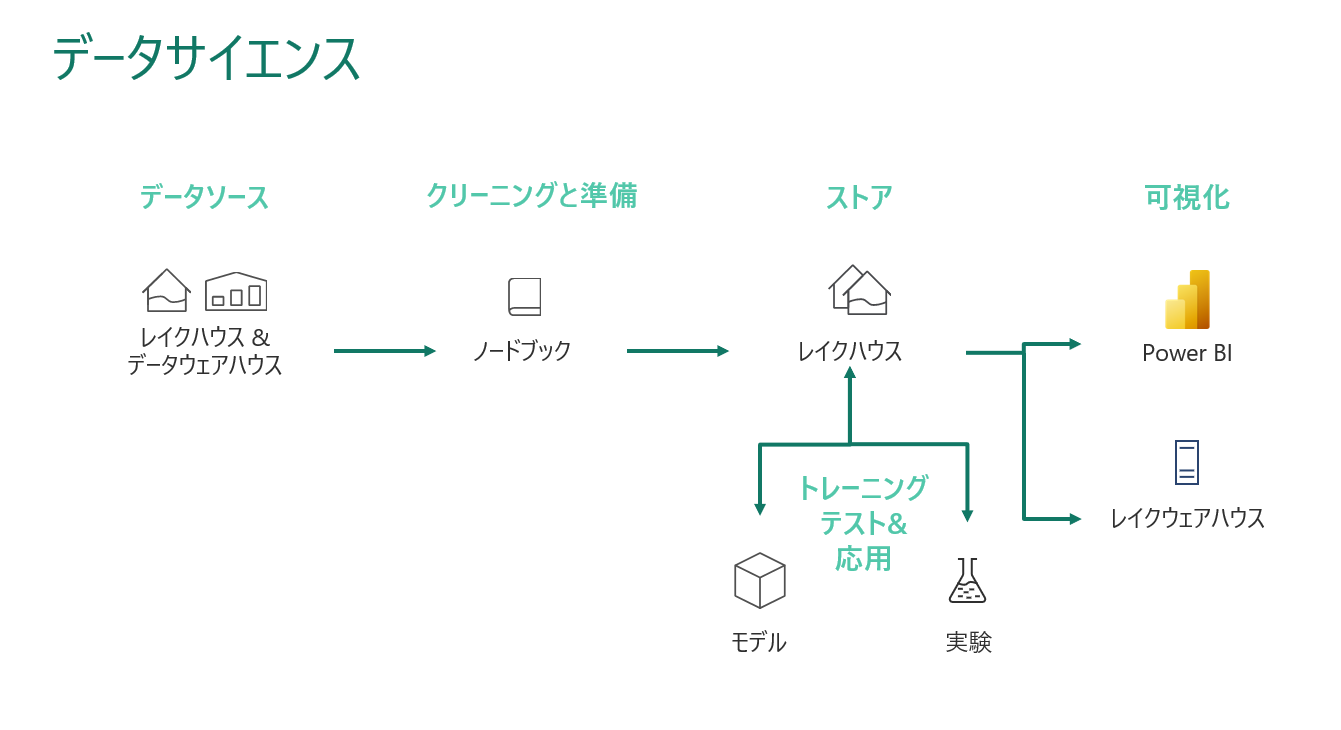
データサイエンス分析のシナリオは、LakehouseやData Warehouseのパスと同様にインジェストすることができます。
データを取り込んだら、ノートブックを使ってクリーニングと準備を行い、メダリオン構造でLakehouseに格納します。
データのクリーニングと保存が完了すると、Lakehouse上で直接機械学習モデルの学習とテストが可能になります。
他のアナリティクスシナリオと同様に、ビジネスユーザーはシースルーモードまたはSQLエンドポイントを使用してPower BIでデータを分析・可視化することができます。
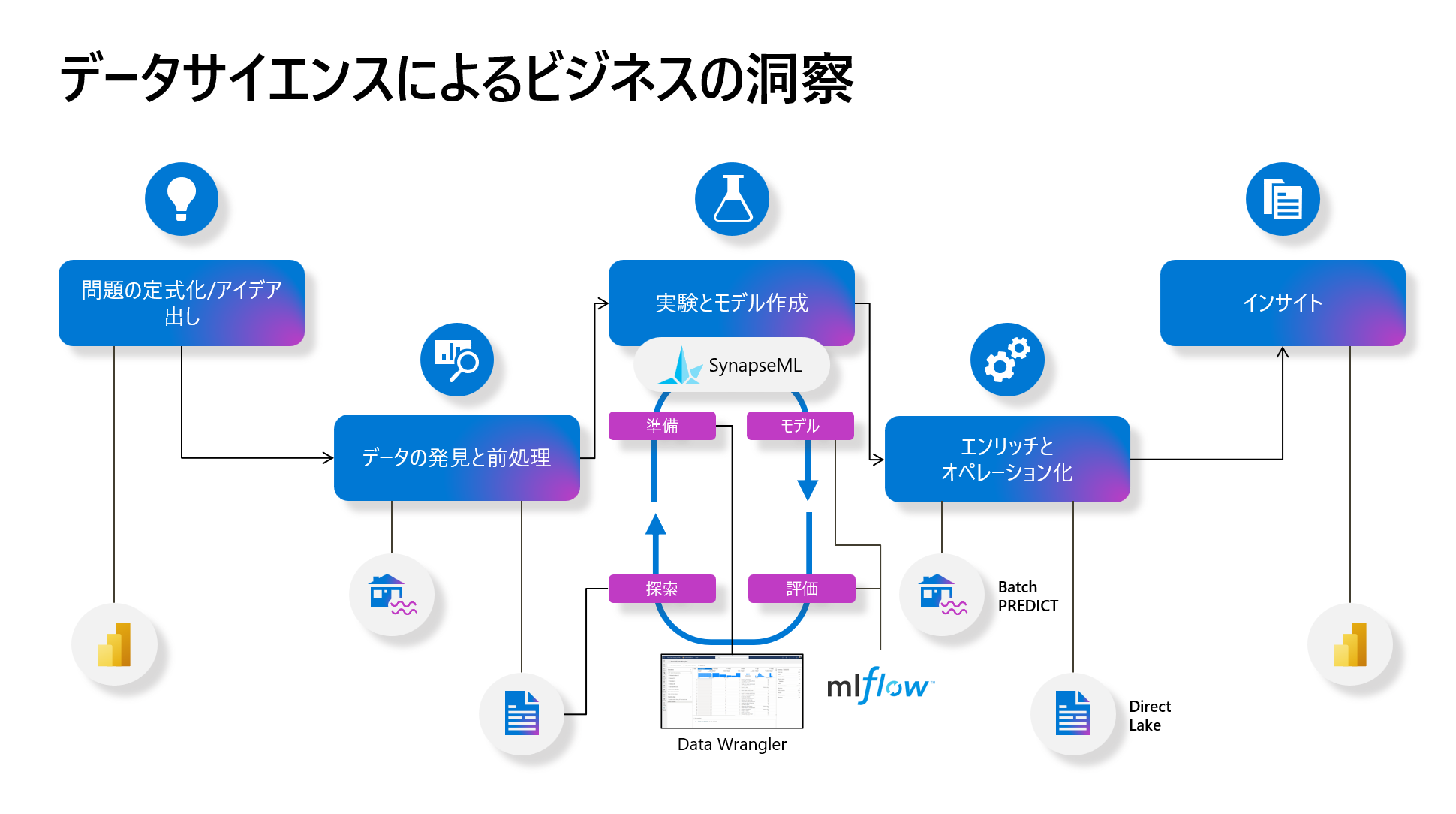
Microsoft Fabric のデータサイエンティストは、一般的なでータサイエンスプロセスの「問題の定式化とアイデア」、「データの検出と前処理」、「実験とモデリング」、「エンリッチメントと運用化」、「洞察を得る」といったそれぞれのプロセスをサポートします。

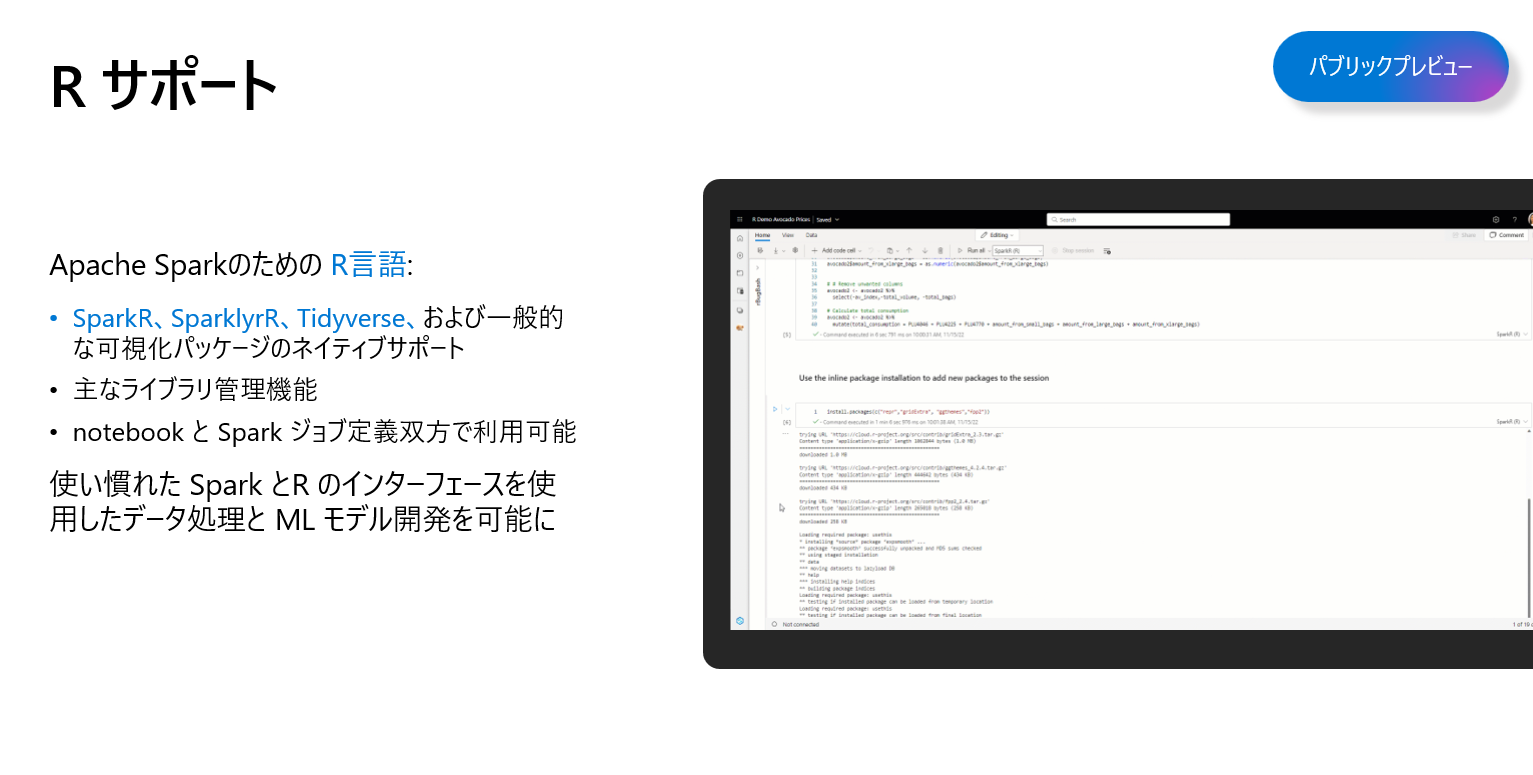
MLflowとR言語、Azure Open AI もサポートします。
Microsoft Fabric Synapse Data Warehose

T-SQL ユーザーにとっては、Microsoft Fabric の中で、唯一、SQL Endpointを提供する進化されたSynapse 専用SQL Poolです。ただし、バックラウンドのアーキテクチャはSynapse 専用 SQL Poolと全く違います。
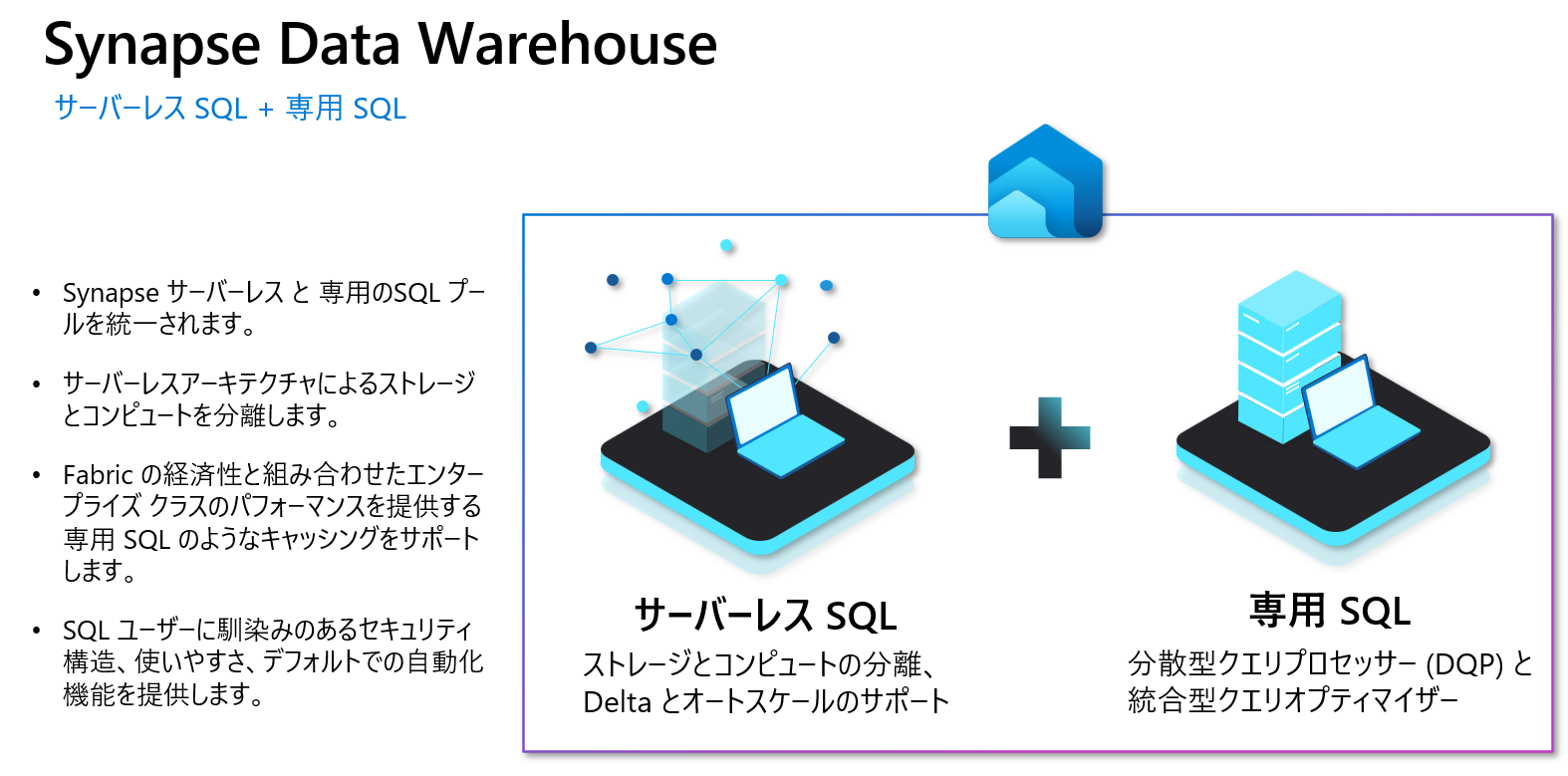
今回のFabric DWは、一言で言いますと、Synapse Serverless SQL Poolと専用SQL Poolのいいところを取って、統一されるようになりました。
その特徴としては、サーバーレスによる、ストレージや計算ノードの分離、そして、プロビジョニングタイプの分散クエリプロセッサー、及び、キャッシングもサポートされるようになっています。
さらに、SQLユーザーによっては、なじみがある使い勝手、セキュリティの設定、そして、自動統計などの機能も提供してくれるようになっています。
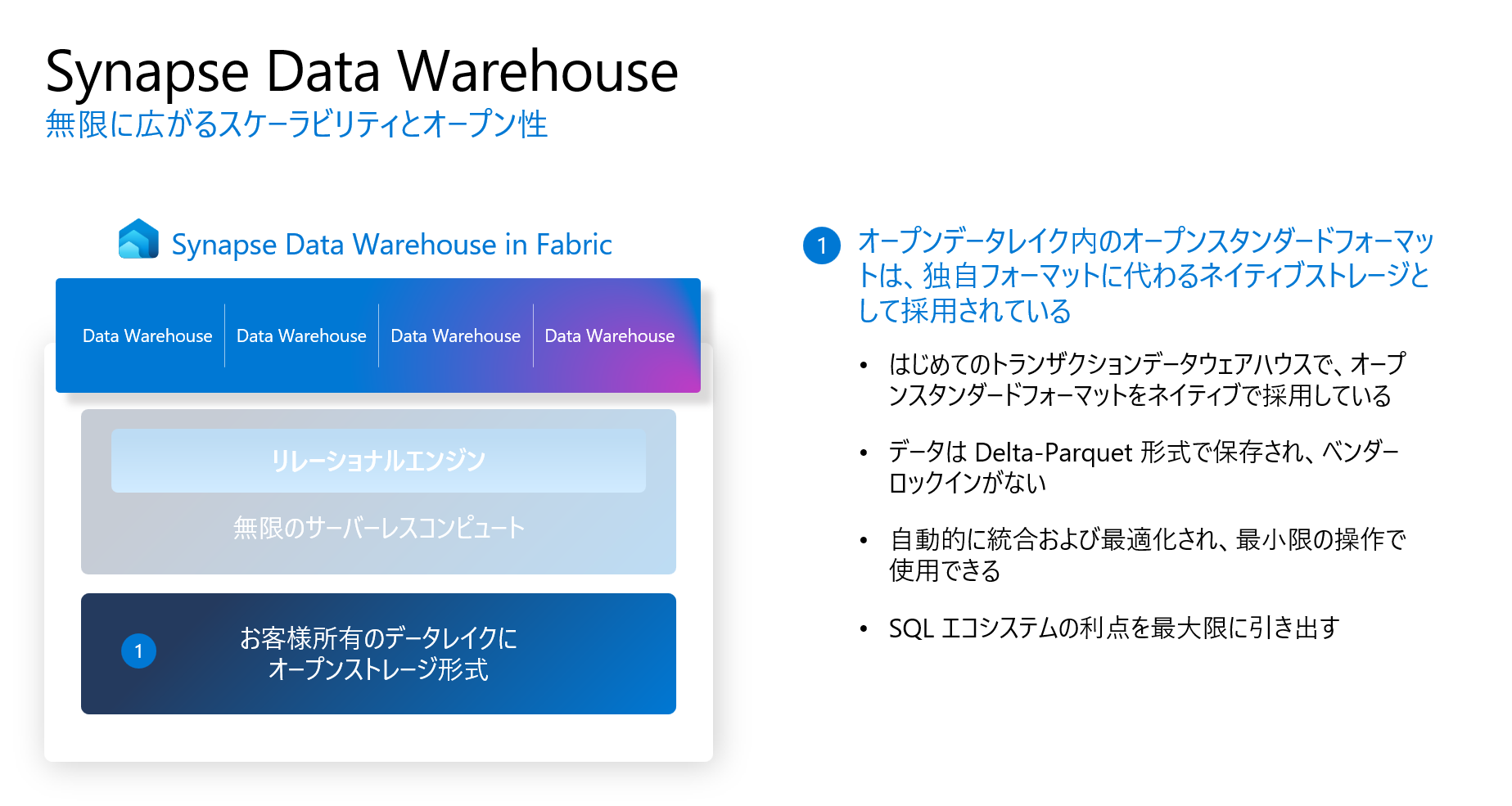
データはすべてDelta Lake形式で、OneLakeに保存されます。つまり、SQL Serverや、SQL Databaseのような独自のフォーマットを持つデータファイルのではなく、すべて、Delta Lake (Parquet)フォーマットとして、データを保存します。従来のSynapse 専用 SQL Poolでは、データのExportを行わないと、このようなことができませんが、Fabric DW は直接に、OneLakeに書き込みます。つまり、Fabric DWは、Delta Lakeを採用しています。
Delta Lake というのは、一言で言いますと、トランザクション型の大規模な、データレイクの、ストレージレイヤーです。Parquetフォーマットでありながら、トランザクションを対応していることです。
ベンダーロックインもなく、オーブンなフォーマットで、OneLake上に保存されているため、他のDB製品や、データ連携も即時に可能です。
T-SQLを使って、OneLake上にある、Delta LakeのParquetに対して、操作するを行います。
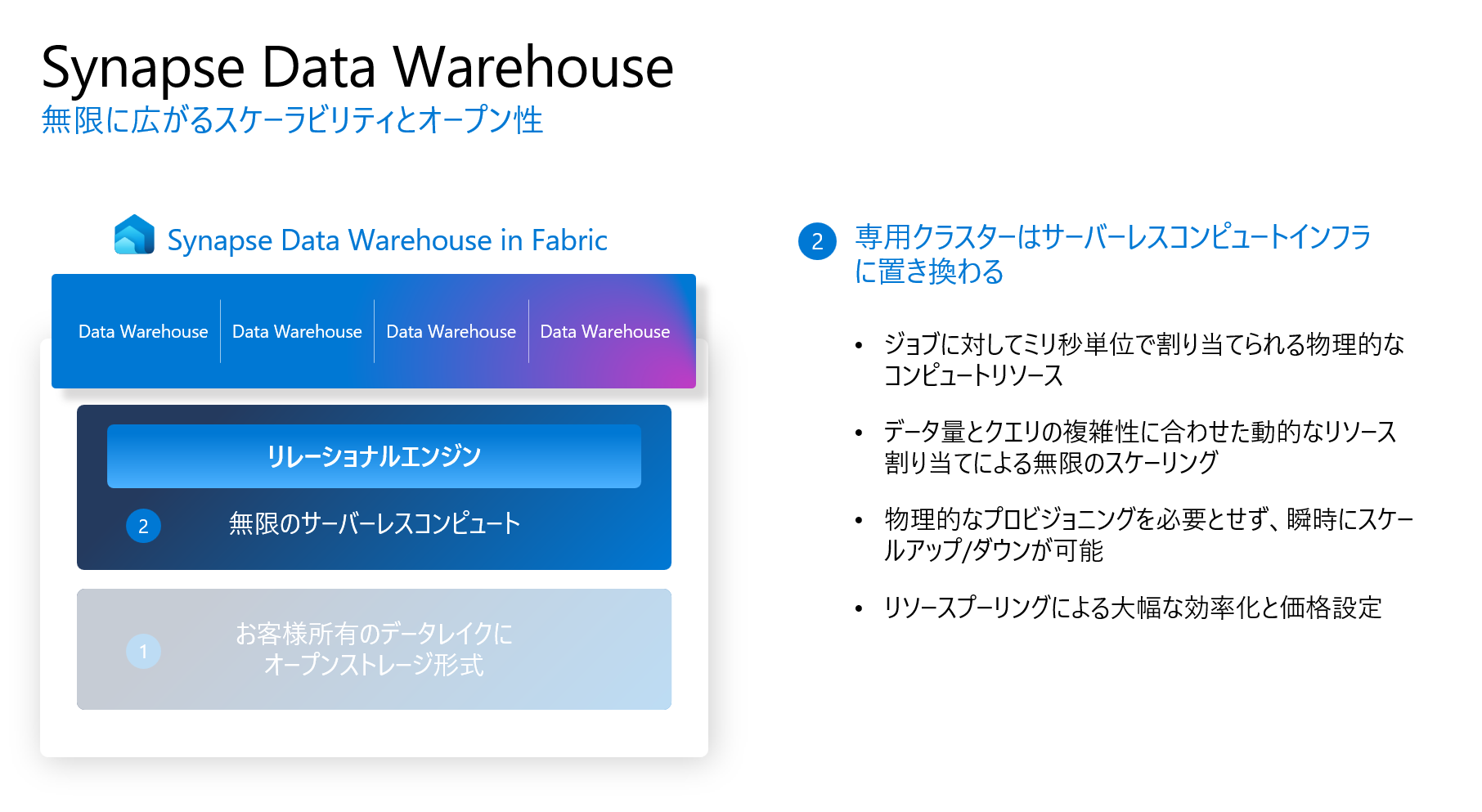
また、従来のプロビジョニングタイプと違い、すべてサーバーレスコンピュートインフラに置き換わるようになっています。つまり、従来のDWUの概念はありません。
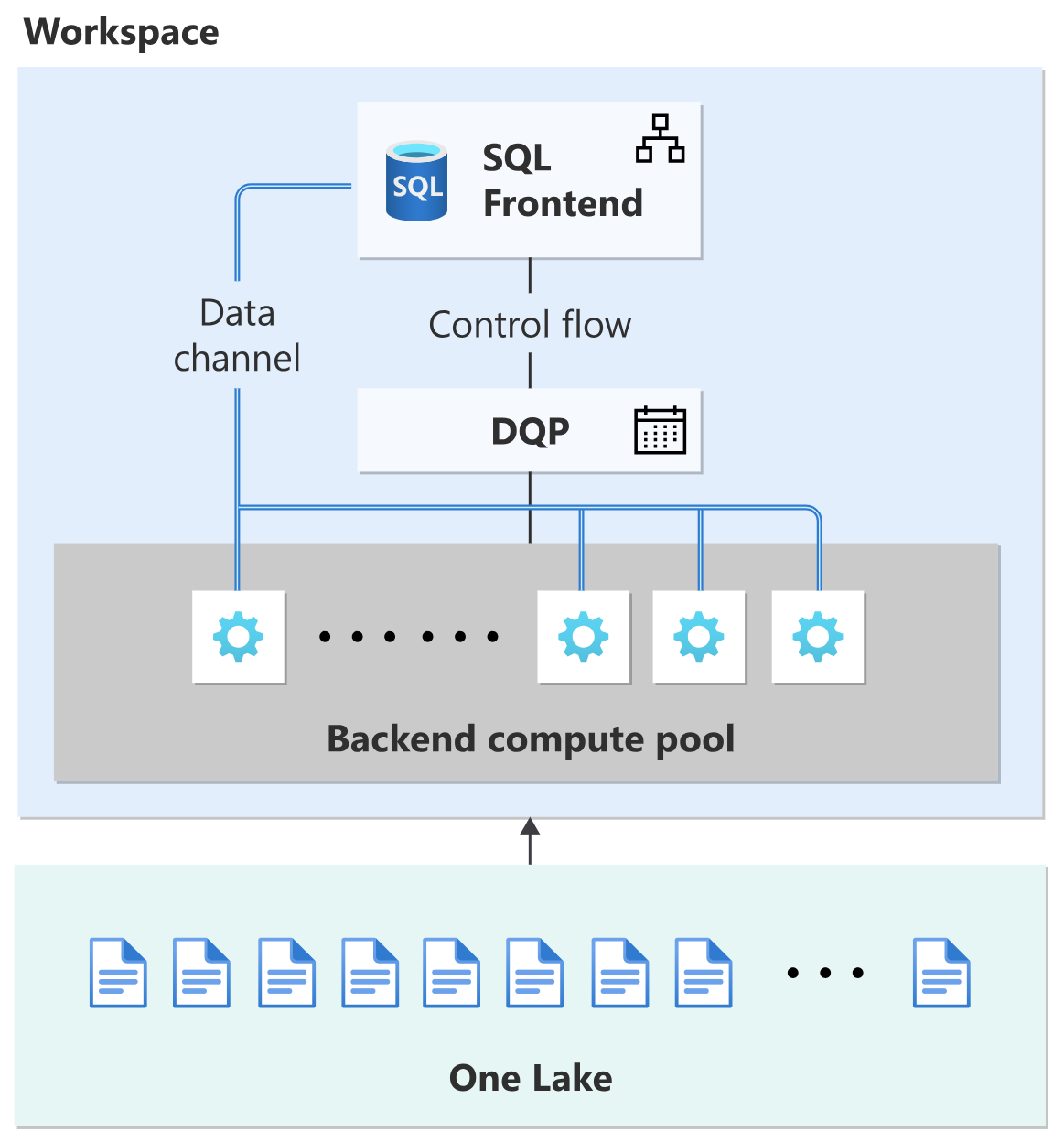
Fabric DWのバックラウンドには、SQL Front End、DQP、SQL Back Endのような分散されたコンピュートが、多数存在しています。
それによって、サーバーレスの特徴で、自由にスケーリングできます。つまり、リソースの上げ下げは、ユーザー側の管理は一切要りません。
しかも、その上げ下げは、ミリ秒単位で、物理のコンピュートリソースが割り当てられます。
僅か、90秒ぐらいで、5000万件のデータをロードできます。それ以上できると考えらえます。
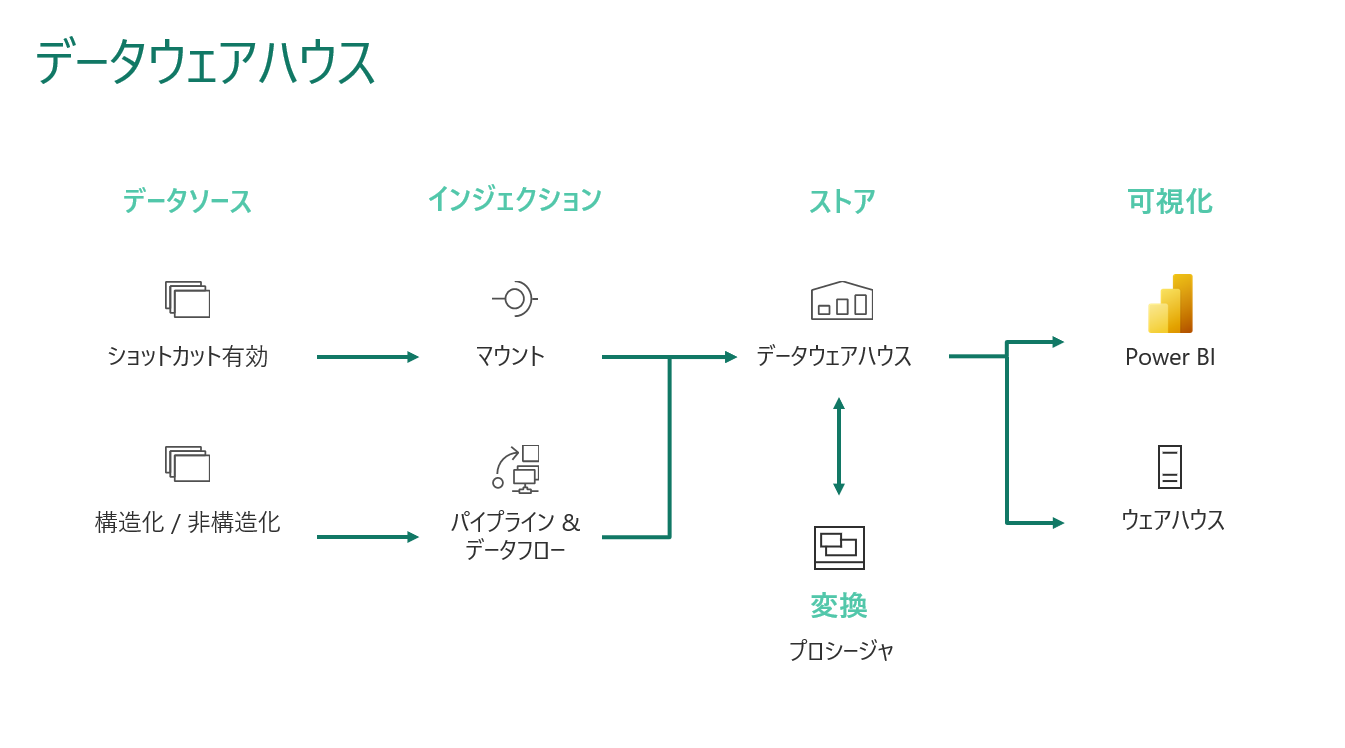
Data Warehouse の分析シナリオでは、搭載されている既存のソースを利用し、パイプラインとデータフローでは、必要なその他のすべてのデータを取り込むことができます。
そして、ITチームはデータを変換するためのプロシージャを定義し、OneLakeにParquet/Delta Lakeファイルとして格納することができます。
そこからビジネスユーザーは、DirectLakeモードまたはSQLエンドポイントを使用して、Power BIでデータを分析・可視化することができます。
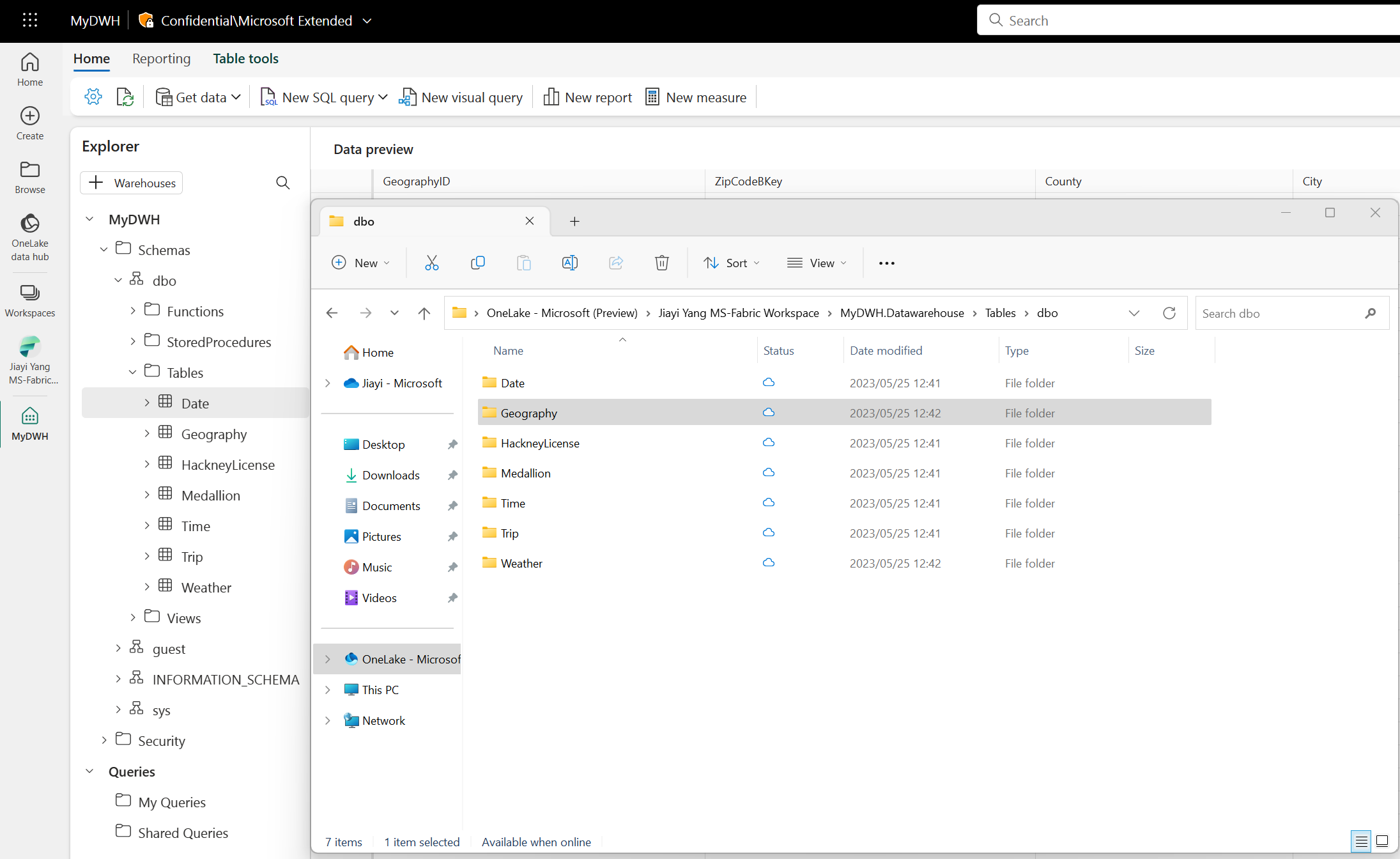
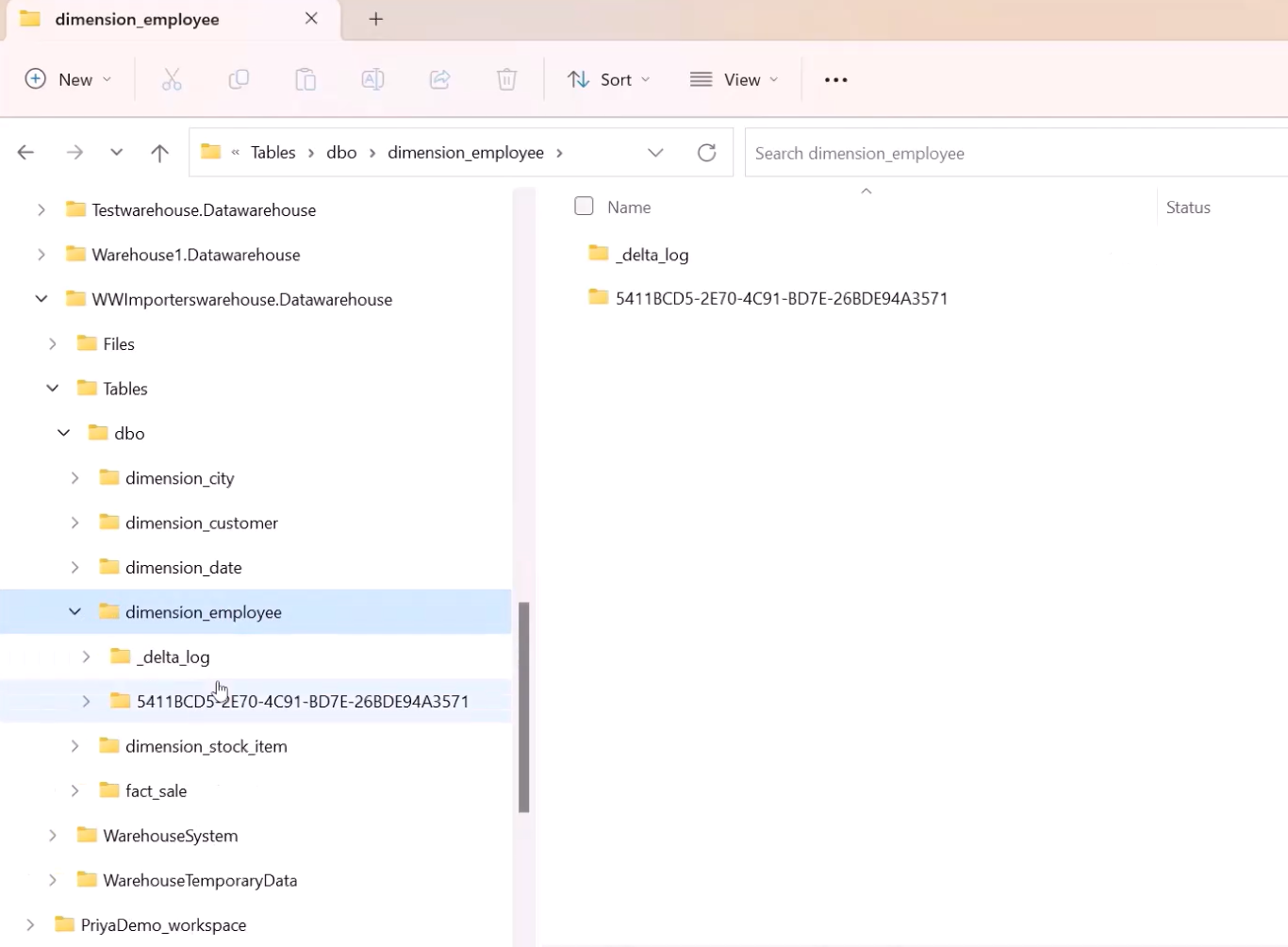
OneLake File Explorerをインストールして、OneDriveのように、Windows エクスプローラーのように、表示や編集も可能です。
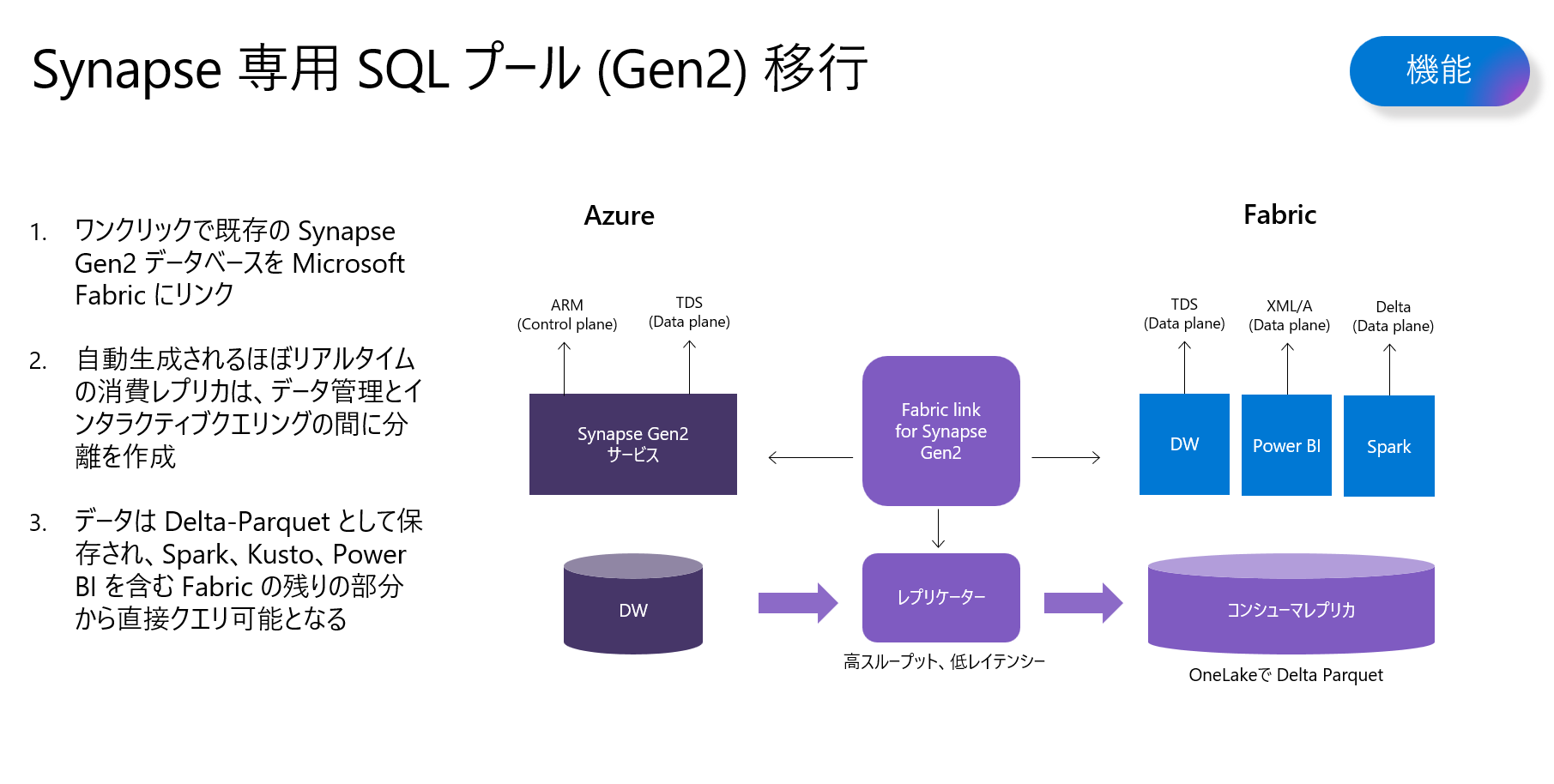
既存のSynapse Dedicated SQL Poolを利用しているユーザーは、わずかワンクリックで、Fabric Link for Synapse Gen2を使って、Fabric にほぼリアルタイムで同期できます。該当機能は、パブリックプレビュー時点では、まだ使えないですが、今後の機能更新を期待したいです。
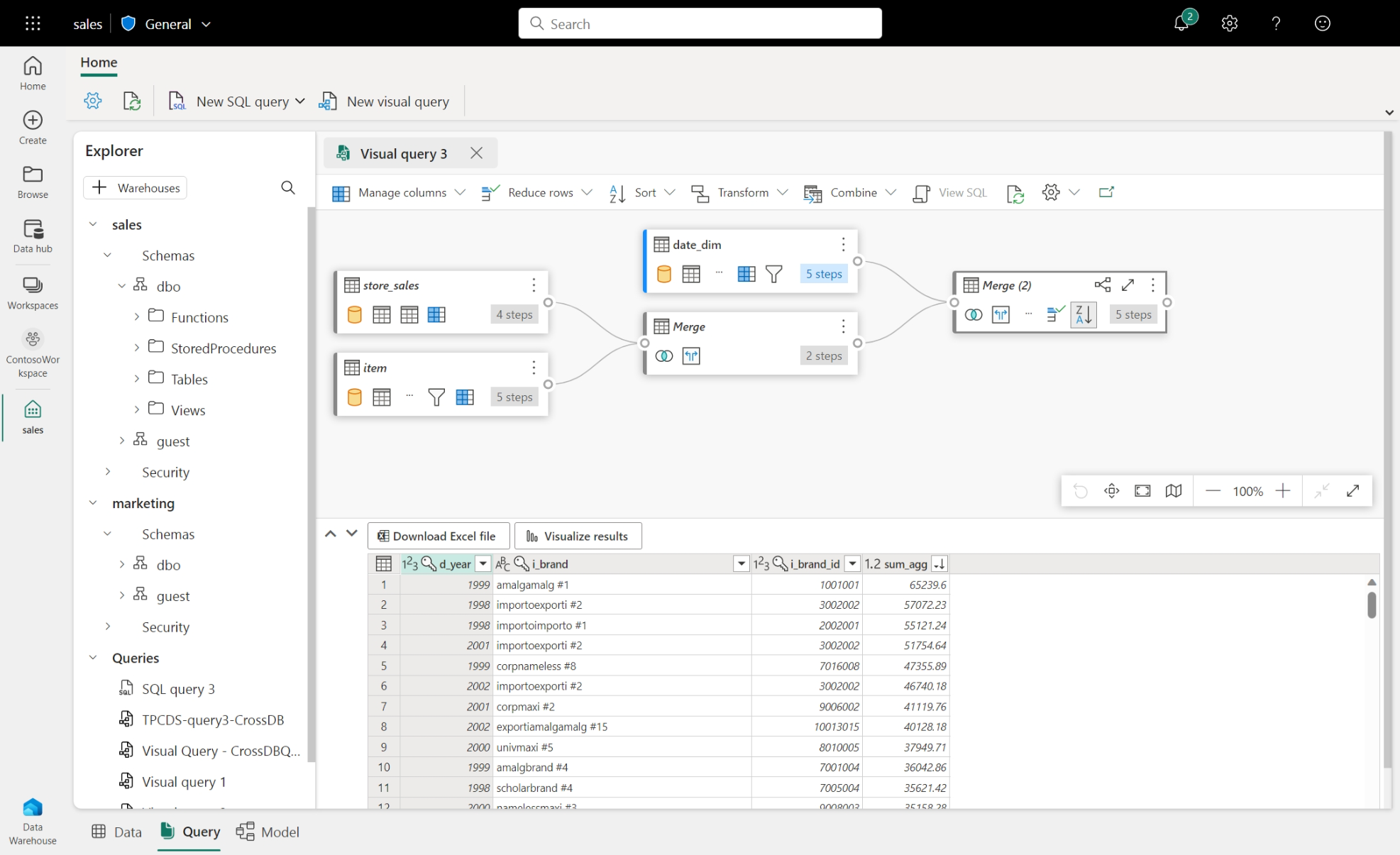
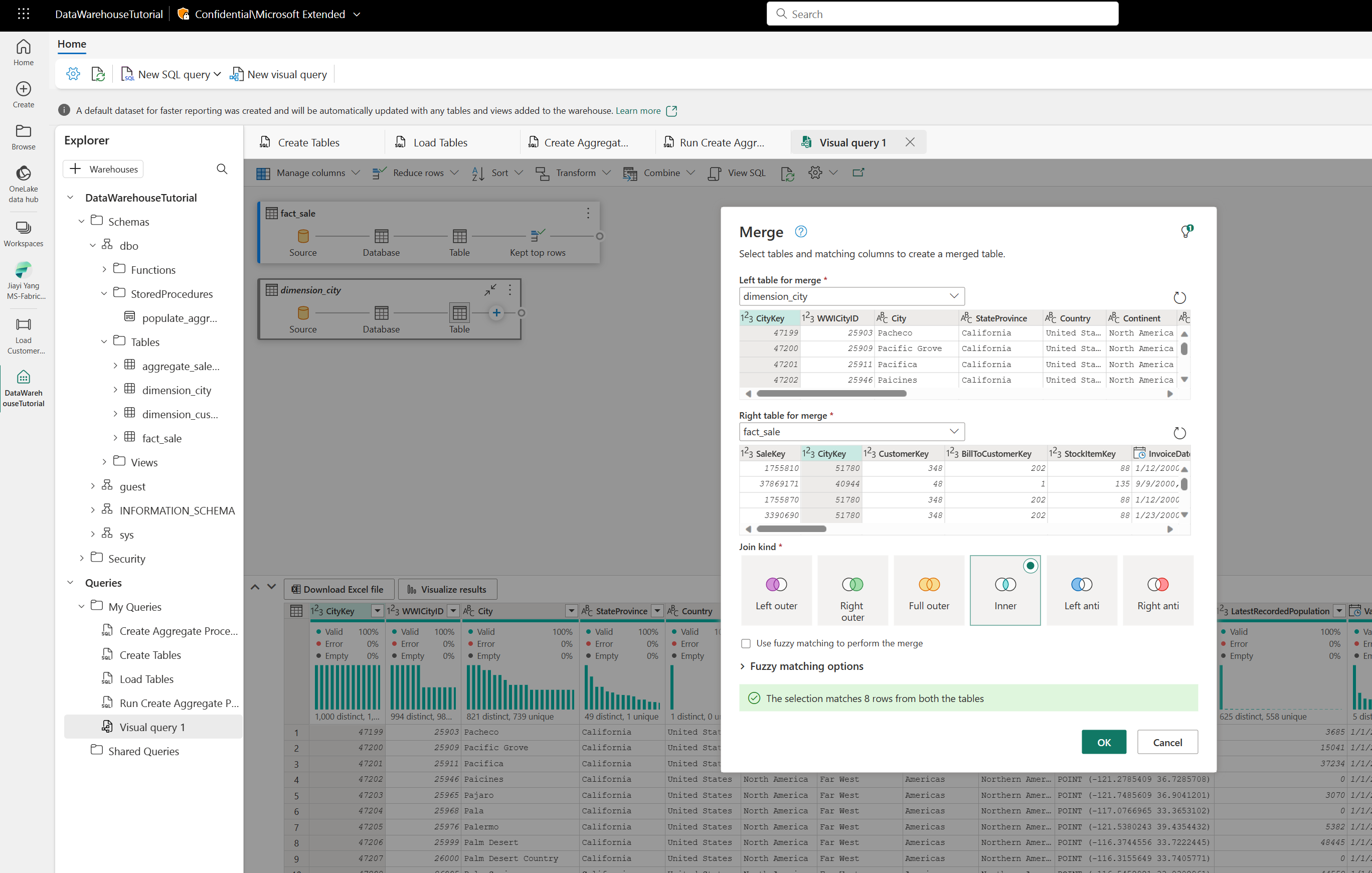
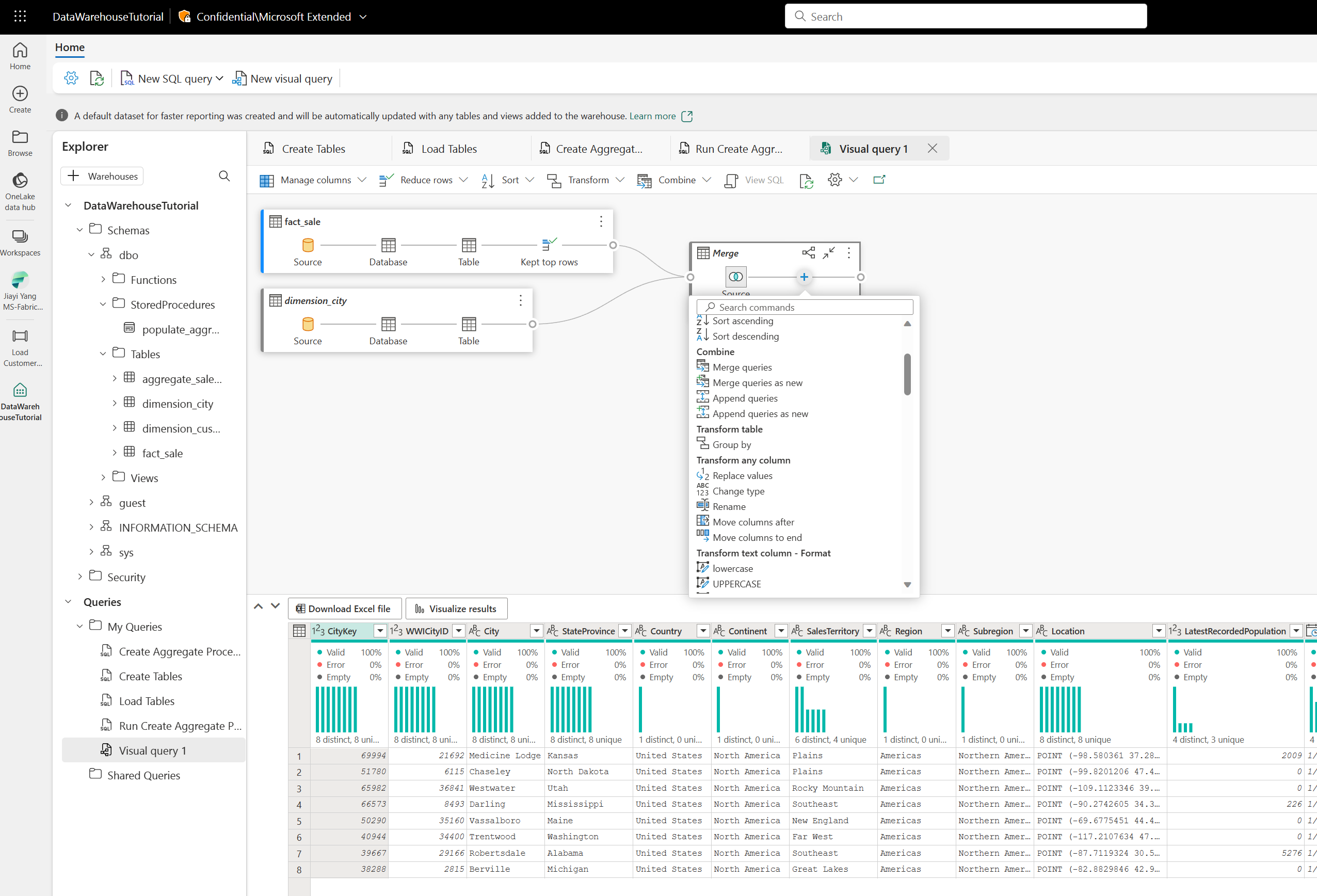
そして、SQLが苦手の方向けに、Visual Query エディターも提供されています。UIで、Table結合したりできます。それは、Azure Data Factory や Synapse の データフローと似ていますが、同じものではありません。そして、UIもクロスクエリもサポートしています。現時点では、DDLまたはDMLがサポートされていないですが、DQLであるSELECT ステートメントのみサポートしています。
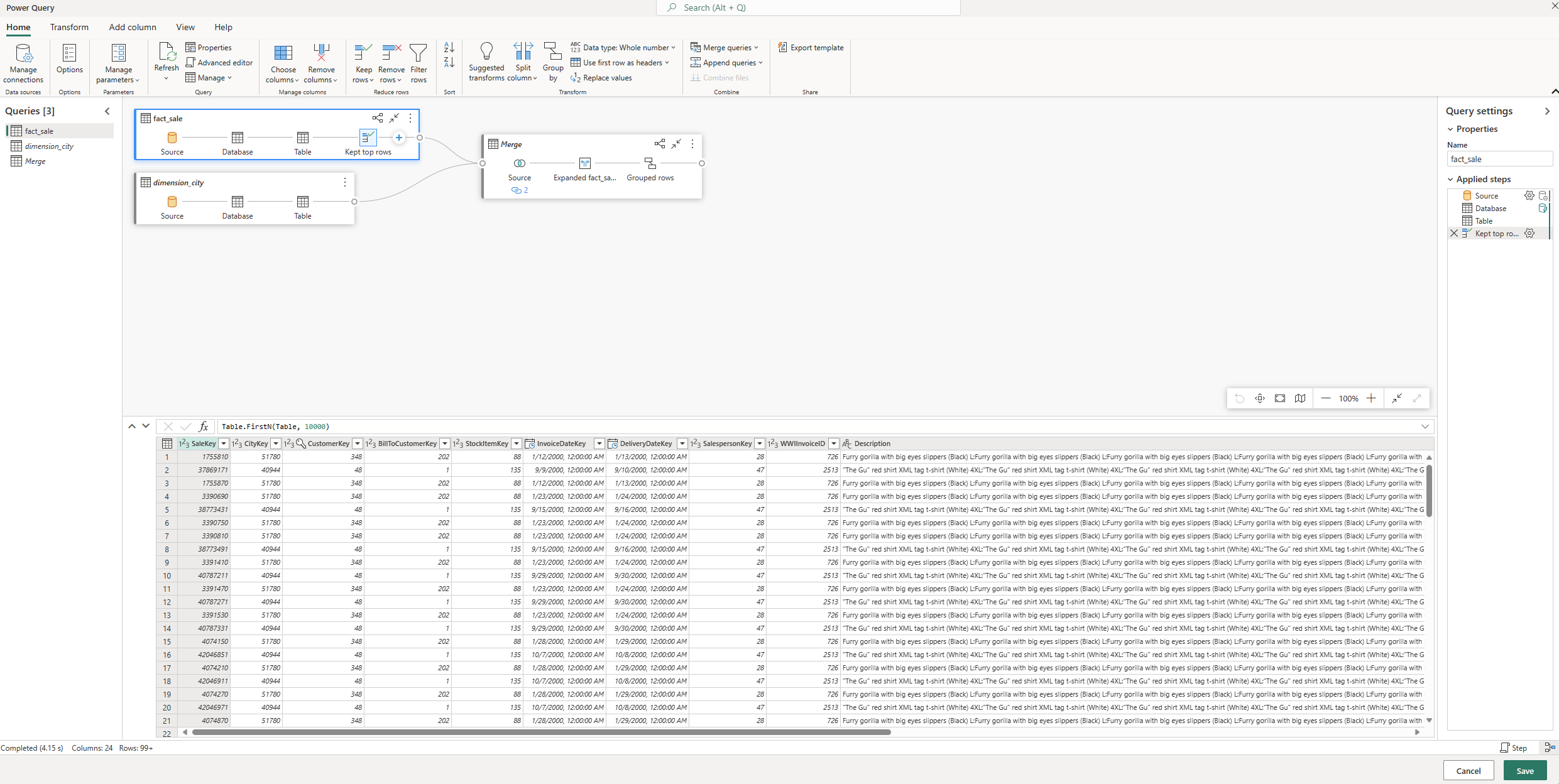
さらに、Power Query になれている方は、このVisual Query から Power Query に「一瞬」で変換、切り替えもできます。そして、Power Query で編集したステップも Visual Query にも反映されます。つまり、連携プレイできます。
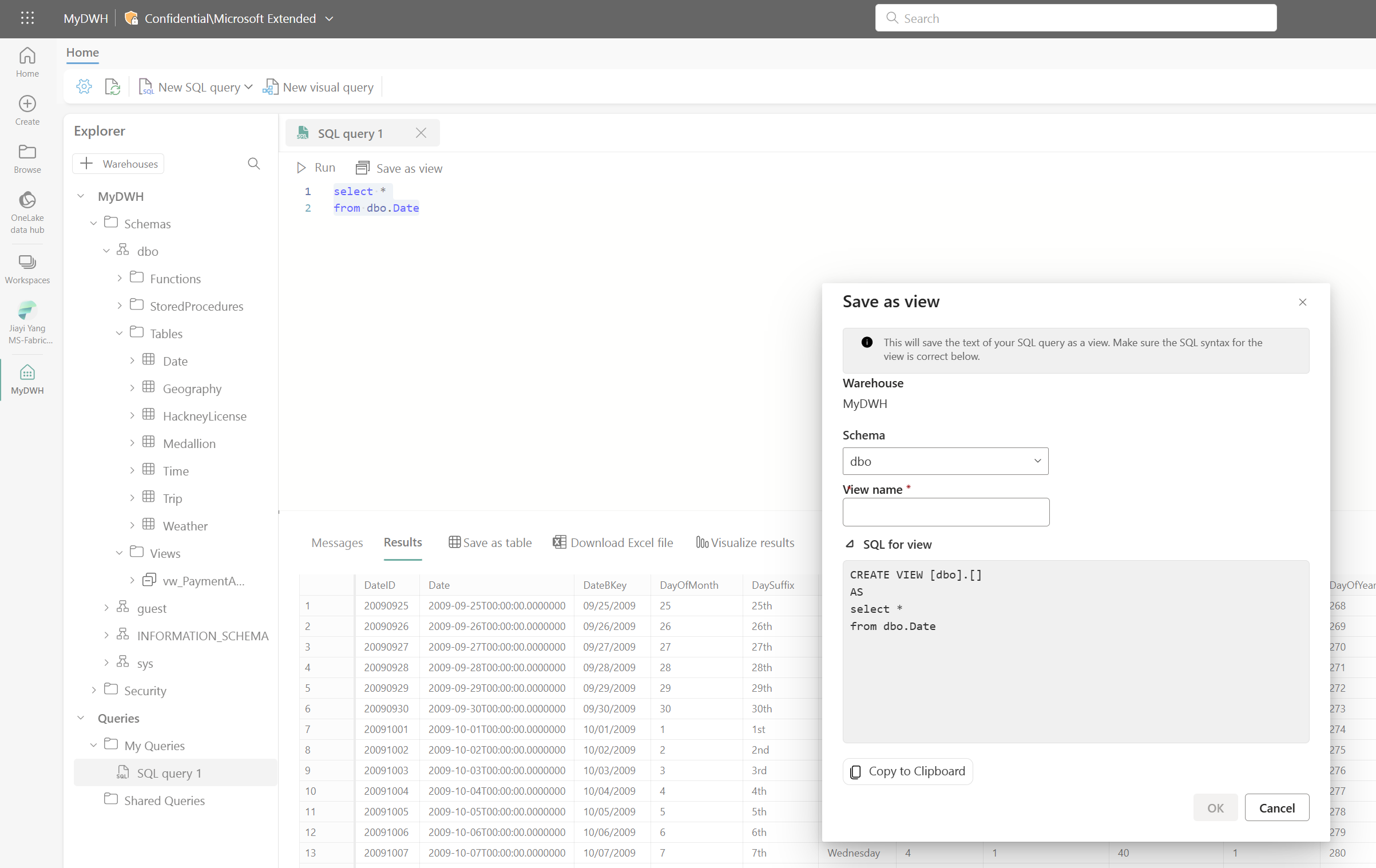
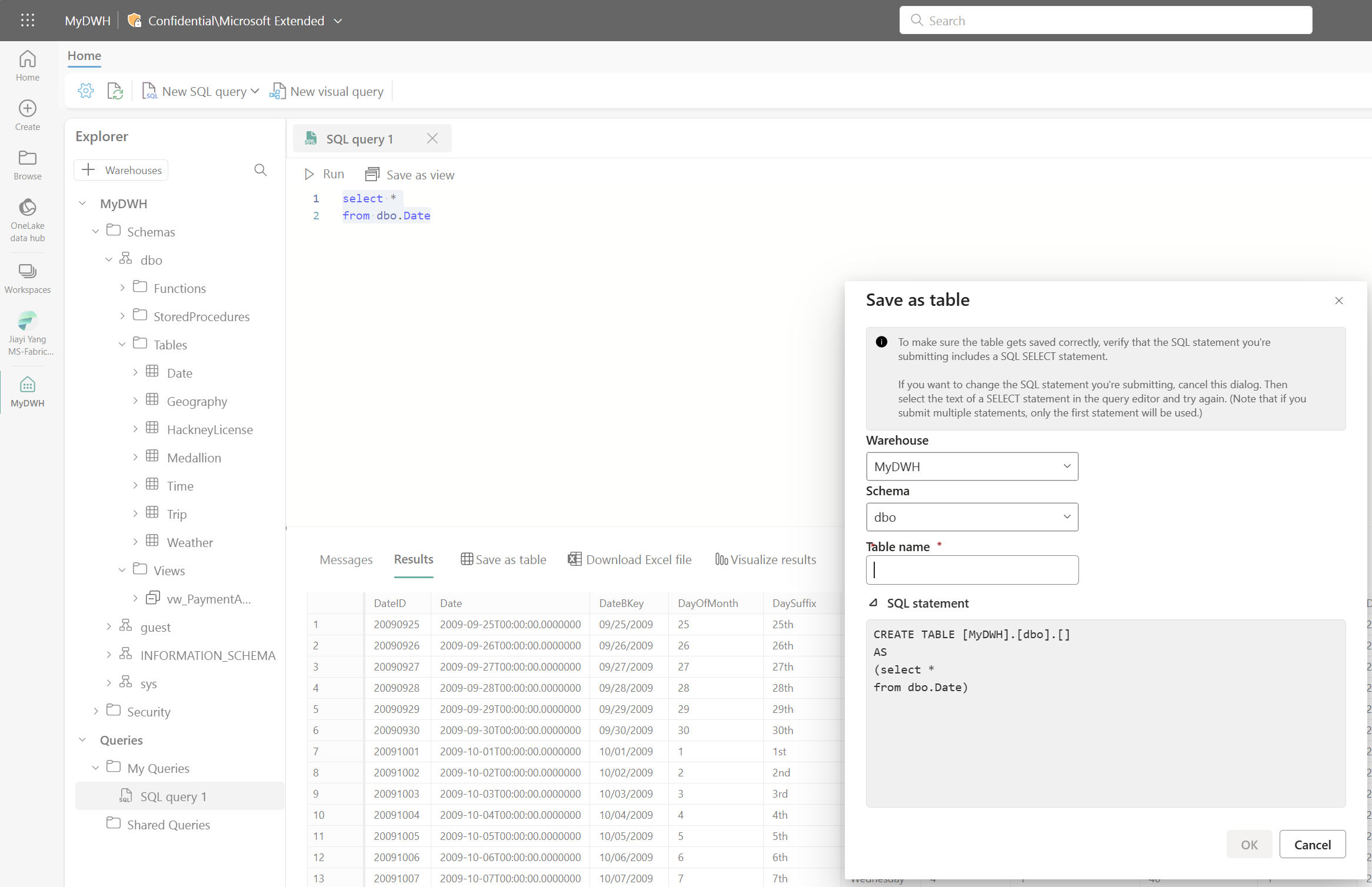
UI で選択したSQLクエリテキストから View また Table を作成できます。必要なスキーマを選択し、View や Table の名前を指定すれば完成です。
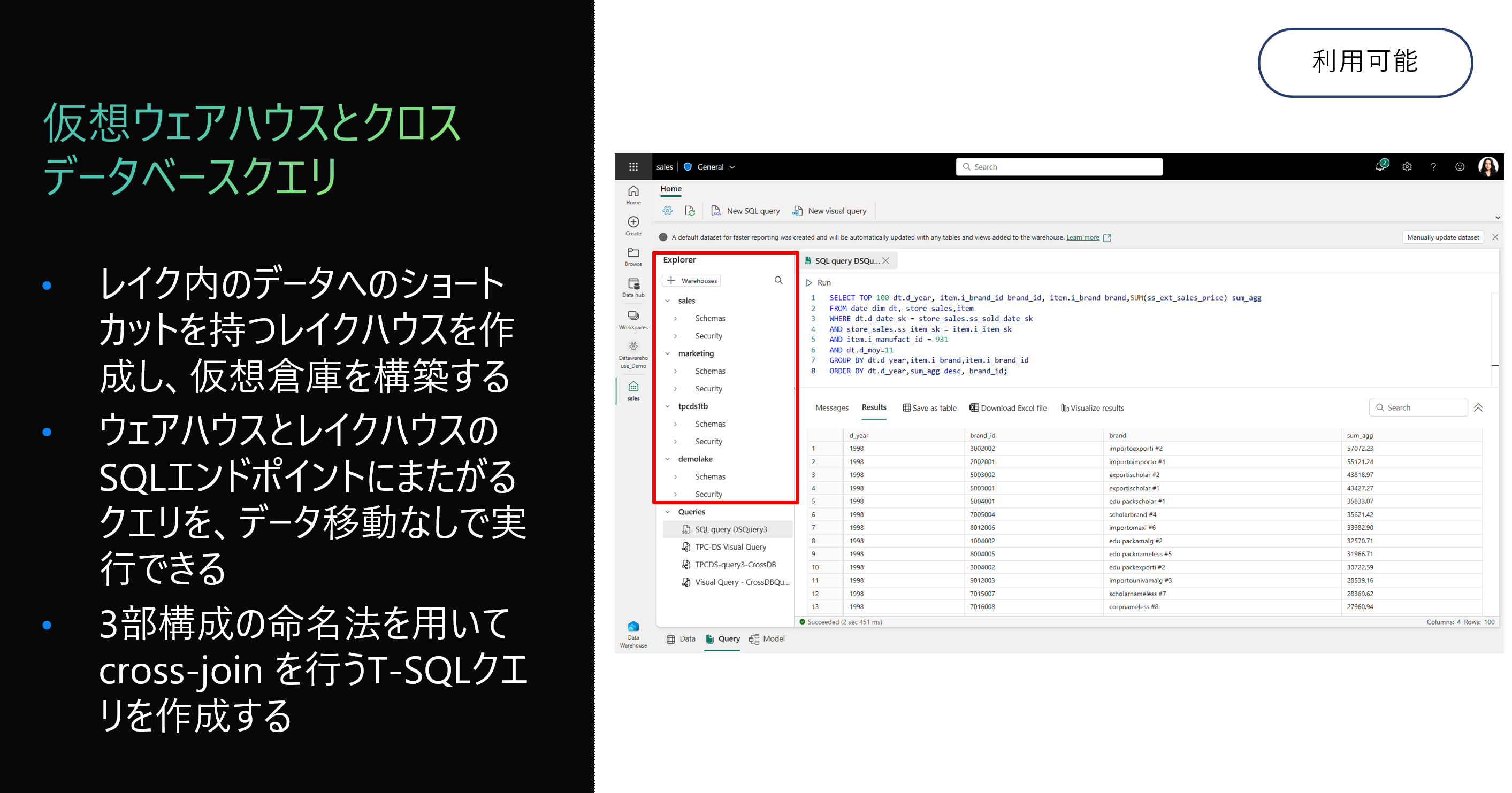
すべてのデータは OneLake 上で保管されているため、複数のウェアハウス、レイクハウスの間に、クロスクエリの実行が可能となっています。
Microsoft Fabric SQL Endpoint
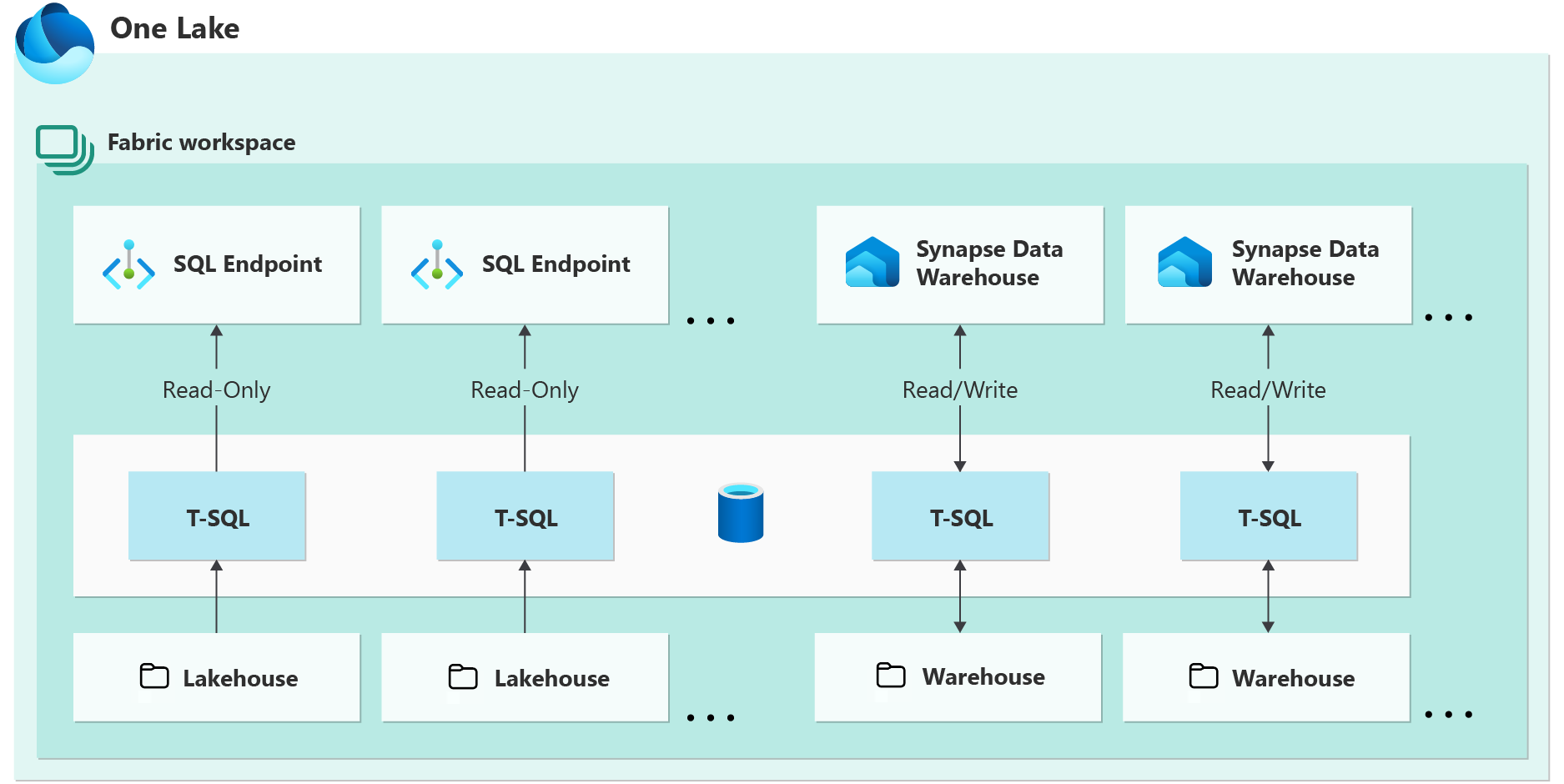
Microsoft Fabric では、Workspace 単位に、1つ SQL Endpoint が提供されています。ただし、レイクハウスか、または、ウェアハウスによにって、読取り専用や読み取り+書き込みのそれぞれの特徴があります。
- レイクハウス用の読取り専用のSQL Endpoint (レイクハウス作成時に自動的に作られます)
- ウェアハウス用の読取り/書込みのSQL Endpoint (ウェアハウス作成時に自動的に作られます)
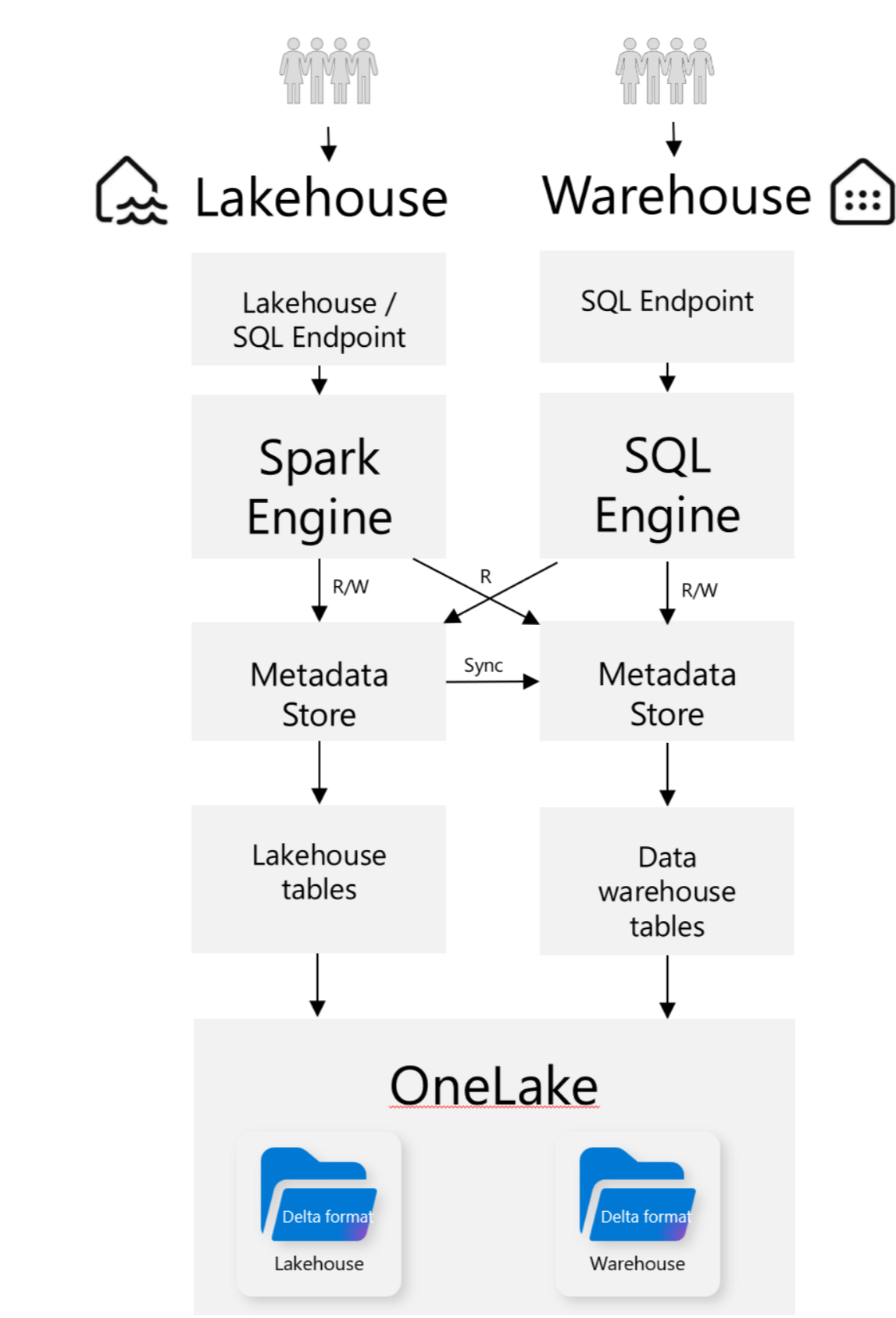
こちらは、レイクハウスとウェアハウスのそれぞれの特徴とできること、できないことのアクセスパスです。ご参考ください。
SQL Server Management Studio を慣れている方は、クライアントツールで、SQL Endpoint に接続することも可能です。Azure AD MFA認証です。
Microsoft Fabric Synapse Real-Time Analytics

リアルタイム分析を実現するには、容易ではありません。ここに書いた通りに、複雑性もあり、コストもかかるほか、さらに、ハイスキルが求めれています。
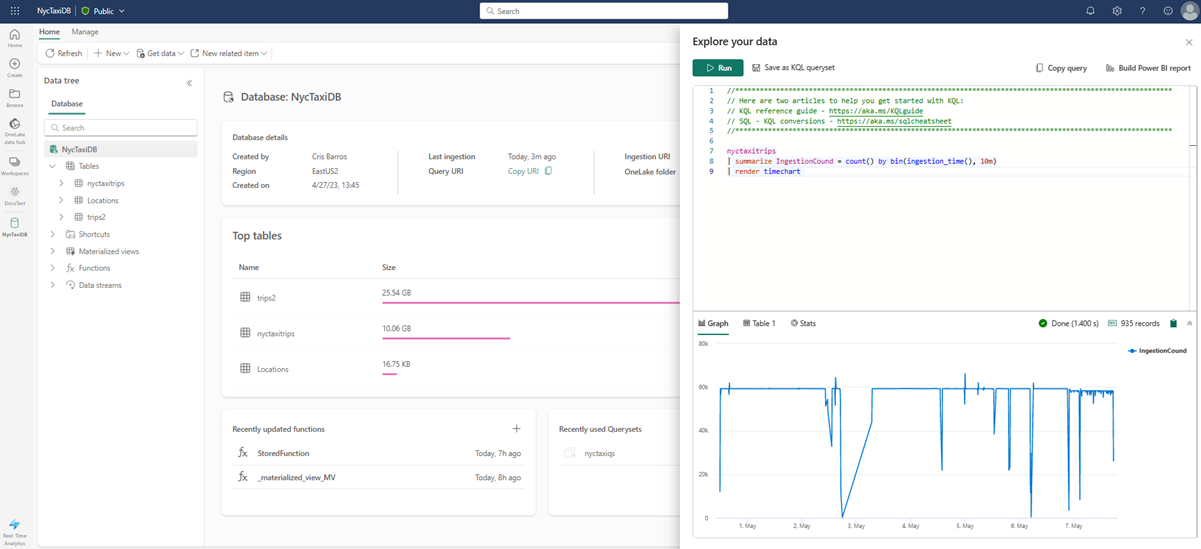
リアルタイム分析が必要な理由は、ビジネスの競争力を維持するために、迅速な意思決定が必要であるためです。リアルタイム分析は、ビジネスの現在の状況を把握し、問題を解決するために必要な情報を提供します。また、リアルタイム分析は、ビジネスの成長に必要な情報を提供することもできます。
Kusuto DBは、OneLakeにも同期され、Synapse Data Explore (SDX) や Azure Data Explore (ADX) の進化版です。
Microsoft Fabric リアルタイム分析は、ストリーミングおよび時系列データ用に最適化されたフルマネージドのビッグ データ分析プラットフォームです。構造化データ、半構造化データ、および非構造化データの検索に優れたパフォーマンスを備えたクエリ言語とエンジンを利用しています。そして、データの読み込み、データ変換、高度な視覚化の両方のシナリオで、Microsoft Fabric 製品のスイート全体と完全に統合されています。
Microsoft Fabric リアルタイム分析と SDXやADXは、同じコア機能を持つ同じコア エンジンを共有しますが、管理動作が異なります。
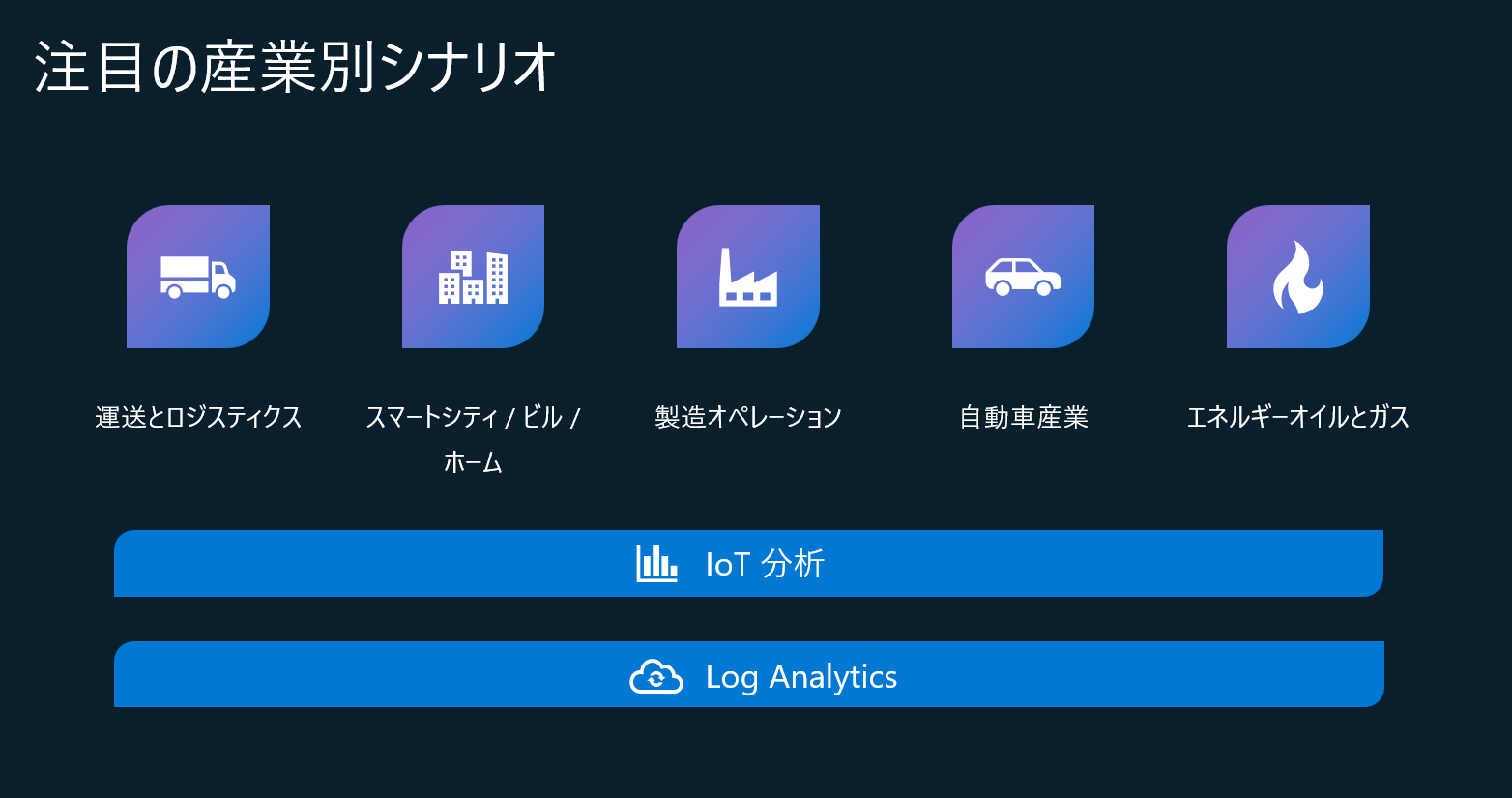
リアルタイム分析は、このような業界で幅広く使われています。
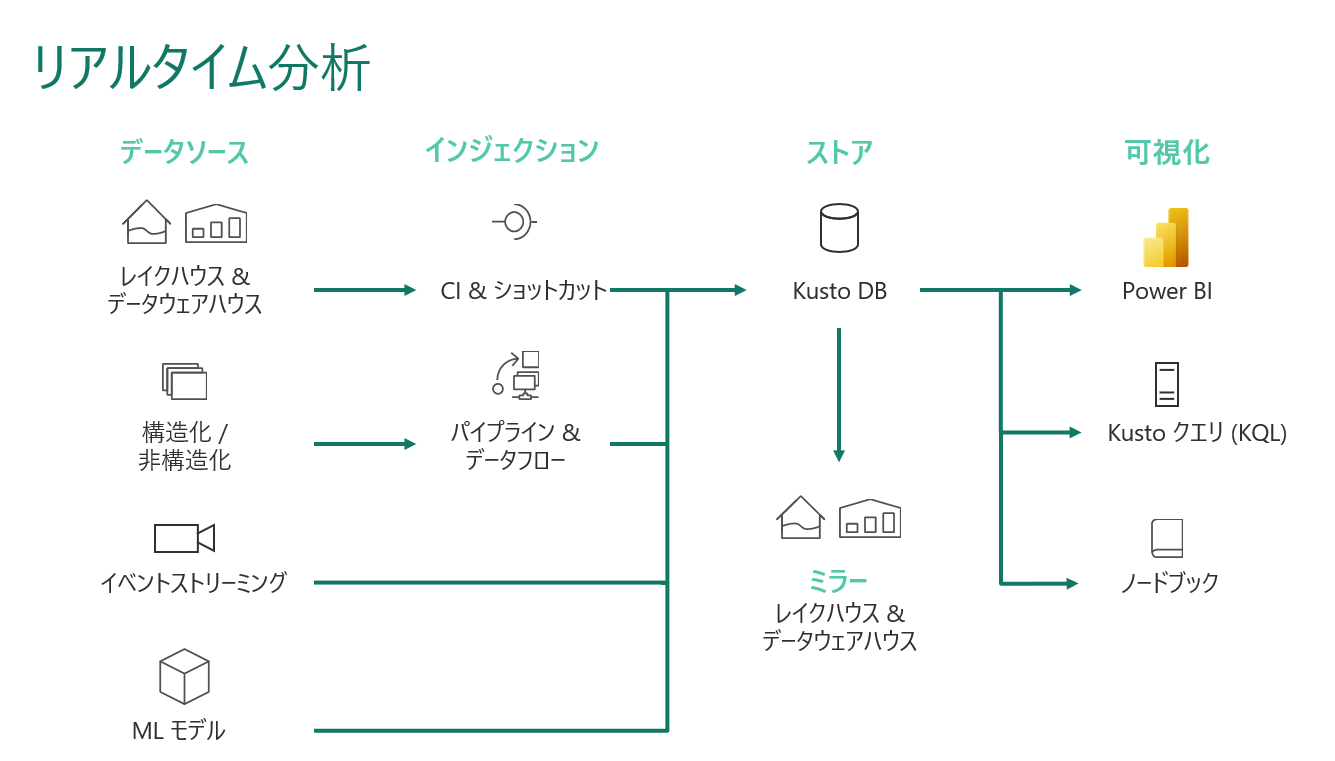
データサイエンス、レイクハウス、データウェアハウスの分析シナリオとは異なり、ストリーミングデータは、リアルタイム分析を実現するために、いくつかの方法でMicrosoft Fabricに取り込むことができます。
ユーザーは、Event Hub、IoT Hub、パイプライン、データフロー、ノートブック、またはKafka、Logstashなどのオープンソース製品を活用することができます。
Microsoft Fabricに取り込まれたストリーミングデータは、Kusto DBに格納され、Lakehouseにミラーリングすることができます。データを保存した後は、機械学習モデルをLakehouse上で直接実験しながら学習・テストすることができます。
他のシナリオと同様に、ビジネスユーザーはシースルーモードまたはSQLエンドポイントを使用してPower BIでデータを分析し、可視化することができます。また、Sparkを使用したKQLやノートブックを通じてデータを公開することも可能です。
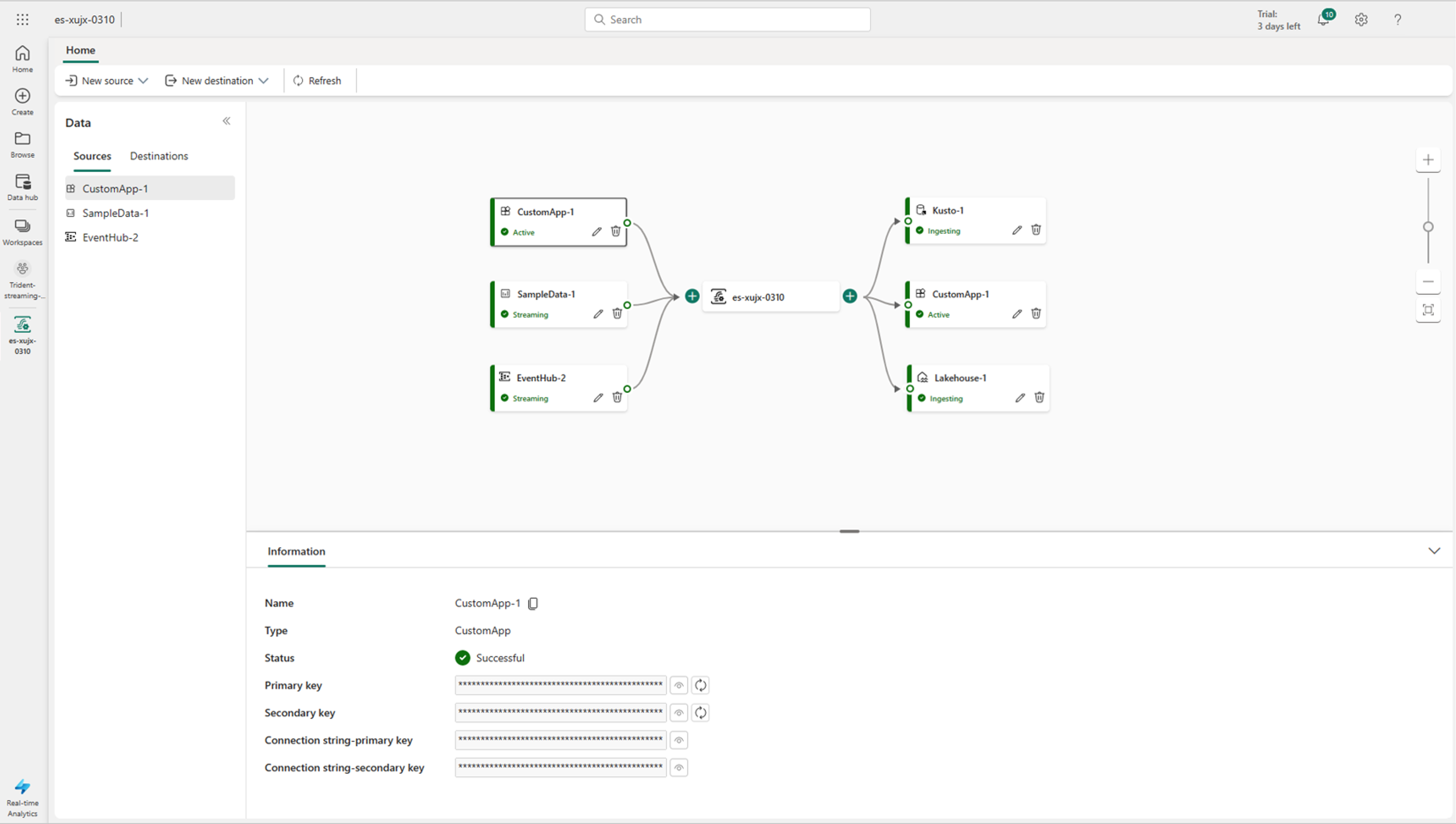
Microsoft Fabric のイベント ストリーム機能は、Fabric プラットフォーム内の一元化された場所であり、リアルタイム イベントをキャプチャ、変換、およびコードなしのエクスペリエンスでさまざまな宛先にルーティングします。これは、リアルタイム分析エクスペリエンスの一部です。ポータルで作成するイベントストリーム項目は、Fabricイベントストリーム(イベントストリームとも呼ばれます)のインスタンスです。変換が必要な場合は、イベント・データ・ソース、ルーティング宛先、およびイベント・プロセッサーをイベント・ストリームに追加します。
こちらはコードを書く必要はありません。No-Codeです。
Microsoft Fabric Data Activator

No-Code で、お客様のデータを監視、そして運用にトリガーさせる機能です。

Data Activator は、検出のシステムです。Data Activator を使えば、ビジネスの専門家が Microsoft Cloud にあるすべてのデータを監視することができます。Microsoft Fabric の使い慣れた簡単な操作で、データをモデリングし、データの変化する条件を定義し、洞察を得ることができます。そして、インサイトに対応するリアルタイムのトリガーを設定します。Data Activator は通知を送信し、ワークフローを起動し、さらには業務システムに直接到達して、ビジネスの実行方法を最適化します。
Microsoft Fabric Power BI
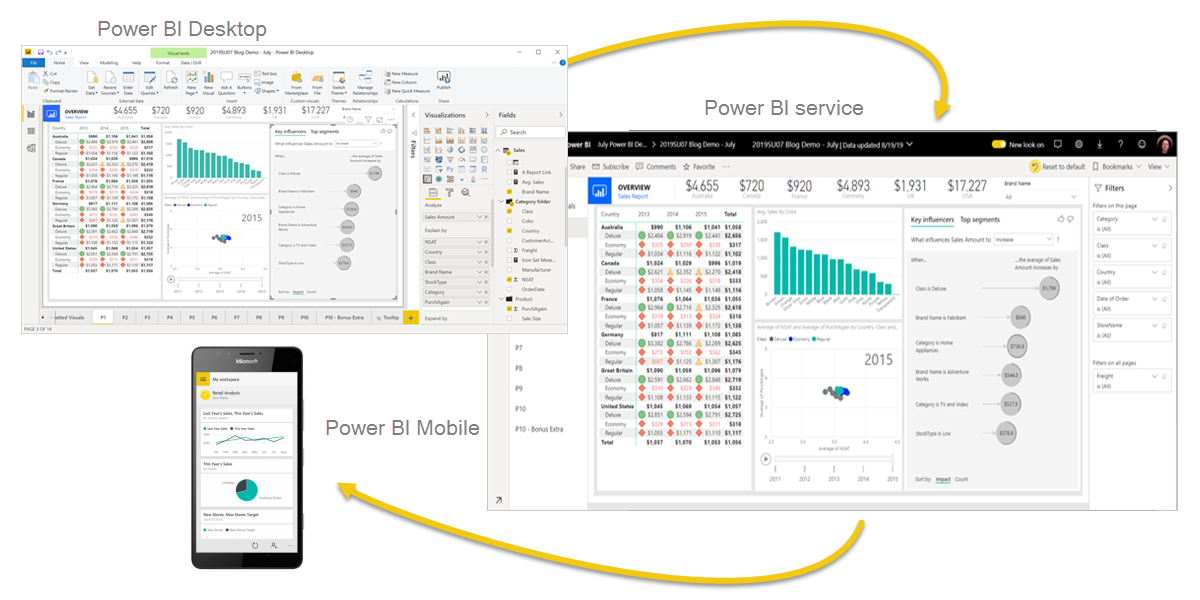
Power BI はソフトウェアサービス、アプリ、コネクタの集合体で、それらが協力して非関連のデータソースを一貫性のある視覚的で対話的な分析情報に変換します。データソースはExcelスプレッドシートや、クラウドベース及びオンプレミスのハイブリッドデータウェアハウスなど様々です。Power BIを用いると、データソースへの接続、重要な情報の視覚化と発見、そしてそれらの共有が容易になります。
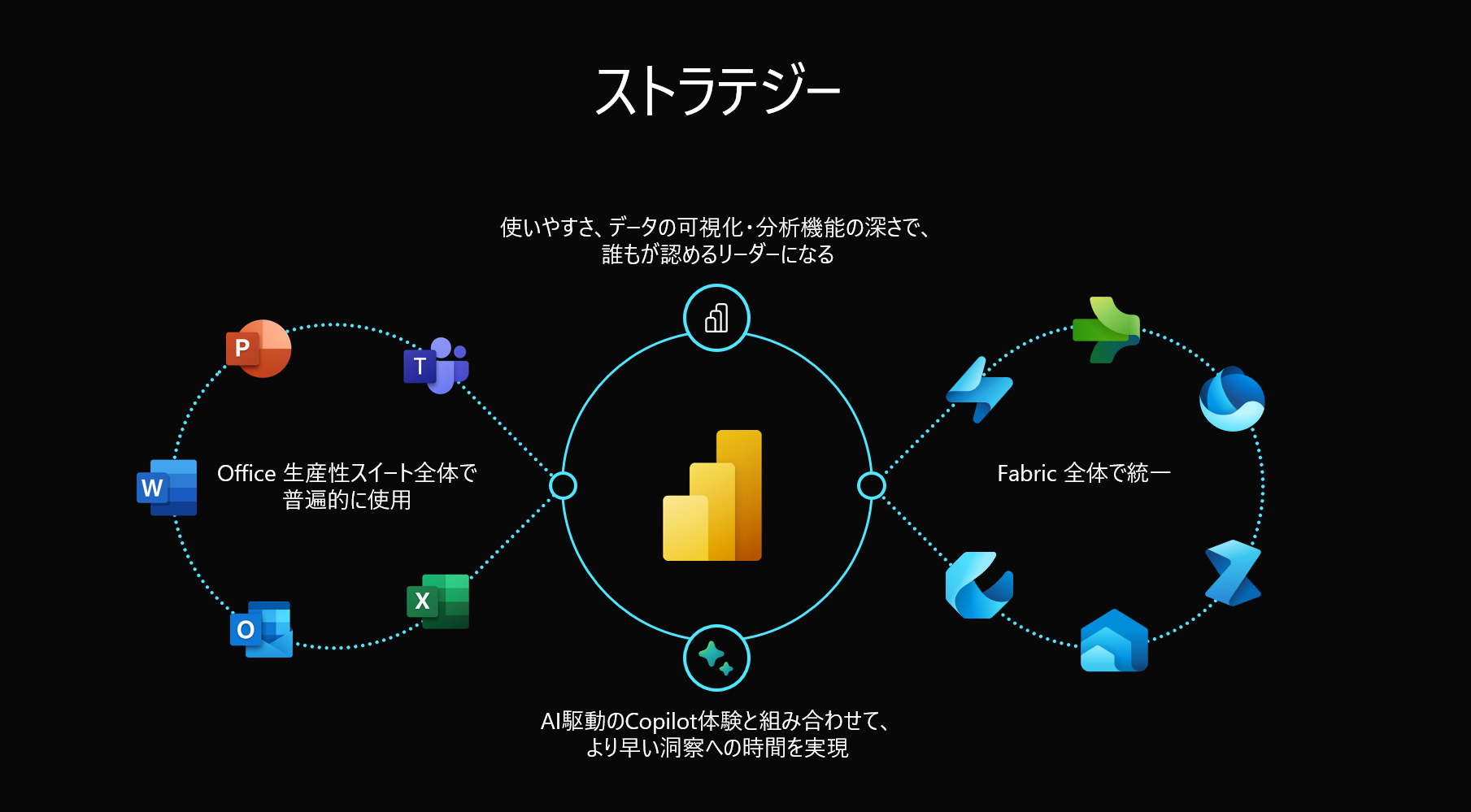
Power BIはSaaSでもあり、そのPower BIを拡張していくように、Power BIをHub (中心) にしている Office 製品と Data 製品の融合の上、さらにAI Copilotと統合することで、All in One の組織のデータ分析基盤を築くことができ、すべての分析プロセスは、Power BIを軸にしています。つまり、Power BI Serviceを拡張し、Power BI Premium Capacity P1以上の Power BI Service はMicrosoft Fabric になることです。(P1 = F64)
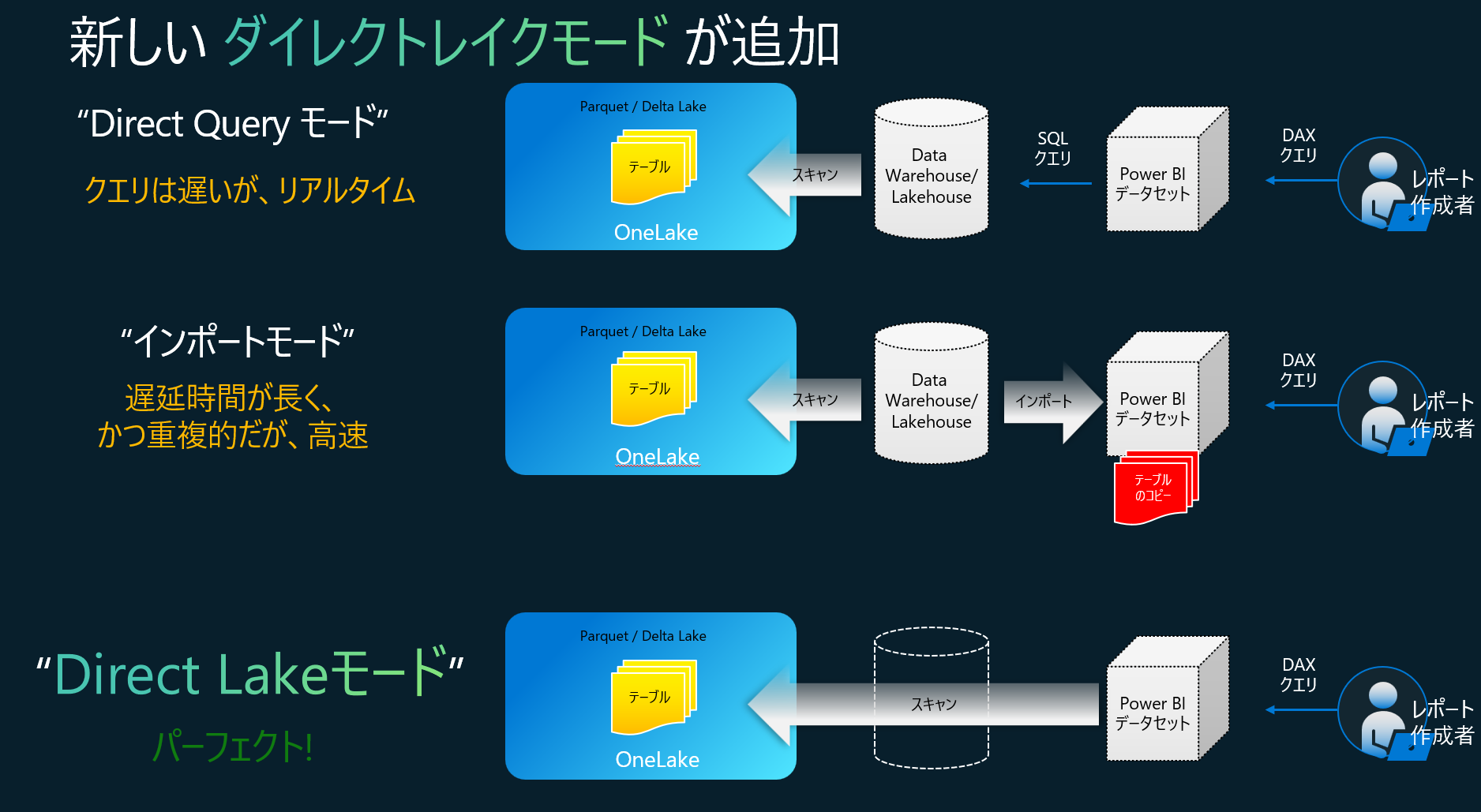
従来の二つ接続モードのほかに、DirectLakeモードを追加されます。現時点では、Power BI Desktopでは使えないものの、Fabric Power BIでは利用可能です。
これは、データウェアハウスまたはレイクハウスのエンドポイントに対してクエリを実行したり、Power BI データセットにデータをインポートまたは複製したりすることなく、Parquet 形式のファイルをデータ レイクから直接読み込むということです。 DirectLake モードは、レイクから Power BI エンジンに直接データを読み込み、分析の準備ができている高速パスです。したがって、非常に大きなデータセットや、ソースで頻繁に更新されるデータセットを分析するのに理想的な選択肢です。
そして、Parquet ファイルでは、優れたパフォーマンスを得るために、Analytics Services が適切に処理するVORDER圧縮を使用します。VORDER は、Power BI エンジンのネイティブ圧縮アルゴリズムを使用してデータを圧縮します。このようにして、エンジンはできるだけ早くデータをメモリに読み込むことができます。
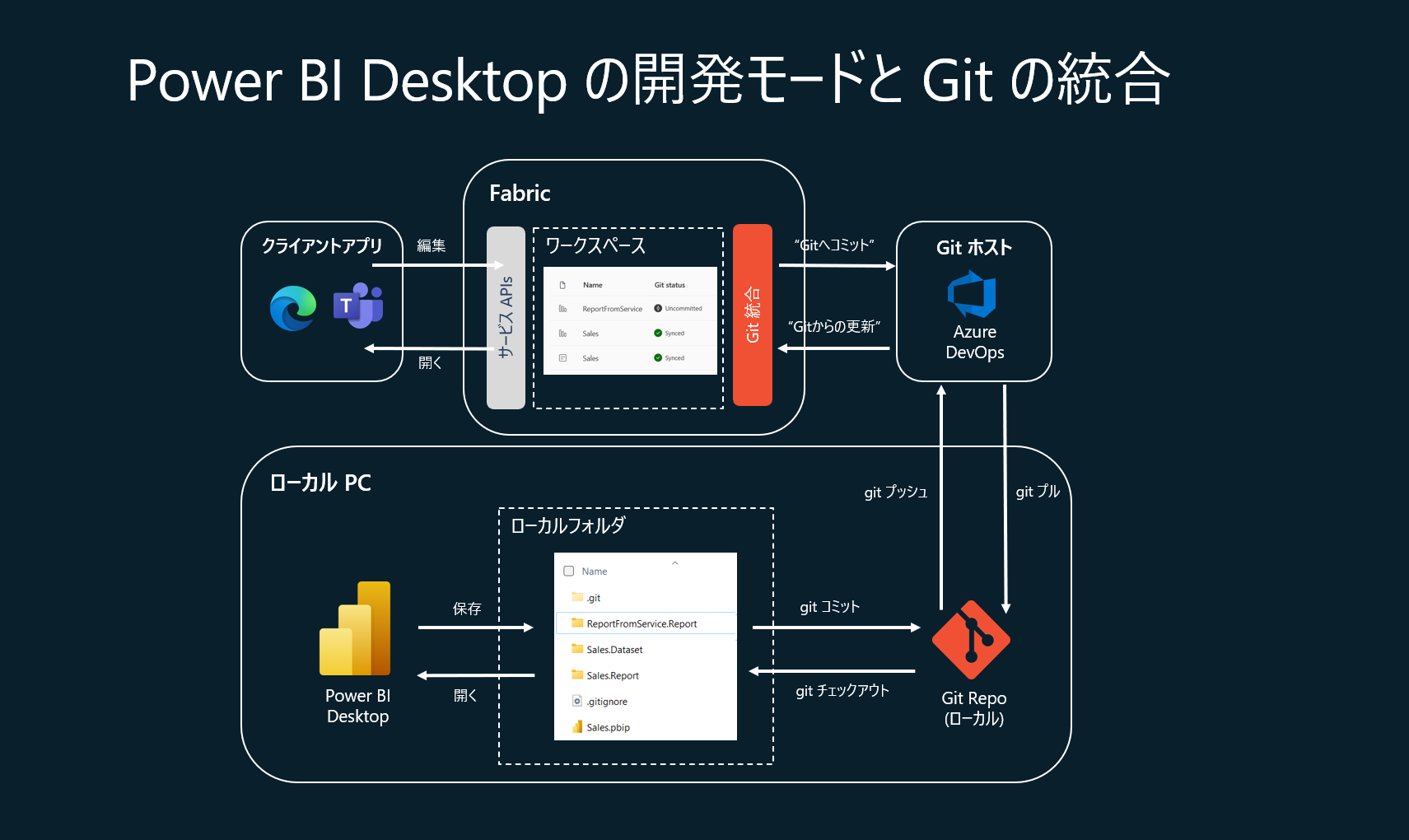
Power BI Desktopで Power BI Projectとして、「.pbip」拡張子で、保存してから、VS Codeで、フォルダを開きます。その後、Git 初期化を行い、Git リポジトリをクローンして Power BI Desktop で開くと、ソース管理できるようになります。
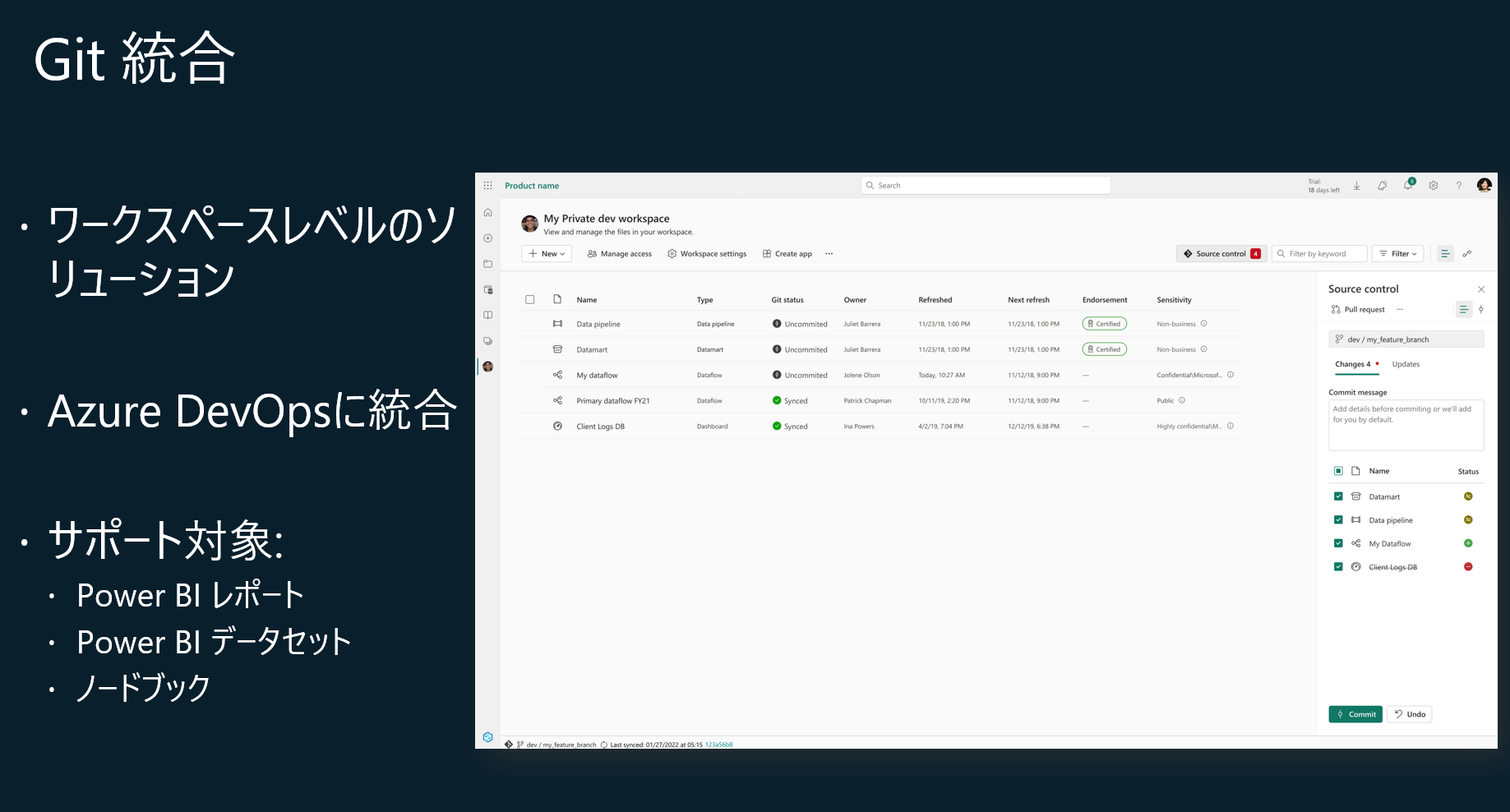
現時点のソース管理のサポートの対象は、Power BI レポート、Power BI データセット、ノードブックとなります。
Microsoft Fabric ライセンス

Microsoft Fabric の課金については、共有コンピューティング容量 + ストレージ容量の計算となります。

Microsoft Fabric Capacityは、Microsoft Fabricのすべての機能を支える共有計算リソースで、一つの容量が通常、複数のプロジェクトを同時にサポートします。

Fabricの容量を購入すると、容量単位 (CU) という一組の単位が得られます。容量単位 (CU) は、必要な計算能力のプールを表す単位です。計算能力はクエリの実行、ジョブ、またはタスクを行うために必要です。
CUの消費は、処理時間中に実行されるタスクに必要な基礎となる計算作業と高度に相関しています。各機能とそれに関連するクエリ、ジョブ、またはタスクはそれぞれ一意の消費率を持っています。

Power BI Premiumの容量のユーザーは、同じ月額料金を支払い、Fabricの一部として新しい分析ワークロードすべてにアクセスできるようになります。
これらすべての機能を支えるコンピューティングユニットは、Power BI vCoreからCapacity Unit (CU)に変わります。1 PBI vcoreは8 CUに等しく、そのため8 vCoresを持つP1 SKUは64 CUを持つF64 vCoreに変換され、Fabric以前と同様の容量をすべてのPBIワークロードが消費します。
また、Power BIアーティファクトの100TBのストレージを維持します。新しいFabricアーティファクトについては、ユーザーは新しいワークロードのためにOneLakeストレージをプロビジョニングする必要があります。

CUsのほかに、OneLakeのストレージ容量の課金となります。
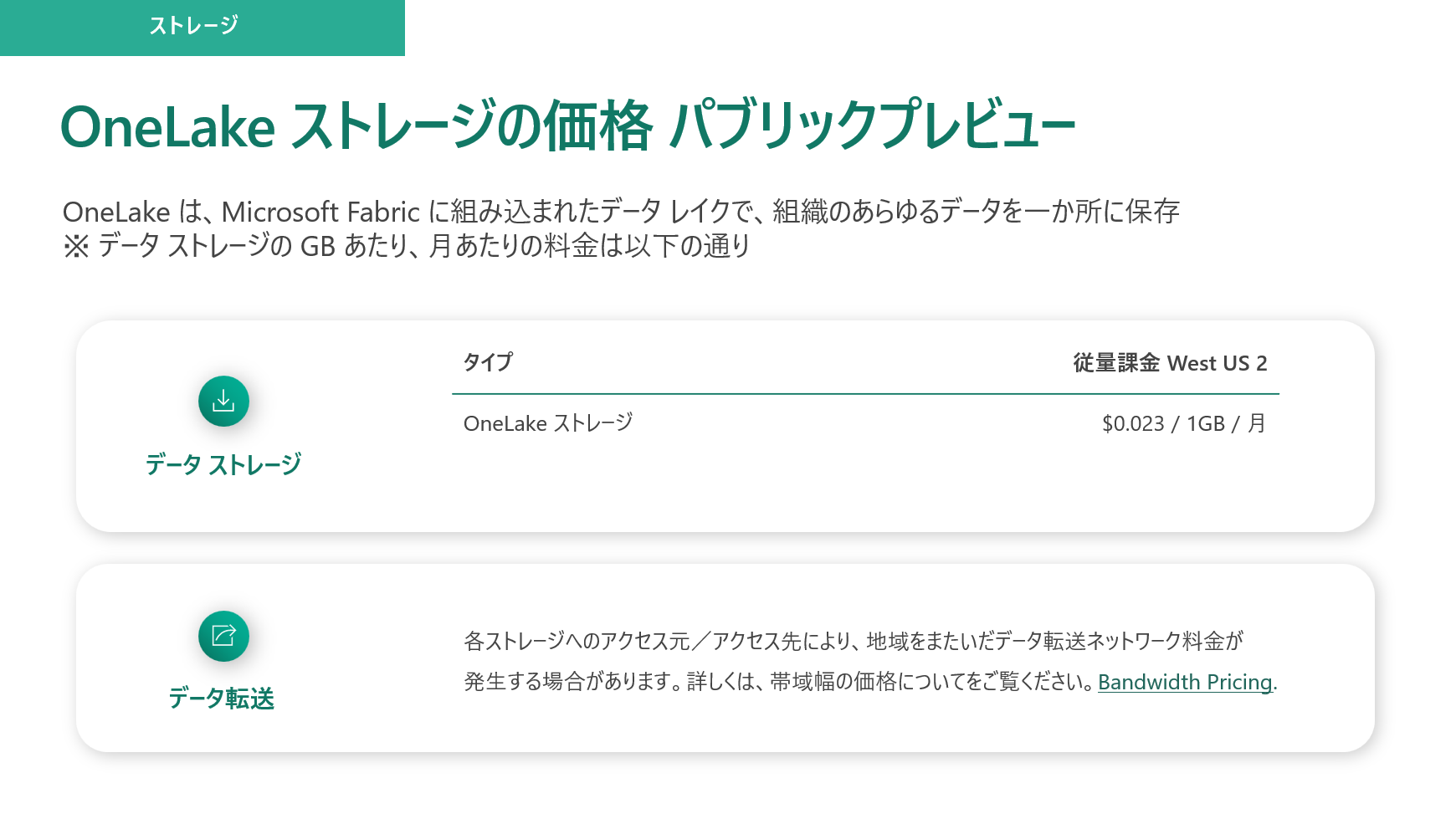
OneLake は Microsoft Fabric に組み込まれたデータレイクで、組織の全データを一箇所に保存するための場所を提供します。データの保存は、毎月GBあたりで請求されます。
地域やクラウド間のデータ転送については、既存のAzure Bandwidthの価格設定により請求されます。
ライセンスや課金、購入プランの詳細については、Fabric Licensingにアクセスし、ご確認ください。
または、Buy a Microsoft Fabric subscriptionにて、詳細情報をご確認ください。
Microsoft Fabric にアクセスするには、3つパスがあります。
- 既存の Power BI Premium サブスクリプションを活用するには、Fabric Preview スイッチをオンにします。すべての Power BI Premium 容量は、追加の操作を必要とせずに、すべてのファブリック ワークロードを即座に強化できます。
- テナントが試用版をサポートしている場合は、Fabric 試用版を開始します。Fabric の試用版を有効にする方法と、Fabric の試用版を開始する方法を確認します。
- Azure portal から Fabric の従量課金制容量を購入できます。
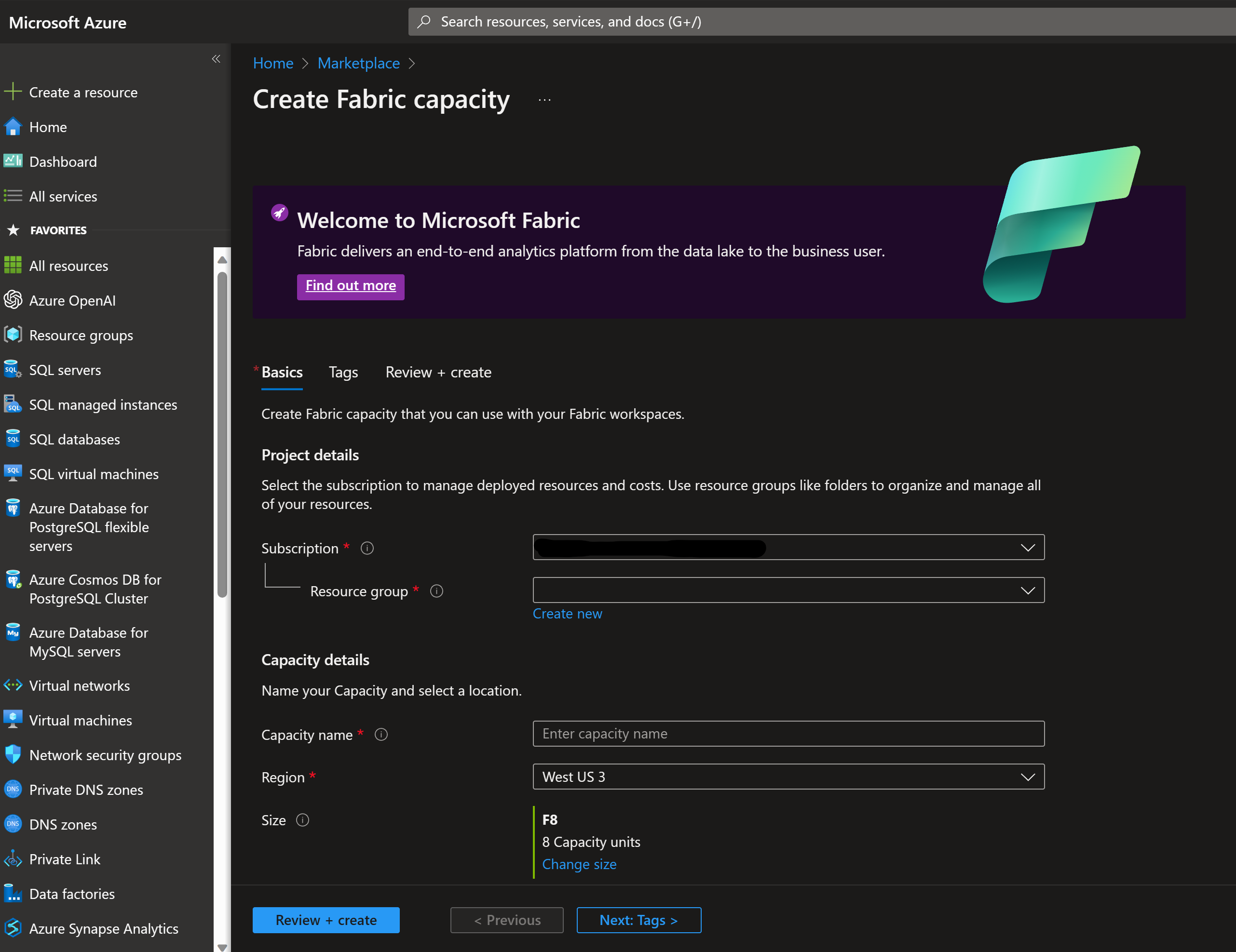
Azure から従量課金 (PAYG) の場合、停止再開がサポートされています。
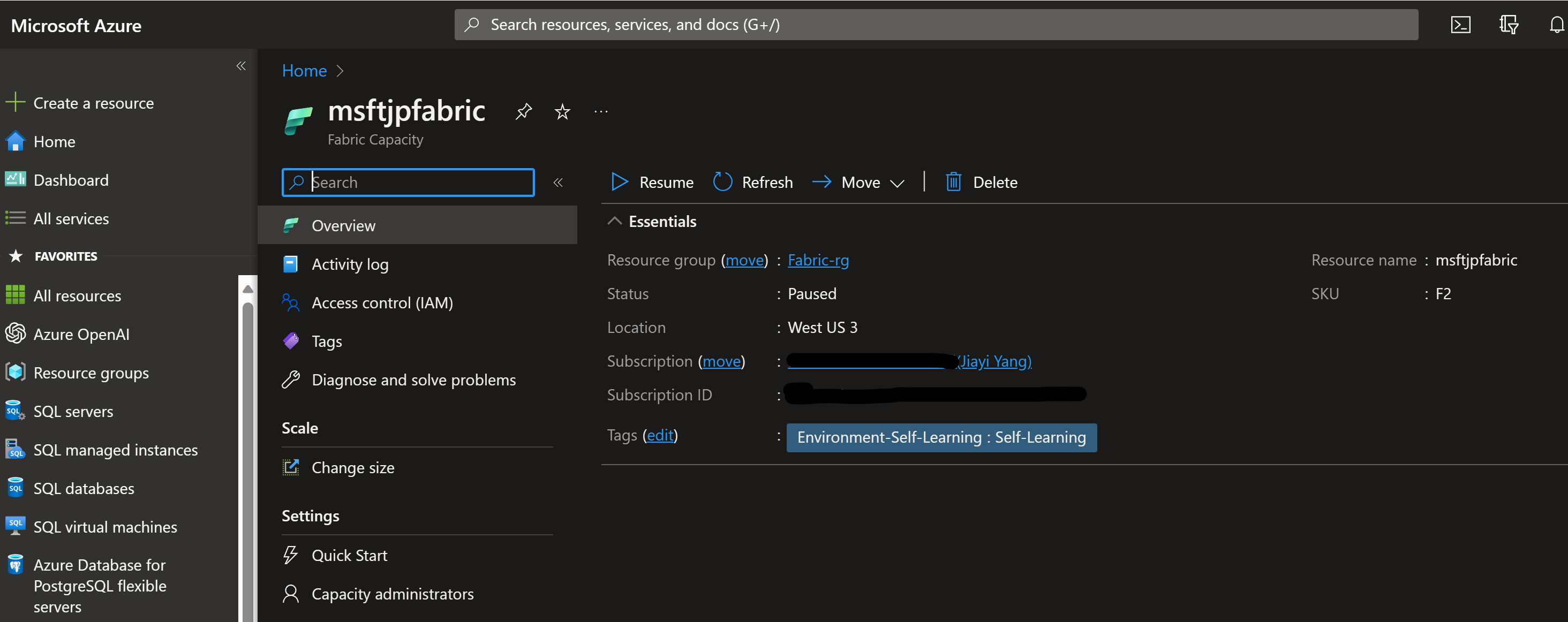
前にも書いた通りに、(Fabric CU課金 + OneLake 課金) = トータル料金になりますが、Fabric CU を停止しても、OneLake は ADLS Gen2 と同じく課金されます。参考価格としては、OneLake の米国西部 2 の価格は、GB あたり月額 $0.023 です。
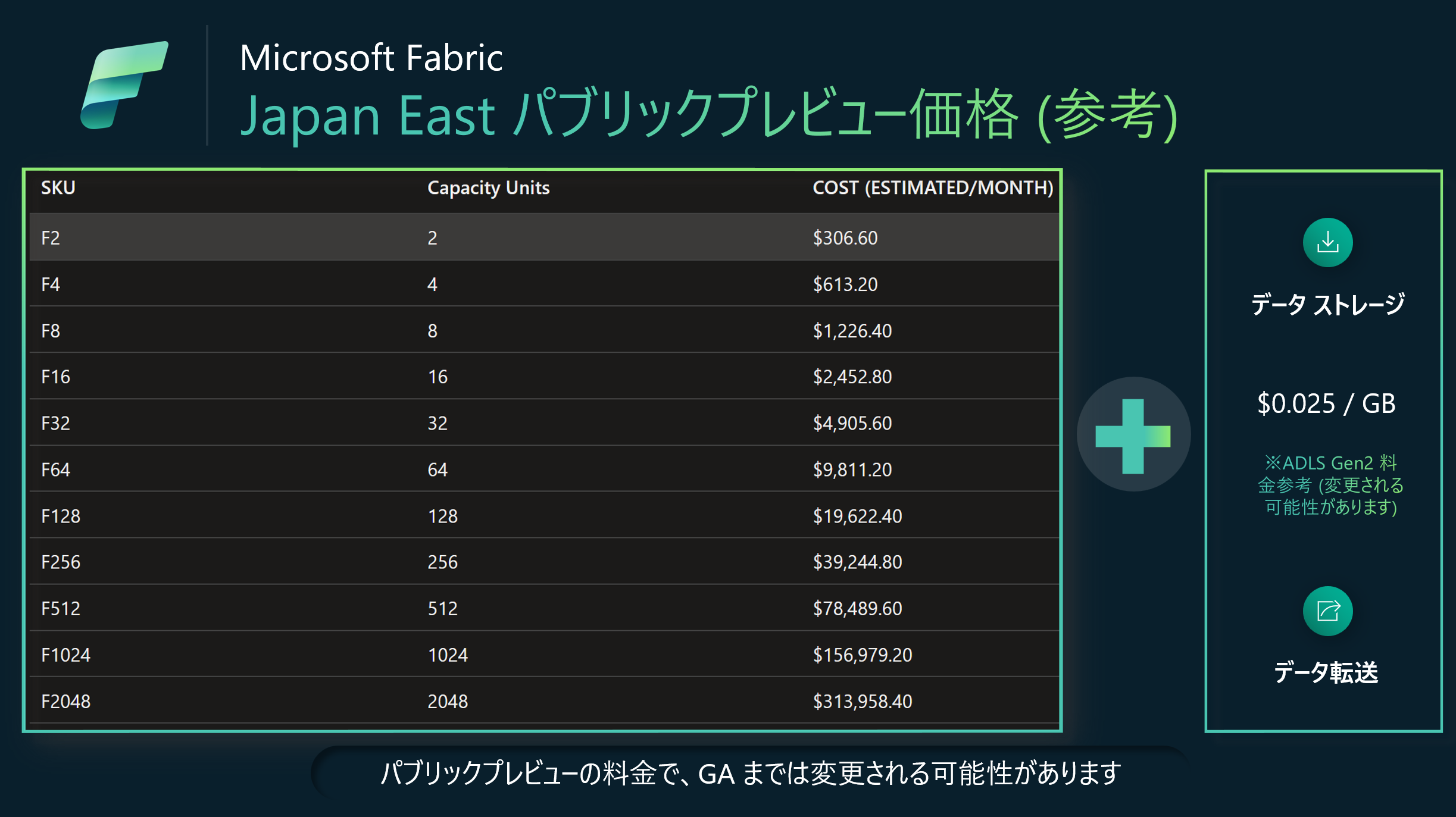
参考として、Japan East のパブリックプレビューの料金です。GA までは変更される可能性はあります。
Announcing Microsoft Fabric capacities are available for purchase
https://blog.fabric.microsoft.com/en-us/blog/announcing-microsoft-fabric-capacities-are-available-for-purchase?ft=All
Microsoft Fabric Capacity Metrics
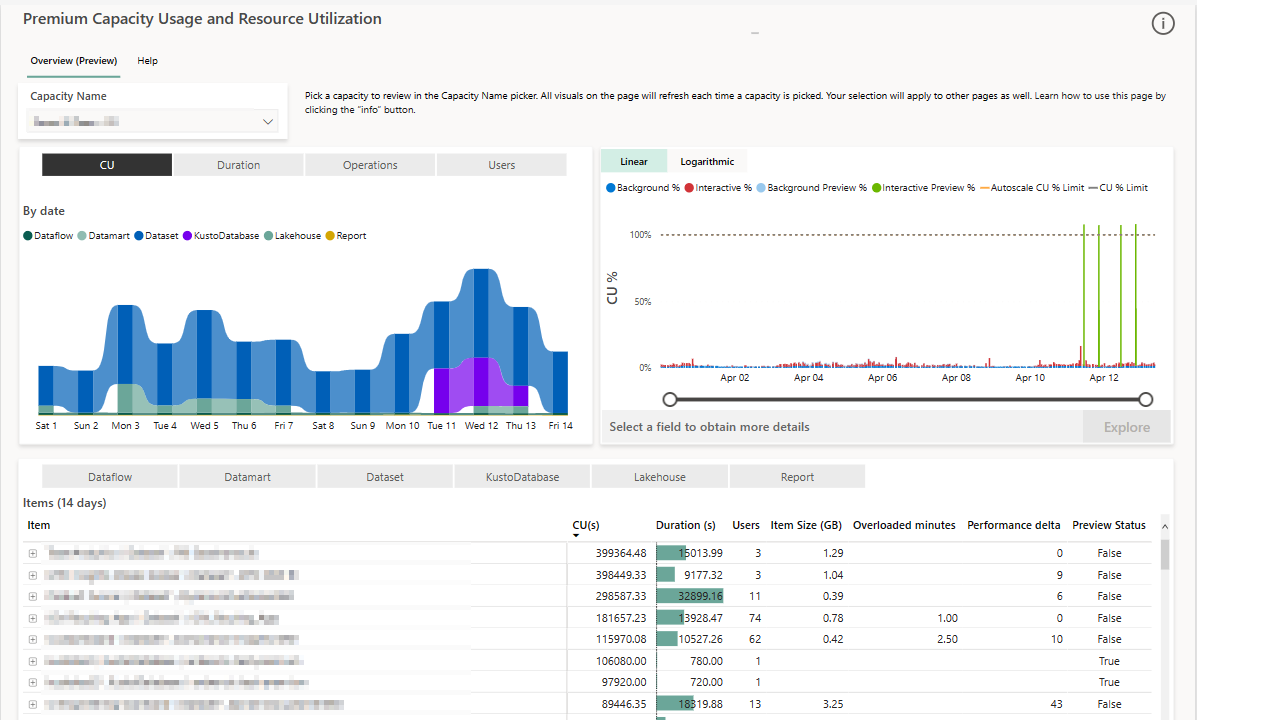
Microsoft Fabric Capacity Metrics を使って、容量リソースを可視化できます。 管理者は、セマンティック モデル、レイクハウス、倉庫、ページ分割されたレポート、データフロー、および Fabric 容量が有効なワークスペース内のその他の項目など、Fabric アイテムによって使用されている CPU 使用率、処理時間、メモリの量を確認できます。過負荷の原因、ピーク需要時間、リソース消費などを可視化し、最も要求の厳しいアイテムや最も人気のあるアイテムを簡単に特定できます。
Microsoft Fabric Capacity Metrics Download
https://appsource.microsoft.com/en-us/product/power-bi/pbi_pcmm.microsoftpremiumfabricpreviewreport?exp=ubp8
Qiita Blog Microsoft Fabric Capacity Metrics アプリの設定方法
https://qiita.com/ryoma-nagata/items/22c3d330bfffe85f0f80
よくある FAQ について
Microsoft Fabric とは何ですか、そしてなぜ気にする必要があるのですか ?
いい質問ですね。Microsoft Fabric は、アナリティクスエステートを構築するために必要なほとんどすべてのものを SaaS で提供する、まさにこの種の最初の製品です。重要な違いは、組織内の誰もが必要とするものが文字通り一つの場所 - OneLake にあるということです。アナリティクスのあらゆるニーズに対応する Microsoft Office のようなものだと考えてください。Microsoft Fabric は、Microsoft 365 のような データ向けのスイートパッケージソリューションです。
レイクハウスかウェアハウスか、何を選ぶか ?
これは簡単です。Microsoft Fabric はレイクセントリックです。つまり、構造化データと非構造化データをすべて 1カ所に収容するレイクハウスを最初に作成することは、非常に理にかなっています。これは、大量のデータを扱うための柔軟でスケーラブルな方法であるため、そうする必要があります。ローカル PC から小さなファイルをアップロードしたり、Microsoft Fabric Data Factory を活用してデータをレイクハウスやウェアハウスに高速に取り込むなど、レイクハウスにデータを取り込むための仕組みは非常に豊富です。
次の考えのポイントとしては、自分は Spark 派なのか、SQL 派なのか、両方なのか、それとも「どれでもない」のか、ということです。Spark /SQL / ローコードやノーコードのいずれを選択するにしても、Microsoft はあなたのために何かを用意しています。Spark での開発が好きなら、数秒でノードブックを立ち上げることができます。SQL が好きなら、ウェアハウスがあなたのホームグラウンドになるでしょう。レイクハウスを作成すると、SQL のエンドポイントが自動的に作成され、指一本触れず (SQL Visual Query エディター)にすぐにクエリを実行できます。また、レイクハウスを作成すると、Power BI データセットがデフォルトで作成されるのも嬉しいポイントです。ボタンをクリックするだけで、数秒以内に PowerBI のレポートが自動生成されます。これは、Power BI よりも SSMS に多くの時間を費やしてきた開発者にとって、特にエキサイティングなことです。
もし、小規模なデータマートを必要とするローコードビジネスユーザーであれば、Datamart でも十分かもしれませんね。
レイクハウスは Spark で管理され、Spark エンジンのみで更新可能ですが、SQL で読むことは可能です。一方、ウェアハウスは SQ Lで管理されます。つまり、SQL エンジンでしか更新できませんが、Spark で読むことは可能です。つまり、レイクハウスの読み書きは Spark を使うため、ノードブックを使います。ウェアハウスの読み書きは SQL を使うため、SQL エディターなどを使います。
レイクハウスとウェアハウス (あるいはデータマート) のどちらで時間を使うべきか、もっと詳しく知りたい方は、こちらをご覧ください。
Microsoft Fabricは、大規模なデータソリューションのストレージ、管理、分析を統合するために設計されたクラウドベースのプラットフォームです。
Microsoft Fabricでは、LakehouseとWarehouseの2つのデータアーティファクトを使用できます。どちらのアーティファクトも、大量のデータを処理および処理する能力を提供し、ペタバイトの領域にまで及びます。両方ともオープンフォーマットのDelta Lakeを採用しており、ベンダーロックインの制約なしに、さまざまなツールやアプリケーション間で自由にデータにアクセスできます。さらに、LakehouseとWarehouseの両方で、Fabricワークスペース内の分析のための標準化された言語であるT-SQLのパワーを活用することができます。これにより、データを効率的に照会および分析し、優れたパフォーマンスとスケーラビリティを提供します。データセットが同等であれば、これらの両方のアーティファクトの分析パフォーマンスは一貫しています。これは、クエリを処理するために同じSQLデータ分析エンジンを利用するためです。さらに、どちらのアーティファクトも、データパイプライン/データフローなどの使いやすいローコードツールを活用して、データをコピーして変換することができます。
それにもかかわらず、データソリューションで1つにコミットする前に、LakehouseとWarehouseの区別を認識することが不可欠です。
Lakehouseは、CSV、Parquet、JSON、Deltaなどの多数の形式で、構造化および半構造化から非構造化まで、さまざまなデータタイプを収容できる汎用性の高いリポジトリとして機能します。この柔軟性は、データ管理と更新のために、PySparkやScalaなどのプログラミング言語にも拡張されます。
対照的に、Warehouseは、特にDelta形式で、構造化データの保存と処理に合わせたデータアーティファクトです。SQLオブジェクト(テーブル、ビュー、ストアドプロシージャ、および関数)を介してT-SQL言語を使用してデータを管理および更新するように設計されています。
データソリューションのLakehouseとWarehouseの選択は、いくつかの重要な要素によって異なります。
①データ管理の言語設定 - LakehouseとWarehouseの選択は、チームの優先プログラミング言語によって異なります。あなたのチームがデータ管理のためにPySparkやScalaに傾いているなら、Lakehouseは自然な選択です。一方、WarehouseはT-SQLを好む人に対応しています。この区別は、ビジュアル、ローコード、または市民開発者にとってはあまり関連性が低いかもしれません。ただし、異なる言語に関連する機能を考慮することが重要です。たとえば、ML/正規表現が必要な場合は、これらの機能がPython/Scalaで利用できるため、Lakehouseが最適です。一方、データベース内のすべてのオブジェクトにきめ細かな権限が必要な場合は、T-SQLでGRANT/DENYコマンドを活用できます。
②データ形式の要件 - データが主にリレーショナル構造のDelta形式で存在する場合、Warehouseはニーズをシームレスに処理します。ただし、CSV、Parquet、JSONなどの多様なフォーマットで作業する場合、または非構造化データを使用している場合、Lakehouseはより汎用性の高いソリューションであることが証明されています。
移行シナリオ - 既存のデータソリューションがSQL Server、Azure SQL、Synapseウェアハウス、またはその他のRDBMSシステムに実装されている場合、またはFabricへの移行中に保持したい重要なSQLコードベースが含まれている場合は、Warehouseが好ましいオプションです。メダリオンのようなアーキテクチャから移行し、すでにノートブックに重要なデータ処理ロジックを実装している場合、LakehouseはFabricエコシステム内の移行へのより簡単なパスを提供します。
要約すると、LakehouseとWarehouseの主な違いは、プロコード開発者がデータ管理のために選択した言語にあります。チームがScala/Pythonに傾いている場合はLakehouseを選択し、T-SQLが好みの場合はWarehouseを選択してください。分析言語であるT-SQLは、両方のアーティファクトで一貫性を保ち、分析パフォーマンスのパリティを確保します。
データ管理に特定の言語の好みがない場合は、Lakehouseはデータ形式と構造の面でより大きな柔軟性を提供します。それにもかかわらず、レイクのアーキテクチャにおけるデルタ形式への継続的なシフトを認識し、既存の形式の使用を減らし、重要な違いとしてこれをゆっくりと取り除くことが不可欠です。既存のソリューションをFabricに移行する場合、WarehouseとLakehouseの選択は、あなたが来ているアーキテクチャによって異なります。
データソリューションのアーキテクチャを定義する場合は、LakehouseとWarehouseを可能な限り同じアーティファクトとして扱い、アーティファクトタイプの選択を延期し、開発チームがコーディングの好みに基づいてこの決定を下すことをお勧めします。アーキテクチャ的には、パフォーマンス、スケーラビリティ、コスト、またはデータ量の面で、これら2つのアーティファクトの間に重要な違いが見えない可能性があるため、いくつかの設計上の制約とチームの好みに基づいて選択が行われる可能性があります。
これらのガイドラインが、Microsoft FabricのLakehouseとWarehouseのアーティファクトのより良い選択に役立つことを願っています。
Microsoft Fabric レイクハウスとウェアハウスの違いは何ですか ?
レイクハウスは、Sparkにより管理され、テーブルはレイク内の特別なフォルダに保持されるDBです。また、SQLエンドポイントを自動生成し、SQLクエリを実行することが可能です。ウェアハウスは、T-SQLにより管理されるDBで、テーブルはDelta Parquet形式で格納されます。どちらのDBも、Power BIデータセットを生成し、"テーブル"フォルダから直接データを読み取ることができます。しかし、メジャーやリレーションシップはデータセット自体が保持しており、レイクハウスやウェアハウス自体には存在しません。そのため、データセットのメタデータはレイクハウスやウェアハウスで定義できるが、それ自体には保存されません。スケールアップやスケールダウンが必要な場合、Fabricへの移行が必要で、その選択はSparkの使用が必要かどうかによります。Fabricは、計算能力の柔軟性を提供します。
Bronze、Silver、Goldのようなメダリオンアーキテクチャにとっては、Microsoft Fabric のベストプラクティスを教えてください。
メダリオンレイクハウスの構成は Microsoft Fabric を使用する場合でも変わらず、しかし Microsoft Fabric は追加のオプションと機能を提供します。通常、Gold レイヤーはデータウェアハウス(DW)を給餌してユーザーサービスを提供しますが、Microsoft Fabric を使用すると、Gold テーブルは SQL エンドポイントを介して直接クエリを処理し、Power BI レポートも DirectLake を使用して処理します。さらに、データサイエンティストが Silver レイヤーにアクセスし、データサイエンスエンジンを使用して更なるデータを生成することが可能になり、結果としてソリューションの柔軟性が向上します。
Microsoft Fabric の Synapse Dedicated SQL Pool と Synapse ウェアハウスは違うのですか ?
Synapse Serverless SQL Pool と Synapse Dedicated SQL Pool の良さを融合させ、従来の独自フォーマットとは異なり、オープンなデータフォーマットで最適化された、真に弾力的でパフォーマンスの高いエンジンをお客様にお届けします。Microsoft Fabric の Synapse データウェアハウスは、「One Copy」の概念を促進するオープンデータ形式である Delta 上で標準化されています。Microsoft Fabric のすべてのコンピュートエンジンは、Delta フォーマットで推論することができます。Synapse ウェアハウスは、たまたまそれを特に高速に実行することができました。
Synapase は無くなります ?
No. Azure Synapse Analytics は、そのまま Azure 内の PaaS として継続提供します。Microsoft Fabric は SaaSとして、サービスを提供していきます。
Synapase Dedicated SQL Pool は無くなります ?
No. Synapse Dedicated SQL Pool は継続的に Azure Data PaaS として提供します。Microsoft Fabric にはプロビジョニング済みの Dedicated SQL Poolはありません。今後、Synapse Serverless SQL Poolから Microsoft Fabric にリンクし、移行できるようになります。
Microsoft Fabric Synapse ウェアハウスでも、裏でMPP (Massively Parallel Processing) システムのアーキテクチャを使用しているのでしょうか ?
Yes. 私たちの MPP システムは、Polaris という分散型クエリーエンジンをベースにしており、ライブのワークロードをリサイズする機能、スケールで予測可能なパフォーマンスを提供する機能、構造化データと非構造化データの両方を効率的に扱う機能、楽しみな革新的な機能など、多くの重要機能を実現するために設計されています。
Microsoft Fabric Synapse ウェアハウスでワークロード管理を行うにはどうすればよいですか ?
これは簡単です - 実行する必要はありません!サーバーレスコンピューティングの利点に基づき、クエリが流れるにつれて計算容量を自動的に上下に調整します。SaaS の精神に則り、私たちの目標は「ノブなし」の経験を提供することであり、それは顧客の課題を Microsoft のエンジニアが解決する課題に転送したことを意味します。それは言うまでもなく、表面化すると利益があると思われるノブがある場合、我々はそれをためらうことはありません。
Synapase Dedicated SQL Pool から Fabric Data Warehoseに移行するには ?
現時点では、Copy アクティビティで、データを移すことが可能ですが、今後、Synapse Serverless SQL Poolから Microsoft Fabric にリンクし、移行できるように開発中です。期待してください。
Synapse Warehouseでインデックスを作成することは可能ですか ?
No. 現在はできません。将来的には可能です!ご期待ください。
ワークロードの最適なパフォーマンスを確保するために、どのようにワークロードの分離を提供するのですか ?
お客様には、自然分離の境界が提供されます。これは何を意味するのでしょうか?クエリーが流れ込んでくると、そのクエリーのワークロード特性をインテリジェントに判断します。アドホッククエリや分析ワークロードは、ETLジョブとコンピュートリソースを共有しないので、日々のロードジョブがエグゼクティブが実行するレポートに干渉する心配はありません。
V-Orderとは何ですか。そして私はそれを心配する必要がありますか ?
No. V-Orderは、単にparquetファイルを書くためのより良い方法です。V-Orderは書き込み時間の最適化で、Power BI、SQL、SparkなどのMicrosoft Fabricコンピュートエンジンの読み込み速度を飛躍的に向上させます。VOrderの詳細はこちら。
Synapse Dedicated SQL Pool に既存投資をしています。どのような選択肢がありますか ?
非常に有効な質問です。 まず、落ち着いてください。これは、Microsoft が長い間考えてきたことです。Synapse Dedicated SQL Pool への既存の投資をお持ちの場合、いくつかの実行可能なオプションがあります。Synapse Dedicated SQL Pool は PaaS として提供されている GA 製品であり、今後もずっと存在し続けるでしょう。
一方、新しいプロジェクトを立ち上げ、レイクファーストのアーキテクチャを採用したいのであれば、データを Delta フォーマットでランディングするのが賢明です。そうすれば、Microsoft Fabric レイクハウスからそのデータへのショートカットを作成し、好みのコンピュートエンジンを使って活用を開始することができます。データをDelta フォーマットで保存しておくと、SQL や Spark の仲間からすぐに利用できるようになるのがいいところです。
マイグレーションに興味がある方は、マイグレーションツールの開発に取り組んでいますので、ご期待ください。
Azure SQL Database と Microsoft Fabric Synapse データウェアハウスの違いは何ですか ?
Azure SQL Database は、トランザクションとレコード用に最適化された OLTP です。
Microsoft Fabric DWは、膨大な量のデータのクエリと要約に最適化されたMPP分析エンジンです。
Azure Data Factory は無くなります ?
No. Azure Data Factoryは、そのままAzure 内のPaaSとして継続提供します。Microsoft Fabric はSaaSとして、サービスを提供していきます。
Azure Data Factory から Fabric Data Factoryに移行するには ?
今後、Fabric から Azure Data Factoryをマウントできるように、開発中です。期待してください。
Azure Data Factory や Syanpse Pipeline の Mapping Data Flow から Fabric Data Factory に移行するには ?
プレビューの現時点では、Microsoft Fabric Data Factory には Azure Data Factory や Syanpse Pipeline の Mapping Data Flow のような機能はなく、Fabric Data Flow Gen2に移行するか、Notebookなどで、作り直していただくことになります。GA までは Update される可能性もあるので、期待してください。
Microsoft Fabric 容量(CU) のサイジングするには ?
現在のところ、必要な容量サイズを簡単に前もって見積もることができる計算式はありません。容量サイズを決めるには、実際に使ってみて負荷を測定するのが一番です。お客様のニーズに合った Fabric の容量サイズを評価するには、Fabric のトライアルから始めるか、テスト用に従量制の Fabric の容量サイズを選ぶかのどちらかになります。元々8月1日までですが、現時点では、10月1日までは、Power BI 以外の Fabric ワークロードは、購入した容量制限にカウントされません。容量測定アプリ(トライアルと有料の容量をサポート)は、プレビューと有料の使用量を表示し、追加コストを発生させることなくサイズを評価することが可能です。
今年後半には、Fabric のニーズをサイズ化するのに役立つプランニング・カルキュレーターをリリースする予定です。
Microsoft Fabric Workspace を指定するリージョンにデプロイできますか ?
Azure Portal でキャパシティがプロビジョニングされるとき、その展開のためのリージョンを選択できます。キャパシティに割り当てられたワークスペースは、すべてのデータがそのリージョンに保存され、コンピュートも同じリージョンで動作するようになります。
異なるリージョンにキャパシティをプロビジョニングすることで、Fabricテナントは望ましいデータレジデンシー要件を維持することができます。
Microsoft Fabric Ideas and Feedback
今後の GA に向けて、皆様の検証されたFeedback、または追加してほしい機能のアイデアなどがありましたら、Fabric Ideas サイトに寄せてください。
Microsoft Fabric Ideas (こちらのサイトでは、これから実装計画、検討しているかどうかの機能もサーチできます)
https://ideas.fabric.microsoft.com/
Azure Synapse Analytics から Microsoft Fabric へ
既存の Azure Synapse Analytics ユーザーではない方は、この章をSkipしてください。
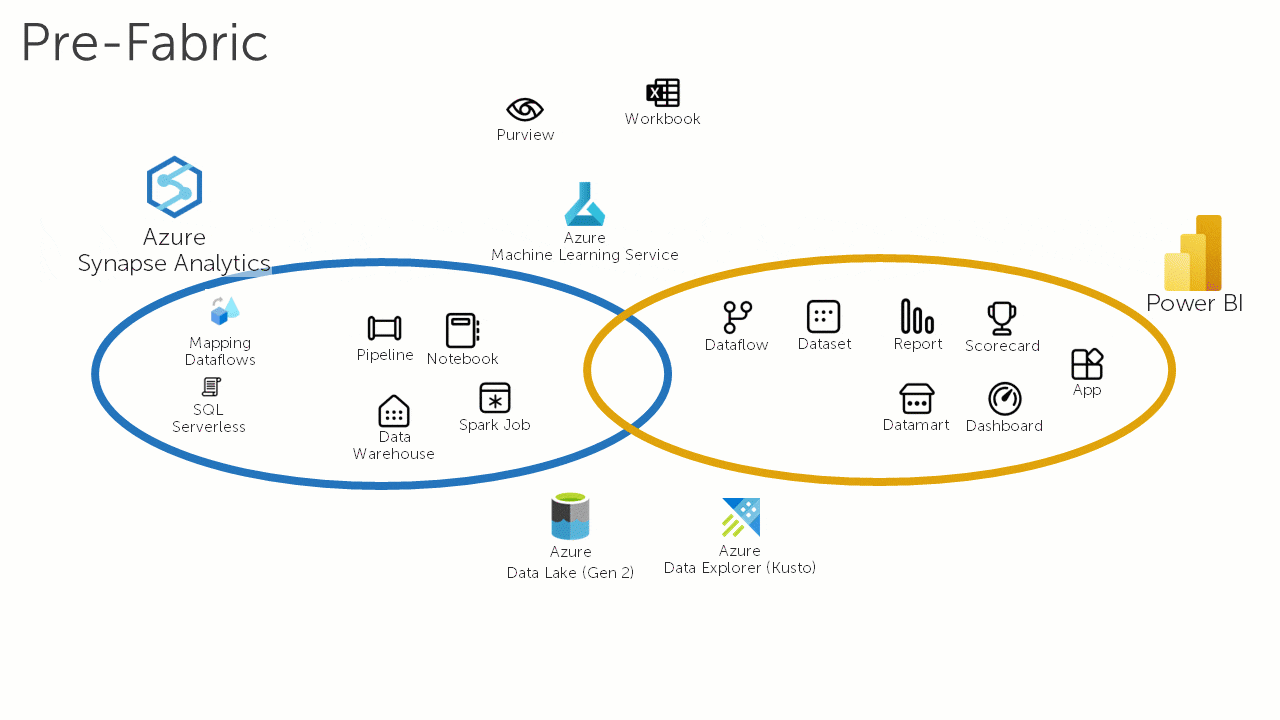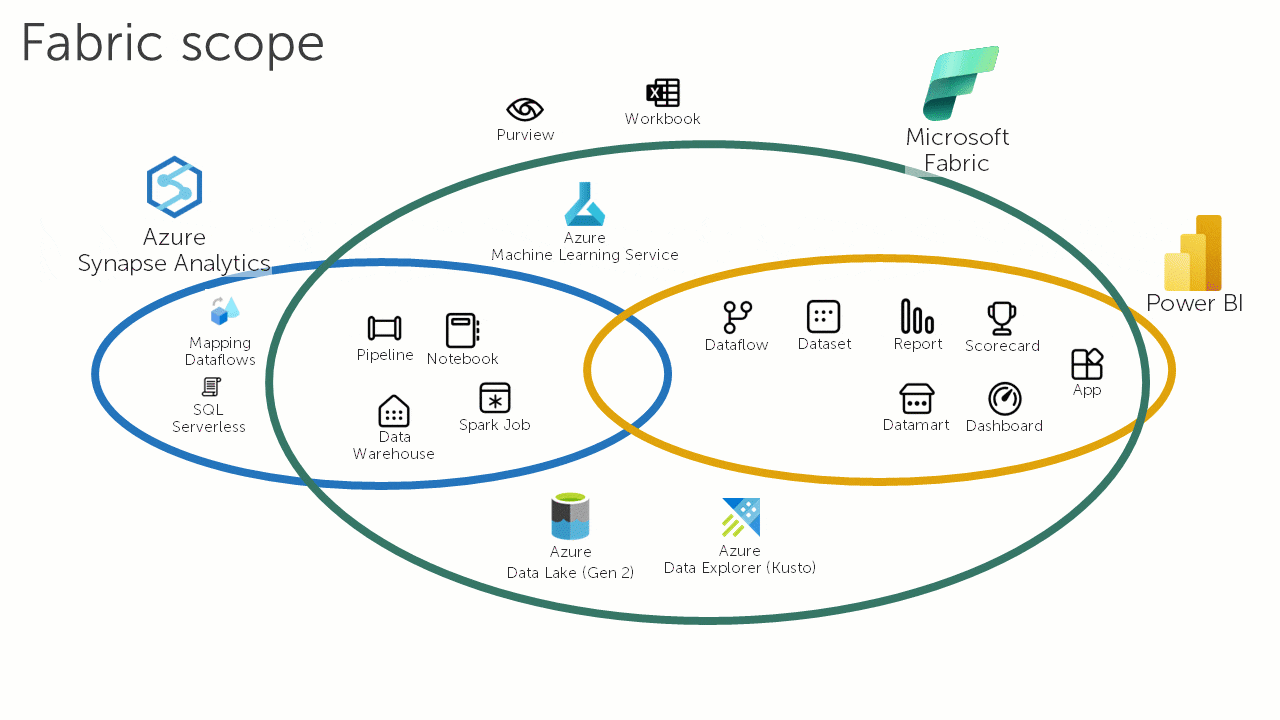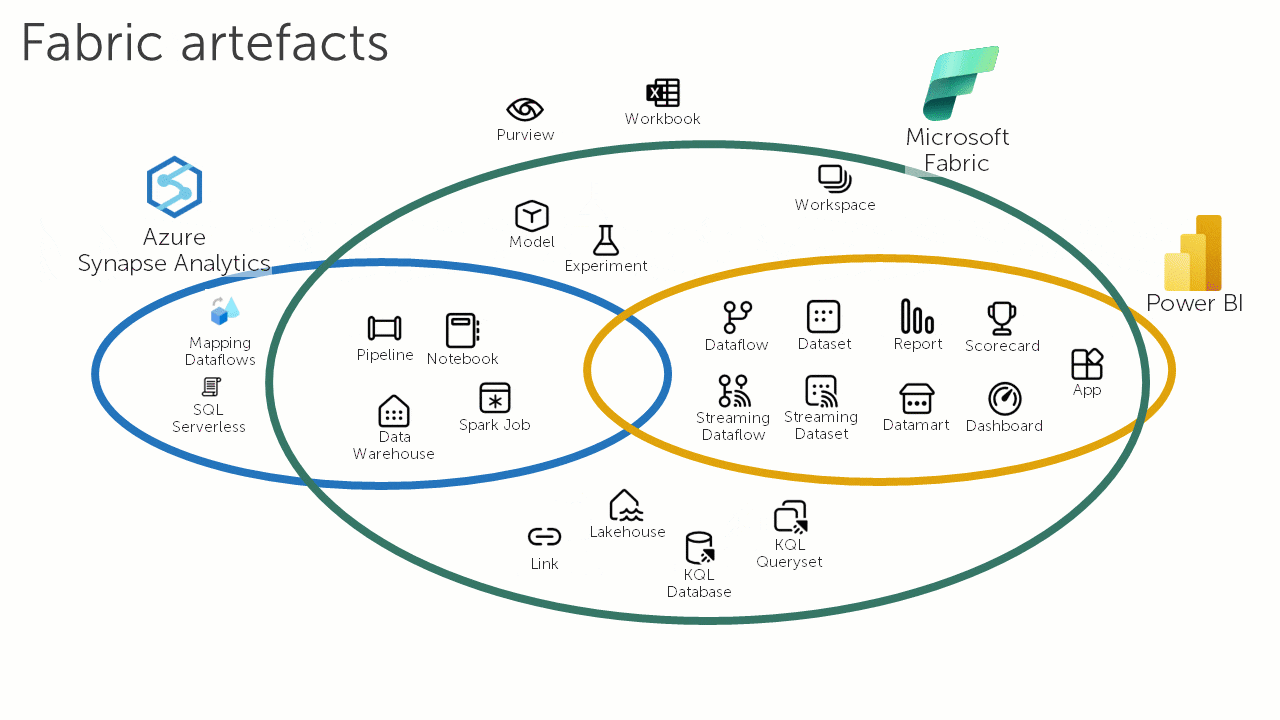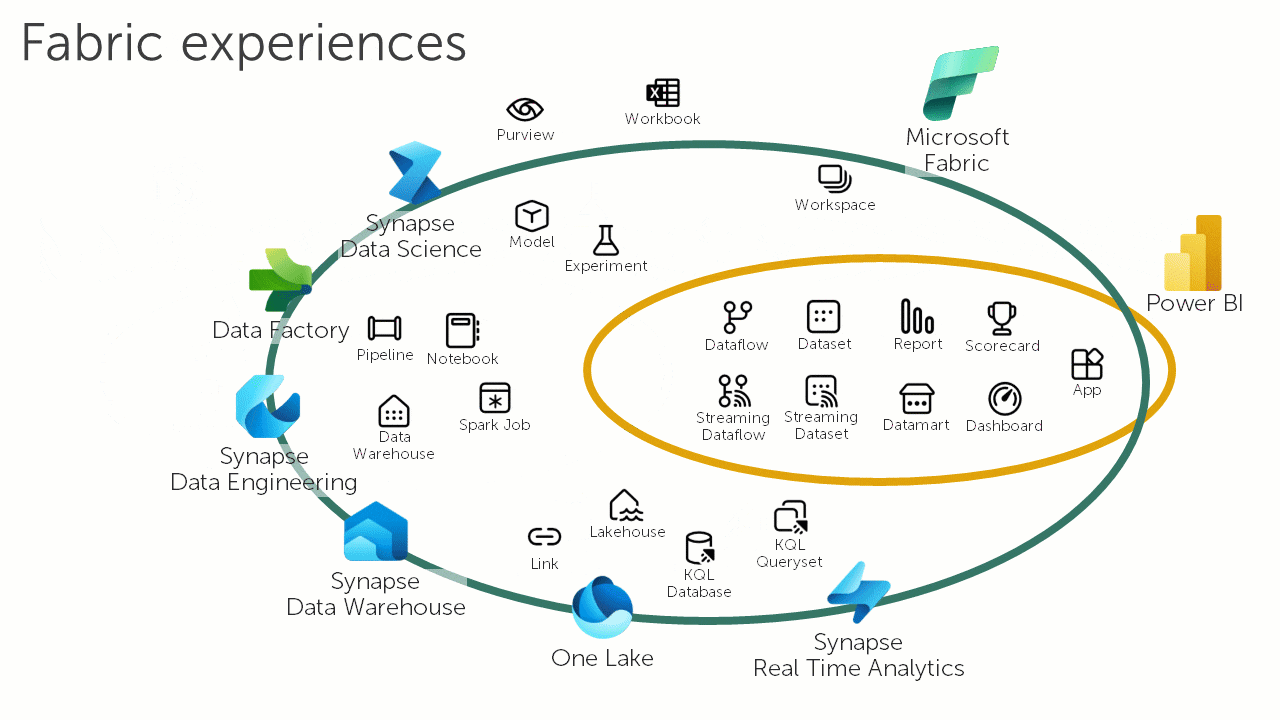
Ref: Azure Synapse Analytics versus Microsoft Fabric: A Side by Side Comparison
こちらのアニメーションは、Microsoft Fabric がデータと分析のランドスケープをどのように変えているかを示しています。
Microsoft Fabric は、セルフサービス プラットフォームを提供することで、データと分析の民主化や「データ製品」の分散型ドメイン駆動型所有権などの新しい要件に対応するために、Auzre Synpase と Power BI で愛用するようになった機能を統合および拡張することで、この利点を実感させようとしています。
現時点のパブリックプレビュー時点では、Microsoft Fabric は Azure Synapse ビジョンの進化形ですが、直接または自動のアップグレードの明確なパスがないため、移行と見なす必要があります。
下記は、Synapse ユーザー向けの違いのまとめ表です。
| Azure Synapse Analytics | Microsoft Fabric | 比較説明 |
|---|---|---|
| Serverless SQL Pool | Fabric SQL Endpoint | OPENROWSET 構文がサポートされていないため、SQL を使用してレイク内のファイルを照会することはできません。ただし、レイクの「テーブル」領域に配置された構造化データを使用すると、「デフォルトウェアハウス」のSQLを介してそのデータを照会できるため、OPENROWSETと同様の機能が提供されます。 |
| Dedicated SQL Pool | Synapse Data Warehouse | ウェアハウス データが OneLake に保持されるようになりました。 |
| Apache Spark Pool | Fabric Managed Spark Pool | Fabric は SaaS であるため、Spark プールを作成して管理する必要はありません。使用する Spark 環境のバージョンを選択し、ノートブック内で動的にこれを行うオプションを含め、特定の Python パッケージを環境に読み込むことができます。パフォーマンスの向上は、基盤となる Spark 環境が数分ではなく数秒で「スピンアップ」することを意味します。 |
| Apache Spark Notebooks | Fabric Notebook | 多くの新機能が追加されました。①コメント機能ですが、Wordと同様にノートブックにコメントを追加する機能。②共同編集機能ですが、複数のユーザーがノートブックを同時に開いて編集できます。③Data Wrangler機能ですが、ノートブックでは、データを探索するための新しいユーティリティを使用できます。現時点 Pandas DFをサポートしています。いわゆる PySparkコードを生成させる UIでも言えます。Pandas DF の Power Query版のようなイメージです。 |
| Apache Spark Jobs | Spark Job Definition | 同じと見なされます。 |
| Data Explorer (KQL Scripts) | KQL Queryset | 同じと見なされます。 |
| Data Explorer Database | KQL Database | 同じと見なされます。 |
| Synapse Link | Fabric Link | 現時点、Synapse Link のようにまだ使えません。将来の Fabric Link シリーズを期待しています。 |
| Synapse Studio | Power BI サービスベースの Fabric UI | ワークスペースは、資産を整理し、セキュリティのいくつかの側面を推進するために使用されます。ユーザー エクスペリエンスは、特定のペルソナ 「データ エンジニアリング」、「データ サイエンス」、「データ ウェアハウス」、「リアルタイム分析」を中心に編成されるようになり、スタンドアロン ツールとして Power BI、Data Factory、Data Activator が引き続き使用できます。 |
| Git 統合 | Git 統合 | Microsoft Fabric は Azure Synapse Analytics と同様の方法で Git 統合をサポートしており、Microsoft Fabric ワークスペースを Git ワークスペースと同期できます。ただし、ノートブックなどのアーティファクトは、Azure Synapse Analytics で採用されている独自の JSON 形式ではなくネイティブ ファイル形式を適応させるため、ソース管理でキャプチャされる方法が大幅に改善されています。ネイティブ構文の採用により、変更の追跡とレビューが大幅に容易になります。 |
| ML / MLOps | Synapse データサイエンス | モデルは、Microsoft Fabric が提供するネイティブ MLFlow エンドポイントを使用して登録し、実験を追跡できます。Azure Synapse Analytics でこれを行うには、Azure Machine Learning のインスタンスを作成し、これを Azure Synapse Analytics 環境と統合する必要があります。モデルのクリーニング、準備、特徴付け、トレーニング、評価のためのコア作業は、Synapse ML などのオープン ソース ライブラリを使用して Spark プラットフォーム上のノートブックで実行され、Azure Synapse Analytics プラットフォームで開発されたノートブックとの継続性を提供します。 |
| Mapping Data Flow | サポートされていません | Mapping Data Flows は、Azure Synapse Analytics でデータを変換するために使用できる 「ノーコード/ローコード」GUI です。これは Microsoft Fabric でサポートされていないため、同様の機能を実現するには、新しいData Flow Gen2 (Power Query) ツールを検討する必要があります。 |
| Synapse Pipeline | Fabric Data Pipeline | 一部のパイプラインアクションが Microsoft Fabric から削除されました。たとえば、機械学習機能との統合は、パイプラインではなくノートブックを介して行われるようになりました。また、Microsoft 365 のようなアクティビティも追加されています。 |
上記の違いを図でまとめると、下記のような表現になります。
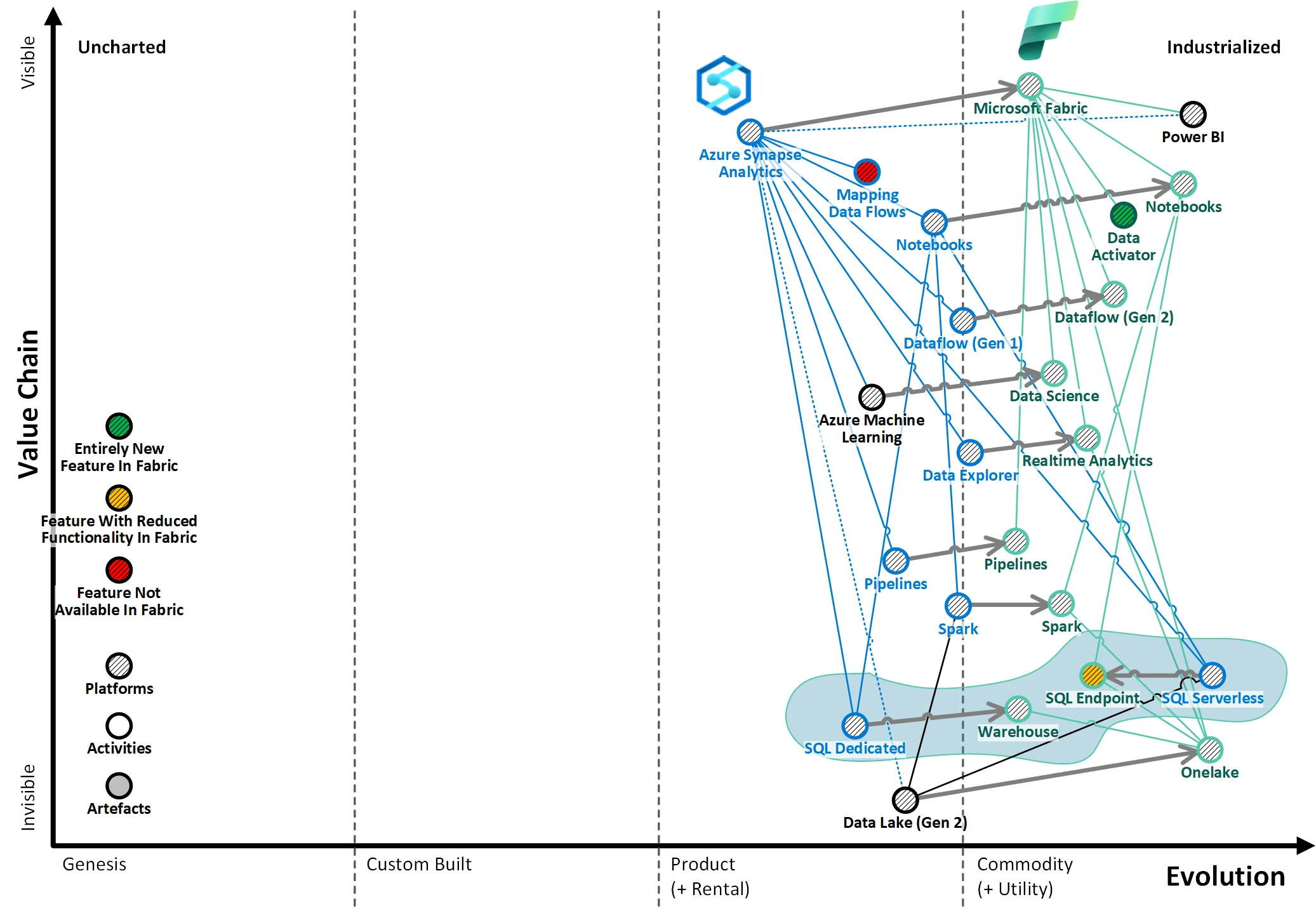
下記は、データバリューチェーンの図です。
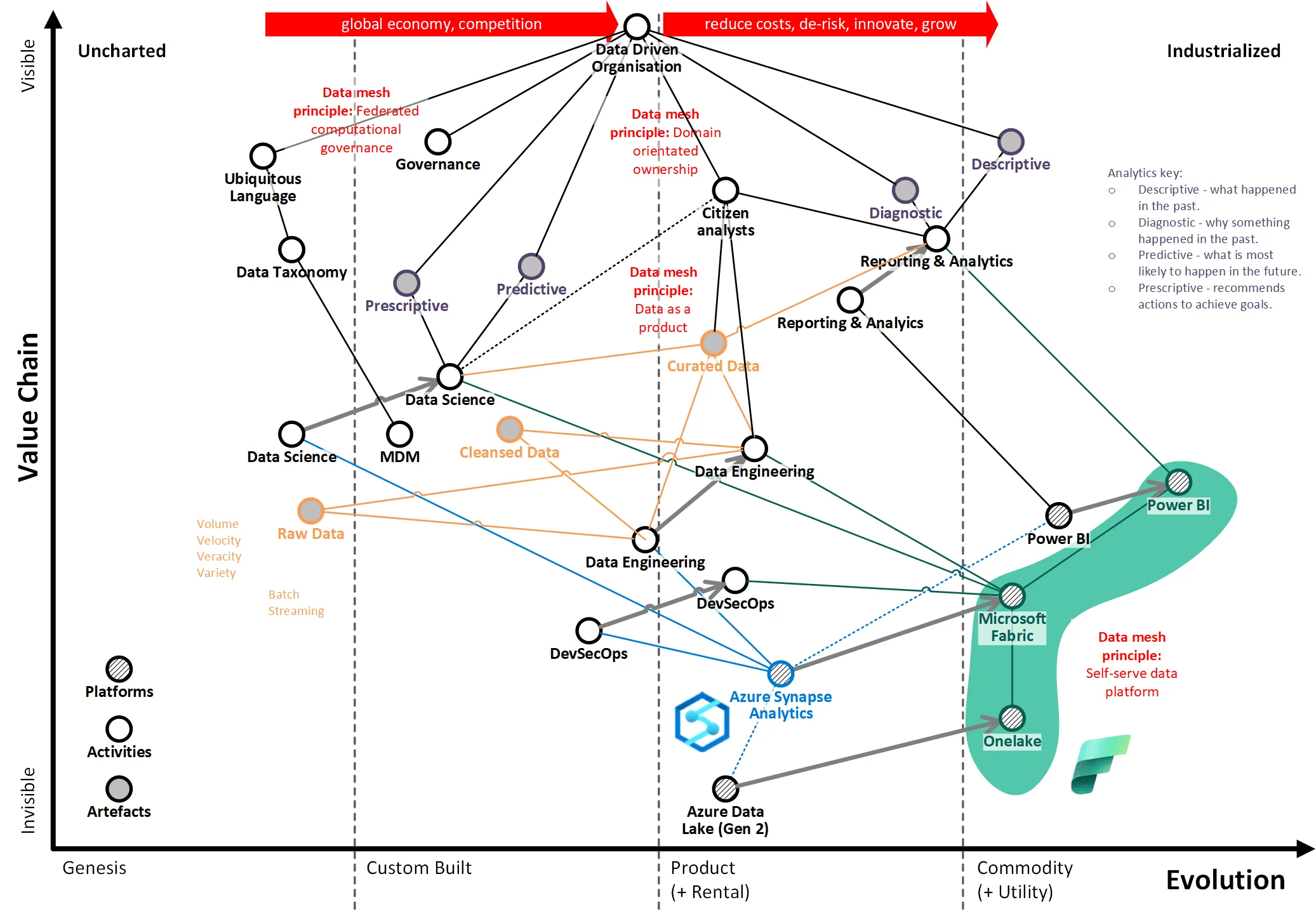
この基盤技術の動きは、より広い「データバリューチェーン」の進化も可能にすると想定しています。データペイロードと分析要件の全範囲をサポートする緊密に統合されたセルフサービスデータプラットフォームを提供することにより、組織はデータから価値を提供できるようになります。
Azure Synapse Analytics から Microsoft Fabric に移行する障壁について
Mapping Data Flow
Microsoft Fabric では、Azure Data Factory や Synapse 用の Mapping Data Flow (Spark UI のようなもの)は現時点では、同じような仕組みは提供されていません。そのため、移行時に、新しい Data Flow Gen2 に作り直す必要があります。ローコードツールに多額の投資を行ってきた組織にとっては、移行に対する大きいな障壁となり、十分に検討と事前検証を行うことをお勧めします。
T-SQL OPENROWSET()
現時点では、Microsoft Fabric の T-SQL クエリがレイク内の構造化データ ファイルを直接アドレス指定できるようにする OPENROWSET 構文はサポートされていません。OPENROWSET を使っているクエリは、書き直す必要があります。構造化データが Delta 形式でない場合(Parquet、CSVなど)、このデータはレイクハウスの「テーブル」エリアに配置でき、Microsoft Fabric はこのデータを自動的にスキャンし、「Default Warehouse」の T-SQL を介してクエリを実行できるようにするため、OPENROWSETと同様の機能を提供しますが、ファイルを直接処理するのではなく、作成された論理管理テーブルに対してクエリを実行します。これは、テクノロジとしての "SQL Serverless" の終焉を意味するものではなく、すべての Microsoft Fabric Lakehouse で利用可能になる "Default Warehouse" は、Synapse の "SQL Serverless" と非常によく似た方法で活用できます。つまり、今まで Azure Synapse Analytics で、Serverless SQL Poolを使って、直接ファイルやフォルダにダイレクトにアクセスすることを、レイクハウスの Table として、作り出すと、同じのことができるという意味です。
Linked Service Dynamic Parameter
Linked Serviceという概念はなくなり、Microsoft Fabric では、Connectionという概念があります。そして、現時点では、Connection には、Dynamic パラメータがサポートされておらず、Synapse Pipelineの中の DataSet の Dynamic パラメータの作り次第ですが、そのままで、Microsoft Fabric Data Factory に持ってこれないため、作り直すことが発生する可能性があります。JSON 定義のままでは、持って来れないということです。
一方、Azure Synapse Analytics ユーザーによって、Microsoft Fabric を使ってうれしいこともあります。
Azure Machine Learning
機械学習モデルを登録して実験をログに記録するために Azure Machine Learning のインスタンスを作成する必要はなく、Fabric には既定で MLFlow エンドポイントが用意されています。それは、Azure Synapse Analytics ではできないことの一つでも言えます。
Power BI
Microsoft Fabric は BI 軸にした SaaS 製品です。Azure Synapse Analytics と Power BI の統合 (Synapse Stuido Power BI テナントリンク) はありましたが、これは Microsoft Fabric によって大幅に強化されています。データセットはレイクハウスに直接簡単に作成でき、モデルとメジャーは Fabric UX内から作成できます。これは段階的な変化のように感じられ、データ エンジニアは、モデルとメジャーを作成するために Microsoft Fabric を離れる必要がないため、生データを分析データに変換して Power BI データセットをセマンティック レイヤーとして使用するために "左から右" で作業する方が自然なことです。さらに、デフォルトのデータセットは、プロセスをさらに強化する Microsoft Fabric のレイクハウスの上に作成されます。最後に、データセットが Power BI への入力としてだけでなく、他の多くの手段で使用できる "データ製品" として Microsoft Fabric で提示される方法は、大きな前進のように感じられ、Microsoft がこのアプローチに基づいて構築し続けています。
Synapse Spark Pool
Sparkインフラストラクチャのスピンアップにかかる時間は大幅に速く、Synapseでは4-5分であるのに対し、通常は3-4秒で、Notebook Cell を実行できます。
Notebook
新しいノートブック エクスペリエンスでは、コラボレーションを強化し、ハンドオフを減らすことで、大規模なチームに魅力的な新機能 (コメント、共同編集など) がいくつか提供されます。そして、VS Code でローカル操作できるため、プロ開発者の生産性がさらに向上します。
Azure Synapse Analytics を使っている組織は、Microsoft Fabric を評価し、そのテクノロジーロードマップに適合するかどうか、判断するポイントとしては、下記になります。
- TCOへの影響:PaaSからSaaSへの移行が総所有コストにどのような影響を与えるか評価します。
- SaaSの長所と短所:FabricがSynapseよりも制御性が高いテクノロジを提供する一方で、決定の自由度が制限される可能性がある。自身の要件と比較して評価する必要があります。
- ベンダーロックイン:Fabricに移行することが、将来的に他のベンダーへの移動を困難にする可能性があるか考慮します。
- Time to Value:Fabricの開発者エクスペリエンスと生産性機能が開発ライフサイクルを効率化する機会を提供するか評価します。
- 技術的負債の最小化:Fabricがコードベースを簡素化し、メンテナンスの負担を軽減するか考慮します。
- Azureのコスト:Fabricが異なる課金モデルを採用しているので、これがAzureの運用経費にどのように影響するか評価します。
- 新機能:Fabricの新機能がどのような新たな機会を提供し、バックログのユースケースを解放するか評価します。
- 戦略:Fabricが長期的なデータ分析戦略にどのように適合し、次世代のデータ分析機能をどの程度実現しているか評価します。
- Lakehouse:データレイクとデータウェアハウスの最良の機能を組み合わせて、クラウドネイティブ分析の提供を効率化します。
- Data Meshアーキテクチャ:分散型ドメイン駆動型所有権、発見/共有可能なデータ製品のサポート、分析の民主化を可能にするセルフサービスのデータプラットフォームの採用を評価します。
- データ仮想化:OneLakeなどの機能の評価を行います。
- 新しいコンセプト:Fabricが次世代のプラットフォームとして導入している新しい概念がビジネス、データ、テクノロジーアーキテクチャに適しているか評価する必要があります。
Microsoft Fabric を始めるには

Power BI Premium Capacity P1以上の組織は、Power BI 組織のテナントが 自動的に、Fabric テナントに移行され、すぐに利用できます。
また、Power BI Premium Capacity P1のお持ちではないユーザーは、Microsoft Fabric (Preview) 試用版で体験できます。

Microsoft Fabric (Preview) 試用版
こちらの https://aka.ms/TryFabric にアクセスし、試用版を開始してください。
現時点、Microsoft FabricがサポートしているリージョンはFabric region availabilityで確認できます。
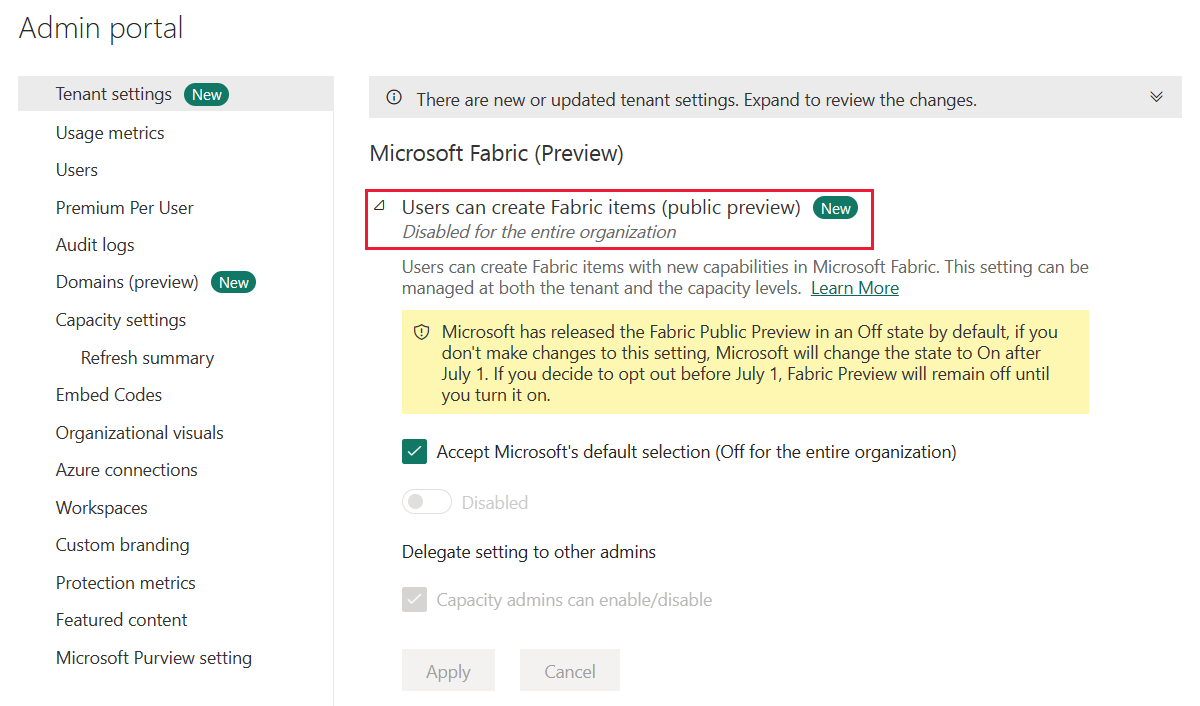
Microsoft 365 Global admin、Power Platform admin、またはPower BI admin権限を持つユーザーはテナントの管理ポータルで、有効にすることができます。
手順 : Step-by-Step Guide to Enable Microsoft Fabric for Microsoft 365 Developer Account
https://techcommunity.microsoft.com/t5/educator-developer-blog/step-by-step-guide-to-enable-microsoft-fabric-for-microsoft-365/ba-p/3831115
Microsoft Fabric 学習コンテンツ

Microsoft Fabric exercises
https://microsoftlearning.github.io/mslearn-fabric/
Microsoft Fabric の概要
https://learn.microsoft.com/ja-jp/training/paths/get-started-fabric/
Microsoft Community Event を参加し、その以上の詳細情報をゲットしましょう!
- 2023/05/24(水) : [特別企画] 超速報!現地からお届けする最新情報満載 Microsoft Build レポート
- 2023/05/25(木) : Power BI 勉強会 夜の採れたて Microsoft Build 2023
- 2023/05/27(土) : Microsoft Build 2023 Data Platform Update (Hybrid) 日本Microsoft本社 SGT
- 2023/06/08(木) : [Recap] Microsoft Build 2023 最新アップデートAnalytics&AI
- 2022/06/15(木) : 最新情報をお届け!MicrosoftのData & AI サービス Update会
- 2022/06/30(金) : ビジネスに必須な AI とデータ分析基盤の最新情報を一挙公開!
Microsoft Fabric 導入相談について

Microsoft Fabric Discussion Request - Japan
https://forms.office.com/r/FeuVqCQ4qn
最後に

ぜひ、次世代のクラウドデータ分析ソリューションである Microsoft Fabric を使ってみてはいかがでしょうか。
その素晴らしいエクスペリエンスをご自身で感じてみてください。

今後のロードマップについては、ご参考ください。
Microsoft Fabric Roadmap
https://aka.ms/fabricroadmap
また、当 Community では、Azure Data Platformの勉強会は毎月に開催しています。ぜひ、Communityもアクセスしてみてください。そして、SQL Server 2022 新機能などのイベントも開催しております。

Japan SQL Server User Group
https://aka.ms/jssug
Join Japan SQL Server User Group Slack
https://join.slack.com/t/jssug-sqlserver/shared_invite/zt-n5r5n88h-JZgmtyYEaPErE1PxX5xxhQ