Pythonのスーパーセットとして互換性を保ちながら、驚くべき速さで実行できると話題の「Mojo」をGoogle Colab上で動作させる方法について解説します。
Mojoについては、おおまかには、以下の通りです。
Modular社は、コンパイラ基盤として広く使われているLLVM、Swift言語、GoogleがAI処理のために設計したCloud TPUなどの開発に関わってきたChris Lattner氏が共同創業者兼CEOを務める企業です。
その同社が5月に初めてMojoを発表した際に、MojoはAI処理を高速に実行するための言語だと説明しました。
MojoはPythonとの互換性によって既存のTensorFlowやPyTorchなどをそのまま利用可能。そのうえで、より高速な処理を実現することで、AI処理の開発や実行のコスト削減などを実現するとしました。
Mojo is a programming language that is as easy to use as Python but with the performance of C++ and Rust. Furthermore, Mojo provides the ability to leverage the entire Python library ecosystem.
との解説の通り、ディープラーニング系、LLM系の開発者には非常に重要(になるかもしれない)言語です。
さらなる詳細については、以下の記事などをご覧ください。
本記事では、カウンティングの計測用関数に対して、Python、Python+numba、Rust、Mojoで速度比較を行います。
Google Colab上では「Rust」と「Mojo」はデフォルトでは動作しないので、どうすれば動作させられるのかを本記事では解説します。
本記事の内容は次の通りです
手順1: MojoのサイトからAuthの情報を取得するために、メールアドレスを登録する
手順2: Google ColabでMojoを使用できるように設定する
手順3: Google ColabでRustを使用できるように設定する
手順4: 速度比較用の実行プログラムを用意
手順5: 速度比較の結果
本記事で解説する、Google Colab上で動作するノートブックの実装コードはこちらになります
手順1: MojoのサイトからAuthの情報を取得するために、メールアドレスを登録する
Mojoのドキュメントの「Get the Mojo SDK」をクリックし、メールアドレスを登録します。
そして届いたメールに記載のコードを入力すると、以下のような画面に遷移します。
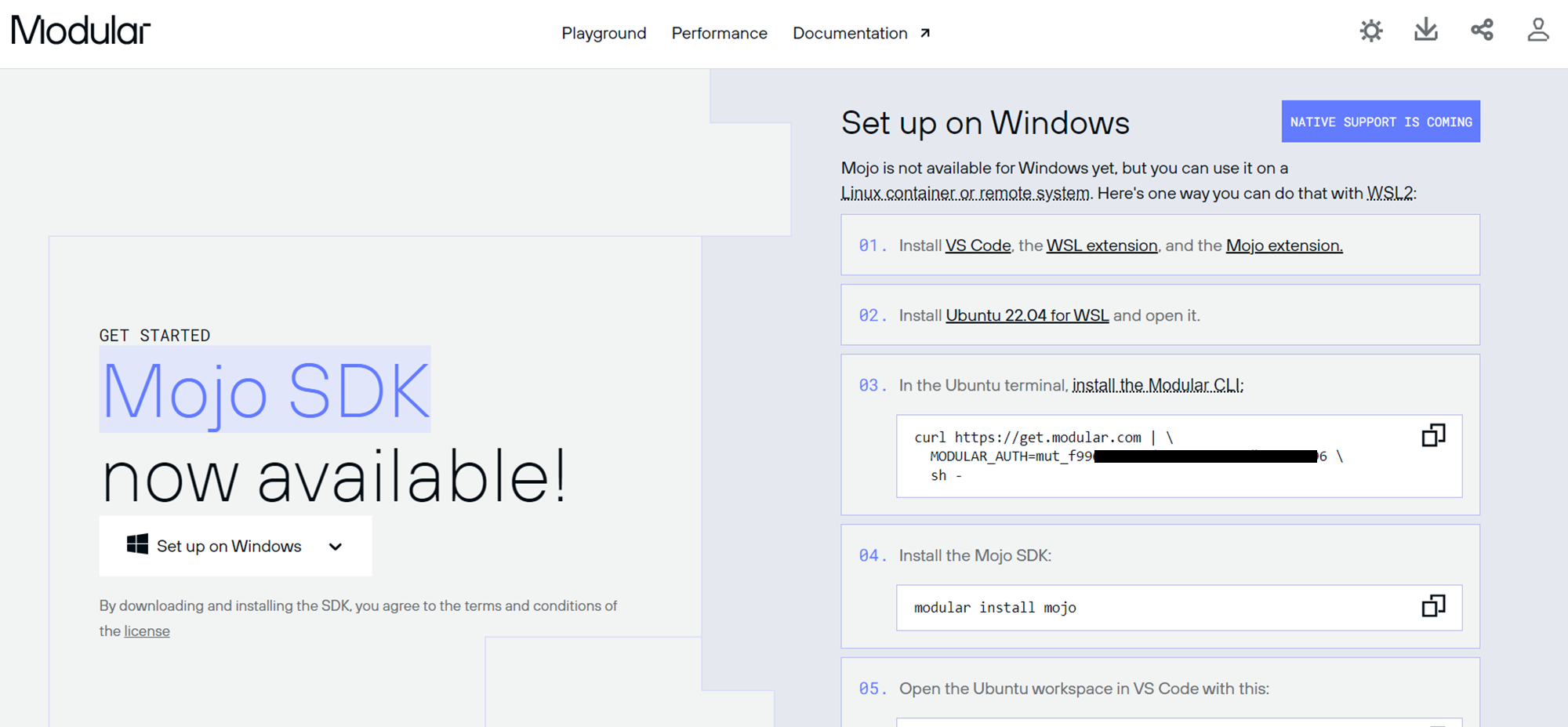
この画面の情報をGoogle Colab上で入力していきます。
手順2: Google ColabでMojoを使用できるように設定する
さきほどの「Set up on Windows」の画面で紹介されている手順の通りにGoogle Colab上で実行していきます。
[1] Install the Modular CLI
! curl https://get.modular.com | \
MODULAR_AUTH=<YOUR_MODULAR_AUTH> \
sh -
こちらが実行完了すると、以下のような結果が表示されます。
[2] Install the Mojo SDK
!modular install mojo
# note
# I tried but cannnot install on the cpu runtime.
次にmodularコマンドでmojoをinstallします。
ここで私がCPU環境のGoogle Colabで実施していると、永遠とここのセルが終了しない問題に遭遇しました。
ランタイムをGPUに切り替えて実施するとすぐにうまくいきました。
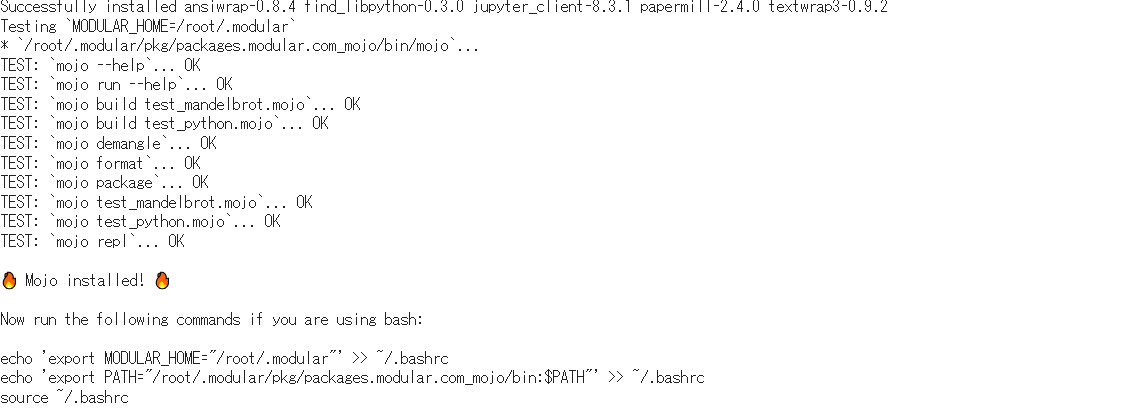
ここで、mojoの動作テストが実施されます。
実行結果は以下の通りです。
[3] Set environment variables on Google Coalboratory
次に、前の実行結果の最後にアナウンスが出力された内容を実施します。
Now run the following commands if you are using bash:
echo 'export MODULAR_HOME="/root/.modular"' >> ~/.bashrc
echo 'export PATH="/root/.modular/pkg/packages.modular.com_mojo/bin:$PATH"' >> ~/.bashrc
source ~/.bashrc
しかし、Google Colabでは基本的に環境変数の設定やPATHの変更は、一時的なセッションのコンテキスト内でのみ有効になります。そのため、exportを使った環境変数の設定とその直後のコマンドの実行は同じセルで行う必要があります
具体的には以下のように実行し、インストールされたmojoのバージョンを確認してみます。
!export MODULAR_HOME="/root/.modular" && \
export PATH="/root/.modular/pkg/packages.modular.com_mojo/bin:$PATH" && \
mojo --version
すると、mojo 0.2.1 (64d14e85)のような出力が表示され、mojoコマンドがきちんと動作していること、mojoがインストールされたことが確認できます。
手順3: Google ColabでRustを使用できるように設定する
速度を比較するのであれば、Pythonと一緒によく使用されるRustとはぜひ比較したいと思うところです。
RustもGoogle Colabではデフォルトでは動作しないので以下のようにして設定します。
!apt install cargo
はじめに「Cargo」(Rustのbuild systemであり、パッケージマネージャでもあります)をインストールします。
あとは、Rustのプロジェクトを作成して、実行するだけとなります。
手順4: 速度比較用の実行プログラムを用意
続いて速度比較用の実験プログラムを用意します。
以下の記事の3重for文で、足し算していく数値の型をint型からfloat型に変えた実験プログラムを今回は試してみました(int型だと早すぎるので、floatで挑戦)
Pythonでの基本的な実装は以下の通りです。
def f(n):
# Main processing
count = 0.0
for i in range(n):
for j in range(i):
for _ in range(j):
count += 1.0
print(count)
return count
そして、このnを2,000に設定した場合と、5,000に設定した場合で実験してみました。
比較対象は
素のPython
Python + numba(@jit(nopython=True)とし、完全にJIT化して実施)
Rust
そして
Mojo
の4種類となります。
手順5: 速度比較の結果
細かい実行部分は実装コードをご覧ください。
なおセル内で実行するものと、ファイルとして作成し、そのファイルを実行するものとに分かれると比較にならないので、すべて一度ファイルに書き出して、実行するように統一しました。
Google Colabo上では、Mojoの実行だけはクセがあるので紹介します。
最初に.mojo形式のファイルを書き出し、
以下のように実行します。
# execution
!export MODULAR_HOME="/root/.modular" && \
export PATH="/root/.modular/pkg/packages.modular.com_mojo/bin:$PATH" && \
mojo main.mojo
もしかしたら、もっと良い方法があるかもしれませんが、9月17日の夜時点では、Google Colabで実行する方法が見つからずです
以下が、速度比較の結果をまとめた表となります。
| Language/Library | Loop Count (2,000 loop) | Loop Count (5,000 loop) |
|---|---|---|
| Python Only | 56.9s | - |
| Python + numba (JIT) | 2.3s | 29.8s |
| Rust | 1.9s | 29.4s |
| Mojo | 1.9s | 29.3s |
素のPythonで3重for文を回すとめちゃくちゃ遅いのは想像通りです。
そして、5,000ループは実行時間が長そうなので、省略しました。
PythonをNumbaと使用すると劇的に早くなります。
Numbaは、PythonおよびNumPyのサブセットのソースコードを高速実行できる機械語へと変換する「JIT コンパイラ」です。
JIT(Just In Time)は、プログラムを実行する前に中間コードにコンパイルしてから実行します。
以下、Rust、Mojoと比較しますが、ほとんど同じ速度になりました。
RustとMojoについては、型をきちんと定義するという点では実装が似ているのですが、より少ない実装コードでMojoは実装が可能です(Pythonに近い)。
またMojoからPythonが実行できること、そしてRustとは異なり、Mojoはコンパイルが明示的ではなく、背後でこっそり実施されているようで(JIT化に似ている?)、RustのようにBuildを待つ時間が不要なのがありがたいです。
現在すでにいくつかのPythonプログラミングでMojoに置き換えてみる試みが始まっています。
例)llama2.mojo
Mojoのリリースにより、[llama2.py]のPythonポートをMojoに移行することにインスパイアされました。その結果、Mojoの[SIMD]および[ベクトル化プリミティブ]を活用したバージョンができ、Pythonのパフォーマンスをほぼ[_ 250倍]に向上させました。驚くべきことに、Mojoバージョンは今や、実行速度優先モードでも、元のllama2.cを15〜20%上回ります。これは、Mojoの高度な機能を通じたハードウェアレベルの最適化のポテンシャルを示しています。これはまた、元のllama2.cのハードウェア最適化がどれだけ進化できるかを見るのに役立つと思います。
DL系の各種モデルに有効活用できそうです。
とくにLLM系アプリケーションを構築する際、推論速度(レスポンス速度)に効きそうです。また、訓練、ファインチューニングの速度向上にもMojoが有効な可能性があります。
今後伸びていく言語かもしれず、個人的には要注目だと感じています。
気になる方はぜひ、最初は手軽にGoogle Colab上で遊んでみてください。
(再掲)本記事で用意したGoogle Colab上で動作するノートブックの実装コードは以下になります。
以上、ご一読いただき、ありがとうございました。
小川 雄太郎
【免責】
本記事の内容は執筆者の意見/発信であり、執筆者が属する企業等の公式見解ではございません