2023/3/10 に Azure OpenAI Serivce で ChatGPT(gpt-35-turbo) がプレビューで利用可能になったと発表されました。この発表と同時に、ChatGPT と Azure Cognitive Search を組み合わせてエンタープライズサーチを構築するためのアーキテクチャ、サンプルコードが提供されました。
この発表およびサンプルコードの重要なポイントは以下です。
- ChatGPT(gpt-35-turbo)モデルでトレーニングされたデータに基づいてテキストを生成するのではなく、企業内に閉じたデータのみから生成する方法の例を示しています
- トークンの制限(4,096)の壁をできるだけ回避するための手法を紹介しています
- 「引用」をテキストに付加することで信頼できる応答を生成します
今回はこのサンプルコードを自分で理解しやすいようにカスタマイズしつつ内容を解説していきたいと思います。今話題の LangChain や gpt-index(LlamaIndex)を使用されている方は仕組みがかぶるので冗長な説明になるかと思いますがご了承ください。
※トークンの制限については、3/15 の GPT-4 の登場で最大 32,768 トークンまで使えるモデルが出てきたので将来的には分割する必要がなくなりそうです。
8/24 本記事の最新版を以下にまとめています
1. データ準備
提供されているサンプルコードに付随している PDF ファイルは、架空の Contoso 社の社内ドキュメントを GPT-3 に生成させたもので、英語です。本記事では、日本語を使って内部の動きを分かりやすく説明します。日本語で特別に考慮すべきポイントを踏まえつつ、サンプルデータも日本語のものを用意します。
今回は、以前 Azure Cognitive Search のセマンティック検索のデモを解説したときと同じ鎌倉時代の武将 Wikipedia を使ってみます。日本の歴史は現状の ChatGPT が不得意とする分野なので、今回のデモには最適です。
1.1. テキストの分割
通常 1 つのドキュメントに含まれるトークン数は 1 度のコンテキストに指定できる最大トークン数をゆうに超えます。サンプルコード(prepdocs.py)では、自前で PDF のテキストを解析し、PDF 自体を分割して Azure Blob Storage へアップロードしてインデックスを構築しています。(マジか)
サンプルコードをそのまま使ってもいいのですが、今回使用する日本語テキストデータは、チャンクの分割に日本語トークンとしての配慮が必要です。今回 LangChain の RecursiveCharacterTextSplitter および、from_tiktoken_encoder を使用して OpenAI に最適化された正確性の高いチャンク分割を行います。
- テキストの分割方法
RecursiveCharacterTextSplitter はチャンクが十分に小さくなるまで、順番に分割します。 - チャンクサイズの測定方法
tiktoken ライブラリのトークナイザーを使用してトークン数を正確に測定します。
text_splitter = RecursiveCharacterTextSplitter.from_tiktoken_encoder(
encoding_name='gpt2',
chunk_size=500,
chunk_overlap=50
)
chunk = text_splitter.split_text(data)
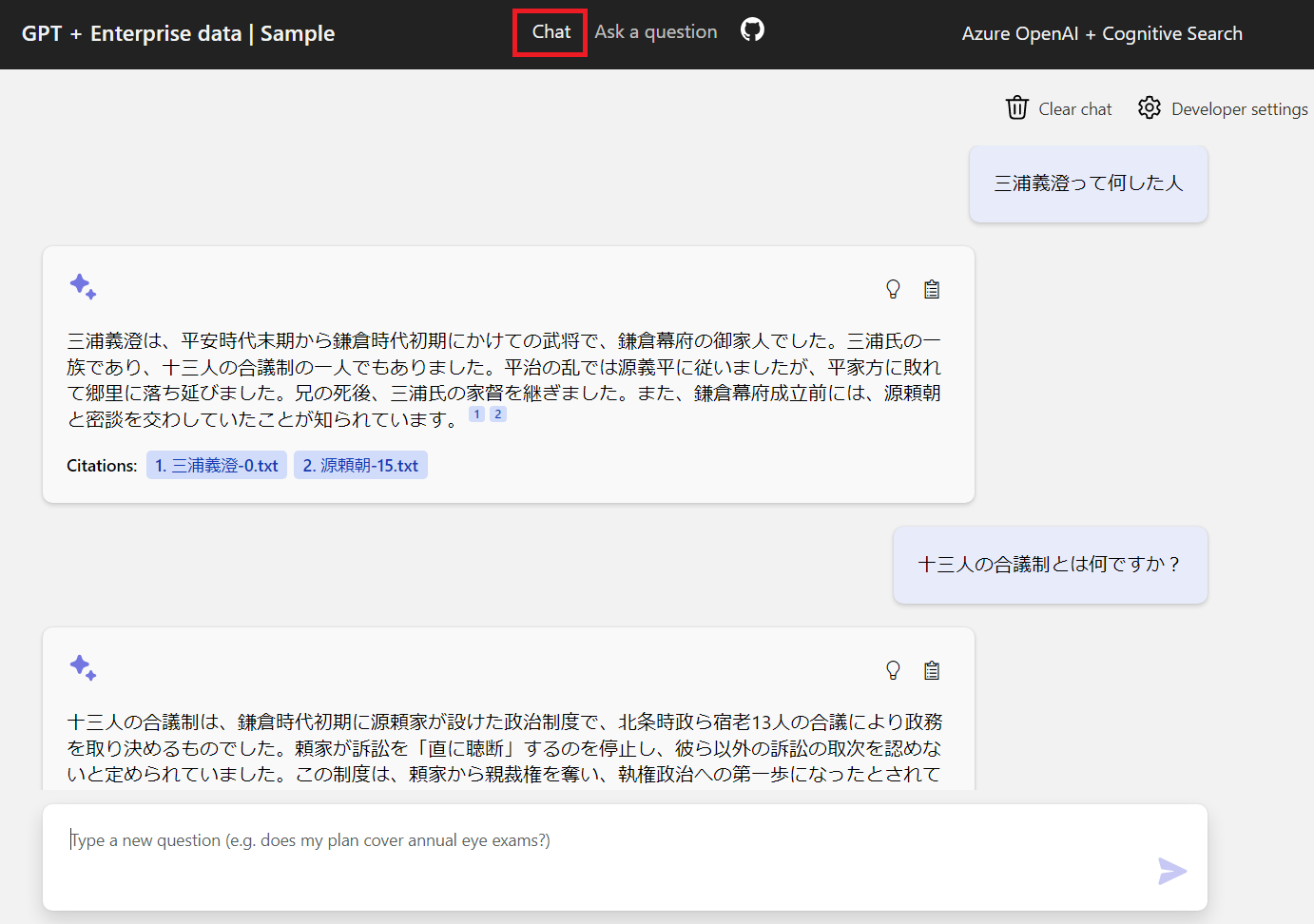
2. チャット UI
チャット UI はデフォルトで表示される UI で、チャットボット形式で質問を重ねることができます。
2.1. 内部の処理
チャット UI の内部処理を以下の図で説明します。
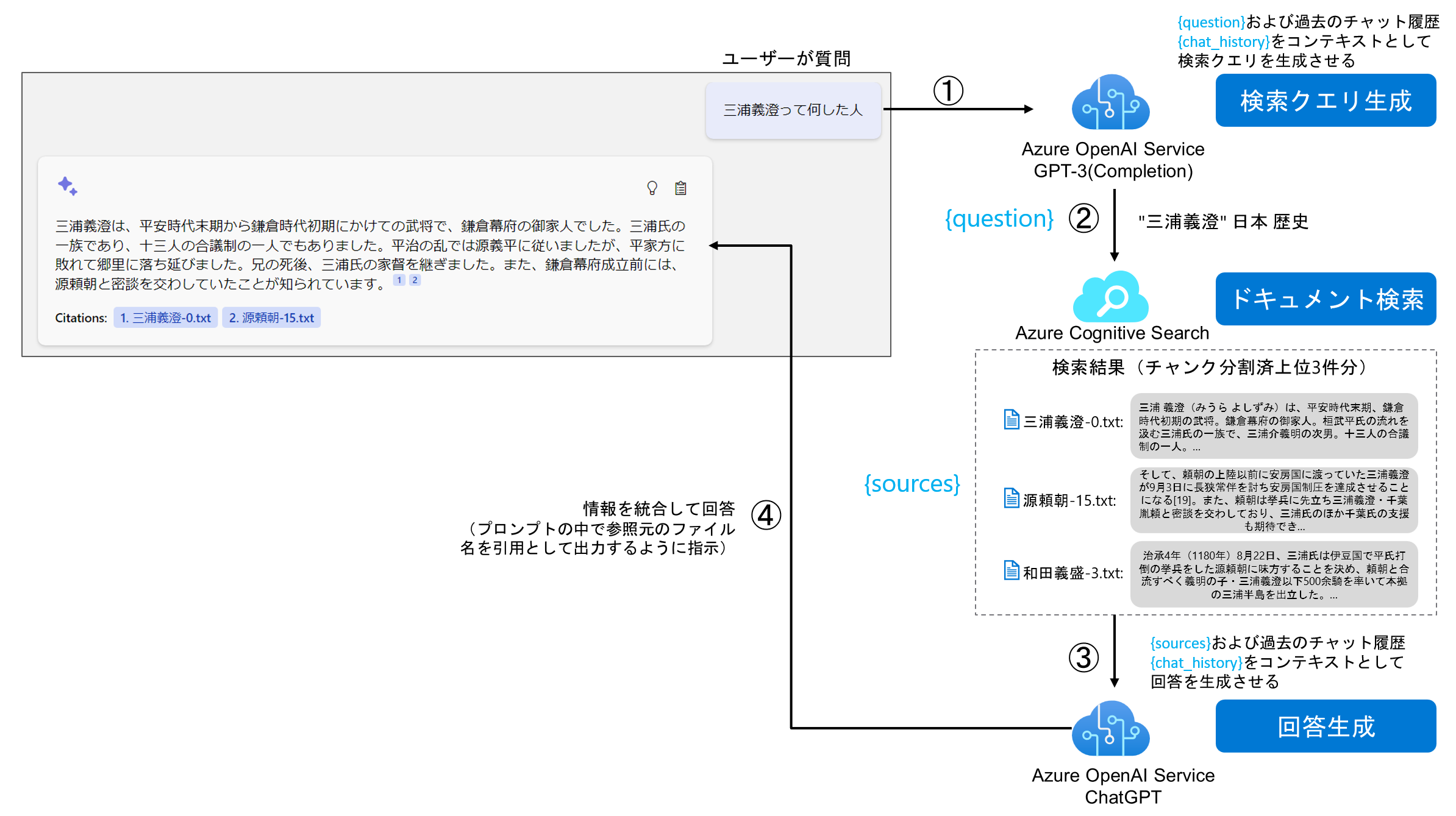
①検索クエリーの生成
チャット履歴と最後の質問をもとに、GPT-3 Completion を利用して最適化されたキーワード検索クエリを生成します。モデルが知らない内容は外部検索エンジンに問い合わせる手法がありますが、その対象を Azure Cognitive Search にしたということですね。また、この部分はベクトル類似検索によって構築することも可能ですね。精度・価格・パフォーマンスなどの観点から検証をしたいところです。
以下コード(chatreadretrieveread.py)ですが、LangChain のプロンプトテンプレートの使い方に似ていますね… 私の方でデモ用に役割を書き換えています。
query_prompt_template = """以下は、これまでの会話の履歴と、日本の歴史に関するナレッジベースを検索して回答する必要がある、ユーザーからの新しい質問です。
会話と新しい質問に基づいて、検索クエリを作成します。
検索クエリには、引用元のファイル名や文書名(info.txtやdoc.pdfなど)を含めないでください。
検索キーワードに[]または<<>>内のテキストを含めないでください。
Chat History:
{chat_history}
Question:
{question}
Search query:
"""
Azure Cognitive Search が BM25 ベースのキーワード検索に頼っていることを考えると、ここの検索精度が生命線になってくるのではないでしょうか。
②検索インデックスから関連文書を取得
①で生成した検索クエリーを使って、Azure Cognitive Search からチャンキングされたドキュメントを取得します。Azure Cognitive Search で現在プレビュー中のセマンティック検索の「セマンティックランカー」機能を利用して検索ランキングの精度を向上させることもできます。
さらにコードを見ると、検索結果のセマンティック キャプション(抽出的要約)を生成して結果のテキストに加えるオプションもあります。
③ChatGPT を利用した回答の生成
Azure Cognitive Search の検索結果やチャット履歴を利用して、コンテキストや内容に応じた回答を生成します。ここでプロンプトを使って出典名を出力するように指示しています。出典名は Azure Cognitive Search のファイル名のフィールドの値を使用します。
prompt_prefix = """<|im_start|>system
日本の歴史に関する質問をサポートする教師アシスタントです。回答は簡潔にしてください。
以下の出典リストに記載されている事実のみを回答してください。以下の情報が十分でない場合は、「わからない」と答えてください。以下の出典を使用しない回答は作成しないでください。ユーザーに明確な質問をすることが助けになる場合は、質問してください。
各出典元には、名前の後にコロンと実際の情報があり、回答で使用する各事実には必ず出典名を記載してください。ソースを参照するには、四角いブラケットを使用します。例えば、[info1.txt]です。出典を組み合わせず、各出典を別々に記載すること。例えば、[info1.txt][info2.pdf] など。
{follow_up_questions_prompt}
{injected_prompt}
Sources:
{sources}
<|im_end|>
{chat_history}
"""
出典名のフォーマットをプロンプトで指示してたとは… 出力された出典名は [出典名] のフォーマットであればフロントエンド側で解釈できます。ここはプログラムで改良可能です。
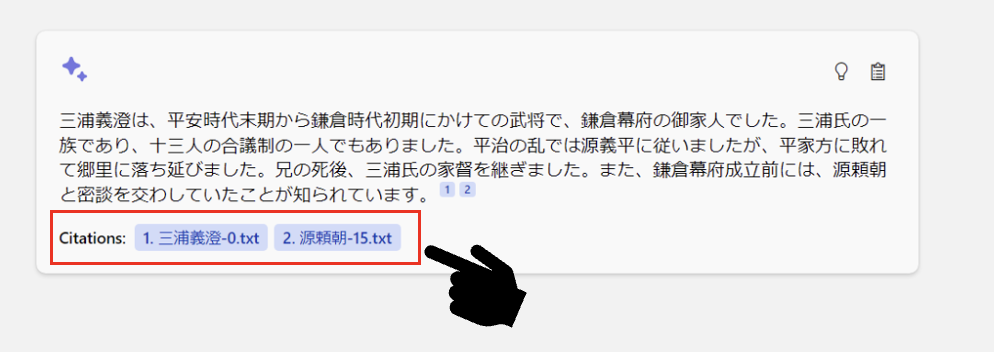
2.2. 画面の解説
Thought process
各回答の💡ボタンをクリックすると、それぞれの回答に使用されたプロンプトの中身を表示することができます。
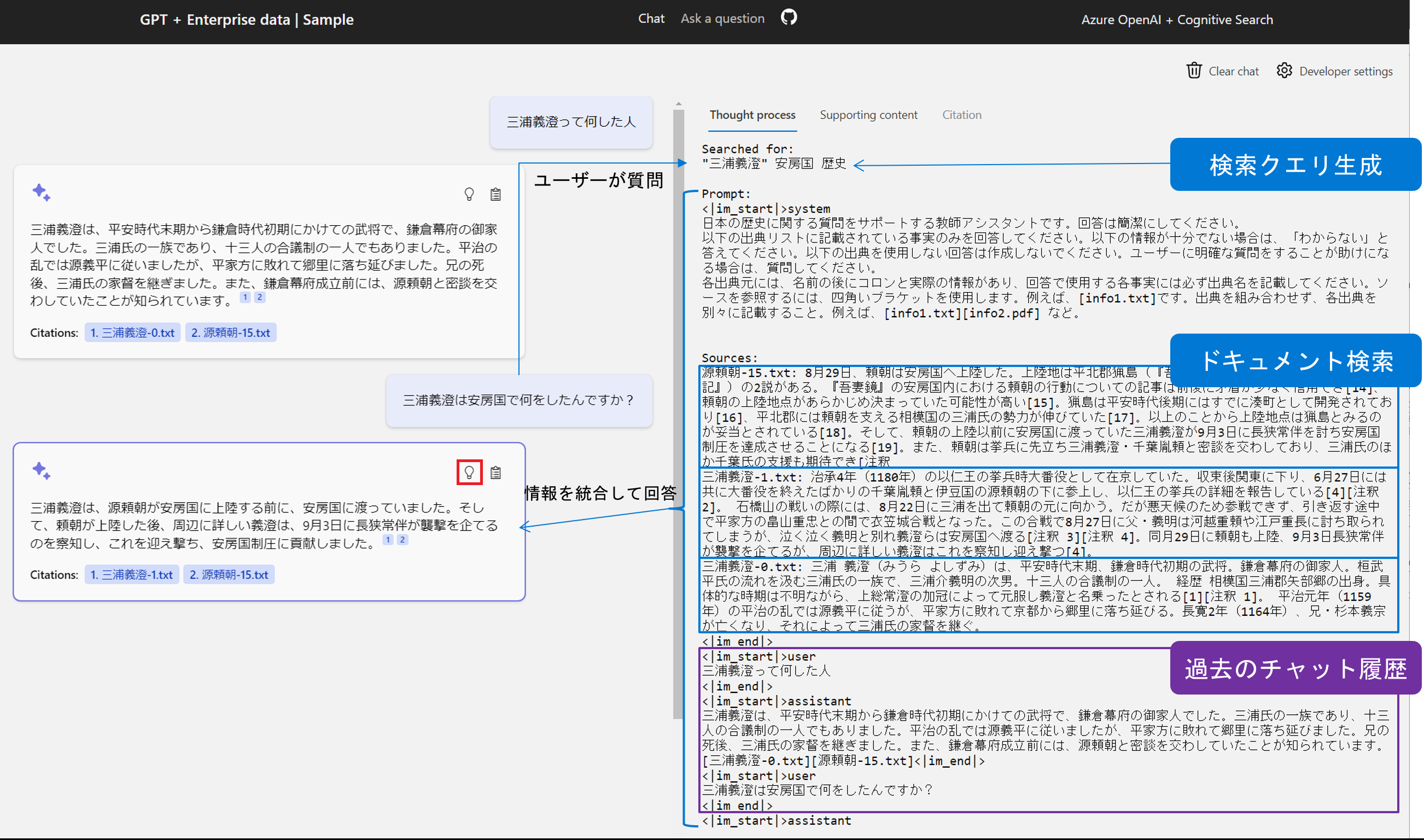
Supporting content
各回答の📋ボタンをクリックすると、それぞれの回答に使用された Azure Cognitive Search の検索結果を見ることができます。
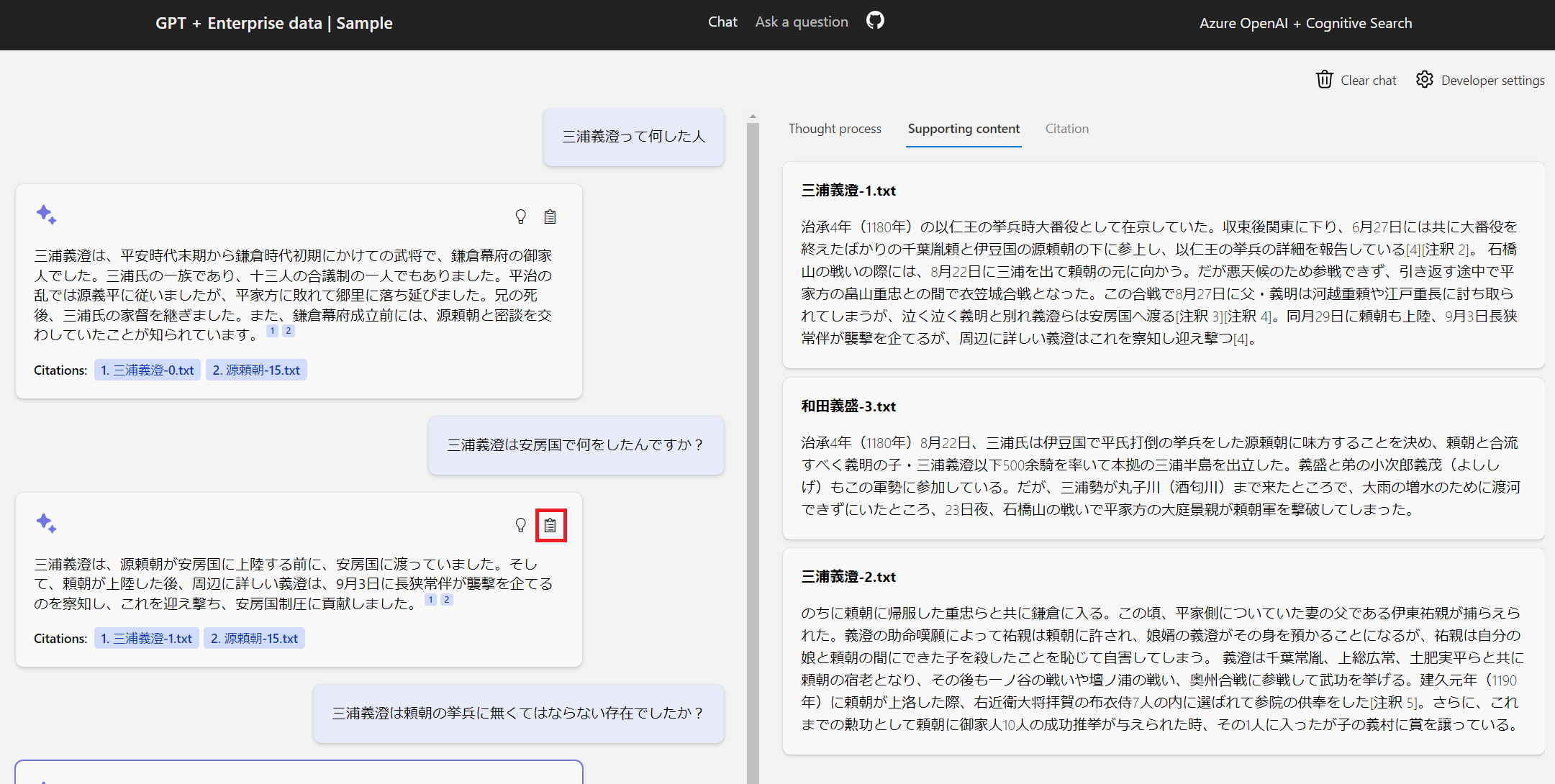
Citation
引用したファイルの中身をプレビューする画面ですが、エンタープライズサーチにおいてファイルの実体にアクセスする機能を実装する場合はセキュリティの観点からアクセス制御に特別な対応が必要です。デモレベルであれば、こちらで紹介しています。
2.3.フォローアップ質問
フォローアップ質問を追加して ChatGPT との対話を促進することができます。
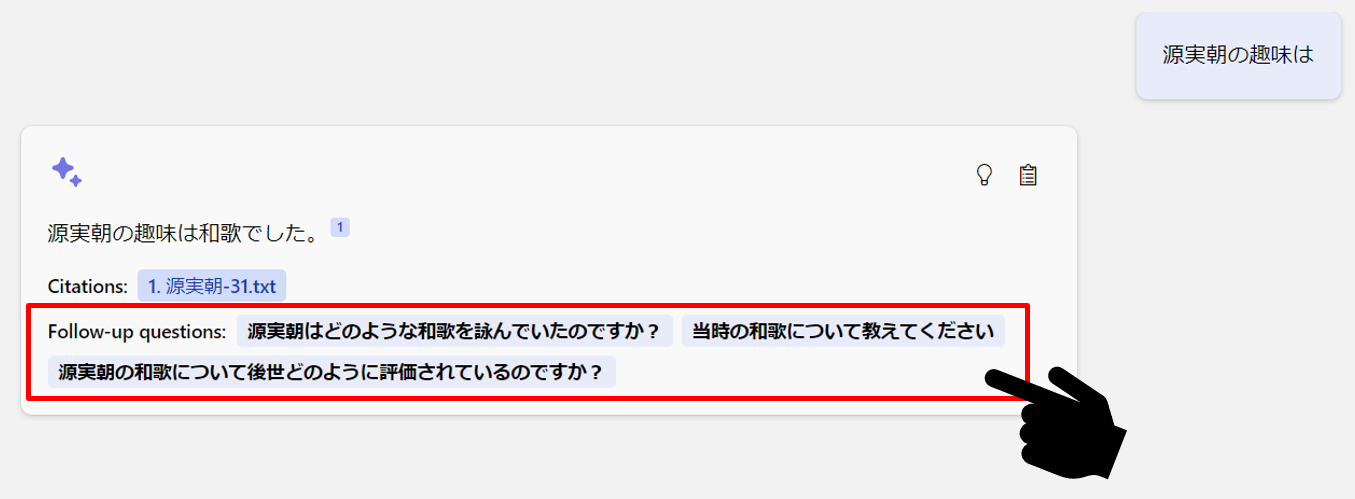
具体的な解説は以下の記事をご覧ください。
2.4. 注意事項
このソースコードはサンプルなのですべての質問に対して完璧には動作しません。私がプロンプトを日本語に訳しているというのもあると思いますが、以下のようにドキュメントには存在しない人物の回答をそれらしく回答するケースもありましたので、プロンプトエンジニアリングおよびプログラムによる制約を強化する必要があるかと思いました。
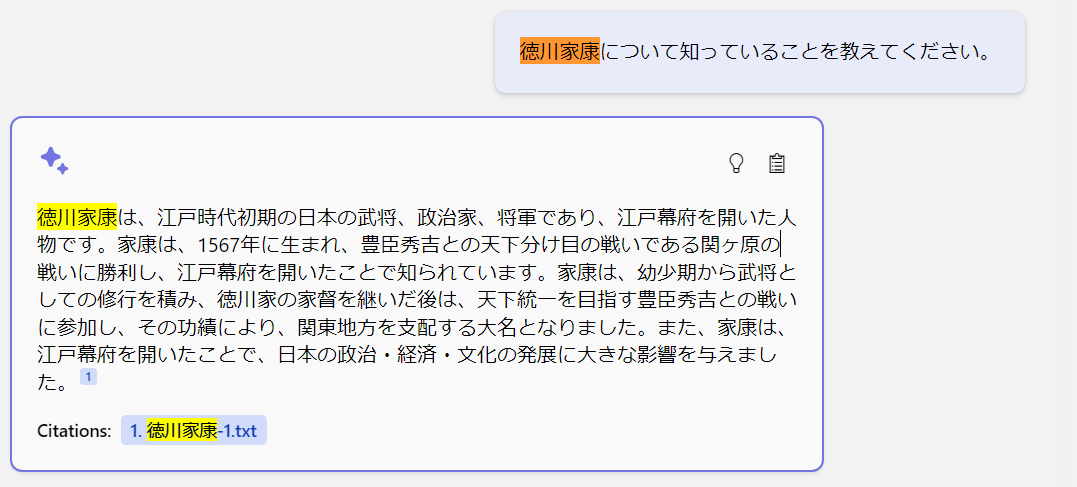
また、このコードだと過去のチャット履歴をつなげ続けると結局は ChatGPT のトークン制限に引っかかるのでこれに対処する仕組みが必要です。AI のセキュリティの観点ではプロンプトインジェクションへの対策も考える必要があります(いったん検索クエリに変換して、ドキュメントを検索してその中から回答する場合の対応なので限られてくるとは思いますが)
データプライバシー
Azure OpenAI Service は、コンプライアンス、プライバシー、およびセキュリティを考慮して設計されています。詳しいデータプライバシーのドキュメントをお読みください。機能としてプライベートネットワーク、ロールベースのアクセス制御(RBAC)、リージョンの可用性、責任ある AI コンテンツのフィルター処理が提供されます。
3. 質問応答 UI
質問応答 UI は一問一答の FAQ を行うための UI です。以下の 3 つの方法が実装されています。
-
Retrive-Then-Read
最もシンプルなアプローチで、ユーザーの質問を Azure Cognitive Search で検索し、上位の候補を取得してその内容をコンテキストとして、プロンプトに送信して回答を生成します。 -
Read-Retrive-Read
質問に対してどのような情報が欠けているのかを確認するために、質問を繰り返し評価し、すべての情報が揃ったところで、回答を作成することを試みます。LangChain の Docs によるとこの手法は zero-shot-react-description に該当し、ReAct フレームワークを使用して、Tool のdescriptionのみに基づいて使用するツールを決定します。コードでは Tool を 2 つ使用して情報を検索しています。 -
Read-Decompose-Ask
react-docstore アプローチを使用して質問を分割してSearchやLookupを行うことで、質問に答えられるまで事実を探します。Searchはドキュメント検索、Lookupで最後に見つかったドキュメント内の用語を検索できるようにする必要があります。外部システムのLookupとしてたとえば、内部アプリケーションの従業員テーブルや顧客サポート アプリケーションのインシデント テーブル等が挙げられます。
3.1. Retrive-Then-Read
チャット UI と仕組みは同じですが、こちらは One-Shot で実行しています。
3.2. Read-Retrive-Read
ZeroShotAgent に指定した 1 つ目の Tool の Azure Cognitive Search のインデックスには、源範頼のゆかりの地にあるカフェに関する情報はありません。2 つ目の Tools に指定した CSV Lookup によって、別のデータソース(今回は武将ごとのゆかりの地にあるカフェデータの CSV)から情報を探して回答しています。
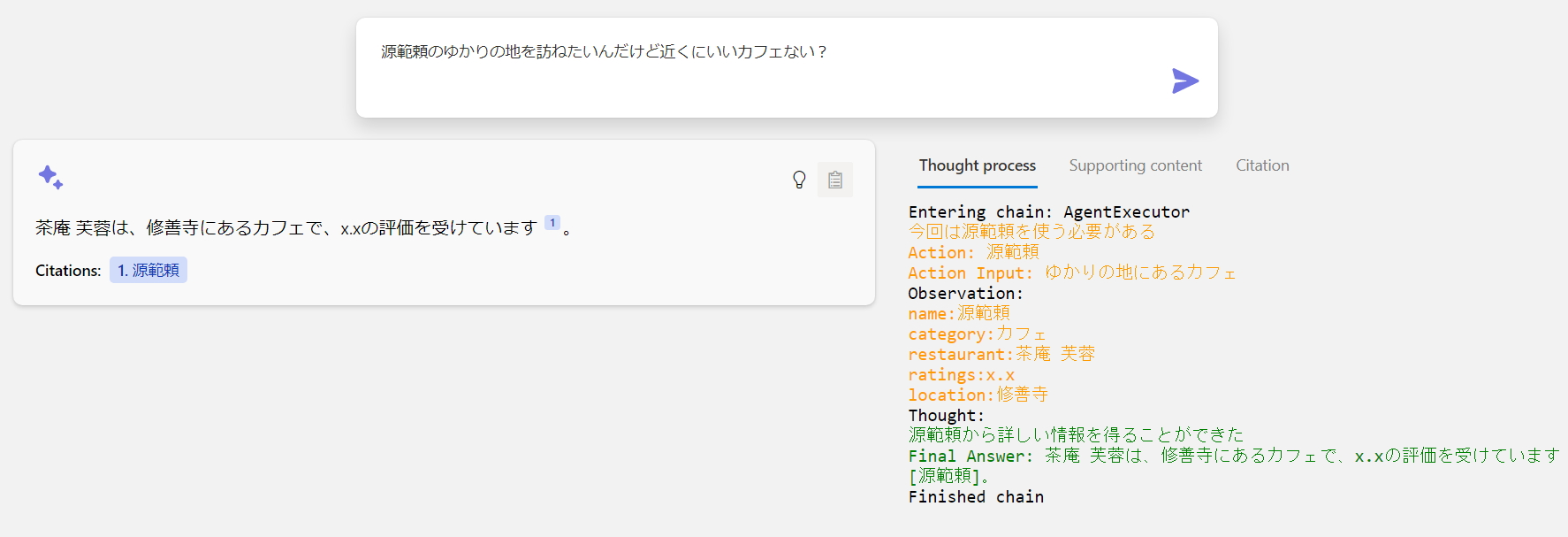
3.2.1 内部の処理(MRKL の実装例)
GPT-3 をオーケストレーター(コントローラー)として動作させる例。

先ほどは問答無用で Azure Cognitive Search へ検索しに行きましたが、MRKL アプローチを実装して事前に与えたツールの中から、「必要なものだけ」使って情報をステップバイステップで収集して回答することができます。これはわざと 2 つのデータソースが必要な質問をしてますが、単にカフェだけを教えてというような質問にすると、Azure Cognitive Search には検索しに行きません。また、これに「行き方を教えて」や、「予約して」みたいな質問にも対応できるように外部 API や社内システムと連携もできるというわけですね。このアプローチもすでにサンプルコードに実装されています。
3.3. Read-Decompose-Ask
日本語で動作させるのが一番つらい機能。普通に質問すると InvalidRequestError: This model's maximum context length is xxx tokens ... エラーが出まくります。なので、コードの各所に制限を加えてとりあえず動くようにはしましたが改善が必要です。
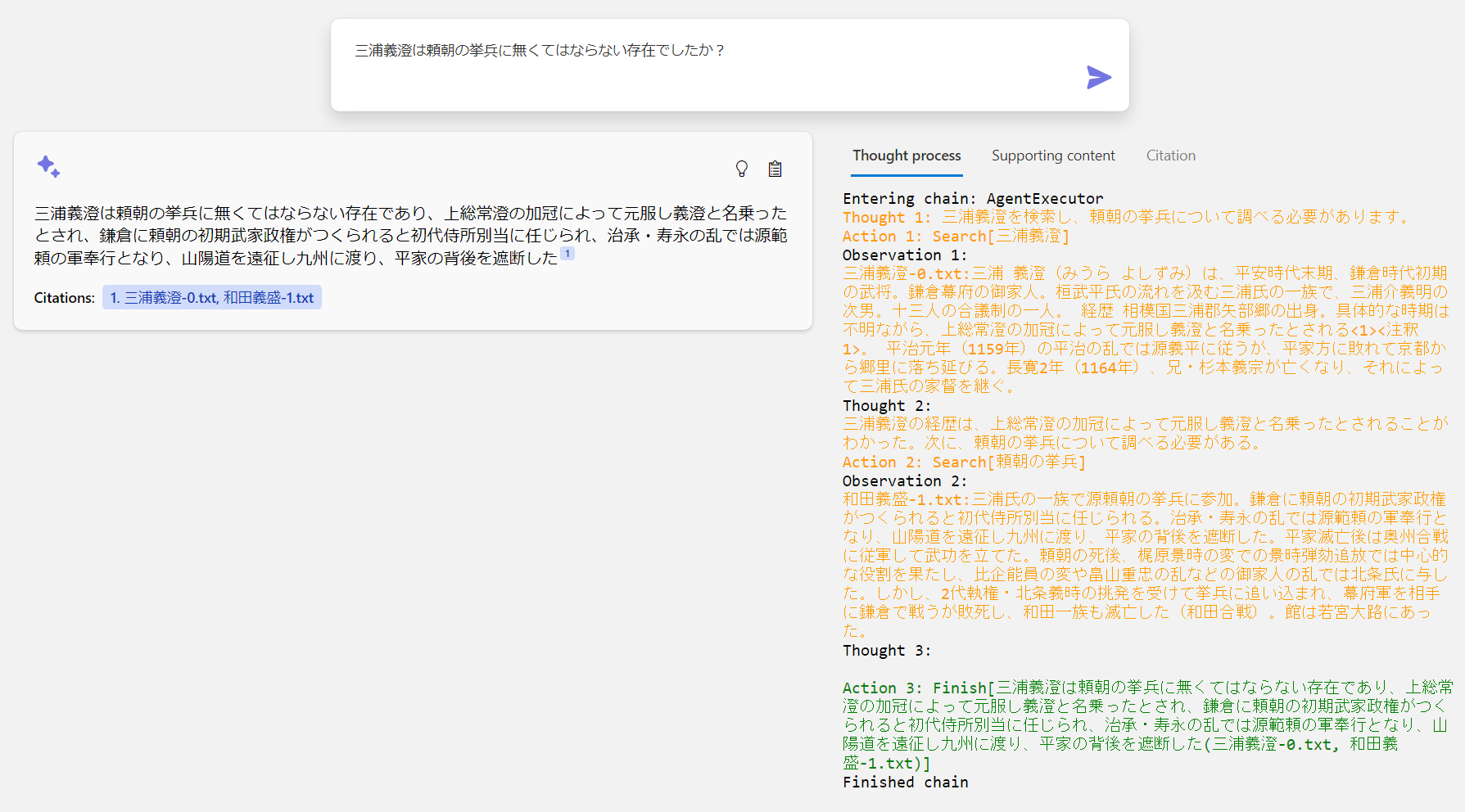
質問文を細かく分割して、短いクエリーごとに Azure Cognitive Search に検索させる、という作業を繰り返しながら段階的に事実を確認していく過程を見ることができます。まぁ、よく見ると間違ってますが…チャンクの区切り方も考えないとですね。
4. 日本語ドキュメント用サンプルコード
公式のほうのサンプルコードを fork して鎌倉時代の武将版に改造したものをアップしています。取り急ぎデモできるレベルの適当カスタマイズです。
4.1. ローカル開発環境構築手順
上記レポジトリの手順参照
おわりに
ChatGPT の盛り上がりと同時に、エンタープライズナレッジベースとしての Azure Cognitive Search も盛り上げていきたいと思っています。今後このサンプルデータを使ったワークショップなども検討したいなと思っています。
3/15 GPT-4 の登場で最大 32,768 トークンまで使えるモデルが出てきたので今後さらに検索体験が向上しそうです。
3/17 新たに発表された Semantic Kernel(SK) と統合することで、さらに高度化しそうです。
4/1 続編はコチラ