はじめに
Microsoft Build 2023 で発表のあった Azure OpenAI on your data のパブリックプレビューが開始されました。「on your data」の名前の通り、Azure OpenAI Studio の Chat Playground 上で Azure Cognitive Search のデータを参照し、モデルが知らない内容を答えられるようにしてからノーコードでAzure AD 認証付きチャットアプリのデプロイまでやってしまうという機能です。
内部アーキテクチャ
「on your data」の仕組みは以下のようなアーキテクチャになっていると考えられます。考えられますというのは、Azure Cognitive Search からの Grounding の処理が on your data REST API 内部で行われるため、詳細が隠蔽されているためです。今回使用する Azure OpenAI モデルが ChatGPT 系だけなので、検索クエリ生成も gpt-35-turbo を使っているかと思います。そしてベクトル検索機能は使用されません。
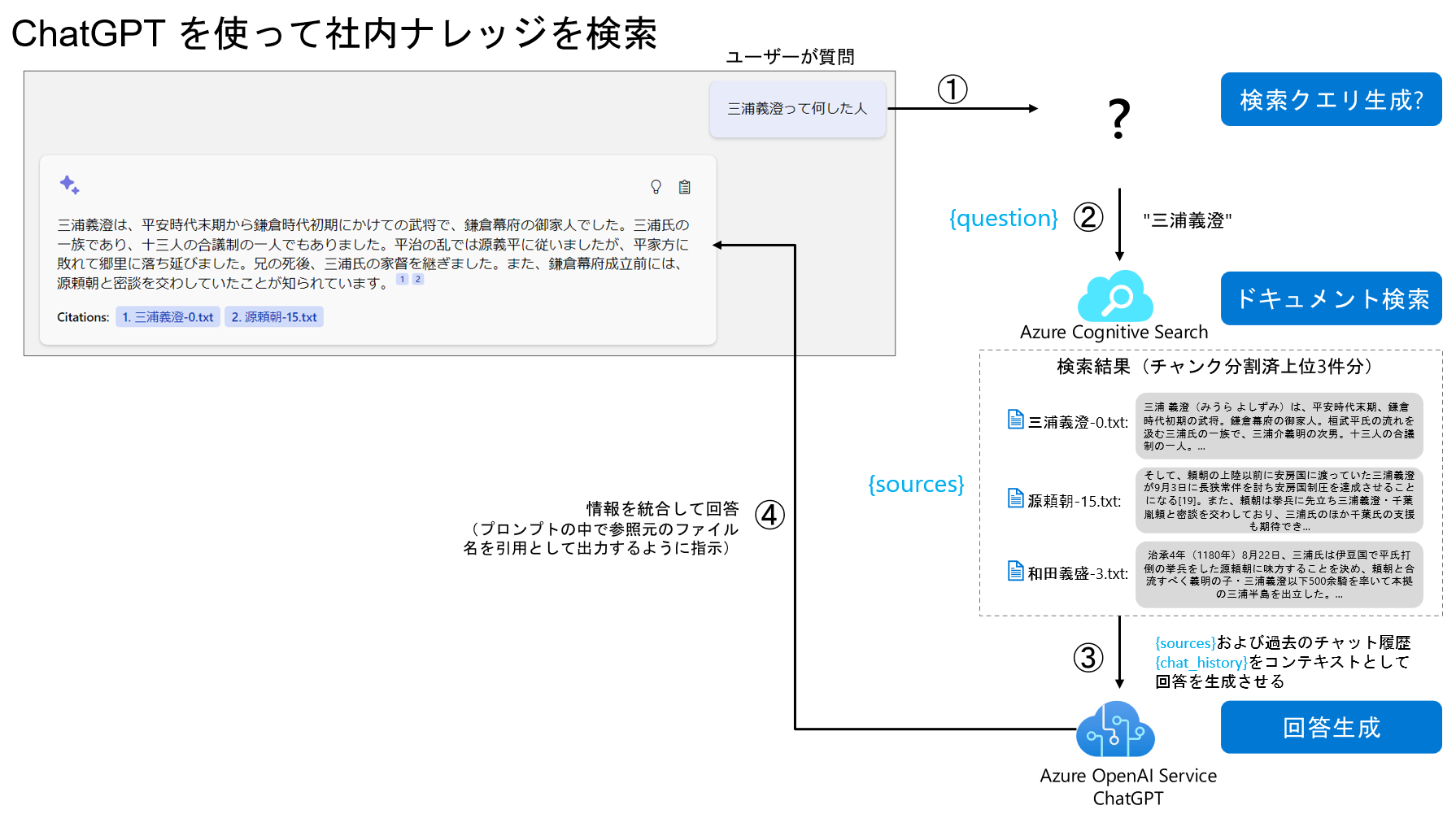
すでにこのアーキテクチャは以下の記事で実装できるサンプルコードを紹介していますので、ご自分で構築されている方はあまり必要のない機能かと思います。
使用方法
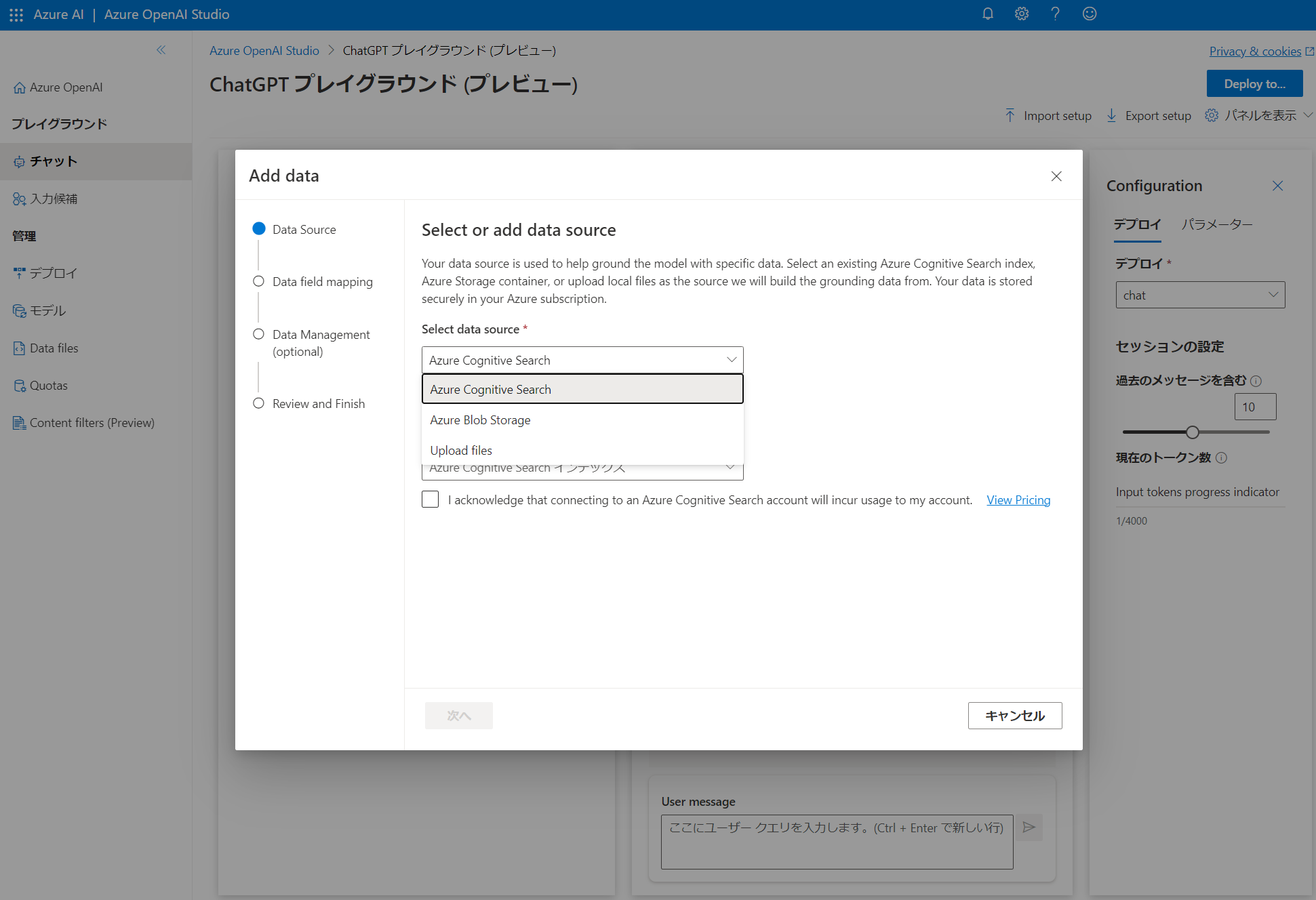
ドキュメントを参考に Chat Playground 上から設定します。現状データソースは 3 つから選択できます。
日本語対応
パブリックプレビュー開始時点では日本語での検索に制約がありますので以下の 1 のみが動作します。 日本語でセマンティック検索は使用できません。
-
Azure Cognitive Search 既存インデックス連携
既存の日本語アナライザーを設定済みのインデックスを用意してから、Semantic search configuration を 「No semantic search configuration selected」状態で接続する必要があります。これはセマンティック検索クエリのパラメータqueryLanguageがen-usに固定されているためです。 -
Azure Blob Storage or Upload files
Azure Blob Storage を用意して、コンテナーにファイルを格納しておけば、自動的にドキュメントをチャンク分割して Azure Cognitive Search インデックスとして登録してくれる機能。現状だと自動で英語アナライザー(standard.lucene)のインデックスを作成してしまうので、日本語検索はうまくできません。(日本語だと一文字ずつトークナイズされているので、一見検索できているように見える)。現状は日本語にちゃんと対応したチャンク分割やインデックス作成をしてあげないといけないですが、早く改善してもらうために、試された方はフィードバックにご協力ください。
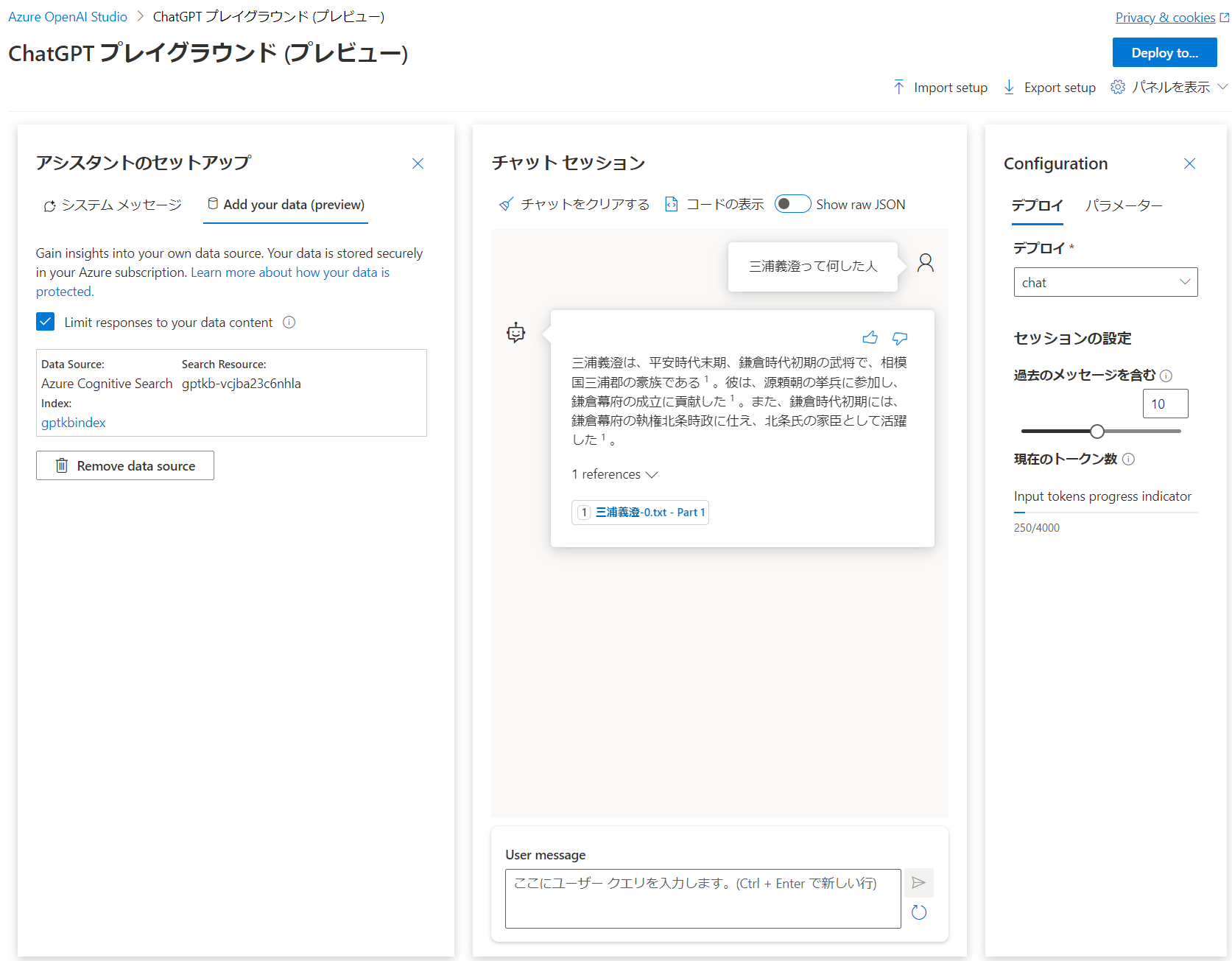
はい、前回すでにチャンク分割済み戦国武将データを作ってましたので、すぐに Grounding できました。この Playground 上で、system メッセージなどをカスタマイズしたり、「Limit responses to your data content」をチェックすることで Azure Cognitive Search のデータのみから回答することができます。現状、すべてのプロンプトが公開されているこちらと比較して、Grounding の精度が悪い印象です。隠蔽されている部分のプロンプト、カスタムできるようにしてもらえないだろうか。フィードバックしておきます。一応戦国武将のデモ用のチャンク分割のサンプルノートブックもあります。
Azure Cognitive Search へのデータ登録
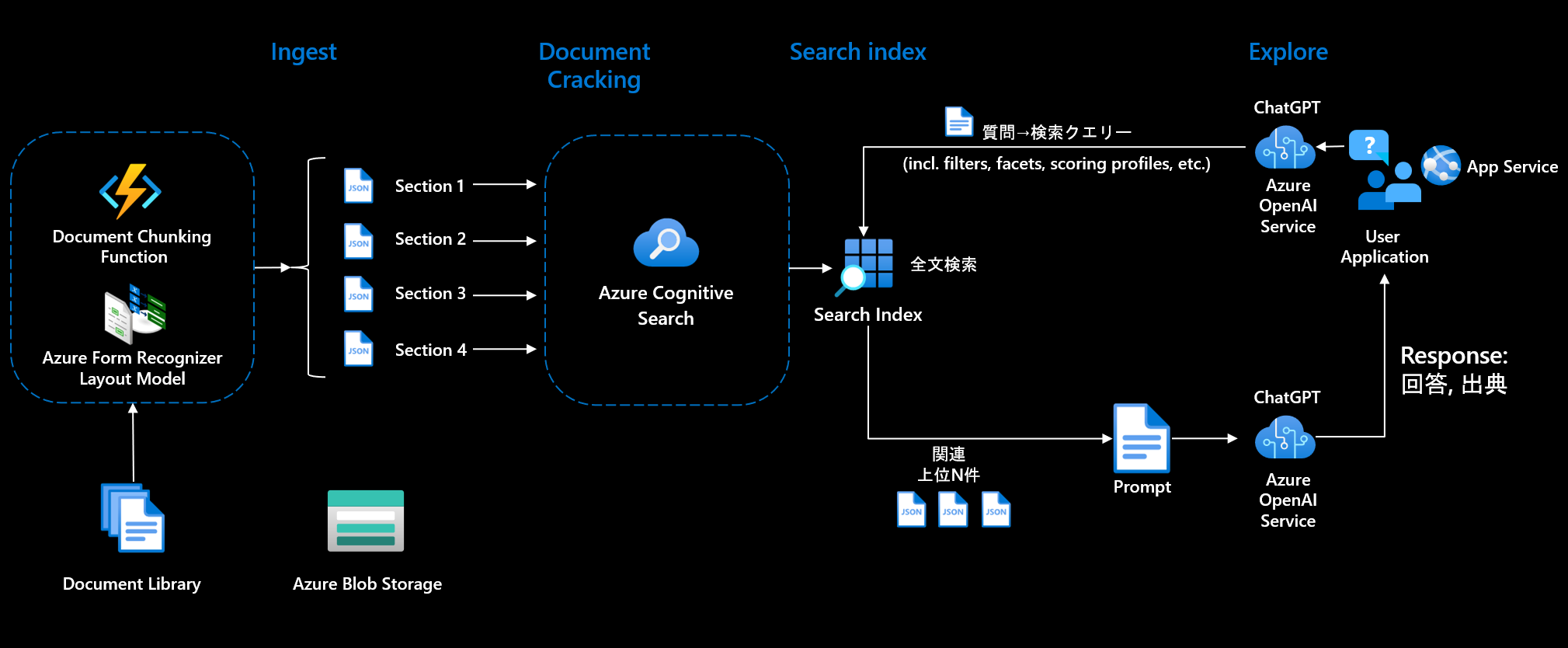
Azure Cognitive Search へデータを登録する部分を含めた参考アーキテクチャですが、「on your data」がドキュメントのチャンク分割を含めた Ingest の部分を自動化しているのでとても楽になります。対応していないファイルや、高度な AI OCR が必要な場合などは、Azure Form Recognizer も検討いただければと思います。
デプロイ
Chat Playground の右上にある「Deploy to...」ボタンをクリックすると、Azure AD 認証付きチャットアプリを App Service にデプロイできます。デフォルトで Azure AD 認証がかかるように設定されていますが、企業データを扱われる方は通信等のセキュリティには注意してください。
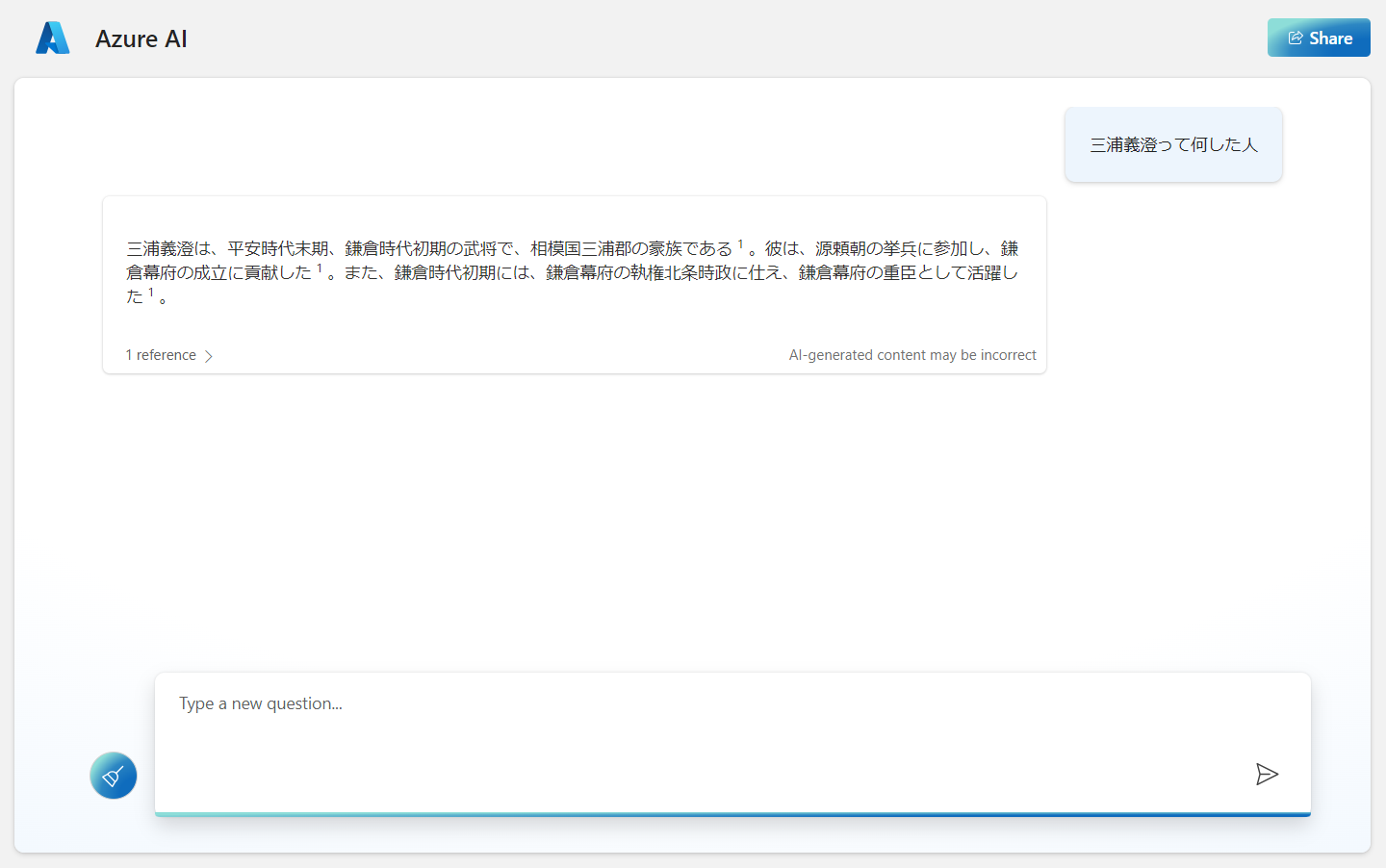
Azure Cognitive Search でヒットした検索結果を表示する引用機能もあります。
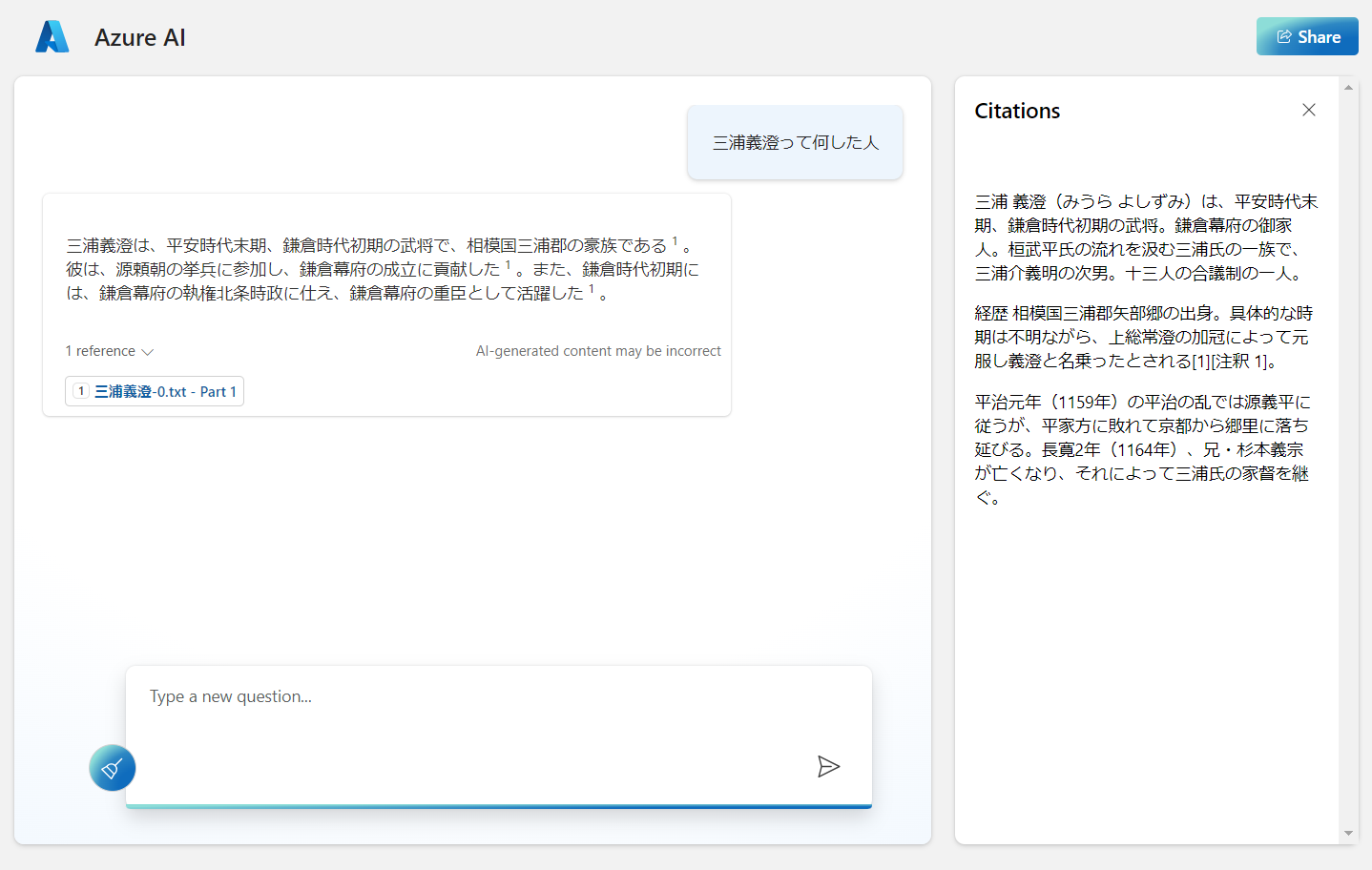
REST API
Azure OpenAI on your data は REST API 経由でも呼び出すことができます。この実装では、Azure Cognitive Search へのクエリー変換やデータの Grounding 部分は extensions/chat/completions API 側が行う処理のためこの部分だけはカスタマイズすることができません。
curl -i -X POST $AOAIEndpoint/openai/deployments/$AOAIDeploymentId/extensions/chat/completions?api-version=2023-06-01-preview \
-H "Content-Type: application/json" \
-H "api-key: $AOAIKey" \
-H "chatgpt_url: $ChatGptUrl" \
-H "chatgpt_key: $ChatGptKey" \
-d \
'
{
"dataSources": [
{
"type": "AzureCognitiveSearch",
"parameters": {
"endpoint": "'$SearchEndpoint'",
"key": "'$SearchKey'",
"indexName": "'$SearchIndex'"
}
}
],
"messages": [
{
"role": "user",
"content": "三浦義澄って何した人"
}
]
}
'
エンタープライズセキュリティ
「on your data」機能はどなたでも手軽に試せるツールといった位置付けです。実際にエンタープライズで利用する場合は以下も検討ください。
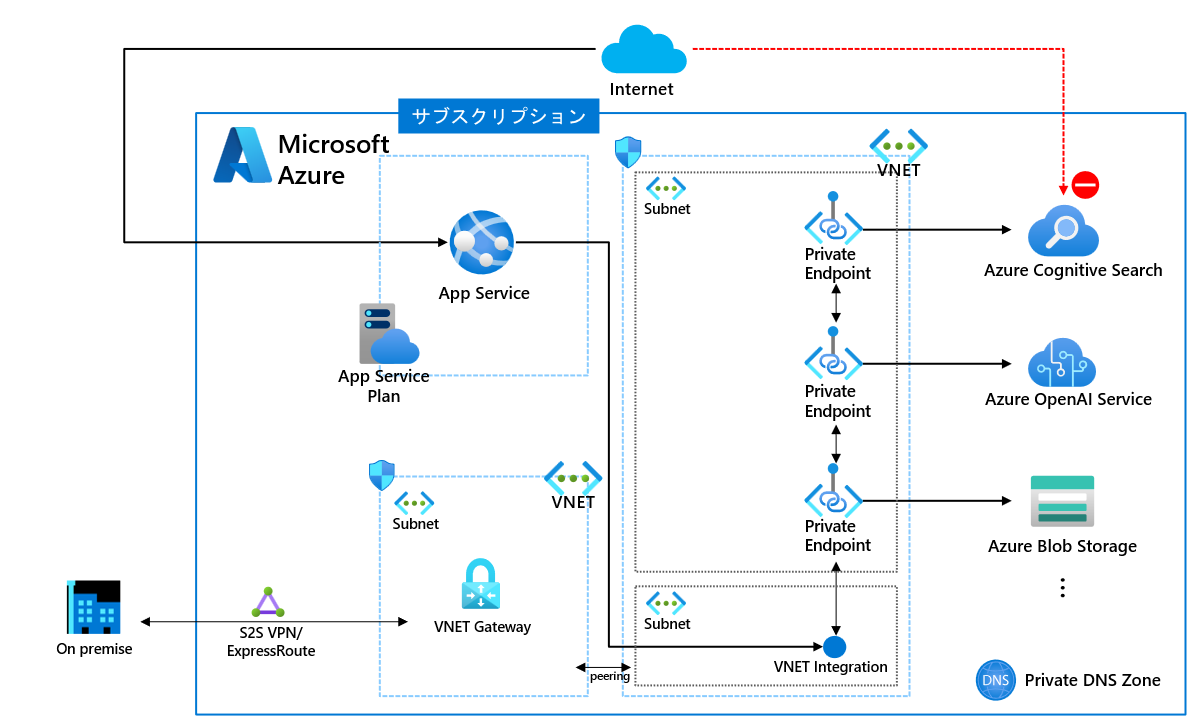
閉域網(VNET)構成
エンタープライズでのセキュアな利用は以下のような閉域網構成も構築可能です。設定はご自分で行う必要があります。
セキュリティフィルター
エンタープライズで Azure Cognitive Search を利用する場合、セキュリティフィルターの考慮が重要になります。Azure AD と連携させてユーザーごとにドキュメントを出し分けるという利用方法はよくあるニーズですので、以下を参考にフィルタークエリの利用を検討してください。
カスタマイズ
チャット UI のフロントエンドについては、以下の GitHub にて公開されているのでカスタマイズすることができます。
このリポジトリの /scripts にドキュメントをチャンク分割して日本語インデックスを作成して登録するスクリプトが用意されてますので、ノーコードではないですがご確認ください。
おわりに
Azure Cognitive Search を用いたデータの Grounding を簡単に試しながらチャットアプリまでデプロイできるようになりました。現在は日本語対応が甘いですが、Azure Cognitive Search Workshop を行っていただくと、インデックスの作成方法から検索クエリーの理解まで通してできますのでおすすめです。