本記事はElastic Stack (Elasticsearch) Advent Calendar 2020 12月15日分の記事です。
やりたいこと
はじめまして、Supership株式会社の中野と申します。業務ではデータ集計・分析基盤と全文検索システムを構築・運用しています。
Elasticsearchを分析目的で使用する場合、少数のノードで大量のデータを高速にフィルタリング・集計できる一方で、indexing負荷の高さからデータ投入にかかる時間が長くなりがちです。
集計負荷に合わせて少ないノード数で運用するとindexingが遅い。indexing負荷に合わせて大量のノードを確保し続けるのはコストがかかる。ということで、indexing時だけノード数を増やして短時間で処理を完了させ、集計時は少数のノードでElasticsearchを運用して価格を抑えたいと考えました。
やったこと概要
650GB, 20.3億件のデータをm6gd.4xlarge 1node上のElasticsearchに取り込み、利用できる状態になるまでの所要時間を3種類の方法で計測しました。
| indexing方法 | 所要時間 |
|---|---|
| 1nodeのまま直接indexing | 237分2秒 |
| 5nodeに増強してindexingし、1nodeにshardを転送して縮退 | 66分52秒 (indexing 54分55秒 + shard転送 11分57秒) |
| 5nodeの一時クラスタでindexingし、S3 snapshot & restoreで集計用クラスタに転送 | 84分37秒 (indexing 54分55秒 + S3 snapshot 4分51秒 + restore 24分51秒) |
| 一時的にノードを増やすことで、indexingを短時間で完了できることを確認できました。詳しく見ていきましょう。 |
詳細
共通
今回の検証では、データ・サーバ・設定を下記の内容で揃えてあります。
- データ
- 非圧縮状態のjsonlファイルで650GB
- 20.3億件
- Elasticsearch 7.10
- サーバはAWS EC2 m6gd.4xlarge
- 今回のようにCPUの複数コアを全開で回す用途では、Graviton2プロセッサのコスパが圧倒的
- ディスクIOがボトルネックになるのを避けるため、Elasticsearchのデータとログはインスタンスストレージに置く
- 本番と同等のデータ量を想定したノードサイズ
- m6gdは日本では未提供なのでus-east-1で検証
- indexing速度最優先の設定
- shard数 = Elasticsearchクラスタ全体に割り当てたvCPU数 とする
- 検索・集計の点からはshard過多。対処は後日改めて考える
- data post 並列数 = Elasticsearchクラスタ全体に割り当てたvCPU数 とする
- refresh_intervalは0、全データPOST後に自分で_refreshを呼ぶ
- shard数 = Elasticsearchクラスタ全体に割り当てたvCPU数 とする
1nodeのまま直接indexing
Elasticsearchのクラスタサイズを変更せず、そのままデータをindexingします。
最もシンプルで、よく行われる方法です。説明は必要ないでしょう。
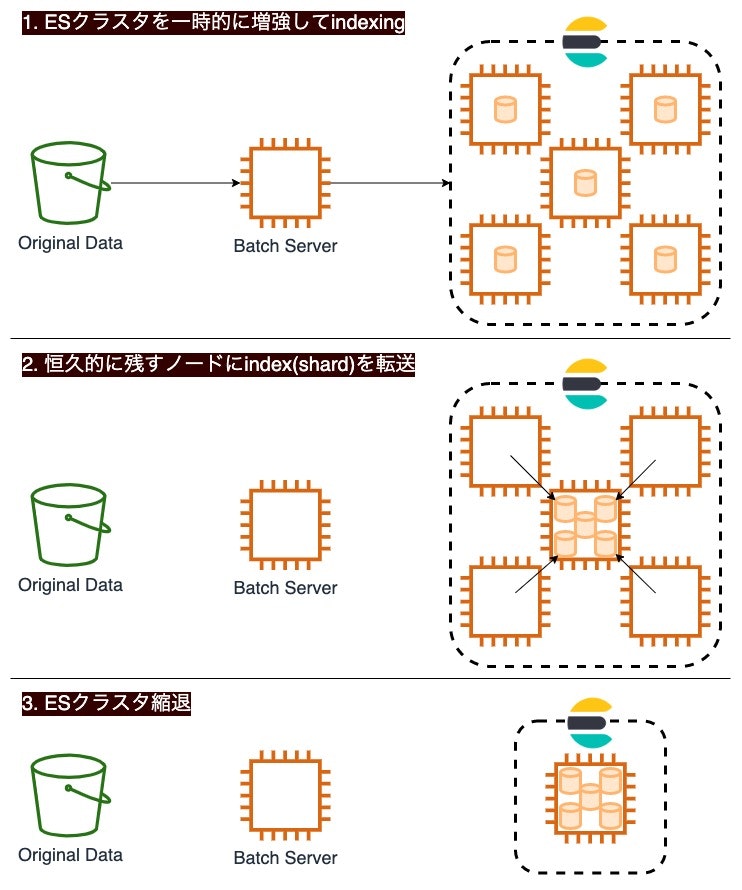
5nodeに増強してindexingし、1nodeにshardを転送して縮退
indexing時だけElasticsearchのノード数を増やし、indexingが終わったらノード数を減らします。
ノードを退役させる前に、作り終わったindexを稼働を続けるノードに転送します。
構築・実装のポイント
- indexing中だけ稼働させるノードは、
elasticsearch.ymlにnode.roles: [data]を設定し、データ専業ノードとします。 - Elasticsearchのデフォルト設定では、shardの転送が負荷にならないよう制限がかかっています。今回は負荷低減よりも速度を優先したいので、下記の操作を行って制限を緩めておきます。
PUT /_cluster/settings
{
"persistent" : {
"indices.recovery.max_bytes_per_sec" : "100gb",
"indices.recovery.max_concurrent_file_chunks": 4,
"indices.recovery.max_concurrent_operations": 4,
"cluster.routing.allocation.node_concurrent_recoveries": 16
}
}
- indexing, refreshが完了した後、下記の操作を行うことでshardの転送が始まります。
PUT /_cluster/settings
{
"transient": {
"cluster.routing.allocation.exclude._ip": "退役させるノードのIPアドレスをカンマ区切りで"
}
}
- shardの転送が完了してindexingに使ったノードを終了させたら、次に同じIPアドレスが使われたときに誤動作しないようallocationの除外設定を外しておきます。
PUT /_cluster/settings
{
"transient": {
"cluster.routing.allocation.exclude._ip": ""
}
}
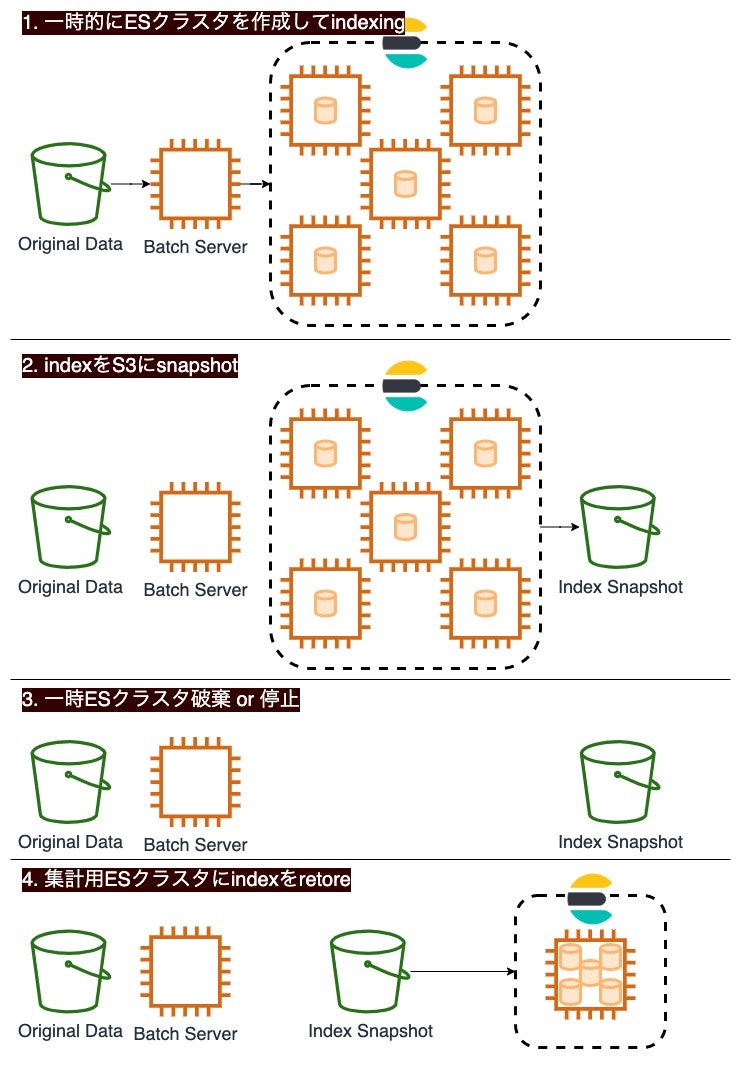
5nodeの一時クラスタでindexingし、S3 snapshot & restoreで集計用クラスタに転送
揮発性の大規模クラスタでindexingを行い、作ったindexをS3にsnapshotで保存してクラスタを削除します。
集計用のクラスタには、S3上のsnapshotをrestoreすることでデータを取り込みます。
構築・実装のポイント
- indexing用一時クラスタ、集計用クラスタの両方でrepository S3 pluginが必要です。aarch64用のElasticsearchはelasticsearch-plugin installコマンドがハングアップして正常終了しないため、zipファイルを特定のディレクトリに展開することでプラグインのインストールを行います。
$ curl -XGET 'https://artifacts.elastic.co/downloads/elasticsearch-plugins/repository-s3/repository-s3-7.10.0.zip' > repository-s3-7.10.0.zip
$ sudo unzip -d /usr/share/elasticsearch/plugins/repository-s3 repository-s3-7.10.0.zip
- S3 snapshotを利用するには、indexing用一時クラスタ、集計用クラスタの両方でsnapshotリポジトリを定義しておきます。
PUT /_snapshot/<snapshotリポジトリ名>
{
"type": "s3",
"settings": {
"bucket": "S3バケット名",
"base_path": "path/to/snapshot/location",
"max_snapshot_bytes_per_sec": "100gb"
}
}
- indexing, refreshが完了した後、indexing用一時クラスタで下記の操作を行うことで、S3にindex snapshotが作られます。
PUT /_snapshot/<snapshotリポジトリ名>/<snapshot名>?wait_for_completion=true
{
"indices": "snapshotするindexをカンマ区切りで",
"include_global_state": false,
"metadata": {
"taken_by": "me",
"comment": "test"
}
}
- Elasticsearchのデフォルト設定では、リカバリが負荷にならないよう制限がかかっています。今回は負荷低減よりも速度を優先したいので、集計用ESクラスタで下記の操作を行って制限を緩めておきます。
PUT /_cluster/settings
{
"persistent" : {
"indices.recovery.max_bytes_per_sec" : "100gb",
"indices.recovery.max_concurrent_file_chunks": 4,
"indices.recovery.max_concurrent_operations": 4,
"cluster.routing.allocation.node_concurrent_recoveries": 16
}
}
- 集計用クラスタで下記の操作を行うことで、S3上のsnapshotからindexをrestoreします。
POST /_snapshot/<snapshotリポジトリ名>/<snapshot名>/_restore?wait_for_completion=true
{
"indices": "restoreするindex名をカンマ区切りで",
"include_global_state": false
}
備考
- 今回はCPUを完全に使い切りindexing時間を短縮することを最優先したため、shard数 = Elasticsearchクラスタ全体に割り当てたvCPU数 と設定しました。5nodeでindexingした場合は80shardとなり、検索・集計の性能を考えればshard数過多でしょう。indexing時にCPUをきっちり使えつつshard数過多にならないバランスは、今後追加検証していく予定です。
- インスタンスストレージは書き込み帯域が500MB/sしか出ず、転送されたshardを書き込む時にボトルネックになってしまいました。大容量のEBS gp2をRAID0で使えば同じくらいの帯域になるはずですし、ap-northeast-1でも使えますし、永続化もできて良いかもしれません。

- 一時clusterでindexing => S3 snapshot & restore はスポットインスタンスを使って検証しました。常時稼働の分析用クラスタはRIやSaving Plansで、揮発性の一時クラスタによるindexingはスポットインスタンスで運用できれば、コストを抑えられそうですね。

検証を終えて
「やりたいこと」で記載した indexing時だけノード数を増やして短時間で処理を完了させ、集計時は少数のノードでElasticsearchを運用して価格を抑えたい を実現する道筋が見えてきました。今のところ、既存の集計用ESクラスタへの影響が少なくindexバックアップも同時に作れる、indexing専用一時クラスタ + S3 snapshot & restore の方法が良さそうと思っています。本番投入に向けて検証を続けていきたいです。
最後に宣伝です。今年、私はSupershipグループと本番環境でやらかしちゃった人のアドベントカレンダーにも参加しています。こちらもぜひご覧ください。